 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Class Cell Detection Using Spatial Context Representation
Oct 10, 2021


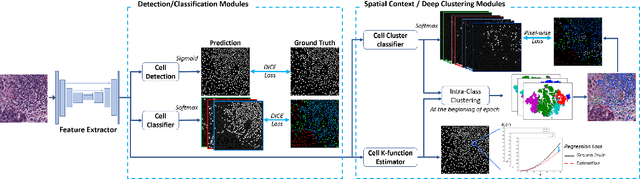

In digital pathology, both detection and classification of cells are important for automatic diagnostic and prognostic tasks. Classifying cells into subtypes, such as tumor cells, lymphocytes or stromal cells is particularly challenging. Existing methods focus on morphological appearance of individual cells, whereas in practice pathologists often infer cell classes through their spatial context. In this paper, we propose a novel method for both detection and classification that explicitly incorporates spatial contextual information. We use the spatial statistical function to describe local density in both a multi-class and a multi-scale manner. Through representation learning and deep clustering techniques, we learn advanced cell representation with both appearance and spatial context. On various benchmarks, our method achieves better performance than state-of-the-arts, especially on the classification task.
Fuzzy-Depth Objects Grasping Based on FSG Algorithm and a Soft Robotic Hand
Oct 21, 2021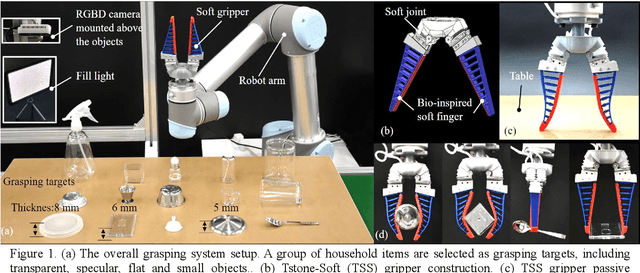
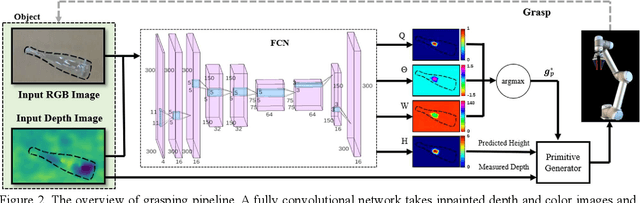
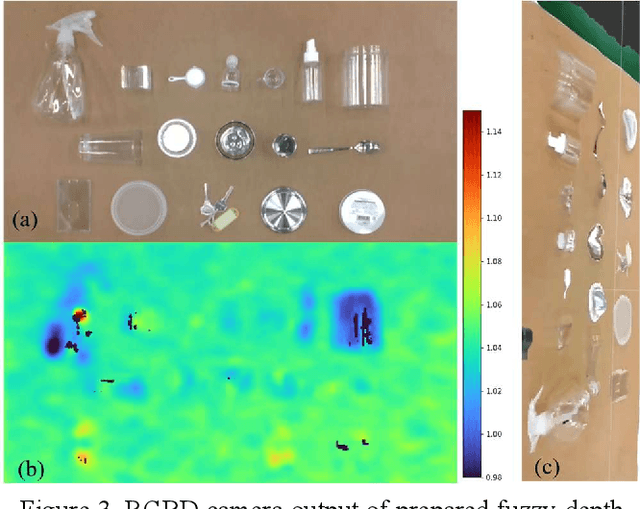

Autonomous grasping is an important factor for robots physically interacting with the environment and executing versatile tasks. However, a universally applicable, cost-effective, and rapidly deployable autonomous grasping approach is still limited by those target objects with fuzzy-depth information. Examples are transparent, specular, flat, and small objects whose depth is difficult to be accurately sensed. In this work, we present a solution to those fuzzy-depth objects. The framework of our approach includes two major components: one is a soft robotic hand and the other one is a Fuzzy-depth Soft Grasping (FSG) algorithm. The soft hand is replaceable for most existing soft hands/grippers with body compliance. FSG algorithm exploits both RGB and depth images to predict grasps while not trying to reconstruct the whole scene. Two grasping primitives are designed to further increase robustness. The proposed method outperforms reference baselines in unseen fuzzy-depth objects grasping experiments (84% success rate).
Finite-Time Error Bounds for Distributed Linear Stochastic Approximation
Nov 24, 2021This paper considers a novel multi-agent linear stochastic approximation algorithm driven by Markovian noise and general consensus-type interaction, in which each agent evolves according to its local stochastic approximation process which depends on the information from its neighbors. The interconnection structure among the agents is described by a time-varying directed graph. While the convergence of consensus-based stochastic approximation algorithms when the interconnection among the agents is described by doubly stochastic matrices (at least in expectation) has been studied, less is known about the case when the interconnection matrix is simply stochastic. For any uniformly strongly connected graph sequences whose associated interaction matrices are stochastic, the paper derives finite-time bounds on the mean-square error, defined as the deviation of the output of the algorithm from the unique equilibrium point of the associated ordinary differential equation. For the case of interconnection matrices being stochastic, the equilibrium point can be any unspecified convex combination of the local equilibria of all the agents in the absence of communication. Both the cases with constant and time-varying step-sizes are considered. In the case when the convex combination is required to be a straight average and interaction between any pair of neighboring agents may be uni-directional, so that doubly stochastic matrices cannot be implemented in a distributed manner, the paper proposes a push-sum-type distributed stochastic approximation algorithm and provides its finite-time bound for the time-varying step-size case by leveraging the analysis for the consensus-type algorithm with stochastic matrices and developing novel properties of the push-sum algorithm.
MutualGraphNet: A novel model for motor imagery classification
Sep 02, 2021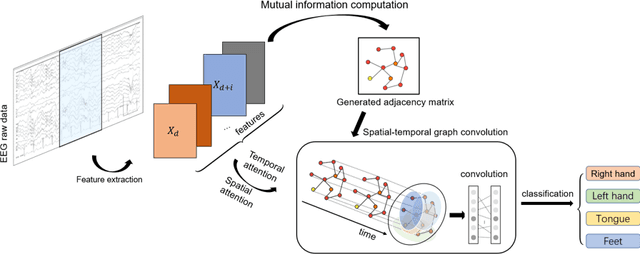
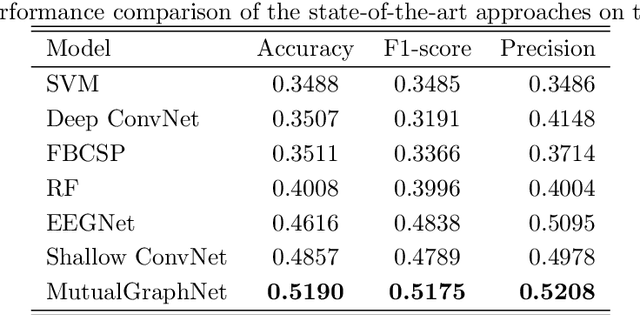
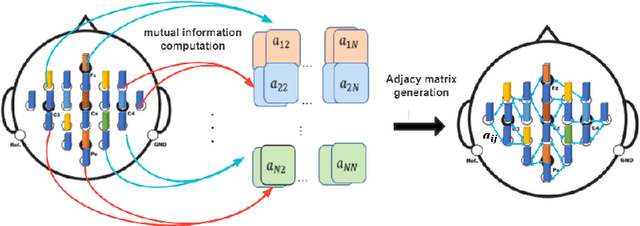
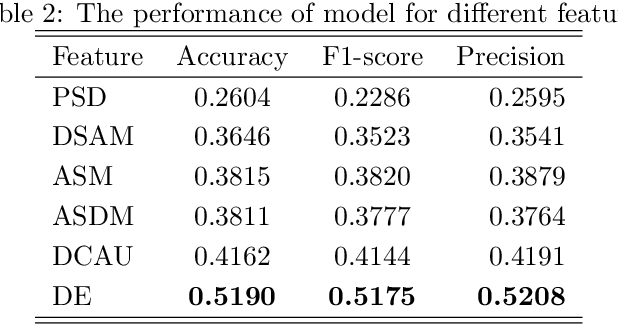
Motor imagery classification is of great significance to humans with mobility impairments, and how to extract and utilize the effective features from motor imagery electroencephalogram(EEG) channels has always been the focus of attention. There are many different methods for the motor imagery classification, but the limited understanding on human brain requires more effective methods for extracting the features of EEG data. Graph neural networks(GNNs) have demonstrated its effectiveness in classifying graph structures; and the use of GNN provides new possibilities for brain structure connection feature extraction. In this paper we propose a novel graph neural network based on the mutual information of the raw EEG channels called MutualGraphNet. We use the mutual information as the adjacency matrix combined with the spatial temporal graph convolution network(ST-GCN) could extract the transition rules of the motor imagery electroencephalogram(EEG) channels data more effectively. Experiments are conducted on motor imagery EEG data set and we compare our model with the current state-of-the-art approaches and the results suggest that MutualGraphNet is robust enough to learn the interpretable features and outperforms the current state-of-the-art methods.
A Robust Deep Learning-Based Beamforming Design for RIS-assisted Multiuser MISO Communications with Practical Constraints
Nov 12, 2021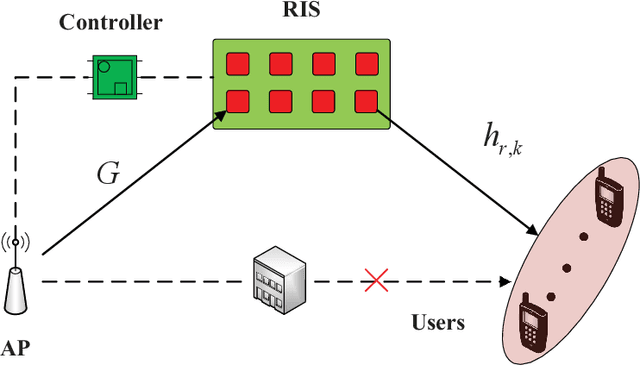
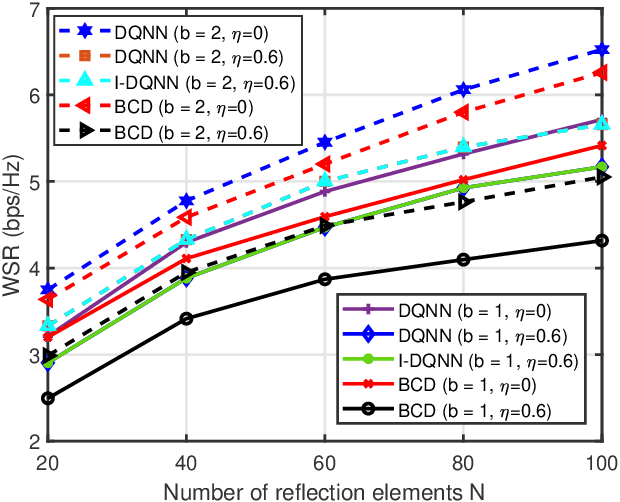
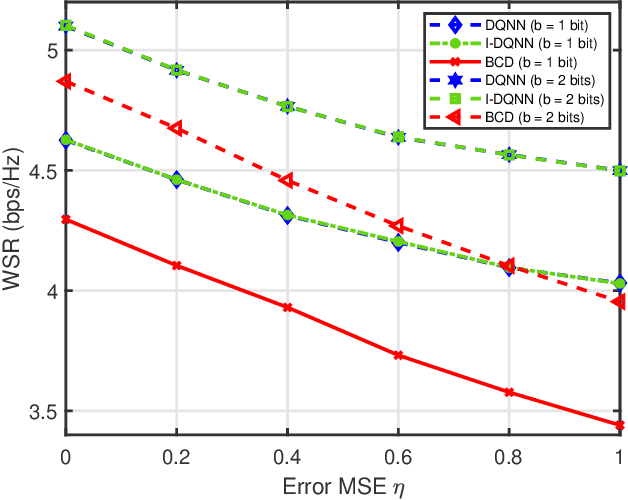
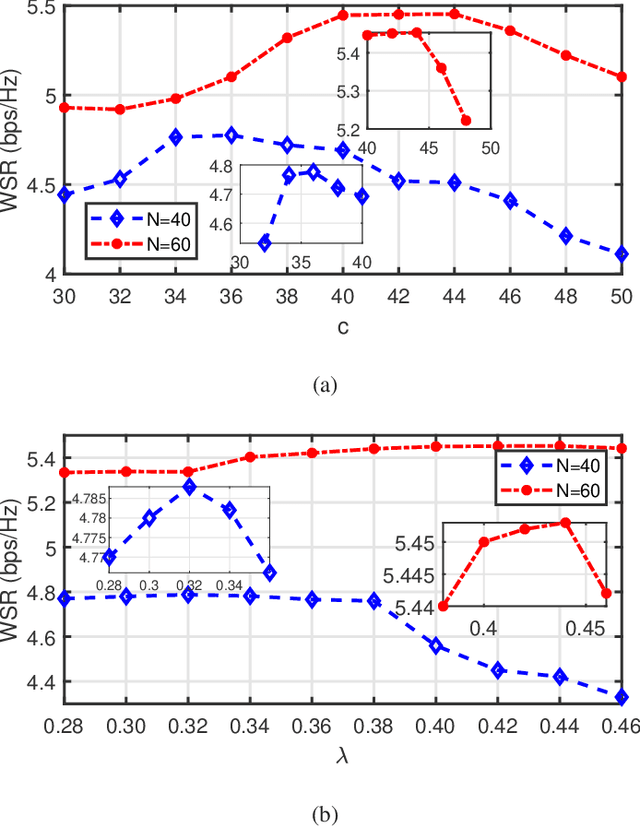
Reconfigurable intelligent surface (RIS) has become a promising technology to improve wireless communication in recent years. It steers the incident signals to create a favorable propagation environment by controlling the reconfigurable passive elements with less hardware cost and lower power consumption. In this paper, we consider a RIS-aided multiuser multiple-input single-output downlink communication system. We aim to maximize the weighted sum-rate of all users by joint optimizing the active beamforming at the access point and the passive beamforming vector of the RIS elements. Unlike most existing works, we consider the more practical situation with the discrete phase shifts and imperfect channel state information (CSI). Specifically, for the situation that the discrete phase shifts and perfect CSI are considered, we first develop a deep quantization neural network (DQNN) to simultaneously design the active and passive beamforming while most reported works design them alternatively. Then, we propose an improved structure (I-DQNN) based on DQNN to simplify the parameters decision process when the control bits of each RIS element are greater than 1 bit. Finally, we extend the two proposed DQNN-based algorithms to the case that the discrete phase shifts and imperfect CSI are considered simultaneously. Our simulation results show that the two DQNN-based algorithms have better performance than traditional algorithms in the perfect CSI case, and are also more robust in the imperfect CSI case.
An Effective Image Restorer: Denoising and Luminance Adjustment for Low-photon-count Imaging
Nov 02, 2021



Imaging under photon-scarce situations introduces challenges to many applications as the captured images are with low signal-to-noise ratio and poor luminance. In this paper, we investigate the raw image restoration under low-photon-count conditions by simulating the imaging of quanta image sensor (QIS). We develop a lightweight framework, which consists of a multi-level pyramid denoising network (MPDNet) and a luminance adjustment (LA) module to achieve separate denoising and luminance enhancement. The main component of our framework is the multi-skip attention residual block (MARB), which integrates multi-scale feature fusion and attention mechanism for better feature representation. Our MPDNet adopts the idea of Laplacian pyramid to learn the small-scale noise map and larger-scale high-frequency details at different levels, and feature extractions are conducted on the multi-scale input images to encode richer contextual information. Our LA module enhances the luminance of the denoised image by estimating its illumination, which can better avoid color distortion. Extensive experimental results have demonstrated that our image restorer can achieve superior performance on the degraded images with various photon levels by suppressing noise and recovering luminance and color effectively.
Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation
Jun 21, 2021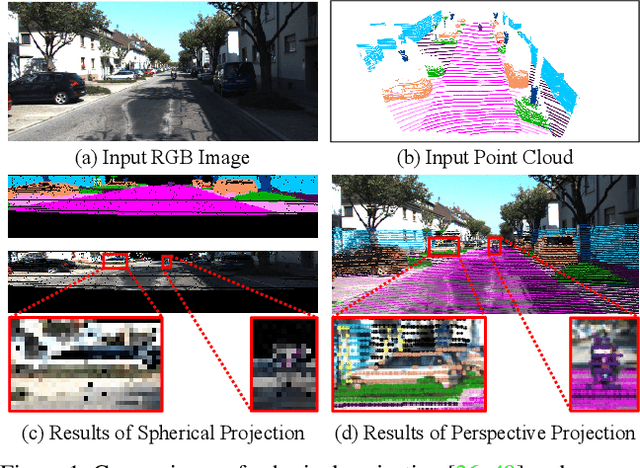
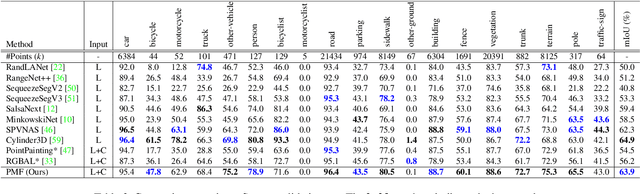
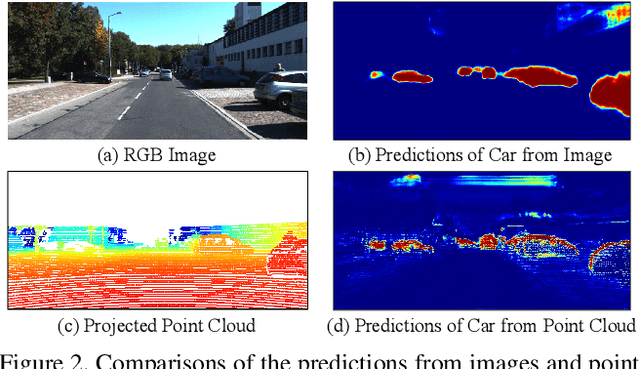
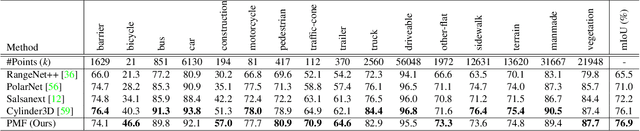
3D LiDAR (light detection and ranging) based semantic segmentation is important in scene understanding for many applications, such as auto-driving and robotics. For example, for autonomous cars equipped with RGB cameras and LiDAR, it is crucial to fuse complementary information from different sensors for robust and accurate segmentation. Existing fusion-based methods, however, may not achieve promising performance due to the vast difference between two modalities. In this work, we investigate a collaborative fusion scheme called perception-aware multi-sensor fusion (PMF) to exploit perceptual information from two modalities, namely, appearance information from RGB images and spatio-depth information from point clouds. To this end, we first project point clouds to the camera coordinates to provide spatio-depth information for RGB images. Then, we propose a two-stream network to extract features from the two modalities, separately, and fuse the features by effective residual-based fusion modules. Moreover, we propose additional perception-aware losses to measure the great perceptual difference between the two modalities. Extensive experiments on two benchmark data sets show the superiority of our method. For example, on nuScenes, our PMF outperforms the state-of-the-art method by 0.8% in mIoU.
Emoji-based Co-attention Network for Microblog Sentiment Analysis
Oct 27, 2021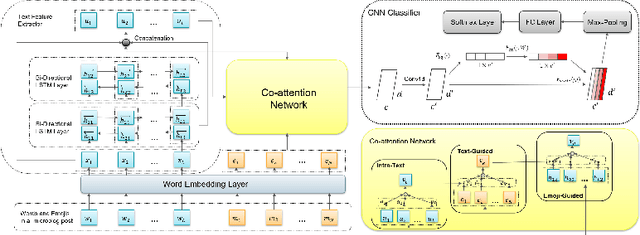
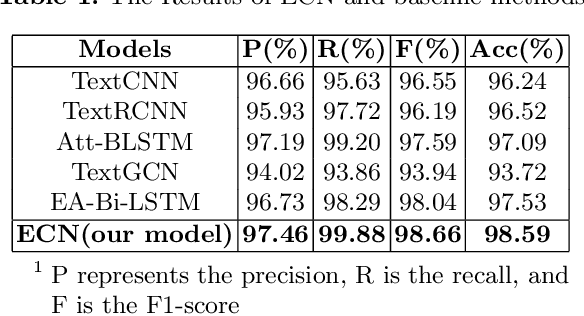
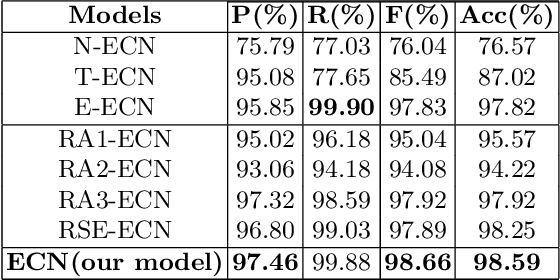
Emojis are widely used in online social networks to express emotions, attitudes, and opinions. As emotional-oriented characters, emojis can be modeled as important features of emotions towards the recipient or subject for sentiment analysis. However, existing methods mainly take emojis as heuristic information that fails to resolve the problem of ambiguity noise. Recent researches have utilized emojis as an independent input to classify text sentiment but they ignore the emotional impact of the interaction between text and emojis. It results that the emotional semantics of emojis cannot be fully explored. In this paper, we propose an emoji-based co-attention network that learns the mutual emotional semantics between text and emojis on microblogs. Our model adopts the co-attention mechanism based on bidirectional long short-term memory incorporating the text and emojis, and integrates a squeeze-and-excitation block in a convolutional neural network classifier to increase its sensitivity to emotional semantic features. Experimental results show that the proposed method can significantly outperform several baselines for sentiment analysis on short texts of social media.
Understanding Human Reading Comprehension with Brain Signals
Aug 04, 2021
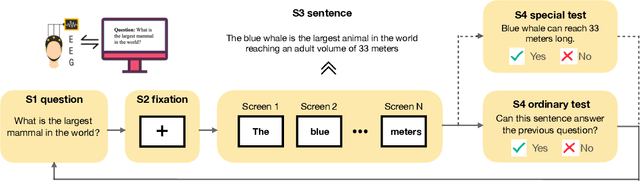
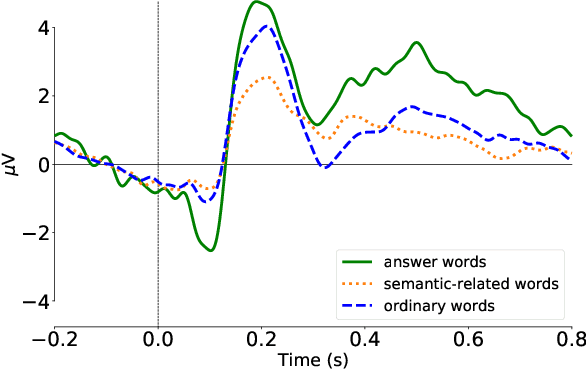

Reading comprehension is a complex cognitive process involving many human brain activities. Plenty of works have studied the reading patterns and attention allocation mechanisms in the reading process. However, little is known about what happens in human brain during reading comprehension and how we can utilize this information as implicit feedback to facilitate information acquisition performance. With the advances in brain imaging techniques such as EEG, it is possible to collect high-precision brain signals in almost real time. With neuroimaging techniques, we carefully design a lab-based user study to investigate brain activities during reading comprehension. Our findings show that neural responses vary with different types of contents, i.e., contents that can satisfy users' information needs and contents that cannot. We suggest that various cognitive activities, e.g., cognitive loading, semantic-thematic understanding, and inferential processing, at the micro-time scale during reading comprehension underpin these neural responses. Inspired by these detectable differences in cognitive activities, we construct supervised learning models based on EEG features for two reading comprehension tasks: answer sentence classification and answer extraction. Results show that it is feasible to improve their performance with brain signals. These findings imply that brain signals are valuable feedback for enhancing human-computer interactions during reading comprehension.
Safe Online Gain Optimization for Variable Impedance Control
Nov 01, 2021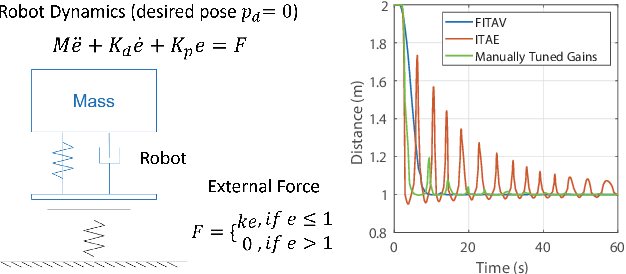
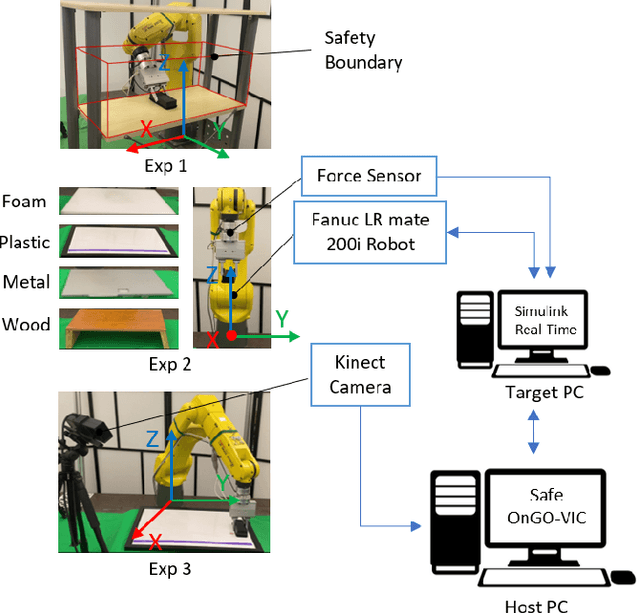
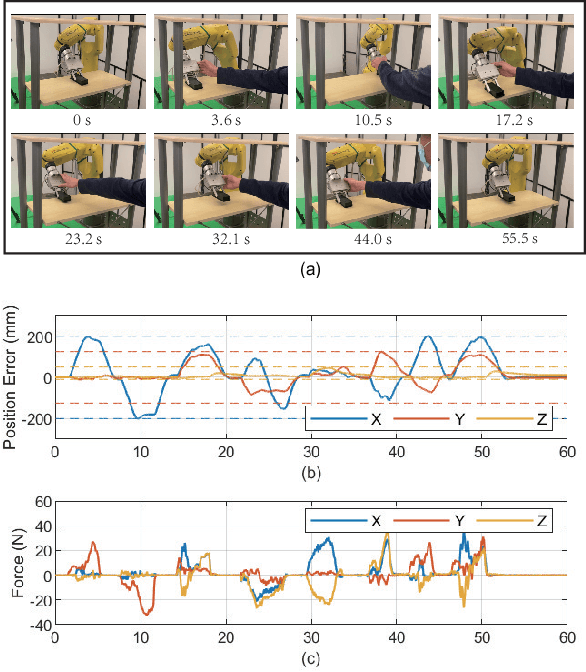
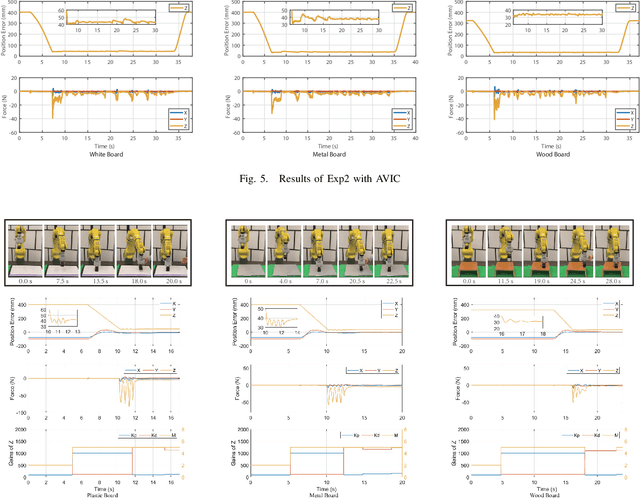
Smooth behaviors are preferable for many contact-rich manipulation tasks. Impedance control arises as an effective way to regulate robot movements by mimicking a mass-spring-damping system. Consequently, the robot behavior can be determined by the impedance gains. However, tuning the impedance gains for different tasks is tricky, especially for unstructured environments. Moreover, online adapting the optimal gains to meet the time-varying performance index is even more challenging. In this paper, we present Safe Online Gain Optimization for Variable Impedance Control (Safe OnGO-VIC). By reformulating the dynamics of impedance control as a control-affine system, in which the impedance gains are the inputs, we provide a novel perspective to understand variable impedance control. Additionally, we innovatively formulate an optimization problem with online collected force information to obtain the optimal impedance gains in real-time. Safety constraints are also embedded in the proposed framework to avoid unwanted collisions. We experimentally validated the proposed algorithm on three manipulation tasks. Comparison results with a constant gain baseline and an adaptive control method prove that the proposed algorithm is effective and generalizable to different scenarios.