 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Not Color Blind: AI Predicts Racial Identity from Black and White Retinal Vessel Segmentations
Sep 28, 2021
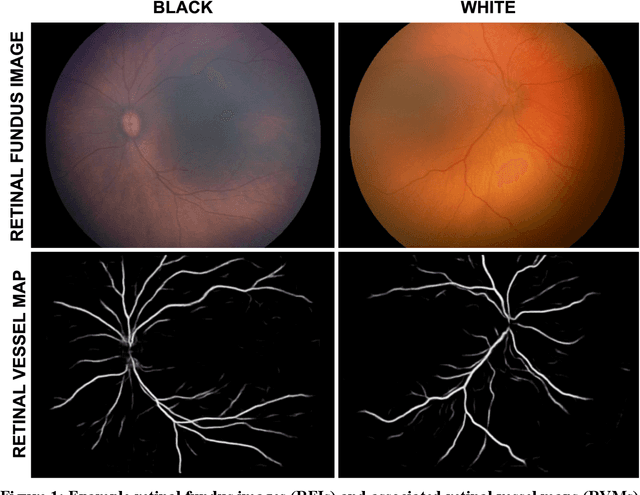
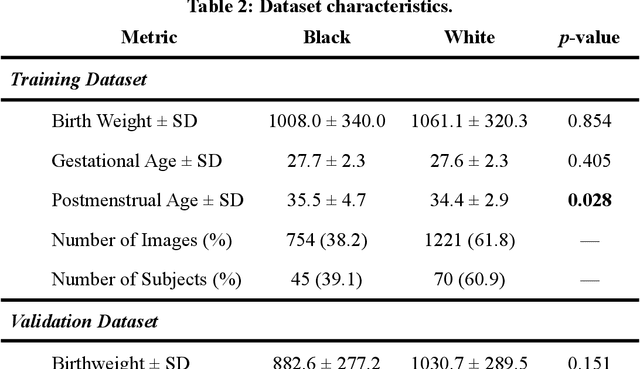
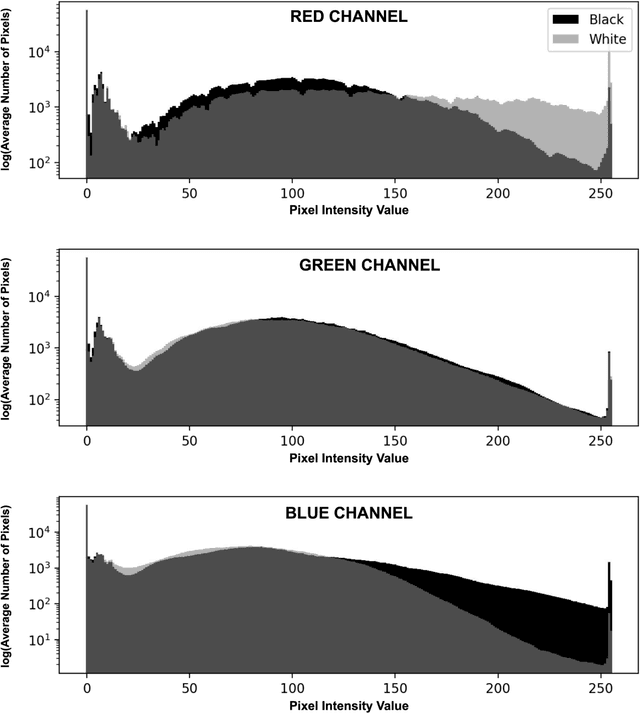
Background: Artificial intelligence (AI) may demonstrate racial bias when skin or choroidal pigmentation is present in medical images. Recent studies have shown that convolutional neural networks (CNNs) can predict race from images that were not previously thought to contain race-specific features. We evaluate whether grayscale retinal vessel maps (RVMs) of patients screened for retinopathy of prematurity (ROP) contain race-specific features. Methods: 4095 retinal fundus images (RFIs) were collected from 245 Black and White infants. A U-Net generated RVMs from RFIs, which were subsequently thresholded, binarized, or skeletonized. To determine whether RVM differences between Black and White eyes were physiological, CNNs were trained to predict race from color RFIs, raw RVMs, and thresholded, binarized, or skeletonized RVMs. Area under the precision-recall curve (AUC-PR) was evaluated. Findings: CNNs predicted race from RFIs near perfectly (image-level AUC-PR: 0.999, subject-level AUC-PR: 1.000). Raw RVMs were almost as informative as color RFIs (image-level AUC-PR: 0.938, subject-level AUC-PR: 0.995). Ultimately, CNNs were able to detect whether RFIs or RVMs were from Black or White babies, regardless of whether images contained color, vessel segmentation brightness differences were nullified, or vessel segmentation widths were normalized. Interpretation: AI can detect race from grayscale RVMs that were not thought to contain racial information. Two potential explanations for these findings are that: retinal vessels physiologically differ between Black and White babies or the U-Net segments the retinal vasculature differently for various fundus pigmentations. Either way, the implications remain the same: AI algorithms have potential to demonstrate racial bias in practice, even when preliminary attempts to remove such information from the underlying images appear to be successful.
Multimodal Breast Lesion Classification Using Cross-Attention Deep Networks
Aug 21, 2021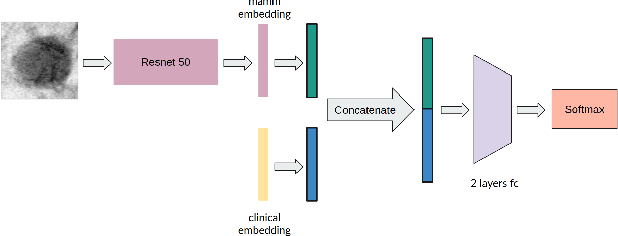
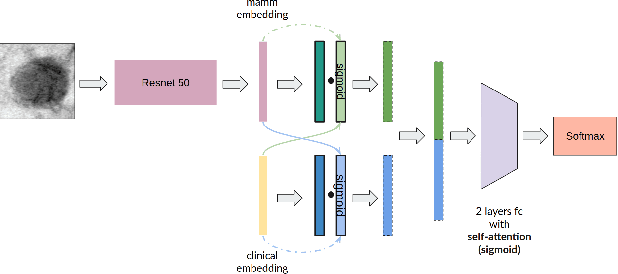
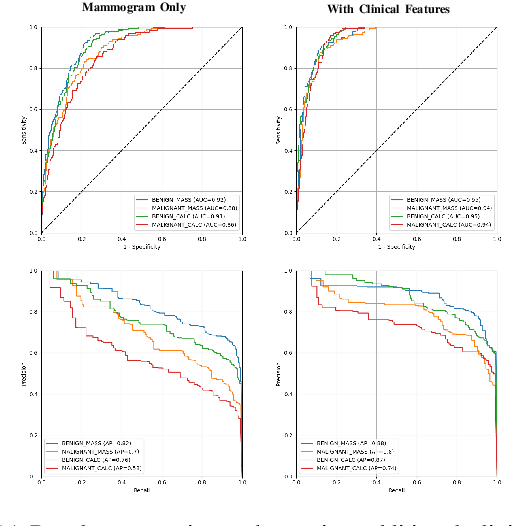

Accurate breast lesion risk estimation can significantly reduce unnecessary biopsies and help doctors decide optimal treatment plans. Most existing computer-aided systems rely solely on mammogram features to classify breast lesions. While this approach is convenient, it does not fully exploit useful information in clinical reports to achieve the optimal performance. Would clinical features significantly improve breast lesion classification compared to using mammograms alone? How to handle missing clinical information caused by variation in medical practice? What is the best way to combine mammograms and clinical features? There is a compelling need for a systematic study to address these fundamental questions. This paper investigates several multimodal deep networks based on feature concatenation, cross-attention, and co-attention to combine mammograms and categorical clinical variables. We show that the proposed architectures significantly increase the lesion classification performance (average area under ROC curves from 0.89 to 0.94). We also evaluate the model when clinical variables are missing.
Time in a Box: Advancing Knowledge Graph Completion with Temporal Scopes
Nov 12, 2021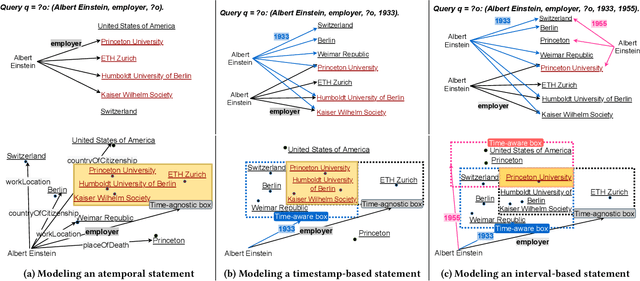
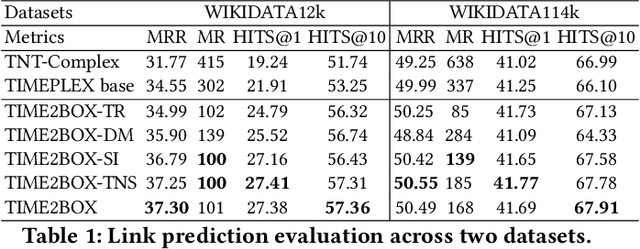
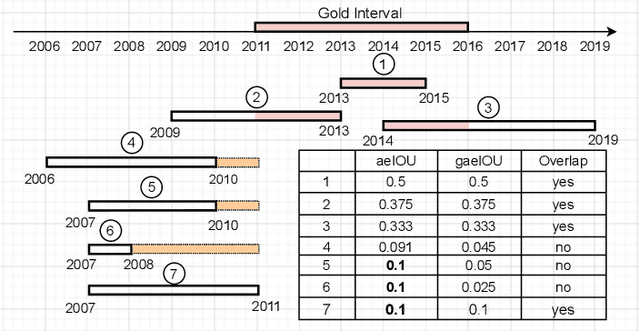
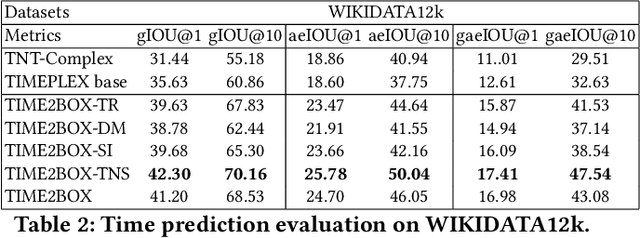
Almost all statements in knowledge bases have a temporal scope during which they are valid. Hence, knowledge base completion (KBC) on temporal knowledge bases (TKB), where each statement \textit{may} be associated with a temporal scope, has attracted growing attention. Prior works assume that each statement in a TKB \textit{must} be associated with a temporal scope. This ignores the fact that the scoping information is commonly missing in a KB. Thus prior work is typically incapable of handling generic use cases where a TKB is composed of temporal statements with/without a known temporal scope. In order to address this issue, we establish a new knowledge base embedding framework, called TIME2BOX, that can deal with atemporal and temporal statements of different types simultaneously. Our main insight is that answers to a temporal query always belong to a subset of answers to a time-agnostic counterpart. Put differently, time is a filter that helps pick out answers to be correct during certain periods. We introduce boxes to represent a set of answer entities to a time-agnostic query. The filtering functionality of time is modeled by intersections over these boxes. In addition, we generalize current evaluation protocols on time interval prediction. We describe experiments on two datasets and show that the proposed method outperforms state-of-the-art (SOTA) methods on both link prediction and time prediction.
Meta-Learning the Search Distribution of Black-Box Random Search Based Adversarial Attacks
Nov 02, 2021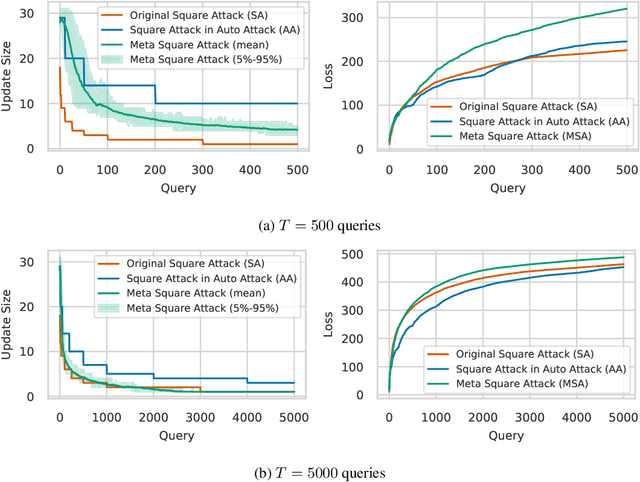
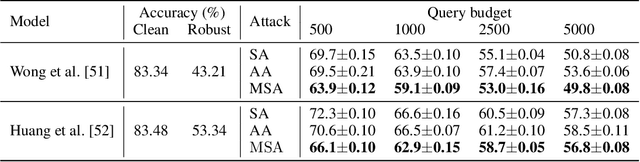

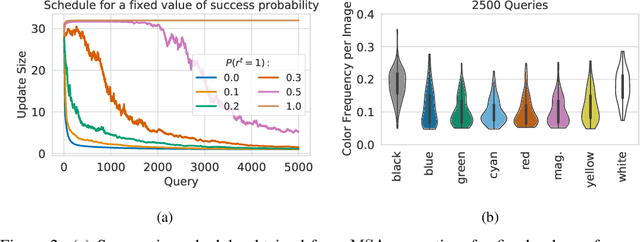
Adversarial attacks based on randomized search schemes have obtained state-of-the-art results in black-box robustness evaluation recently. However, as we demonstrate in this work, their efficiency in different query budget regimes depends on manual design and heuristic tuning of the underlying proposal distributions. We study how this issue can be addressed by adapting the proposal distribution online based on the information obtained during the attack. We consider Square Attack, which is a state-of-the-art score-based black-box attack, and demonstrate how its performance can be improved by a learned controller that adjusts the parameters of the proposal distribution online during the attack. We train the controller using gradient-based end-to-end training on a CIFAR10 model with white box access. We demonstrate that plugging the learned controller into the attack consistently improves its black-box robustness estimate in different query regimes by up to 20% for a wide range of different models with black-box access. We further show that the learned adaptation principle transfers well to the other data distributions such as CIFAR100 or ImageNet and to the targeted attack setting.
Multi-input Architecture and Disentangled Representation Learning for Multi-dimensional Modeling of Music Similarity
Nov 02, 2021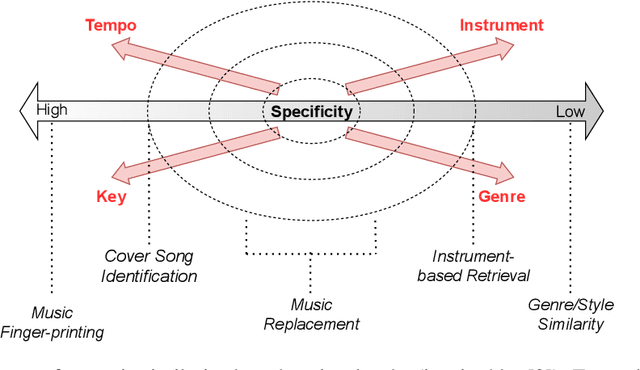
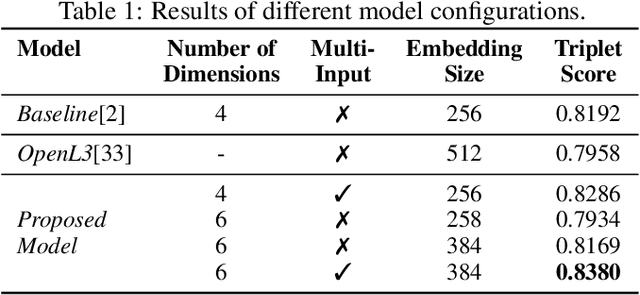
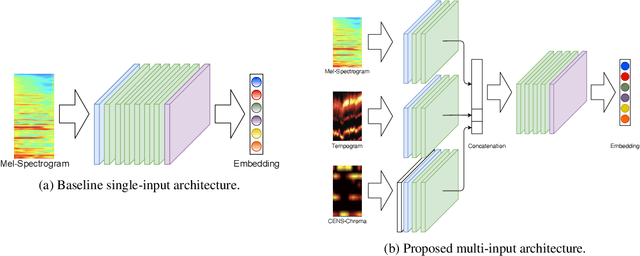
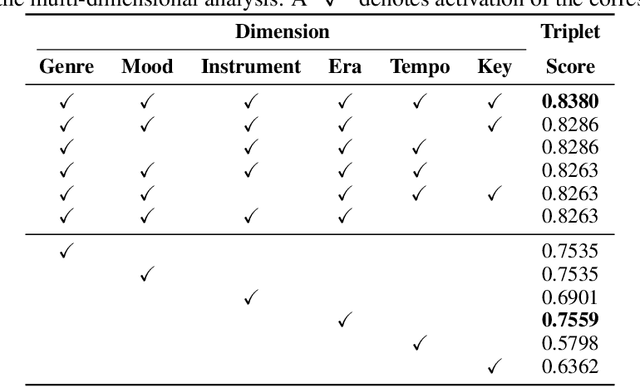
In the context of music information retrieval, similarity-based approaches are useful for a variety of tasks that benefit from a query-by-example scenario. Music however, naturally decomposes into a set of semantically meaningful factors of variation. Current representation learning strategies pursue the disentanglement of such factors from deep representations, resulting in highly interpretable models. This allows the modeling of music similarity perception, which is highly subjective and multi-dimensional. While the focus of prior work is on metadata driven notions of similarity, we suggest to directly model the human notion of multi-dimensional music similarity. To achieve this, we propose a multi-input deep neural network architecture, which simultaneously processes mel-spectrogram, CENS-chromagram and tempogram in order to extract informative features for the different disentangled musical dimensions: genre, mood, instrument, era, tempo, and key. We evaluated the proposed music similarity approach using a triplet prediction task and found that the proposed multi-input architecture outperforms a state of the art method. Furthermore, we present a novel multi-dimensional analysis in order to evaluate the influence of each disentangled dimension on the perception of music similarity.
Minimax Optimal Quantile and Semi-Adversarial Regret via Root-Logarithmic Regularizers
Oct 27, 2021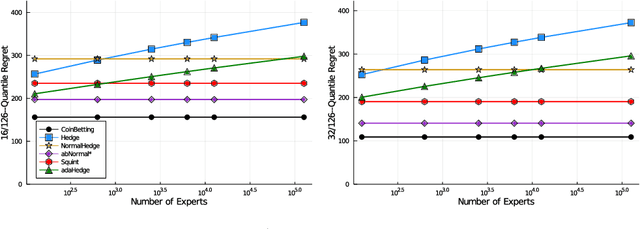
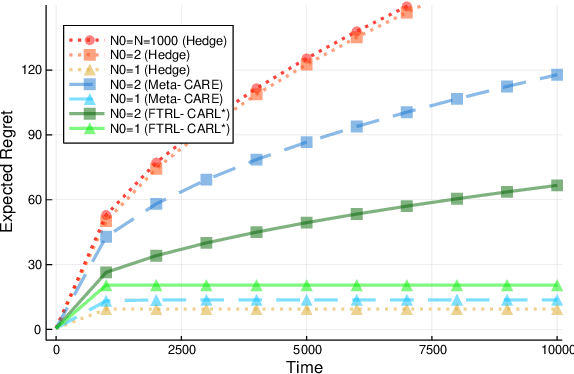
Quantile (and, more generally, KL) regret bounds, such as those achieved by NormalHedge (Chaudhuri, Freund, and Hsu 2009) and its variants, relax the goal of competing against the best individual expert to only competing against a majority of experts on adversarial data. More recently, the semi-adversarial paradigm (Bilodeau, Negrea, and Roy 2020) provides an alternative relaxation of adversarial online learning by considering data that may be neither fully adversarial nor stochastic (i.i.d.). We achieve the minimax optimal regret in both paradigms using FTRL with separate, novel, root-logarithmic regularizers, both of which can be interpreted as yielding variants of NormalHedge. We extend existing KL regret upper bounds, which hold uniformly over target distributions, to possibly uncountable expert classes with arbitrary priors; provide the first full-information lower bounds for quantile regret on finite expert classes (which are tight); and provide an adaptively minimax optimal algorithm for the semi-adversarial paradigm that adapts to the true, unknown constraint faster, leading to uniformly improved regret bounds over existing methods.
* 30 pages, 2 figures. Jeffrey Negrea and Blair Bilodeau are equal-contribution authors
WhyAct: Identifying Action Reasons in Lifestyle Vlogs
Sep 09, 2021
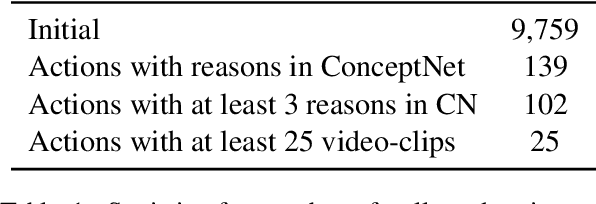

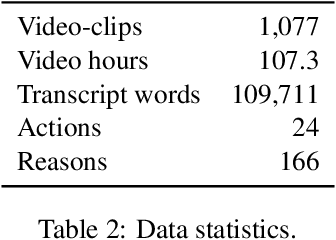
We aim to automatically identify human action reasons in online videos. We focus on the widespread genre of lifestyle vlogs, in which people perform actions while verbally describing them. We introduce and make publicly available the WhyAct dataset, consisting of 1,077 visual actions manually annotated with their reasons. We describe a multimodal model that leverages visual and textual information to automatically infer the reasons corresponding to an action presented in the video.
The Neural Data Router: Adaptive Control Flow in Transformers Improves Systematic Generalization
Oct 14, 2021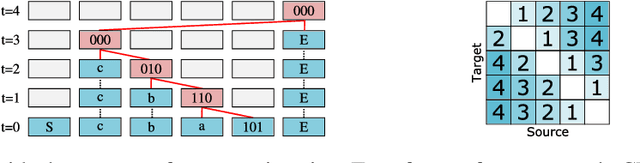
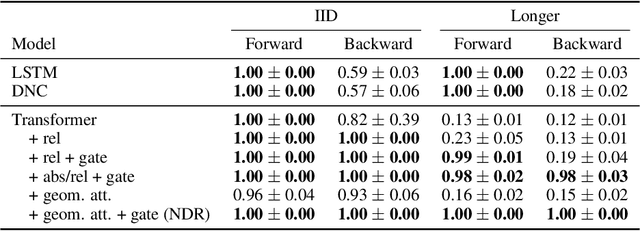

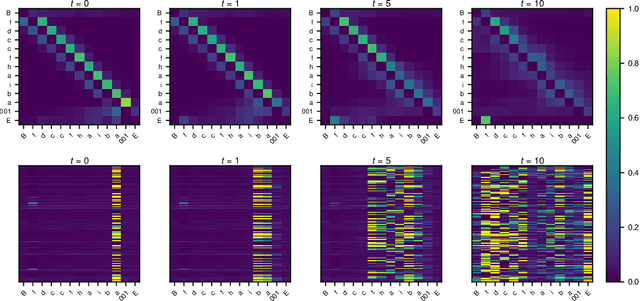
Despite successes across a broad range of applications, Transformers have limited success in systematic generalization. The situation is especially frustrating in the case of algorithmic tasks, where they often fail to find intuitive solutions that route relevant information to the right node/operation at the right time in the grid represented by Transformer columns. To facilitate the learning of useful control flow, we propose two modifications to the Transformer architecture, copy gate and geometric attention. Our novel Neural Data Router (NDR) achieves 100% length generalization accuracy on the classic compositional table lookup task, as well as near-perfect accuracy on the simple arithmetic task and a new variant of ListOps testing for generalization across computational depth. NDR's attention and gating patterns tend to be interpretable as an intuitive form of neural routing. Our code is public.
Description-based Label Attention Classifier for Explainable ICD-9 Classification
Sep 24, 2021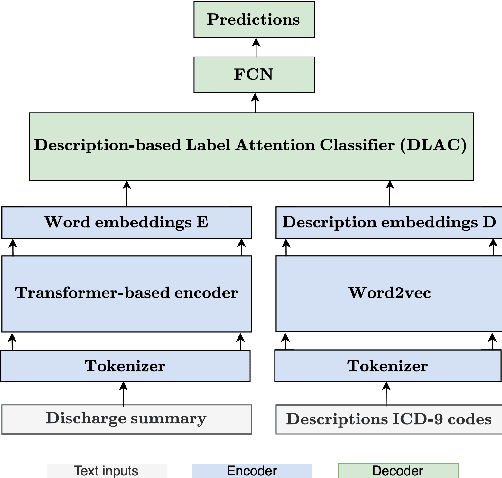
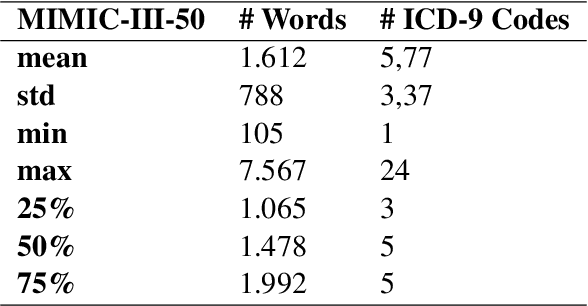
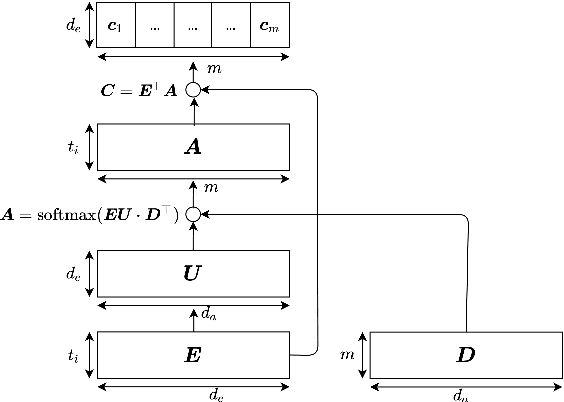
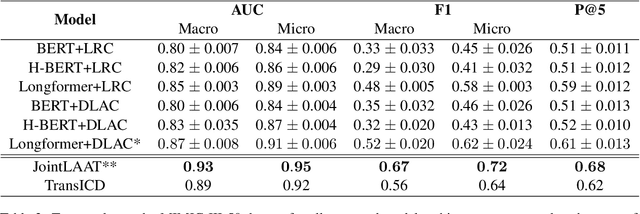
ICD-9 coding is a relevant clinical billing task, where unstructured texts with information about a patient's diagnosis and treatments are annotated with multiple ICD-9 codes. Automated ICD-9 coding is an active research field, where CNN- and RNN-based model architectures represent the state-of-the-art approaches. In this work, we propose a description-based label attention classifier to improve the model explainability when dealing with noisy texts like clinical notes. We evaluate our proposed method with different transformer-based encoders on the MIMIC-III-50 dataset. Our method achieves strong results together with augmented explainablilty.
A Case Study to Reveal if an Area of Interest has a Trend in Ongoing Tweets Using Word and Sentence Embeddings
Oct 02, 2021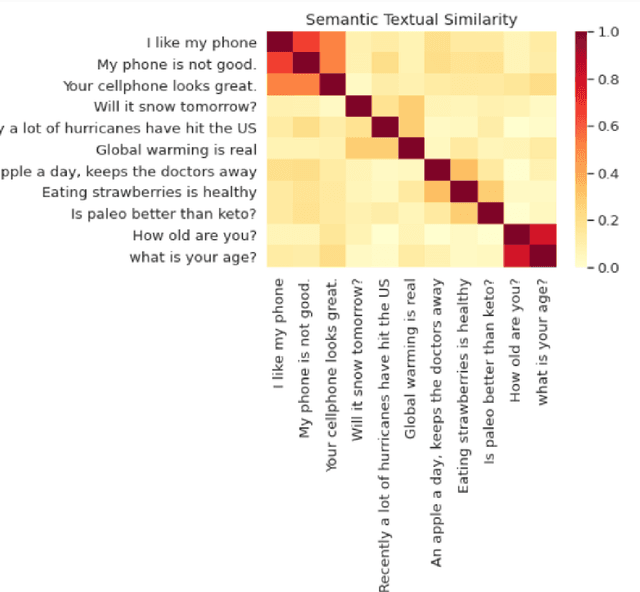
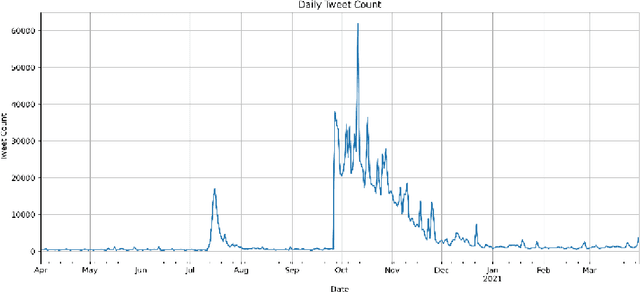
In the field of Natural Language Processing, information extraction from texts has been the objective of many researchers for years. Many different techniques have been applied in order to reveal the opinion that a tweet might have, thus understanding the sentiment of the small writing up to 280 characters. Other than figuring out the sentiment of a tweet, a study can also focus on finding the correlation of the tweets with a certain area of interest, which constitutes the purpose of this study. In order to reveal if an area of interest has a trend in ongoing tweets, we have proposed an easily applicable automated methodology in which the Daily Mean Similarity Scores that show the similarity between the daily tweet corpus and the target words representing our area of interest is calculated by using a na\"ive correlation-based technique without training any Machine Learning Model. The Daily Mean Similarity Scores have mainly based on cosine similarity and word/sentence embeddings computed by Multilanguage Universal Sentence Encoder and showed main opinion stream of the tweets with respect to a certain area of interest, which proves that an ongoing trend of a specific subject on Twitter can easily be captured in almost real time by using the proposed methodology in this study. We have also compared the effectiveness of using word versus sentence embeddings while applying our methodology and realized that both give almost the same results, whereas using word embeddings requires less computational time than sentence embeddings, thus being more effective. This paper will start with an introduction followed by the background information about the basics, then continue with the explanation of the proposed methodology and later on finish by interpreting the results and concluding the findings.