 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Logic of Expertise
Jul 22, 2021
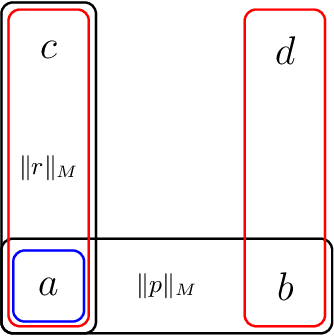
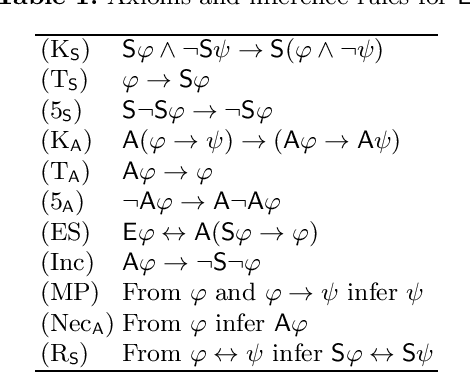
In this paper we introduce a simple modal logic framework to reason about the expertise of an information source. In the framework, a source is an expert on a proposition $p$ if they are able to correctly determine the truth value of $p$ in any possible world. We also consider how information may be false, but true after accounting for the lack of expertise of the source. This is relevant for modelling situations in which information sources make claims beyond their domain of expertise. We use non-standard semantics for the language based on an expertise set with certain closure properties. It turns out there is a close connection between our semantics and S5 epistemic logic, so that expertise can be expressed in terms of knowledge at all possible states. We use this connection to obtain a sound and complete axiomatisation.
G-image Segmentation: Similarity-preserving Fuzzy C-Means with Spatial Information Constraint in Wavelet Space
Jun 20, 2020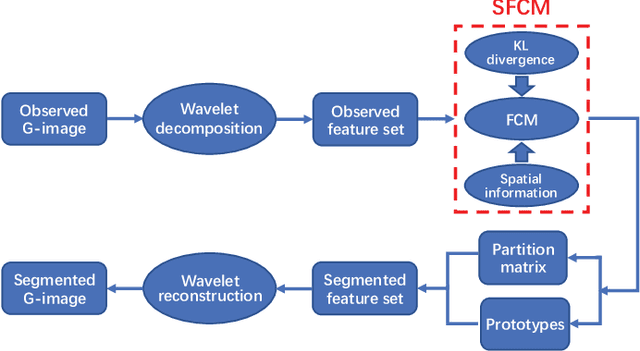
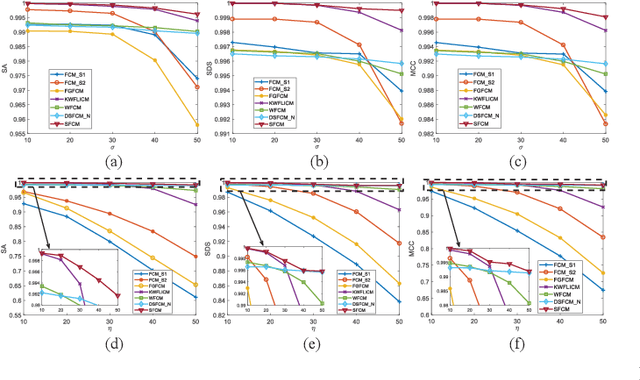
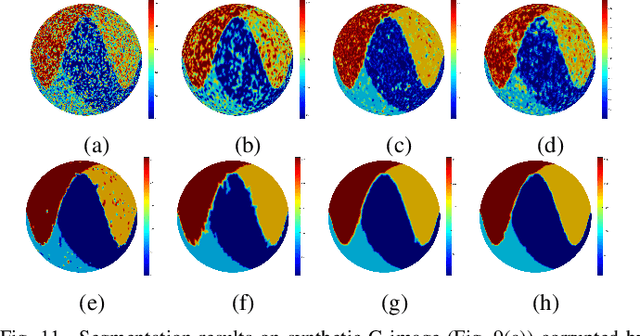
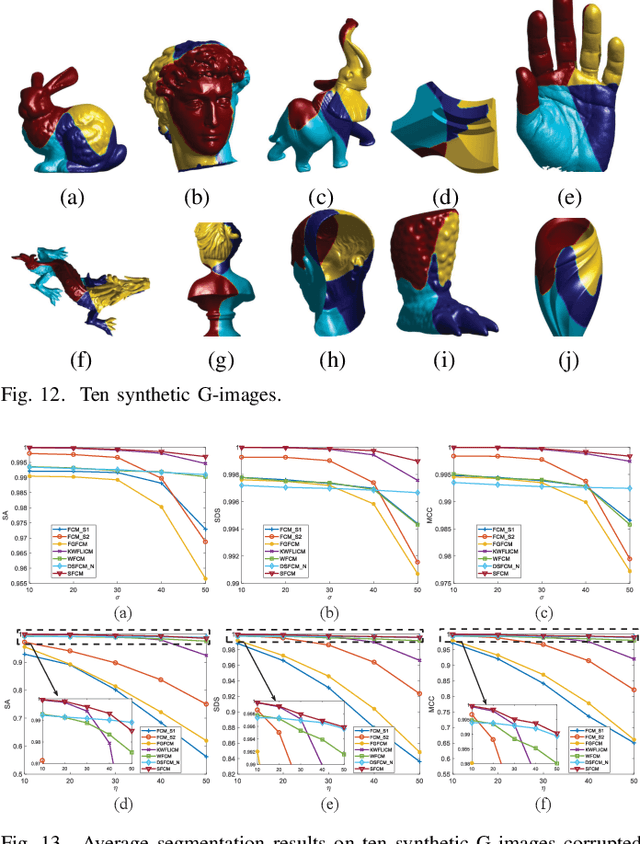
G-images refer to image data defined on irregular graph domains. This work elaborates a similarity-preserving Fuzzy C-Means (FCM) algorithm for G-image segmentation and aims to develop techniques and tools for segmenting G-images. To preserve the membership similarity between an arbitrary image pixel and its neighbors, a Kullback-Leibler divergence term on membership partition is introduced as a part of FCM. As a result, similarity-preserving FCM is developed by considering spatial information of image pixels for its robustness enhancement. Due to superior characteristics of a wavelet space, the proposed FCM is performed in this space rather than Euclidean one used in conventional FCM to secure its high robustness. Experiments on synthetic and real-world G-images demonstrate that it indeed achieves higher robustness and performance than the state-of-the-art FCM algorithms. Moreover, it requires less computation than most of them.
Multi-target Joint Tracking and Classification Using the Trajectory PHD Filter
Nov 06, 2021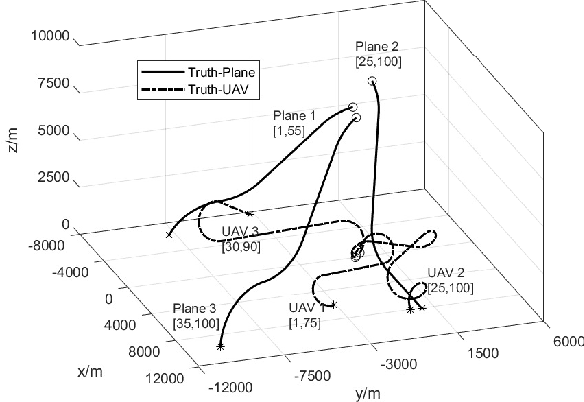
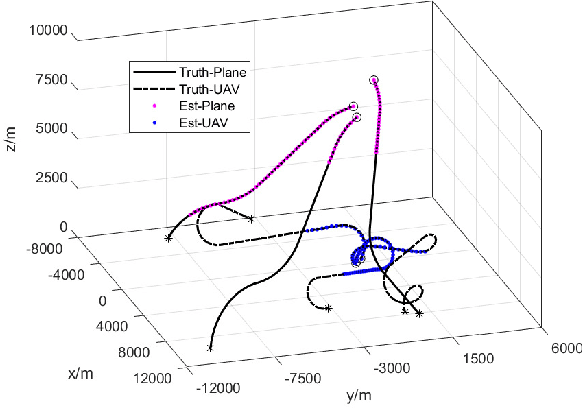
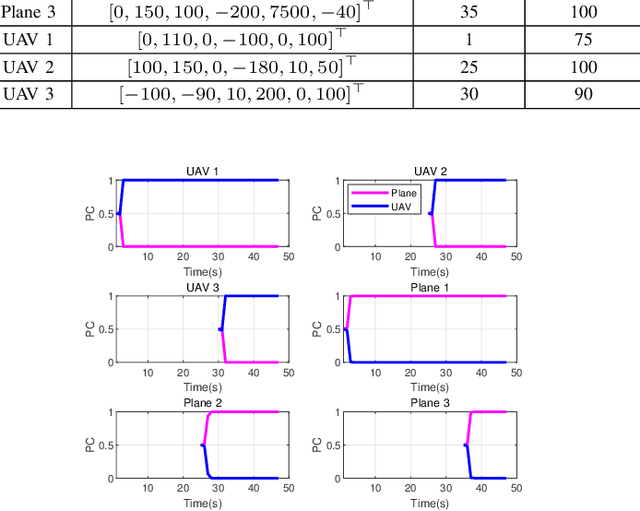
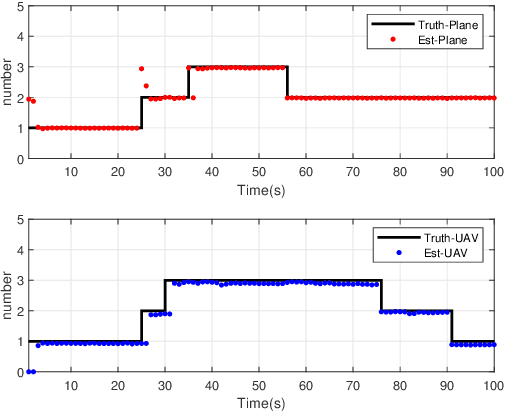
To account for joint tracking and classification (JTC) of multiple targets from observation sets in presence of detection uncertainty, noise and clutter, this paper develops a new trajectory probability hypothesis density (TPHD) filter, which is referred to as the JTC-TPHD filter. The JTC-TPHD filter classifies different targets based on their motion models and each target is assigned with multiple class hypotheses. By using this strategy, we can not only obtain the category information of the targets, but also a more accurate trajectory estimation than the traditional TPHD filter. The JTC-TPHD filter is derived by finding the best Poisson posterior approximation over trajectories on an augmented state space using the Kullback-Leibler divergence (KLD) minimization. The Gaussian mixture is adopted for the implementation, which is referred to as the GM-JTC-TPHD filter. The L-scan approximation is also presented for the GM-JTC-TPHD filter, which possesses lower computational burden. Simulation results show that the GM-JTC-TPHD filter can classify targets correctly and obtain accurate trajectory estimation.
Pitch-Informed Instrument Assignment Using a Deep Convolutional Network with Multiple Kernel Shapes
Jul 28, 2021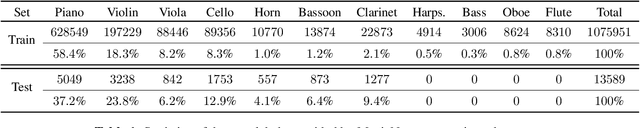
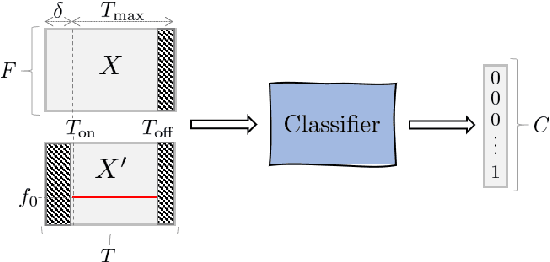
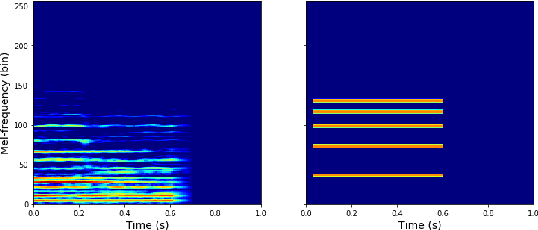
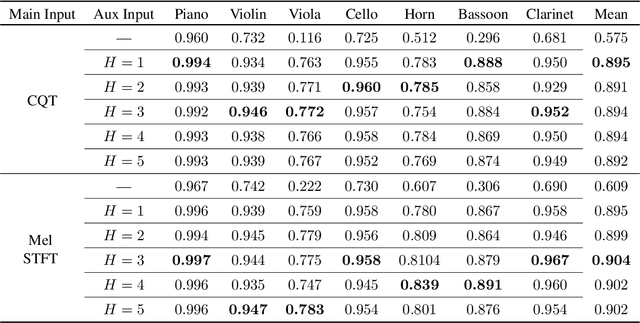
This paper proposes a deep convolutional neural network for performing note-level instrument assignment. Given a polyphonic multi-instrumental music signal along with its ground truth or predicted notes, the objective is to assign an instrumental source for each note. This problem is addressed as a pitch-informed classification task where each note is analysed individually. We also propose to utilise several kernel shapes in the convolutional layers in order to facilitate learning of efficient timbre-discriminative feature maps. Experiments on the MusicNet dataset using 7 instrument classes show that our approach is able to achieve an average F-score of 0.904 when the original multi-pitch annotations are used as the pitch information for the system, and that it also excels if the note information is provided using third-party multi-pitch estimation algorithms. We also include ablation studies investigating the effects of the use of multiple kernel shapes and comparing different input representations for the audio and the note-related information.
Fight Detection from Still Images in the Wild
Nov 17, 2021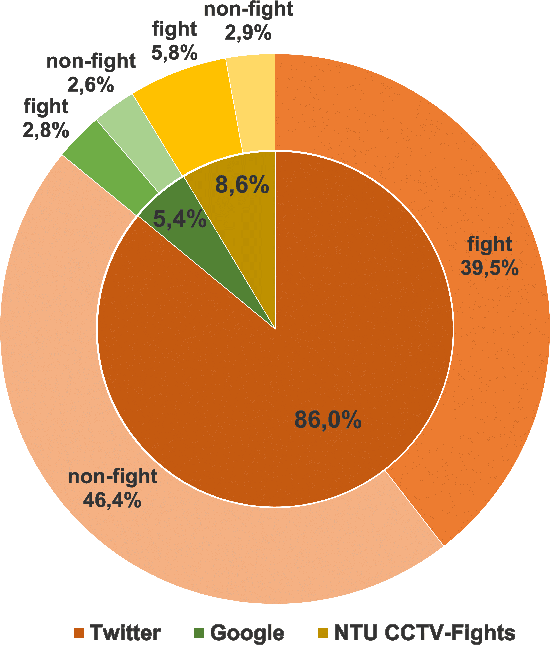
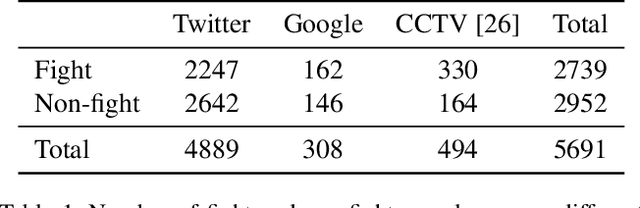
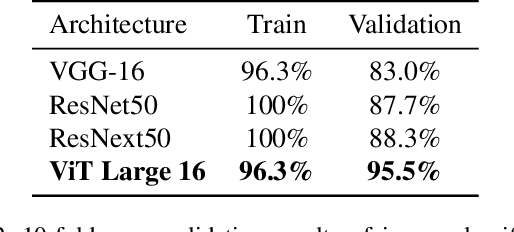

Detecting fights from still images shared on social media is an important task required to limit the distribution of violent scenes in order to prevent their negative effects. For this reason, in this study, we address the problem of fight detection from still images collected from the web and social media. We explore how well one can detect fights from just a single still image. We also propose a new dataset, named Social Media Fight Images (SMFI), comprising real-world images of fight actions. Results of the extensive experiments on the proposed dataset show that fight actions can be recognized successfully from still images. That is, even without exploiting the temporal information, it is possible to detect fights with high accuracy by utilizing appearance only. We also perform cross-dataset experiments to evaluate the representation capacity of the collected dataset. These experiments indicate that, as in the other computer vision problems, there exists a dataset bias for the fight recognition problem. Although the methods achieve close to 100% accuracy when trained and tested on the same fight dataset, the cross-dataset accuracies are significantly lower, i.e., around 70% when more representative datasets are used for training. SMFI dataset is found to be one of the two most representative datasets among the utilized five fight datasets.
Reconstruction-Computation-Quantization (RCQ): A Paradigm for Low Bit Width LDPC Decoding
Nov 17, 2021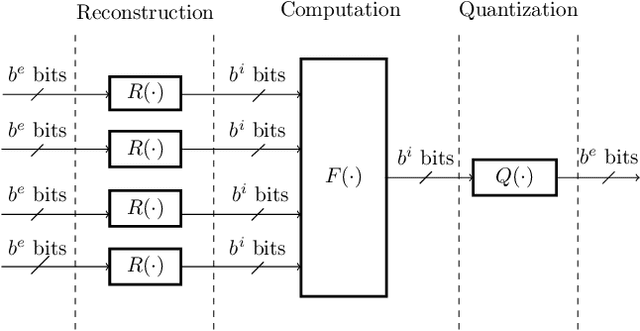
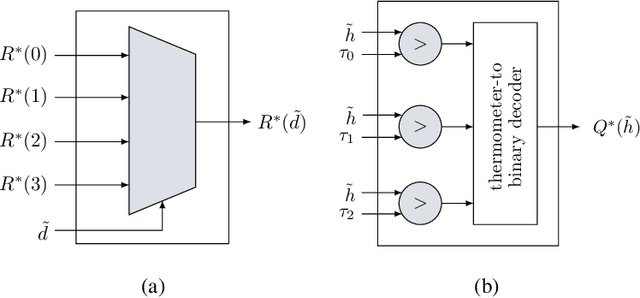
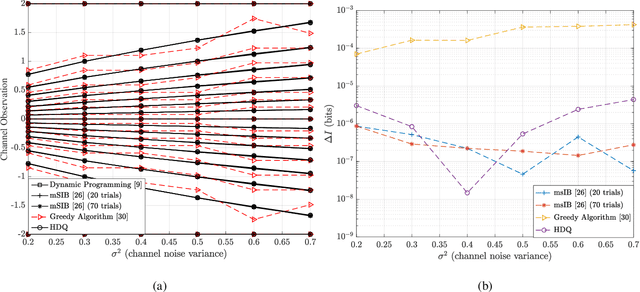
This paper uses the reconstruction-computation-quantization (RCQ) paradigm to decode low-density parity-check (LDPC) codes. RCQ facilitates dynamic non-uniform quantization to achieve good frame error rate (FER) performance with very low message precision. For message-passing according to a flooding schedule, the RCQ parameters are designed by discrete density evolution (DDE). Simulation results on an IEEE 802.11 LDPC code show that for 4-bit messages, a flooding MinSum RCQ decoder outperforms table-lookup approaches such as information bottleneck (IB) or Min-IB decoding, with significantly fewer parameters to be stored. Additionally, this paper introduces layer-specific RCQ (LS-RCQ), an extension of RCQ decoding for layered architectures. LS-RCQ uses layer-specific message representations to achieve the best possible FER performance. For LS-RCQ, this paper proposes using layered DDE featuring hierarchical dynamic quantization (HDQ) to design LS-RCQ parameters efficiently. Finally, this paper studies field-programmable gate array (FPGA) implementations of RCQ decoders. Simulation results for a (9472, 8192) quasi-cyclic (QC) LDPC code show that a layered MinSum RCQ decoder with 3-bit messages achieves more than a $10\%$ reduction in LUTs and routed nets and more than a $6\%$ decrease in register usage while maintaining comparable decoding performance, compared to a 5-bit offset MinSum decoder.
Trustworthy Medical Segmentation with Uncertainty Estimation
Nov 30, 2021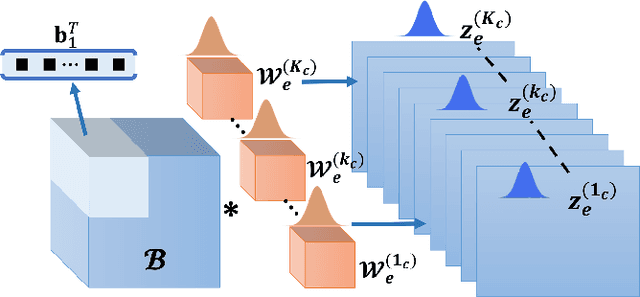
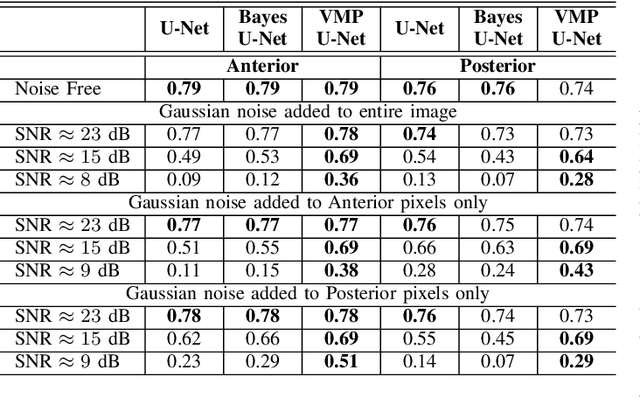
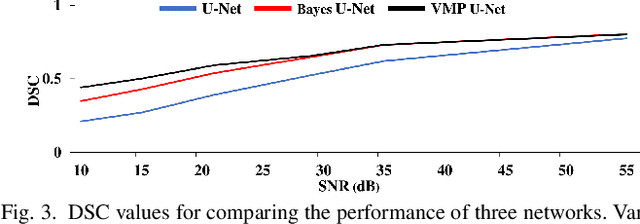

Deep Learning (DL) holds great promise in reshaping the healthcare systems given its precision, efficiency, and objectivity. However, the brittleness of DL models to noisy and out-of-distribution inputs is ailing their deployment in the clinic. Most systems produce point estimates without further information about model uncertainty or confidence. This paper introduces a new Bayesian deep learning framework for uncertainty quantification in segmentation neural networks, specifically encoder-decoder architectures. The proposed framework uses the first-order Taylor series approximation to propagate and learn the first two moments (mean and covariance) of the distribution of the model parameters given the training data by maximizing the evidence lower bound. The output consists of two maps: the segmented image and the uncertainty map of the segmentation. The uncertainty in the segmentation decisions is captured by the covariance matrix of the predictive distribution. We evaluate the proposed framework on medical image segmentation data from Magnetic Resonances Imaging and Computed Tomography scans. Our experiments on multiple benchmark datasets demonstrate that the proposed framework is more robust to noise and adversarial attacks as compared to state-of-the-art segmentation models. Moreover, the uncertainty map of the proposed framework associates low confidence (or equivalently high uncertainty) to patches in the test input images that are corrupted with noise, artifacts or adversarial attacks. Thus, the model can self-assess its segmentation decisions when it makes an erroneous prediction or misses part of the segmentation structures, e.g., tumor, by presenting higher values in the uncertainty map.
Conical Classification For Computationally Efficient One-Class Topic Determination
Oct 31, 2021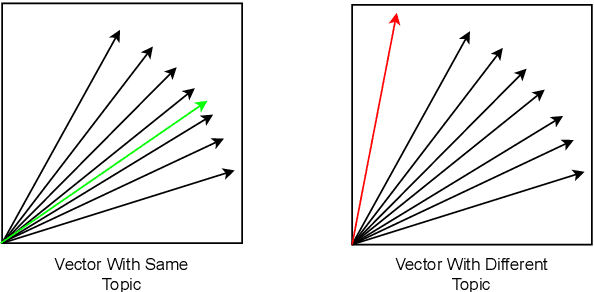
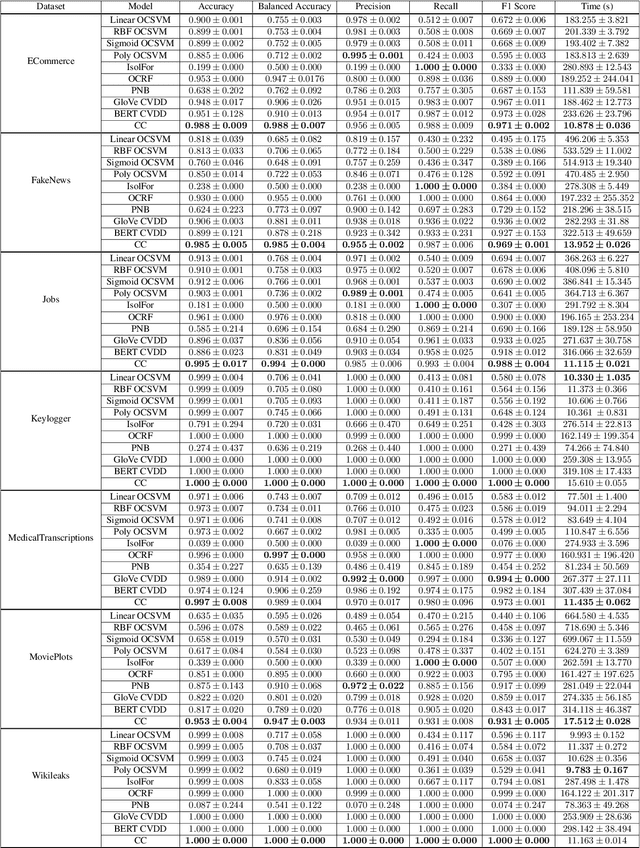
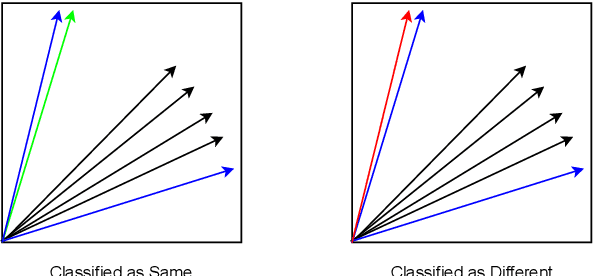
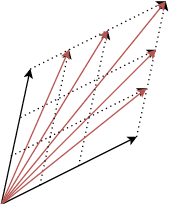
As the Internet grows in size, so does the amount of text based information that exists. For many application spaces it is paramount to isolate and identify texts that relate to a particular topic. While one-class classification would be ideal for such analysis, there is a relative lack of research regarding efficient approaches with high predictive power. By noting that the range of documents we wish to identify can be represented as positive linear combinations of the Vector Space Model representing our text, we propose Conical classification, an approach that allows us to identify if a document is of a particular topic in a computationally efficient manner. We also propose Normal Exclusion, a modified version of Bi-Normal Separation that makes it more suitable within the one-class classification context. We show in our analysis that our approach not only has higher predictive power on our datasets, but is also faster to compute.
Random Graph-Based Neuromorphic Learning with a Layer-Weaken Structure
Nov 17, 2021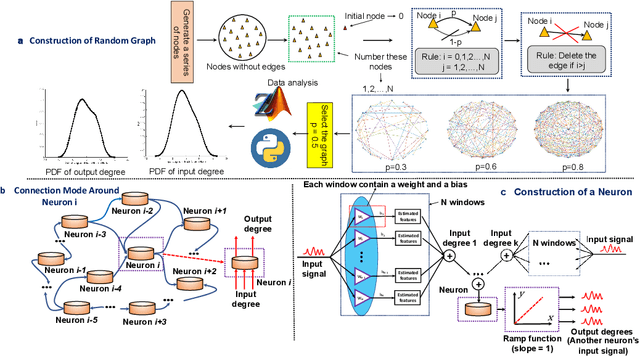
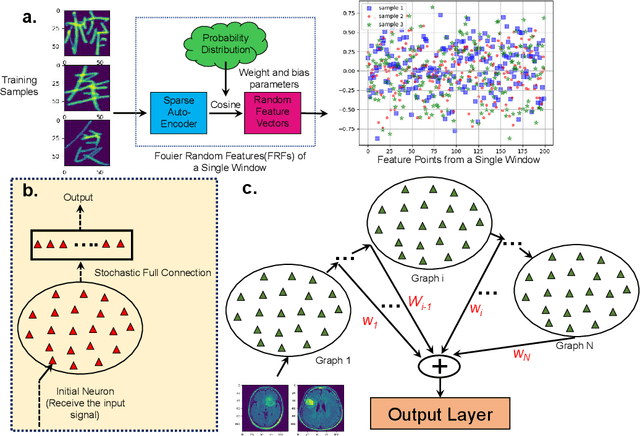
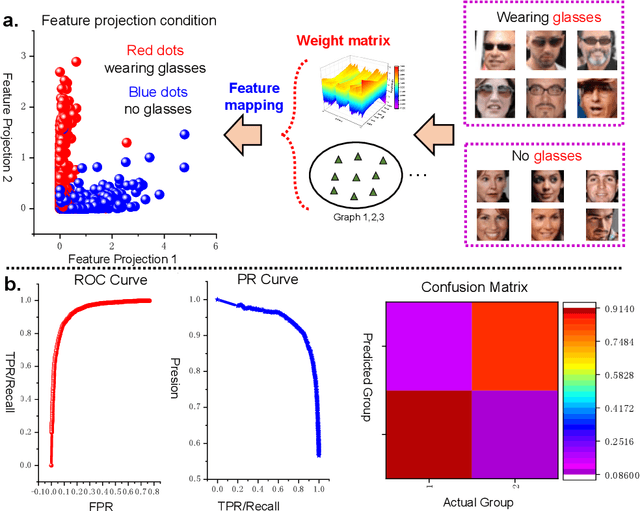
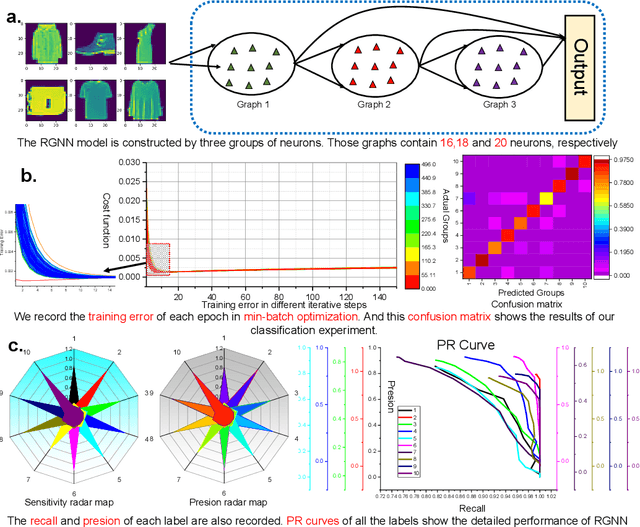
Unified understanding of neuro networks (NNs) gets the users into great trouble because they have been puzzled by what kind of rules should be obeyed to optimize the internal structure of NNs. Considering the potential capability of random graphs to alter how computation is performed, we demonstrate that they can serve as architecture generators to optimize the internal structure of NNs. To transform the random graph theory into an NN model with practical meaning and based on clarifying the input-output relationship of each neuron, we complete data feature mapping by calculating Fourier Random Features (FRFs). Under the usage of this low-operation cost approach, neurons are assigned to several groups of which connection relationships can be regarded as uniform representations of random graphs they belong to, and random arrangement fuses those neurons to establish the pattern matrix, markedly reducing manual participation and computational cost without the fixed and deep architecture. Leveraging this single neuromorphic learning model termed random graph-based neuro network (RGNN) we develop a joint classification mechanism involving information interaction between multiple RGNNs and realize significant performance improvements in supervised learning for three benchmark tasks, whereby they effectively avoid the adverse impact of the interpretability of NNs on the structure design and engineering practice.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

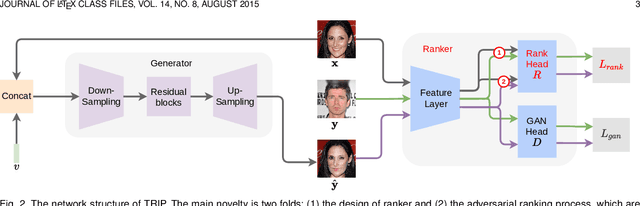
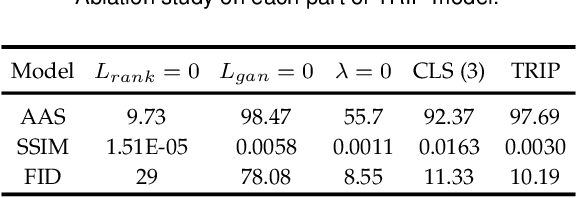
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.