 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HD-cos Networks: Efficient Neural Architectures for Secure Multi-Party Computation
Oct 28, 2021

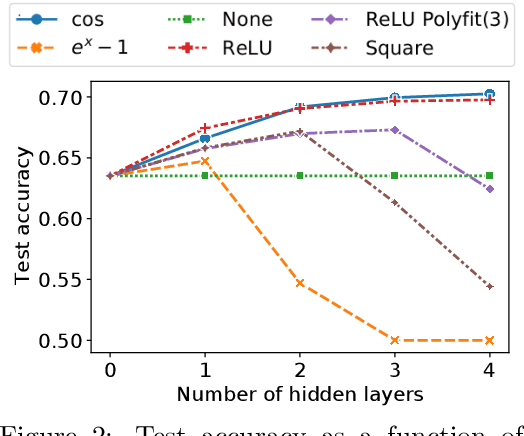
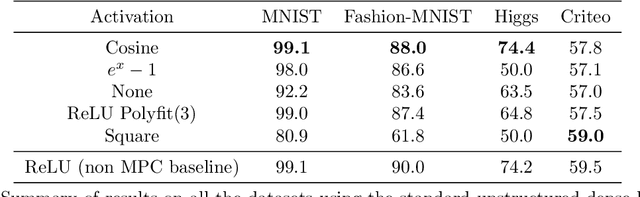

Multi-party computation (MPC) is a branch of cryptography where multiple non-colluding parties execute a well designed protocol to securely compute a function. With the non-colluding party assumption, MPC has a cryptographic guarantee that the parties will not learn sensitive information from the computation process, making it an appealing framework for applications that involve privacy-sensitive user data. In this paper, we study training and inference of neural networks under the MPC setup. This is challenging because the elementary operations of neural networks such as the ReLU activation function and matrix-vector multiplications are very expensive to compute due to the added multi-party communication overhead. To address this, we propose the HD-cos network that uses 1) cosine as activation function, 2) the Hadamard-Diagonal transformation to replace the unstructured linear transformations. We show that both of the approaches enjoy strong theoretical motivations and efficient computation under the MPC setup. We demonstrate on multiple public datasets that HD-cos matches the quality of the more expensive baselines.
Universal Decision Models
Oct 28, 2021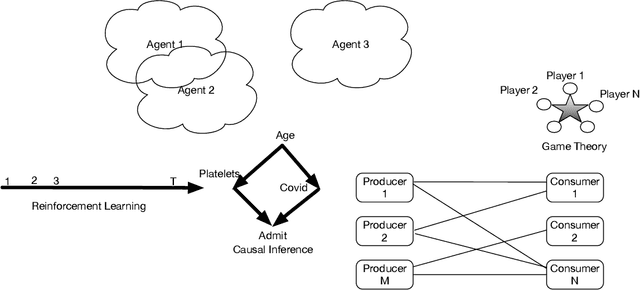
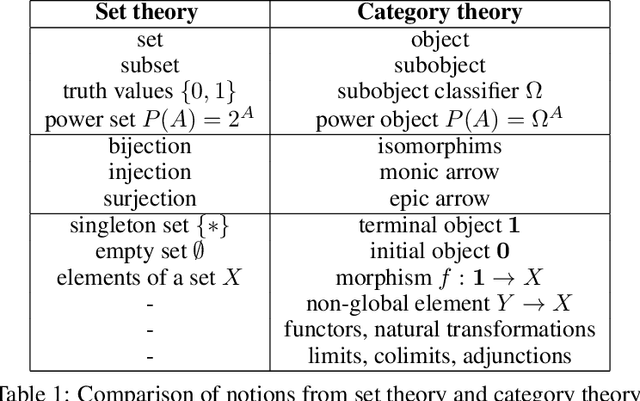


Humans are universal decision makers: we reason causally to understand the world; we act competitively to gain advantage in commerce, games, and war; and we are able to learn to make better decisions through trial and error. In this paper, we propose Universal Decision Model (UDM), a mathematical formalism based on category theory. Decision objects in a UDM correspond to instances of decision tasks, ranging from causal models and dynamical systems such as Markov decision processes and predictive state representations, to network multiplayer games and Witsenhausen's intrinsic models, which generalizes all these previous formalisms. A UDM is a category of objects, which include decision objects, observation objects, and solution objects. Bisimulation morphisms map between decision objects that capture structure-preserving abstractions. We formulate universal properties of UDMs, including information integration, decision solvability, and hierarchical abstraction. We describe universal functorial representations of UDMs, and propose an algorithm for computing the minimal object in a UDM using algebraic topology. We sketch out an application of UDMs to causal inference in network economics, using a complex multiplayer producer-consumer two-sided marketplace.
CANet: A Context-Aware Network for Shadow Removal
Aug 23, 2021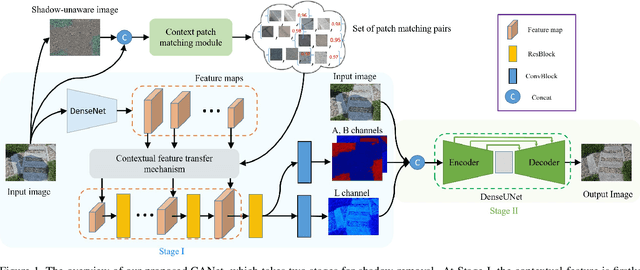
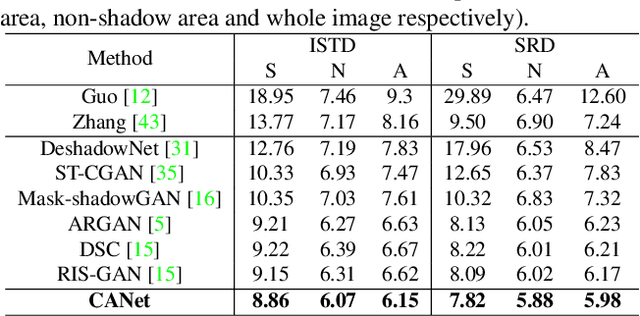
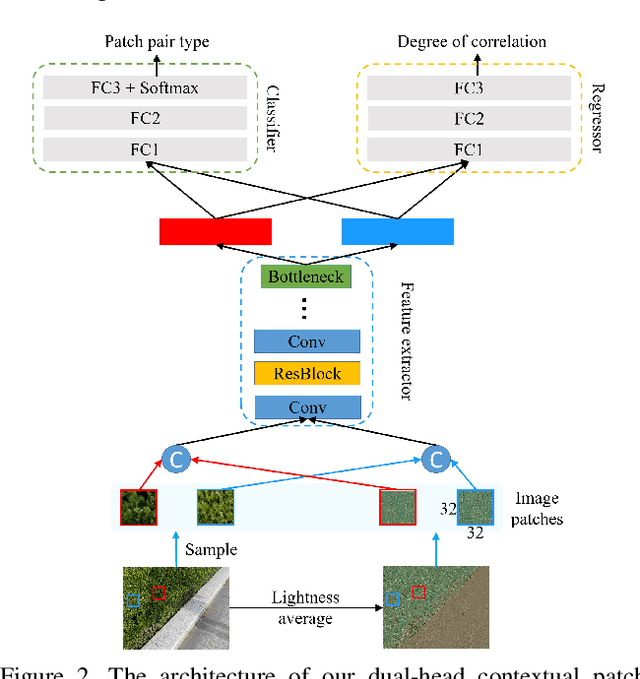
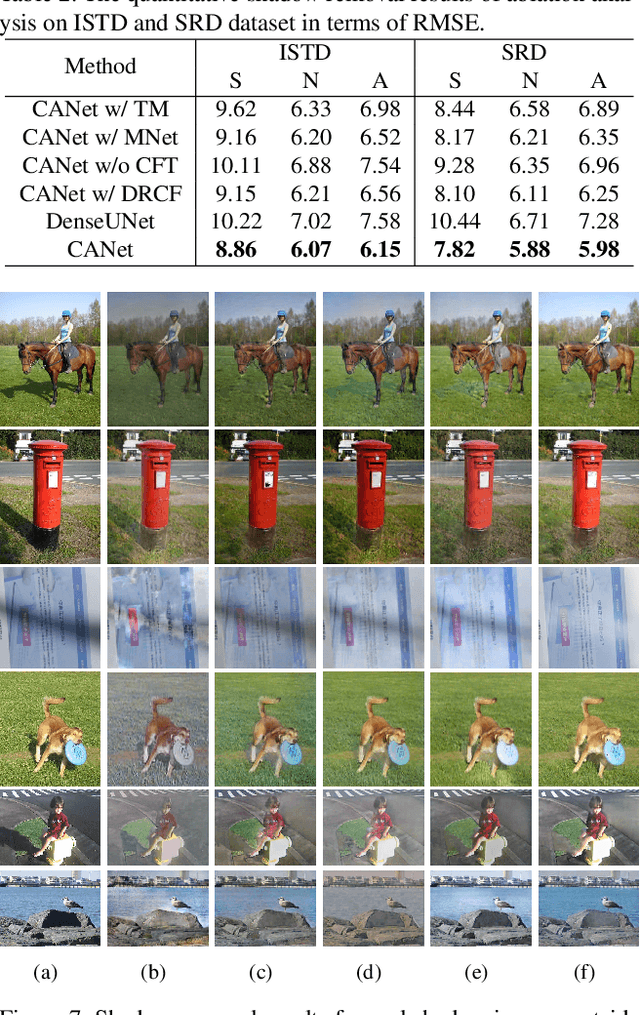
In this paper, we propose a novel two-stage context-aware network named CANet for shadow removal, in which the contextual information from non-shadow regions is transferred to shadow regions at the embedded feature spaces. At Stage-I, we propose a contextual patch matching (CPM) module to generate a set of potential matching pairs of shadow and non-shadow patches. Combined with the potential contextual relationships between shadow and non-shadow regions, our well-designed contextual feature transfer (CFT) mechanism can transfer contextual information from non-shadow to shadow regions at different scales. With the reconstructed feature maps, we remove shadows at L and A/B channels separately. At Stage-II, we use an encoder-decoder to refine current results and generate the final shadow removal results. We evaluate our proposed CANet on two benchmark datasets and some real-world shadow images with complex scenes. Extensive experimental results strongly demonstrate the efficacy of our proposed CANet and exhibit superior performance to state-of-the-arts.
Heuristical choice of SVM parameters
Nov 03, 2021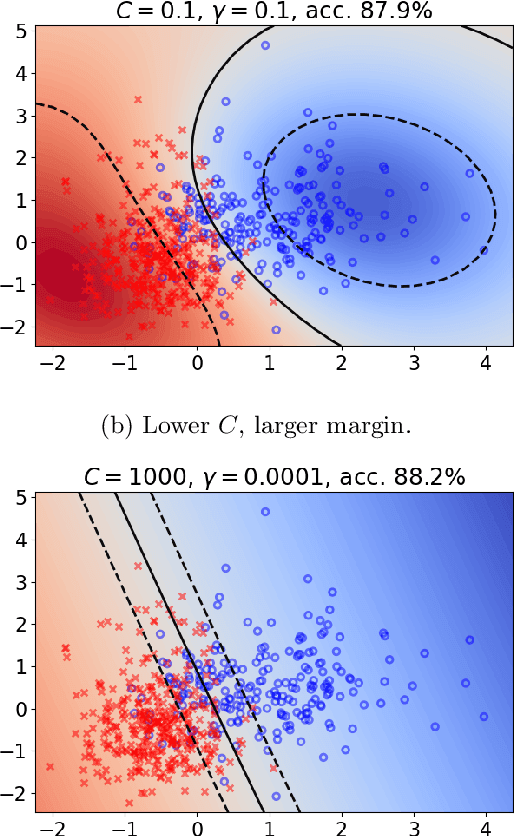
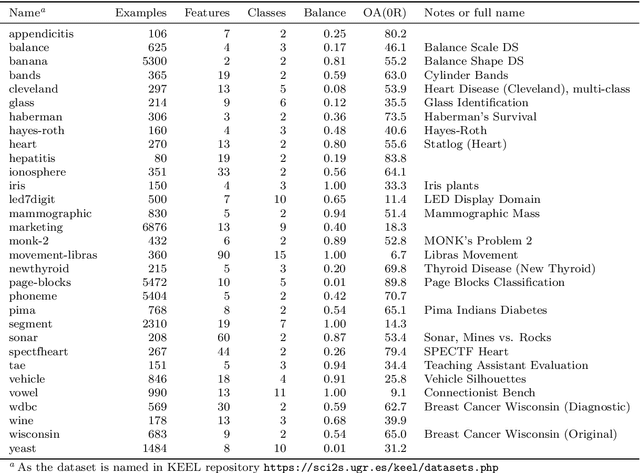
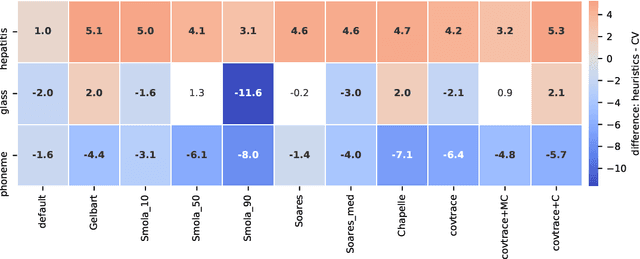
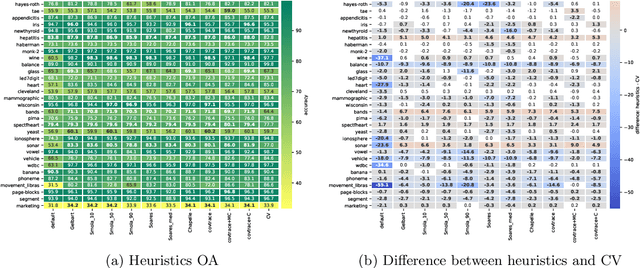
Support Vector Machine (SVM) is one of the most popular classification methods, and a de-facto reference for many Machine Learning approaches. Its performance is determined by parameter selection, which is usually achieved by a time-consuming grid search cross-validation procedure. There exist, however, several unsupervised heuristics that take advantage of the characteristics of the dataset for selecting parameters instead of using class label information. Unsupervised heuristics, while an order of magnitude faster, are scarcely used under the assumption that their results are significantly worse than those of grid search. To challenge that assumption we have conducted a wide study of various heuristics for SVM parameter selection on over thirty datasets, in both supervised and semi-supervised scenarios. In most cases, the cross-validation grid search did not achieve a significant advantage over the heuristics. In particular, heuristical parameter selection may be preferable for high dimensional and unbalanced datasets or when a small number of examples is available. Our results also show that using a heuristic to determine the starting point of further cross-validation does not yield significantly better results than the default start.
Unsupervised embedding and similarity detection of microregions using public transport schedules
Nov 03, 2021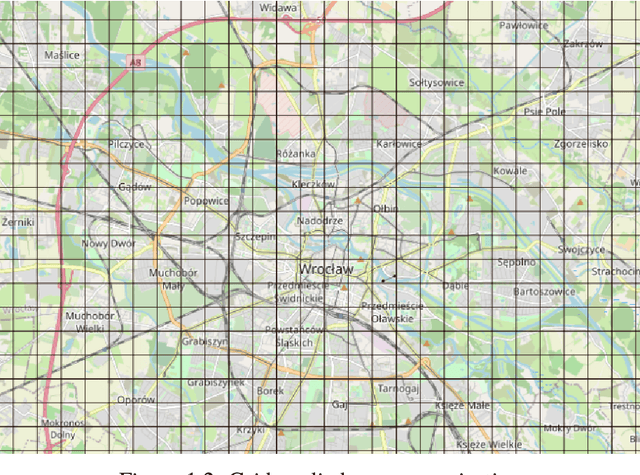
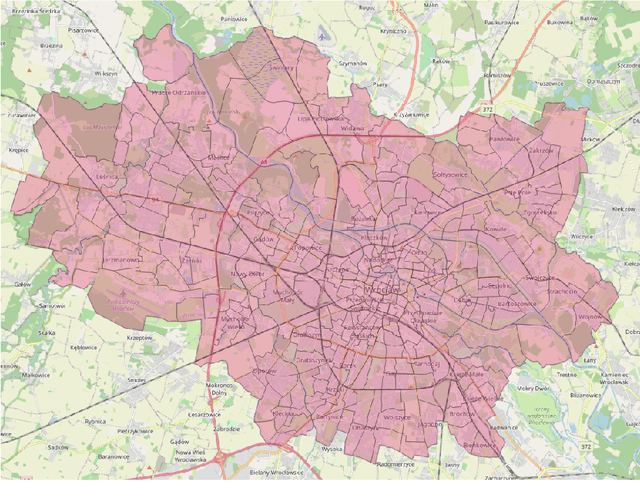
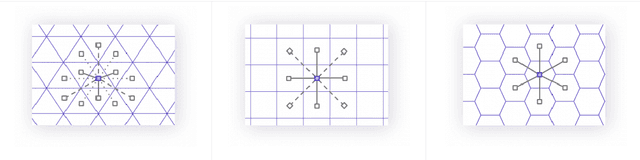
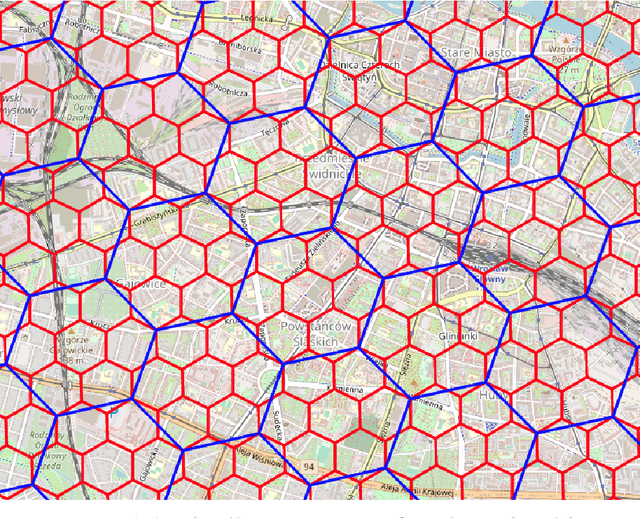
The role of spatial data in tackling city-related tasks has been growing in recent years. To use them in machine learning models, it is often necessary to transform them into a vector representation, which has led to the development in the field of spatial data representation learning. There is also a growing variety of spatial data types for which representation learning methods are proposed. Public transport timetables have so far not been used in the task of learning representations of regions in a city. In this work, a method is developed to embed public transport availability information into vector space. To conduct experiments on its application, public transport timetables were collected from 48 European cities. Using the H3 spatial indexing method, they were divided into micro-regions. A method was also proposed to identify regions with similar characteristics of public transport offers. On its basis, a multi-level typology of public transport offers in the regions was defined. This thesis shows that the proposed representation method makes it possible to identify micro-regions with similar public transport characteristics between the cities, and can be used to evaluate the quality of public transport available in a city.
Multi-view Contrastive Graph Clustering
Oct 22, 2021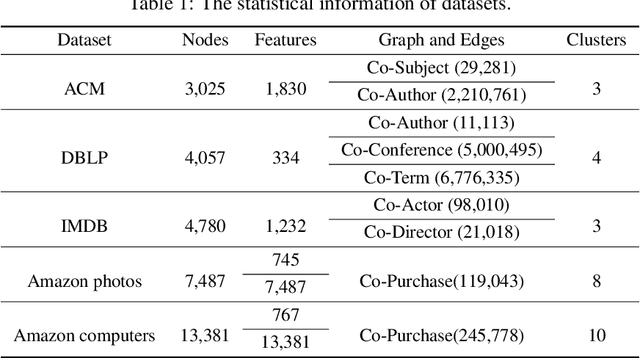
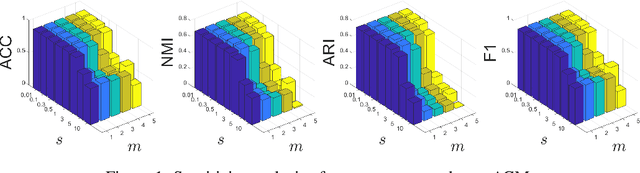
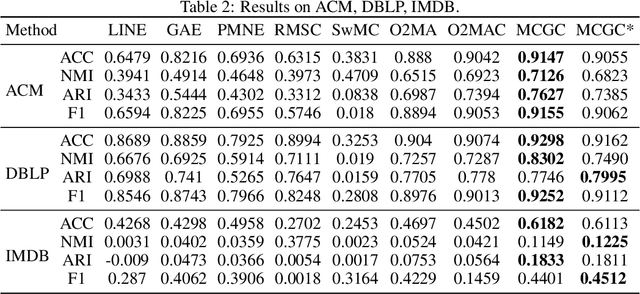
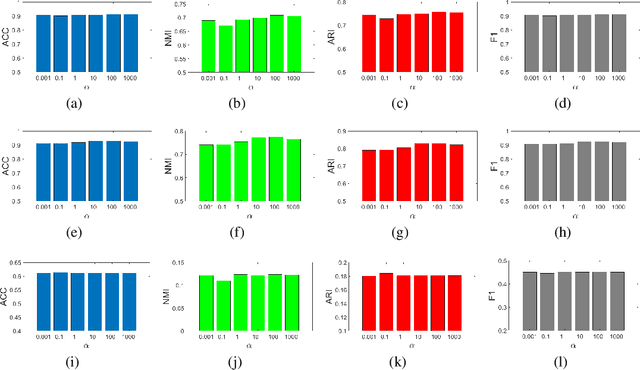
With the explosive growth of information technology, multi-view graph data have become increasingly prevalent and valuable. Most existing multi-view clustering techniques either focus on the scenario of multiple graphs or multi-view attributes. In this paper, we propose a generic framework to cluster multi-view attributed graph data. Specifically, inspired by the success of contrastive learning, we propose multi-view contrastive graph clustering (MCGC) method to learn a consensus graph since the original graph could be noisy or incomplete and is not directly applicable. Our method composes of two key steps: we first filter out the undesirable high-frequency noise while preserving the graph geometric features via graph filtering and obtain a smooth representation of nodes; we then learn a consensus graph regularized by graph contrastive loss. Results on several benchmark datasets show the superiority of our method with respect to state-of-the-art approaches. In particular, our simple approach outperforms existing deep learning-based methods.
Selective Regression Under Fairness Criteria
Oct 28, 2021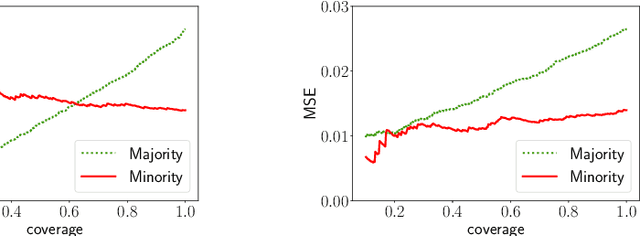
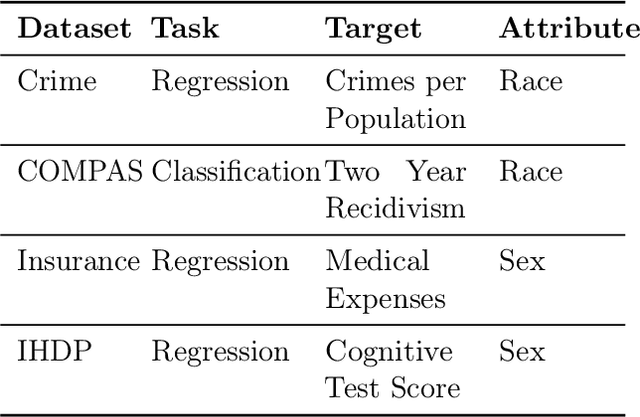
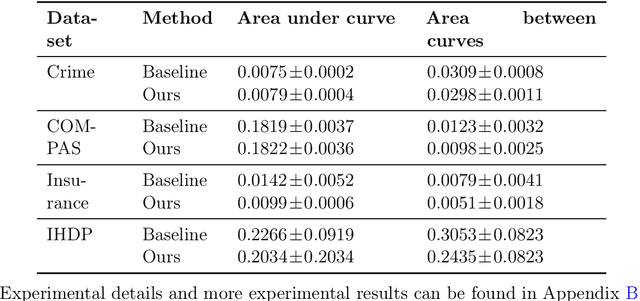
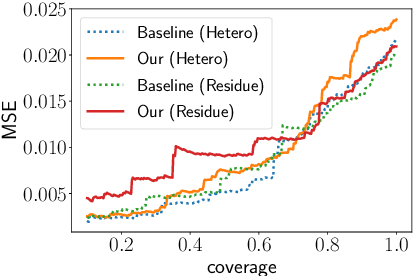
Selective regression allows abstention from prediction if the confidence to make an accurate prediction is not sufficient. In general, by allowing a reject option, one expects the performance of a regression model to increase at the cost of reducing coverage (i.e., by predicting fewer samples). However, as shown in this work, in some cases, the performance of minority group can decrease while we reduce the coverage, and thus selective regression can magnify disparities between different sensitive groups. We show that such an unwanted behavior can be avoided if we can construct features satisfying the sufficiency criterion, so that the mean prediction and the associated uncertainty are calibrated across all the groups. Further, to mitigate the disparity in the performance across groups, we introduce two approaches based on this calibration criterion: (a) by regularizing an upper bound of conditional mutual information under a Gaussian assumption and (b) by regularizing a contrastive loss for mean and uncertainty prediction. The effectiveness of these approaches are demonstrated on synthetic as well as real-world datasets.
Attempt to Predict Failure Case Classification in a Failure Database by using Neural Network Models
Aug 29, 2021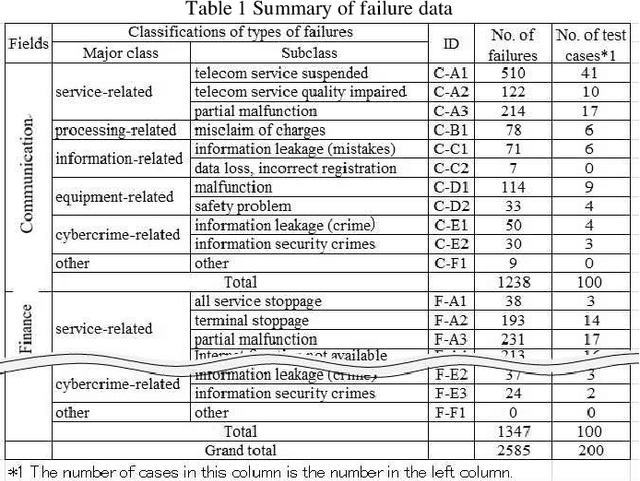
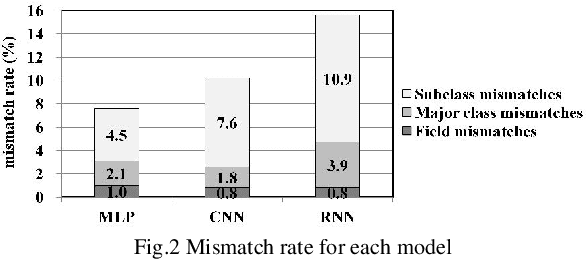
With the recent progress of information technology, the use of networked information systems has rapidly expanded. Electronic commerce and electronic payments between banks and companies, and online shopping and social networking services used by the general public are examples of such systems. Therefore, in order to maintain and improve the dependability of these systems, we are constructing a failure database from past failure cases. When importing new failure cases to the database, it is necessary to classify these cases according to failure type. The problems are the accuracy and efficiency of the classification. Especially when working with multiple individuals, unification of classification is required. Therefore, we are attempting to automate classification using machine learning. As evaluation models, we selected the multilayer perceptron (MLP), the convolutional neural network (CNN), and the recurrent neural network (RNN), which are models that use neural networks. As a result, the optimal model in terms of accuracy is first the MLP followed by the CNN, and the processing time of the classification is practical.
MSFNet:Multi-scale features network for monocular depth estimation
Jul 14, 2021
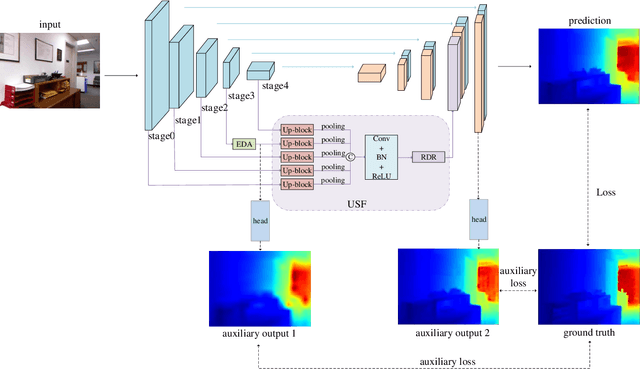
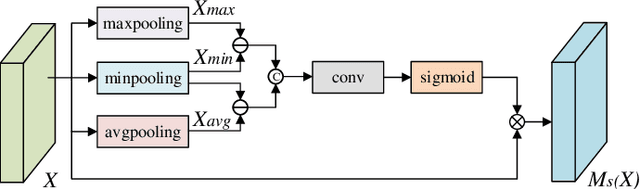
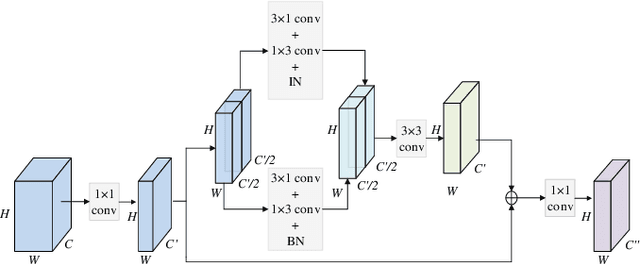
In recent years, monocular depth estimation is applied to understand the surrounding 3D environment and has made great progress. However, there is an ill-posed problem on how to gain depth information directly from a single image. With the rapid development of deep learning, this problem is possible to be solved. Although more and more approaches are proposed one after another, most of existing methods inevitably lost details due to continuous downsampling when mapping from RGB space to depth space. To the end, we design a Multi-scale Features Network (MSFNet), which consists of Enhanced Diverse Attention (EDA) module and Upsample-Stage Fusion (USF) module. The EDA module employs the spatial attention method to learn significant spatial information, while USF module complements low-level detail information with high-level semantic information from the perspective of multi-scale feature fusion to improve the predicted effect. In addition, since the simple samples are always trained to a better effect first, the hard samples are difficult to converge. Therefore, we design a batch-loss to assign large loss factors to the harder samples in a batch. Experiments on NYU-Depth V2 dataset and KITTI dataset demonstrate that our proposed approach is more competitive with the state-of-the-art methods in both qualitative and quantitative evaluation.
Fast Successive-Cancellation List Flip Decoding of Polar Codes
Sep 25, 2021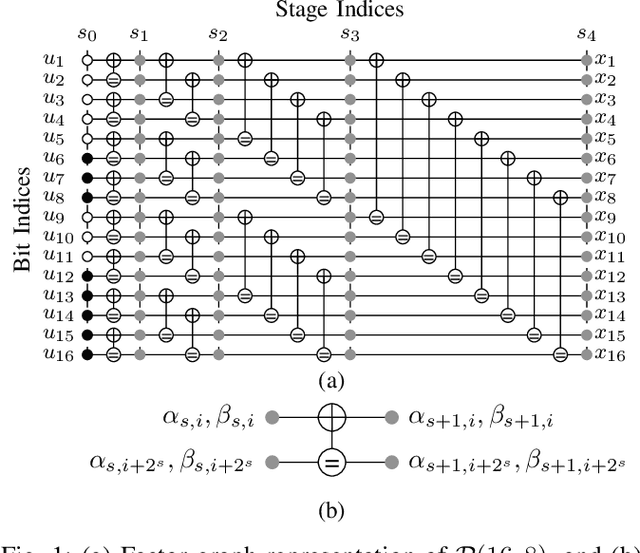
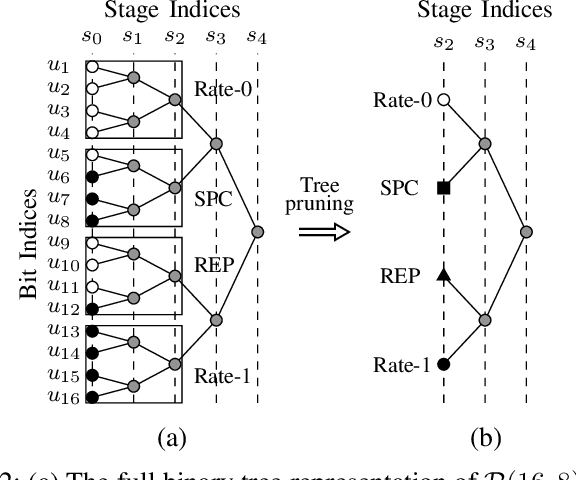


This work presents a fast successive-cancellation list flip (Fast-SCLF) decoding algorithm for polar codes that addresses the high latency issue associated with the successive-cancellation list flip (SCLF) decoding algorithm. We first propose a bit-flipping strategy tailored to the state-of-the-art fast successive-cancellation list (FSCL) decoding that avoids tree-traversal in the binary tree representation of SCLF, thus reducing the latency of the decoding process. We then derive a parameterized path-selection error model to accurately estimate the bit index at which the correct decoding path is eliminated from the initial FSCL decoding. The trainable parameter is optimized online based on an efficient supervised learning framework. Simulation results show that for a polar code of length 512 with 256 information bits, with similar error-correction performance and memory consumption, the proposed Fast-SCLF decoder reduces up to $73.4\%$ of the average decoding latency of the SCLF decoder with the same list size at the frame error rate of $10^{-4}$, while incurring a maximum computational overhead of $36.2\%$. For the same polar code of length 512 with 256 information bits and at practical signal-to-noise ratios, the proposed decoder with list size 4 reduces $89.1\%$ and $43.7\%$ of the average complexity and decoding latency of the FSCL decoder with list size 32 (FSCL-32), respectively, while also reducing $83.3\%$ of the memory consumption of FSCL-32. The significant improvements of the proposed decoder come at the cost of only $0.07$ dB error-correction performance degradation compared with FSCL-32.