 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
$p$-Laplacian Based Graph Neural Networks
Nov 14, 2021
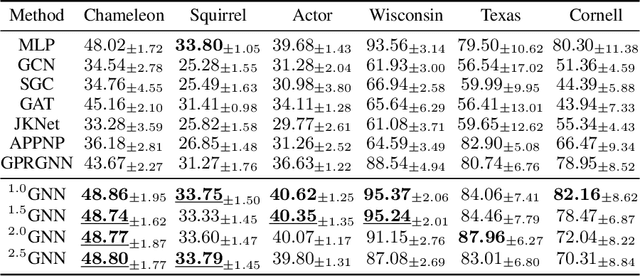
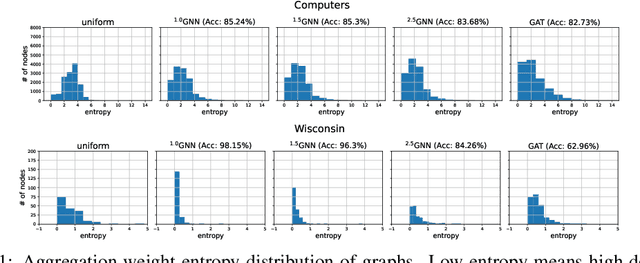
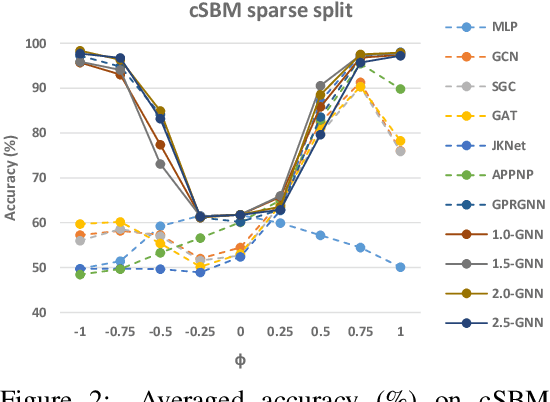
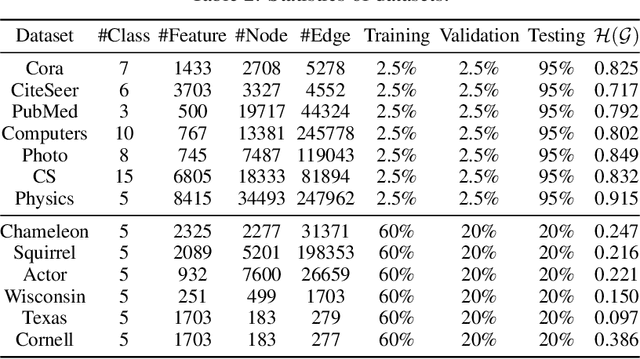
Graph neural networks (GNNs) have demonstrated superior performance for semi-supervised node classification on graphs, as a result of their ability to exploit node features and topological information simultaneously. However, most GNNs implicitly assume that the labels of nodes and their neighbors in a graph are the same or consistent, which does not hold in heterophilic graphs, where the labels of linked nodes are likely to differ. Hence, when the topology is non-informative for label prediction, ordinary GNNs may work significantly worse than simply applying multi-layer perceptrons (MLPs) on each node. To tackle the above problem, we propose a new $p$-Laplacian based GNN model, termed as $^p$GNN, whose message passing mechanism is derived from a discrete regularization framework and could be theoretically explained as an approximation of a polynomial graph filter defined on the spectral domain of $p$-Laplacians. The spectral analysis shows that the new message passing mechanism works simultaneously as low-pass and high-pass filters, thus making $^p$GNNs are effective on both homophilic and heterophilic graphs. Empirical studies on real-world and synthetic datasets validate our findings and demonstrate that $^p$GNNs significantly outperform several state-of-the-art GNN architectures on heterophilic benchmarks while achieving competitive performance on homophilic benchmarks. Moreover, $^p$GNNs can adaptively learn aggregation weights and are robust to noisy edges.
Unbiased Graph Embedding with Biased Graph Observations
Oct 29, 2021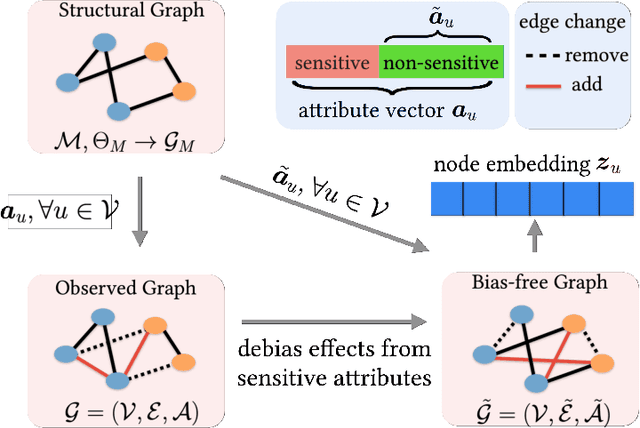
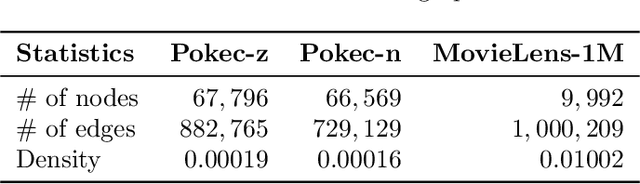
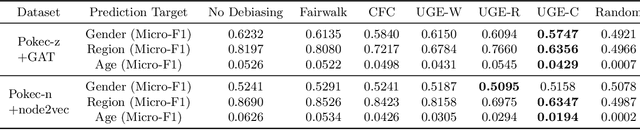
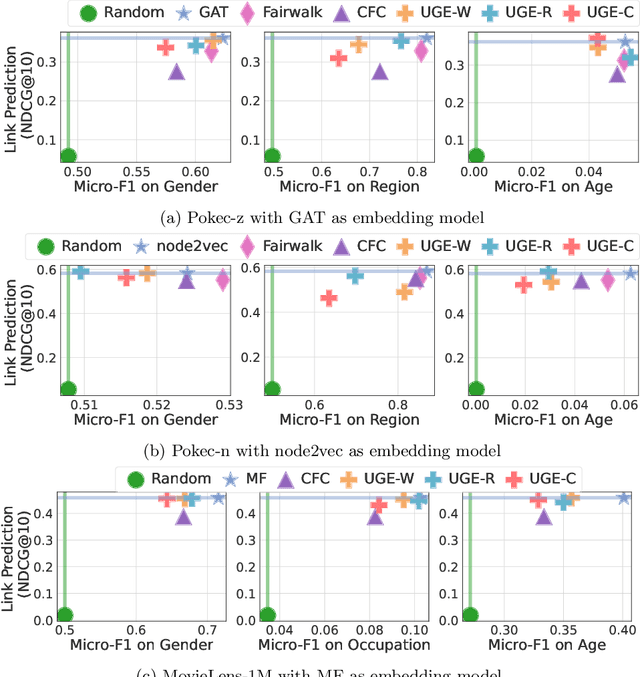
Graph embedding techniques have been increasingly employed in real-world machine learning tasks on graph-structured data, such as social recommendations and protein structure modeling. Since the generation of a graph is inevitably affected by some sensitive node attributes (such as gender and age of users in a social network), the learned graph representations can inherit such sensitive information and introduce undesirable biases in downstream tasks. Most existing works on debiasing graph representations add ad-hoc constraints on the learned embeddings to restrict their distributions, which however compromise the utility of resulting graph representations in downstream tasks. In this paper, we propose a principled new way for obtaining unbiased representations by learning from an underlying bias-free graph that is not influenced by sensitive attributes. Based on this new perspective, we propose two complementary methods for uncovering such an underlying graph with the goal of introducing minimum impact on the utility of learned representations in downstream tasks. Both our theoretical justification and extensive experiment comparisons against state-of-the-art solutions demonstrate the effectiveness of our proposed methods.
Performance Effectiveness of Multimedia Information Search Using the Epsilon-Greedy Algorithm
Nov 22, 2019


In the search and retrieval of multimedia objects, it is impractical to either manually or automatically extract the contents for indexing since most of the multimedia contents are not machine extractable, while manual extraction tends to be highly laborious and time-consuming. However, by systematically capturing and analyzing the feedback patterns of human users, vital information concerning the multimedia contents can be harvested for effective indexing and subsequent search. By learning from the human judgment and mental evaluation of users, effective search indices can be gradually developed and built up, and subsequently be exploited to find the most relevant multimedia objects. To avoid hovering around a local maximum, we apply the epsilon-greedy method to systematically explore the search space. Through such methodic exploration, we show that the proposed approach is able to guarantee that the most relevant objects can always be discovered, even though initially it may have been overlooked or not regarded as relevant. The search behavior of the present approach is quantitatively analyzed, and closed-form expressions are obtained for the performance of two variants of the epsilon-greedy algorithm, namely EGSE-A and EGSE-B. Simulations and experiments on real data set have been performed which show good agreement with the theoretical findings. The present method is able to leverage exploration in an effective way to significantly raise the performance of multimedia information search, and enables the certain discovery of relevant objects which may be otherwise undiscoverable.
Attempt to Predict Failure Case Classification in a Failure Database by using Neural Network Models
Aug 29, 2021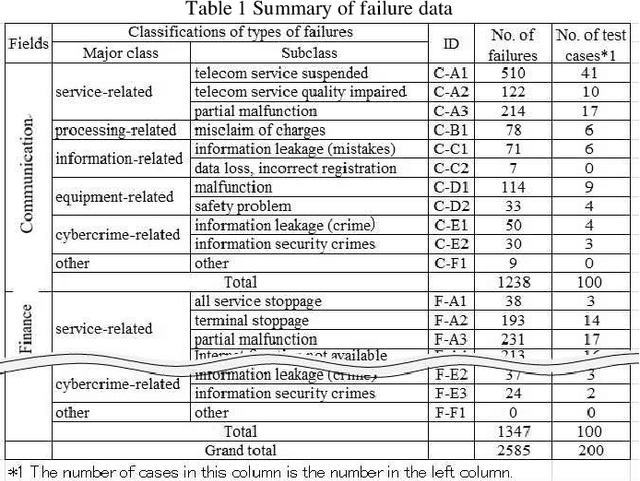
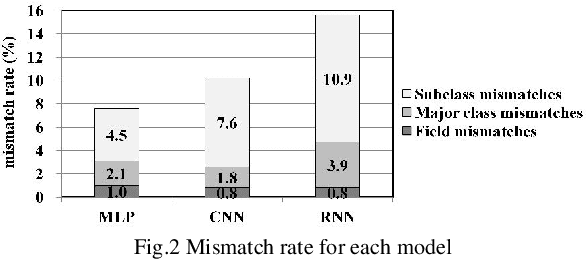
With the recent progress of information technology, the use of networked information systems has rapidly expanded. Electronic commerce and electronic payments between banks and companies, and online shopping and social networking services used by the general public are examples of such systems. Therefore, in order to maintain and improve the dependability of these systems, we are constructing a failure database from past failure cases. When importing new failure cases to the database, it is necessary to classify these cases according to failure type. The problems are the accuracy and efficiency of the classification. Especially when working with multiple individuals, unification of classification is required. Therefore, we are attempting to automate classification using machine learning. As evaluation models, we selected the multilayer perceptron (MLP), the convolutional neural network (CNN), and the recurrent neural network (RNN), which are models that use neural networks. As a result, the optimal model in terms of accuracy is first the MLP followed by the CNN, and the processing time of the classification is practical.
Inductive learning for product assortment graph completion
Oct 04, 2021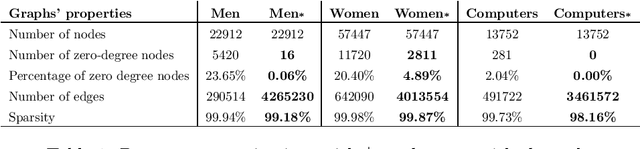
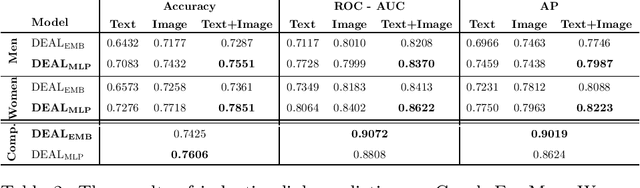
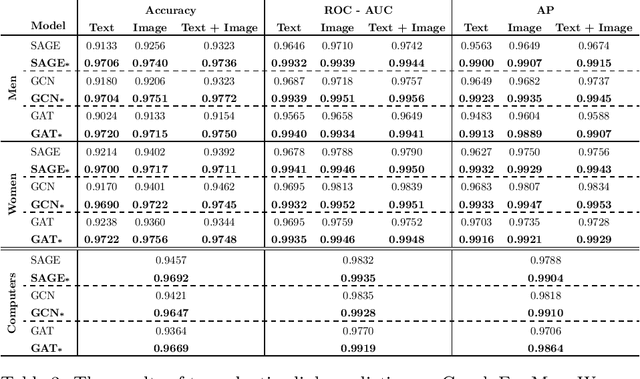
Global retailers have assortments that contain hundreds of thousands of products that can be linked by several types of relationships like style compatibility, "bought together", "watched together", etc. Graphs are a natural representation for assortments, where products are nodes and relations are edges. Relations like style compatibility are often produced by a manual process and therefore do not cover uniformly the whole graph. We propose to use inductive learning to enhance a graph encoding style compatibility of a fashion assortment, leveraging rich node information comprising textual descriptions and visual data. Then, we show how the proposed graph enhancement improves substantially the performance on transductive tasks with a minor impact on graph sparsity.
* 6 pages
A Few More Examples May Be Worth Billions of Parameters
Oct 08, 2021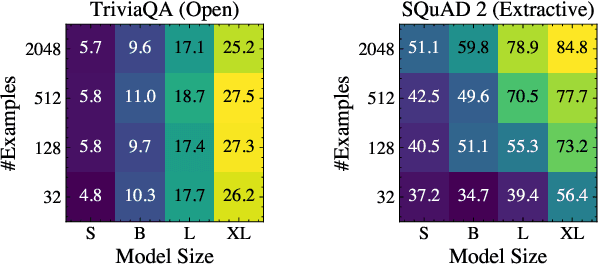
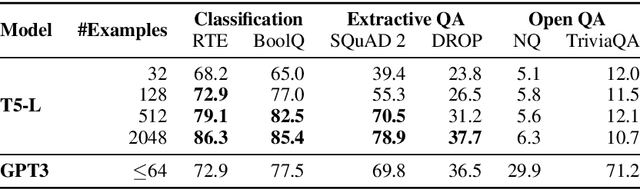
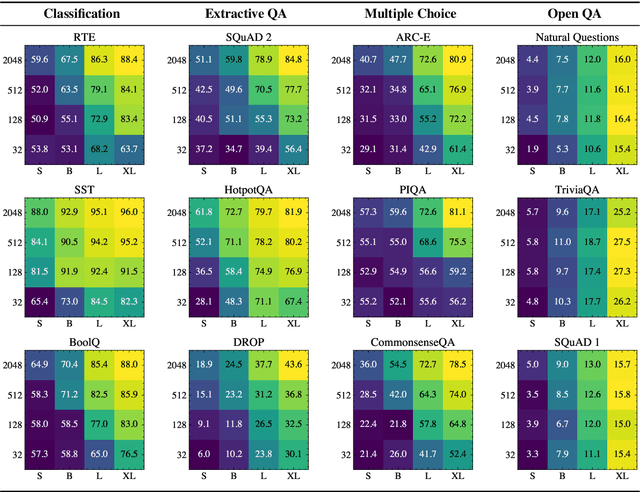
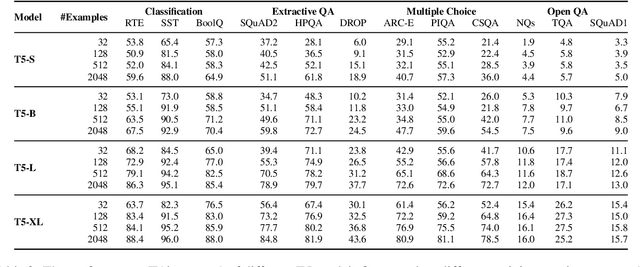
We investigate the dynamics of increasing the number of model parameters versus the number of labeled examples across a wide variety of tasks. Our exploration reveals that while scaling parameters consistently yields performance improvements, the contribution of additional examples highly depends on the task's format. Specifically, in open question answering tasks, enlarging the training set does not improve performance. In contrast, classification, extractive question answering, and multiple choice tasks benefit so much from additional examples that collecting a few hundred examples is often "worth" billions of parameters. We hypothesize that unlike open question answering, which involves recalling specific information, solving strategies for tasks with a more restricted output space transfer across examples, and can therefore be learned with small amounts of labeled data.
Network In Graph Neural Network
Nov 23, 2021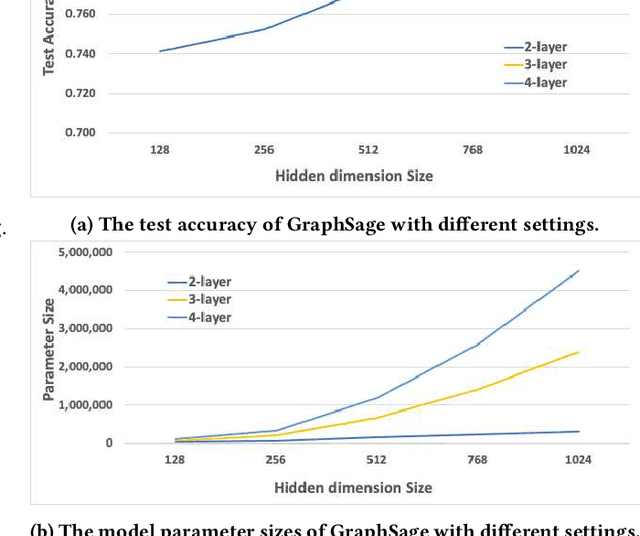
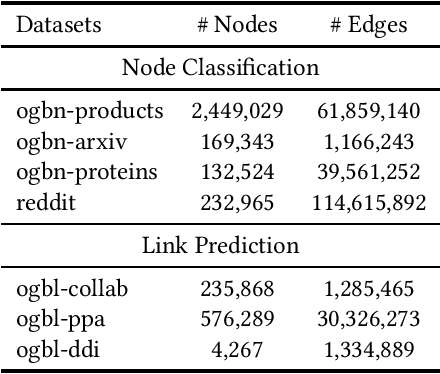
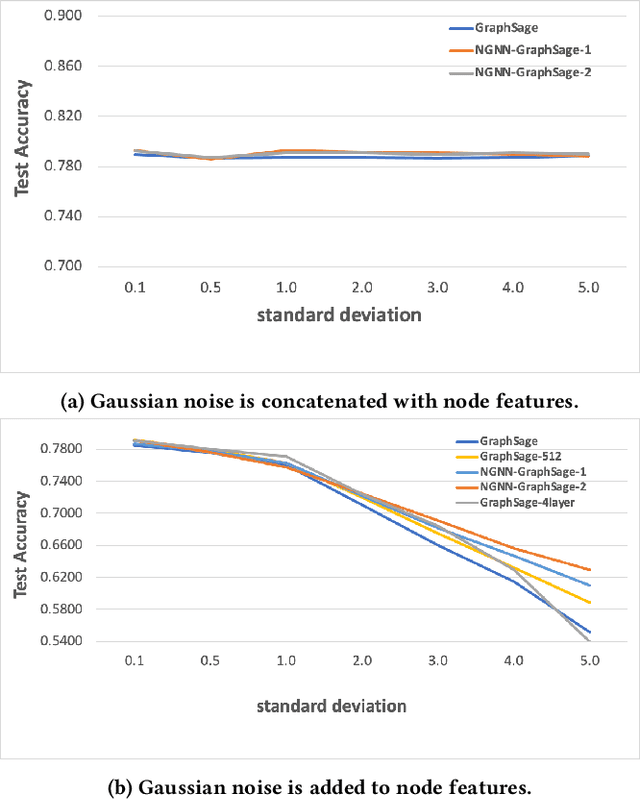

Graph Neural Networks (GNNs) have shown success in learning from graph structured data containing node/edge feature information, with application to social networks, recommendation, fraud detection and knowledge graph reasoning. In this regard, various strategies have been proposed in the past to improve the expressiveness of GNNs. For example, one straightforward option is to simply increase the parameter size by either expanding the hid-den dimension or increasing the number of GNN layers. However, wider hidden layers can easily lead to overfitting, and incrementally adding more GNN layers can potentially result in over-smoothing.In this paper, we present a model-agnostic methodology, namely Network In Graph Neural Network (NGNN ), that allows arbitrary GNN models to increase their model capacity by making the model deeper. However, instead of adding or widening GNN layers, NGNN deepens a GNN model by inserting non-linear feedforward neural network layer(s) within each GNN layer. An analysis of NGNN as applied to a GraphSage base GNN on ogbn-products data demonstrate that it can keep the model stable against either node feature or graph structure perturbations. Furthermore, wide-ranging evaluation results on both node classification and link prediction tasks show that NGNN works reliably across diverse GNN architectures.For instance, it improves the test accuracy of GraphSage on the ogbn-products by 1.6% and improves the hits@100 score of SEAL on ogbl-ppa by 7.08% and the hits@20 score of GraphSage+Edge-Attr on ogbl-ppi by 6.22%. And at the time of this submission, it achieved two first places on the OGB link prediction leaderboard.
BioLeaF: A Bio-plausible Learning Framework for Training of Spiking Neural Networks
Nov 14, 2021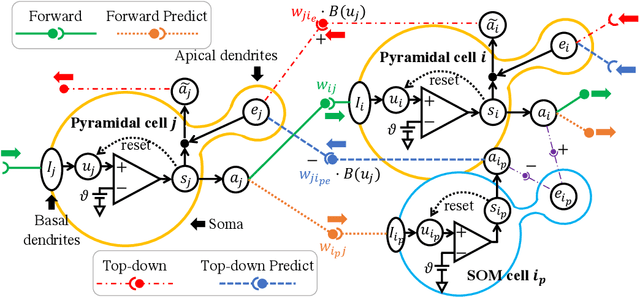
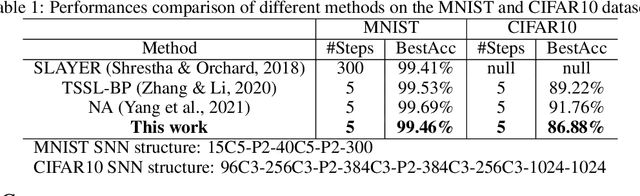
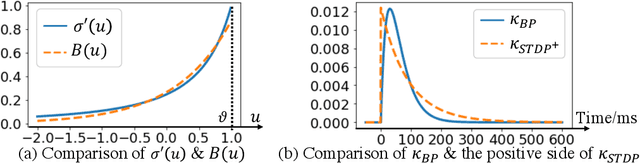
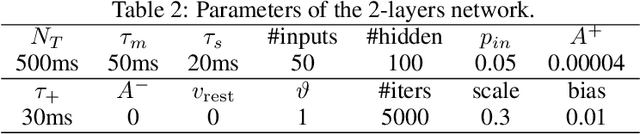
Our brain consists of biological neurons encoding information through accurate spike timing, yet both the architecture and learning rules of our brain remain largely unknown. Comparing to the recent development of backpropagation-based (BP-based) methods that are able to train spiking neural networks (SNNs) with high accuracy, biologically plausible methods are still in their infancy. In this work, we wish to answer the question of whether it is possible to attain comparable accuracy of SNNs trained by BP-based rules with bio-plausible mechanisms. We propose a new bio-plausible learning framework, consisting of two components: a new architecture, and its supporting learning rules. With two types of cells and four types of synaptic connections, the proposed local microcircuit architecture can compute and propagate error signals through local feedback connections and support training of multi-layers SNNs with a globally defined spiking error function. Under our microcircuit architecture, we employ the Spike-Timing-Dependent-Plasticity (STDP) rule operating in local compartments to update synaptic weights and achieve supervised learning in a biologically plausible manner. Finally, We interpret the proposed framework from an optimization point of view and show the equivalence between it and the BP-based rules under a special circumstance. Our experiments show that the proposed framework demonstrates learning accuracy comparable to BP-based rules and may provide new insights on how learning is orchestrated in biological systems.
Multi-Round Parsing-based Multiword Rules for Scientific OpenIE
Aug 04, 2021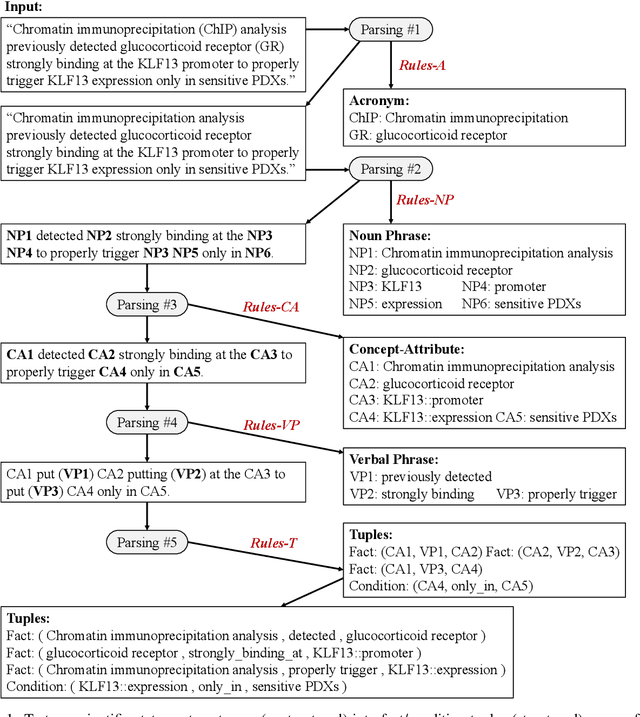
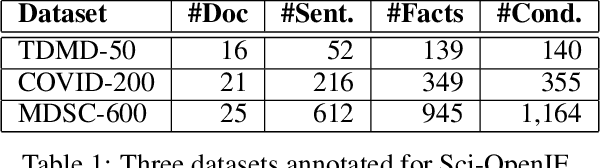
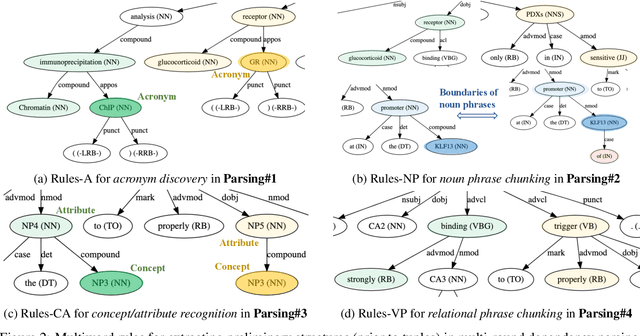
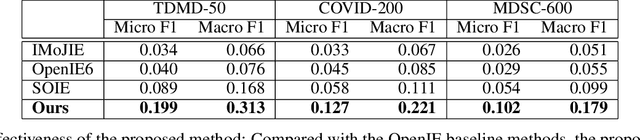
Information extraction (IE) in scientific literature has facilitated many down-stream tasks. OpenIE, which does not require any relation schema but identifies a relational phrase to describe the relationship between a subject and an object, is being a trending topic of IE in sciences. The subjects, objects, and relations are often multiword expressions, which brings challenges for methods to identify the boundaries of the expressions given very limited or even no training data. In this work, we present a set of rules for extracting structured information based on dependency parsing that can be applied to any scientific dataset requiring no expert's annotation. Results on novel datasets show the effectiveness of the proposed method. We discuss negative results as well.
Fusing ASR Outputs in Joint Training for Speech Emotion Recognition
Oct 29, 2021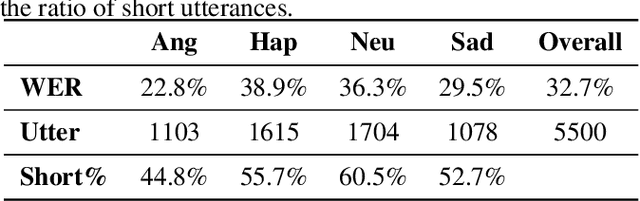
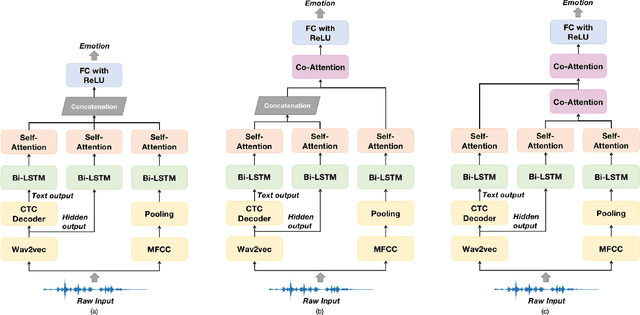
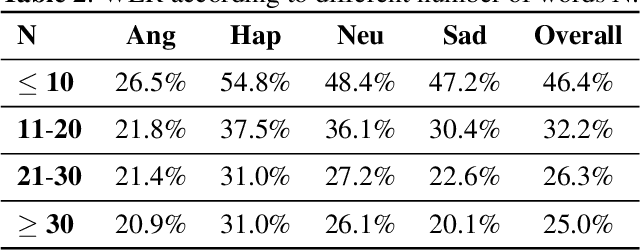

Alongside acoustic information, linguistic features based on speech transcripts have been proven useful in Speech Emotion Recognition (SER). However, due to the scarcity of emotion labelled data and the difficulty of recognizing emotional speech, it is hard to obtain reliable linguistic features and models in this research area. In this paper, we propose to fuse Automatic Speech Recognition (ASR) outputs into the pipeline for joint training SER. The relationship between ASR and SER is understudied, and it is unclear what and how ASR features benefit SER. By examining various ASR outputs and fusion methods, our experiments show that in joint ASR-SER training, incorporating both ASR hidden and text output using a hierarchical co-attention fusion approach improves the SER performance the most. On the IEMOCAP corpus, our approach achieves 63.4% weighted accuracy, which is close to the baseline results achieved by combining ground-truth transcripts. In addition, we also present novel word error rate analysis on IEMOCAP and layer-difference analysis of the Wav2vec 2.0 model to better understand the relationship between ASR and SER.