 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Winning the ICCV'2021 VALUE Challenge: Task-aware Ensemble and Transfer Learning with Visual Concepts
Oct 13, 2021
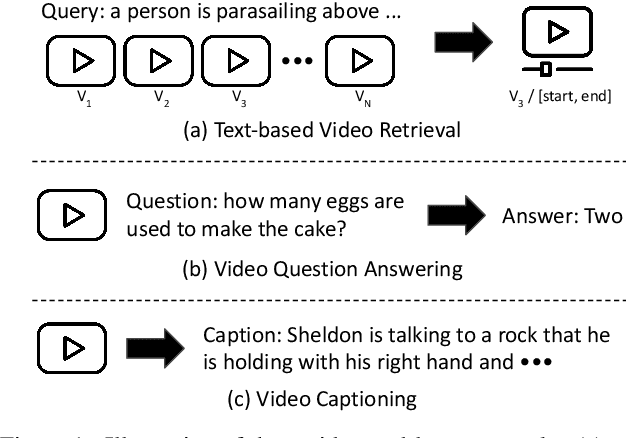

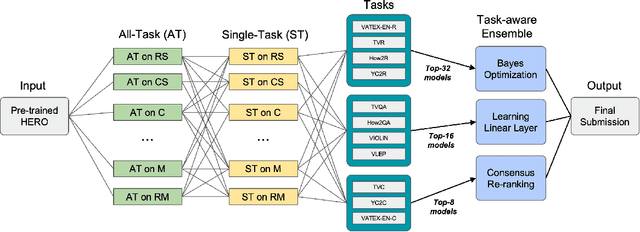
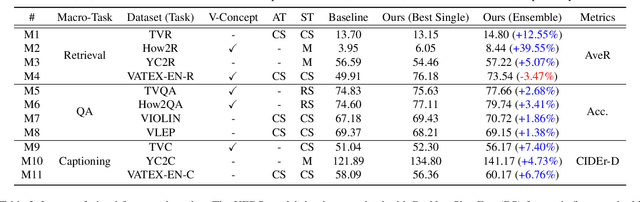
The VALUE (Video-And-Language Understanding Evaluation) benchmark is newly introduced to evaluate and analyze multi-modal representation learning algorithms on three video-and-language tasks: Retrieval, QA, and Captioning. The main objective of the VALUE challenge is to train a task-agnostic model that is simultaneously applicable for various tasks with different characteristics. This technical report describes our winning strategies for the VALUE challenge: 1) single model optimization, 2) transfer learning with visual concepts, and 3) task-aware ensemble. The first and third strategies are designed to address heterogeneous characteristics of each task, and the second one is to leverage rich and fine-grained visual information. We provide a detailed and comprehensive analysis with extensive experimental results. Based on our approach, we ranked first place on the VALUE and QA phases for the competition.
When expertise gone missing: Uncovering the loss of prolific contributors in Wikipedia
Sep 21, 2021

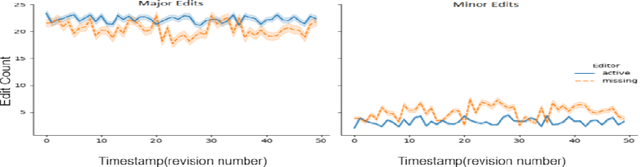

Success of planetary-scale online collaborative platforms such as Wikipedia is hinged on active and continued participation of its voluntary contributors. The phenomenal success of Wikipedia as a valued multilingual source of information is a testament to the possibilities of collective intelligence. Specifically, the sustained and prudent contributions by the experienced prolific editors play a crucial role to operate the platform smoothly for decades. However, it has been brought to light that growth of Wikipedia is stagnating in terms of the number of editors that faces steady decline over time. This decreasing productivity and ever increasing attrition rate in both newcomer and experienced editors is a major concern for not only the future of this platform but also for several industry-scale information retrieval systems such as Siri, Alexa which depend on Wikipedia as knowledge store. In this paper, we have studied the ongoing crisis in which experienced and prolific editors withdraw. We performed extensive analysis of the editor activities and their language usage to identify features that can forecast prolific Wikipedians, who are at risk of ceasing voluntary services. To the best of our knowledge, this is the first work which proposes a scalable prediction pipeline, towards detecting the prolific Wikipedians, who might be at a risk of retiring from the platform and, thereby, can potentially enable moderators to launch appropriate incentive mechanisms to retain such `would-be missing' valued Wikipedians.
BioLeaF: A Bio-plausible Learning Framework for Training of Spiking Neural Networks
Nov 14, 2021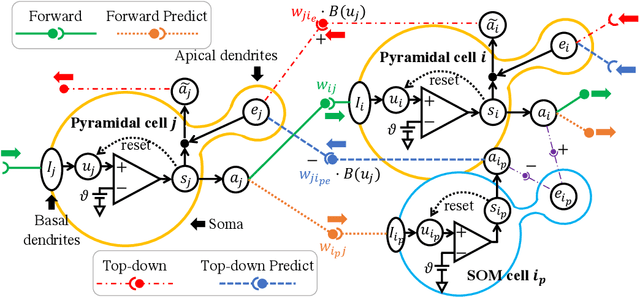
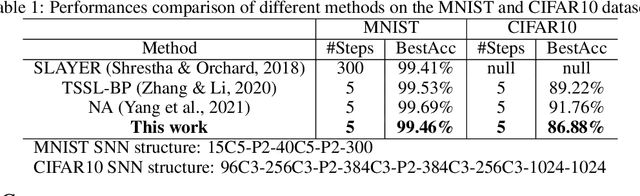
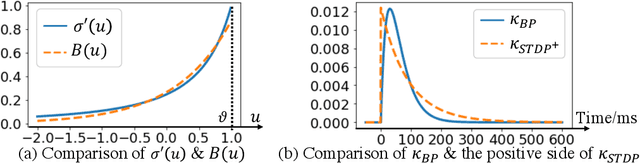
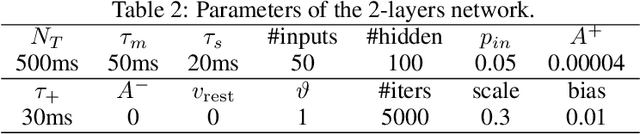
Our brain consists of biological neurons encoding information through accurate spike timing, yet both the architecture and learning rules of our brain remain largely unknown. Comparing to the recent development of backpropagation-based (BP-based) methods that are able to train spiking neural networks (SNNs) with high accuracy, biologically plausible methods are still in their infancy. In this work, we wish to answer the question of whether it is possible to attain comparable accuracy of SNNs trained by BP-based rules with bio-plausible mechanisms. We propose a new bio-plausible learning framework, consisting of two components: a new architecture, and its supporting learning rules. With two types of cells and four types of synaptic connections, the proposed local microcircuit architecture can compute and propagate error signals through local feedback connections and support training of multi-layers SNNs with a globally defined spiking error function. Under our microcircuit architecture, we employ the Spike-Timing-Dependent-Plasticity (STDP) rule operating in local compartments to update synaptic weights and achieve supervised learning in a biologically plausible manner. Finally, We interpret the proposed framework from an optimization point of view and show the equivalence between it and the BP-based rules under a special circumstance. Our experiments show that the proposed framework demonstrates learning accuracy comparable to BP-based rules and may provide new insights on how learning is orchestrated in biological systems.
Provable Regret Bounds for Deep Online Learning and Control
Oct 20, 2021The use of deep neural networks has been highly successful in reinforcement learning and control, although few theoretical guarantees for deep learning exist for these problems. There are two main challenges for deriving performance guarantees: a) control has state information and thus is inherently online and b) deep networks are non-convex predictors for which online learning cannot provide provable guarantees in general. Building on the linearization technique for overparameterized neural networks, we derive provable regret bounds for efficient online learning with deep neural networks. Specifically, we show that over any sequence of convex loss functions, any low-regret algorithm can be adapted to optimize the parameters of a neural network such that it competes with the best net in hindsight. As an application of these results in the online setting, we obtain provable bounds for online episodic control with deep neural network controllers.
COfEE: A Comprehensive Ontology for Event Extraction from text, with an online annotation tool
Aug 01, 2021

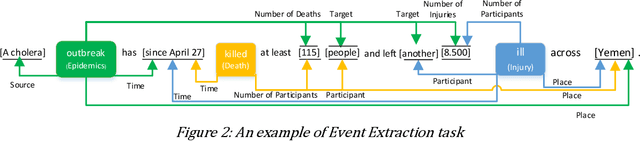
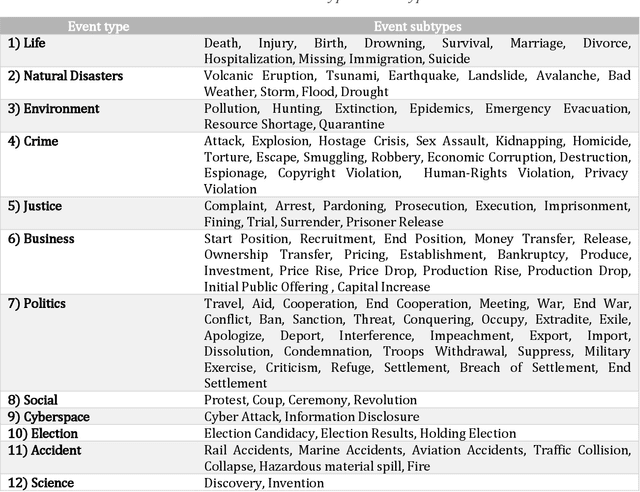
Data is published on the web over time in great volumes, but majority of the data is unstructured, making it hard to understand and difficult to interpret. Information Extraction (IE) methods extract structured information from unstructured data. One of the challenging IE tasks is Event Extraction (EE) which seeks to derive information about specific incidents and their actors from the text. EE is useful in many domains such as building a knowledge base, information retrieval, summarization and online monitoring systems. In the past decades, some event ontologies like ACE, CAMEO and ICEWS were developed to define event forms, actors and dimensions of events observed in the text. These event ontologies still have some shortcomings such as covering only a few topics like political events, having inflexible structure in defining argument roles, lack of analytical dimensions, and complexity in choosing event sub-types. To address these concerns, we propose an event ontology, namely COfEE, that incorporates both expert domain knowledge, previous ontologies and a data-driven approach for identifying events from text. COfEE consists of two hierarchy levels (event types and event sub-types) that include new categories relating to environmental issues, cyberspace, criminal activity and natural disasters which need to be monitored instantly. Also, dynamic roles according to each event sub-type are defined to capture various dimensions of events. In a follow-up experiment, the proposed ontology is evaluated on Wikipedia events, and it is shown to be general and comprehensive. Moreover, in order to facilitate the preparation of gold-standard data for event extraction, a language-independent online tool is presented based on COfEE.
Feature-Rich Named Entity Recognition for Bulgarian Using Conditional Random Fields
Sep 26, 2021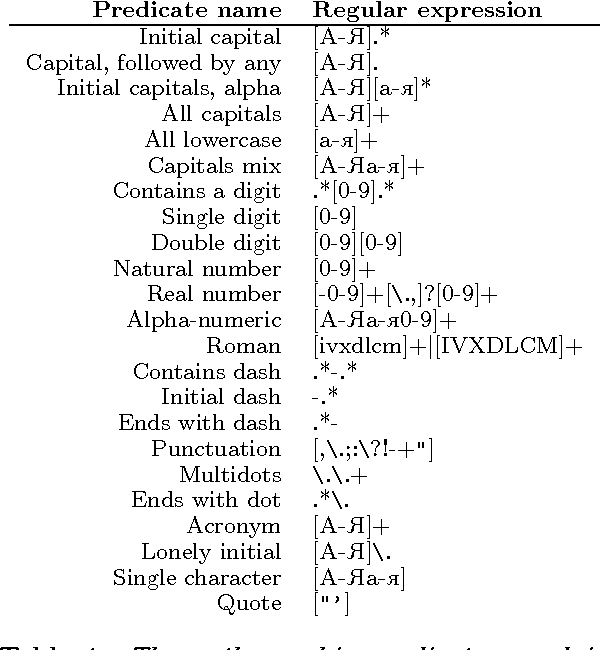

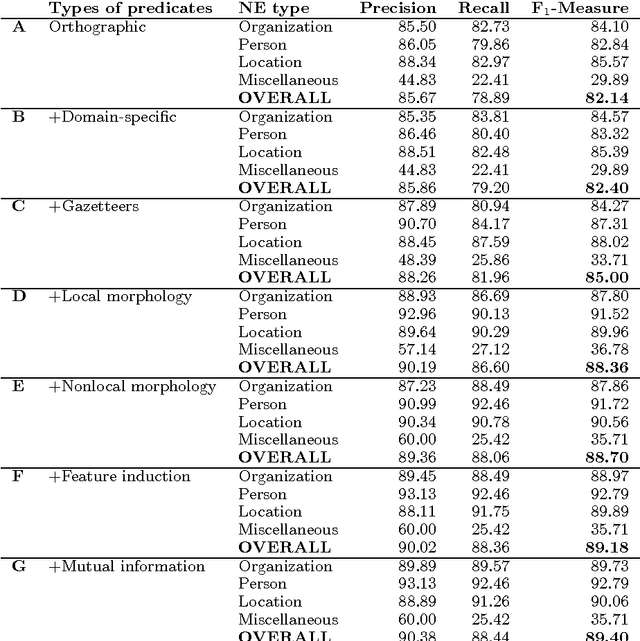
The paper presents a feature-rich approach to the automatic recognition and categorization of named entities (persons, organizations, locations, and miscellaneous) in news text for Bulgarian. We combine well-established features used for other languages with language-specific lexical, syntactic and morphological information. In particular, we make use of the rich tagset annotation of the BulTreeBank (680 morpho-syntactic tags), from which we derive suitable task-specific tagsets (local and nonlocal). We further add domain-specific gazetteers and additional unlabeled data, achieving F1=89.4%, which is comparable to the state-of-the-art results for English.
* named entity recognition, NER, conditional random fields, CRF, Bulgarian, BulTreeBank
Unbiased Graph Embedding with Biased Graph Observations
Oct 29, 2021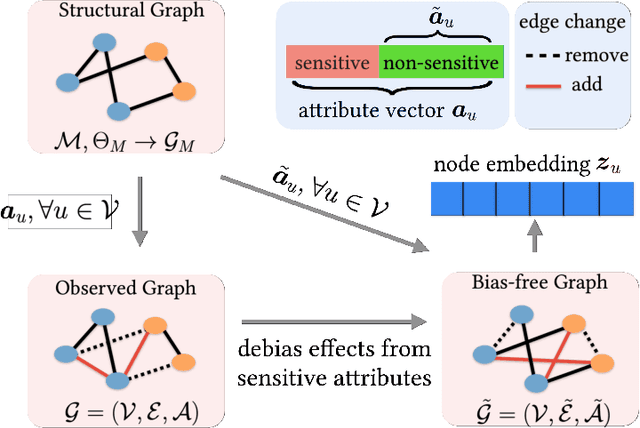
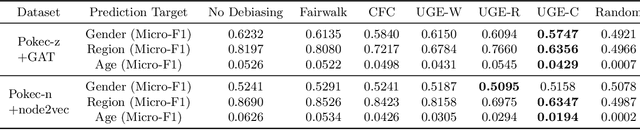
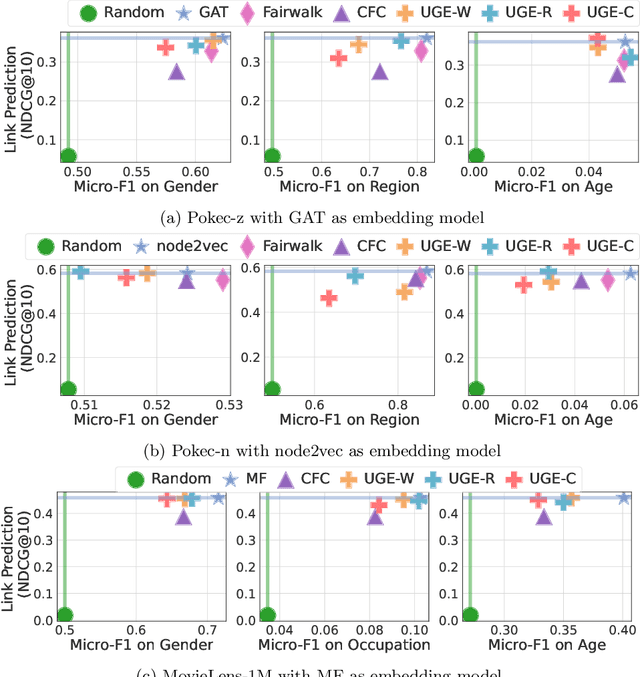
Graph embedding techniques have been increasingly employed in real-world machine learning tasks on graph-structured data, such as social recommendations and protein structure modeling. Since the generation of a graph is inevitably affected by some sensitive node attributes (such as gender and age of users in a social network), the learned graph representations can inherit such sensitive information and introduce undesirable biases in downstream tasks. Most existing works on debiasing graph representations add ad-hoc constraints on the learned embeddings to restrict their distributions, which however compromise the utility of resulting graph representations in downstream tasks. In this paper, we propose a principled new way for obtaining unbiased representations by learning from an underlying bias-free graph that is not influenced by sensitive attributes. Based on this new perspective, we propose two complementary methods for uncovering such an underlying graph with the goal of introducing minimum impact on the utility of learned representations in downstream tasks. Both our theoretical justification and extensive experiment comparisons against state-of-the-art solutions demonstrate the effectiveness of our proposed methods.
Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations
Nov 26, 2021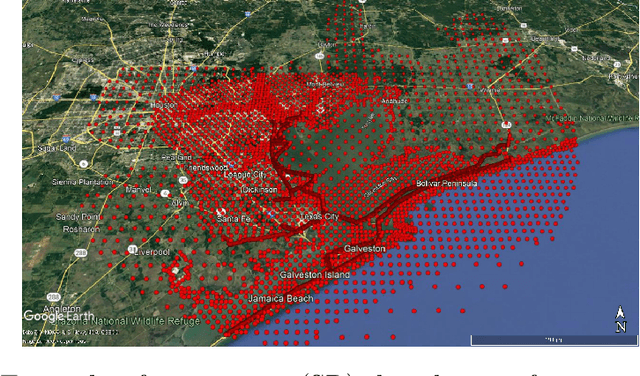
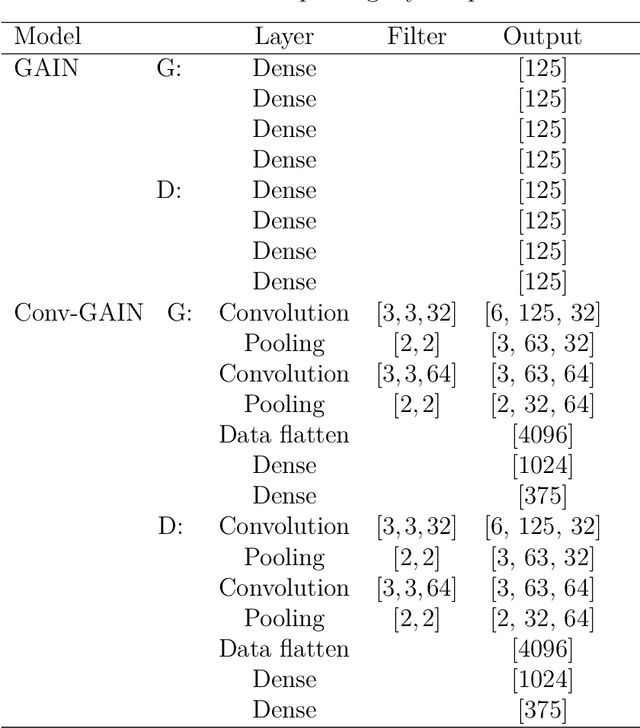
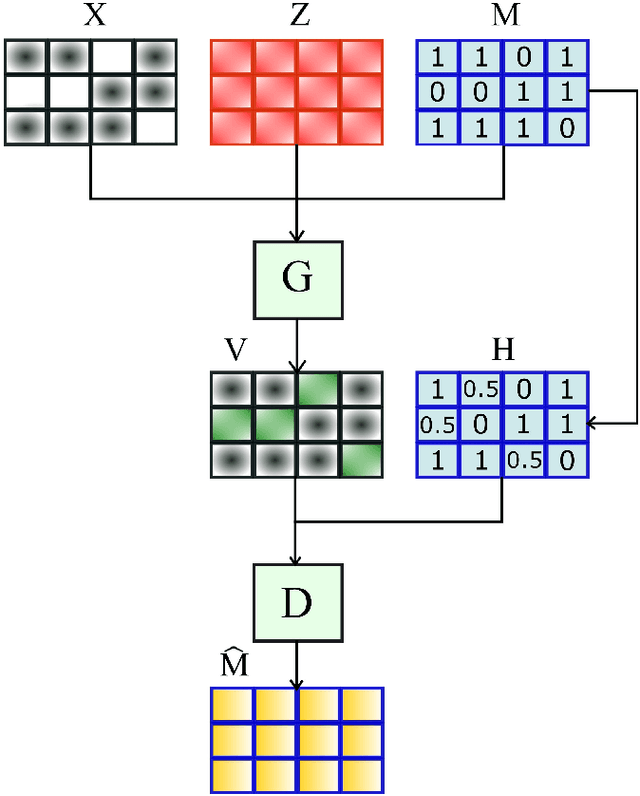

Imputation of missing data is a task that plays a vital role in a number of engineering and science applications. Often such missing data arise in experimental observations from limitations of sensors or post-processing transformation errors. Other times they arise from numerical and algorithmic constraints in computer simulations. One such instance and the application emphasis of this paper are numerical simulations of storm surge. The simulation data corresponds to time-series surge predictions over a number of save points within the geographic domain of interest, creating a spatio-temporal imputation problem where the surge points are heavily correlated spatially and temporally, and the missing values regions are structurally distributed at random. Very recently, machine learning techniques such as neural network methods have been developed and employed for missing data imputation tasks. Generative Adversarial Nets (GANs) and GAN-based techniques have particularly attracted attention as unsupervised machine learning methods. In this study, the Generative Adversarial Imputation Nets (GAIN) performance is improved by applying convolutional neural networks instead of fully connected layers to better capture the correlation of data and promote learning from the adjacent surge points. Another adjustment to the method needed specifically for the studied data is to consider the coordinates of the points as additional features to provide the model more information through the convolutional layers. We name our proposed method as Convolutional Generative Adversarial Imputation Nets (Conv-GAIN). The proposed method's performance by considering the improvements and adaptations required for the storm surge data is assessed and compared to the original GAIN and a few other techniques. The results show that Conv-GAIN has better performance than the alternative methods on the studied data.
A Reinforcement Learning Approach for the Continuous Electricity Market of Germany: Trading from the Perspective of a Wind Park Operator
Nov 26, 2021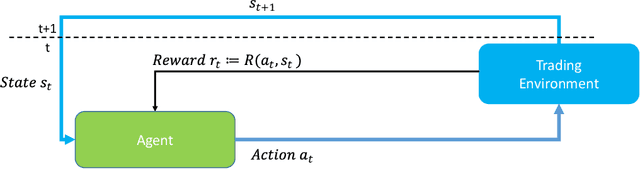
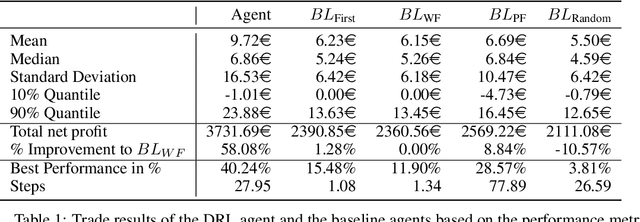
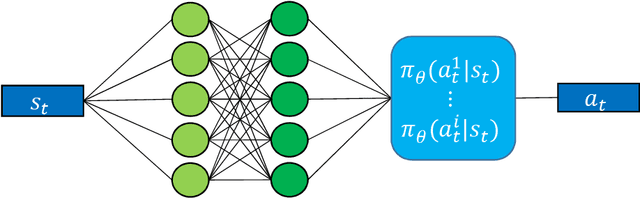
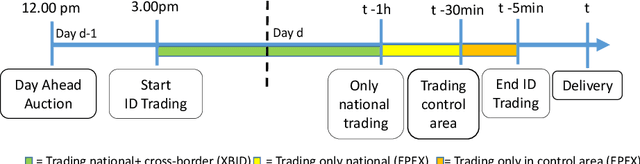
With the rising extension of renewable energies, the intraday electricity markets have recorded a growing popularity amongst traders as well as electric utilities to cope with the induced volatility of the energy supply. Through their short trading horizon and continuous nature, the intraday markets offer the ability to adjust trading decisions from the day-ahead market or reduce trading risk in a short-term notice. Producers of renewable energies utilize the intraday market to lower their forecast risk, by modifying their provided capacities based on current forecasts. However, the market dynamics are complex due to the fact that the power grids have to remain stable and electricity is only partly storable. Consequently, robust and intelligent trading strategies are required that are capable to operate in the intraday market. In this work, we propose a novel autonomous trading approach based on Deep Reinforcement Learning (DRL) algorithms as a possible solution. For this purpose, we model the intraday trade as a Markov Decision Problem (MDP) and employ the Proximal Policy Optimization (PPO) algorithm as our DRL approach. A simulation framework is introduced that enables the trading of the continuous intraday price in a resolution of one minute steps. We test our framework in a case study from the perspective of a wind park operator. We include next to general trade information both price and wind forecasts. On a test scenario of German intraday trading results from 2018, we are able to outperform multiple baselines with at least 45.24% improvement, showing the advantage of the DRL algorithm. However, we also discuss limitations and enhancements of the DRL agent, in order to increase the performance in future works.
Qimera: Data-free Quantization with Synthetic Boundary Supporting Samples
Nov 04, 2021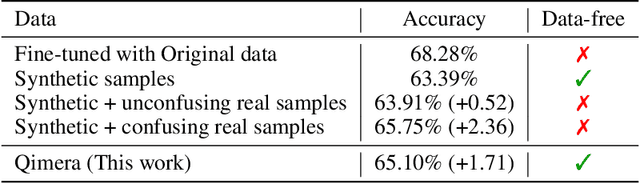
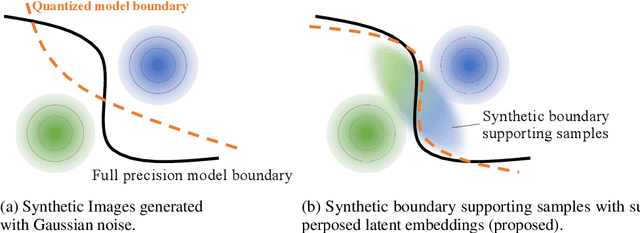
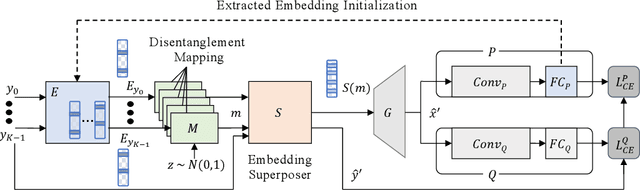
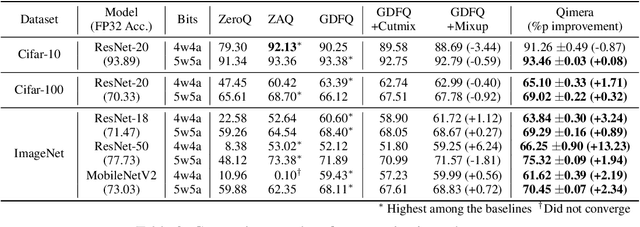
Model quantization is known as a promising method to compress deep neural networks, especially for inferences on lightweight mobile or edge devices. However, model quantization usually requires access to the original training data to maintain the accuracy of the full-precision models, which is often infeasible in real-world scenarios for security and privacy issues. A popular approach to perform quantization without access to the original data is to use synthetically generated samples, based on batch-normalization statistics or adversarial learning. However, the drawback of such approaches is that they primarily rely on random noise input to the generator to attain diversity of the synthetic samples. We find that this is often insufficient to capture the distribution of the original data, especially around the decision boundaries. To this end, we propose Qimera, a method that uses superposed latent embeddings to generate synthetic boundary supporting samples. For the superposed embeddings to better reflect the original distribution, we also propose using an additional disentanglement mapping layer and extracting information from the full-precision model. The experimental results show that Qimera achieves state-of-the-art performances for various settings on data-free quantization. Code is available at https://github.com/iamkanghyunchoi/qimera.