 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rethink Dilated Convolution for Real-time Semantic Segmentation
Nov 18, 2021
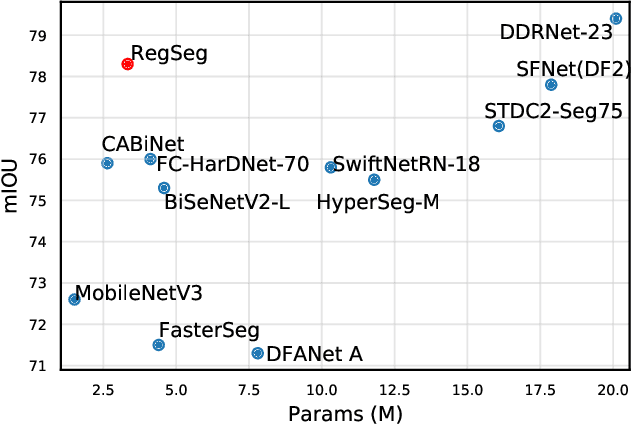
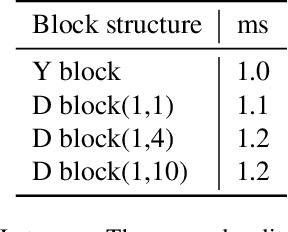
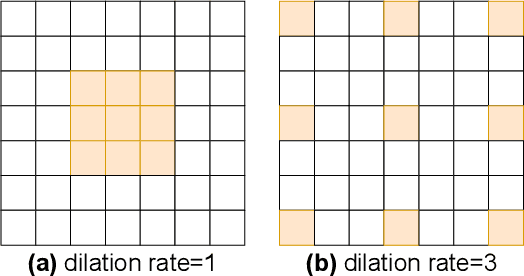
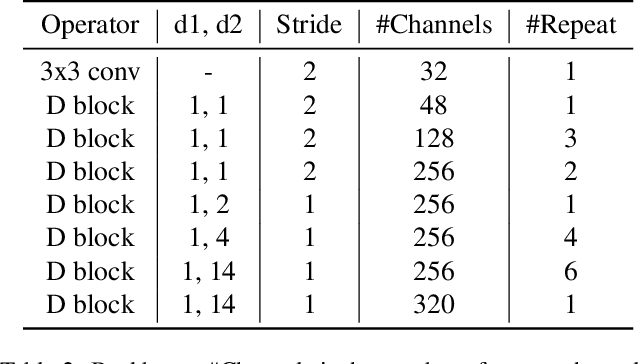
Recent advances in semantic segmentation generally adapt an ImageNet pretrained backbone with a special context module after it to quickly increase the field-of-view. Although successful, the backbone, in which most of the computation lies, does not have a large enough field-of-view to make the best decisions. Some recent advances tackle this problem by rapidly downsampling the resolution in the backbone while also having one or more parallel branches with higher resolutions. We take a different approach by designing a ResNeXt inspired block structure that uses two parallel 3x3 convolutional layers with different dilation rates to increase the field-of-view while also preserving the local details. By repeating this block structure in the backbone, we do not need to append any special context module after it. In addition, we propose a lightweight decoder that restores local information better than common alternatives. To demonstrate the effectiveness of our approach, our model RegSeg achieves state-of-the-art results on real-time Cityscapes and CamVid datasets. Using a T4 GPU with mixed precision, RegSeg achieves 78.3 mIOU on Cityscapes test set at 30 FPS, and 80.9 mIOU on CamVid test set at 70 FPS, both without ImageNet pretraining.
Lookup or Exploratory: What is Your Search Intent?
Oct 09, 2021
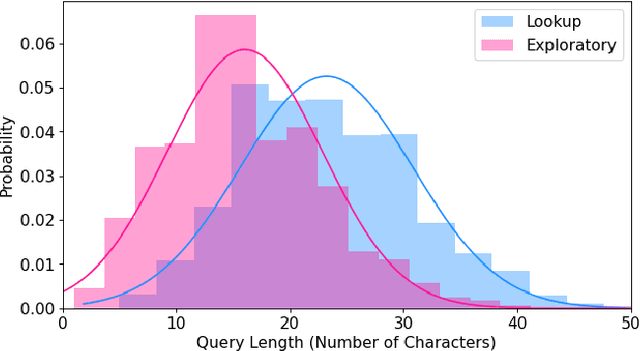
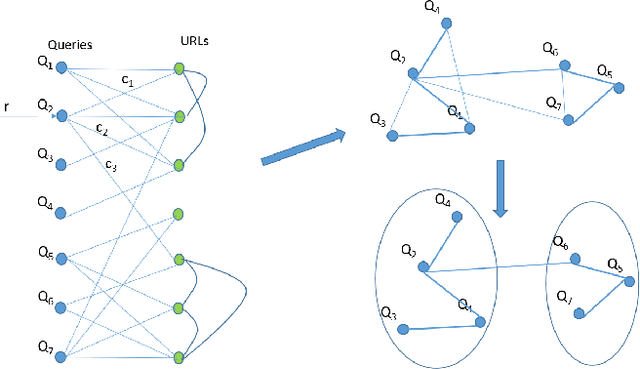

Search query specificity is broadly divided into two categories - Exploratory or Lookup. If a query specificity can be identified at the run time, it can be used to significantly improve the search results as well as quality of suggestions to alter the query. However, with millions of queries coming every day on a commercial search engine, it is non-trivial to develop a horizontal technique to determine query specificity at run time. Existing techniques suffer either from lack of enough training data or are dependent on information such as query length or session information. In this paper, we show that such methodologies are inadequate or at times misleading. We propose a novel methodology, to overcome these limitations. First, we demonstrate a heuristic-based method to identify Exploratory or Lookup intent queries at scale, classifying millions of queries into the two classes with a high accuracy, as shown in our experiments. Our methodology is not dependent on session data or on query length. Next, we train a transformer-based deep neural network to classify the queries into one of the two classes at run time. Our method uses a bidirectional GRU initialized with pretrained BERT-base-uncased embeddings and an augmented triplet loss to classify the intent of queries without using any session data. We also introduce a novel Semi-Greedy Iterative Training approach to fine-tune our model. Our model is deployable for real time query specificity identification with response time of less than one millisecond. Our technique is generic, and the results have valuable implications for improving the quality of search results and suggestions.
Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection
Dec 09, 2021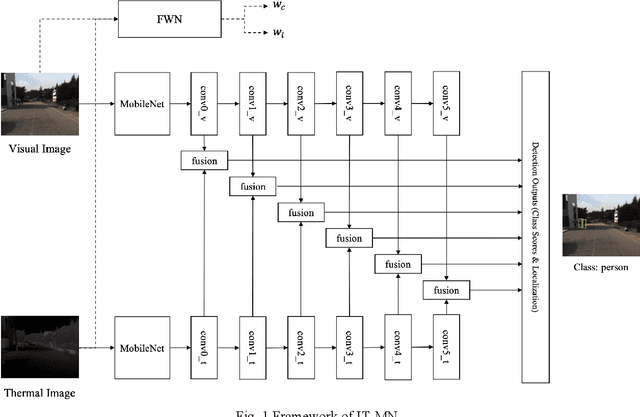
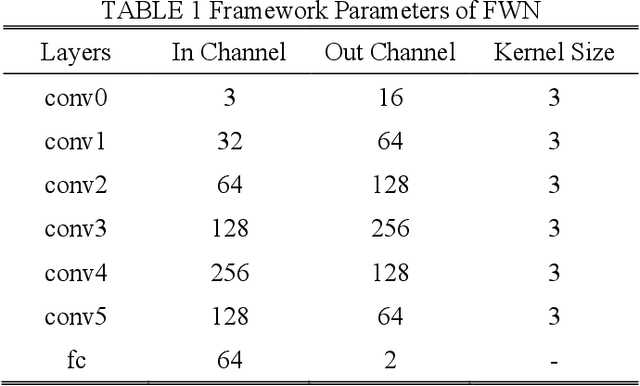
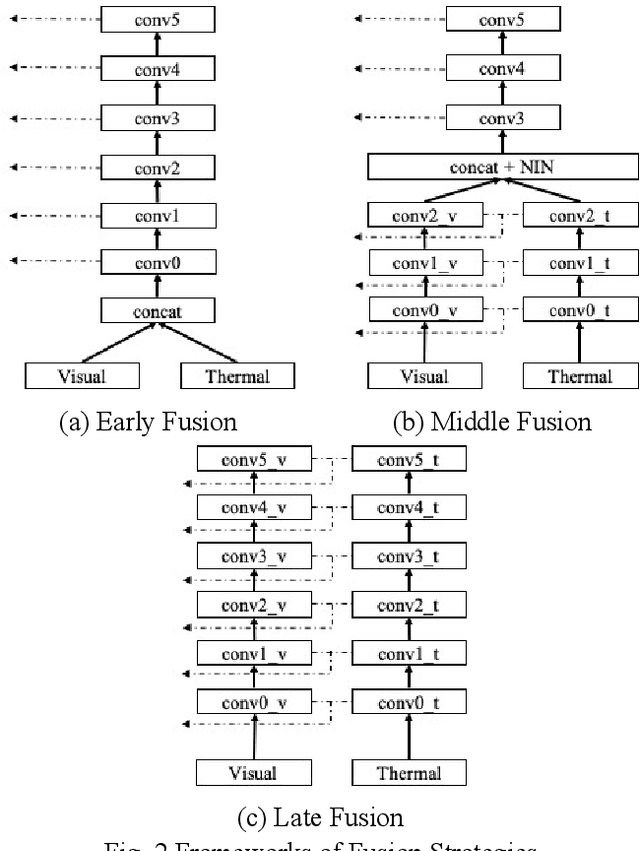
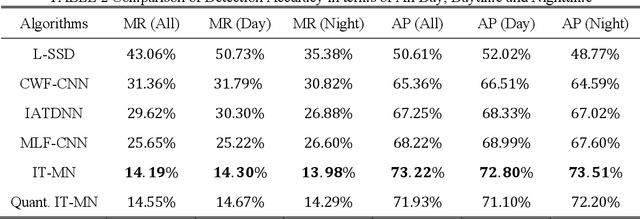
Accurate and efficient pedestrian detection is crucial for the intelligent transportation system regarding pedestrian safety and mobility, e.g., Advanced Driver Assistance Systems, and smart pedestrian crosswalk systems. Among all pedestrian detection methods, vision-based detection method is demonstrated to be the most effective in previous studies. However, the existing vision-based pedestrian detection algorithms still have two limitations that restrict their implementations, those being real-time performance as well as the resistance to the impacts of environmental factors, e.g., low illumination conditions. To address these issues, this study proposes a lightweight Illumination and Temperature-aware Multispectral Network (IT-MN) for accurate and efficient pedestrian detection. The proposed IT-MN is an efficient one-stage detector. For accommodating the impacts of environmental factors and enhancing the sensing accuracy, thermal image data is fused by the proposed IT-MN with visual images to enrich useful information when visual image quality is limited. In addition, an innovative and effective late fusion strategy is also developed to optimize the image fusion performance. To make the proposed model implementable for edge computing, the model quantization is applied to reduce the model size by 75% while shortening the inference time significantly. The proposed algorithm is evaluated by comparing with the selected state-of-the-art algorithms using a public dataset collected by in-vehicle cameras. The results show that the proposed algorithm achieves a low miss rate and inference time at 14.19% and 0.03 seconds per image pair on GPU. Besides, the quantized IT-MN achieves an inference time of 0.21 seconds per image pair on the edge device, which also demonstrates the potentiality of deploying the proposed model on edge devices as a highly efficient pedestrian detection algorithm.
Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
May 09, 2019
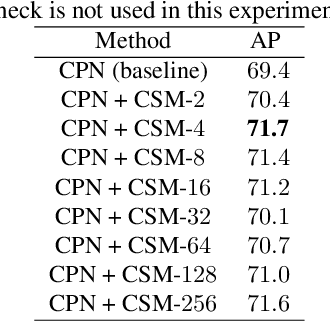
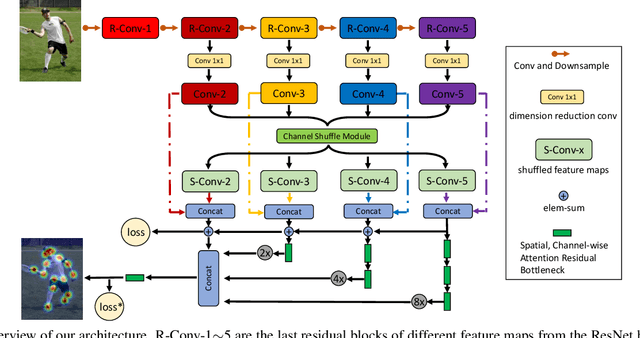
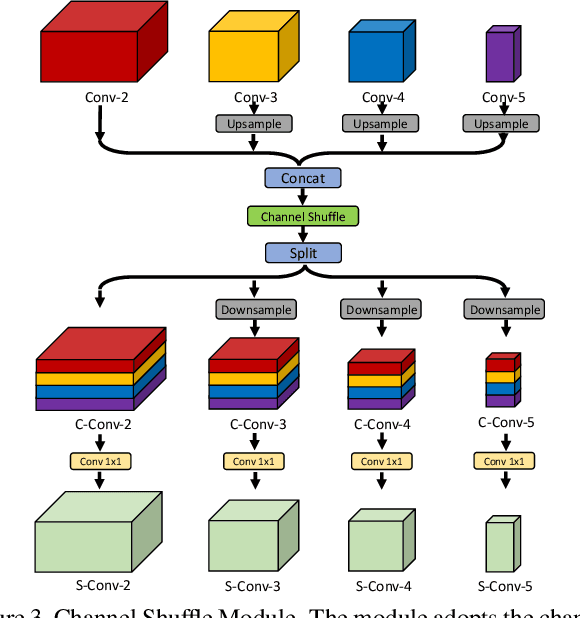
Multi-person pose estimation is an important but challenging problem in computer vision. Although current approaches have achieved significant progress by fusing the multi-scale feature maps, they pay little attention to enhancing the channel-wise and spatial information of the feature maps. In this paper, we propose two novel modules to perform the enhancement of the information for the multi-person pose estimation. First, a Channel Shuffle Module (CSM) is proposed to adopt the channel shuffle operation on the feature maps with different levels, promoting cross-channel information communication among the pyramid feature maps. Second, a Spatial, Channel-wise Attention Residual Bottleneck (SCARB) is designed to boost the original residual unit with attention mechanism, adaptively highlighting the information of the feature maps both in the spatial and channel-wise context. The effectiveness of our proposed modules is evaluated on the COCO keypoint benchmark, and experimental results show that our approach achieves the state-of-the-art results.
Multi-phase Liver Tumor Segmentation with Spatial Aggregation and Uncertain Region Inpainting
Aug 05, 2021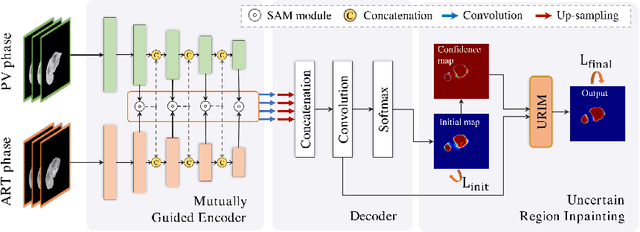
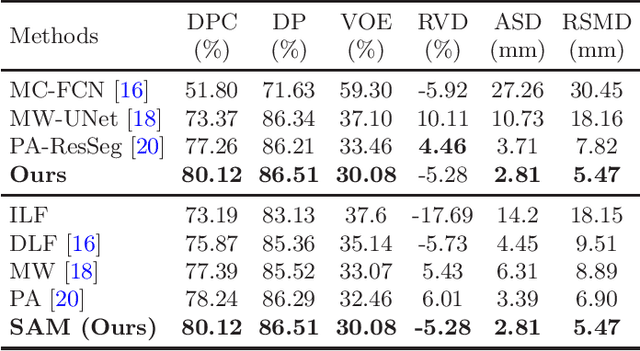
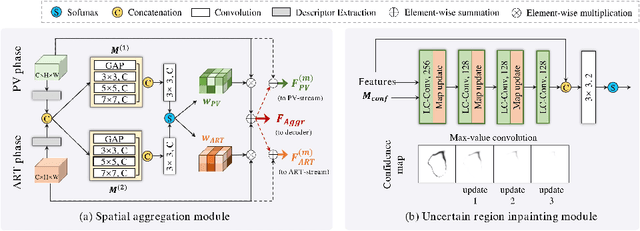
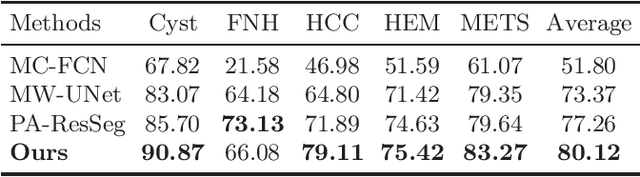
Multi-phase computed tomography (CT) images provide crucial complementary information for accurate liver tumor segmentation (LiTS). State-of-the-art multi-phase LiTS methods usually fused cross-phase features through phase-weighted summation or channel-attention based concatenation. However, these methods ignored the spatial (pixel-wise) relationships between different phases, hence leading to insufficient feature integration. In addition, the performance of existing methods remains subject to the uncertainty in segmentation, which is particularly acute in tumor boundary regions. In this work, we propose a novel LiTS method to adequately aggregate multi-phase information and refine uncertain region segmentation. To this end, we introduce a spatial aggregation module (SAM), which encourages per-pixel interactions between different phases, to make full use of cross-phase information. Moreover, we devise an uncertain region inpainting module (URIM) to refine uncertain pixels using neighboring discriminative features. Experiments on an in-house multi-phase CT dataset of focal liver lesions (MPCT-FLLs) demonstrate that our method achieves promising liver tumor segmentation and outperforms state-of-the-arts.
AASeg: Attention Aware Network for Real Time Semantic Segmentation
Aug 11, 2021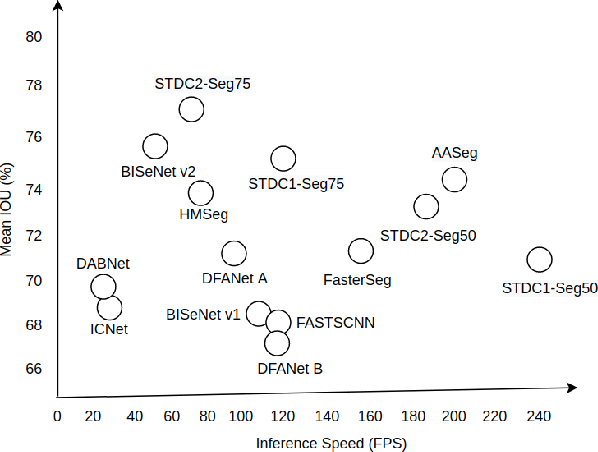
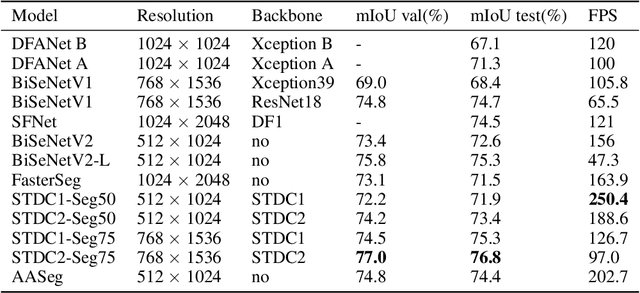
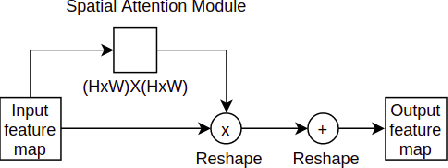
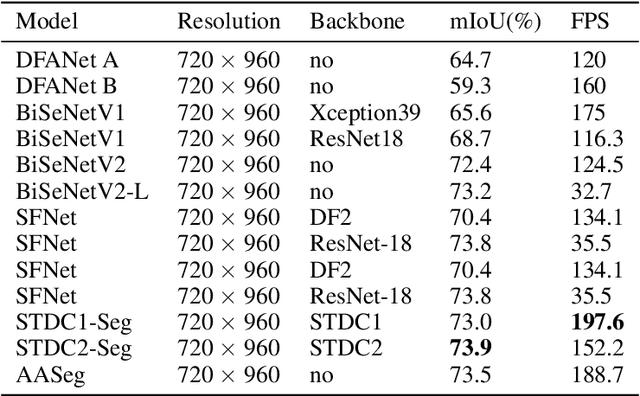
In this paper, we present a new network named Attention Aware Network (AASeg) for real time semantic image segmentation. Our network incorporates spatial and channel information using Spatial Attention (SA) and Channel Attention (CA) modules respectively. It also uses dense local multi-scale context information using Multi Scale Context (MSC) module. The feature maps are concatenated individually to produce the final segmentation map. We demonstrate the effectiveness of our method using a comprehensive analysis, quantitative experimental results and ablation study using Cityscapes, ADE20K and Camvid datasets. Our network performs better than most previous architectures with a 74.4\% Mean IOU on Cityscapes test dataset while running at 202.7 FPS.
Automated volumetric and statistical shape assessment of cam-type morphology of the femoral head-neck region from 3D magnetic resonance images
Dec 06, 2021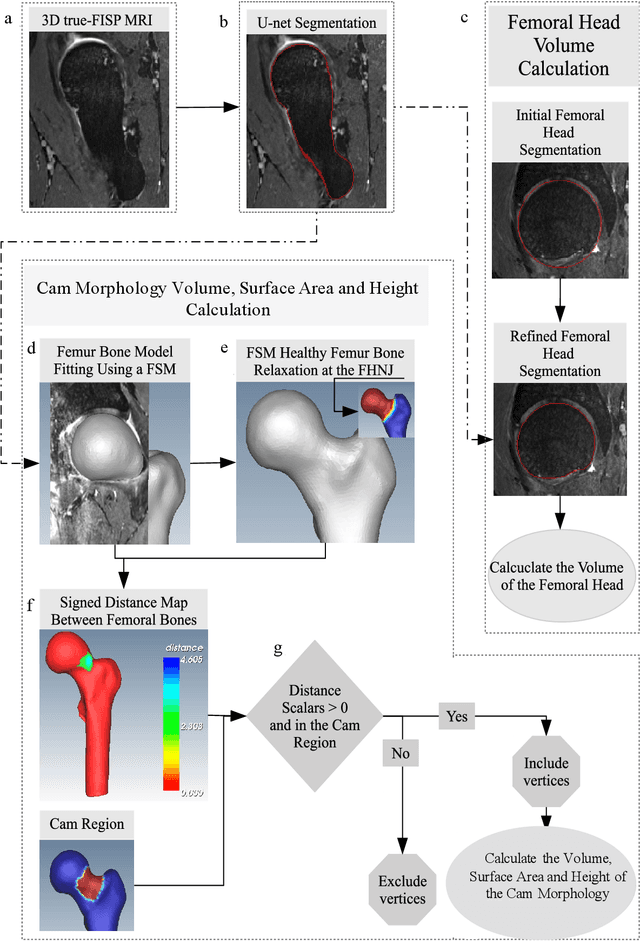
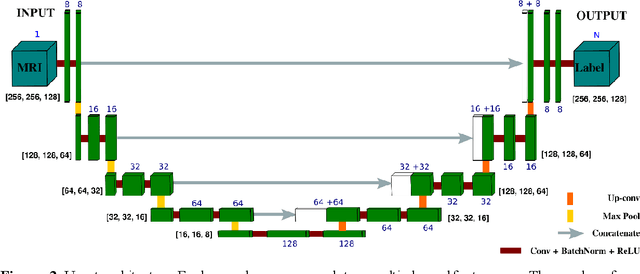

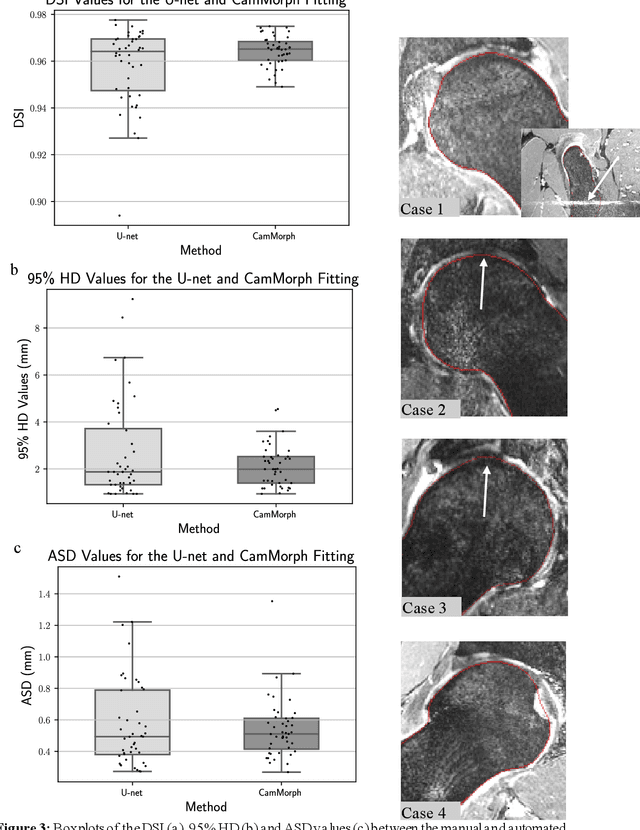
Femoroacetabular impingement (FAI) cam morphology is routinely assessed using two-dimensional alpha angles which do not provide specific data on cam size characteristics. The purpose of this study is to implement a novel, automated three-dimensional (3D) pipeline, CamMorph, for segmentation and measurement of cam volume, surface area and height from magnetic resonance (MR) images in patients with FAI. The CamMorph pipeline involves two processes: i) proximal femur segmentation using an approach integrating 3D U-net with focused shape modelling (FSM); ii) use of patient-specific anatomical information from 3D FSM to simulate healthy femoral bone models and pathological region constraints to identify cam bone mass. Agreement between manual and automated segmentation of the proximal femur was evaluated with the Dice similarity index (DSI) and surface distance measures. Independent t-tests or Mann-Whitney U rank tests were used to compare the femoral head volume, cam volume, surface area and height data between female and male patients with FAI. There was a mean DSI value of 0.964 between manual and automated segmentation of proximal femur volume. Compared to female FAI patients, male patients had a significantly larger mean femoral head volume (66.12cm3 v 46.02cm3, p<0.001). Compared to female FAI patients, male patients had a significantly larger mean cam volume (1136.87mm3 v 337.86mm3, p<0.001), surface area (657.36mm2 v 306.93mm2 , p<0.001), maximum-height (3.89mm v 2.23mm, p<0.001) and average-height (1.94mm v 1.00mm, p<0.001). Automated analyses of 3D MR images from patients with FAI using the CamMorph pipeline showed that, in comparison with female patients, male patients had significantly greater cam volume, surface area and height.
Emulation of physical processes with Emukit
Oct 25, 2021
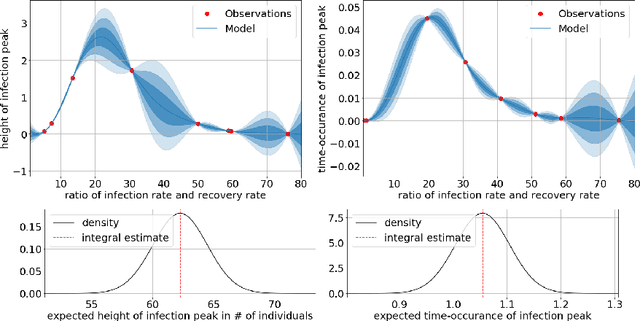
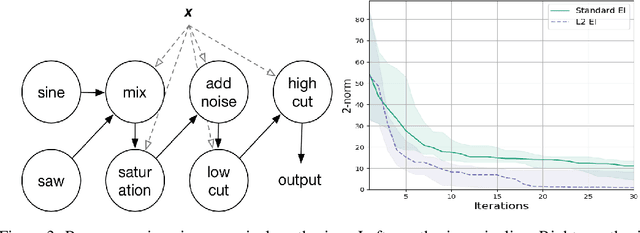
Decision making in uncertain scenarios is an ubiquitous challenge in real world systems. Tools to deal with this challenge include simulations to gather information and statistical emulation to quantify uncertainty. The machine learning community has developed a number of methods to facilitate decision making, but so far they are scattered in multiple different toolkits, and generally rely on a fixed backend. In this paper, we present Emukit, a highly adaptable Python toolkit for enriching decision making under uncertainty. Emukit allows users to: (i) use state of the art methods including Bayesian optimization, multi-fidelity emulation, experimental design, Bayesian quadrature and sensitivity analysis; (ii) easily prototype new decision making methods for new problems. Emukit is agnostic to the underlying modeling framework and enables users to use their own custom models. We show how Emukit can be used on three exemplary case studies.
Simultaneous Semantic and Collision Learning for 6-DoF Grasp Pose Estimation
Aug 05, 2021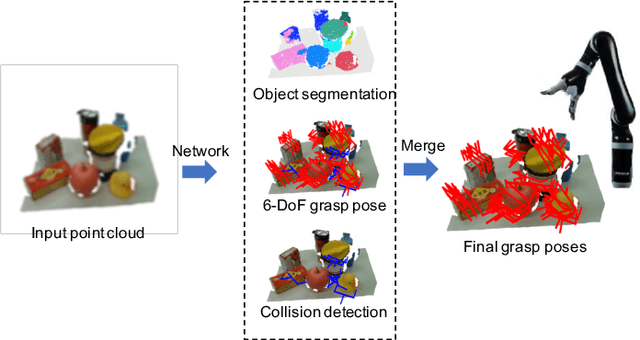
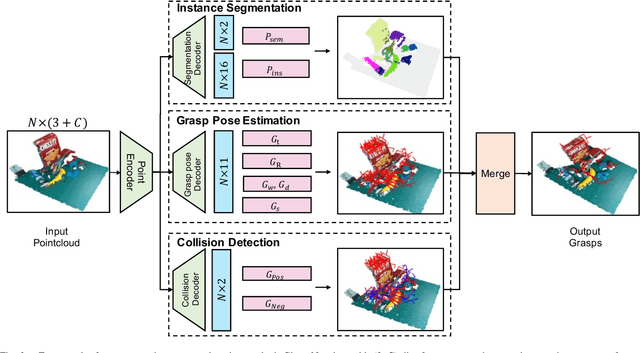
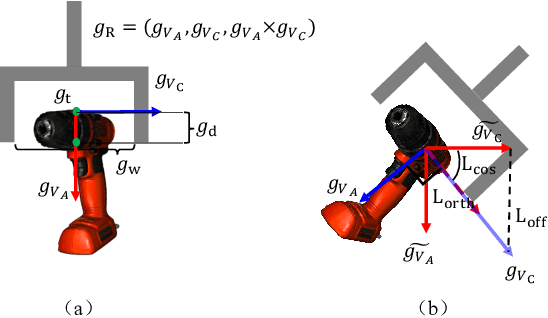

Grasping in cluttered scenes has always been a great challenge for robots, due to the requirement of the ability to well understand the scene and object information. Previous works usually assume that the geometry information of the objects is available, or utilize a step-wise, multi-stage strategy to predict the feasible 6-DoF grasp poses. In this work, we propose to formalize the 6-DoF grasp pose estimation as a simultaneous multi-task learning problem. In a unified framework, we jointly predict the feasible 6-DoF grasp poses, instance semantic segmentation, and collision information. The whole framework is jointly optimized and end-to-end differentiable. Our model is evaluated on large-scale benchmarks as well as the real robot system. On the public dataset, our method outperforms prior state-of-the-art methods by a large margin (+4.08 AP). We also demonstrate the implementation of our model on a real robotic platform and show that the robot can accurately grasp target objects in cluttered scenarios with a high success rate. Project link: https://openbyterobotics.github.io/sscl
Variable Augmented Network for Invertible Modality Synthesis-Fusion
Sep 02, 2021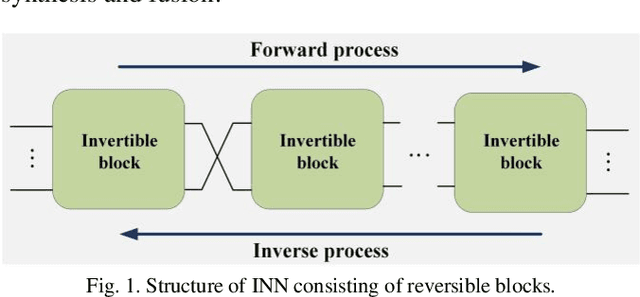
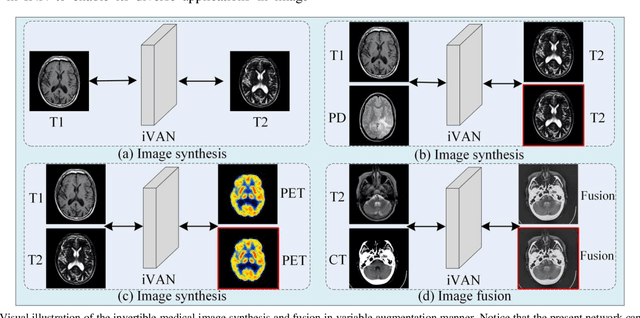
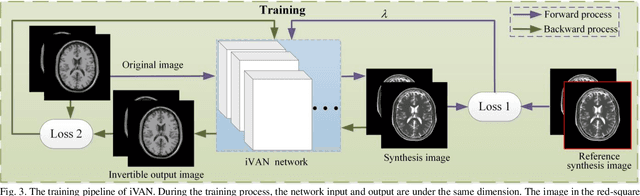
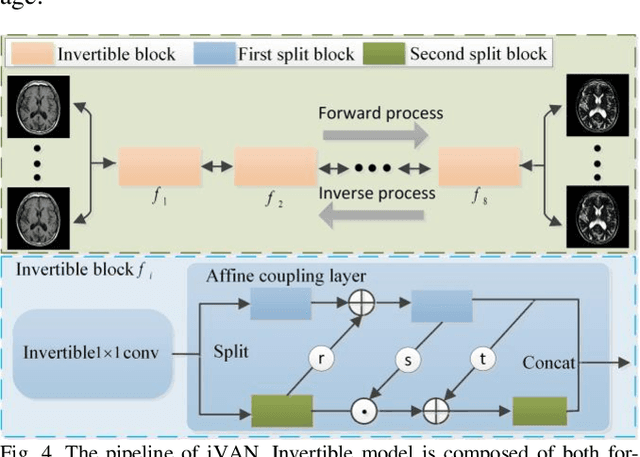
As an effective way to integrate the information contained in multiple medical images under different modalities, medical image synthesis and fusion have emerged in various clinical applications such as disease diagnosis and treatment planning. In this paper, an invertible and variable augmented network (iVAN) is proposed for medical image synthesis and fusion. In iVAN, the channel number of the network input and output is the same through variable augmentation technology, and data relevance is enhanced, which is conducive to the generation of characterization information. Meanwhile, the invertible network is used to achieve the bidirectional inference processes. Due to the invertible and variable augmentation schemes, iVAN can not only be applied to the mappings of multi-input to one-output and multi-input to multi-output, but also be applied to one-input to multi-output. Experimental results demonstrated that the proposed method can obtain competitive or superior performance in comparison to representative medical image synthesis and fusion methods.