 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An extended physics informed neural network for preliminary analysis of parametric optimal control problems
Oct 26, 2021
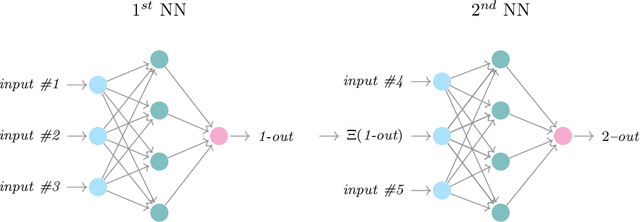
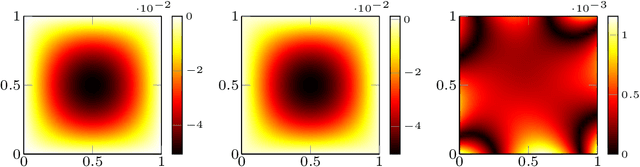
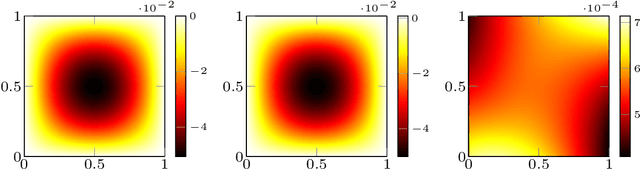
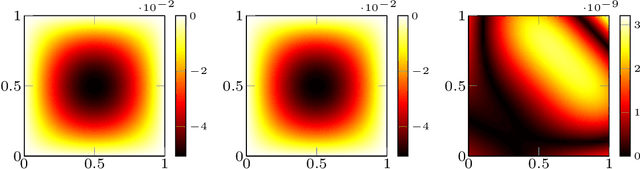
In this work we propose an extension of physics informed supervised learning strategies to parametric partial differential equations. Indeed, even if the latter are indisputably useful in many applications, they can be computationally expensive most of all in a real-time and many-query setting. Thus, our main goal is to provide a physics informed learning paradigm to simulate parametrized phenomena in a small amount of time. The physics information will be exploited in many ways, in the loss function (standard physics informed neural networks), as an augmented input (extra feature employment) and as a guideline to build an effective structure for the neural network (physics informed architecture). These three aspects, combined together, will lead to a faster training phase and to a more accurate parametric prediction. The methodology has been tested for several equations and also in an optimal control framework.
FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation
Oct 10, 2021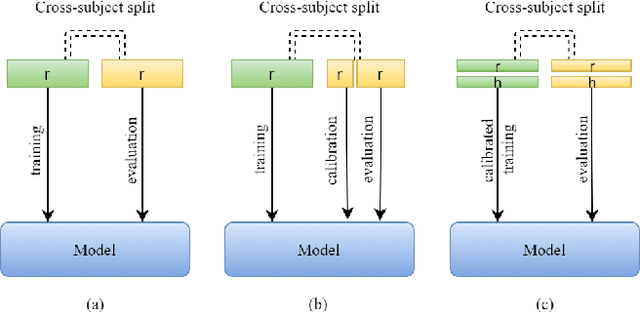

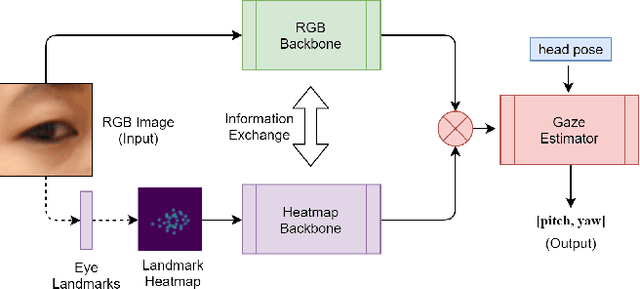
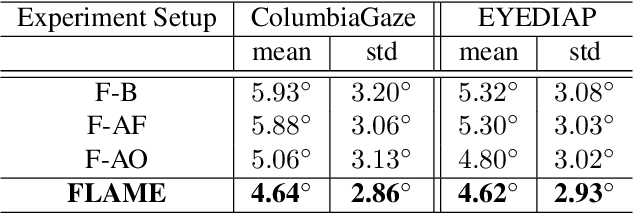
3D gaze estimation is about predicting the line of sight of a person in 3D space. Person-independent models for the same lack precision due to anatomical differences of subjects, whereas person-specific calibrated techniques add strict constraints on scalability. To overcome these issues, we propose a novel technique, Facial Landmark Heatmap Activated Multimodal Gaze Estimation (FLAME), as a way of combining eye anatomical information using eye landmark heatmaps to obtain precise gaze estimation without any person-specific calibration. Our evaluation demonstrates a competitive performance of about 10% improvement on benchmark datasets ColumbiaGaze and EYEDIAP. We also conduct an ablation study to validate our method.
Autonomous Robot Navigation with Rich Information Mapping in Nuclear Storage Environments
Apr 11, 2019

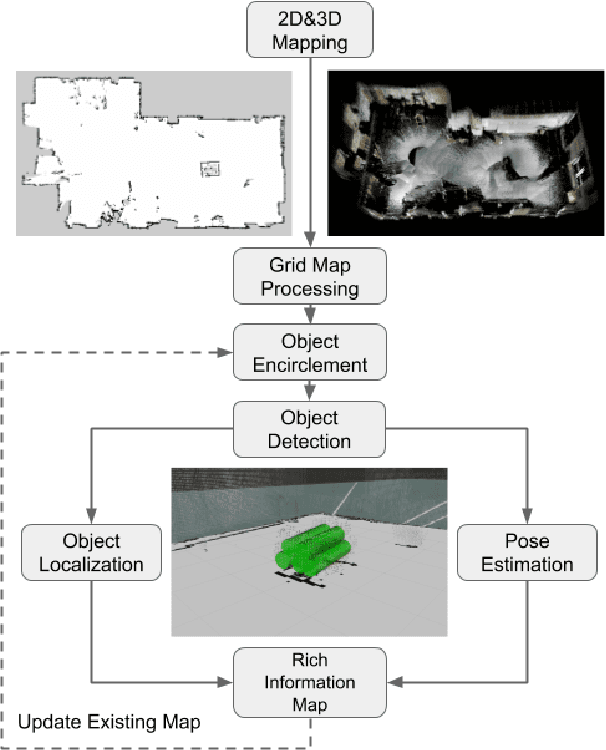
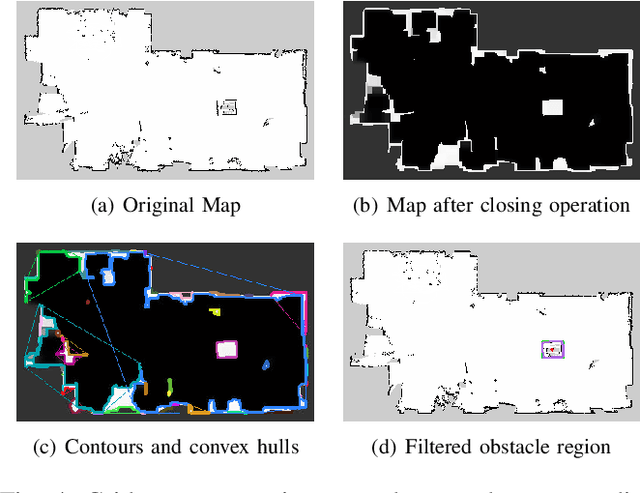
This paper presents our approach to develop a method for an unmanned ground vehicle (UGV) to perform inspection tasks in nuclear environments using rich information maps. To reduce inspectors' exposure to elevated radiation levels, an autonomous navigation framework for the UGV has been developed to perform routine inspections such as counting containers, recording their ID tags and performing gamma measurements on some of them. In order to achieve autonomy, a rich information map is generated which includes not only the 2D global cost map consisting of obstacle locations for path planning, but also the location and orientation information for the objects of interest from the inspector's perspective. The UGV's autonomy framework utilizes this information to prioritize locations to navigate to perform the inspections. In this paper, we present our method of generating this rich information map, originally developed to meet the requirements of the International Atomic Energy Agency (IAEA) Robotics Challenge. We demonstrate the performance of our method in a simulated testbed environment containing uranium hexafluoride (UF6) storage container mock ups.
Differentiable Tracking-Based Training of Deep Learning Sound Source Localizers
Oct 29, 2021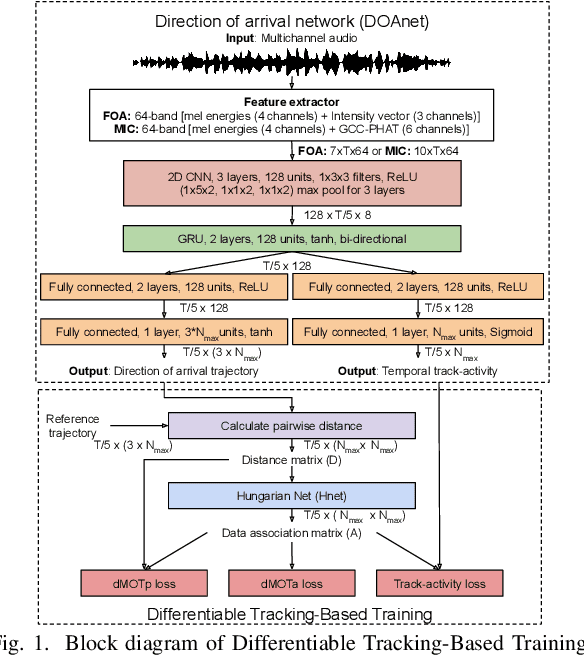
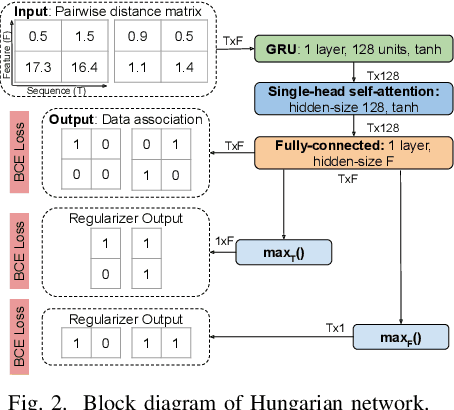
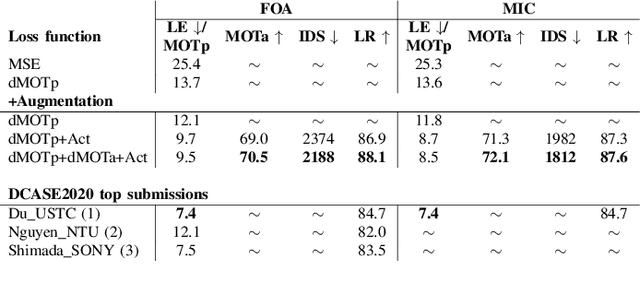
Data-based and learning-based sound source localization (SSL) has shown promising results in challenging conditions, and is commonly set as a classification or a regression problem. Regression-based approaches have certain advantages over classification-based, such as continuous direction-of-arrival estimation of static and moving sources. However, multi-source scenarios require multiple regressors without a clear training strategy up-to-date, that does not rely on auxiliary information such as simultaneous sound classification. We investigate end-to-end training of such methods with a technique recently proposed for video object detectors, adapted to the SSL setting. A differentiable network is constructed that can be plugged to the output of the localizer to solve the optimal assignment between predictions and references, optimizing directly the popular CLEAR-MOT tracking metrics. Results indicate large improvements over directly optimizing mean squared errors, in terms of localization error, detection metrics, and tracking capabilities.
Learning an Adaptive Meta Model-Generator for Incrementally Updating Recommender Systems
Nov 08, 2021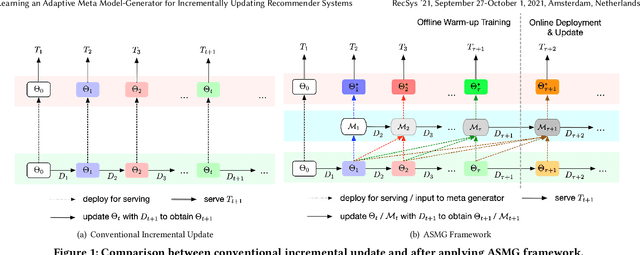
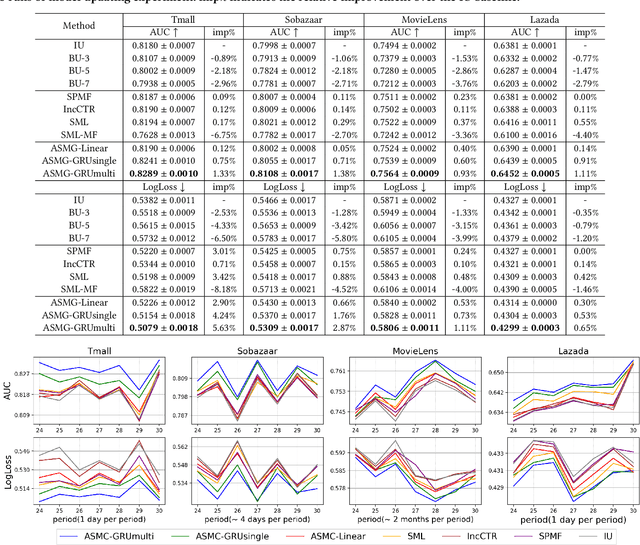
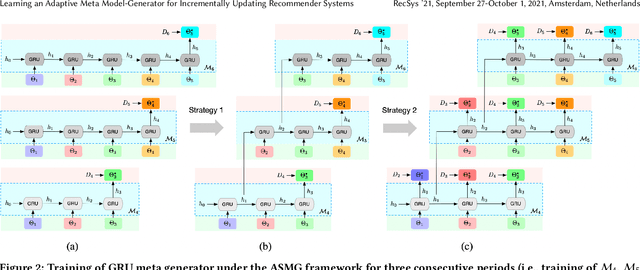
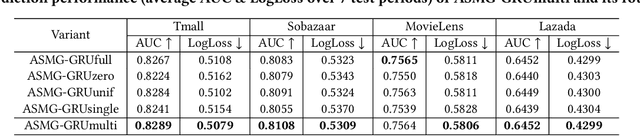
Recommender Systems (RSs) in real-world applications often deal with billions of user interactions daily. To capture the most recent trends effectively, it is common to update the model incrementally using only the newly arrived data. However, this may impede the model's ability to retain long-term information due to the potential overfitting and forgetting issues. To address this problem, we propose a novel Adaptive Sequential Model Generation (ASMG) framework, which generates a better serving model from a sequence of historical models via a meta generator. For the design of the meta generator, we propose to employ Gated Recurrent Units (GRUs) to leverage its ability to capture the long-term dependencies. We further introduce some novel strategies to apply together with the GRU meta generator, which not only improve its computational efficiency but also enable more accurate sequential modeling. By instantiating the model-agnostic framework on a general deep learning-based RS model, we demonstrate that our method achieves state-of-the-art performance on three public datasets and one industrial dataset.
FIBA: Frequency-Injection based Backdoor Attack in Medical Image Analysis
Dec 02, 2021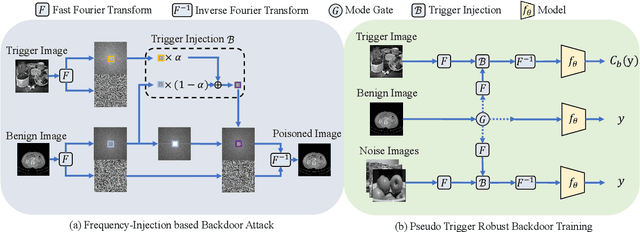
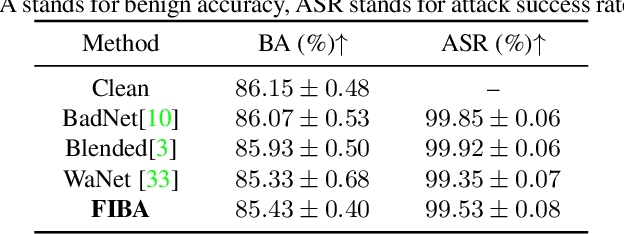
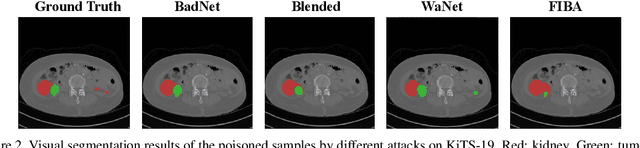

In recent years, the security of AI systems has drawn increasing research attention, especially in the medical imaging realm. To develop a secure medical image analysis (MIA) system, it is a must to study possible backdoor attacks (BAs), which can embed hidden malicious behaviors into the system. However, designing a unified BA method that can be applied to various MIA systems is challenging due to the diversity of imaging modalities (e.g., X-Ray, CT, and MRI) and analysis tasks (e.g., classification, detection, and segmentation). Most existing BA methods are designed to attack natural image classification models, which apply spatial triggers to training images and inevitably corrupt the semantics of poisoned pixels, leading to the failures of attacking dense prediction models. To address this issue, we propose a novel Frequency-Injection based Backdoor Attack method (FIBA) that is capable of delivering attacks in various MIA tasks. Specifically, FIBA leverages a trigger function in the frequency domain that can inject the low-frequency information of a trigger image into the poisoned image by linearly combining the spectral amplitude of both images. Since it preserves the semantics of the poisoned image pixels, FIBA can perform attacks on both classification and dense prediction models. Experiments on three benchmarks in MIA (i.e., ISIC-2019 for skin lesion classification, KiTS-19 for kidney tumor segmentation, and EAD-2019 for endoscopic artifact detection), validate the effectiveness of FIBA and its superiority over state-of-the-art methods in attacking MIA models as well as bypassing backdoor defense. The code will be available at https://github.com/HazardFY/FIBA.
Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
May 09, 2019
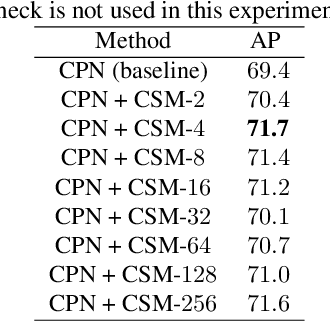
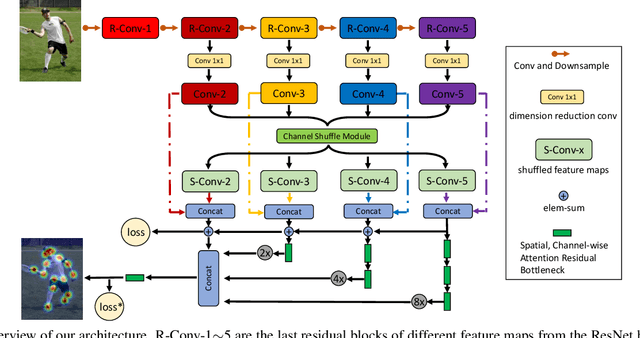
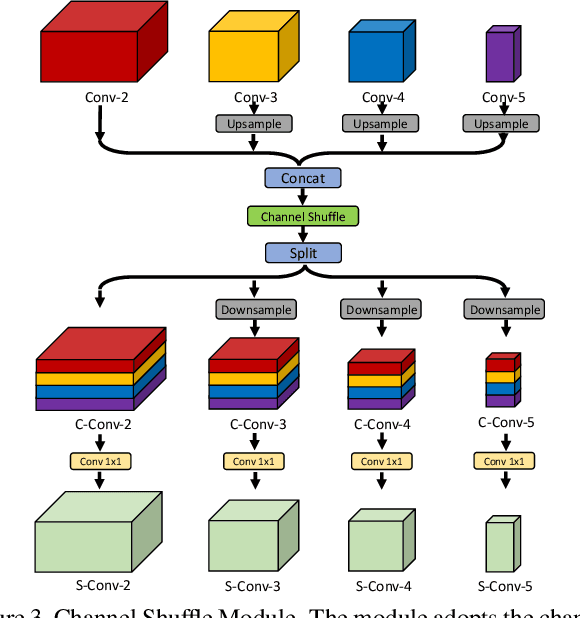
Multi-person pose estimation is an important but challenging problem in computer vision. Although current approaches have achieved significant progress by fusing the multi-scale feature maps, they pay little attention to enhancing the channel-wise and spatial information of the feature maps. In this paper, we propose two novel modules to perform the enhancement of the information for the multi-person pose estimation. First, a Channel Shuffle Module (CSM) is proposed to adopt the channel shuffle operation on the feature maps with different levels, promoting cross-channel information communication among the pyramid feature maps. Second, a Spatial, Channel-wise Attention Residual Bottleneck (SCARB) is designed to boost the original residual unit with attention mechanism, adaptively highlighting the information of the feature maps both in the spatial and channel-wise context. The effectiveness of our proposed modules is evaluated on the COCO keypoint benchmark, and experimental results show that our approach achieves the state-of-the-art results.
Temporal Clustering with External Memory Network for Disease Progression Modeling
Oct 09, 2021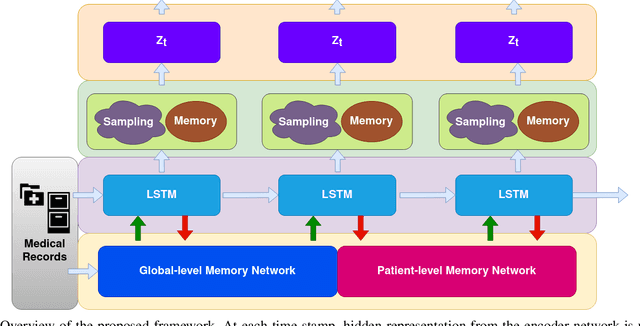
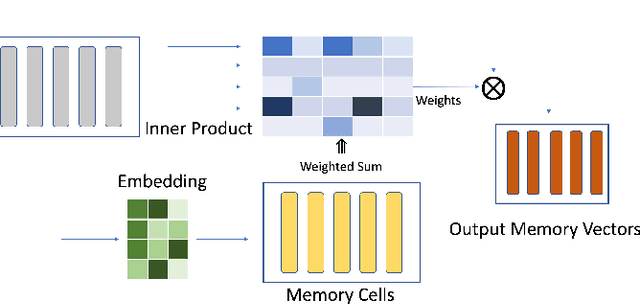
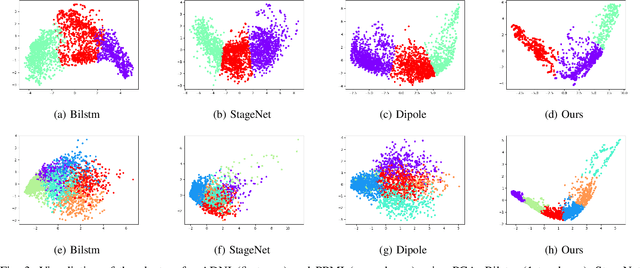
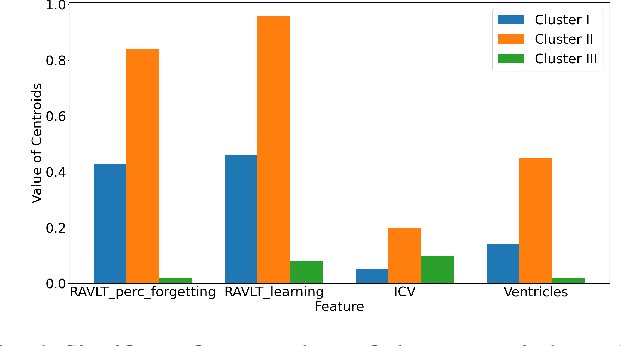
Disease progression modeling (DPM) involves using mathematical frameworks to quantitatively measure the severity of how certain disease progresses. DPM is useful in many ways such as predicting health state, categorizing disease stages, and assessing patients disease trajectory etc. Recently, with wider availability of electronic health records (EHR) and the broad application of data-driven machine learning method, DPM has attracted much attention yet remains two major challenges: (i) Due to the existence of irregularity, heterogeneity and long-term dependency in EHRs, most existing DPM methods might not be able to provide comprehensive patient representations. (ii) Lots of records in EHRs might be irrelevant to the target disease. Most existing models learn to automatically focus on the relevant information instead of explicitly capture the target-relevant events, which might make the learned model suboptimal. To address these two issues, we propose Temporal Clustering with External Memory Network (TC-EMNet) for DPM that groups patients with similar trajectories to form disease clusters/stages. TC-EMNet uses a variational autoencoder (VAE) to capture internal complexity from the input data and utilizes an external memory work to capture long term distance information, both of which are helpful for producing comprehensive patient states. Last but not least, k-means algorithm is adopted to cluster the extracted comprehensive patient states to capture disease progression. Experiments on two real-world datasets show that our model demonstrates competitive clustering performance against state-of-the-art methods and is able to identify clinically meaningful clusters. The visualization of the extracted patient states shows that the proposed model can generate better patient states than the baselines.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.
Contrastive Adaptive Propagation Graph Neural Networks for Efficient Graph Learning
Dec 02, 2021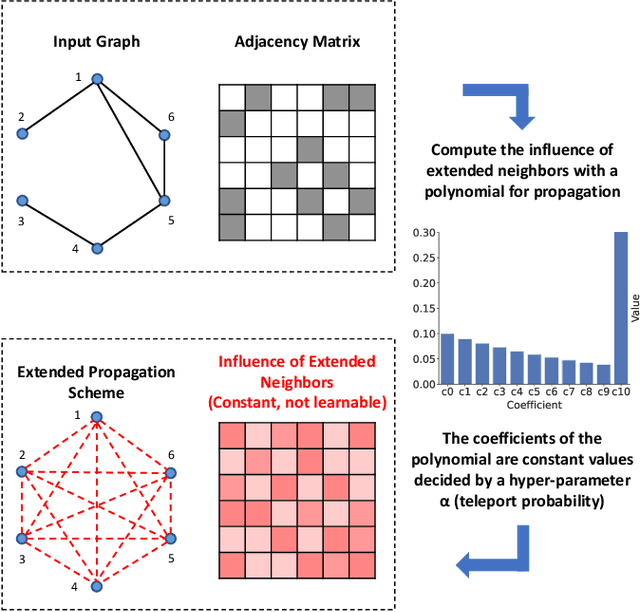
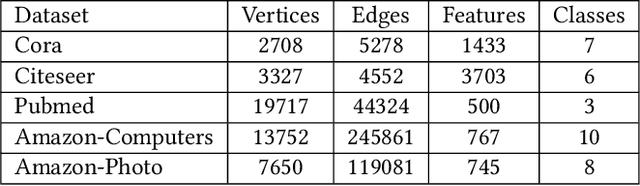
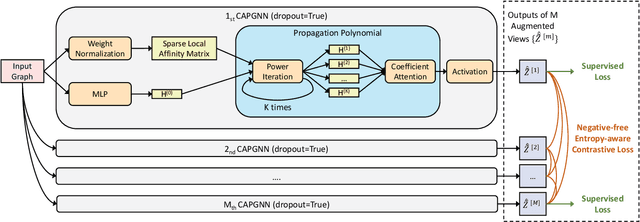

Graph Neural Networks (GNNs) have achieved great success in processing graph data by extracting and propagating structure-aware features. Existing GNN research designs various propagation schemes to guide the aggregation of neighbor information. Recently the field has advanced from local propagation schemes that focus on local neighbors towards extended propagation schemes that can directly deal with extended neighbors consisting of both local and high-order neighbors. Despite the impressive performance, existing approaches are still insufficient to build an efficient and learnable extended propagation scheme that can adaptively adjust the influence of local and high-order neighbors. This paper proposes an efficient yet effective end-to-end framework, namely Contrastive Adaptive Propagation Graph Neural Networks (CAPGNN), to address these issues by combining Personalized PageRank and attention techniques. CAPGNN models the learnable extended propagation scheme with a polynomial of a sparse local affinity matrix, where the polynomial relies on Personalized PageRank to provide superior initial coefficients. In order to adaptively adjust the influence of both local and high-order neighbors, a coefficient-attention model is introduced to learn to adjust the coefficients of the polynomial. In addition, we leverage self-supervised learning techniques and design a negative-free entropy-aware contrastive loss to explicitly take advantage of unlabeled data for training. We implement CAPGNN as two different versions named CAPGCN and CAPGAT, which use static and dynamic sparse local affinity matrices, respectively. Experiments on graph benchmark datasets suggest that CAPGNN can consistently outperform or match state-of-the-art baselines. The source code is publicly available at https://github.com/hujunxianligong/CAPGNN.