 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mapping Vulnerable Populations with AI
Jul 29, 2021
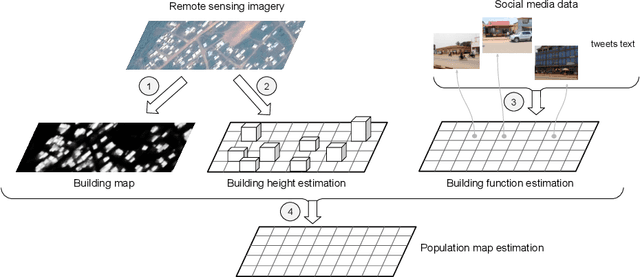


Humanitarian actions require accurate information to efficiently delegate support operations. Such information can be maps of building footprints, building functions, and population densities. While the access to this information is comparably easy in industrialized countries thanks to reliable census data and national geo-data infrastructures, this is not the case for developing countries, where that data is often incomplete or outdated. Building maps derived from remote sensing images may partially remedy this challenge in such countries, but are not always accurate due to different landscape configurations and lack of validation data. Even when they exist, building footprint layers usually do not reveal more fine-grained building properties, such as the number of stories or the building's function (e.g., office, residential, school, etc.). In this project we aim to automate building footprint and function mapping using heterogeneous data sources. In a first step, we intend to delineate buildings from satellite data, using deep learning models for semantic image segmentation. Building functions shall be retrieved by parsing social media data like for instance tweets, as well as ground-based imagery, to automatically identify different buildings functions and retrieve further information such as the number of building stories. Building maps augmented with those additional attributes make it possible to derive more accurate population density maps, needed to support the targeted provision of humanitarian aid.
AEDA: An Easier Data Augmentation Technique for Text Classification
Aug 30, 2021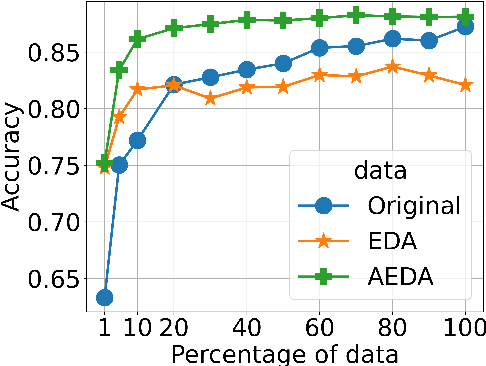
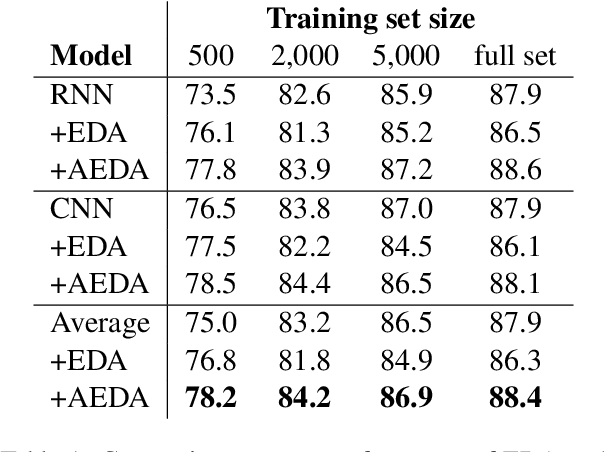

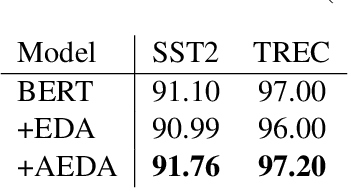
This paper proposes AEDA (An Easier Data Augmentation) technique to help improve the performance on text classification tasks. AEDA includes only random insertion of punctuation marks into the original text. This is an easier technique to implement for data augmentation than EDA method (Wei and Zou, 2019) with which we compare our results. In addition, it keeps the order of the words while changing their positions in the sentence leading to a better generalized performance. Furthermore, the deletion operation in EDA can cause loss of information which, in turn, misleads the network, whereas AEDA preserves all the input information. Following the baseline, we perform experiments on five different datasets for text classification. We show that using the AEDA-augmented data for training, the models show superior performance compared to using the EDA-augmented data in all five datasets. The source code is available for further study and reproduction of the results.
Online Search With Best-Price and Query-Based Predictions
Dec 02, 2021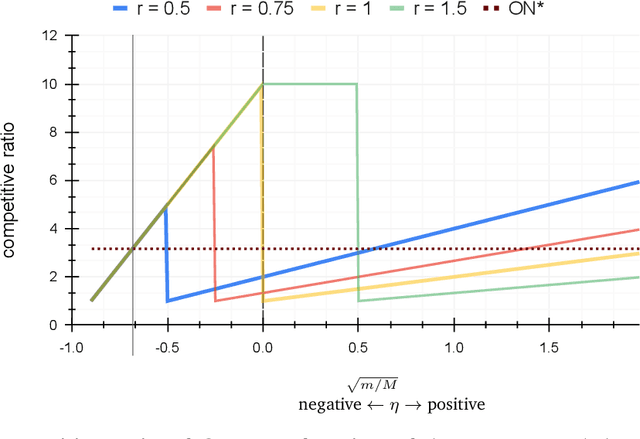
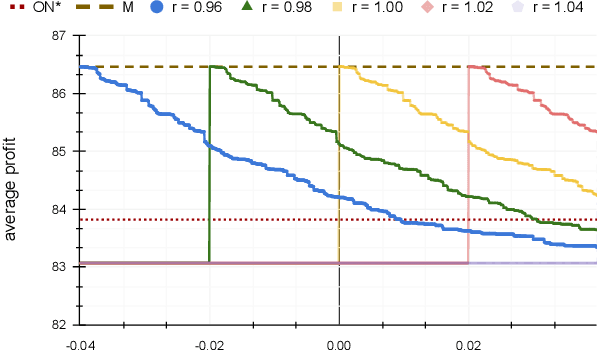
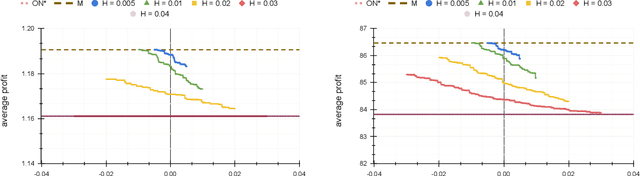
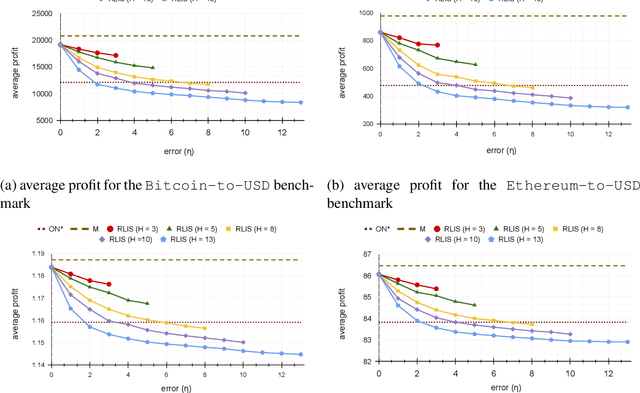
In the online (time-series) search problem, a player is presented with a sequence of prices which are revealed in an online manner. In the standard definition of the problem, for each revealed price, the player must decide irrevocably whether to accept or reject it, without knowledge of future prices (other than an upper and a lower bound on their extreme values), and the objective is to minimize the competitive ratio, namely the worst-case ratio between the maximum price in the sequence and the one selected by the player. The problem formulates several applications of decision-making in the face of uncertainty on the revealed samples. Previous work on this problem has largely assumed extreme scenarios in which either the player has almost no information about the input, or the player is provided with some powerful, and error-free advice. In this work, we study learning-augmented algorithms, in which there is a potentially erroneous prediction concerning the input. Specifically, we consider two different settings: the setting in which the prediction is related to the maximum price in the sequence, as well as the setting in which the prediction is obtained as a response to a number of binary queries. For both settings, we provide tight, or near-tight upper and lower bounds on the worst-case performance of search algorithms as a function of the prediction error. We also provide experimental results on data obtained from stock exchange markets that confirm the theoretical analysis, and explain how our techniques can be applicable to other learning-augmented applications.
Belief propagation for permutations, rankings, and partial orders
Oct 01, 2021
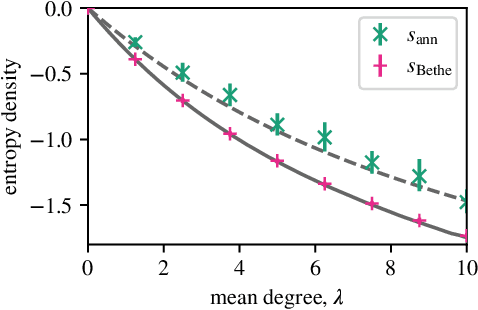
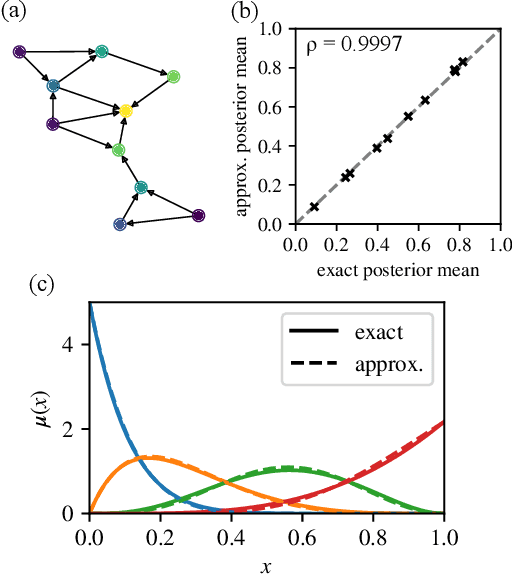
Many datasets give partial information about an ordering or ranking by indicating which team won a game, which item a user prefers, or who infected whom. We define a continuous spin system whose Gibbs distribution is the posterior distribution on permutations, given a probabilistic model of these interactions. Using the cavity method we derive a belief propagation algorithm that computes the marginal distribution of each node's position. In addition, the Bethe free energy lets us approximate the number of linear extensions of a partial order and perform model selection.
Hydroclimatic time series features at multiple time scales
Dec 02, 2021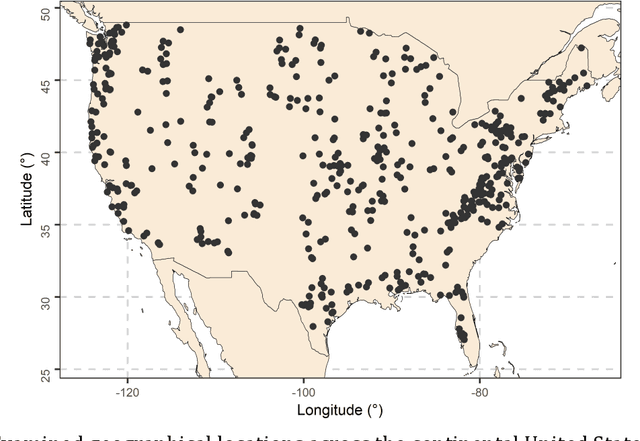
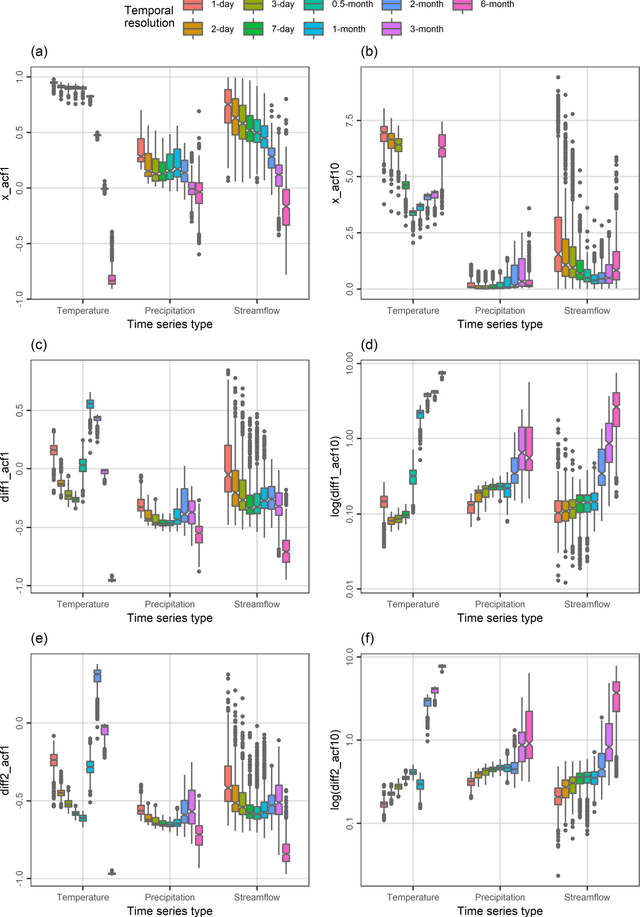
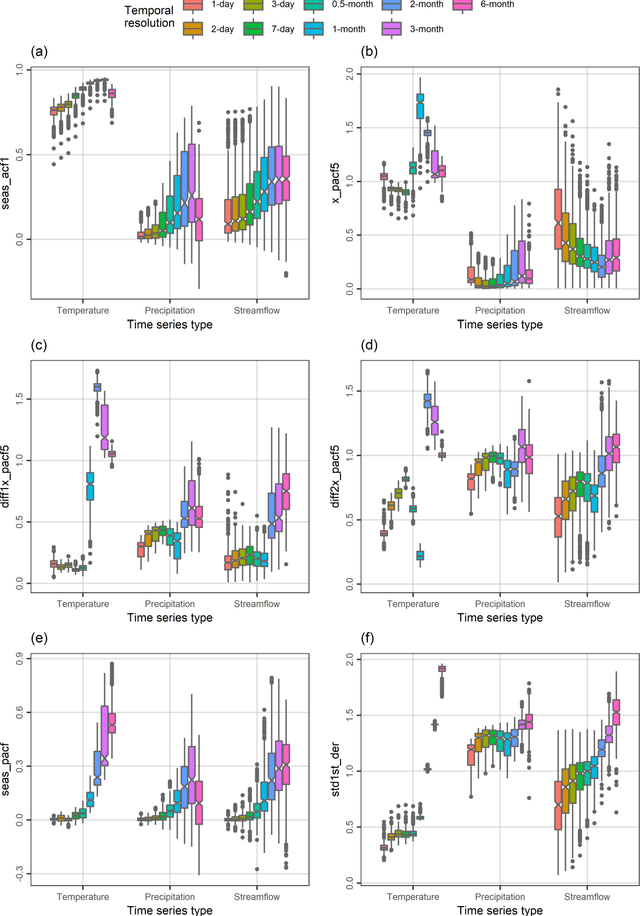
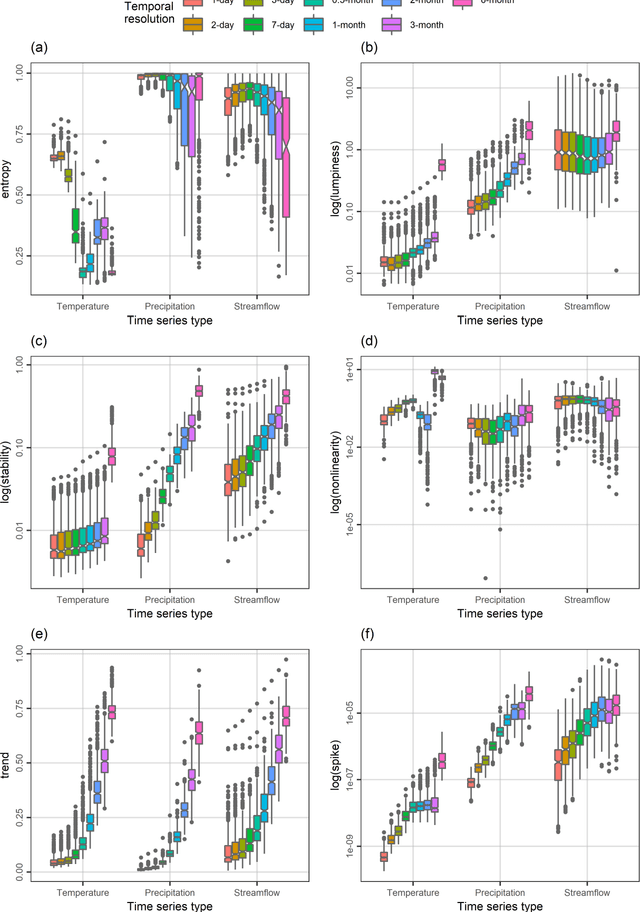
A comprehensive understanding of the behaviours of the various geophysical processes requires, among others, detailed investigations across temporal scales. In this work, we propose a new time series feature compilation for advancing and enriching such investigations in a hydroclimatic context. This specific compilation can facilitate largely interpretable feature investigations and comparisons in terms of temporal dependence, temporal variation, "forecastability", lumpiness, stability, nonlinearity (and linearity), trends, spikiness, curvature and seasonality. Detailed quantifications and multifaceted characterizations are herein obtained by computing the values of the proposed feature compilation across nine temporal resolutions (i.e., the 1-day, 2-day, 3-day, 7-day, 0.5-month, 1-month, 2-month, 3-month and 6-month ones) and three hydroclimatic time series types (i.e., temperature, precipitation and streamflow) for 34-year-long time series records originating from 511 geographical locations across the continental United States. Based on the acquired information and knowledge, similarities and differences between the examined time series types with respect to the evolution patterns characterizing their feature values with increasing (or decreasing) temporal resolution are identified. To our view, the similarities in these patterns are rather surprising. We also find that the spatial patterns emerging from feature-based time series clustering are largely analogous across temporal scales, and compare the features with respect to their usefulness in clustering the time series at the various temporal resolutions. For most of the features, this usefulness can vary to a notable degree across temporal resolutions and time series types, thereby pointing out the need for conducting multifaceted time series characterizations for the study of hydroclimatic similarity.
Beamforming using Digital Piezoelectric MEMS Microphone Array
Nov 19, 2021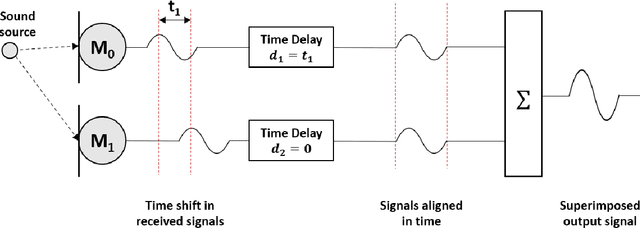
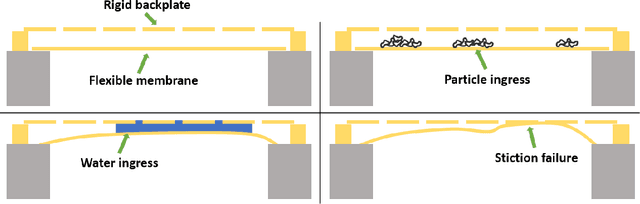
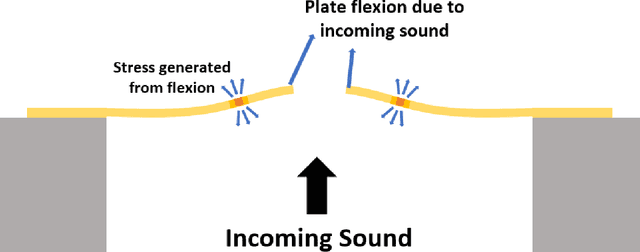
The recent explosion in low-cost, low-power wireless microcontrollers, coupled with low-power, robust MEMS sensors has opened up the opportunity to create new forms of low-cost Industrial Internet-of-Things (IIoT) devices for condition monitoring. Piezoelectric MEMS microphones constructed with a cantilever diaphragm are a potential solution against failure modes, such as water and dust ingress, that have challenged the use of capacitive MEMS microphones in industrial applications. In this paper, we couple a pair of piezoelectric MEMS microphones to a COTS microcontroller to create a stand-alone microphone array capable of discerning the direction of a noise source. The microphone array is designed to acquire sound data without aliasing at frequencies of 2000 Hz or below. Testing is conducted in an anechoic chamber. We compare the performance of this microphone array to a simple idealized theoretical model. The experimental results obtained in the anechoic chamber compare well with the theoretical model. The work stands as a proof-of-principle. By providing detailed information on how we coupled the sensors to a COTS microcontroller, and the open-source code used to process the data, we hope that others will be able to build upon this work by expanding on both the number and type of sensors used.
A Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021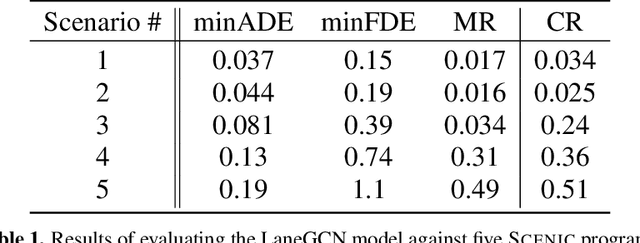

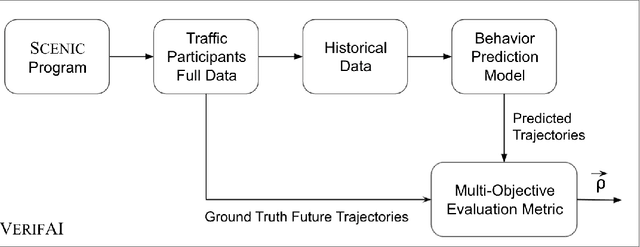
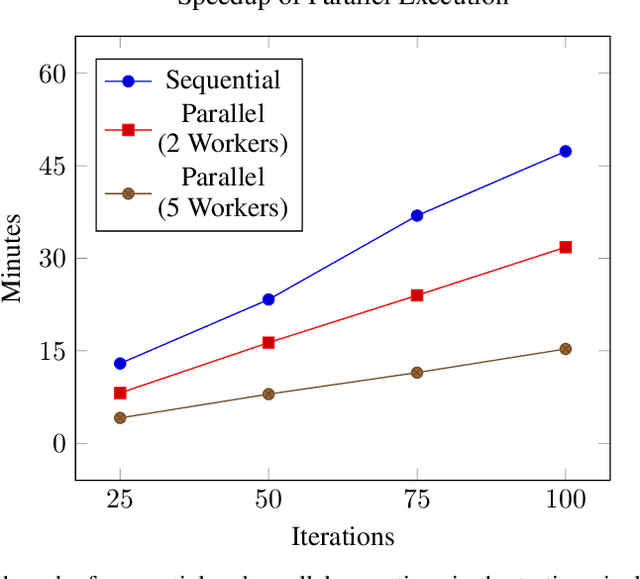
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
The ubiquitous digital file: A review of file management research
Sep 20, 2021Computer users spend time every day interacting with digital files and folders, including downloading, moving, naming, navigating to, searching for, sharing, and deleting them. Such file management has been the focus of many studies across various fields, but has not been explicitly acknowledged nor made the focus of dedicated review. In this article we present the first dedicated review of this topic and its research, synthesizing more than 230 publications from various research domains to establish what is known and what remains to be investigated, particularly by examining the common motivations, methods, and findings evinced by the previously furcate body of work. We find three typical research motivations in the literature reviewed: understanding how and why users store, organize, retrieve, and share files and folders, understanding factors that determine their behavior, and attempting to improve the user experience through novel interfaces and information services. Relevant conceptual frameworks and approaches to designing and testing systems are described, and open research challenges and the significance for other research areas are discussed. We conclude that file management is a ubiquitous, challenging, and relatively unsupported activity that invites and has received attention from several disciplines and has broad importance for topics across information science.
* Final version at https://doi.org/10.1002/asi.24222
BloomNet: A Robust Transformer based model for Bloom's Learning Outcome Classification
Aug 16, 2021
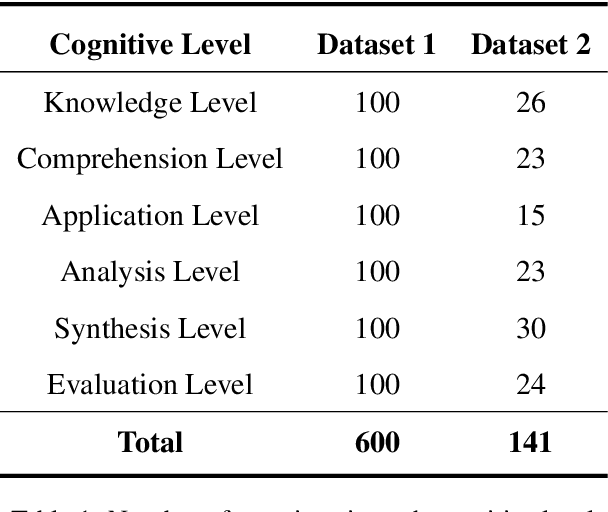
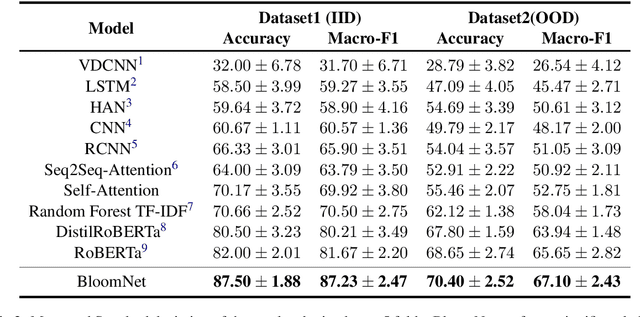
Bloom taxonomy is a common paradigm for categorizing educational learning objectives into three learning levels: cognitive, affective, and psychomotor. For the optimization of educational programs, it is crucial to design course learning outcomes (CLOs) according to the different cognitive levels of Bloom Taxonomy. Usually, administrators of the institutions manually complete the tedious work of mapping CLOs and examination questions to Bloom taxonomy levels. To address this issue, we propose a transformer-based model named BloomNet that captures linguistic as well semantic information to classify the course learning outcomes (CLOs). We compare BloomNet with a diverse set of basic as well as strong baselines and we observe that our model performs better than all the experimented baselines. Further, we also test the generalization capability of BloomNet by evaluating it on different distributions which our model does not encounter during training and we observe that our model is less susceptible to distribution shift compared to the other considered models. We support our findings by performing extensive result analysis. In ablation study we observe that on explicitly encapsulating the linguistic information along with semantic information improves the model on IID (independent and identically distributed) performance as well as OOD (out-of-distribution) generalization capability.
Autonomous Robot Navigation with Rich Information Mapping in Nuclear Storage Environments
Apr 11, 2019

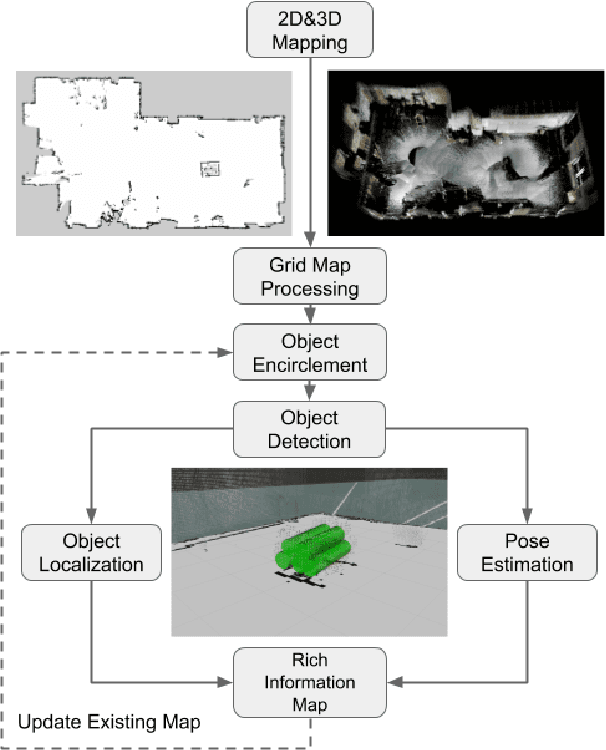
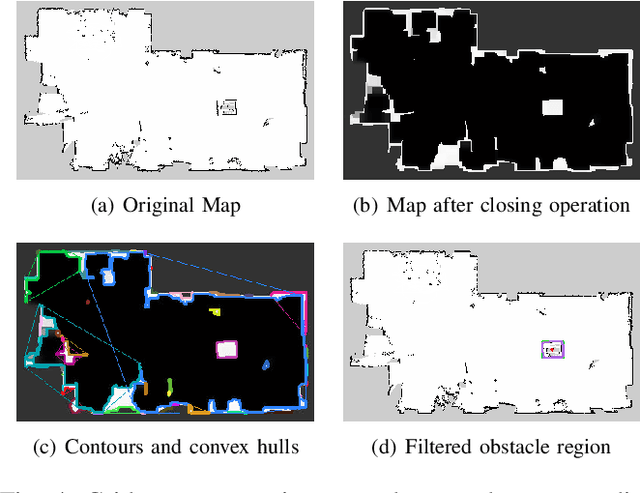
This paper presents our approach to develop a method for an unmanned ground vehicle (UGV) to perform inspection tasks in nuclear environments using rich information maps. To reduce inspectors' exposure to elevated radiation levels, an autonomous navigation framework for the UGV has been developed to perform routine inspections such as counting containers, recording their ID tags and performing gamma measurements on some of them. In order to achieve autonomy, a rich information map is generated which includes not only the 2D global cost map consisting of obstacle locations for path planning, but also the location and orientation information for the objects of interest from the inspector's perspective. The UGV's autonomy framework utilizes this information to prioritize locations to navigate to perform the inspections. In this paper, we present our method of generating this rich information map, originally developed to meet the requirements of the International Atomic Energy Agency (IAEA) Robotics Challenge. We demonstrate the performance of our method in a simulated testbed environment containing uranium hexafluoride (UF6) storage container mock ups.