 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GAP Enhancing Semantic Interoperability of Genomic Datasets and Provenance Through Nanopublications
Nov 18, 2021

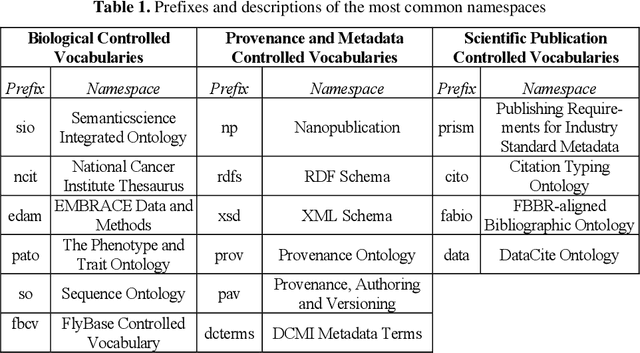
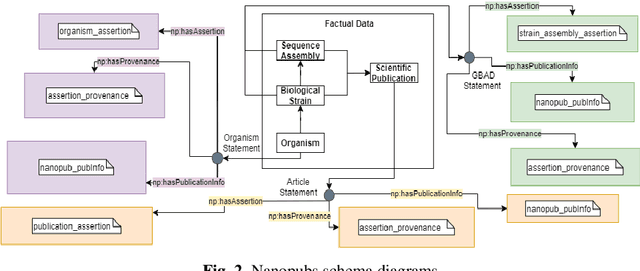

While the publication of datasets in scientific repositories has become broadly recognised, the repositories tend to have increasing semantic-related problems. For instance, they present various data reuse obstacles for machine-actionable processes, especially in biological repositories, hampering the reproducibility of scientific experiments. An example of these shortcomings is the GenBank database. We propose GAP, an innovative data model to enhance the semantic data meaning to address these issues. The model focuses on converging related approaches like data provenance, semantic interoperability, FAIR principles, and nanopublications. Our experiments include a prototype to scrape genomic data and trace them to nanopublications as a proof of concept. For this, (meta)data are stored in a three-level nanopub data model. The first level is related to a target organism, specifying data in terms of biological taxonomy. The second level focuses on the biological strains of the target, the central part of our contribution. The strains express information related to deciphered (meta)data of the genetic variations of the genomic material. The third level stores related scientific papers (meta)data. We expect it will offer higher data storage flexibility and more extensive interoperability with other data sources by incorporating and adopting associated approaches to store genomic data in the proposed model.
Neural Entropic Estimation: A faster path to mutual information estimation
May 31, 2019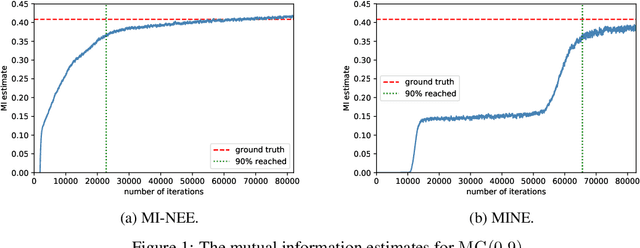
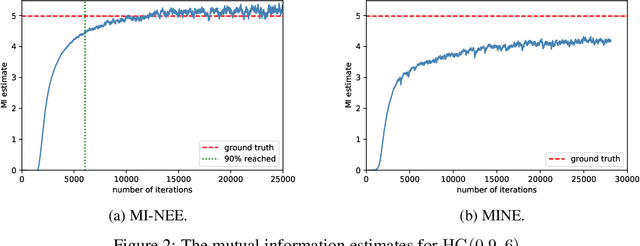
We point out a limitation of the mutual information neural estimation (MINE) where the network fails to learn at the initial training phase, leading to slow convergence in the number of training iterations. To solve this problem, we propose a faster method called the mutual information neural entropic estimation (MI-NEE). Our solution first generalizes MINE to estimate the entropy using a custom reference distribution. The entropy estimate can then be used to estimate the mutual information. We argue that the seemingly redundant intermediate step of entropy estimation allows one to improve the convergence by an appropriate reference distribution. In particular, we show that MI-NEE reduces to MINE in the special case when the reference distribution is the product of marginal distributions, but faster convergence is possible by choosing the uniform distribution as the reference distribution instead. Compared to the product of marginals, the uniform distribution introduces more samples in low-density regions and fewer samples in high-density regions, which appear to lead to an overall larger gradient for faster convergence.
High-order joint embedding for multi-level link prediction
Nov 07, 2021
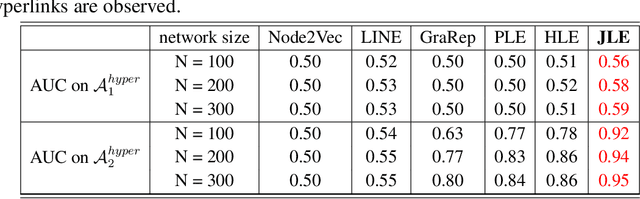
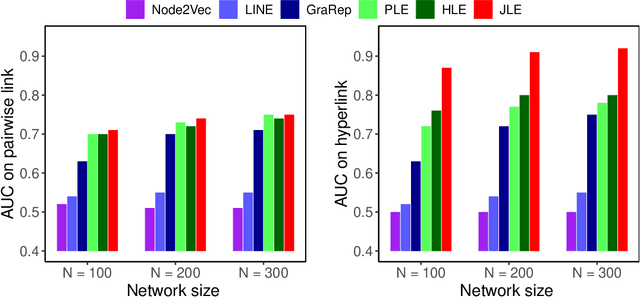
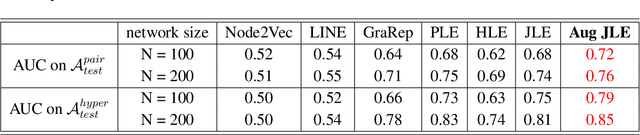
Link prediction infers potential links from observed networks, and is one of the essential problems in network analyses. In contrast to traditional graph representation modeling which only predicts two-way pairwise relations, we propose a novel tensor-based joint network embedding approach on simultaneously encoding pairwise links and hyperlinks onto a latent space, which captures the dependency between pairwise and multi-way links in inferring potential unobserved hyperlinks. The major advantage of the proposed embedding procedure is that it incorporates both the pairwise relationships and subgroup-wise structure among nodes to capture richer network information. In addition, the proposed method introduces a hierarchical dependency among links to infer potential hyperlinks, and leads to better link prediction. In theory we establish the estimation consistency for the proposed embedding approach, and provide a faster convergence rate compared to link prediction utilizing pairwise links or hyperlinks only. Numerical studies on both simulation settings and Facebook ego-networks indicate that the proposed method improves both hyperlink and pairwise link prediction accuracy compared to existing link prediction algorithms.
Spatial Aggregation and Temporal Convolution Networks for Real-time Kriging
Sep 24, 2021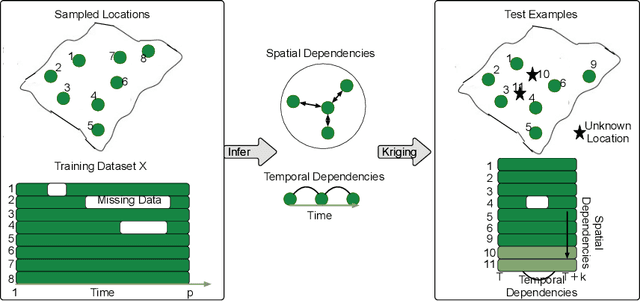

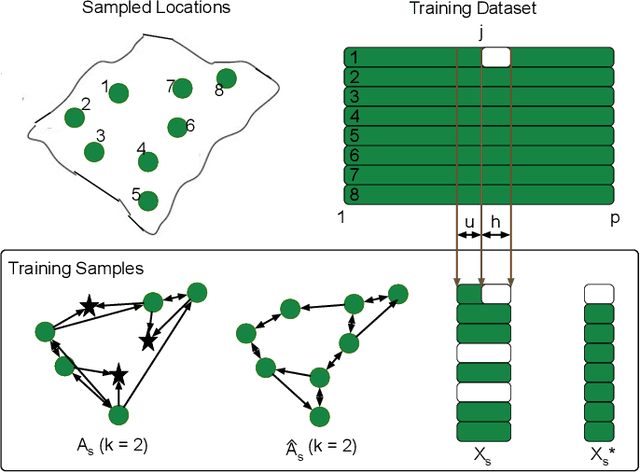
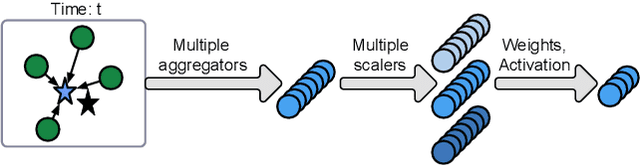
Spatiotemporal kriging is an important application in spatiotemporal data analysis, aiming to recover/interpolate signals for unsampled/unobserved locations based on observed signals. The principle challenge for spatiotemporal kriging is how to effectively model and leverage the spatiotemporal dependencies within the data. Recently, graph neural networks (GNNs) have shown great promise for spatiotemporal kriging tasks. However, standard GNNs often require a carefully designed adjacency matrix and specific aggregation functions, which are inflexible for general applications/problems. To address this issue, we present SATCN -- Spatial Aggregation and Temporal Convolution Networks -- a universal and flexible framework to perform spatiotemporal kriging for various spatiotemporal datasets without the need for model specification. Specifically, we propose a novel spatial aggregation network (SAN) inspired by Principal Neighborhood Aggregation, which uses multiple aggregation functions to help one node gather diverse information from its neighbors. To exclude information from unsampled nodes, a masking strategy that prevents the unsampled sensors from sending messages to their neighborhood is introduced to SAN. We capture temporal dependencies by the temporal convolutional networks, which allows our model to cope with data of diverse sizes. To make SATCN generalizable to unseen nodes and even unseen graph structures, we employ an inductive strategy to train SATCN. We conduct extensive experiments on three real-world spatiotemporal datasets, including traffic speed and climate recordings. Our results demonstrate the superiority of SATCN over traditional and GNN-based kriging models.
$\infty$-former: Infinite Memory Transformer
Sep 01, 2021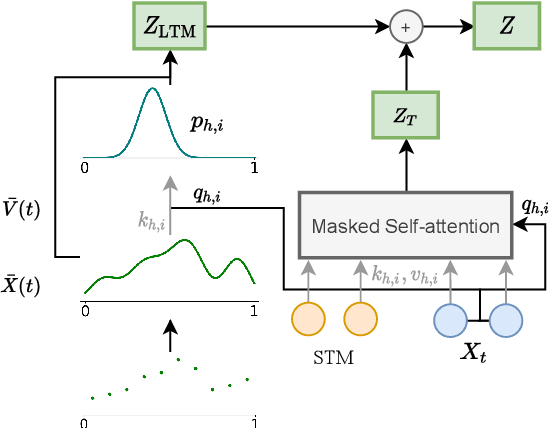

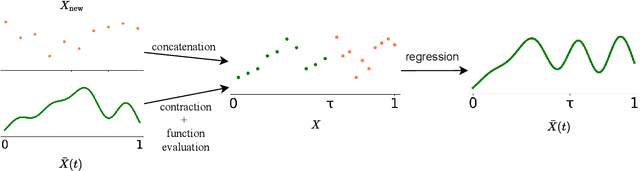

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.
Learning to Control using Image Feedback
Oct 28, 2021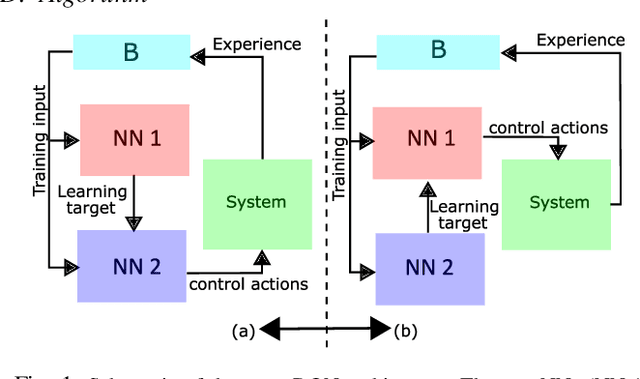
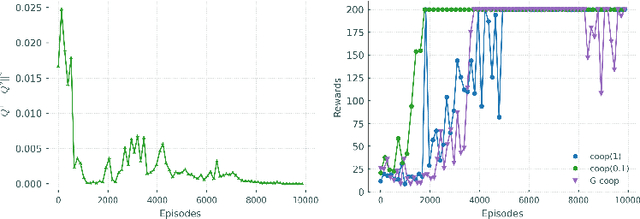
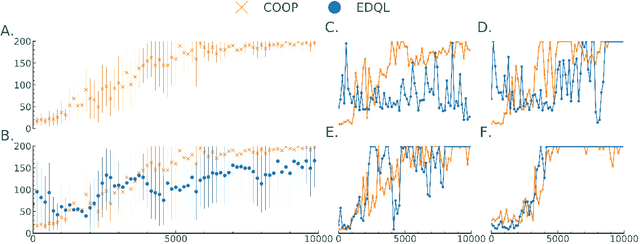
Learning to control complex systems using non-traditional feedback, e.g., in the form of snapshot images, is an important task encountered in diverse domains such as robotics, neuroscience, and biology (cellular systems). In this paper, we present a two neural-network (NN)-based feedback control framework to design control policies for systems that generate feedback in the form of images. In particular, we develop a deep $Q$-network (DQN)-driven learning control strategy to synthesize a sequence of control inputs from snapshot images that encode the information pertaining to the current state and control action of the system. Further, to train the networks we employ a direct error-driven learning (EDL) approach that utilizes a set of linear transformations of the NN training error to update the NN weights in each layer. We verify the efficacy of the proposed control strategy using numerical examples.
Semantics-aware Attention Improves Neural Machine Translation
Oct 13, 2021
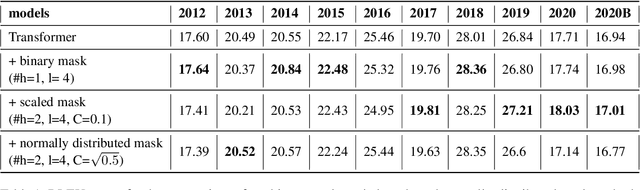
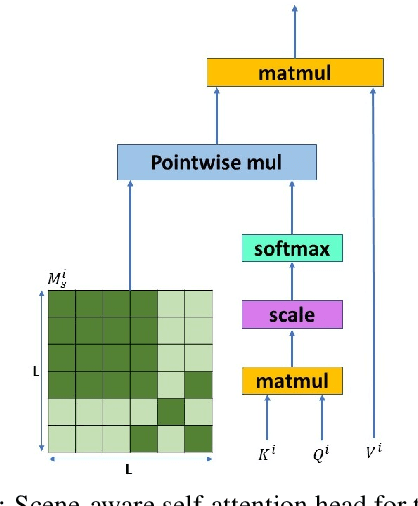

The integration of syntactic structures into Transformer machine translation has shown positive results, but to our knowledge, no work has attempted to do so with semantic structures. In this work we propose two novel parameter-free methods for injecting semantic information into Transformers, both rely on semantics-aware masking of (some of) the attention heads. One such method operates on the encoder, through a Scene-Aware Self-Attention (SASA) head. Another on the decoder, through a Scene-Aware Cross-Attention (SACrA) head. We show a consistent improvement over the vanilla Transformer and syntax-aware models for four language pairs. We further show an additional gain when using both semantic and syntactic structures in some language pairs.
SciCap: Generating Captions for Scientific Figures
Oct 25, 2021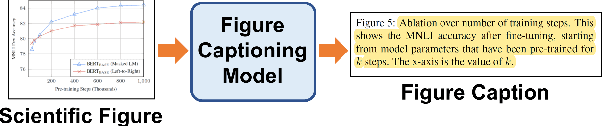
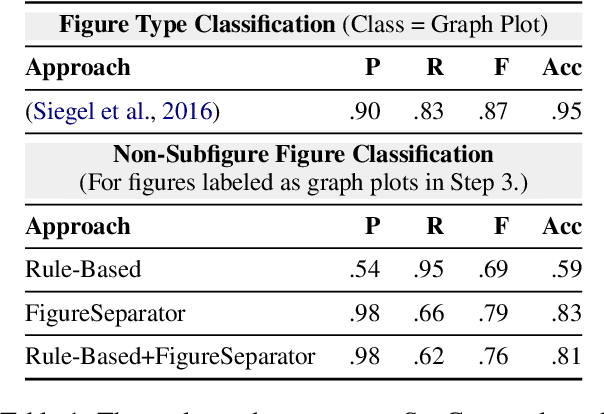
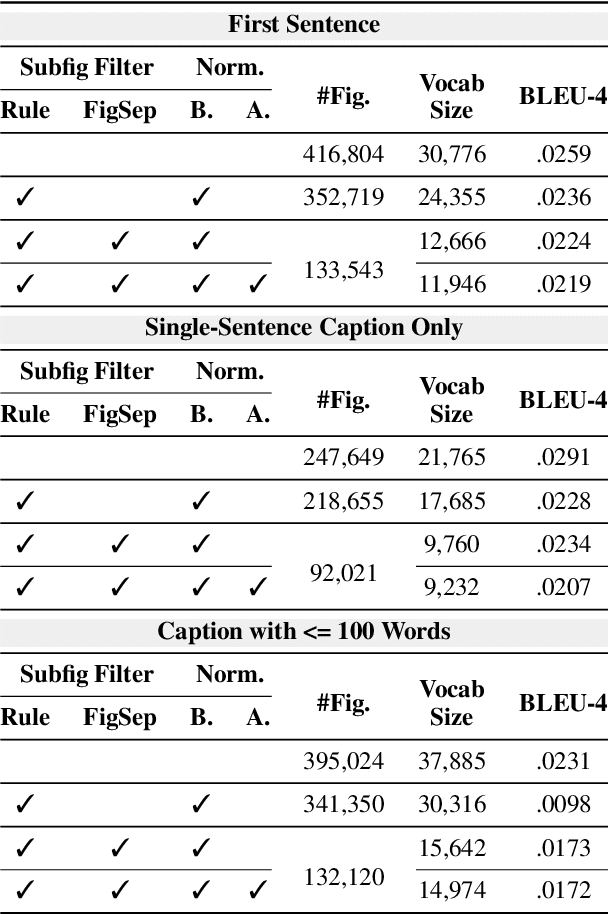
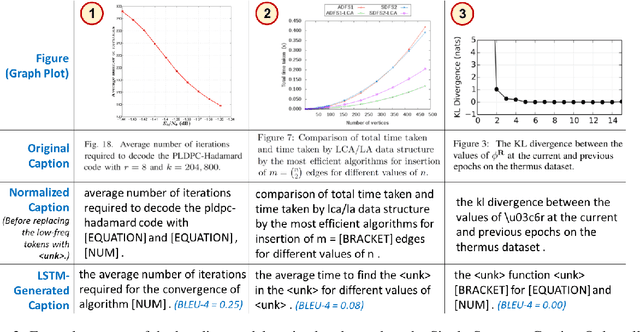
Researchers use figures to communicate rich, complex information in scientific papers. The captions of these figures are critical to conveying effective messages. However, low-quality figure captions commonly occur in scientific articles and may decrease understanding. In this paper, we propose an end-to-end neural framework to automatically generate informative, high-quality captions for scientific figures. To this end, we introduce SCICAP, a large-scale figure-caption dataset based on computer science arXiv papers published between 2010 and 2020. After pre-processing - including figure-type classification, sub-figure identification, text normalization, and caption text selection - SCICAP contained more than two million figures extracted from over 290,000 papers. We then established baseline models that caption graph plots, the dominant (19.2%) figure type. The experimental results showed both opportunities and steep challenges of generating captions for scientific figures.
Towards Tokenized Human Dynamics Representation
Nov 22, 2021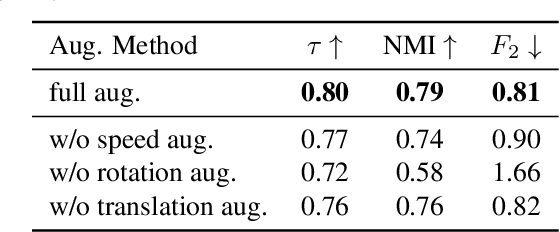
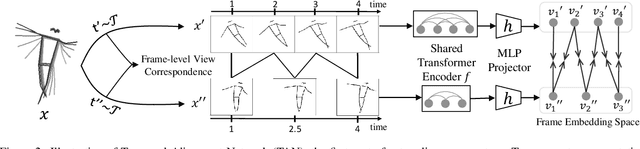

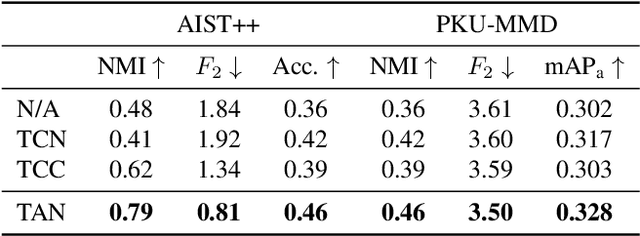
For human action understanding, a popular research direction is to analyze short video clips with unambiguous semantic content, such as jumping and drinking. However, methods for understanding short semantic actions cannot be directly translated to long human dynamics such as dancing, where it becomes challenging even to label the human movements semantically. Meanwhile, the natural language processing (NLP) community has made progress in solving a similar challenge of annotation scarcity by large-scale pre-training, which improves several downstream tasks with one model. In this work, we study how to segment and cluster videos into recurring temporal patterns in a self-supervised way, namely acton discovery, the main roadblock towards video tokenization. We propose a two-stage framework that first obtains a frame-wise representation by contrasting two augmented views of video frames conditioned on their temporal context. The frame-wise representations across a collection of videos are then clustered by K-means. Actons are then automatically extracted by forming a continuous motion sequence from frames within the same cluster. We evaluate the frame-wise representation learning step by Kendall's Tau and the lexicon building step by normalized mutual information and language entropy. We also study three applications of this tokenization: genre classification, action segmentation, and action composition. On the AIST++ and PKU-MMD datasets, actons bring significant performance improvements compared to several baselines.
A scalable saliency-based Feature selection method with instance level information
Apr 30, 2019

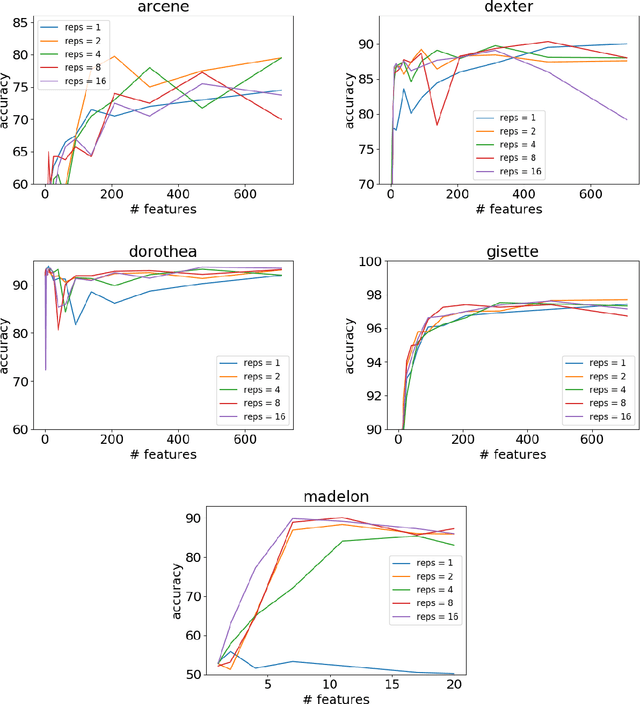
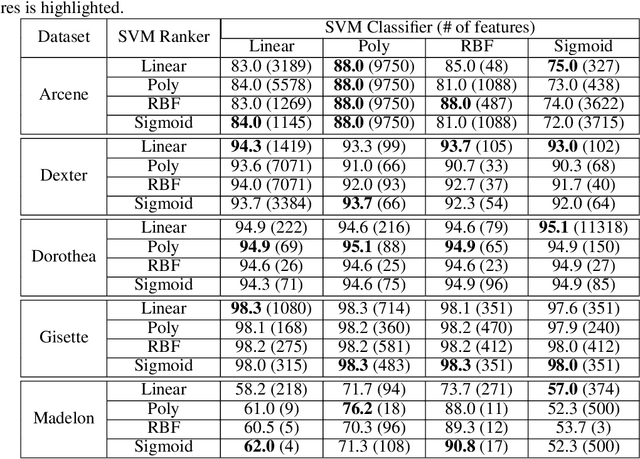
Classic feature selection techniques remove those features that are either irrelevant or redundant, achieving a subset of relevant features that help to provide a better knowledge extraction. This allows the creation of compact models that are easier to interpret. Most of these techniques work over the whole dataset, but they are unable to provide the user with successful information when only instance information is needed. In short, given any example, classic feature selection algorithms do not give any information about which the most relevant information is, regarding this sample. This work aims to overcome this handicap by developing a novel feature selection method, called Saliency-based Feature Selection (SFS), based in deep-learning saliency techniques. Our experimental results will prove that this algorithm can be successfully used not only in Neural Networks, but also under any given architecture trained by using Gradient Descent techniques.