 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using UAVs for vehicle tracking and collision risk assessment at intersections
Oct 11, 2021
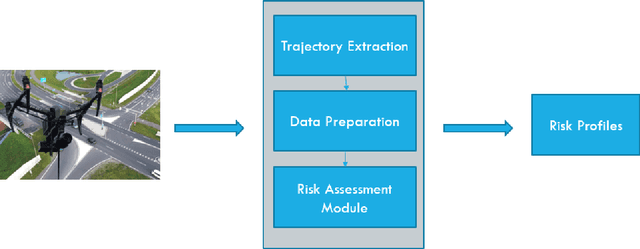
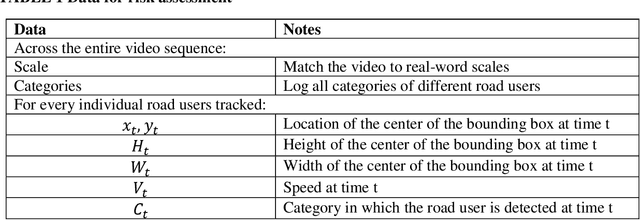
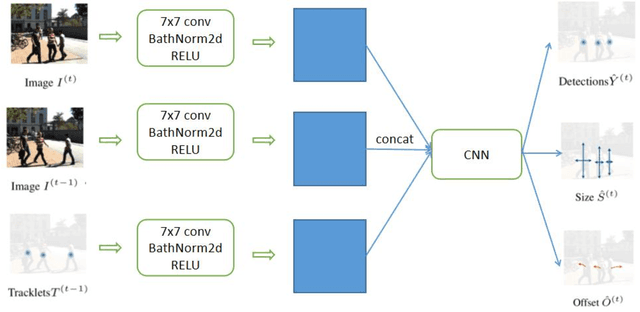

Assessing collision risk is a critical challenge to effective traffic safety management. The deployment of unmanned aerial vehicles (UAVs) to address this issue has shown much promise, given their wide visual field and movement flexibility. This research demonstrates the application of UAVs and V2X connectivity to track the movement of road users and assess potential collisions at intersections. The study uses videos captured by UAVs. The proposed method combines deep-learning based tracking algorithms and time-to-collision tasks. The results not only provide beneficial information for vehicle's recognition of potential crashes and motion planning but also provided a valuable tool for urban road agencies and safety management engineers.
Precise Learning of Source Code Contextual Semantics via Hierarchical Dependence Structure and Graph Attention Networks
Nov 20, 2021
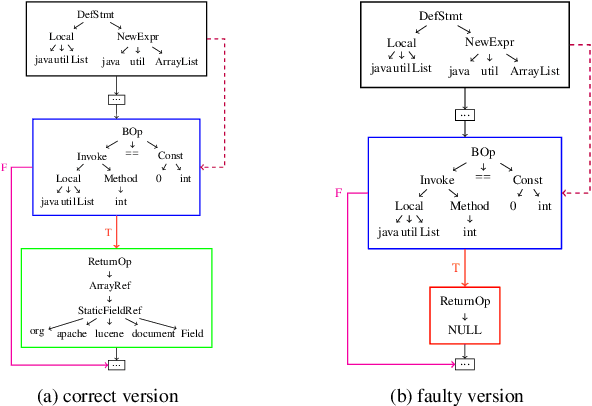
Deep learning is being used extensively in a variety of software engineering tasks, e.g., program classification and defect prediction. Although the technique eliminates the required process of feature engineering, the construction of source code model significantly affects the performance on those tasks. Most recent works was mainly focused on complementing AST-based source code models by introducing contextual dependencies extracted from CFG. However, all of them pay little attention to the representation of basic blocks, which are the basis of contextual dependencies. In this paper, we integrated AST and CFG and proposed a novel source code model embedded with hierarchical dependencies. Based on that, we also designed a neural network that depends on the graph attention mechanism.Specifically, we introduced the syntactic structural of the basic block, i.e., its corresponding AST, in source code model to provide sufficient information and fill the gap. We have evaluated this model on three practical software engineering tasks and compared it with other state-of-the-art methods. The results show that our model can significantly improve the performance. For example, compared to the best performing baseline, our model reduces the scale of parameters by 50\% and achieves 4\% improvement on accuracy on program classification task.
* 17pages, published on Journal of Systems and Software
Revisiting Flow Information for Traffic Prediction
Jun 03, 2019
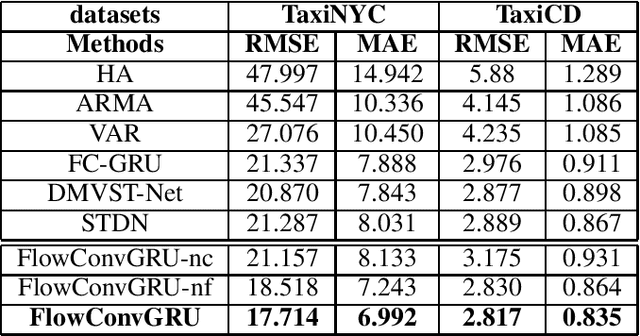
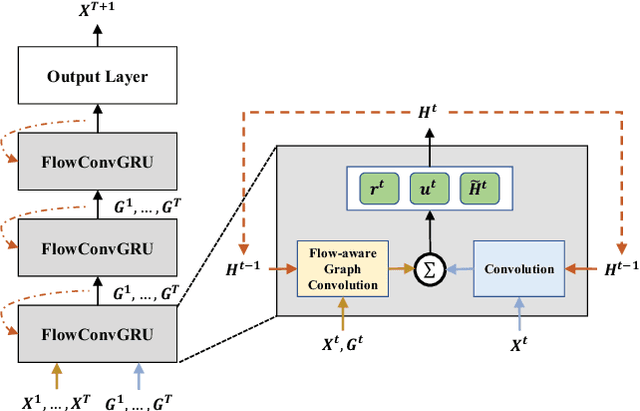
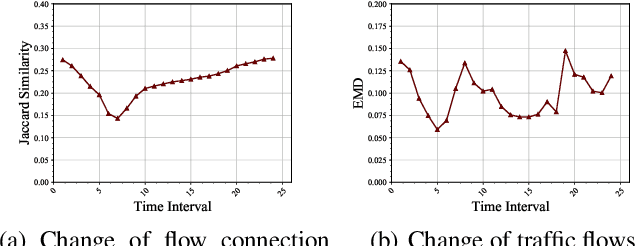
Traffic prediction is a fundamental task in many real applications, which aims to predict the future traffic volume in any region of a city. In essence, traffic volume in a region is the aggregation of traffic flows from/to the region. However, existing traffic prediction methods focus on modeling complex spatiotemporal traffic correlations and seldomly study the influence of the original traffic flows among regions. In this paper, we revisit the traffic flow information and exploit the direct flow correlations among regions towards more accurate traffic prediction. We introduce a novel flow-aware graph convolution to model dynamic flow correlations among regions. We further introduce an integrated Gated Recurrent Unit network to incorporate flow correlations with spatiotemporal modeling. The experimental results on real-world traffic datasets validate the effectiveness of the proposed method, especially on the traffic conditions with a great change on flows.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021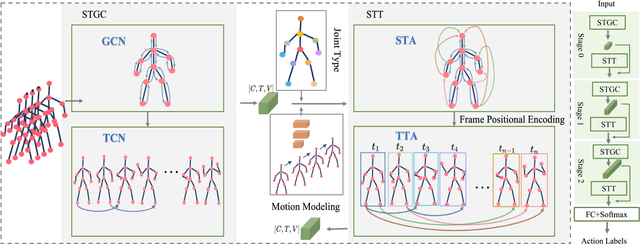
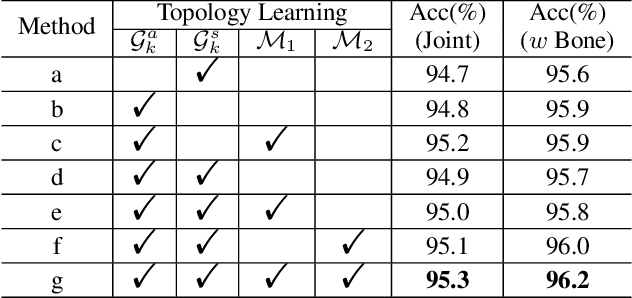
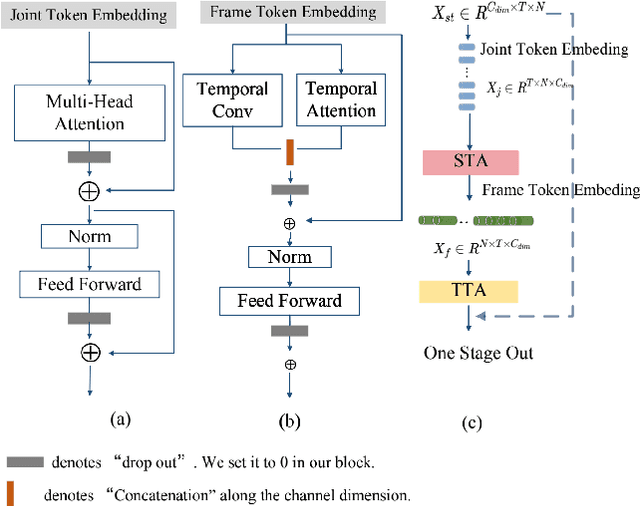
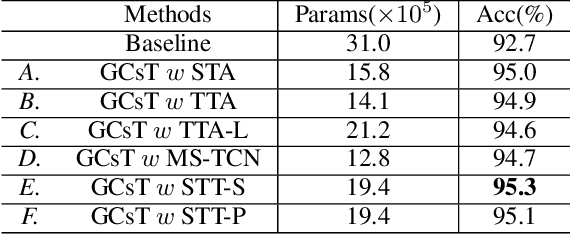
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.
Learnable Adaptive Cosine Estimator (LACE) for Image Classification
Oct 11, 2021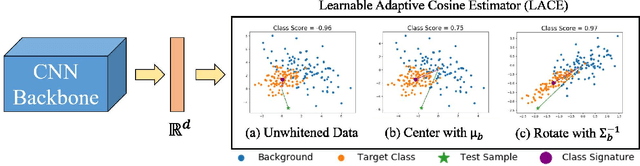
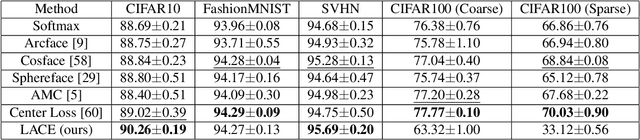
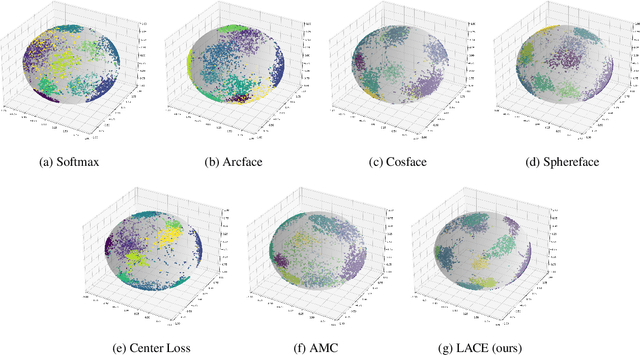
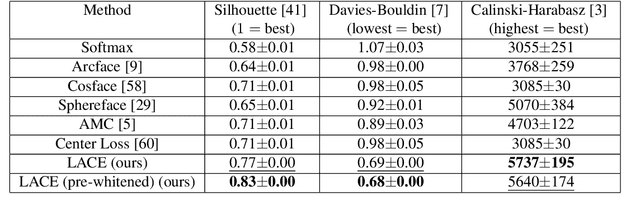
In this work, we propose a new loss to improve feature discriminability and classification performance. Motivated by the adaptive cosine/coherence estimator (ACE), our proposed method incorporates angular information that is inherently learned by artificial neural networks. Our learnable ACE (LACE) transforms the data into a new ``whitened" space that improves the inter-class separability and intra-class compactness. We compare our LACE to alternative state-of-the art softmax-based and feature regularization approaches. Our results show that the proposed method can serve as a viable alternative to cross entropy and angular softmax approaches. Our code is publicly available: https://github.com/GatorSense/LACE.
American Hate Crime Trends Prediction with Event Extraction
Nov 09, 2021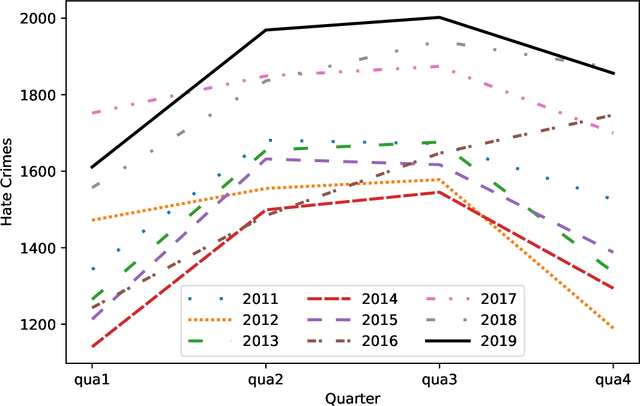
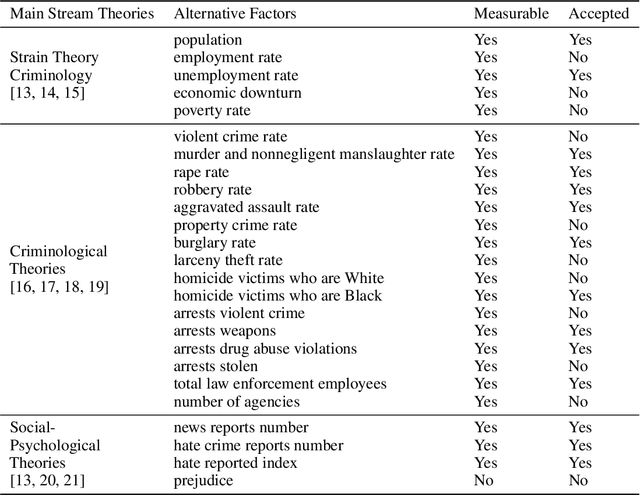
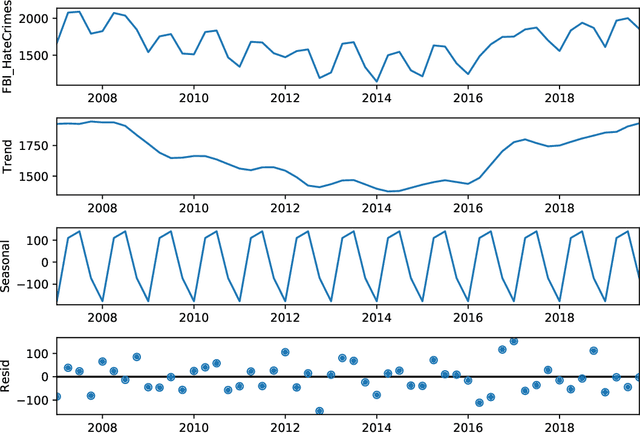

Social media platforms may provide potential space for discourses that contain hate speech, and even worse, can act as a propagation mechanism for hate crimes. The FBI's Uniform Crime Reporting (UCR) Program collects hate crime data and releases statistic report yearly. These statistics provide information in determining national hate crime trends. The statistics can also provide valuable holistic and strategic insight for law enforcement agencies or justify lawmakers for specific legislation. However, the reports are mostly released next year and lag behind many immediate needs. Recent research mainly focuses on hate speech detection in social media text or empirical studies on the impact of a confirmed crime. This paper proposes a framework that first utilizes text mining techniques to extract hate crime events from New York Times news, then uses the results to facilitate predicting American national-level and state-level hate crime trends. Experimental results show that our method can significantly enhance the prediction performance compared with time series or regression methods without event-related factors. Our framework broadens the methods of national-level and state-level hate crime trends prediction.
Video 3D Sampling for Self-supervised Representation Learning
Jul 08, 2021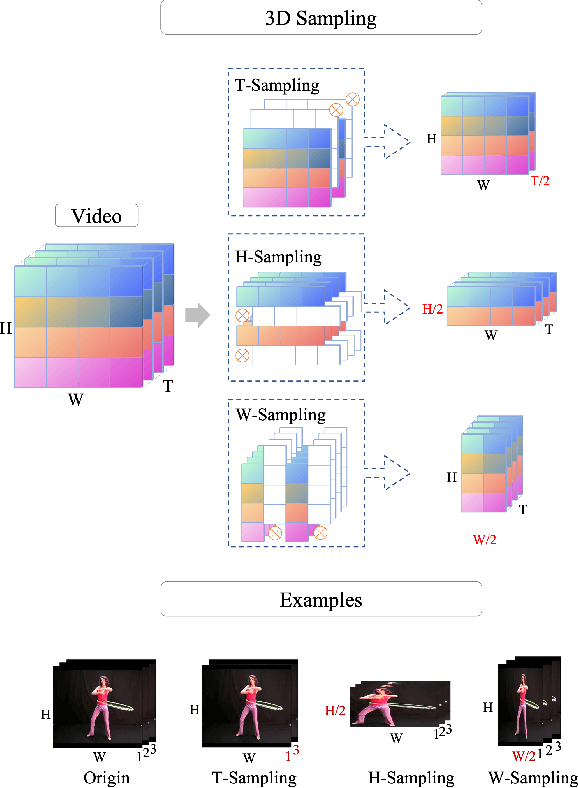
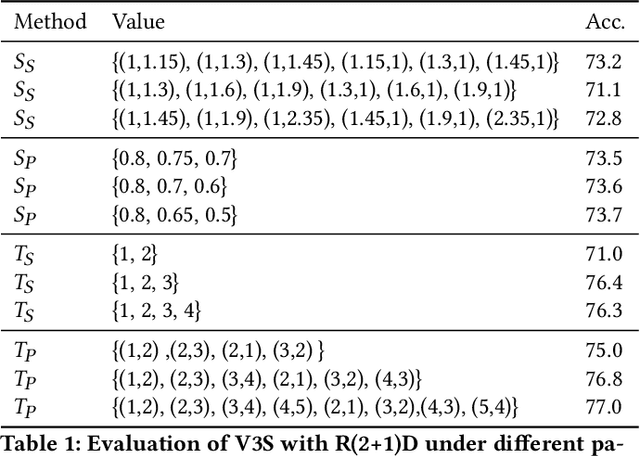
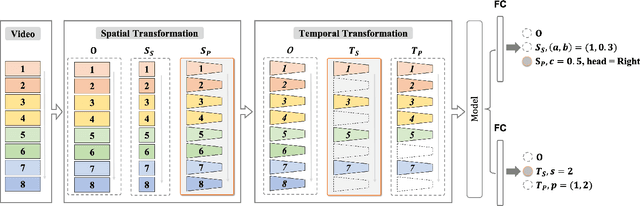
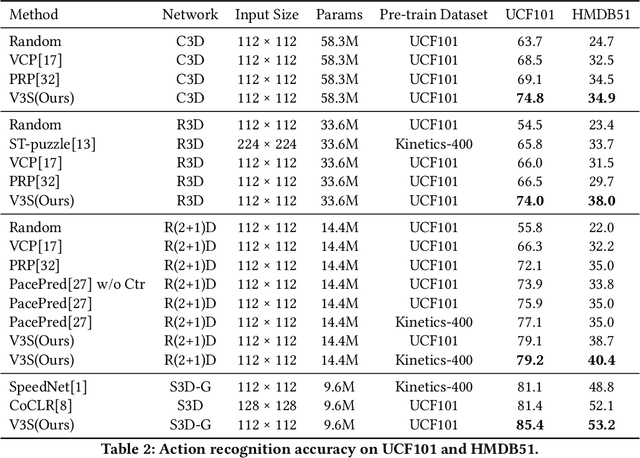
Most of the existing video self-supervised methods mainly leverage temporal signals of videos, ignoring that the semantics of moving objects and environmental information are all critical for video-related tasks. In this paper, we propose a novel self-supervised method for video representation learning, referred to as Video 3D Sampling (V3S). In order to sufficiently utilize the information (spatial and temporal) provided in videos, we pre-process a video from three dimensions (width, height, time). As a result, we can leverage the spatial information (the size of objects), temporal information (the direction and magnitude of motions) as our learning target. In our implementation, we combine the sampling of the three dimensions and propose the scale and projection transformations in space and time respectively. The experimental results show that, when applied to action recognition, video retrieval and action similarity labeling, our approach improves the state-of-the-arts with significant margins.
A Condense-then-Select Strategy for Text Summarization
Jun 19, 2021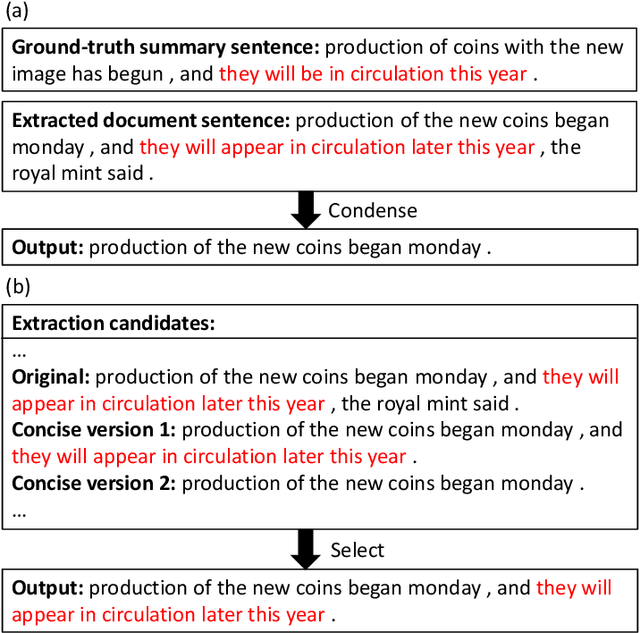
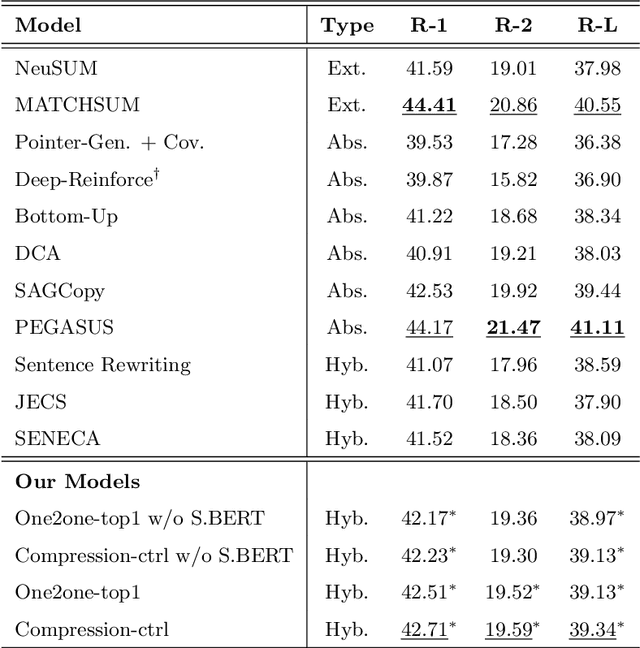
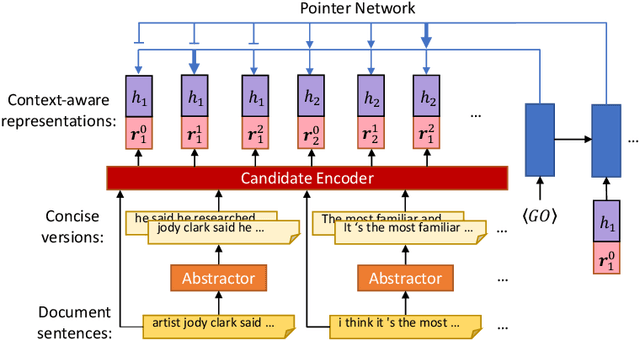
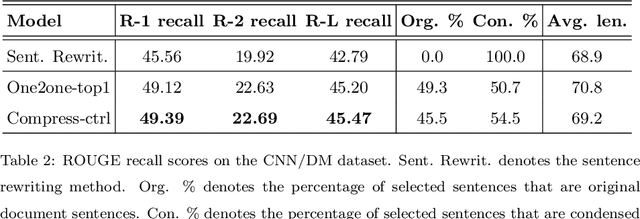
Select-then-compress is a popular hybrid, framework for text summarization due to its high efficiency. This framework first selects salient sentences and then independently condenses each of the selected sentences into a concise version. However, compressing sentences separately ignores the context information of the document, and is therefore prone to delete salient information. To address this limitation, we propose a novel condense-then-select framework for text summarization. Our framework first concurrently condenses each document sentence. Original document sentences and their compressed versions then become the candidates for extraction. Finally, an extractor utilizes the context information of the document to select candidates and assembles them into a summary. If salient information is deleted during condensing, the extractor can select an original sentence to retain the information. Thus, our framework helps to avoid the loss of salient information, while preserving the high efficiency of sentence-level compression. Experiment results on the CNN/DailyMail, DUC-2002, and Pubmed datasets demonstrate that our framework outperforms the select-then-compress framework and other strong baselines.
VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling
Nov 24, 2021
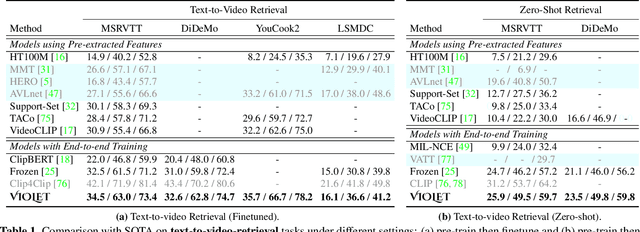
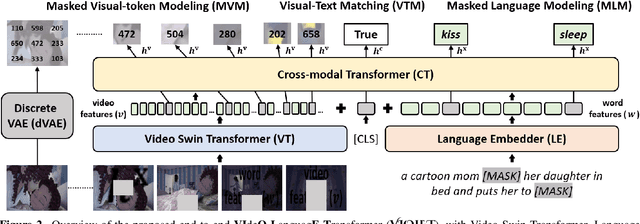
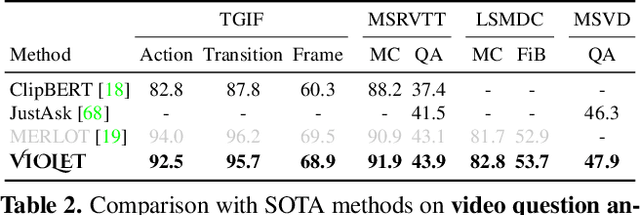
A great challenge in video-language (VidL) modeling lies in the disconnection between fixed video representations extracted from image/video understanding models and downstream VidL data. Recent studies try to mitigate this disconnection via end-to-end training. To make it computationally feasible, prior works tend to "imagify" video inputs, i.e., a handful of sparsely sampled frames are fed into a 2D CNN, followed by a simple mean-pooling or concatenation to obtain the overall video representations. Although achieving promising results, such simple approaches may lose temporal information that is essential for performing downstream VidL tasks. In this work, we present VIOLET, a fully end-to-end VIdeO-LanguagE Transformer, which adopts a video transformer to explicitly model the temporal dynamics of video inputs. Further, unlike previous studies that found pre-training tasks on video inputs (e.g., masked frame modeling) not very effective, we design a new pre-training task, Masked Visual-token Modeling (MVM), for better video modeling. Specifically, the original video frame patches are "tokenized" into discrete visual tokens, and the goal is to recover the original visual tokens based on the masked patches. Comprehensive analysis demonstrates the effectiveness of both explicit temporal modeling via video transformer and MVM. As a result, VIOLET achieves new state-of-the-art performance on 5 video question answering tasks and 4 text-to-video retrieval tasks.
Nonlinear Intensity Sonar Image Matching based on Deep Convolution Features
Nov 29, 2021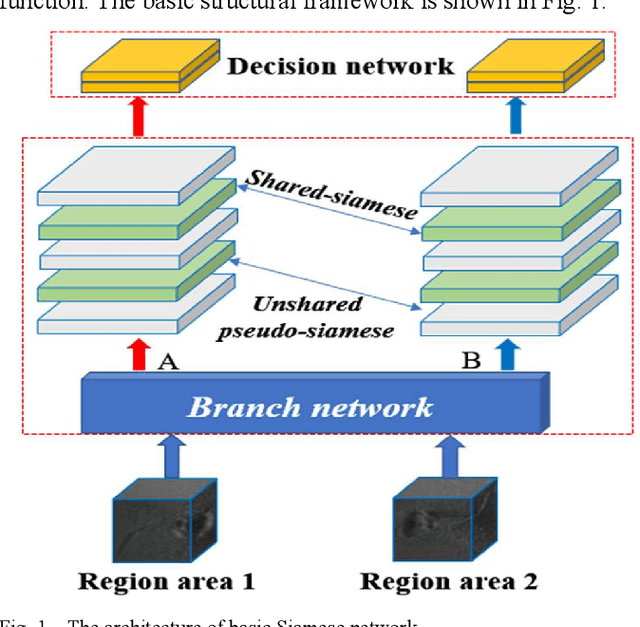
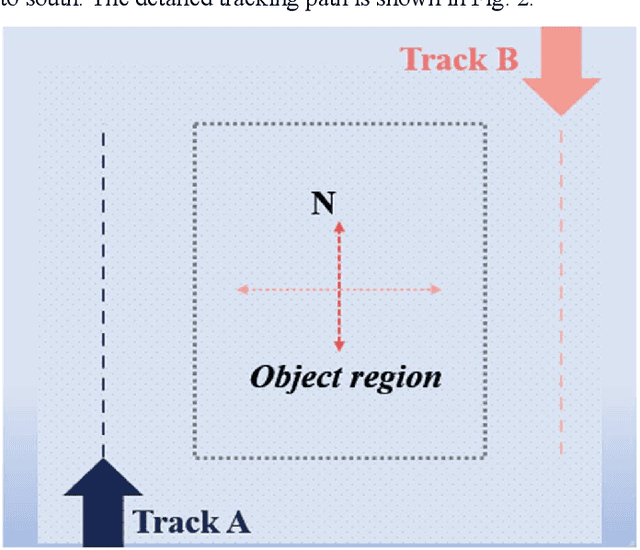
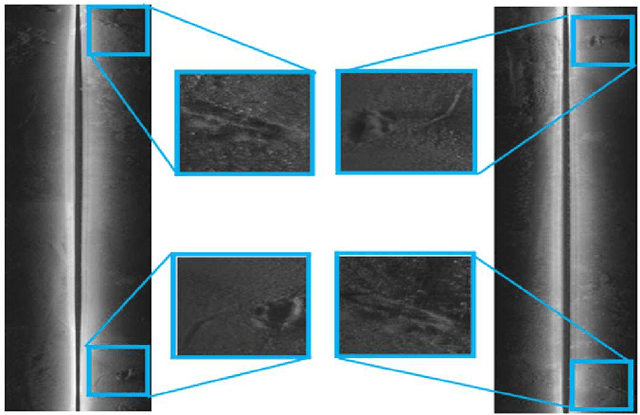
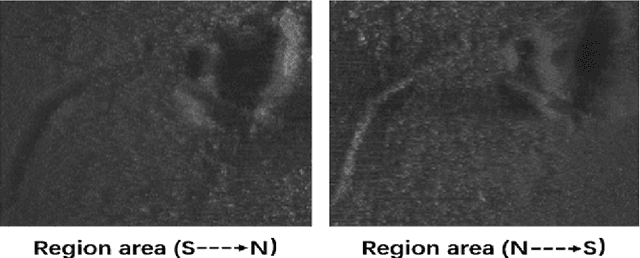
In the field of deep-sea exploration, sonar is presently the only efficient long-distance sensing device. The complicated underwater environment, such as noise interference, low target intensity or background dynamics, has brought many negative effects on sonar imaging. Among them, the problem of nonlinear intensity is extremely prevalent. It is also known as the anisotropy of acoustic imaging, that is, when AUVs carry sonar to detect the same target from different angles, the intensity difference between image pairs is sometimes very large, which makes the traditional matching algorithm almost ineffective. However, image matching is the basis of comprehensive tasks such as navigation, positioning, and mapping. Therefore, it is very valuable to obtain robust and accurate matching results. This paper proposes a combined matching method based on phase information and deep convolution features. It has two outstanding advantages: one is that deep convolution features could be used to measure the similarity of the local and global positions of the sonar image; the other is that local feature matching could be performed at the key target position of the sonar image. This method does not need complex manual design, and completes the matching task of nonlinear intensity sonar images in a close end-to-end manner. Feature matching experiments are carried out on the deep-sea sonar images captured by AUVs, and the results show that our proposal has good matching accuracy and robustness.