 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-objective Explanations of GNN Predictions
Nov 29, 2021
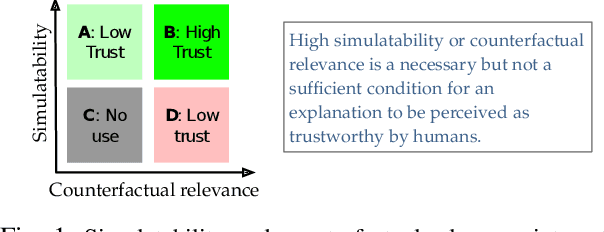
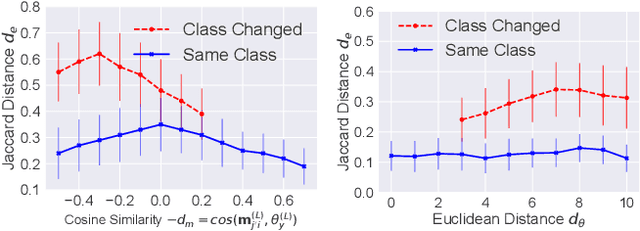
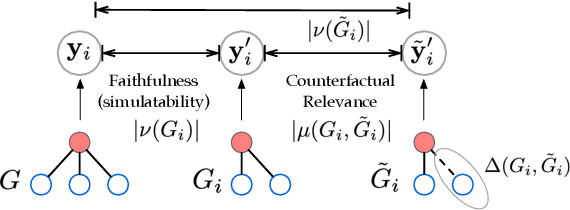
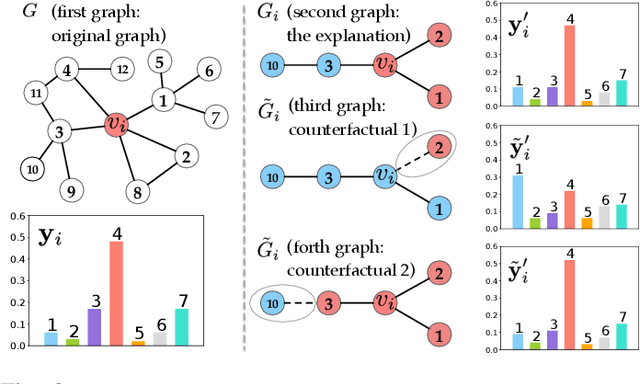
Graph Neural Network (GNN) has achieved state-of-the-art performance in various high-stake prediction tasks, but multiple layers of aggregations on graphs with irregular structures make GNN a less interpretable model. Prior methods use simpler subgraphs to simulate the full model, or counterfactuals to identify the causes of a prediction. The two families of approaches aim at two distinct objectives, "simulatability" and "counterfactual relevance", but it is not clear how the objectives can jointly influence the human understanding of an explanation. We design a user study to investigate such joint effects and use the findings to design a multi-objective optimization (MOO) algorithm to find Pareto optimal explanations that are well-balanced in simulatability and counterfactual. Since the target model can be of any GNN variants and may not be accessible due to privacy concerns, we design a search algorithm using zeroth-order information without accessing the architecture and parameters of the target model. Quantitative experiments on nine graphs from four applications demonstrate that the Pareto efficient explanations dominate single-objective baselines that use first-order continuous optimization or discrete combinatorial search. The explanations are further evaluated in robustness and sensitivity to show their capability of revealing convincing causes while being cautious about the possible confounders. The diverse dominating counterfactuals can certify the feasibility of algorithmic recourse, that can potentially promote algorithmic fairness where humans are participating in the decision-making using GNN.
DRMIME: Differentiable Mutual Information and Matrix Exponential for Multi-Resolution Image Registration
Jan 27, 2020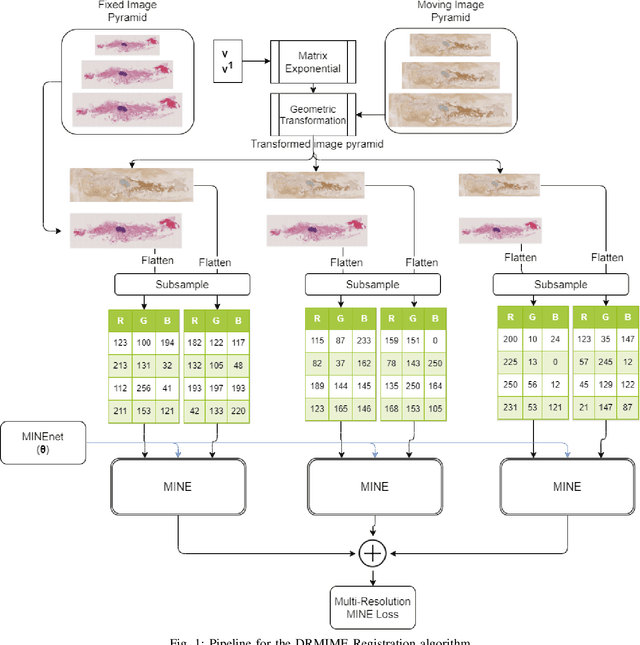
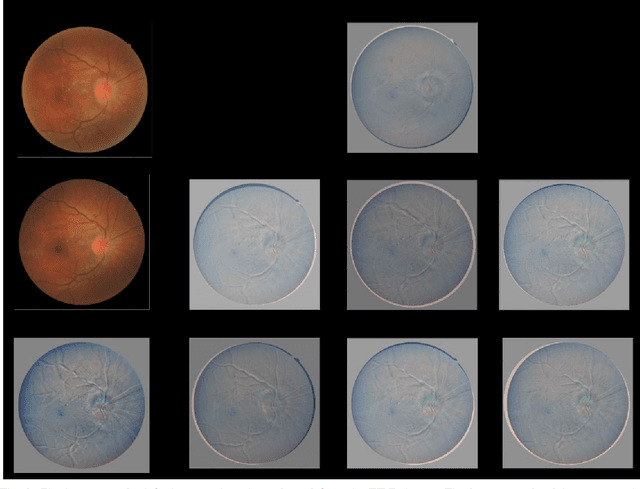
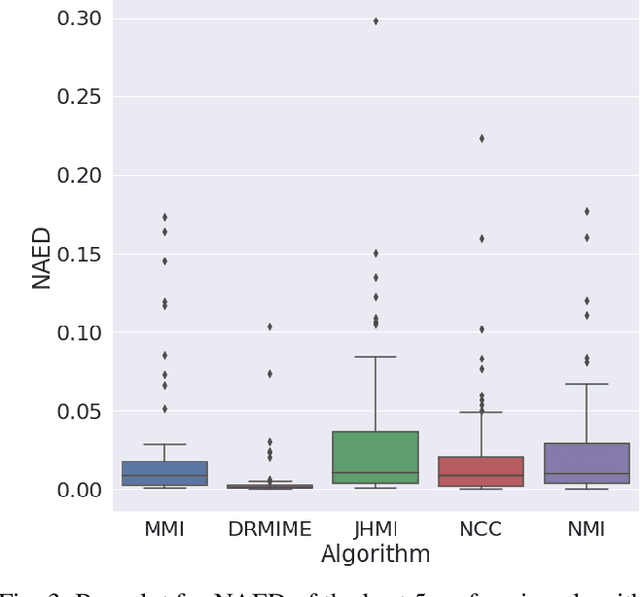
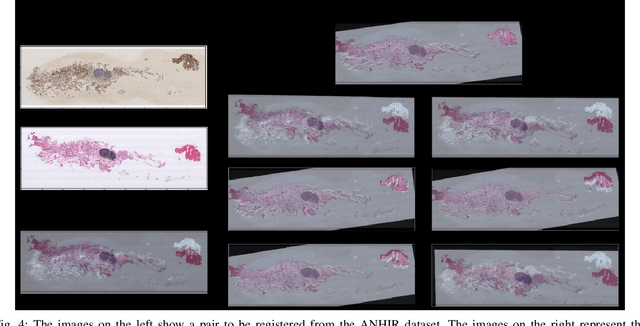
In this work, we present a novel unsupervised image registration algorithm. It is differentiable end-to-end and can be used for both multi-modal and mono-modal registration. This is done using mutual information (MI) as a metric. The novelty here is that rather than using traditional ways of approximating MI, we use a neural estimator called MINE and supplement it with matrix exponential for transformation matrix computation. This leads to improved results as compared to the standard algorithms available out-of-the-box in state-of-the-art image registration toolboxes.
Automatic Evaluation and Moderation of Open-domain Dialogue Systems
Nov 03, 2021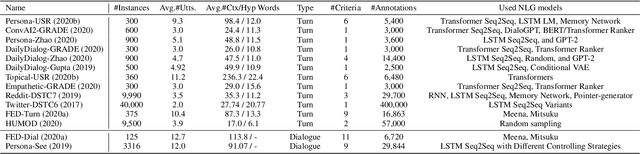


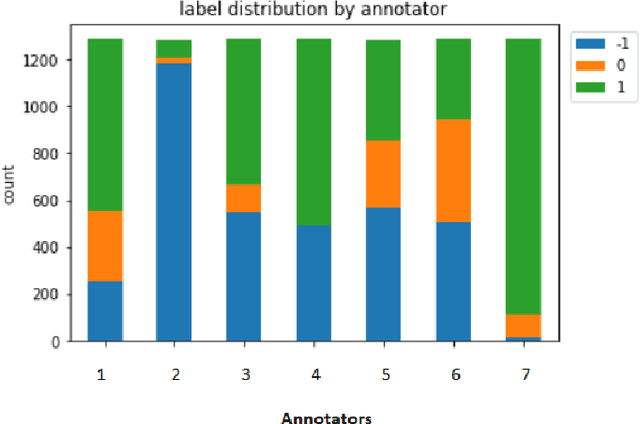
In recent years, dialogue systems have attracted significant interests in both academia and industry. Especially the discipline of open-domain dialogue systems, aka chatbots, has gained great momentum. Yet, a long standing challenge that bothers the researchers is the lack of effective automatic evaluation metrics, which results in significant impediment in the current research. Common practice in assessing the performance of open-domain dialogue models involves extensive human evaluation on the final deployed models, which is both time- and cost- intensive. Moreover, a recent trend in building open-domain chatbots involve pre-training dialogue models with a large amount of social media conversation data. However, the information contained in the social media conversations may be offensive and inappropriate. Indiscriminate usage of such data can result in insensitive and toxic generative models. This paper describes the data, baselines and results obtained for the Track 5 at the Dialogue System Technology Challenge 10 (DSTC10).
Ethically aligned Deep Learning: Unbiased Facial Aesthetic Prediction
Nov 09, 2021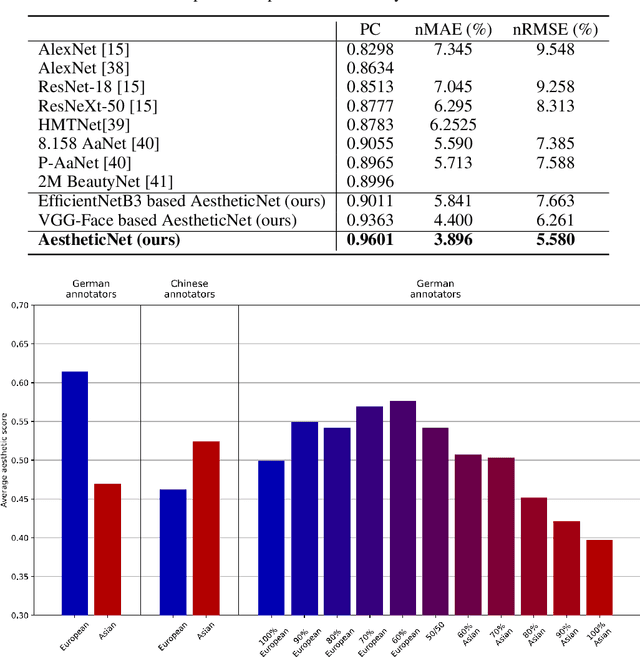
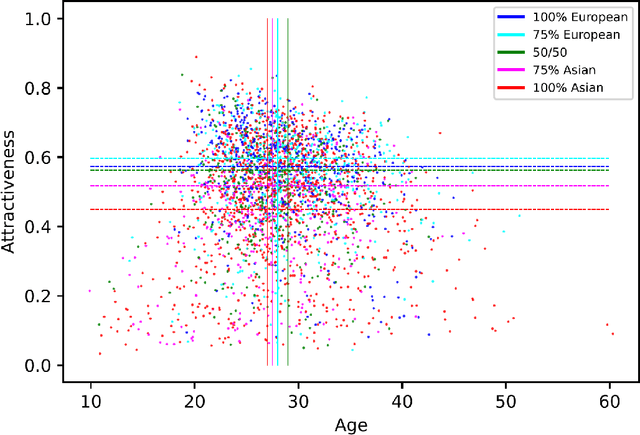
Facial beauty prediction (FBP) aims to develop a machine that automatically makes facial attractiveness assessment. In the past those results were highly correlated with human ratings, therefore also with their bias in annotating. As artificial intelligence can have racist and discriminatory tendencies, the cause of skews in the data must be identified. Development of training data and AI algorithms that are robust against biased information is a new challenge for scientists. As aesthetic judgement usually is biased, we want to take it one step further and propose an Unbiased Convolutional Neural Network for FBP. While it is possible to create network models that can rate attractiveness of faces on a high level, from an ethical point of view, it is equally important to make sure the model is unbiased. In this work, we introduce AestheticNet, a state-of-the-art attractiveness prediction network, which significantly outperforms competitors with a Pearson Correlation of 0.9601. Additionally, we propose a new approach for generating a bias-free CNN to improve fairness in machine learning.
Overcoming the Domain Gap in Contrastive Learning of Neural Action Representations
Nov 29, 2021
A fundamental goal in neuroscience is to understand the relationship between neural activity and behavior. For example, the ability to extract behavioral intentions from neural data, or neural decoding, is critical for developing effective brain machine interfaces. Although simple linear models have been applied to this challenge, they cannot identify important non-linear relationships. Thus, a self-supervised means of identifying non-linear relationships between neural dynamics and behavior, in order to compute neural representations, remains an important open problem. To address this challenge, we generated a new multimodal dataset consisting of the spontaneous behaviors generated by fruit flies, Drosophila melanogaster -- a popular model organism in neuroscience research. The dataset includes 3D markerless motion capture data from six camera views of the animal generating spontaneous actions, as well as synchronously acquired two-photon microscope images capturing the activity of descending neuron populations that are thought to drive actions. Standard contrastive learning and unsupervised domain adaptation techniques struggle to learn neural action representations (embeddings computed from the neural data describing action labels) due to large inter-animal differences in both neural and behavioral modalities. To overcome this deficiency, we developed simple yet effective augmentations that close the inter-animal domain gap, allowing us to extract behaviorally relevant, yet domain agnostic, information from neural data. This multimodal dataset and our new set of augmentations promise to accelerate the application of self-supervised learning methods in neuroscience.
Similarity Contrastive Estimation for Self-Supervised Soft Contrastive Learning
Nov 29, 2021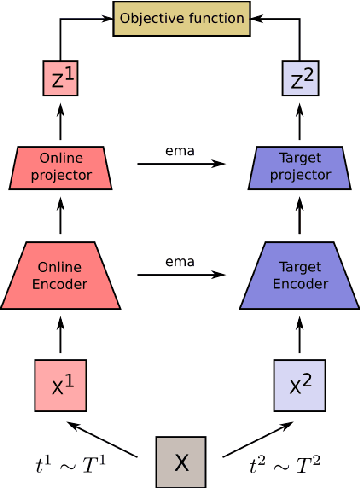

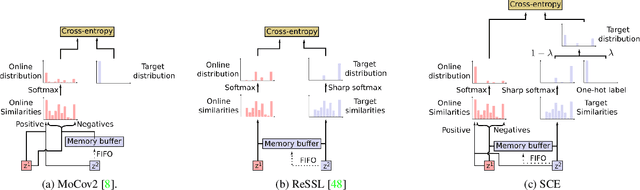
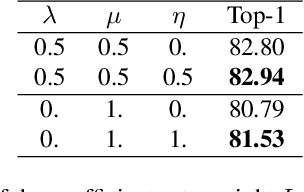
Contrastive representation learning has proven to be an effective self-supervised learning method. Most successful approaches are based on the Noise Contrastive Estimation (NCE) paradigm and consider different views of an instance as positives and other instances as noise that positives should be contrasted with. However, all instances in a dataset are drawn from the same distribution and share underlying semantic information that should not be considered as noise. We argue that a good data representation contains the relations, or semantic similarity, between the instances. Contrastive learning implicitly learns relations but considers the negatives as noise which is harmful to the quality of the learned relations and therefore the quality of the representation. To circumvent this issue we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective can be considered as soft contrastive learning. Instead of hard classifying positives and negatives, we propose a continuous distribution to push or pull instances based on their semantic similarities. The target similarity distribution is computed from weak augmented instances and sharpened to eliminate irrelevant relations. Each weak augmented instance is paired with a strong augmented instance that contrasts its positive while maintaining the target similarity distribution. Experimental results show that our proposed SCE outperforms its baselines MoCov2 and ReSSL on various datasets and is competitive with state-of-the-art algorithms on the ImageNet linear evaluation protocol.
Enhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization
Aug 01, 2021

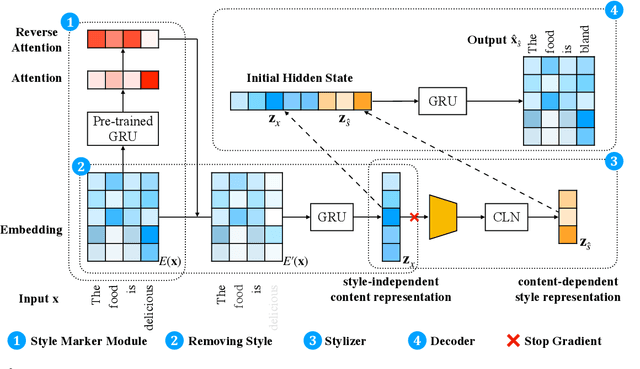
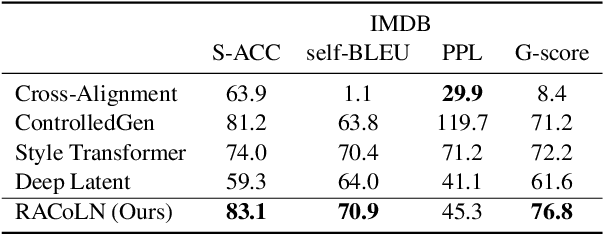
Text style transfer aims to alter the style (e.g., sentiment) of a sentence while preserving its content. A common approach is to map a given sentence to content representation that is free of style, and the content representation is fed to a decoder with a target style. Previous methods in filtering style completely remove tokens with style at the token level, which incurs the loss of content information. In this paper, we propose to enhance content preservation by implicitly removing the style information of each token with reverse attention, and thereby retain the content. Furthermore, we fuse content information when building the target style representation, making it dynamic with respect to the content. Our method creates not only style-independent content representation, but also content-dependent style representation in transferring style. Empirical results show that our method outperforms the state-of-the-art baselines by a large margin in terms of content preservation. In addition, it is also competitive in terms of style transfer accuracy and fluency.
Recovering a Single Community with Side Information
Sep 05, 2018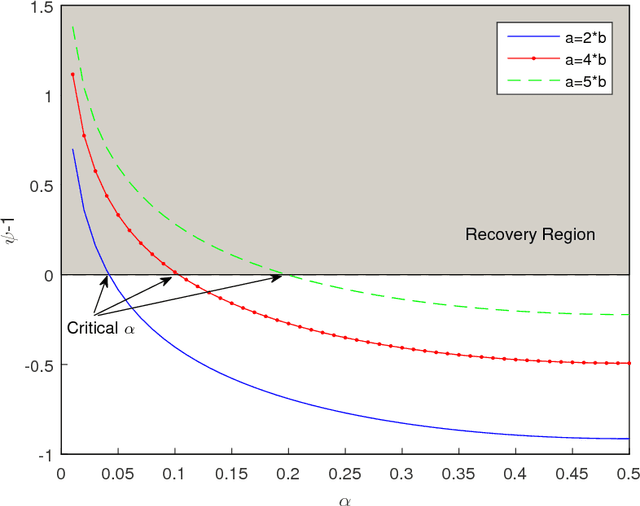
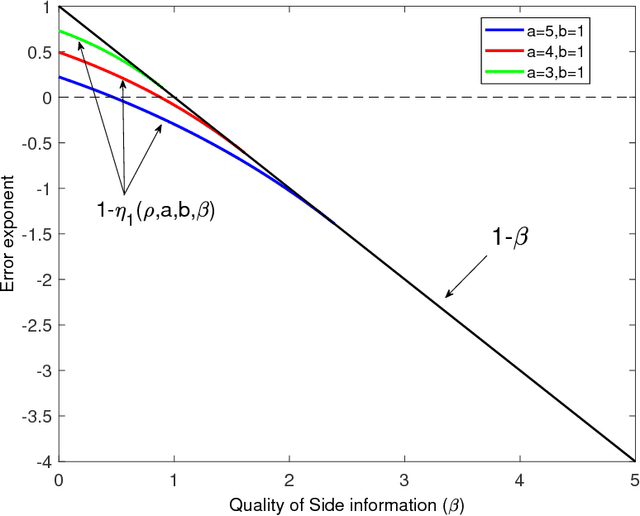
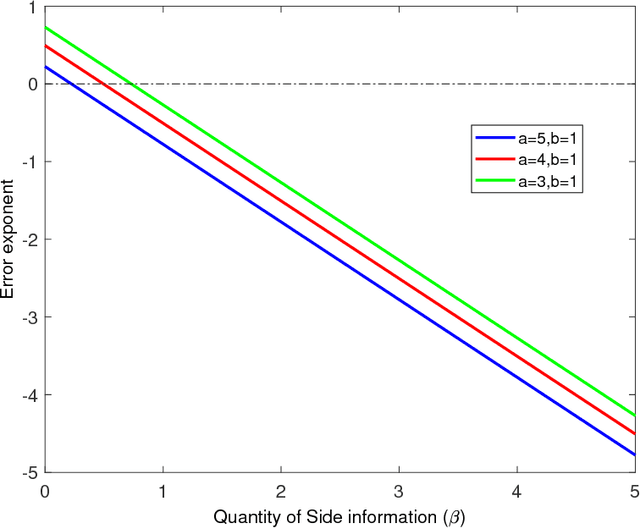
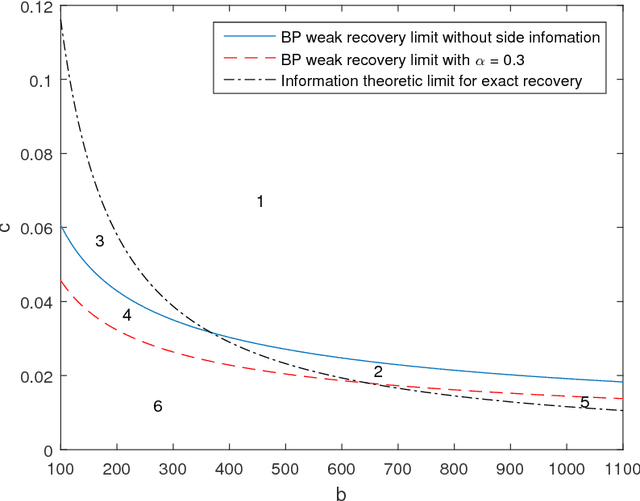
We study the effect of the quality and quantity of side information on the recovery of a hidden community of size $K=o(n)$ in a graph of size $n$. Side information for each node in the graph is modeled by a random vector with the following features: either the dimension of the vector is allowed to vary with $n$, while log-likelihood ratio (LLR) of each component with respect to the node label is fixed, or the LLR is allowed to vary and the vector dimension is fixed. These two models represent the variation in quality and quantity of side information. Under maximum likelihood detection, we calculate tight necessary and sufficient conditions for exact recovery of the labels. We demonstrate how side information needs to evolve with $n$ in terms of either its quantity, or quality, to improve the exact recovery threshold. A similar set of results are obtained for weak recovery. Under belief propagation, tight necessary and sufficient conditions for weak recovery are calculated when the LLRs are constant, and sufficient conditions when the LLRs vary with $n$. Moreover, we design and analyze a local voting procedure using side information that can achieve exact recovery when applied after belief propagation. The results for belief propagation are validated via simulations on finite synthetic data-sets, showing that the asymptotic results of this paper can also shed light on the performance at finite $n$.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 03, 2021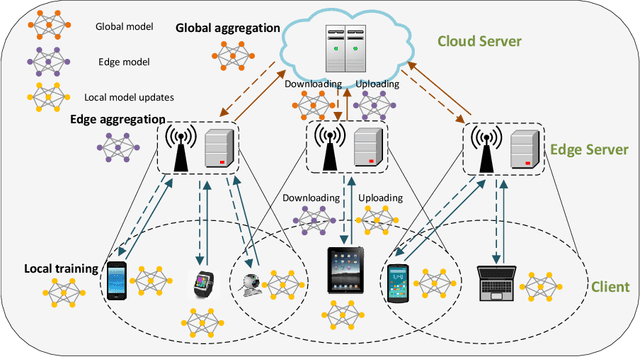
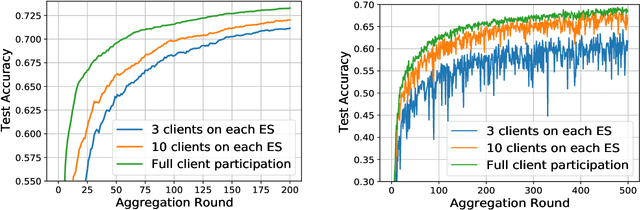
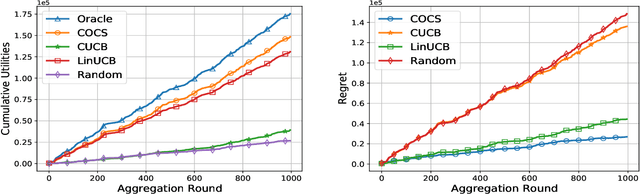
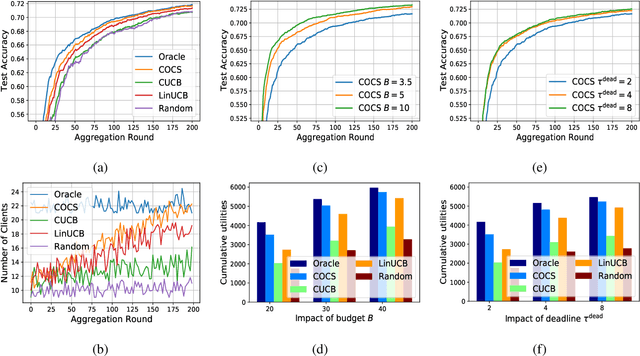
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.
Looking Outside the Window: Wider-Context Transformer for the Semantic Segmentation of High-Resolution Remote Sensing Images
Jul 01, 2021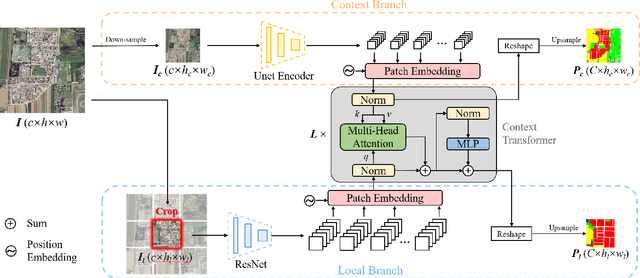
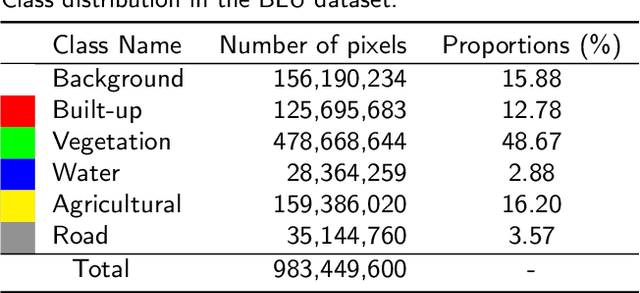
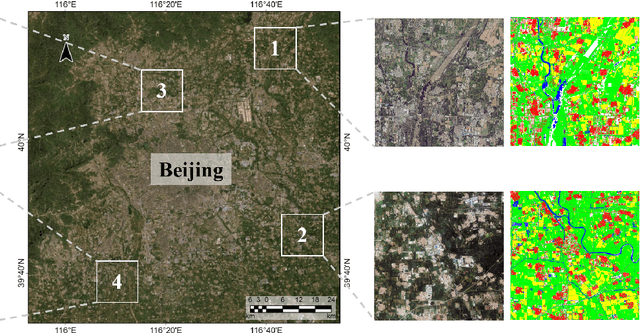
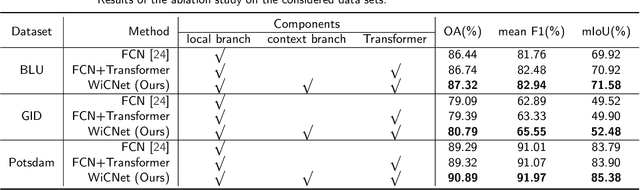
Long-range context information is crucial for the semantic segmentation of High-Resolution (HR) Remote Sensing Images (RSIs). The image cropping operations, commonly used for training neural networks, limit the perception of long-range context information in large RSIs. To break this limitation, we propose a Wider-Context Network (WiCNet) for the semantic segmentation of HR RSIs. In the WiCNet, apart from a conventional feature extraction network to aggregate the local information, an extra context branch is designed to explicitly model the context information in a larger image area. The information between the two branches is communicated through a Context Transformer, which is a novel design derived from the Vision Transformer to model the long-range context correlations. Ablation studies and comparative experiments conducted on several benchmark datasets prove the effectiveness of the proposed method. Additionally, we present a new Beijing Land-Use (BLU) dataset. This is a large-scale HR satellite dataset provided with high-quality and fine-grained reference labels, which we hope will boost future studies in this field.