 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pulmonary Disease Classification Using Globally Correlated Maximum Likelihood: an Auxiliary Attention mechanism for Convolutional Neural Networks
Sep 01, 2021
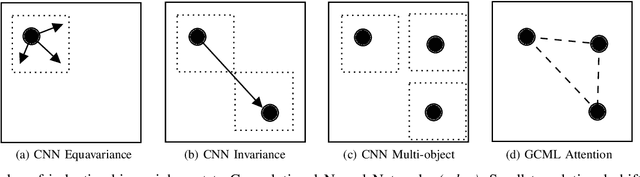



Convolutional neural networks (CNN) are now being widely used for classifying and detecting pulmonary abnormalities in chest radiographs. Two complementary generalization properties of CNNs, translation invariance and equivariance, are particularly useful in detecting manifested abnormalities associated with pulmonary disease, regardless of their spatial locations within the image. However, these properties also come with the loss of exact spatial information and global relative positions of abnormalities detected in local regions. Global relative positions of such abnormalities may help distinguish similar conditions, such as COVID-19 and viral pneumonia. In such instances, a global attention mechanism is needed, which CNNs do not support in their traditional architectures that aim for generalization afforded by translation invariance and equivariance. Vision Transformers provide a global attention mechanism, but lack translation invariance and equivariance, requiring significantly more training data samples to match generalization of CNNs. To address the loss of spatial information and global relations between features, while preserving the inductive biases of CNNs, we present a novel technique that serves as an auxiliary attention mechanism to existing CNN architectures, in order to extract global correlations between salient features.
Belief Evolution Network: Probability Transformation of Basic Belief Assignment and Fusion Conflict Probability
Oct 07, 2021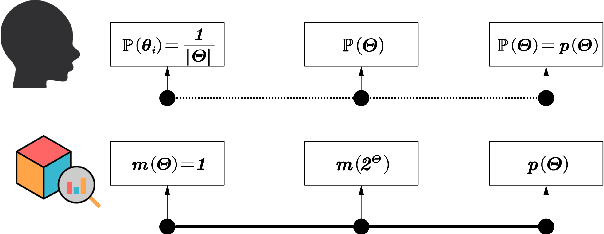
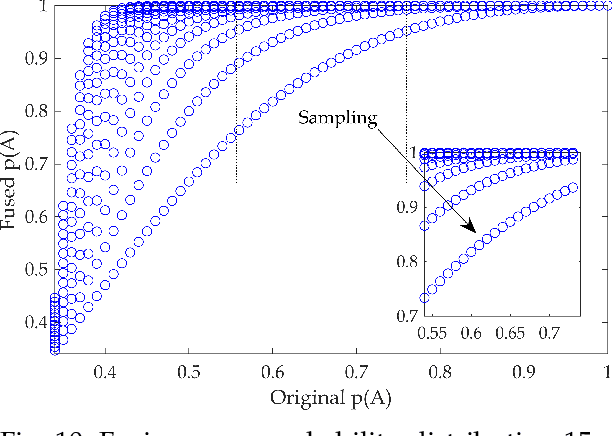
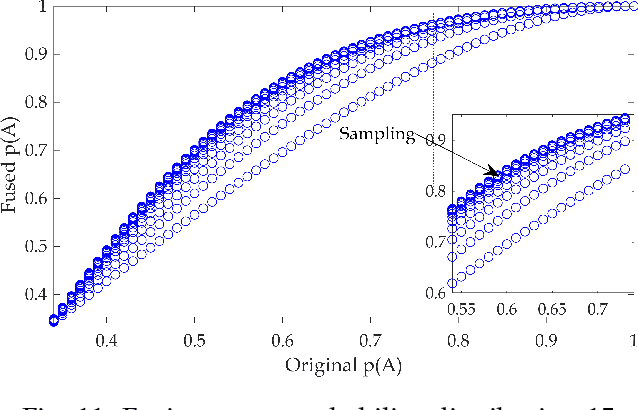
We give a new interpretation of basic belief assignment transformation into probability distribution, and use directed acyclic network called belief evolution network to describe the causality between the focal elements of a BBA. On this basis, a new probability transformations method called full causality probability transformation is proposed, and this method is superior to all previous method after verification from the process and the result. In addition, using this method combined with disjunctive combination rule, we propose a new probabilistic combination rule called disjunctive transformation combination rule. It has an excellent ability to merge conflicts and an interesting pseudo-Matthew effect, which offer a new idea to information fusion besides the combination rule of Dempster.
A General Framework for Information Extraction using Dynamic Span Graphs
Apr 05, 2019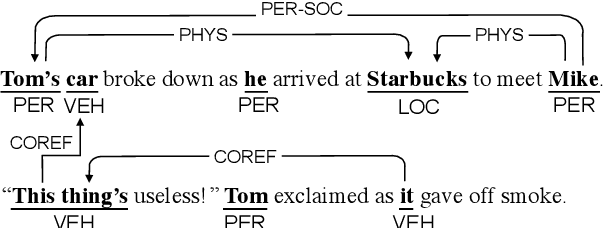
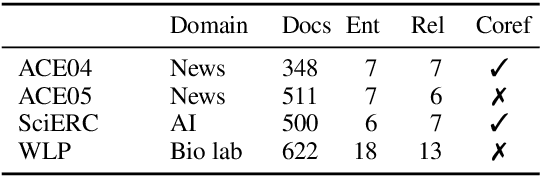
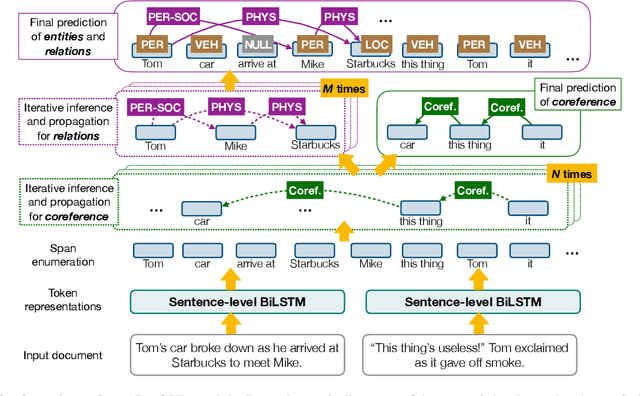
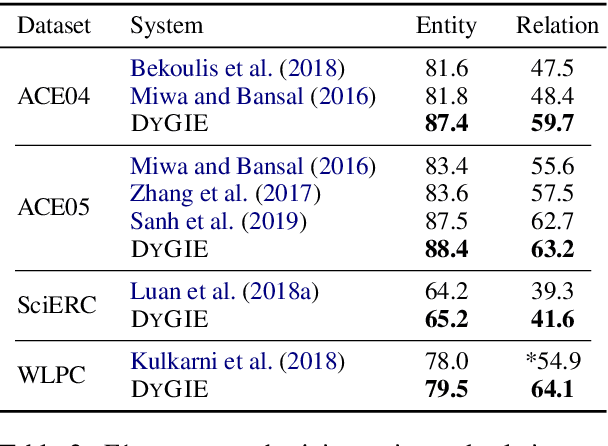
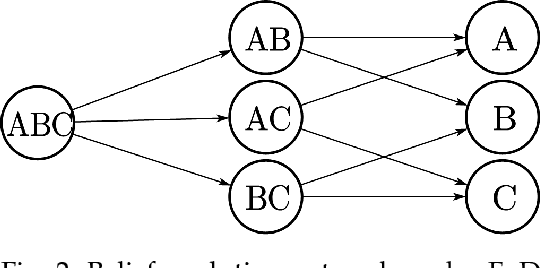
We introduce a general framework for several information extraction tasks that share span representations using dynamically constructed span graphs. The graphs are constructed by selecting the most confident entity spans and linking these nodes with confidence-weighted relation types and coreferences. The dynamic span graph allows coreference and relation type confidences to propagate through the graph to iteratively refine the span representations. This is unlike previous multi-task frameworks for information extraction in which the only interaction between tasks is in the shared first-layer LSTM. Our framework significantly outperforms the state-of-the-art on multiple information extraction tasks across multiple datasets reflecting different domains. We further observe that the span enumeration approach is good at detecting nested span entities, with significant F1 score improvement on the ACE dataset.
Data-Efficient Mutual Information Neural Estimator
May 24, 2019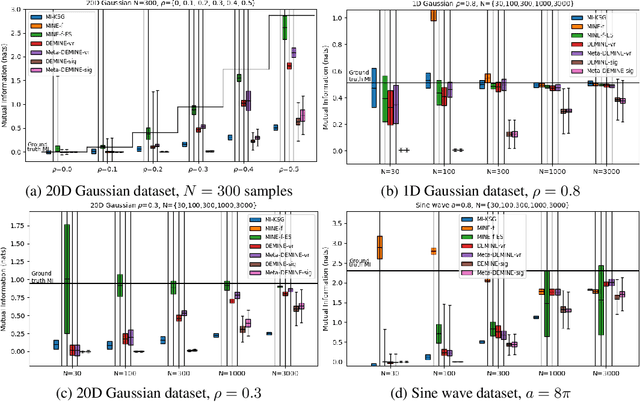
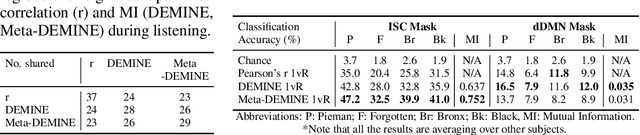
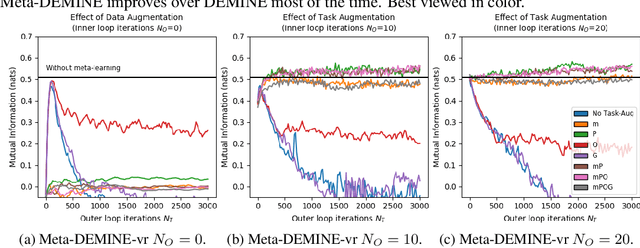
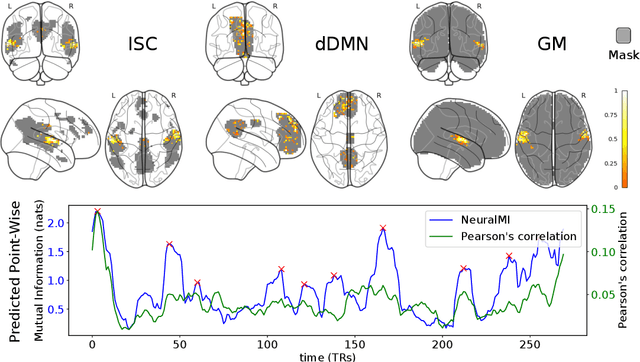
Measuring Mutual Information (MI) between high-dimensional, continuous, random variables from observed samples has wide theoretical and practical applications. Recent work, MINE (Belghazi et al. 2018), focused on estimating tight variational lower bounds of MI using neural networks, but assumed unlimited supply of samples to prevent overfitting. In real world applications, data is not always available at a surplus. In this work, we focus on improving data efficiency and propose a Data-Efficient MINE Estimator (DEMINE), by developing a relaxed predictive MI lower bound that can be estimated at higher data efficiency by orders of magnitudes. The predictive MI lower bound also enables us to develop a new meta-learning approach using task augmentation, Meta-DEMINE, to improve generalization of the network and further boost estimation accuracy empirically. With improved data-efficiency, our estimators enables statistical testing of dependency at practical dataset sizes. We demonstrate the effectiveness of our estimators on synthetic benchmarks and a real world fMRI data, with application of inter-subject correlation analysis.
Revealing and Protecting Labels in Distributed Training
Oct 31, 2021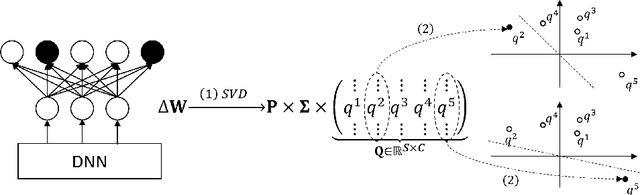
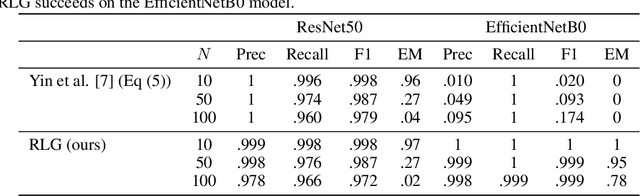
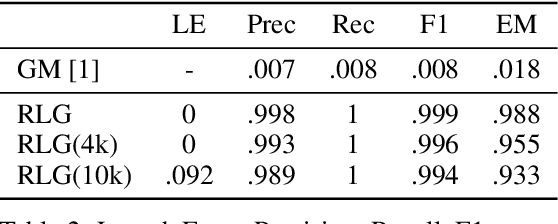
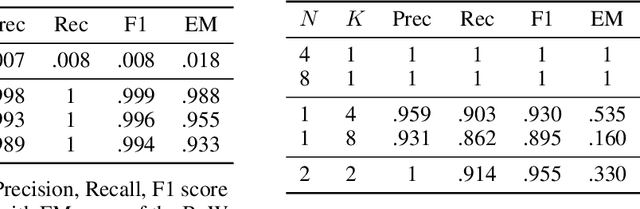
Distributed learning paradigms such as federated learning often involve transmission of model updates, or gradients, over a network, thereby avoiding transmission of private data. However, it is possible for sensitive information about the training data to be revealed from such gradients. Prior works have demonstrated that labels can be revealed analytically from the last layer of certain models (e.g., ResNet), or they can be reconstructed jointly with model inputs by using Gradients Matching [Zhu et al'19] with additional knowledge about the current state of the model. In this work, we propose a method to discover the set of labels of training samples from only the gradient of the last layer and the id to label mapping. Our method is applicable to a wide variety of model architectures across multiple domains. We demonstrate the effectiveness of our method for model training in two domains - image classification, and automatic speech recognition. Furthermore, we show that existing reconstruction techniques improve their efficacy when used in conjunction with our method. Conversely, we demonstrate that gradient quantization and sparsification can significantly reduce the success of the attack.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021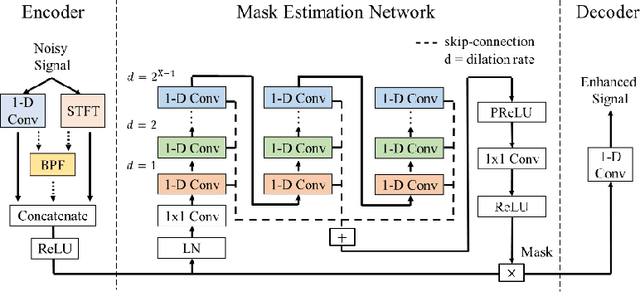
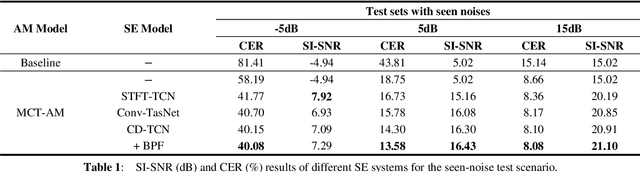
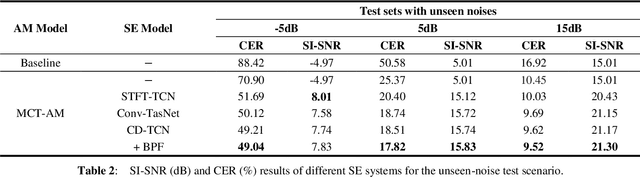
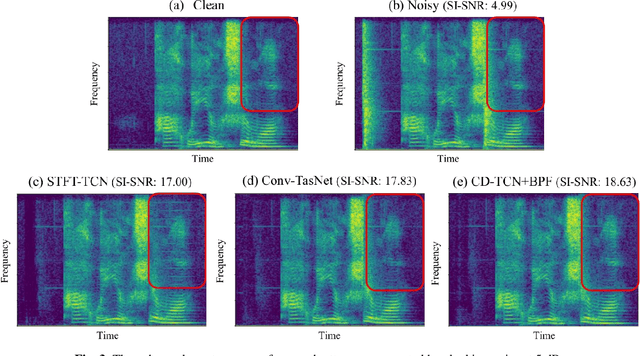
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
A Multi-input Multi-output Transformer-based Hybrid Neural Network for Multi-class Privacy Disclosure Detection
Aug 19, 2021
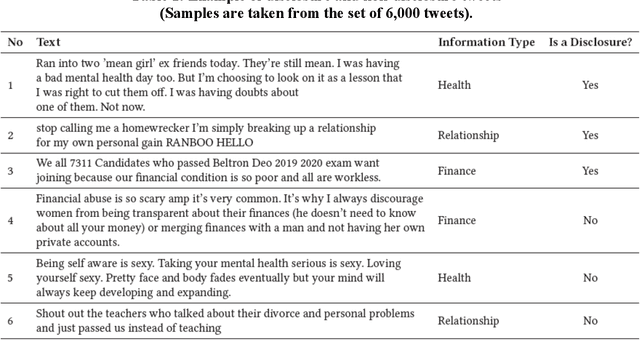
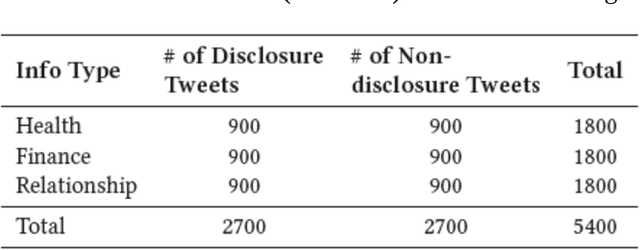

The concern regarding users' data privacy has risen to its highest level due to the massive increase in communication platforms, social networking sites, and greater users' participation in online public discourse. An increasing number of people exchange private information via emails, text messages, and social media without being aware of the risks and implications. Researchers in the field of Natural Language Processing (NLP) have concentrated on creating tools and strategies to identify, categorize, and sanitize private information in text data since a substantial amount of data is exchanged in textual form. However, most of the detection methods solely rely on the existence of pre-identified keywords in the text and disregard the inference of the underlying meaning of the utterance in a specific context. Hence, in some situations, these tools and algorithms fail to detect disclosure, or the produced results are miss-classified. In this paper, we propose a multi-input, multi-output hybrid neural network which utilizes transfer-learning, linguistics, and metadata to learn the hidden patterns. Our goal is to better classify disclosure/non-disclosure content in terms of the context of situation. We trained and evaluated our model on a human-annotated ground truth dataset, containing a total of 5,400 tweets. The results show that the proposed model was able to identify privacy disclosure through tweets with an accuracy of 77.4% while classifying the information type of those tweets with an impressive accuracy of 99%, by jointly learning for two separate tasks.
* 20 pages
Towards Domain-Independent and Real-Time Gesture Recognition Using mmWave Signal
Nov 11, 2021
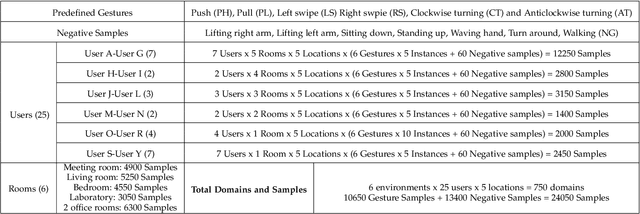


Human gesture recognition using millimeter wave (mmWave) signals provides attractive applications including smart home and in-car interface. While existing works achieve promising performance under controlled settings, practical applications are still limited due to the need of intensive data collection, extra training efforts when adapting to new domains (i.e. environments, persons and locations) and poor performance for real-time recognition. In this paper, we propose DI-Gesture, a domain-independent and real-time mmWave gesture recognition system. Specifically, we first derive the signal variation corresponding to human gestures with spatial-temporal processing. To enhance the robustness of the system and reduce data collecting efforts, we design a data augmentation framework based on the correlation between signal patterns and gesture variations. Furthermore, we propose a dynamic window mechanism to perform gesture segmentation automatically and accurately, thus enable real-time recognition. Finally, we build a lightweight neural network to extract spatial-temporal information from the data for gesture classification. Extensive experimental results show DI-Gesture achieves an average accuracy of 97.92%, 99.18% and 98.76% for new users, environments and locations, respectively. In real-time scenario, the accuracy of DI-Gesutre reaches over 97% with average inference time of 2.87ms, which demonstrates the superior robustness and effectiveness of our system.
Self-supervised High-fidelity and Re-renderable 3D Facial Reconstruction from a Single Image
Nov 16, 2021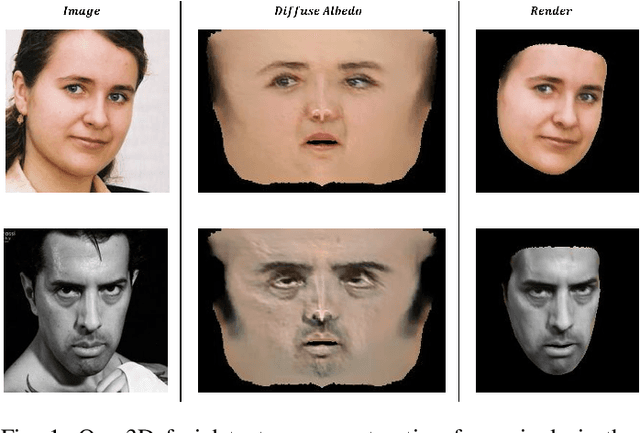

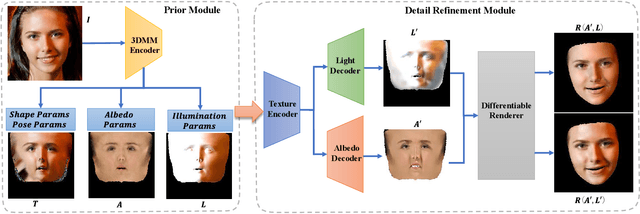

Reconstructing high-fidelity 3D facial texture from a single image is a challenging task since the lack of complete face information and the domain gap between the 3D face and 2D image. The most recent works tackle facial texture reconstruction problem by applying either generation-based or reconstruction-based methods. Although each method has its own advantage, none of them is capable of recovering a high-fidelity and re-renderable facial texture, where the term 're-renderable' demands the facial texture to be spatially complete and disentangled with environmental illumination. In this paper, we propose a novel self-supervised learning framework for reconstructing high-quality 3D faces from single-view images in-the-wild. Our main idea is to first utilize the prior generation module to produce a prior albedo, then leverage the detail refinement module to obtain detailed albedo. To further make facial textures disentangled with illumination, we present a novel detailed illumination representation which is reconstructed with the detailed albedo together. We also design several regularization loss functions on both the albedo side and illumination side to facilitate the disentanglement of these two factors. Finally, thanks to the differentiable rendering technique, our neural network can be efficiently trained in a self-supervised manner. Extensive experiments on challenging datasets demonstrate that our framework substantially outperforms state-of-the-art approaches in both qualitative and quantitative comparisons.
Pairwise Emotional Relationship Recognition in Drama Videos: Dataset and Benchmark
Sep 23, 2021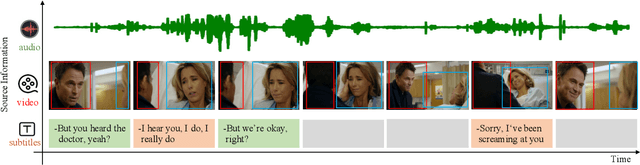
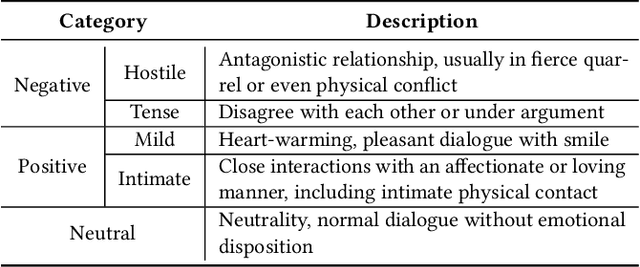
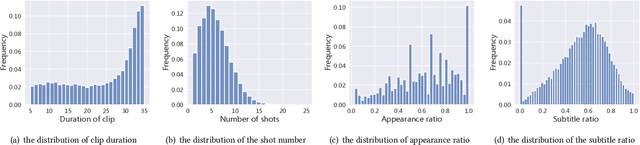
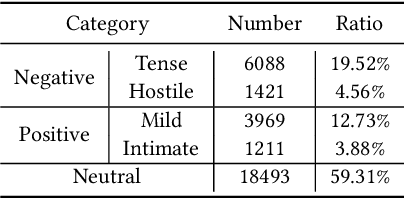
Recognizing the emotional state of people is a basic but challenging task in video understanding. In this paper, we propose a new task in this field, named Pairwise Emotional Relationship Recognition (PERR). This task aims to recognize the emotional relationship between the two interactive characters in a given video clip. It is different from the traditional emotion and social relation recognition task. Varieties of information, consisting of character appearance, behaviors, facial emotions, dialogues, background music as well as subtitles contribute differently to the final results, which makes the task more challenging but meaningful in developing more advanced multi-modal models. To facilitate the task, we develop a new dataset called Emotional RelAtionship of inTeractiOn (ERATO) based on dramas and movies. ERATO is a large-scale multi-modal dataset for PERR task, which has 31,182 video clips, lasting about 203 video hours. Different from the existing datasets, ERATO contains interaction-centric videos with multi-shots, varied video length, and multiple modalities including visual, audio and text. As a minor contribution, we propose a baseline model composed of Synchronous Modal-Temporal Attention (SMTA) unit to fuse the multi-modal information for the PERR task. In contrast to other prevailing attention mechanisms, our proposed SMTA can steadily improve the performance by about 1\%. We expect the ERATO as well as our proposed SMTA to open up a new way for PERR task in video understanding and further improve the research of multi-modal fusion methodology.