 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multi-input Multi-output Transformer-based Hybrid Neural Network for Multi-class Privacy Disclosure Detection
Aug 19, 2021

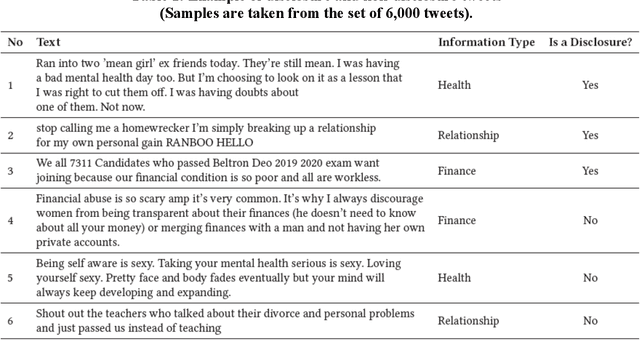
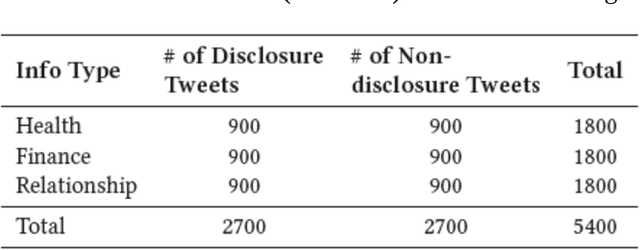

The concern regarding users' data privacy has risen to its highest level due to the massive increase in communication platforms, social networking sites, and greater users' participation in online public discourse. An increasing number of people exchange private information via emails, text messages, and social media without being aware of the risks and implications. Researchers in the field of Natural Language Processing (NLP) have concentrated on creating tools and strategies to identify, categorize, and sanitize private information in text data since a substantial amount of data is exchanged in textual form. However, most of the detection methods solely rely on the existence of pre-identified keywords in the text and disregard the inference of the underlying meaning of the utterance in a specific context. Hence, in some situations, these tools and algorithms fail to detect disclosure, or the produced results are miss-classified. In this paper, we propose a multi-input, multi-output hybrid neural network which utilizes transfer-learning, linguistics, and metadata to learn the hidden patterns. Our goal is to better classify disclosure/non-disclosure content in terms of the context of situation. We trained and evaluated our model on a human-annotated ground truth dataset, containing a total of 5,400 tweets. The results show that the proposed model was able to identify privacy disclosure through tweets with an accuracy of 77.4% while classifying the information type of those tweets with an impressive accuracy of 99%, by jointly learning for two separate tasks.
* 20 pages
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021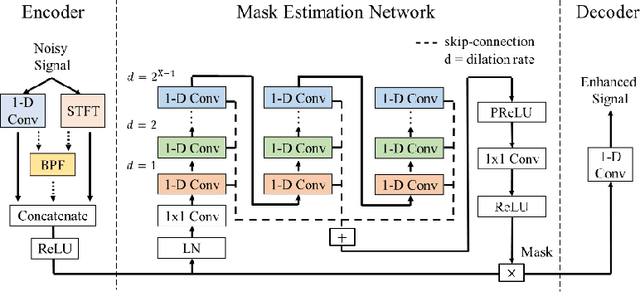
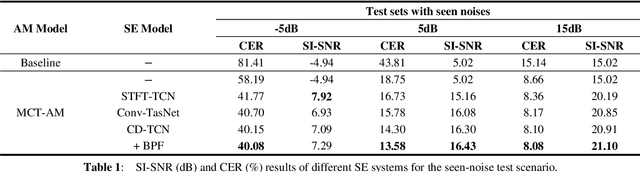
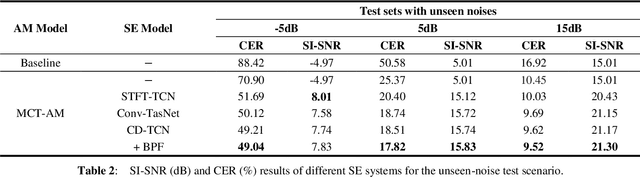
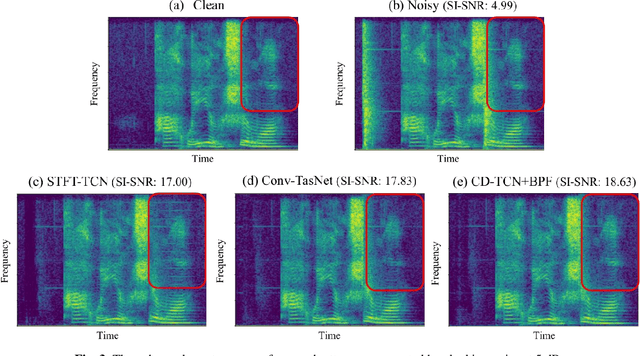
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
Direct source and early reflections localization using deep deconvolution network under reverberant environment
Oct 22, 2021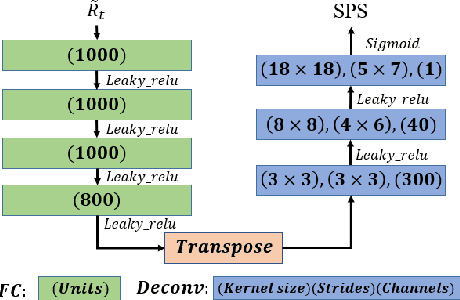
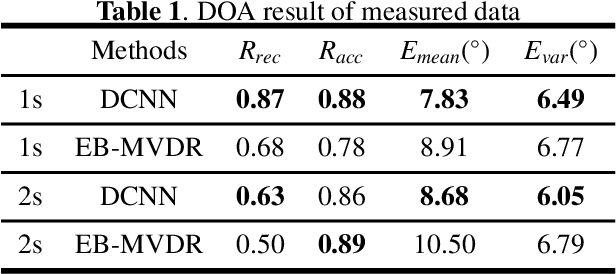
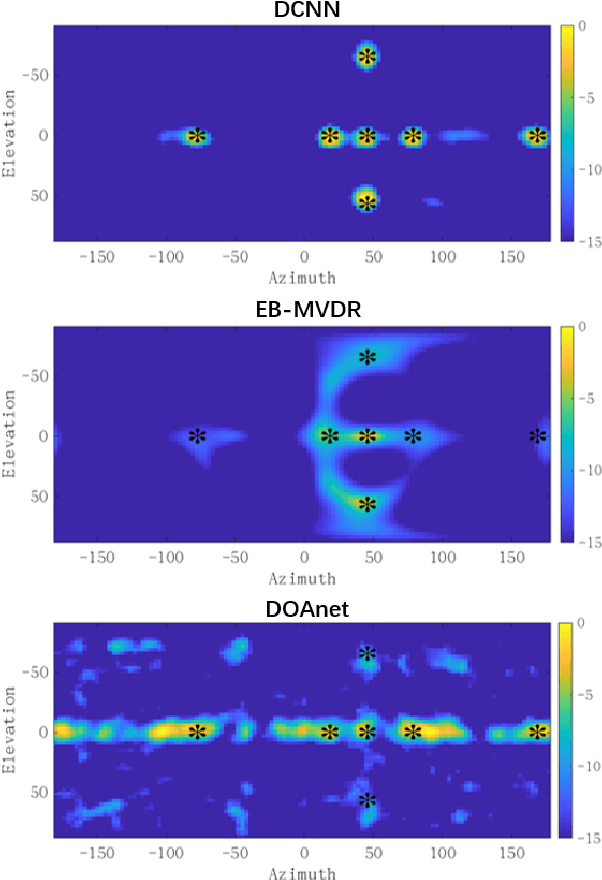
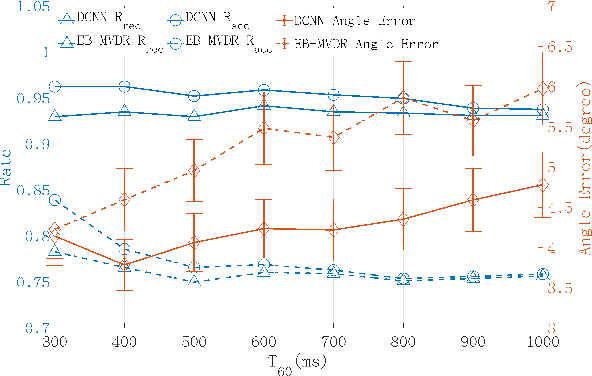
This paper proposes a deconvolution-based network (DCNN) model for DOA estimation of direct source and early reflections under reverberant scenarios. Considering that the first-order reflections of the sound source also contain spatial directivity like the direct source, we treat both of them as the sources in the learning process. We use the covariance matrix of high order Ambisonics (HOA) signals in the time domain as the input feature of the network, which is concise while containing precise spatial information under reverberant scenarios. Besides, we use the deconvolution-based network for the spatial pseudo-spectrum (SPS) reconstruction in the 2D polar space, based on which the spatial relationship between elevation and azimuth can be depicted. We have carried out a series of experiments based on simulated and measured data under different reverberant scenarios, which prove the robustness and accuracy of the proposed DCNN model.
Decoupled Low-light Image Enhancement
Nov 29, 2021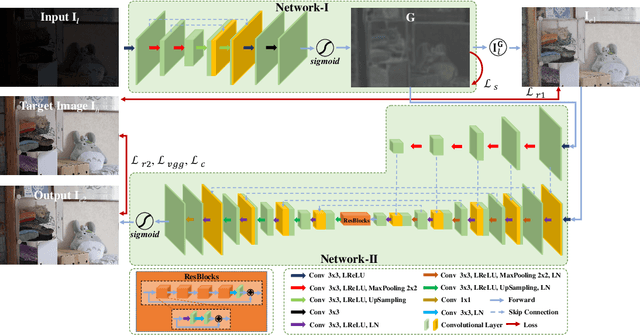
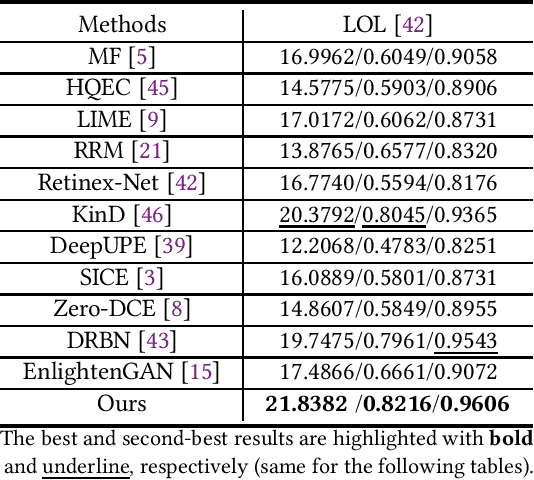

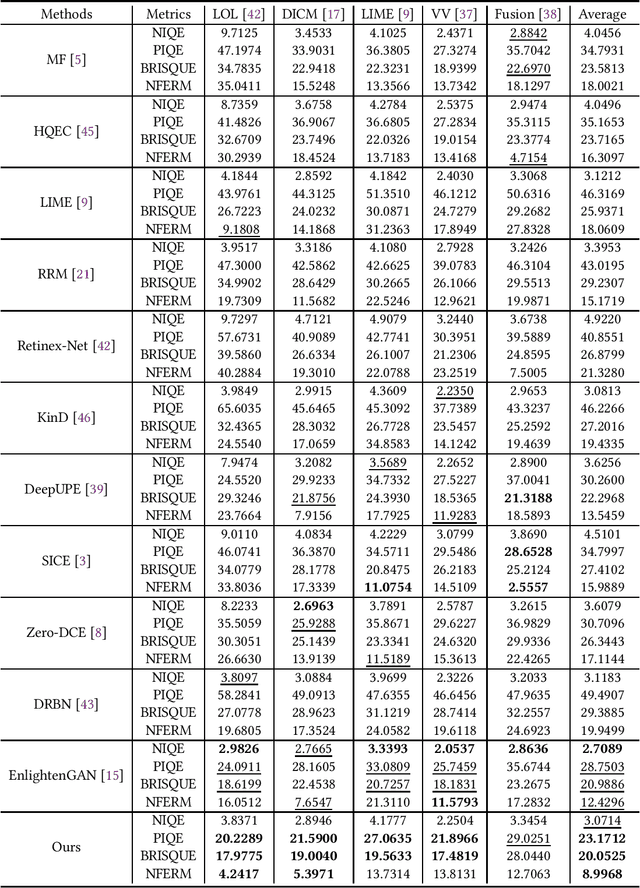
The visual quality of photographs taken under imperfect lightness conditions can be degenerated by multiple factors, e.g., low lightness, imaging noise, color distortion and so on. Current low-light image enhancement models focus on the improvement of low lightness only, or simply deal with all the degeneration factors as a whole, therefore leading to a sub-optimal performance. In this paper, we propose to decouple the enhancement model into two sequential stages. The first stage focuses on improving the scene visibility based on a pixel-wise non-linear mapping. The second stage focuses on improving the appearance fidelity by suppressing the rest degeneration factors. The decoupled model facilitates the enhancement in two aspects. On the one hand, the whole low-light enhancement can be divided into two easier subtasks. The first one only aims to enhance the visibility. It also helps to bridge the large intensity gap between the low-light and normal-light images. In this way, the second subtask can be shaped as the local appearance adjustment. On the other hand, since the parameter matrix learned from the first stage is aware of the lightness distribution and the scene structure, it can be incorporated into the second stage as the complementary information. In the experiments, our model demonstrates the state-of-the-art performance in both qualitative and quantitative comparisons, compared with other low-light image enhancement models. In addition, the ablation studies also validate the effectiveness of our model in multiple aspects, such as model structure and loss function. The trained model is available at https://github.com/hanxuhfut/Decoupled-Low-light-Image-Enhancement.
FDGATII : Fast Dynamic Graph Attention with Initial Residual and Identity Mapping
Oct 25, 2021
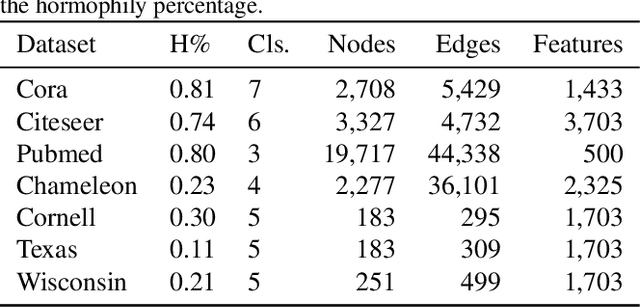
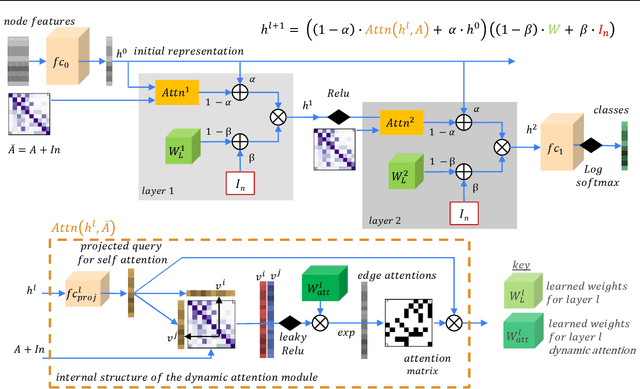
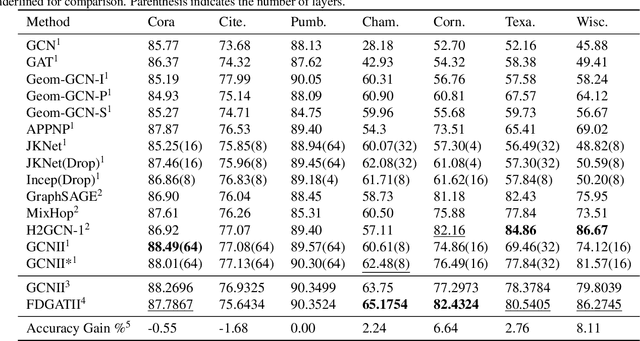
While Graph Neural Networks have gained popularity in multiple domains, graph-structured input remains a major challenge due to (a) over-smoothing, (b) noisy neighbours (heterophily), and (c) the suspended animation problem. To address all these problems simultaneously, we propose a novel graph neural network FDGATII, inspired by attention mechanism's ability to focus on selective information supplemented with two feature preserving mechanisms. FDGATII combines Initial Residuals and Identity Mapping with the more expressive dynamic self-attention to handle noise prevalent from the neighbourhoods in heterophilic data sets. By using sparse dynamic attention, FDGATII is inherently parallelizable in design, whist efficient in operation; thus theoretically able to scale to arbitrary graphs with ease. Our approach has been extensively evaluated on 7 datasets. We show that FDGATII outperforms GAT and GCN based benchmarks in accuracy and performance on fully supervised tasks, obtaining state-of-the-art results on Chameleon and Cornell datasets with zero domain-specific graph pre-processing, and demonstrate its versatility and fairness.
Federated Social Recommendation with Graph Neural Network
Nov 21, 2021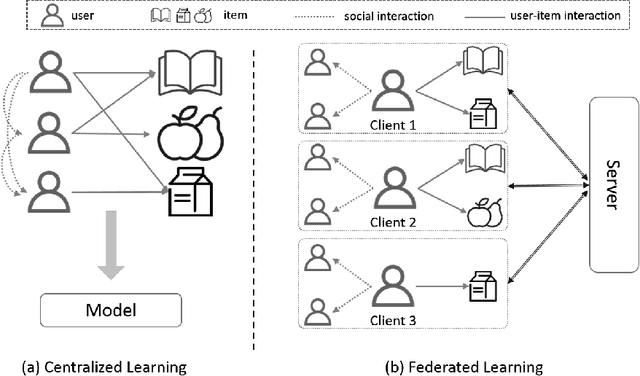


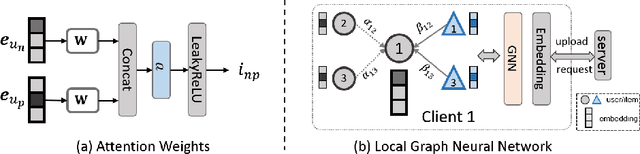
Recommender systems have become prosperous nowadays, designed to predict users' potential interests in items by learning embeddings. Recent developments of the Graph Neural Networks~(GNNs) also provide recommender systems with powerful backbones to learn embeddings from a user-item graph. However, only leveraging the user-item interactions suffers from the cold-start issue due to the difficulty in data collection. Hence, current endeavors propose fusing social information with user-item interactions to alleviate it, which is the social recommendation problem. Existing work employs GNNs to aggregate both social links and user-item interactions simultaneously. However, they all require centralized storage of the social links and item interactions of users, which leads to privacy concerns. Additionally, according to strict privacy protection under General Data Protection Regulation, centralized data storage may not be feasible in the future, urging a decentralized framework of social recommendation. To this end, we devise a novel framework \textbf{Fe}drated \textbf{So}cial recommendation with \textbf{G}raph neural network (FeSoG). Firstly, FeSoG adopts relational attention and aggregation to handle heterogeneity. Secondly, FeSoG infers user embeddings using local data to retain personalization. Last but not least, the proposed model employs pseudo-labeling techniques with item sampling to protect the privacy and enhance training. Extensive experiments on three real-world datasets justify the effectiveness of FeSoG in completing social recommendation and privacy protection. We are the first work proposing a federated learning framework for social recommendation to the best of our knowledge.
The Pareto Frontier of model selection for general Contextual Bandits
Oct 25, 2021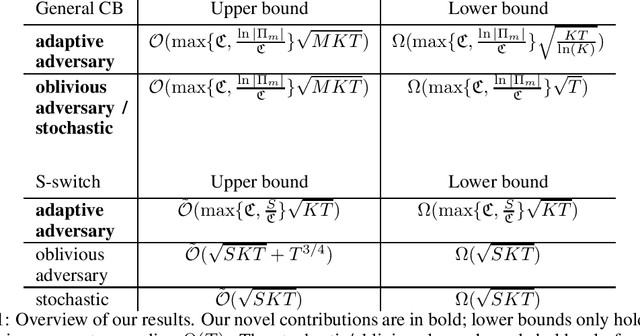
Recent progress in model selection raises the question of the fundamental limits of these techniques. Under specific scrutiny has been model selection for general contextual bandits with nested policy classes, resulting in a COLT2020 open problem. It asks whether it is possible to obtain simultaneously the optimal single algorithm guarantees over all policies in a nested sequence of policy classes, or if otherwise this is possible for a trade-off $\alpha\in[\frac{1}{2},1)$ between complexity term and time: $\ln(|\Pi_m|)^{1-\alpha}T^\alpha$. We give a disappointing answer to this question. Even in the purely stochastic regime, the desired results are unobtainable. We present a Pareto frontier of up to logarithmic factors matching upper and lower bounds, thereby proving that an increase in the complexity term $\ln(|\Pi_m|)$ independent of $T$ is unavoidable for general policy classes. As a side result, we also resolve a COLT2016 open problem concerning second-order bounds in full-information games.
Belief Evolution Network: Probability Transformation of Basic Belief Assignment and Fusion Conflict Probability
Oct 07, 2021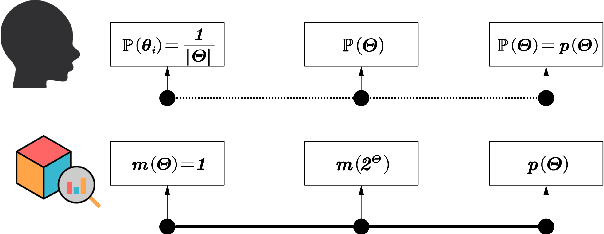
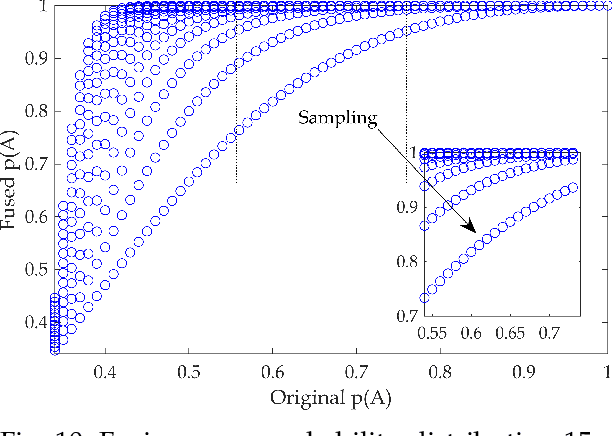
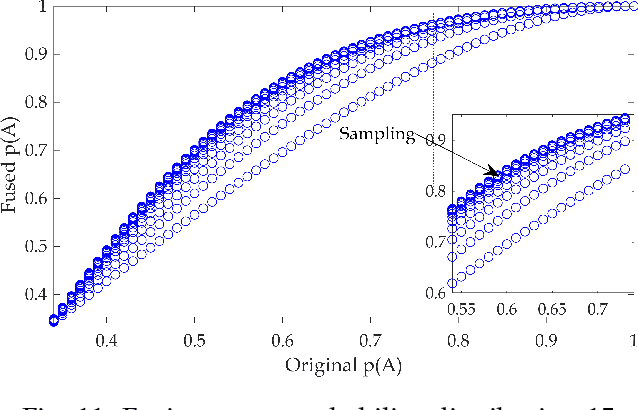
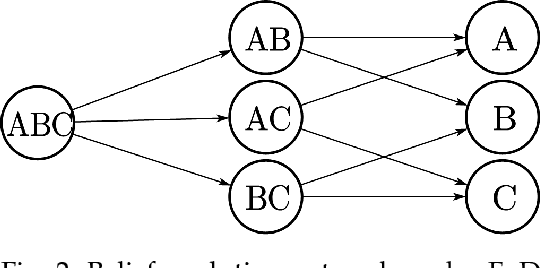
We give a new interpretation of basic belief assignment transformation into probability distribution, and use directed acyclic network called belief evolution network to describe the causality between the focal elements of a BBA. On this basis, a new probability transformations method called full causality probability transformation is proposed, and this method is superior to all previous method after verification from the process and the result. In addition, using this method combined with disjunctive combination rule, we propose a new probabilistic combination rule called disjunctive transformation combination rule. It has an excellent ability to merge conflicts and an interesting pseudo-Matthew effect, which offer a new idea to information fusion besides the combination rule of Dempster.
Homography-based Visual Servoing with Remote Center of Motion for Semi-autonomous Robotic Endoscope Manipulation
Oct 25, 2021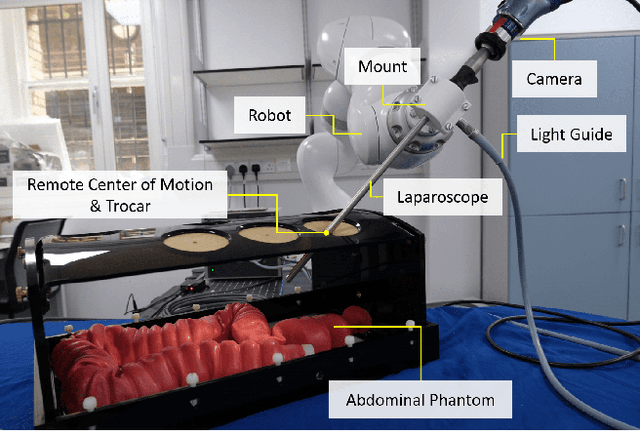
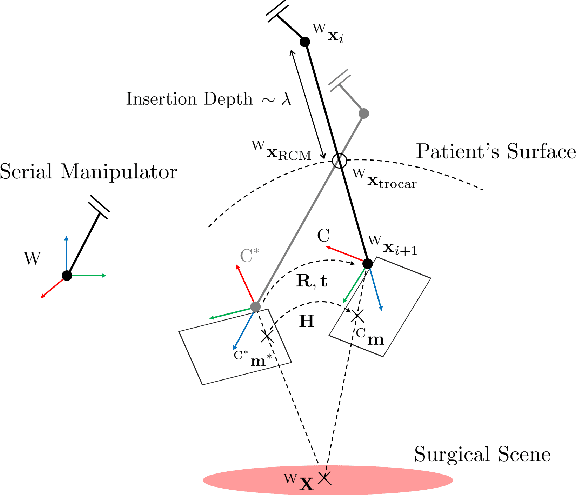
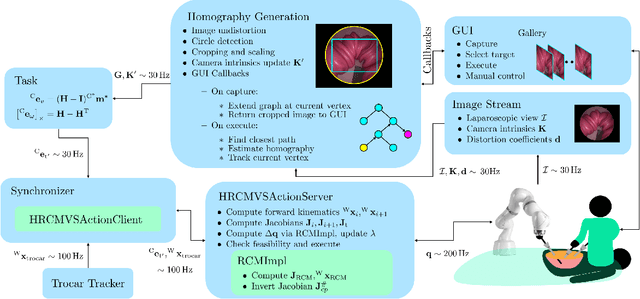
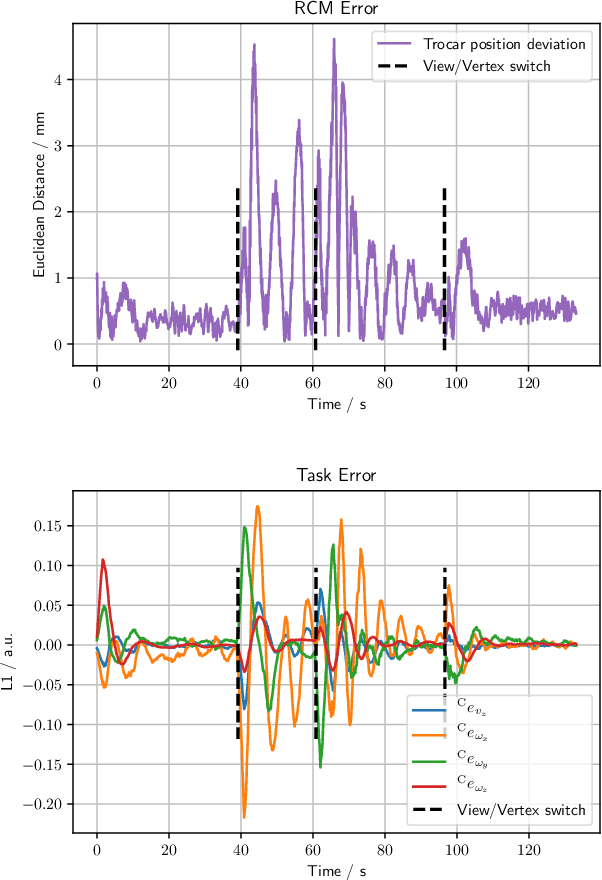
The dominant visual servoing approaches in Minimally Invasive Surgery (MIS) follow single points or adapt the endoscope's field of view based on the surgical tools' distance. These methods rely on point positions with respect to the camera frame to infer a control policy. Deviating from the dominant methods, we formulate a robotic controller that allows for image-based visual servoing that requires neither explicit tool and camera positions nor any explicit image depth information. The proposed method relies on homography-based image registration, which changes the automation paradigm from point-centric towards surgical-scene-centric approach. It simultaneously respects a programmable Remote Center of Motion (RCM). Our approach allows a surgeon to build a graph of desired views, from which, once built, views can be manually selected and automatically servoed to irrespective of robot-patient frame transformation changes. We evaluate our method on an abdominal phantom and provide an open source ROS Moveit integration for use with any serial manipulator.
Efficient Federated Learning for AIoT Applications Using Knowledge Distillation
Nov 29, 2021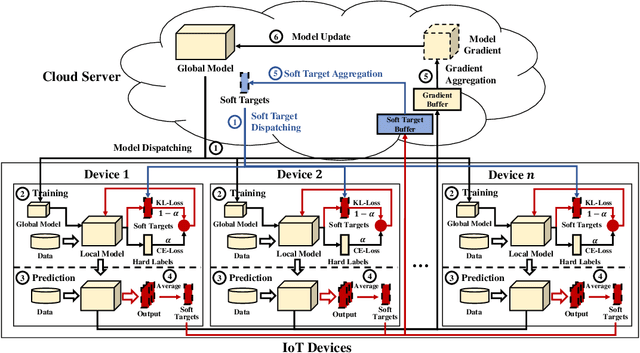
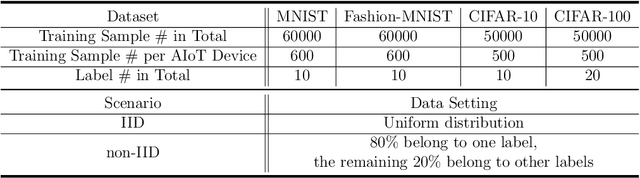
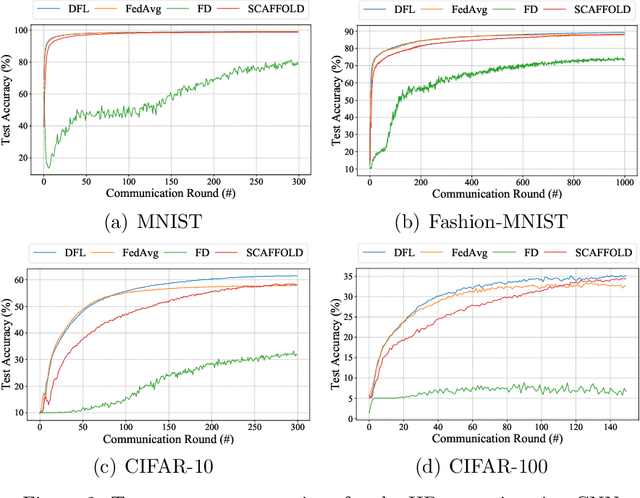
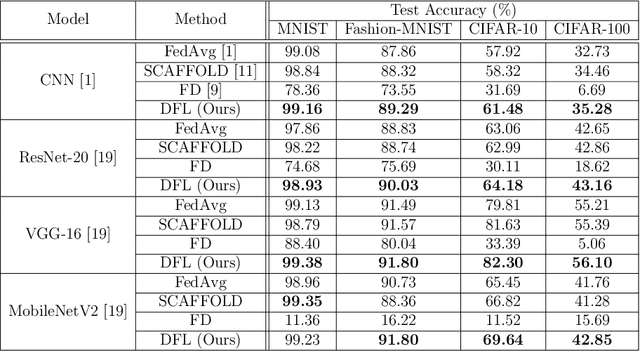
As a promising distributed machine learning paradigm, Federated Learning (FL) trains a central model with decentralized data without compromising user privacy, which has made it widely used by Artificial Intelligence Internet of Things (AIoT) applications. However, the traditional FL suffers from model inaccuracy since it trains local models using hard labels of data and ignores useful information of incorrect predictions with small probabilities. Although various solutions try to tackle the bottleneck of the traditional FL, most of them introduce significant communication and memory overhead, making the deployment of large-scale AIoT devices a great challenge. To address the above problem, this paper presents a novel Distillation-based Federated Learning (DFL) architecture that enables efficient and accurate FL for AIoT applications. Inspired by Knowledge Distillation (KD) that can increase the model accuracy, our approach adds the soft targets used by KD to the FL model training, which occupies negligible network resources. The soft targets are generated by local sample predictions of each AIoT device after each round of local training and used for the next round of model training. During the local training of DFL, both soft targets and hard labels are used as approximation objectives of model predictions to improve model accuracy by supplementing the knowledge of soft targets. To further improve the performance of our DFL model, we design a dynamic adjustment strategy for tuning the ratio of two loss functions used in KD, which can maximize the use of both soft targets and hard labels. Comprehensive experimental results on well-known benchmarks show that our approach can significantly improve the model accuracy of FL with both Independent and Identically Distributed (IID) and non-IID data.