 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PSTN: Periodic Spatial-temporal Deep Neural Network for Traffic Condition Prediction
Aug 05, 2021
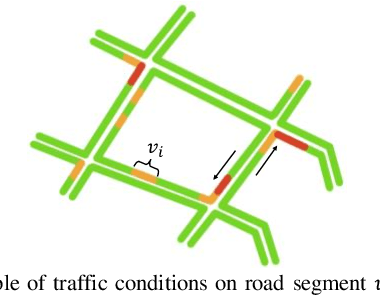
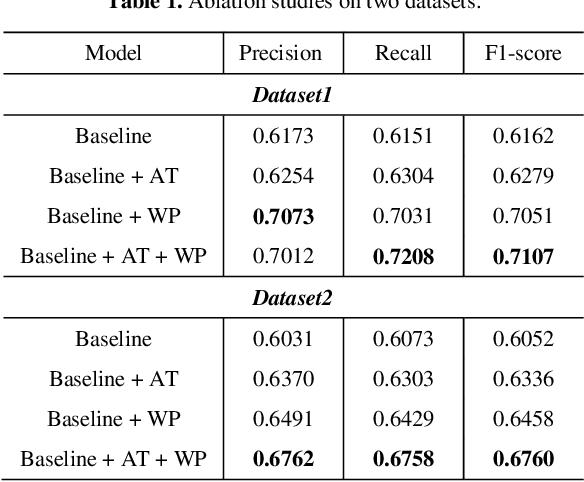
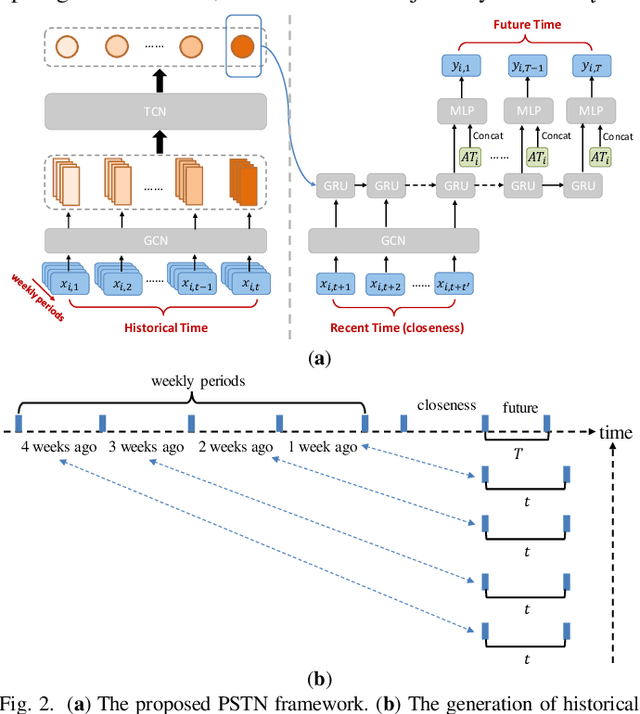
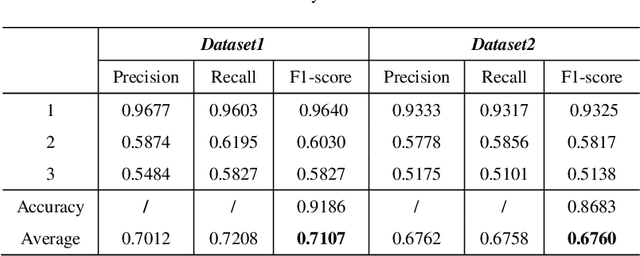
Accurate forecasting of traffic conditions is critical for improving safety, stability, and efficiency of a city transportation system. In reality, it is challenging to produce accurate traffic forecasts due to the complex and dynamic spatiotemporal correlations. Most existing works only consider partial characteristics and features of traffic data, and result in unsatisfactory performances on modeling and forecasting. In this paper, we propose a periodic spatial-temporal deep neural network (PSTN) with three pivotal modules to improve the forecasting performance of traffic conditions through a novel integration of three types of information. First, the historical traffic information is folded and fed into a module consisting of a graph convolutional network and a temporal convolutional network. Second, the recent traffic information together with the historical output passes through the second module consisting of a graph convolutional network and a gated recurrent unit framework. Finally, a multi-layer perceptron is applied to process the auxiliary road attributes and output the final predictions. Experimental results on two publicly accessible real-world urban traffic data sets show that the proposed PSTN outperforms the state-of-the-art benchmarks by significant margins for short-term traffic conditions forecasting
DVM-CAR: A large-scale automotive dataset for visual marketing research and applications
Aug 10, 2021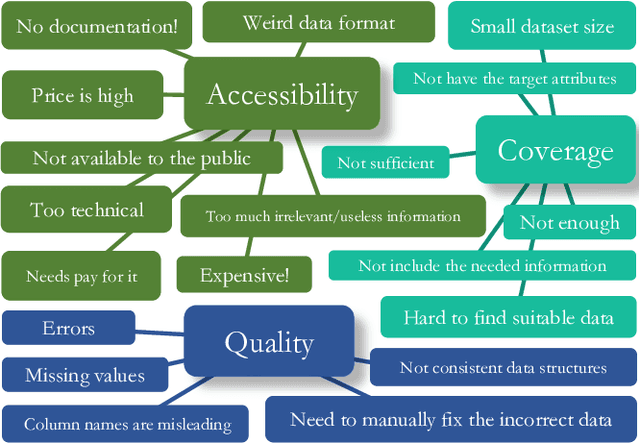
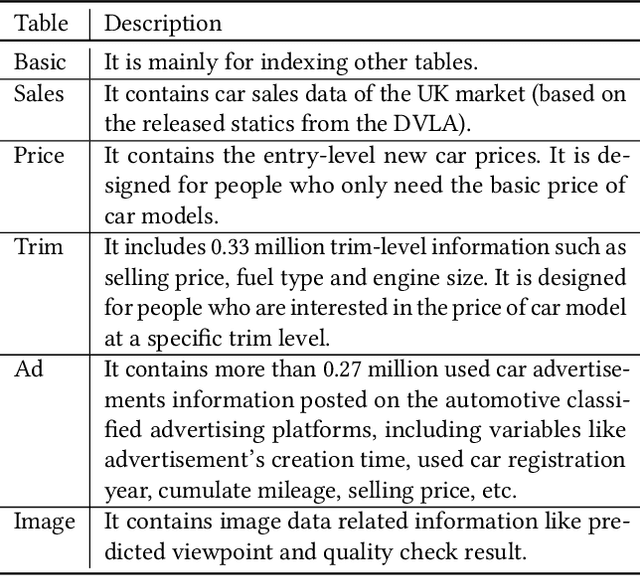

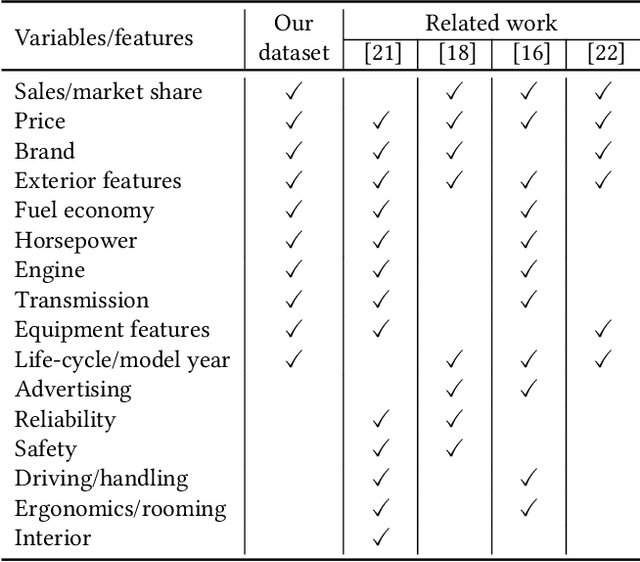
The automotive industry is being transformed by technologies, applications and services ranging from sensors to big data analytics and to artificial intelligence. In this paper, we present our multidisciplinary initiative of creating a publicly available dataset to facilitate the visual-related marketing research and applications in automotive industry such as automotive exterior design, consumer analytics and sales modelling. We are motivated by the fact that there is growing interest in product aesthetics but there is no large-scale dataset available that covers a wide range of variables and information. We summarise the common issues faced by marketing researchers and computer scientists through a user survey study, and design our dataset to alleviate these issues. Our dataset contains 1.4 million images from 899 car models as well as their corresponding car model specification and sales information over more than ten years in the UK market. To the best of our knowledge, this is the very first large-scale automotive dataset which contains images, text and sales information from multiple sources over a long period of time. We describe the detailed data structure and the preparation steps, which we believe has the methodological contribution to the multi-source data fusion and sharing. In addition, we discuss three dataset application examples to illustrate the value of our dataset.
MELONS: generating melody with long-term structure using transformers and structure graph
Oct 12, 2021

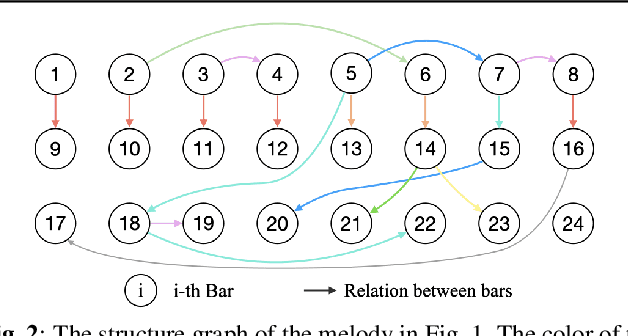
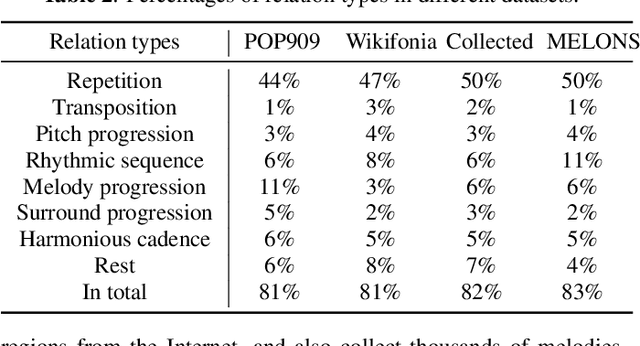
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
Roadside-assisted Cooperative Planning using Future Path Sharing for Autonomous Driving
Aug 10, 2021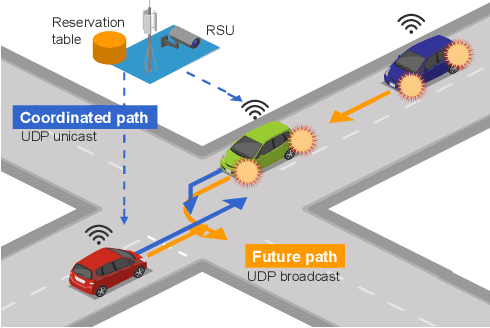
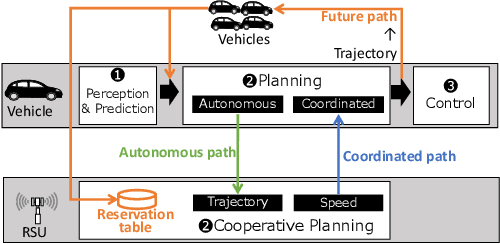
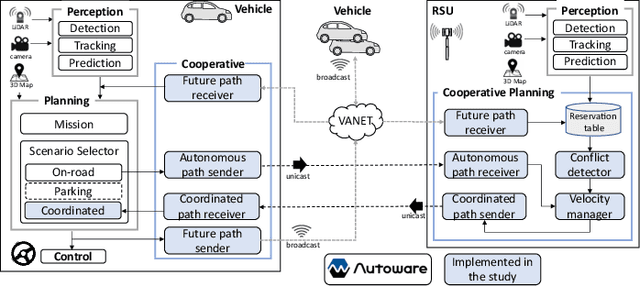
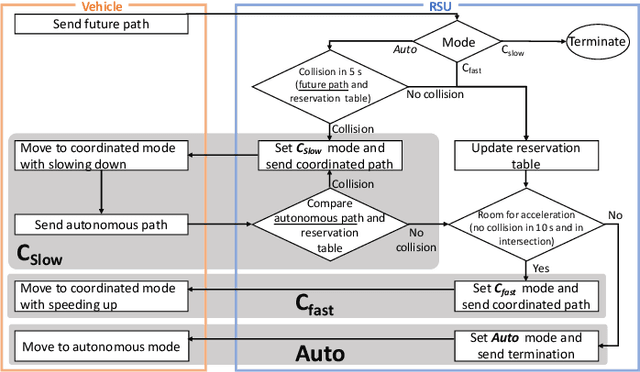
Cooperative intelligent transportation systems (ITS) are used by autonomous vehicles to communicate with surrounding autonomous vehicles and roadside units (RSU). Current C-ITS applications focus primarily on real-time information sharing, such as cooperative perception. In addition to real-time information sharing, self-driving cars need to coordinate their action plans to achieve higher safety and efficiency. For this reason, this study defines a vehicle's future action plan/path and designs a cooperative path-planning model at intersections using future path sharing based on the future path information of multiple vehicles. The notion is that when the RSU detects a potential conflict of vehicle paths or an acceleration opportunity according to the shared future paths, it will generate a coordinated path update that adjusts the speeds of the vehicles. We implemented the proposed method using the open-source Autoware autonomous driving software and evaluated it with the LGSVL autonomous vehicle simulator. We conducted simulation experiments with two vehicles at a blind intersection scenario, finding that each car can travel safely and more efficiently by planning a path that reflects the action plans of all vehicles involved. The time consumed by introducing the RSU is 23.0 % and 28.1 % shorter than that of the stand-alone autonomous driving case at the intersection.
The Faulty GPS Problem: Shortest Time Paths in Networks with Unreliable Directions
Nov 17, 2021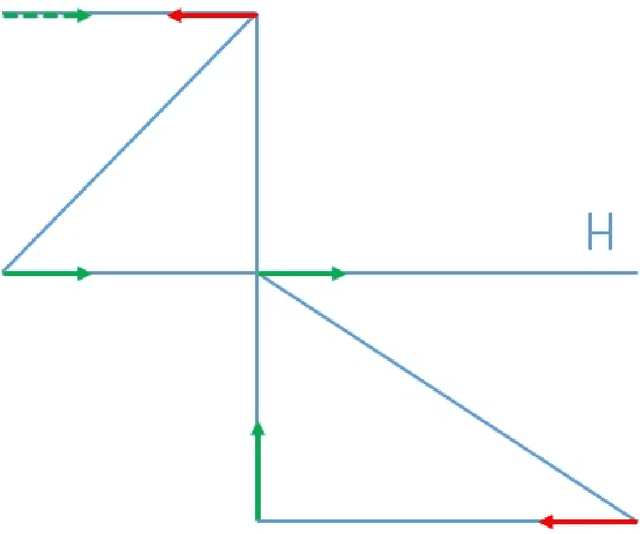
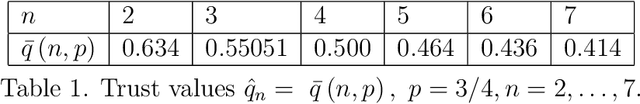
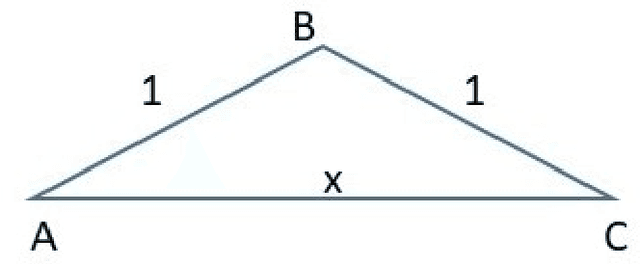
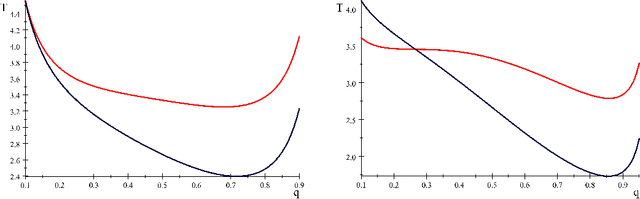
This paper optimizes motion planning when there is a known risk that the road choice suggested by a Satnav (GPS) is not on a shortest path. At every branch node of a network Q, a Satnav (GPS) points to the arc leading to the destination, or home node, H - but only with a high known probability p. Always trusting the Satnav's suggestion may lead to an infinite cycle. If one wishes to reach H in least expected time, with what probability q=q(Q,p) should one trust the pointer (if not, one chooses randomly among the other arcs)? We call this the Faulty Satnav (GPS) Problem. We also consider versions where the trust probability q can depend on the degree of the current node and a `treasure hunt' where two searchers try to reach H first. The agent searching for H need not be a car, that is just a familiar example -- it could equally be a UAV receiving unreliable GPS information. This problem has its origin not in driver frustration but in the work of Fonio et al (2017) on ant navigation, where the pointers correspond to pheromone markers pointing to the nest. Neither the driver or ant will know the exact process by which a choice (arc) is suggested, which puts the problem into the domain of how much to trust an option suggested by AI.
AugmentedCode: Examining the Effects of Natural Language Resources in Code Retrieval Models
Oct 16, 2021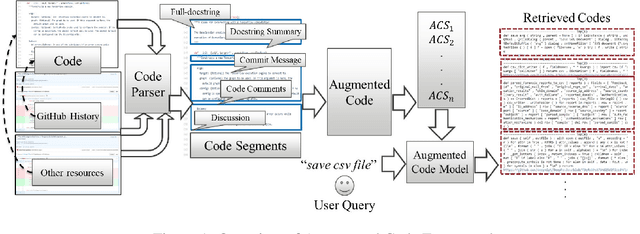

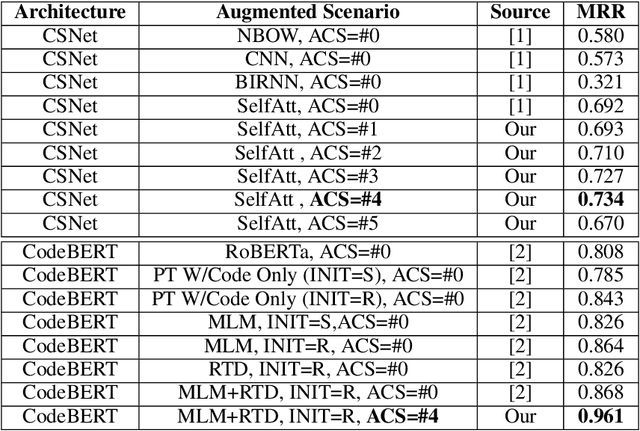
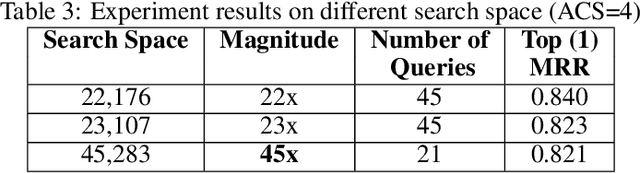
Code retrieval is allowing software engineers to search codes through a natural language query, which relies on both natural language processing and software engineering techniques. There have been several attempts on code retrieval from searching snippet codes to function codes. In this paper, we introduce Augmented Code (AugmentedCode) retrieval which takes advantage of existing information within the code and constructs augmented programming language to improve the code retrieval models' performance. We curated a large corpus of Python and showcased the the framework and the results of augmented programming language which outperforms on CodeSearchNet and CodeBERT with a Mean Reciprocal Rank (MRR) of 0.73 and 0.96, respectively. The outperformed fine-tuned augmented code retrieval model is published in HuggingFace at https://huggingface.co/Fujitsu/AugCode and a demonstration video is available at: https://youtu.be/mnZrUTANjGs .
AI-Based Detection, Classification and Prediction/Prognosis in Medical Imaging: Towards Radiophenomics
Nov 01, 2021
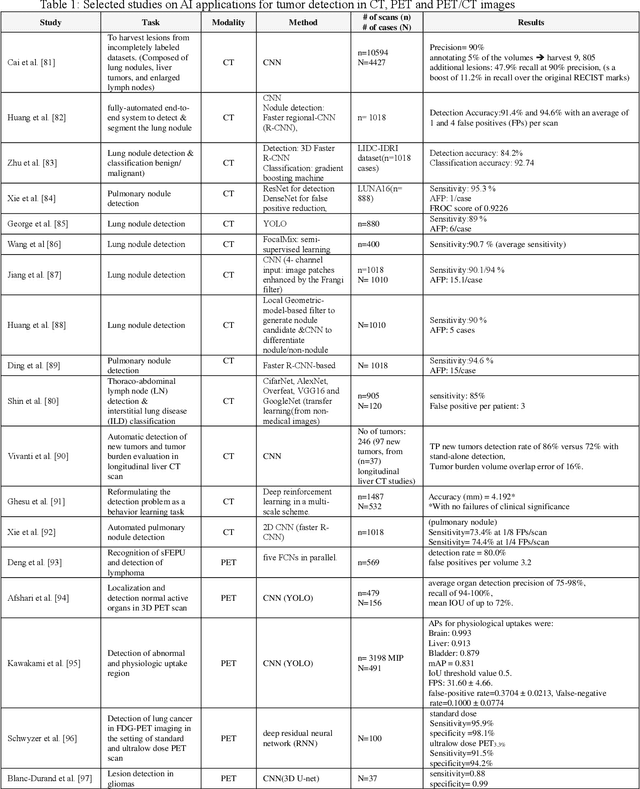

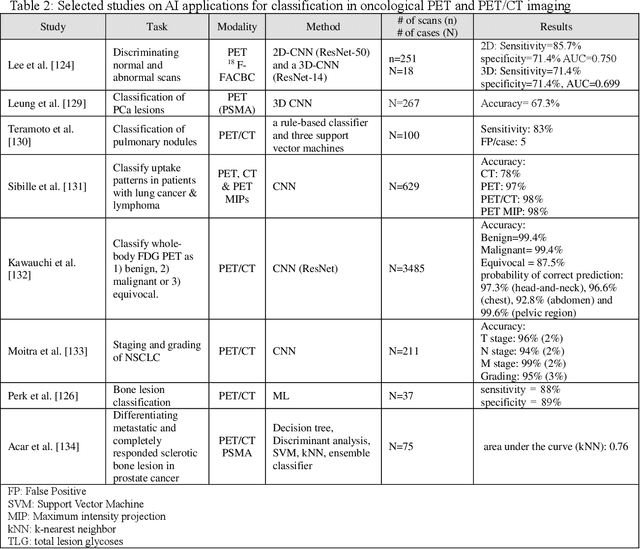
Artificial intelligence (AI) techniques have significant potential to enable effective, robust and automated image phenotyping including identification of subtle patterns. AI-based detection searches the image space to find the regions of interest based on patterns and features. There is a spectrum of tumor histologies from benign to malignant that can be identified by AI-based classification approaches using image features. The extraction of minable information from images gives way to the field of radiomics and can be explored via explicit (handcrafted/engineered) and deep radiomics frameworks. Radiomics analysis has the potential to be utilized as a noninvasive technique for the accurate characterization of tumors to improve diagnosis and treatment monitoring. This work reviews AI-based techniques, with a special focus on oncological PET and PET/CT imaging, for different detection, classification, and prediction/prognosis tasks. We also discuss needed efforts to enable the translation of AI techniques to routine clinical workflows, and potential improvements and complementary techniques such as the use of natural language processing on electronic health records and neuro-symbolic AI techniques.
Goal-Aware Cross-Entropy for Multi-Target Reinforcement Learning
Oct 26, 2021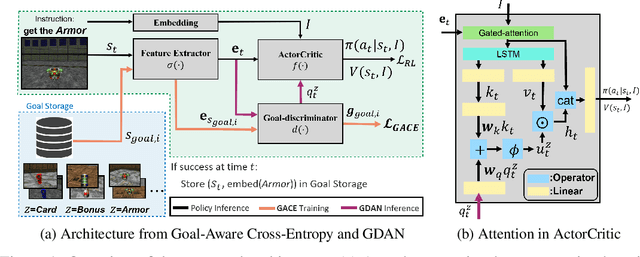
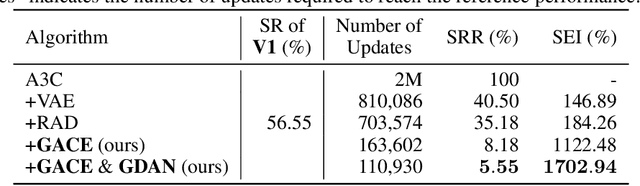


Learning in a multi-target environment without prior knowledge about the targets requires a large amount of samples and makes generalization difficult. To solve this problem, it is important to be able to discriminate targets through semantic understanding. In this paper, we propose goal-aware cross-entropy (GACE) loss, that can be utilized in a self-supervised way using auto-labeled goal states alongside reinforcement learning. Based on the loss, we then devise goal-discriminative attention networks (GDAN) which utilize the goal-relevant information to focus on the given instruction. We evaluate the proposed methods on visual navigation and robot arm manipulation tasks with multi-target environments and show that GDAN outperforms the state-of-the-art methods in terms of task success ratio, sample efficiency, and generalization. Additionally, qualitative analyses demonstrate that our proposed method can help the agent become aware of and focus on the given instruction clearly, promoting goal-directed behavior.
Waveform Learning for Next-Generation Wireless Communication Systems
Sep 02, 2021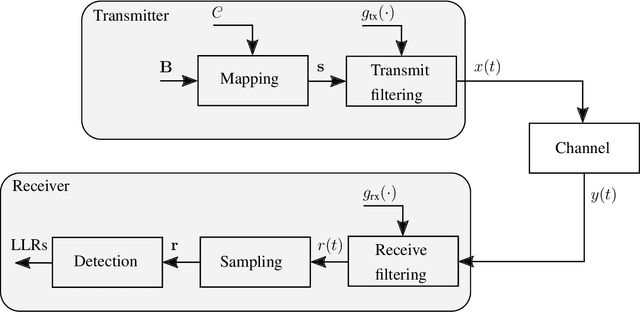
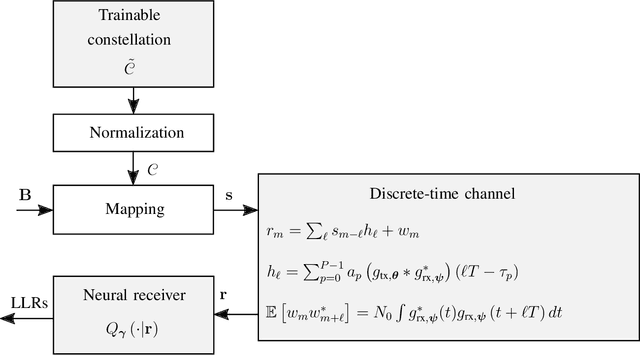
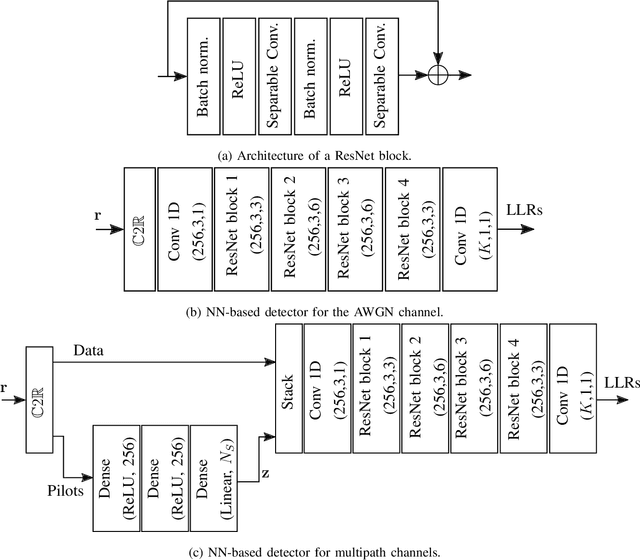
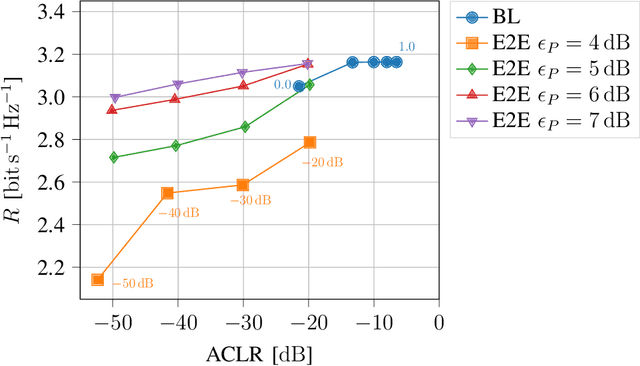
We propose a learning-based method for the joint design of a transmit and receive filter, the constellation geometry and associated bit labeling, as well as a neural network (NN)-based detector. The method maximizes an achievable information rate, while simultaneously satisfying constraints on the adjacent channel leakage ratio (ACLR) and peak-to-average power ratio (PAPR). This allows control of the tradeoff between spectral containment, peak power, and communication rate. Evaluation on an additive white Gaussian noise (AWGN) channel shows significant reduction of ACLR and PAPR compared to a conventional baseline relying on quadrature amplitude modulation (QAM) and root-raised-cosine (RRC), without significant loss of information rate. When considering a 3rd Generation Partnership Project (3GPP) multipath channel, the learned waveform and neural receiver enable competitive or higher rates than an orthogonal frequency division multiplexing (OFDM) baseline, while reducing the ACLR by 10 dB and the PAPR by 2 dB. The proposed method incurs no additional complexity on the transmitter side and might be an attractive tool for waveform design of beyond-5G systems.
Semantic Communication with Adaptive Universal Transformer
Aug 20, 2021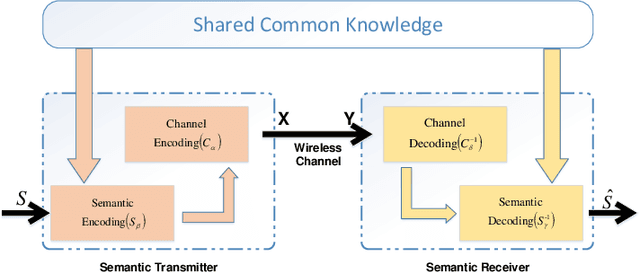
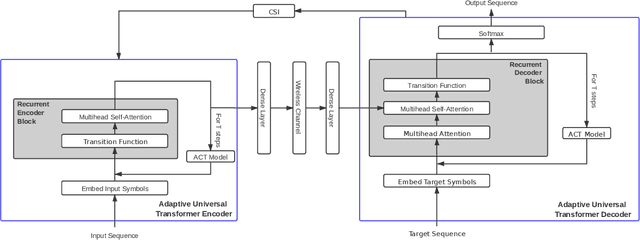
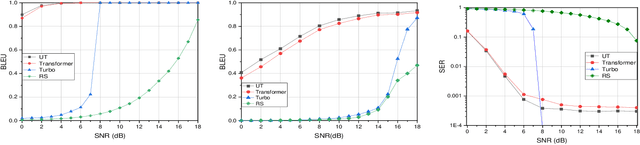
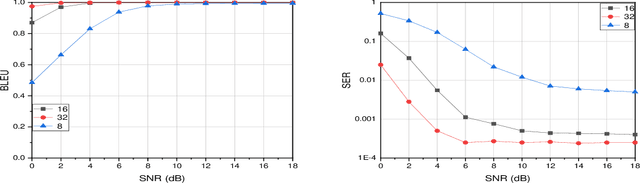
With the development of deep learning (DL), natural language processing (NLP) makes it possible for us to analyze and understand a large amount of language texts. Accordingly, we can achieve a semantic communication in terms of joint semantic source and channel coding over a noisy channel with the help of NLP. However, the existing method to realize this goal is to use a fixed transformer of NLP while ignoring the difference of semantic information contained in each sentence. To solve this problem, we propose a new semantic communication system based on Universal Transformer. Compared with the traditional transformer, an adaptive circulation mechanism is introduced in the Universal Transformer. Through the introduction of the circulation mechanism, the new semantic communication system can be more flexible to transmit sentences with different semantic information, and achieve better end-to-end performance under various channel conditions.