 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021
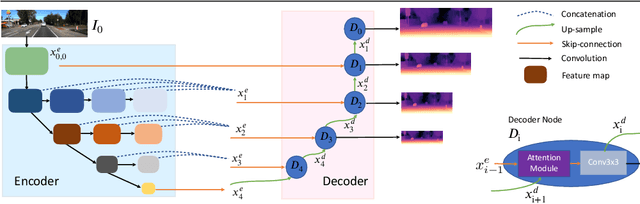
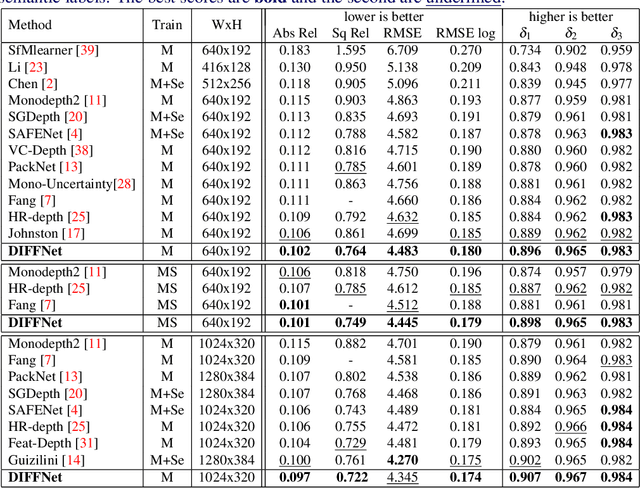

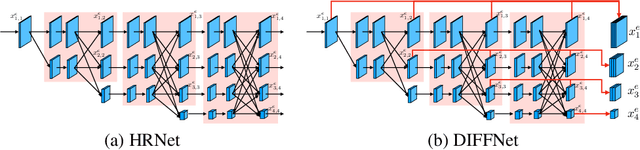
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.
Hyperspectral Mixed Noise Removal via Subspace Representation and Weighted Low-rank Tensor Regularization
Nov 13, 2021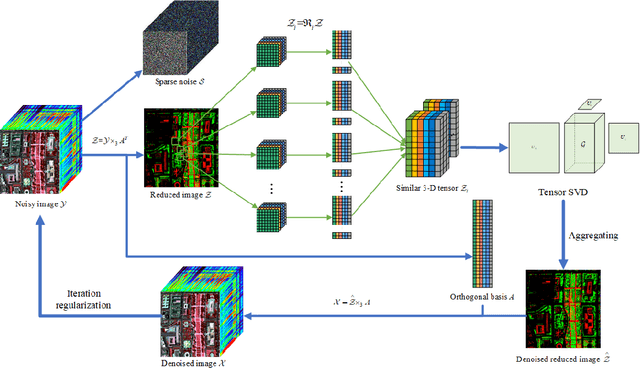


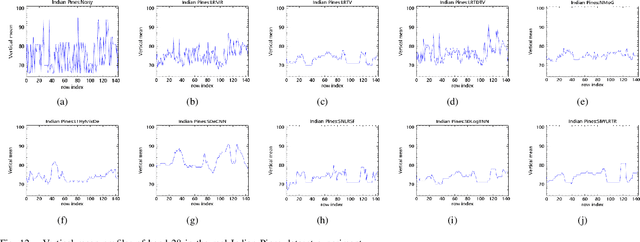
Recently, the low-rank property of different components extracted from the image has been considered in man hyperspectral image denoising methods. However, these methods usually unfold the 3D tensor to 2D matrix or 1D vector to exploit the prior information, such as nonlocal spatial self-similarity (NSS) and global spectral correlation (GSC), which break the intrinsic structure correlation of hyperspectral image (HSI) and thus lead to poor restoration quality. In addition, most of them suffer from heavy computational burden issues due to the involvement of singular value decomposition operation on matrix and tensor in the original high-dimensionality space of HSI. We employ subspace representation and the weighted low-rank tensor regularization (SWLRTR) into the model to remove the mixed noise in the hyperspectral image. Specifically, to employ the GSC among spectral bands, the noisy HSI is projected into a low-dimensional subspace which simplified calculation. After that, a weighted low-rank tensor regularization term is introduced to characterize the priors in the reduced image subspace. Moreover, we design an algorithm based on alternating minimization to solve the nonconvex problem. Experiments on simulated and real datasets demonstrate that the SWLRTR method performs better than other hyperspectral denoising methods quantitatively and visually.
SPAN: Subgraph Prediction Attention Network for Dynamic Graphs
Aug 17, 2021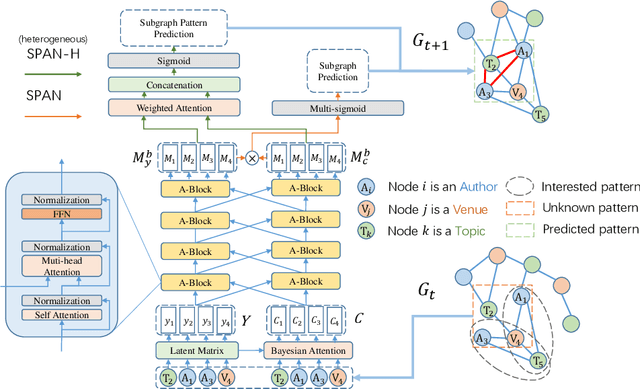
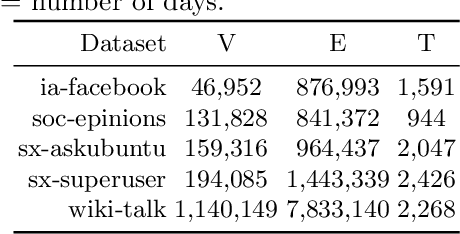
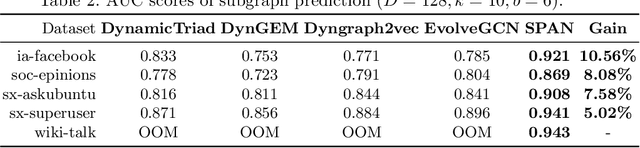
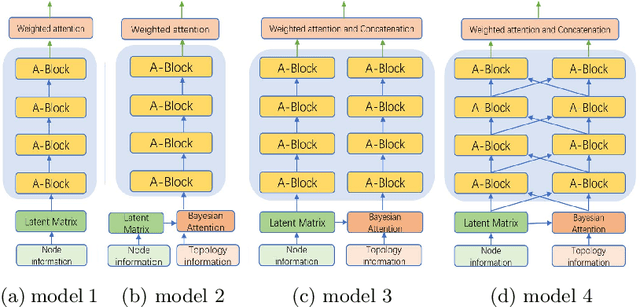
This paper proposes a novel model for predicting subgraphs in dynamic graphs, an extension of traditional link prediction. This proposed end-to-end model learns a mapping from the subgraph structures in the current snapshot to the subgraph structures in the next snapshot directly, i.e., edge existence among multiple nodes in the subgraph. A new mechanism named cross-attention with a twin-tower module is designed to integrate node attribute information and topology information collaboratively for learning subgraph evolution. We compare our model with several state-of-the-art methods for subgraph prediction and subgraph pattern prediction in multiple real-world homogeneous and heterogeneous dynamic graphs, respectively. Experimental results demonstrate that our model outperforms other models in these two tasks, with a gain increase from 5.02% to 10.88%.
HHP-Net: A light Heteroscedastic neural network for Head Pose estimation with uncertainty
Nov 02, 2021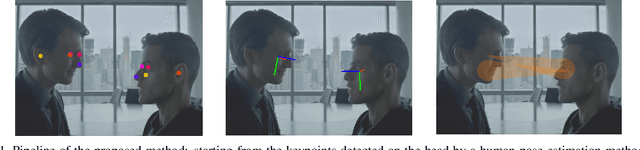
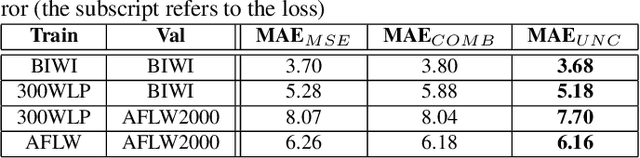
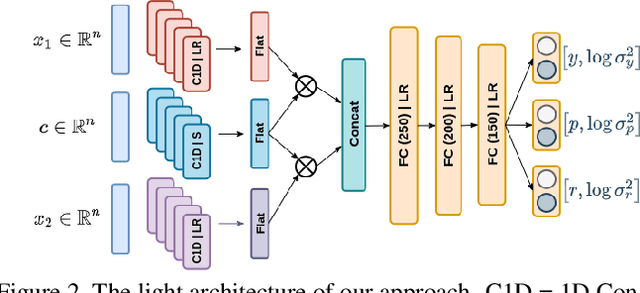
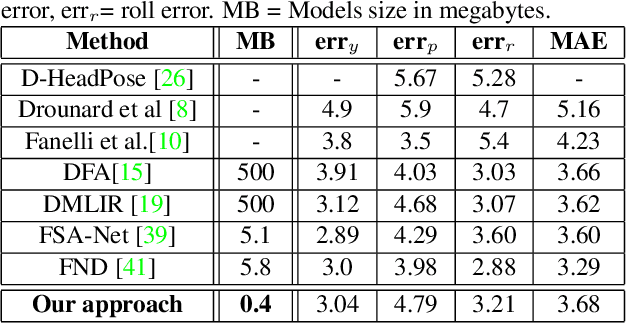
In this paper we introduce a novel method to estimate the head pose of people in single images starting from a small set of head keypoints. To this purpose, we propose a regression model that exploits keypoints computed automatically by 2D pose estimation algorithms and outputs the head pose represented by yaw, pitch, and roll. Our model is simple to implement and more efficient with respect to the state of the art -- faster in inference and smaller in terms of memory occupancy -- with comparable accuracy. Our method also provides a measure of the heteroscedastic uncertainties associated with the three angles, through an appropriately designed loss function; we show there is a correlation between error and uncertainty values, thus this extra source of information may be used in subsequent computational steps. As an example application, we address social interaction analysis in images: we propose an algorithm for a quantitative estimation of the level of interaction between people, starting from their head poses and reasoning on their mutual positions. The code is available at https://github.com/cantarinigiorgio/HHP-Net.
PGNets: Planet mass prediction using convolutional neural networks for radio continuum observations of protoplanetary disks
Nov 30, 2021
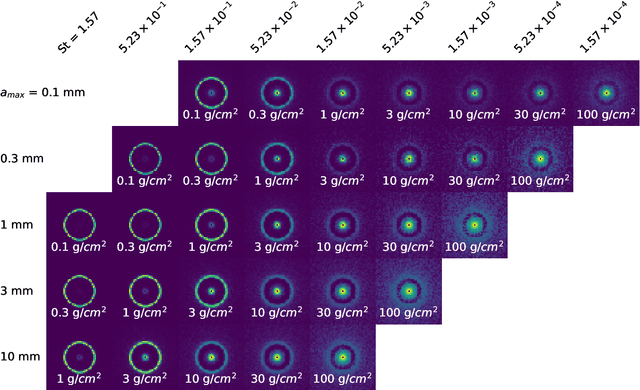
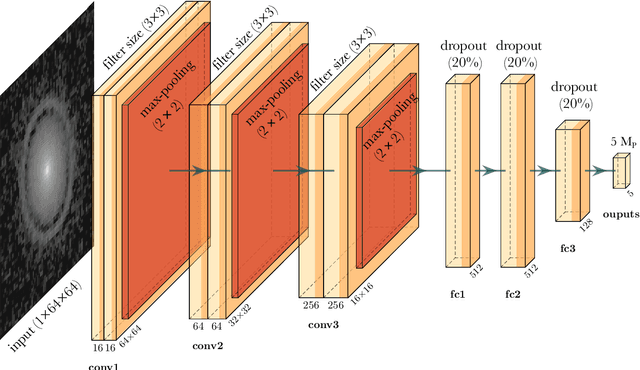
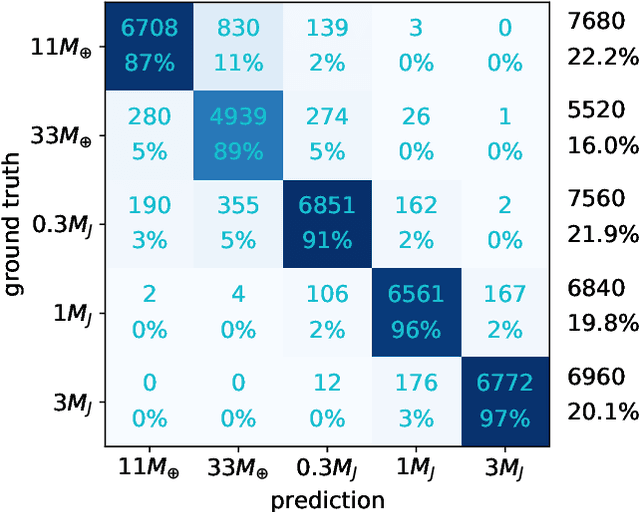
We developed Convolutional Neural Networks (CNNs) to rapidly and directly infer the planet mass from radio dust continuum images. Substructures induced by young planets in protoplanetary disks can be used to infer the potential young planets' properties. Hydrodynamical simulations have been used to study the relationships between the planet's properties and these disk features. However, these attempts either fine-tuned numerical simulations to fit one protoplanetary disk at a time, which was time-consuming, or azimuthally averaged simulation results to derive some linear relationships between the gap width/depth and the planet mass, which lost information on asymmetric features in disks. To cope with these disadvantages, we developed Planet Gap neural Networks (PGNets) to infer the planet mass from 2D images. We first fit the gridded data in Zhang et al. (2018) as a classification problem. Then, we quadrupled the data set by running additional simulations with near-randomly sampled parameters, and derived the planet mass and disk viscosity together as a regression problem. The classification approach can reach an accuracy of 92\%, whereas the regression approach can reach 1$\sigma$ as 0.16 dex for planet mass and 0.23 dex for disk viscosity. We can reproduce the degeneracy scaling $\alpha$ $\propto$ $M_p^3$ found in the linear fitting method, which means that the CNN method can even be used to find degeneracy relationship. The gradient-weighted class activation mapping effectively confirms that PGNets use proper disk features to constrain the planet mass. We provide programs for PGNets and the traditional fitting method from Zhang et al. (2018), and discuss each method's advantages and disadvantages.
DisenHAN: Disentangled Heterogeneous Graph Attention Network for Recommendation
Jun 21, 2021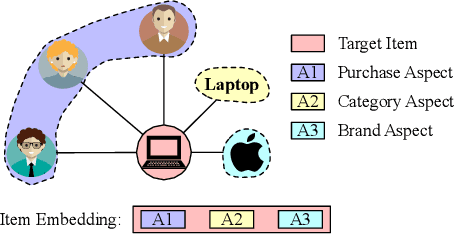
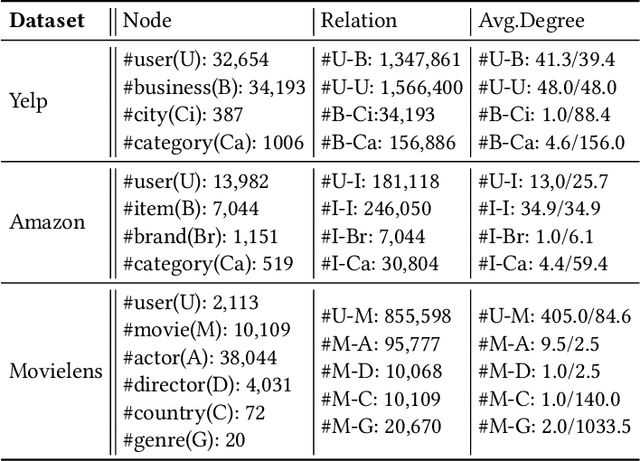
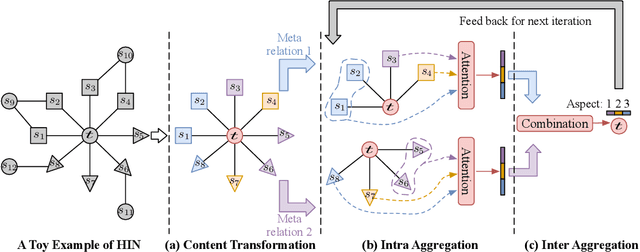

Heterogeneous information network has been widely used to alleviate sparsity and cold start problems in recommender systems since it can model rich context information in user-item interactions. Graph neural network is able to encode this rich context information through propagation on the graph. However, existing heterogeneous graph neural networks neglect entanglement of the latent factors stemming from different aspects. Moreover, meta paths in existing approaches are simplified as connecting paths or side information between node pairs, overlooking the rich semantic information in the paths. In this paper, we propose a novel disentangled heterogeneous graph attention network DisenHAN for top-$N$ recommendation, which learns disentangled user/item representations from different aspects in a heterogeneous information network. In particular, we use meta relations to decompose high-order connectivity between node pairs and propose a disentangled embedding propagation layer which can iteratively identify the major aspect of meta relations. Our model aggregates corresponding aspect features from each meta relation for the target user/item. With different layers of embedding propagation, DisenHAN is able to explicitly capture the collaborative filtering effect semantically. Extensive experiments on three real-world datasets show that DisenHAN consistently outperforms state-of-the-art approaches. We further demonstrate the effectiveness and interpretability of the learned disentangled representations via insightful case studies and visualization.
CATNet: Context AggregaTion Network for Instance Segmentation in Remote Sensing Images
Nov 22, 2021

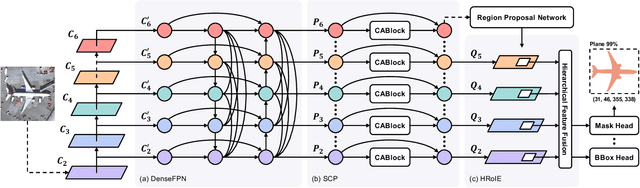
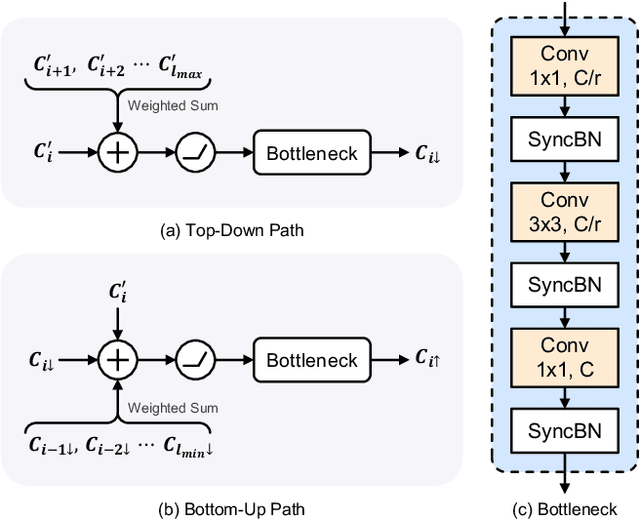
The task of instance segmentation in remote sensing images, aiming at performing per-pixel labeling of objects at instance level, is of great importance for various civil applications. Despite previous successes, most existing instance segmentation methods designed for natural images encounter sharp performance degradations when directly applied to top-view remote sensing images. Through careful analysis, we observe that the challenges mainly come from lack of discriminative object features due to severe scale variations, low contrasts, and clustered distributions. In order to address these problems, a novel context aggregation network (CATNet) is proposed to improve the feature extraction process. The proposed model exploits three lightweight plug-and-play modules, namely dense feature pyramid network (DenseFPN), spatial context pyramid (SCP), and hierarchical region of interest extractor (HRoIE), to aggregate global visual context at feature, spatial, and instance domains, respectively. DenseFPN is a multi-scale feature propagation module that establishes more flexible information flows by adopting inter-level residual connections, cross-level dense connections, and feature re-weighting strategy. Leveraging the attention mechanism, SCP further augments the features by aggregating global spatial context into local regions. For each instance, HRoIE adaptively generates RoI features for different downstream tasks. We carry out extensive evaluation of the proposed scheme on the challenging iSAID, DIOR, NWPU VHR-10, and HRSID datasets. The evaluation results demonstrate that the proposed approach outperforms state-of-the-arts with similar computational costs. Code is available at https://github.com/yeliudev/CATNet.
Does the Data Induce Capacity Control in Deep Learning?
Oct 27, 2021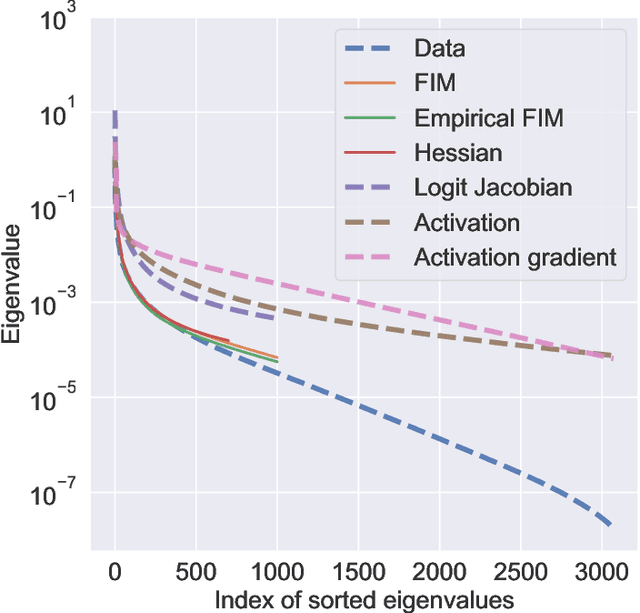
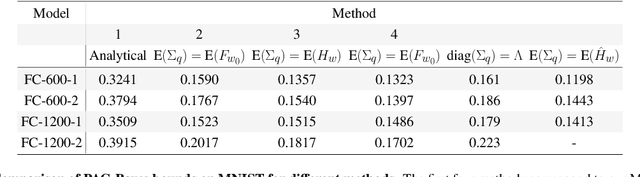
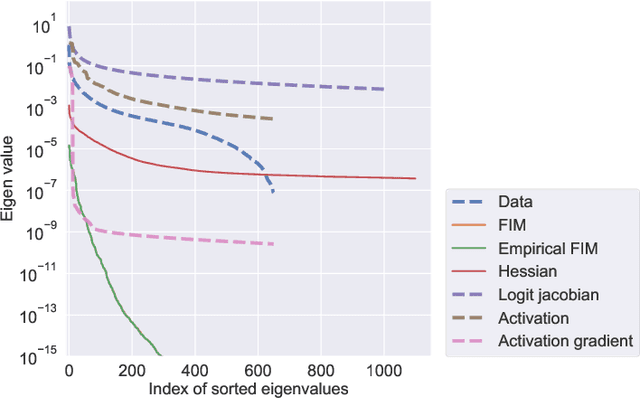
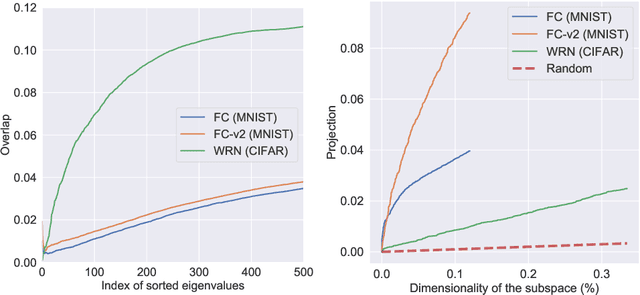
This paper studies how the dataset may be the cause of the anomalous generalization performance of deep networks. We show that the data correlation matrix of typical classification datasets has an eigenspectrum where, after a sharp initial drop, a large number of small eigenvalues are distributed uniformly over an exponentially large range. This structure is mirrored in a network trained on this data: we show that the Hessian and the Fisher Information Matrix (FIM) have eigenvalues that are spread uniformly over exponentially large ranges. We call such eigenspectra "sloppy" because sets of weights corresponding to small eigenvalues can be changed by large magnitudes without affecting the loss. Networks trained on atypical, non-sloppy synthetic data do not share these traits. We show how this structure in the data can give to non-vacuous PAC-Bayes generalization bounds analytically; we also construct data-distribution dependent priors that lead to accurate bounds using numerical optimization.
Federated Causal Inference in Heterogeneous Observational Data
Aug 10, 2021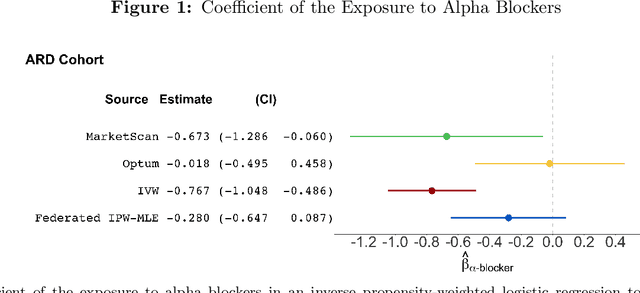

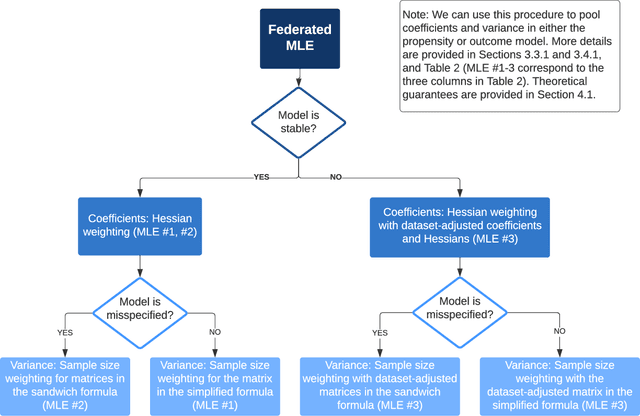
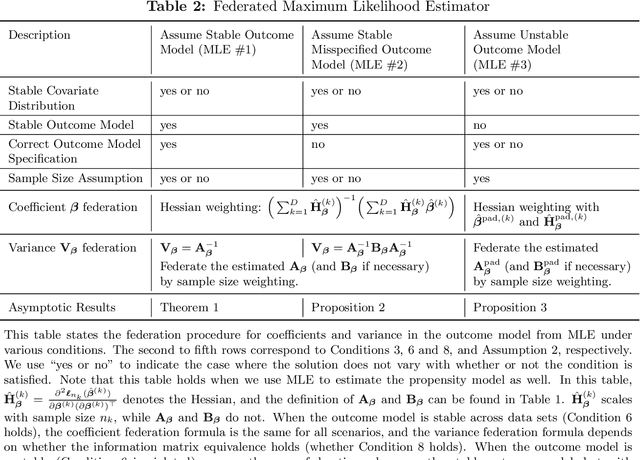
Analyzing observational data from multiple sources can be useful for increasing statistical power to detect a treatment effect; however, practical constraints such as privacy considerations may restrict individual-level information sharing across data sets. This paper develops federated methods that only utilize summary-level information from heterogeneous data sets. Our federated methods provide doubly-robust point estimates of treatment effects as well as variance estimates. We derive the asymptotic distributions of our federated estimators, which are shown to be asymptotically equivalent to the corresponding estimators from the combined, individual-level data. We show that to achieve these properties, federated methods should be adjusted based on conditions such as whether models are correctly specified and stable across heterogeneous data sets.
Metadata-based Multi-Task Bandits with Bayesian Hierarchical Models
Aug 13, 2021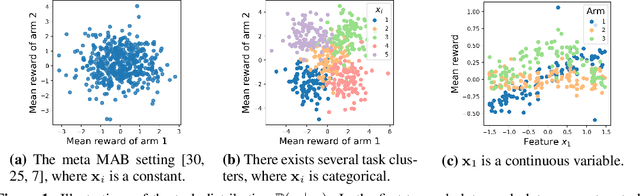

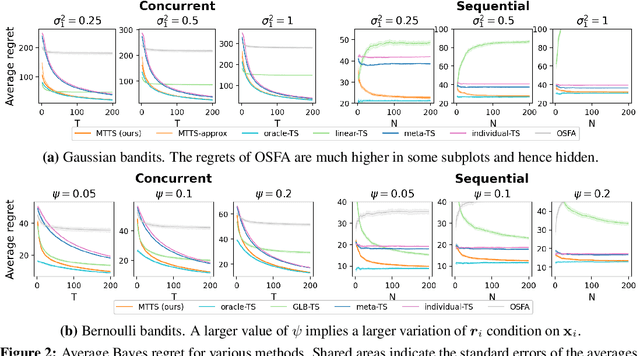
How to explore efficiently is a central problem in multi-armed bandits. In this paper, we introduce the metadata-based multi-task bandit problem, where the agent needs to solve a large number of related multi-armed bandit tasks and can leverage some task-specific features (i.e., metadata) to share knowledge across tasks. As a general framework, we propose to capture task relations through the lens of Bayesian hierarchical models, upon which a Thompson sampling algorithm is designed to efficiently learn task relations, share information, and minimize the cumulative regrets. Two concrete examples for Gaussian bandits and Bernoulli bandits are carefully analyzed. The Bayes regret for Gaussian bandits clearly demonstrates the benefits of information sharing with our algorithm. The proposed method is further supported by extensive experiments.