 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 19, 2021
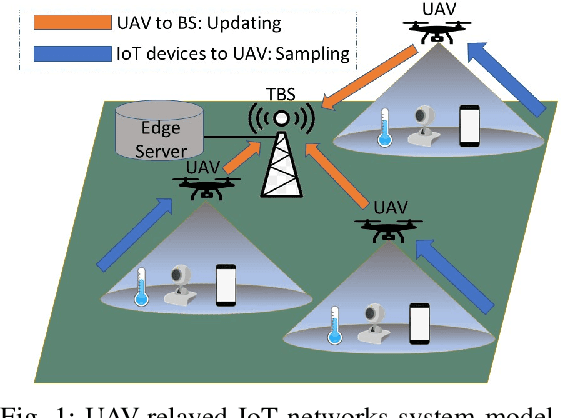
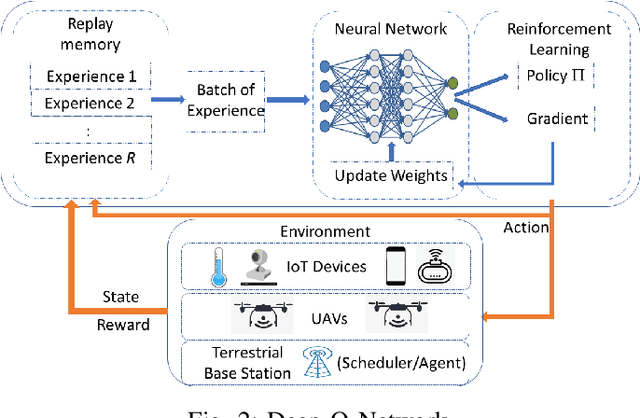
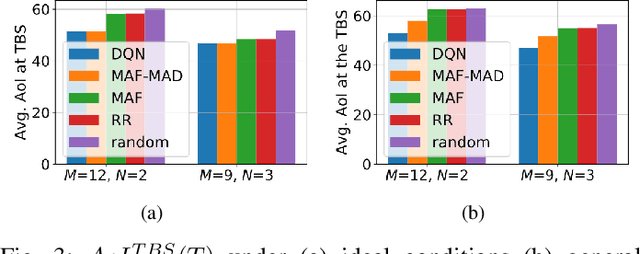
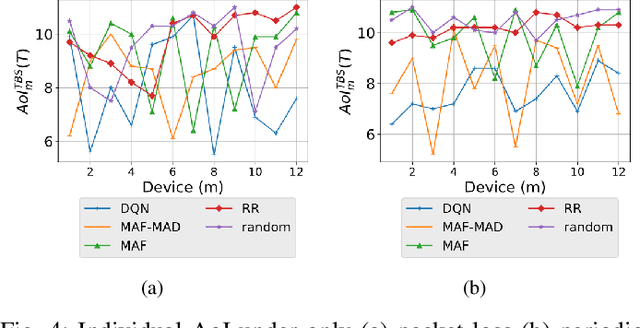
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.
Over-the-Air Aggregation for Federated Learning: Waveform Superposition and Prototype Validation
Oct 27, 2021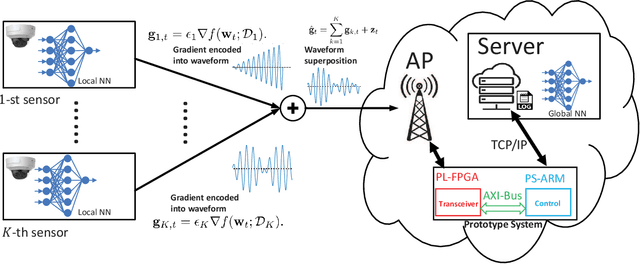
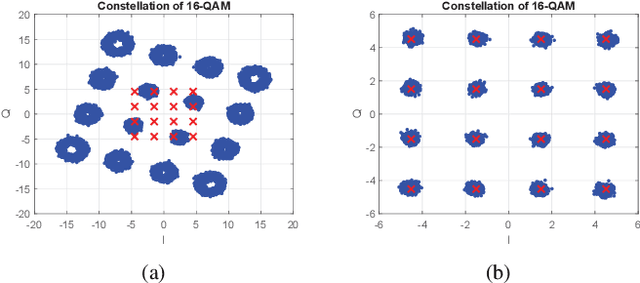
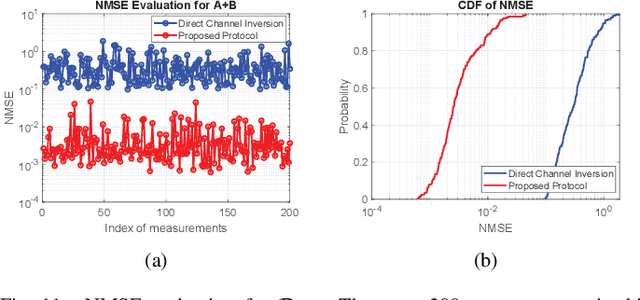

In this paper, we develop an orthogonal-frequency-division-multiplexing (OFDM)-based over-the-air (OTA) aggregation solution for wireless federated learning (FL). In particular, the local gradients in massive IoT devices are modulated by an analog waveform and are then transmitted using the same wireless resources. To this end, achieving perfect waveform superposition is the key challenge, which is difficult due to the existence of frame timing offset (TO) and carrier frequency offset (CFO). In order to address these issues, we propose a two-stage waveform pre-equalization technique with a customized multiple access protocol that can estimate and then mitigate the TO and CFO for the OTA aggregation. Based on the proposed solution, we develop a hardware transceiver and application software to train a real-world FL task, which learns a deep neural network to predict the received signal strength with global positioning system information. Experiments verify that the proposed OTA aggregation solution can achieve comparable performance to offline learning procedures with high prediction accuracy.
Gated Linear Model induced U-net for surrogate modeling and uncertainty quantification
Nov 08, 2021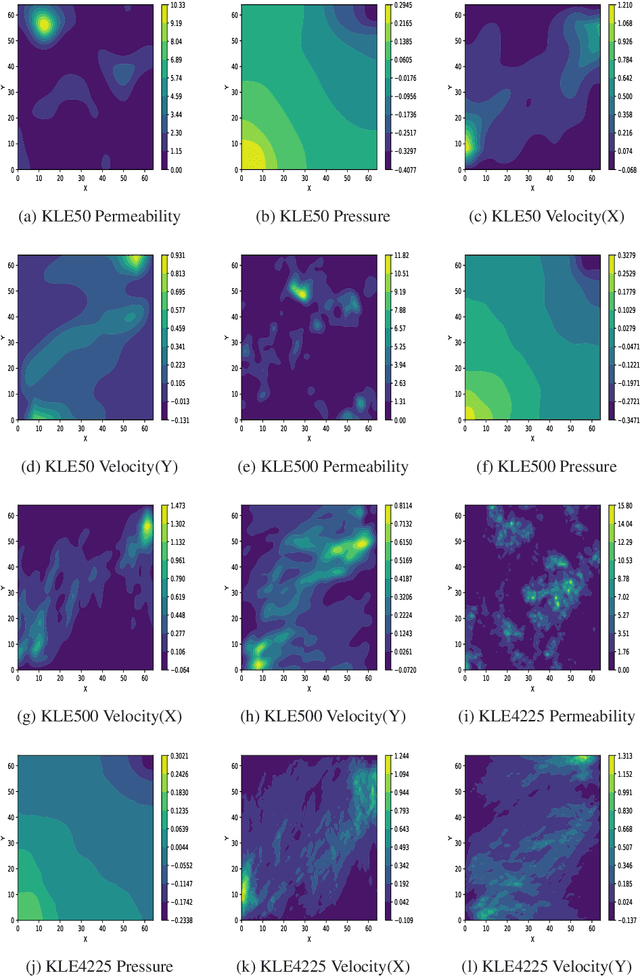
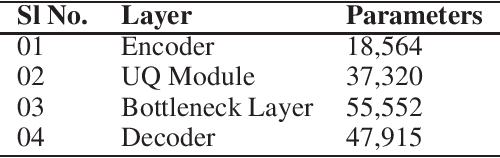
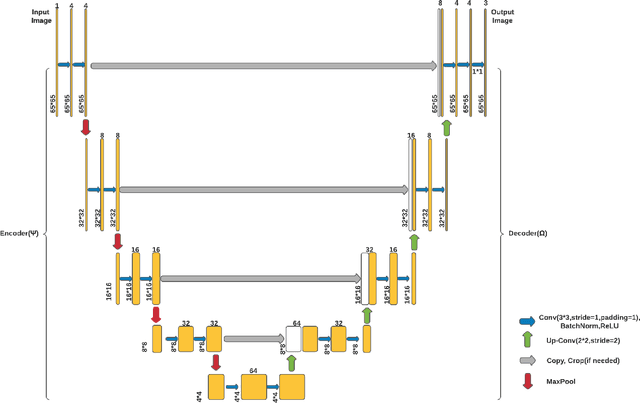

We propose a novel deep learning based surrogate model for solving high-dimensional uncertainty quantification and uncertainty propagation problems. The proposed deep learning architecture is developed by integrating the well-known U-net architecture with the Gaussian Gated Linear Network (GGLN) and referred to as the Gated Linear Network induced U-net or GLU-net. The proposed GLU-net treats the uncertainty propagation problem as an image to image regression and hence, is extremely data efficient. Additionally, it also provides estimates of the predictive uncertainty. The network architecture of GLU-net is less complex with 44\% fewer parameters than the contemporary works. We illustrate the performance of the proposed GLU-net in solving the Darcy flow problem under uncertainty under the sparse data scenario. We consider the stochastic input dimensionality to be up to 4225. Benchmark results are generated using the vanilla Monte Carlo simulation. We observe the proposed GLU-net to be accurate and extremely efficient even when no information about the structure of the inputs is provided to the network. Case studies are performed by varying the training sample size and stochastic input dimensionality to illustrate the robustness of the proposed approach.
Bilingual Topic Models for Comparable Corpora
Nov 30, 2021

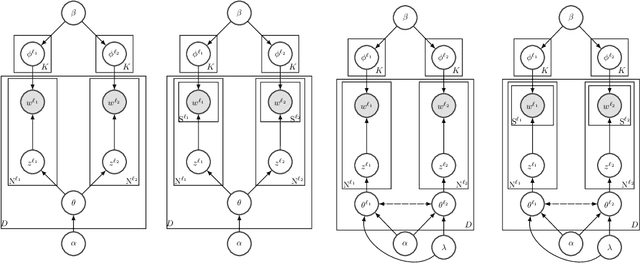
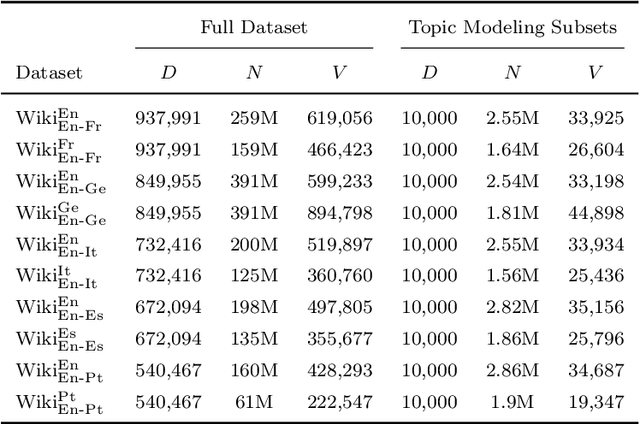
Probabilistic topic models like Latent Dirichlet Allocation (LDA) have been previously extended to the bilingual setting. A fundamental modeling assumption in several of these extensions is that the input corpora are in the form of document pairs whose constituent documents share a single topic distribution. However, this assumption is strong for comparable corpora that consist of documents thematically similar to an extent only, which are, in turn, the most commonly available or easy to obtain. In this paper we relax this assumption by proposing for the paired documents to have separate, yet bound topic distributions. % a binding mechanism between the distributions of the paired documents. We suggest that the strength of the bound should depend on each pair's semantic similarity. To estimate the similarity of documents that are written in different languages we use cross-lingual word embeddings that are learned with shallow neural networks. We evaluate the proposed binding mechanism by extending two topic models: a bilingual adaptation of LDA that assumes bag-of-words inputs and a model that incorporates part of the text structure in the form of boundaries of semantically coherent segments. To assess the performance of the novel topic models we conduct intrinsic and extrinsic experiments on five bilingual, comparable corpora of English documents with French, German, Italian, Spanish and Portuguese documents. The results demonstrate the efficiency of our approach in terms of both topic coherence measured by the normalized point-wise mutual information, and generalization performance measured by perplexity and in terms of Mean Reciprocal Rank in a cross-lingual document retrieval task for each of the language pairs.
Template NeRF: Towards Modeling Dense Shape Correspondences from Category-Specific Object Images
Nov 08, 2021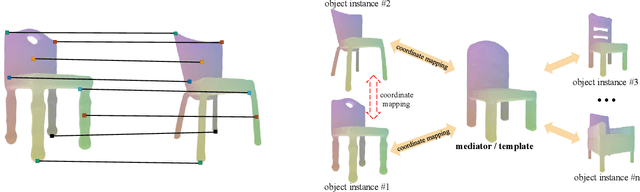
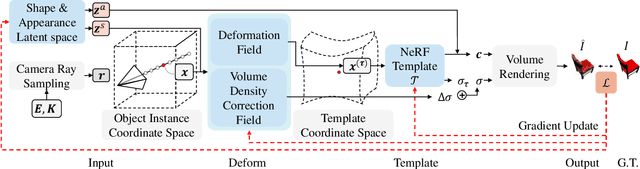
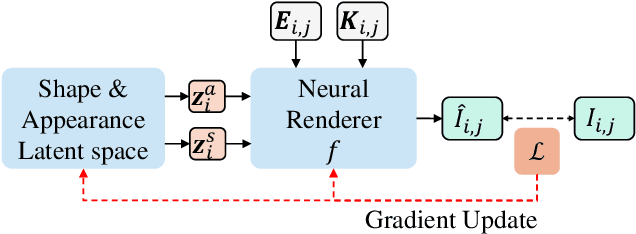
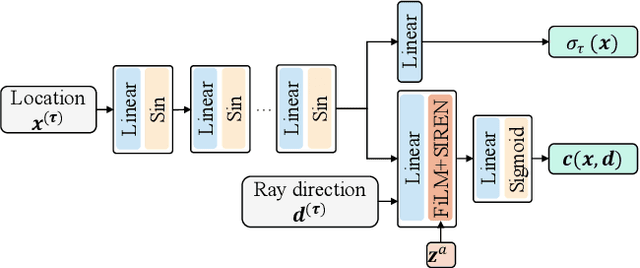
We present neural radiance fields (NeRF) with templates, dubbed Template-NeRF, for modeling appearance and geometry and generating dense shape correspondences simultaneously among objects of the same category from only multi-view posed images, without the need of either 3D supervision or ground-truth correspondence knowledge. The learned dense correspondences can be readily used for various image-based tasks such as keypoint detection, part segmentation, and texture transfer that previously require specific model designs. Our method can also accommodate annotation transfer in a one or few-shot manner, given only one or a few instances of the category. Using periodic activation and feature-wise linear modulation (FiLM) conditioning, we introduce deep implicit templates on 3D data into the 3D-aware image synthesis pipeline NeRF. By representing object instances within the same category as shape and appearance variation of a shared NeRF template, our proposed method can achieve dense shape correspondences reasoning on images for a wide range of object classes. We demonstrate the results and applications on both synthetic and real-world data with competitive results compared with other methods based on 3D information.
RRNet: Relational Reasoning Network with Parallel Multi-scale Attention for Salient Object Detection in Optical Remote Sensing Images
Oct 27, 2021
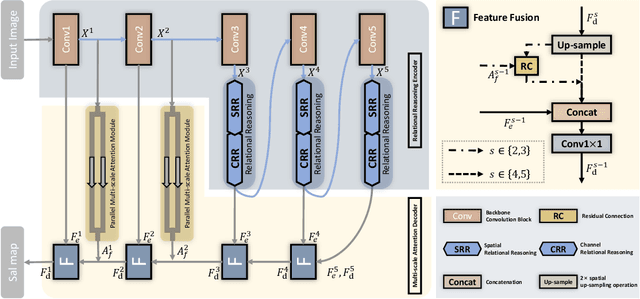

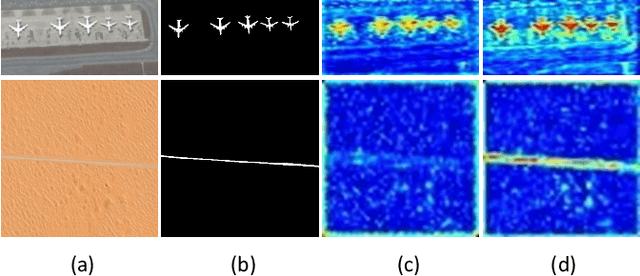
Salient object detection (SOD) for optical remote sensing images (RSIs) aims at locating and extracting visually distinctive objects/regions from the optical RSIs. Despite some saliency models were proposed to solve the intrinsic problem of optical RSIs (such as complex background and scale-variant objects), the accuracy and completeness are still unsatisfactory. To this end, we propose a relational reasoning network with parallel multi-scale attention for SOD in optical RSIs in this paper. The relational reasoning module that integrates the spatial and the channel dimensions is designed to infer the semantic relationship by utilizing high-level encoder features, thereby promoting the generation of more complete detection results. The parallel multi-scale attention module is proposed to effectively restore the detail information and address the scale variation of salient objects by using the low-level features refined by multi-scale attention. Extensive experiments on two datasets demonstrate that our proposed RRNet outperforms the existing state-of-the-art SOD competitors both qualitatively and quantitatively.
Variational Marginal Particle Filters
Sep 30, 2021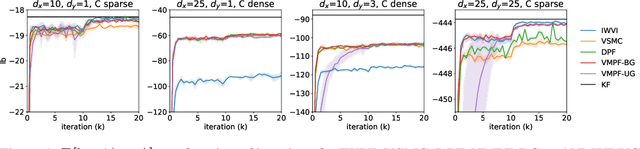
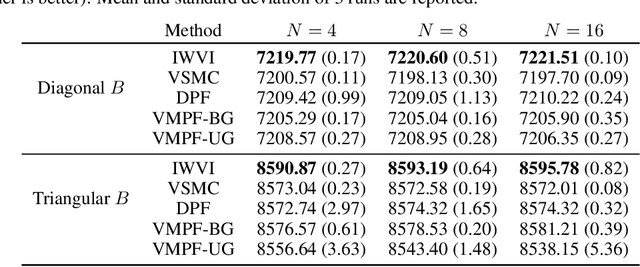
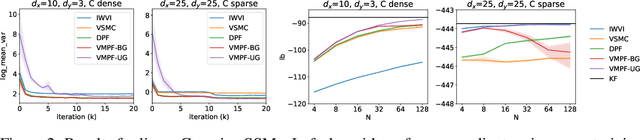
Variational inference for state space models (SSMs) is known to be hard in general. Recent works focus on deriving variational objectives for SSMs from unbiased sequential Monte Carlo estimators. We reveal that the marginal particle filter is obtained from sequential Monte Carlo by applying Rao-Blackwellization operations, which sacrifices the trajectory information for reduced variance and differentiability. We propose the variational marginal particle filter (VMPF), which is a differentiable and reparameterizable variational filtering objective for SSMs based on an unbiased estimator. We find that VMPF with biased gradients gives tighter bounds than previous objectives, and the unbiased reparameterization gradients are sometimes beneficial.
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
May 28, 2020
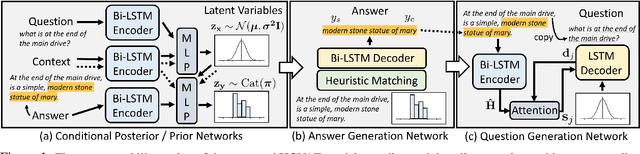
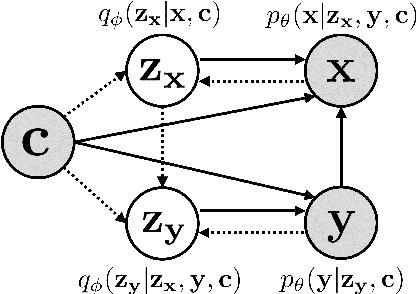
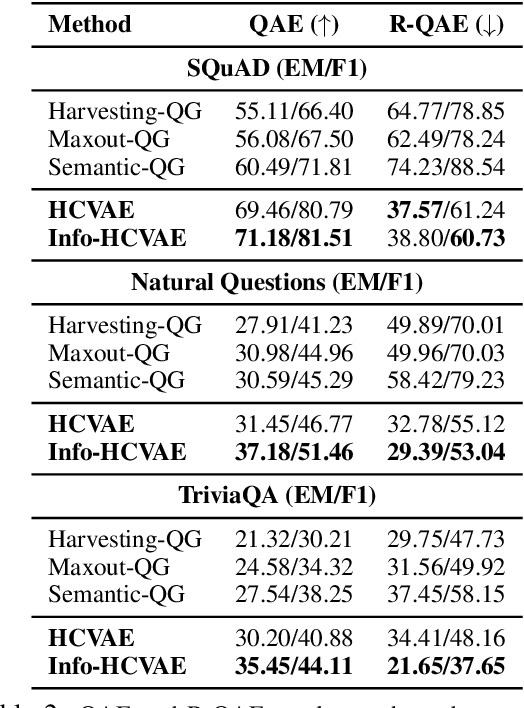
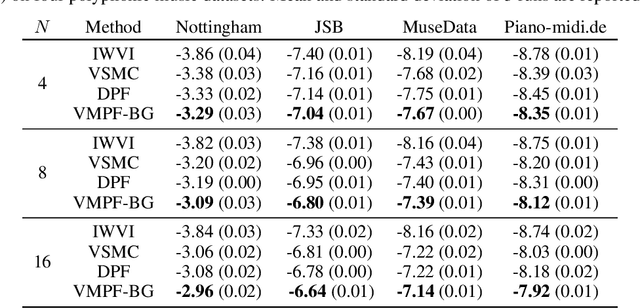
One of the most crucial challenges in questionanswering (QA) is the scarcity of labeled data,since it is costly to obtain question-answer(QA) pairs for a target text domain with human annotation. An alternative approach totackle the problem is to use automatically generated QA pairs from either the problem context or from large amount of unstructured texts(e.g. Wikipedia). In this work, we propose a hierarchical conditional variational autoencoder(HCVAE) for generating QA pairs given unstructured texts as contexts, while maximizingthe mutual information between generated QApairs to ensure their consistency. We validateourInformation MaximizingHierarchicalConditionalVariationalAutoEncoder (Info-HCVAE) on several benchmark datasets byevaluating the performance of the QA model(BERT-base) using only the generated QApairs (QA-based evaluation) or by using boththe generated and human-labeled pairs (semi-supervised learning) for training, against state-of-the-art baseline models. The results showthat our model obtains impressive performance gains over all baselines on both tasks,using only a fraction of data for training
Hyperspectral Mixed Noise Removal via Subspace Representation and Weighted Low-rank Tensor Regularization
Nov 13, 2021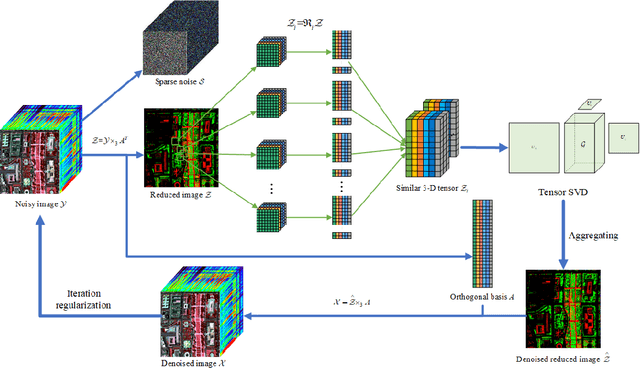


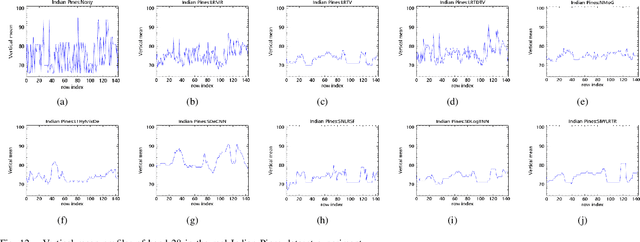
Recently, the low-rank property of different components extracted from the image has been considered in man hyperspectral image denoising methods. However, these methods usually unfold the 3D tensor to 2D matrix or 1D vector to exploit the prior information, such as nonlocal spatial self-similarity (NSS) and global spectral correlation (GSC), which break the intrinsic structure correlation of hyperspectral image (HSI) and thus lead to poor restoration quality. In addition, most of them suffer from heavy computational burden issues due to the involvement of singular value decomposition operation on matrix and tensor in the original high-dimensionality space of HSI. We employ subspace representation and the weighted low-rank tensor regularization (SWLRTR) into the model to remove the mixed noise in the hyperspectral image. Specifically, to employ the GSC among spectral bands, the noisy HSI is projected into a low-dimensional subspace which simplified calculation. After that, a weighted low-rank tensor regularization term is introduced to characterize the priors in the reduced image subspace. Moreover, we design an algorithm based on alternating minimization to solve the nonconvex problem. Experiments on simulated and real datasets demonstrate that the SWLRTR method performs better than other hyperspectral denoising methods quantitatively and visually.
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021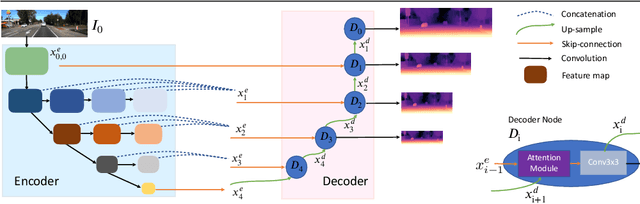
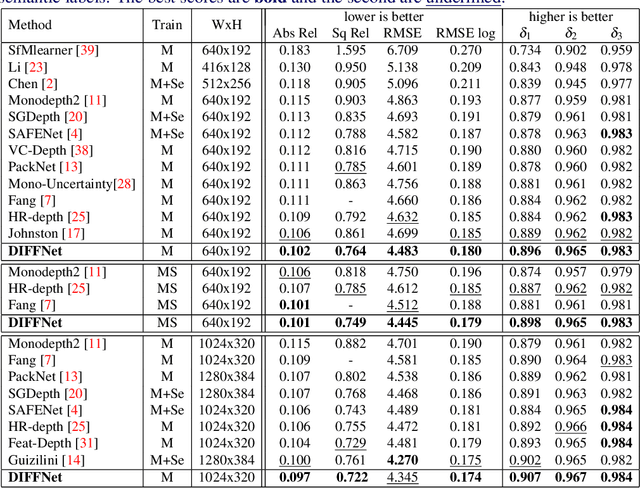

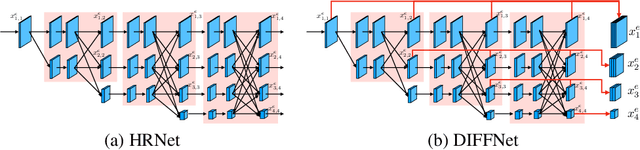
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.