 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Forecasting Crude Oil Price Using Event Extraction
Nov 14, 2021
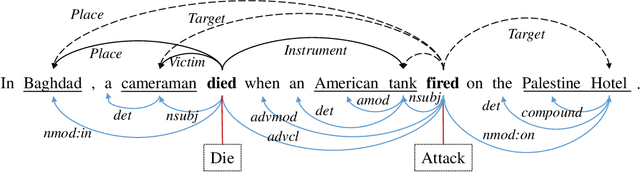
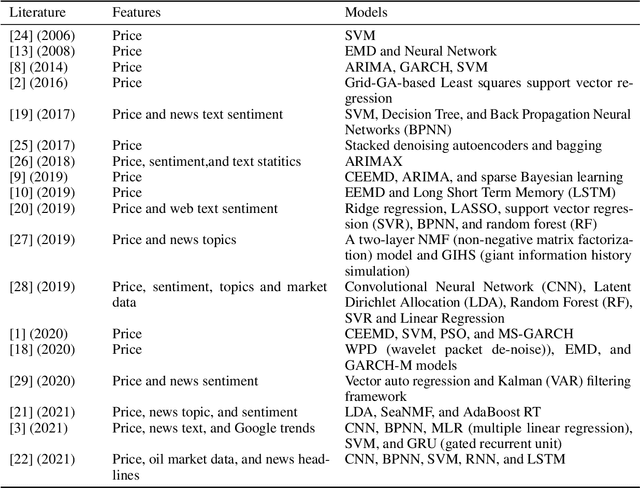

Research on crude oil price forecasting has attracted tremendous attention from scholars and policymakers due to its significant effect on the global economy. Besides supply and demand, crude oil prices are largely influenced by various factors, such as economic development, financial markets, conflicts, wars, and political events. Most previous research treats crude oil price forecasting as a time series or econometric variable prediction problem. Although recently there have been researches considering the effects of real-time news events, most of these works mainly use raw news headlines or topic models to extract text features without profoundly exploring the event information. In this study, a novel crude oil price forecasting framework, AGESL, is proposed to deal with this problem. In our approach, an open domain event extraction algorithm is utilized to extract underlying related events, and a text sentiment analysis algorithm is used to extract sentiment from massive news. Then a deep neural network integrating the news event features, sentimental features, and historical price features is built to predict future crude oil prices. Empirical experiments are performed on West Texas Intermediate (WTI) crude oil price data, and the results show that our approach obtains superior performance compared with several benchmark methods.
* 14 pages, 5 figures, 5 tables
Federated Causal Inference in Heterogeneous Observational Data
Aug 10, 2021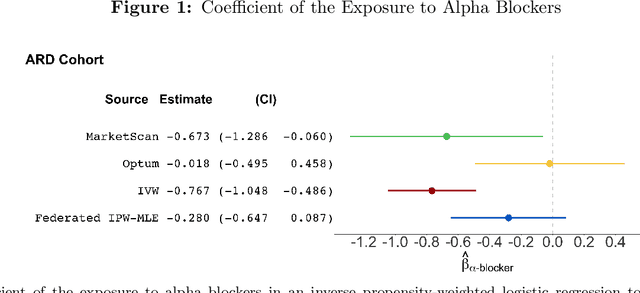

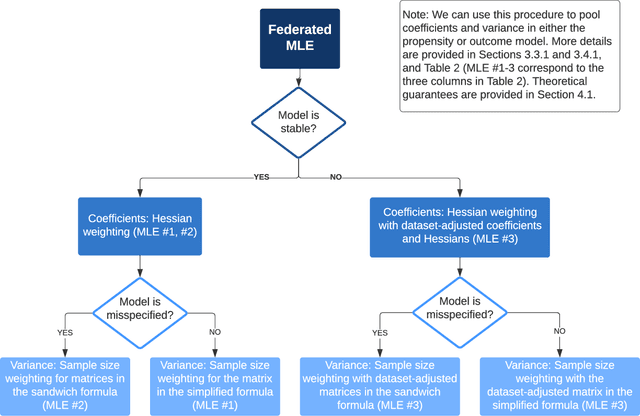
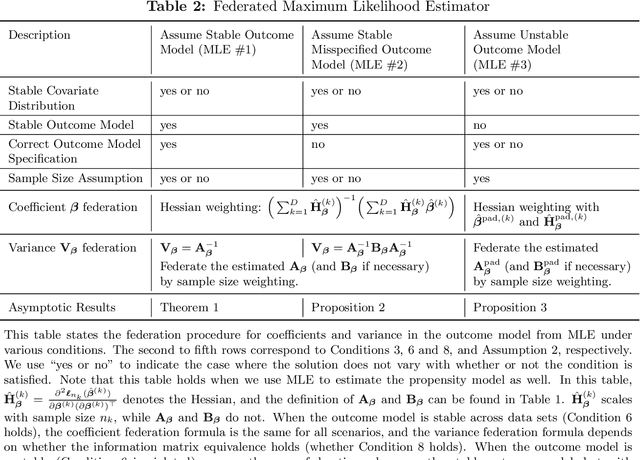
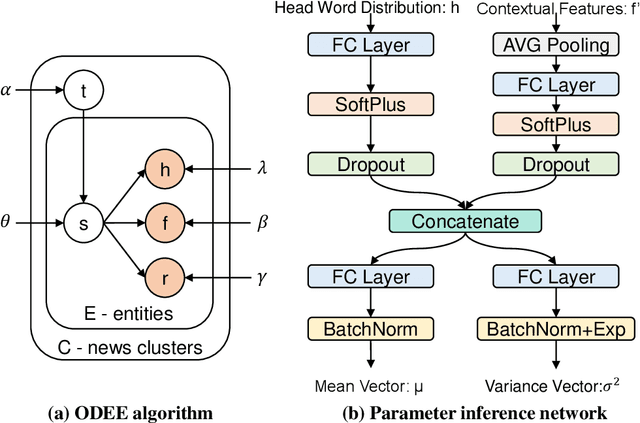
Analyzing observational data from multiple sources can be useful for increasing statistical power to detect a treatment effect; however, practical constraints such as privacy considerations may restrict individual-level information sharing across data sets. This paper develops federated methods that only utilize summary-level information from heterogeneous data sets. Our federated methods provide doubly-robust point estimates of treatment effects as well as variance estimates. We derive the asymptotic distributions of our federated estimators, which are shown to be asymptotically equivalent to the corresponding estimators from the combined, individual-level data. We show that to achieve these properties, federated methods should be adjusted based on conditions such as whether models are correctly specified and stable across heterogeneous data sets.
MFM-Net: Unpaired Shape Completion Network with Multi-stage Feature Matching
Nov 23, 2021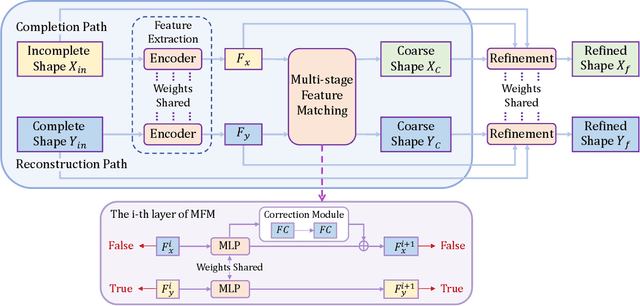
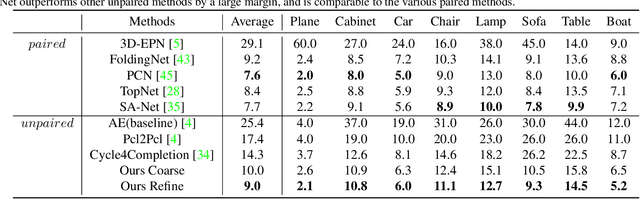
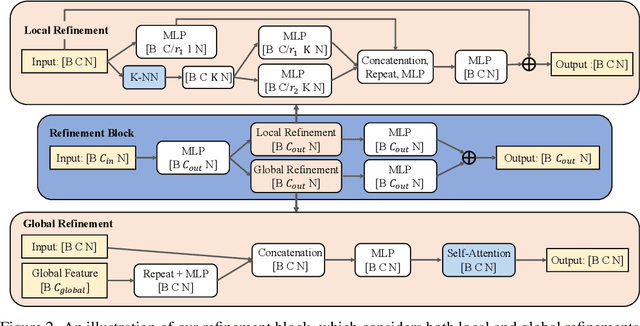
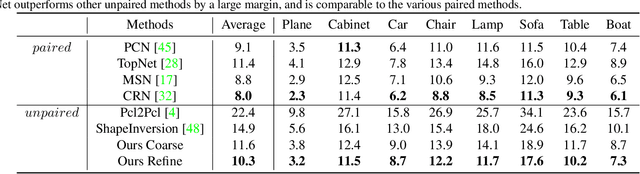
Unpaired 3D object completion aims to predict a complete 3D shape from an incomplete input without knowing the correspondence between the complete and incomplete shapes during training. To build the correspondence between two data modalities, previous methods usually apply adversarial training to match the global shape features extracted by the encoder. However, this ignores the correspondence between multi-scaled geometric information embedded in the pyramidal hierarchy of the decoder, which makes previous methods struggle to generate high-quality complete shapes. To address this problem, we propose a novel unpaired shape completion network, named MFM-Net, using multi-stage feature matching, which decomposes the learning of geometric correspondence into multi-stages throughout the hierarchical generation process in the point cloud decoder. Specifically, MFM-Net adopts a dual path architecture to establish multiple feature matching channels in different layers of the decoder, which is then combined with the adversarial learning to merge the distribution of features from complete and incomplete modalities. In addition, a refinement is applied to enhance the details. As a result, MFM-Net makes use of a more comprehensive understanding to establish the geometric correspondence between complete and incomplete shapes in a local-to-global perspective, which enables more detailed geometric inference for generating high-quality complete shapes. We conduct comprehensive experiments on several datasets, and the results show that our method outperforms previous methods of unpaired point cloud completion with a large margin.
Dual Progressive Prototype Network for Generalized Zero-Shot Learning
Nov 03, 2021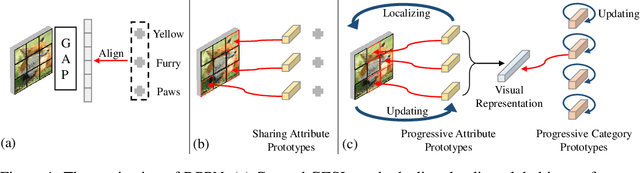
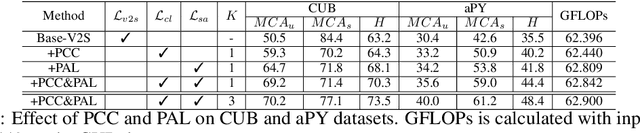
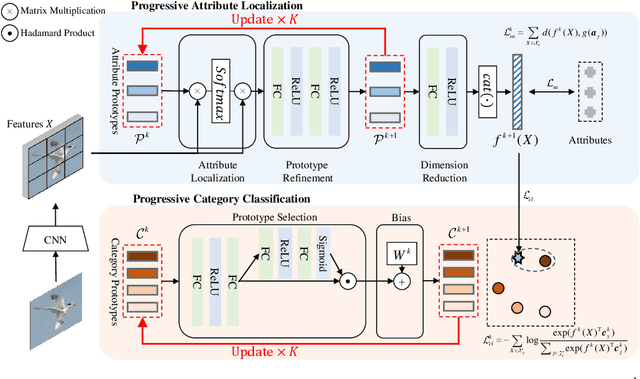
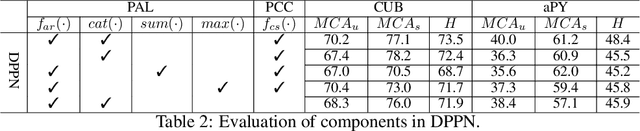
Generalized Zero-Shot Learning (GZSL) aims to recognize new categories with auxiliary semantic information,e.g., category attributes. In this paper, we handle the critical issue of domain shift problem, i.e., confusion between seen and unseen categories, by progressively improving cross-domain transferability and category discriminability of visual representations. Our approach, named Dual Progressive Prototype Network (DPPN), constructs two types of prototypes that record prototypical visual patterns for attributes and categories, respectively. With attribute prototypes, DPPN alternately searches attribute-related local regions and updates corresponding attribute prototypes to progressively explore accurate attribute-region correspondence. This enables DPPN to produce visual representations with accurate attribute localization ability, which benefits the semantic-visual alignment and representation transferability. Besides, along with progressive attribute localization, DPPN further projects category prototypes into multiple spaces to progressively repel visual representations from different categories, which boosts category discriminability. Both attribute and category prototypes are collaboratively learned in a unified framework, which makes visual representations of DPPN transferable and distinctive. Experiments on four benchmarks prove that DPPN effectively alleviates the domain shift problem in GZSL.
SPAN: Subgraph Prediction Attention Network for Dynamic Graphs
Aug 17, 2021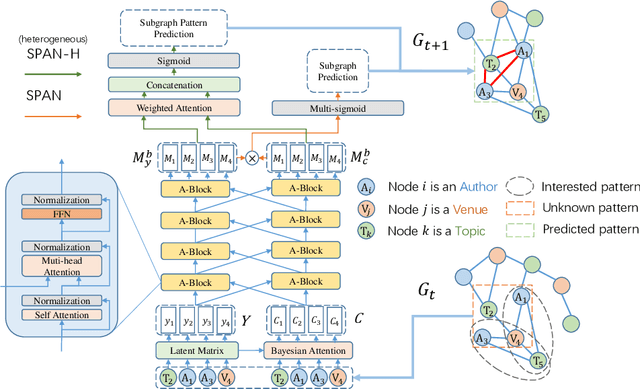
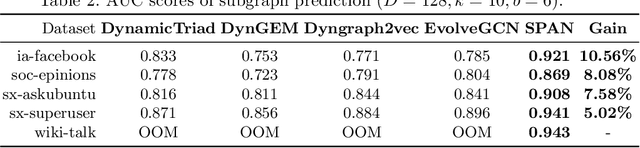
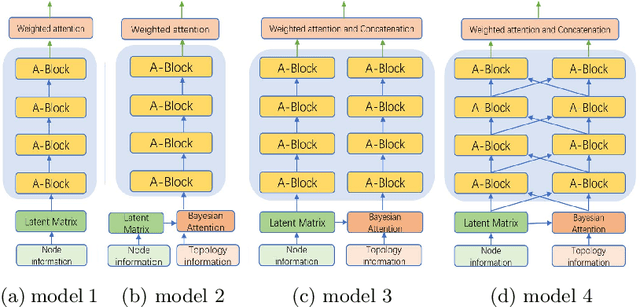
This paper proposes a novel model for predicting subgraphs in dynamic graphs, an extension of traditional link prediction. This proposed end-to-end model learns a mapping from the subgraph structures in the current snapshot to the subgraph structures in the next snapshot directly, i.e., edge existence among multiple nodes in the subgraph. A new mechanism named cross-attention with a twin-tower module is designed to integrate node attribute information and topology information collaboratively for learning subgraph evolution. We compare our model with several state-of-the-art methods for subgraph prediction and subgraph pattern prediction in multiple real-world homogeneous and heterogeneous dynamic graphs, respectively. Experimental results demonstrate that our model outperforms other models in these two tasks, with a gain increase from 5.02% to 10.88%.
A General Framework for Information Extraction using Dynamic Span Graphs
Apr 05, 2019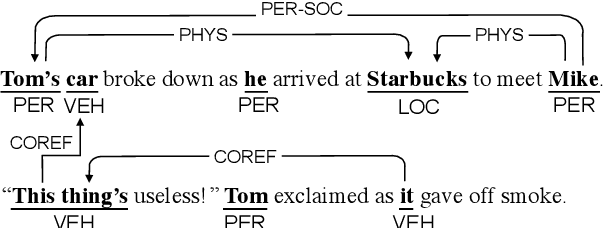
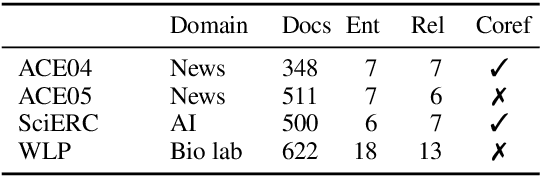
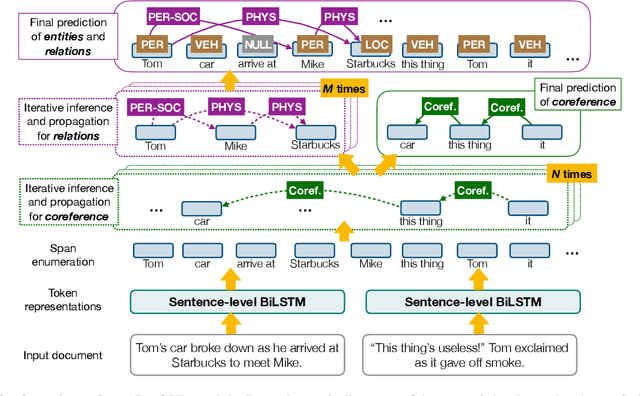
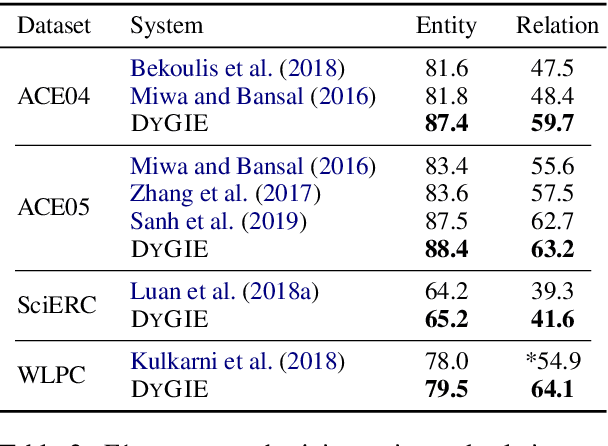
We introduce a general framework for several information extraction tasks that share span representations using dynamically constructed span graphs. The graphs are constructed by selecting the most confident entity spans and linking these nodes with confidence-weighted relation types and coreferences. The dynamic span graph allows coreference and relation type confidences to propagate through the graph to iteratively refine the span representations. This is unlike previous multi-task frameworks for information extraction in which the only interaction between tasks is in the shared first-layer LSTM. Our framework significantly outperforms the state-of-the-art on multiple information extraction tasks across multiple datasets reflecting different domains. We further observe that the span enumeration approach is good at detecting nested span entities, with significant F1 score improvement on the ACE dataset.
Metadata-based Multi-Task Bandits with Bayesian Hierarchical Models
Aug 13, 2021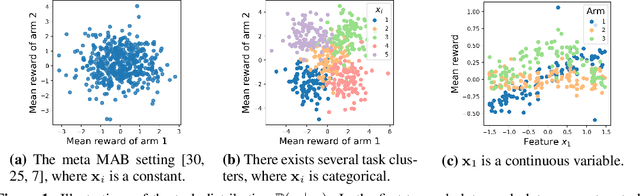

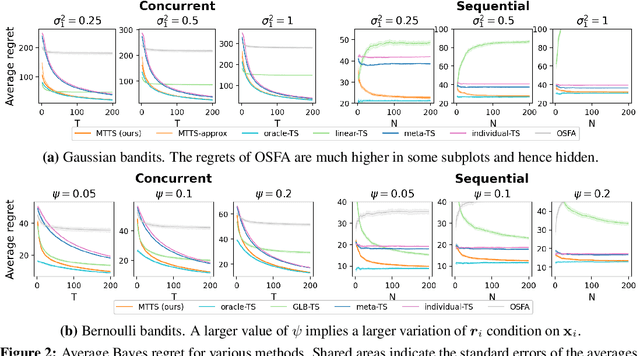
How to explore efficiently is a central problem in multi-armed bandits. In this paper, we introduce the metadata-based multi-task bandit problem, where the agent needs to solve a large number of related multi-armed bandit tasks and can leverage some task-specific features (i.e., metadata) to share knowledge across tasks. As a general framework, we propose to capture task relations through the lens of Bayesian hierarchical models, upon which a Thompson sampling algorithm is designed to efficiently learn task relations, share information, and minimize the cumulative regrets. Two concrete examples for Gaussian bandits and Bernoulli bandits are carefully analyzed. The Bayes regret for Gaussian bandits clearly demonstrates the benefits of information sharing with our algorithm. The proposed method is further supported by extensive experiments.
HRFormer: High-Resolution Transformer for Dense Prediction
Oct 21, 2021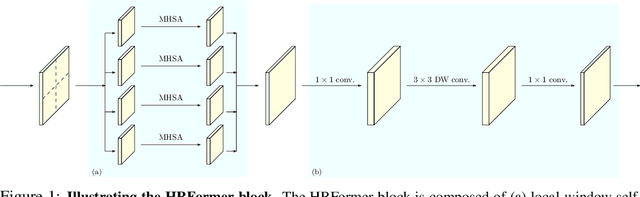
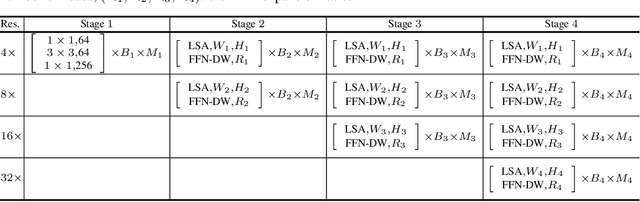


We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021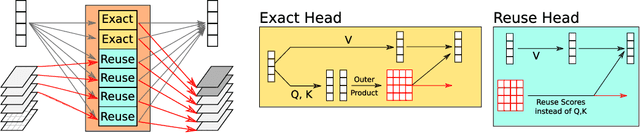
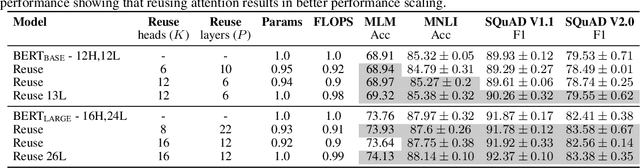
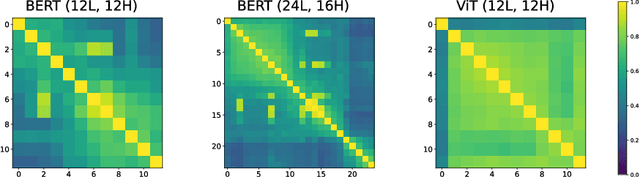
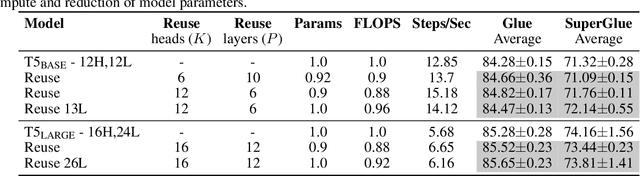
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
RF Lens Antenna Array-Based One-Shot Coarse Pointing for Hybrid RF/FSO Communications
Oct 05, 2021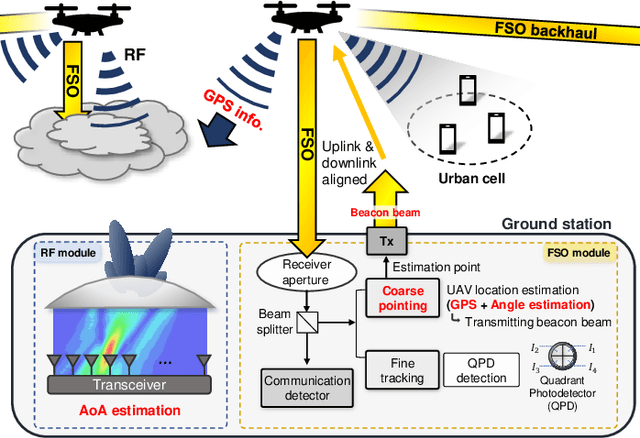
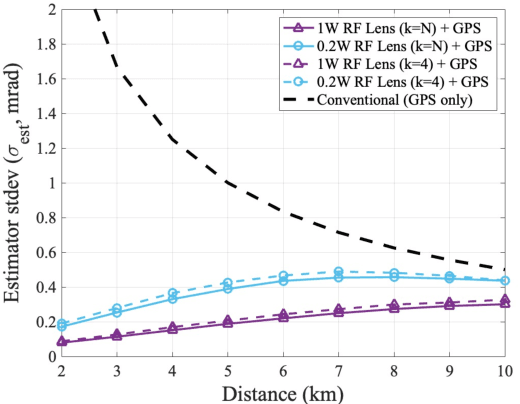
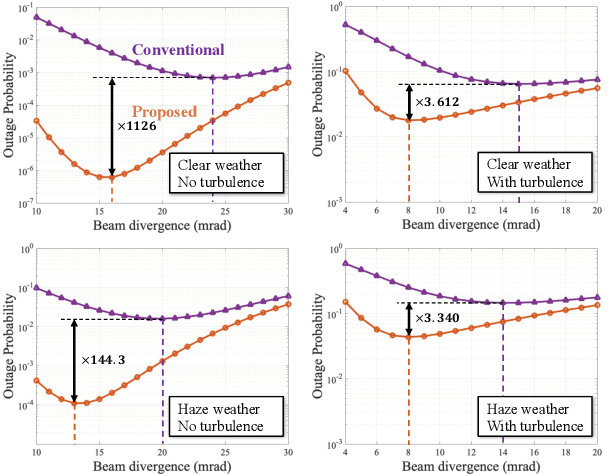
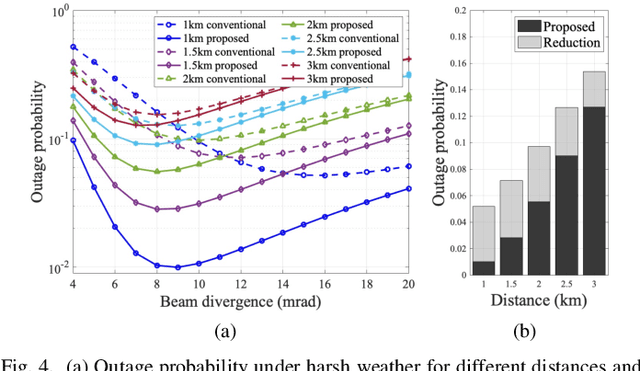
Because of its high directivity, free-space optical (FSO) communication offers a number of advantages. It can, however, give rise to major system difficulties concerning alignment between two terminals. During the link-acquisition step (a.k.a. coarse pointing), a ground station can be prevented from acquiring optical links due to pointing errors and insufficient information about unmanned aerial vehicle locations. We propose, in this letter, a radio-frequency (RF) lens antenna array to increase the performance of coarse pointing in hybrid RF/FSO communications. The proposed algorithm using a novel closed-form angle estimator, compared to conventional methods, reduces the minimum outage probability by over a thousand times.