 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Activity Detection, Channel Estimation, and Data Decoding for Grant-free Massive Random Access
Jul 12, 2021
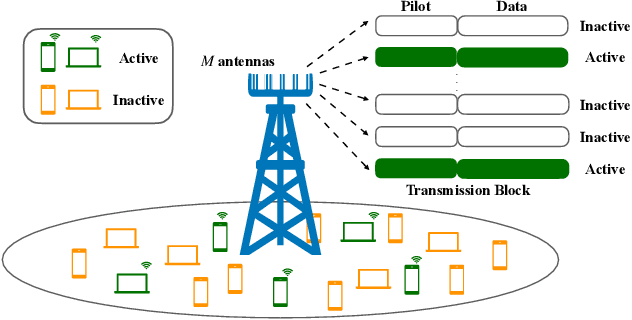
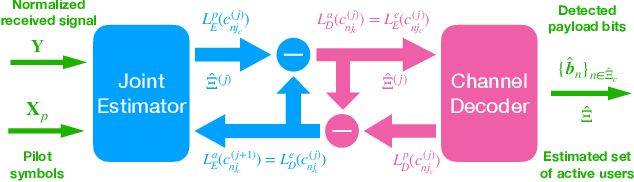
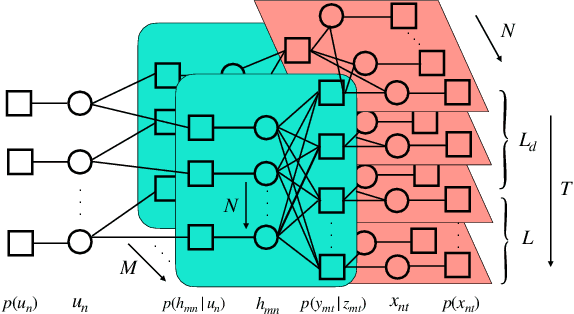
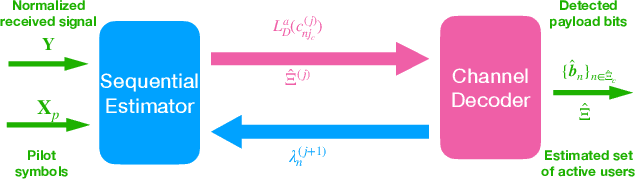
In the massive machine-type communication (mMTC) scenario, a large number of devices with sporadic traffic need to access the network on limited radio resources. While grant-free random access has emerged as a promising mechanism for massive access, its potential has not been fully unleashed. In particular, the common sparsity pattern in the received pilot and data signal has been ignored in most existing studies, and auxiliary information of channel decoding has not been utilized for user activity detection. This paper endeavors to develop advanced receivers in a holistic manner for joint activity detection, channel estimation, and data decoding. In particular, a turbo receiver based on the bilinear generalized approximate message passing (BiG-AMP) algorithm is developed. In this receiver, all the received symbols will be utilized to jointly estimate the channel state, user activity, and soft data symbols, which effectively exploits the common sparsity pattern. Meanwhile, the extrinsic information from the channel decoder will assist the joint channel estimation and data detection. To reduce the complexity, a low-cost side information-aided receiver is also proposed, where the channel decoder provides side information to update the estimates on whether a user is active or not. Simulation results show that the turbo receiver is able to reduce the activity detection, channel estimation, and data decoding errors effectively, while the side information-aided receiver notably outperforms the conventional method with a relatively low complexity.
Task-Oriented Multi-User Semantic Communications for Multimodal Data
Aug 16, 2021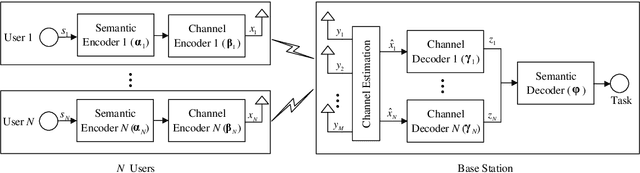
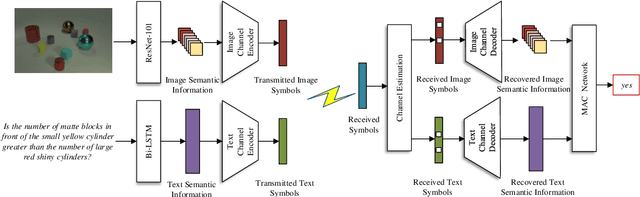
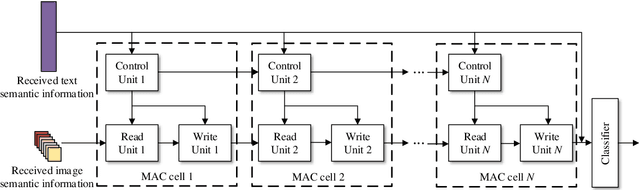
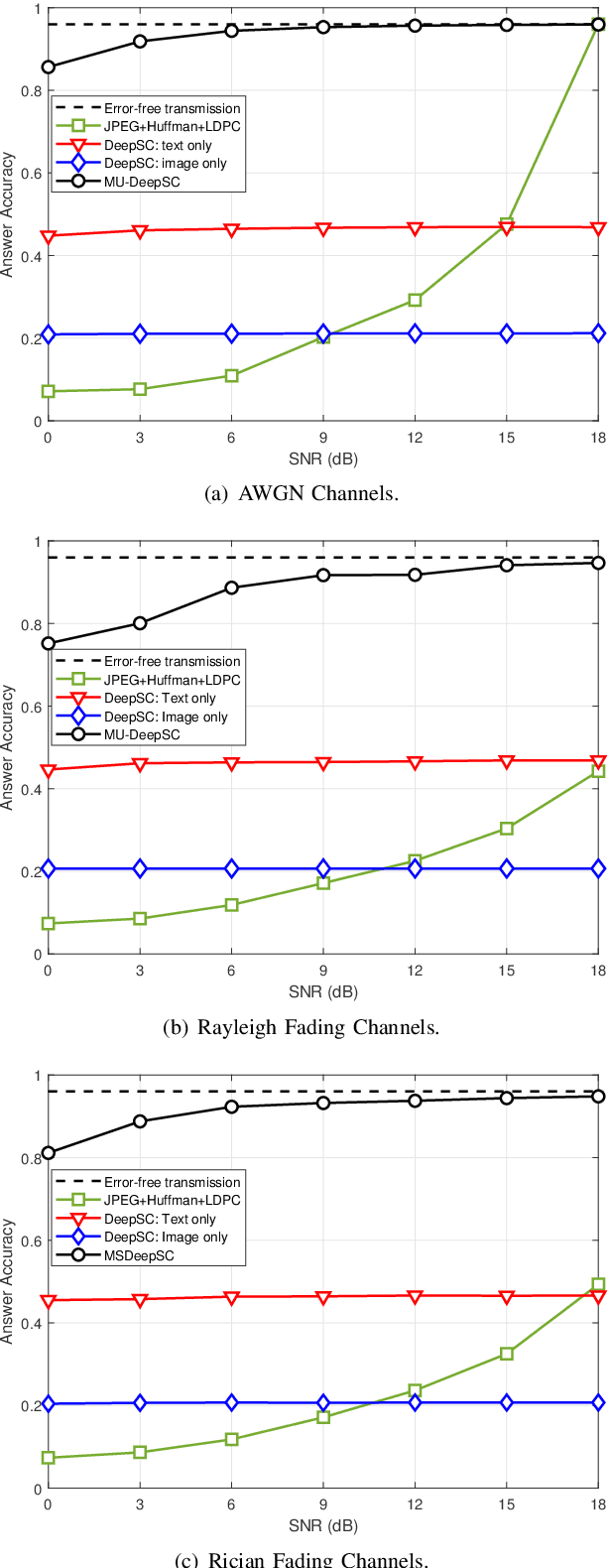
Semantic communications focus on the successful transmission of information relevant to the transmission task. In this paper, we investigate multi-users transmission for multimodal data in a task semantic communication system. We take the vision-answering as the semantic transmission task, in which part of the users transmit images and the other users transmit text to inquiry the information about the images. The receiver will provide answers based on the image and text from multiple users in the considered system. To exploit the correlation between the multimodal data from multiple users, we proposed a deep neural network enabled multi-user semantic communication system, named MU-DeepSC, for the visual question answering (VQA) task, in which the answer is highly dependent on the related image and text from the multiple users. Particularly, based on the memory, attention, and composition (MAC) neural network, we jointly design the transceiver and merge the MAC network to capture the features from the correlated multimodal data for serving the transmission task. The MU-DeepSC extracts the semantic information of image and text from different users and then generates the corresponding answers. Simulation results validate the feasibility of the proposed MU-DeepSC, which is more robust to various channel conditions than the traditional communication systems, especially in the low signal-to-noise (SNR) regime.
Unsupervised Keyphrase Extraction by Jointly Modeling Local and Global Context
Sep 15, 2021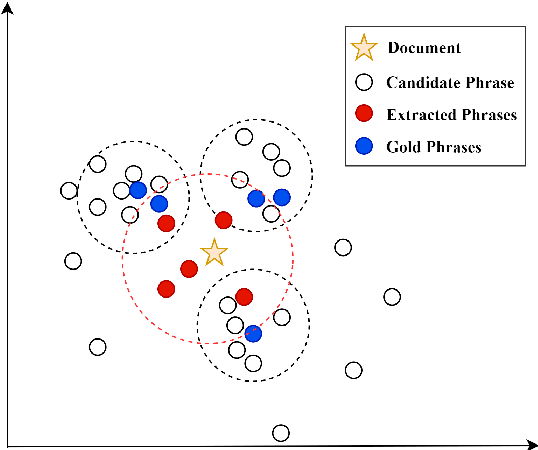
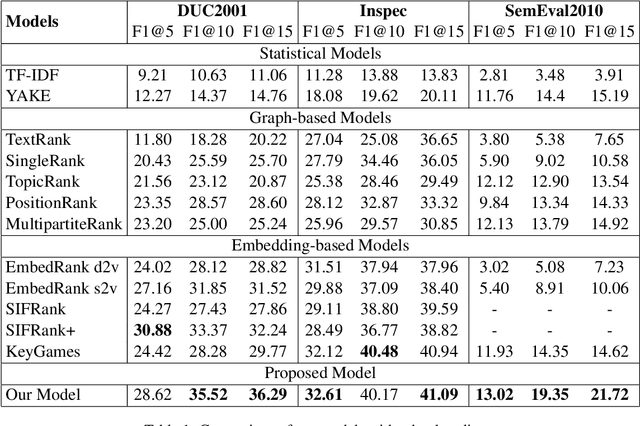
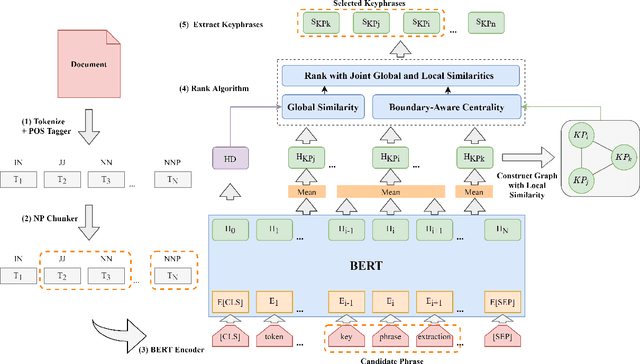

Embedding based methods are widely used for unsupervised keyphrase extraction (UKE) tasks. Generally, these methods simply calculate similarities between phrase embeddings and document embedding, which is insufficient to capture different context for a more effective UKE model. In this paper, we propose a novel method for UKE, where local and global contexts are jointly modeled. From a global view, we calculate the similarity between a certain phrase and the whole document in the vector space as transitional embedding based models do. In terms of the local view, we first build a graph structure based on the document where phrases are regarded as vertices and the edges are similarities between vertices. Then, we proposed a new centrality computation method to capture local salient information based on the graph structure. Finally, we further combine the modeling of global and local context for ranking. We evaluate our models on three public benchmarks (Inspec, DUC 2001, SemEval 2010) and compare with existing state-of-the-art models. The results show that our model outperforms most models while generalizing better on input documents with different domains and length. Additional ablation study shows that both the local and global information is crucial for unsupervised keyphrase extraction tasks.
PNC Enabled IIoT: A General Framework for Channel-Coded Asymmetric Physical-Layer Network Coding
Jul 08, 2021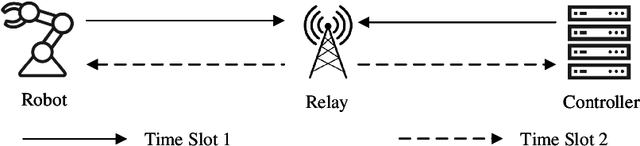
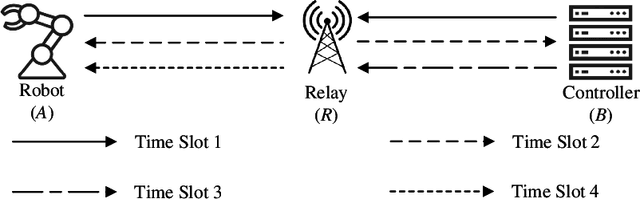
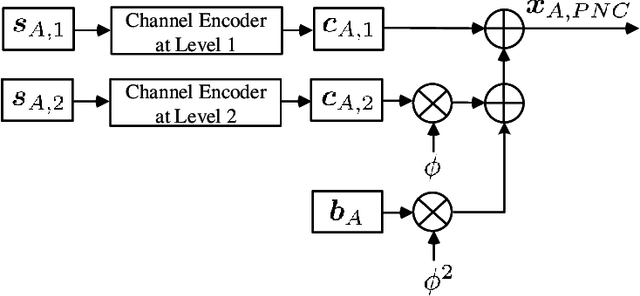
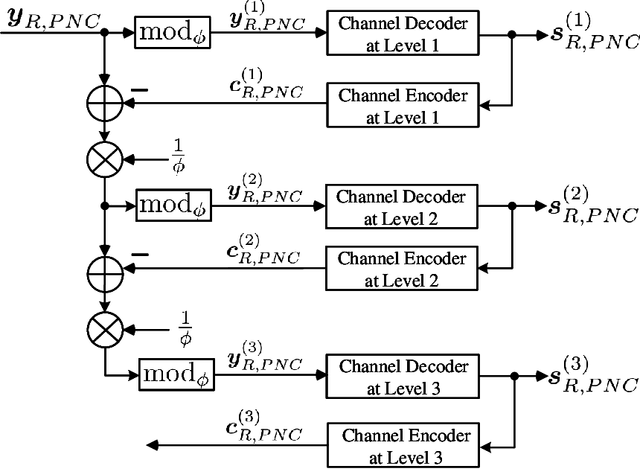
This paper investigates the application of physical-layer network coding (PNC) to Industrial Internet-of-Things (IIoT) where a controller and a robot are out of each other's transmission range, and they exchange messages with the assistance of a relay. We particularly focus on a scenario where the controller has more transmitted information, and the channel of the controller is stronger than that of the robot. To reduce the communication latency, we propose an asymmetric transmission scheme where the controller and robot transmit different amount of information in the uplink of PNC simultaneously. To achieve this, the controller chooses a higher order modulation. In addition, the both users apply channel codes to guarantee the reliability. A problem is a superimposed symbol at the relay contains different amount of source information from the two end users. It is thus hard for the relay to deduce meaningful network-coded messages by applying the current PNC decoding techniques which require the end users to transmit the same amount of information. To solve this problem, we propose a lattice-based scheme where the two users encode-and-modulate their information in lattices with different lattice construction levels. Our design is versatile on that the two end users can freely choose their modulation orders based on their channel power, and the design is applicable for arbitrary channel codes.
Vision Transformer for Classification of Breast Ultrasound Images
Oct 27, 2021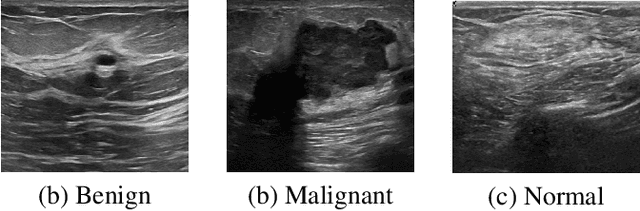
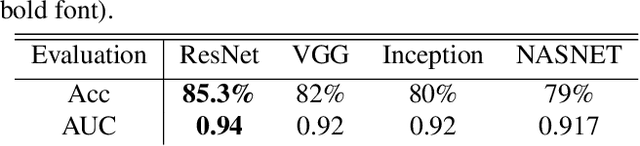
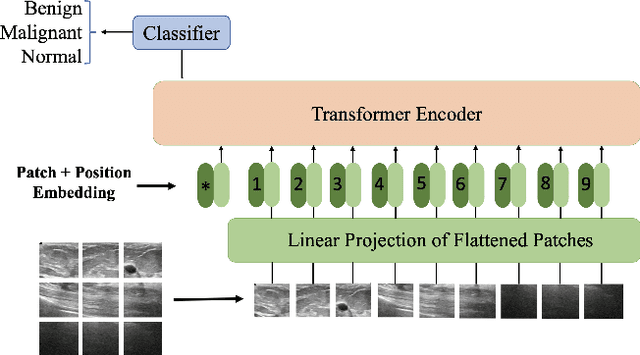

Medical ultrasound (US) imaging has become a prominent modality for breast cancer imaging due to its ease-of-use, low-cost and safety. In the past decade, convolutional neural networks (CNNs) have emerged as the method of choice in vision applications and have shown excellent potential in automatic classification of US images. Despite their success, their restricted local receptive field limits their ability to learn global context information. Recently, Vision Transformer (ViT) designs that are based on self-attention between image patches have shown great potential to be an alternative to CNNs. In this study, for the first time, we utilize ViT to classify breast US images using different augmentation strategies. The results are provided as classification accuracy and Area Under the Curve (AUC) metrics, and the performance is compared with the state-of-the-art CNNs. The results indicate that the ViT models have comparable efficiency with or even better than the CNNs in classification of US breast images.
Interpretable Visual Understanding with Cognitive Attention Network
Aug 14, 2021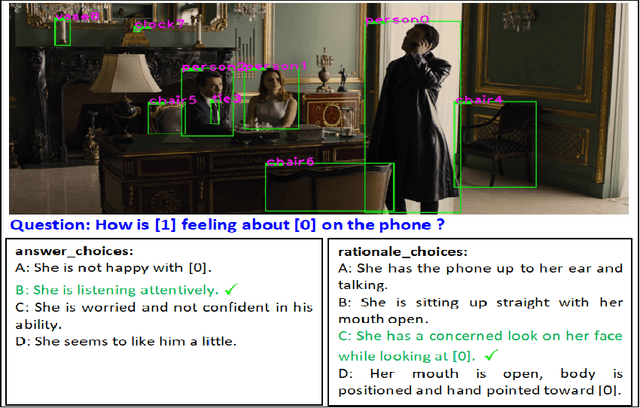
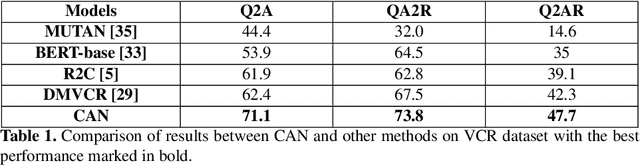
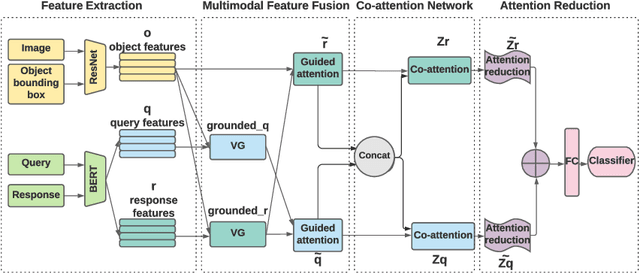
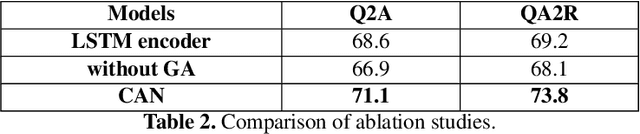
While image understanding on recognition-level has achieved remarkable advancements, reliable visual scene understanding requires comprehensive image understanding on recognition-level but also cognition-level, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge. In this paper, we propose a novel Cognitive Attention Network (CAN) for visual commonsense reasoning to achieve interpretable visual understanding. Specifically, we first introduce an image-text fusion module to fuse information from images and text collectively. Second, a novel inference module is designed to encode commonsense among image, query and response. Extensive experiments on large-scale Visual Commonsense Reasoning (VCR) benchmark dataset demonstrate the effectiveness of our approach. The implementation is publicly available at https://github.com/tanjatang/CAN
Joint Direction and Proximity Classification of Overlapping Sound Events from Binaural Audio
Jul 26, 2021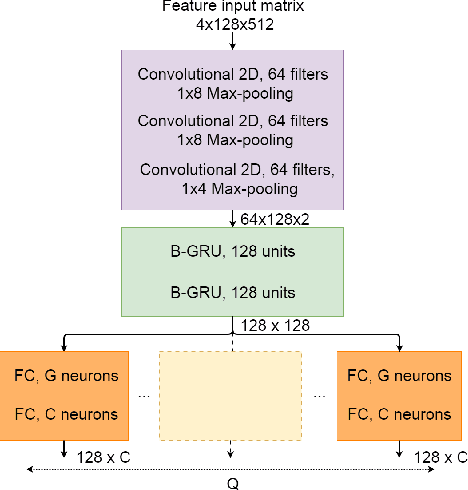
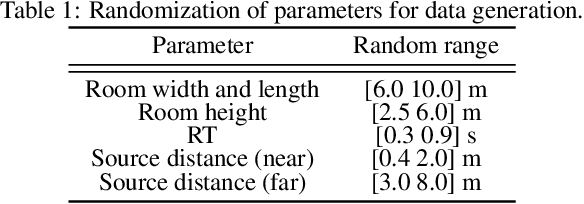
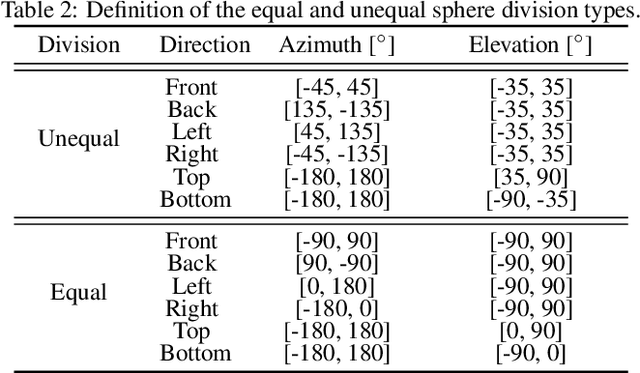
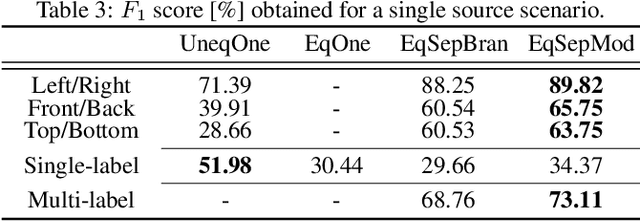
Sound source proximity and distance estimation are of great interest in many practical applications, since they provide significant information for acoustic scene analysis. As both tasks share complementary qualities, ensuring efficient interaction between these two is crucial for a complete picture of an aural environment. In this paper, we aim to investigate several ways of performing joint proximity and direction estimation from binaural recordings, both defined as coarse classification problems based on Deep Neural Networks (DNNs). Considering the limitations of binaural audio, we propose two methods of splitting the sphere into angular areas in order to obtain a set of directional classes. For each method we study different model types to acquire information about the direction-of-arrival (DoA). Finally, we propose various ways of combining the proximity and direction estimation problems into a joint task providing temporal information about the onsets and offsets of the appearing sources. Experiments are performed for a synthetic reverberant binaural dataset consisting of up to two overlapping sound events.
Structure of Deep Neural Networks with a Priori Information in Wireless Tasks
Nov 06, 2019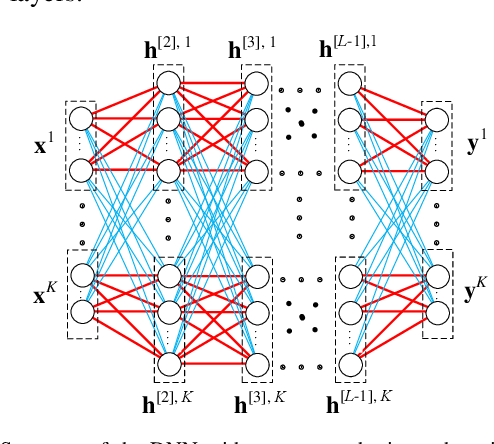
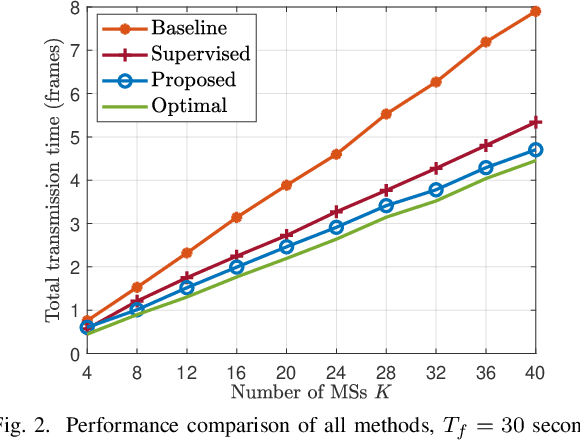
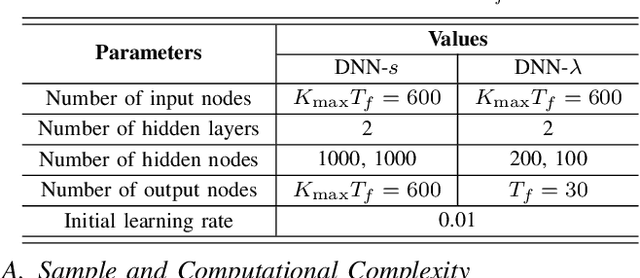
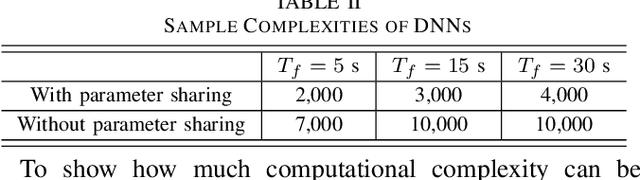
Deep neural networks (DNNs) have been employed for designing wireless networks in many aspects, such as transceiver optimization, resource allocation, and information prediction. Existing works either use fully-connected DNN or the DNNs with specific structures that are designed in other domains. In this paper, we show that a priori information widely existed in wireless tasks is permutation invariant. For these tasks, we propose a DNN with special structure, where the weight matrices between layers of the DNN only consist of two smaller sub-matrices. By such way of parameter sharing, the number of model parameters reduces, giving rise to low sample and computational complexity for training a DNN. We take predictive resource allocation as an example to show how the designed DNN can be applied for learning the optimal policy with unsupervised learning. Simulations results validate our analysis and show dramatic gain of the proposed structure in terms of reducing training complexity.
Leveraging redundancy in attention with Reuse Transformers
Oct 13, 2021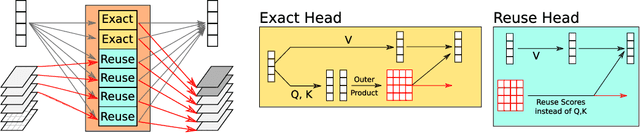
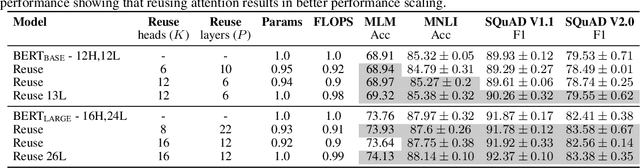
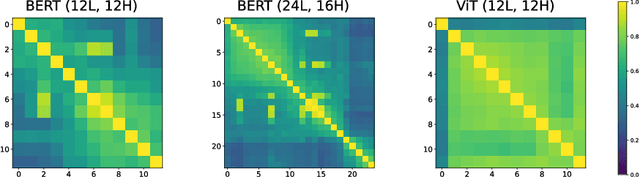
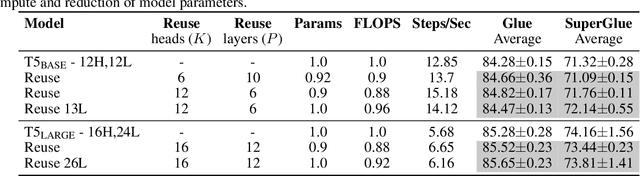
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Benign Adversarial Attack: Tricking Algorithm for Goodness
Jul 26, 2021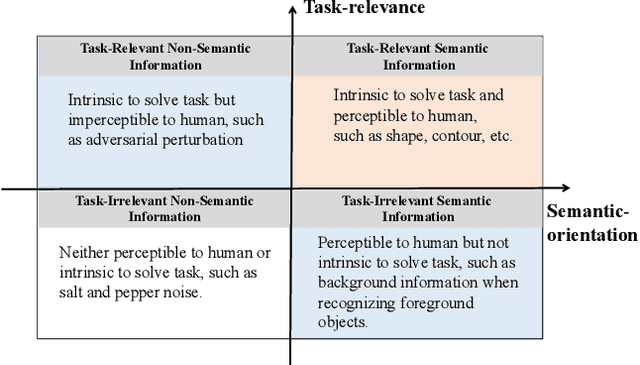
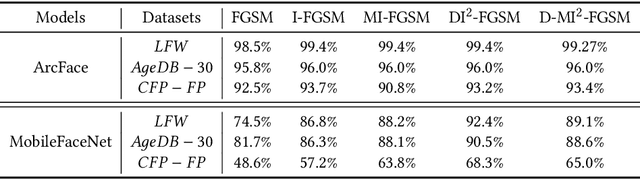


In spite of the successful application in many fields, machine learning algorithms today suffer from notorious problems like vulnerability to adversarial examples. Beyond falling into the cat-and-mouse game between adversarial attack and defense, this paper provides alternative perspective to consider adversarial example and explore whether we can exploit it in benign applications. We first propose a novel taxonomy of visual information along task-relevance and semantic-orientation. The emergence of adversarial example is attributed to algorithm's utilization of task-relevant non-semantic information. While largely ignored in classical machine learning mechanisms, task-relevant non-semantic information enjoys three interesting characteristics as (1) exclusive to algorithm, (2) reflecting common weakness, and (3) utilizable as features. Inspired by this, we present brave new idea called benign adversarial attack to exploit adversarial examples for goodness in three directions: (1) adversarial Turing test, (2) rejecting malicious algorithm, and (3) adversarial data augmentation. Each direction is positioned with motivation elaboration, justification analysis and prototype applications to showcase its potential.