 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Benign Adversarial Attack: Tricking Algorithm for Goodness
Jul 26, 2021
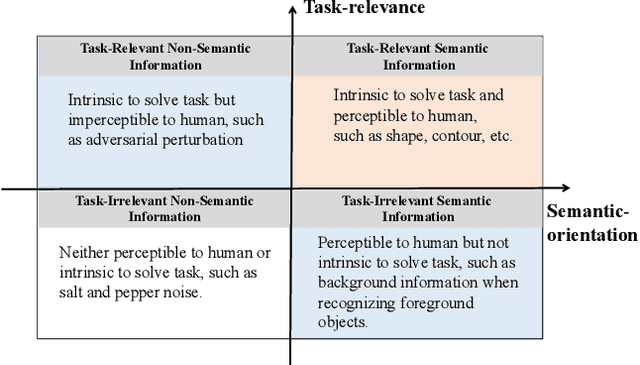
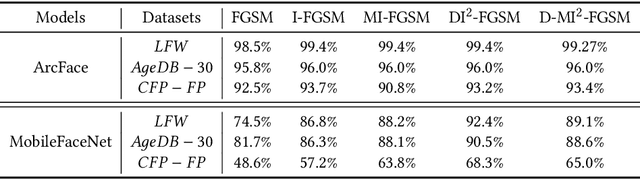


In spite of the successful application in many fields, machine learning algorithms today suffer from notorious problems like vulnerability to adversarial examples. Beyond falling into the cat-and-mouse game between adversarial attack and defense, this paper provides alternative perspective to consider adversarial example and explore whether we can exploit it in benign applications. We first propose a novel taxonomy of visual information along task-relevance and semantic-orientation. The emergence of adversarial example is attributed to algorithm's utilization of task-relevant non-semantic information. While largely ignored in classical machine learning mechanisms, task-relevant non-semantic information enjoys three interesting characteristics as (1) exclusive to algorithm, (2) reflecting common weakness, and (3) utilizable as features. Inspired by this, we present brave new idea called benign adversarial attack to exploit adversarial examples for goodness in three directions: (1) adversarial Turing test, (2) rejecting malicious algorithm, and (3) adversarial data augmentation. Each direction is positioned with motivation elaboration, justification analysis and prototype applications to showcase its potential.
Analyzing Wikipedia Membership Dataset and PredictingUnconnected Nodes in the Signed Networks
Oct 18, 2021
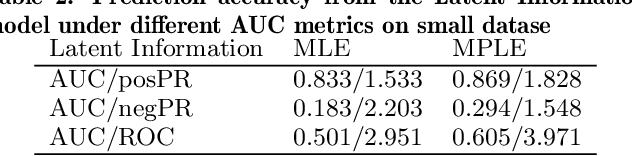
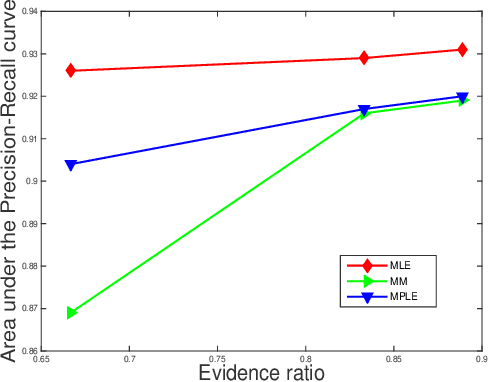
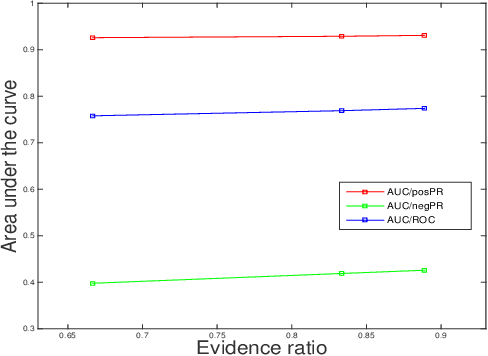
In the age of digital interaction, person-to-person relationships existing on social media may be different from the very same interactions that exist offline. Examining potential or spurious relationships between members in a social network is a fertile area of research for computer scientists -- here we examine how relationships can be predicted between two unconnected people in a social network by using area under Precison-Recall curve and ROC. Modeling the social network as a signed graph, we compare Triadic model,Latent Information model and Sentiment model and use them to predict peer to peer interactions, first using a plain signed network, and second using a signed network with comments as context. We see that our models are much better than random model and could complement each other in different cases.
RIS-Enabled Localization Continuity Under Near-Field Conditions
Sep 24, 2021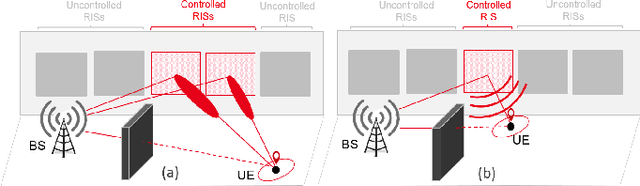
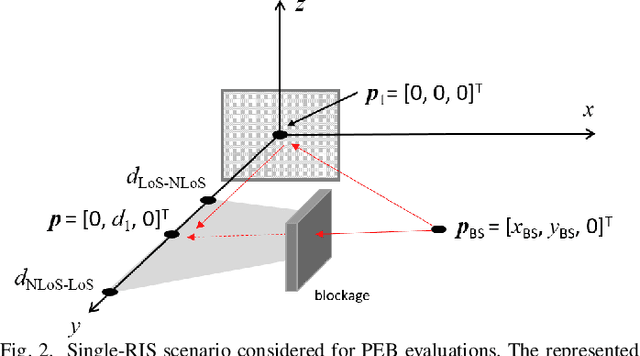
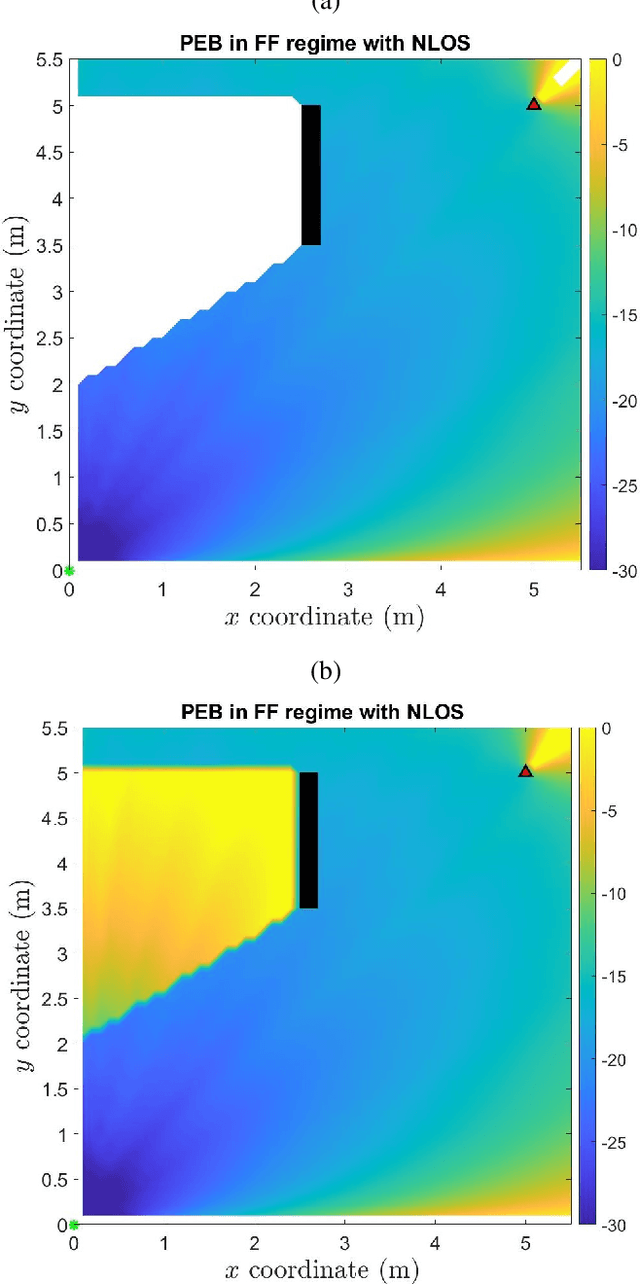
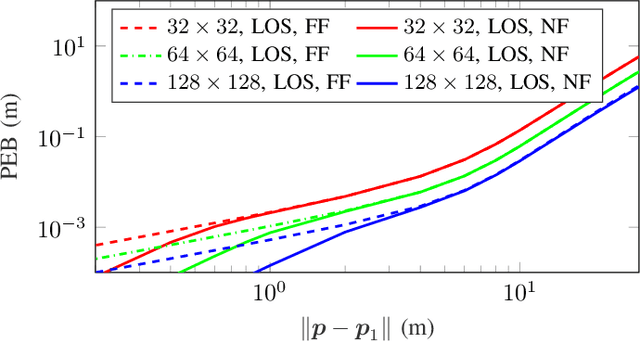
Reconfigurable intelligent surfaces (RISs) have the potential to enable user localization in scenarios where traditional approaches fail. Building on prior work in single-antenna RIS-enabled localization, we investigate the potential to exploit wavefront curvature in geometric near-field conditions. Via a Fisher information analysis, we demonstrate that while near-field improves localization accuracy mostly at short distances when the line-of-sight (LoS) path is present, it could still provide reasonable performance when this path is blocked by relying on a single RIS reflection.
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021
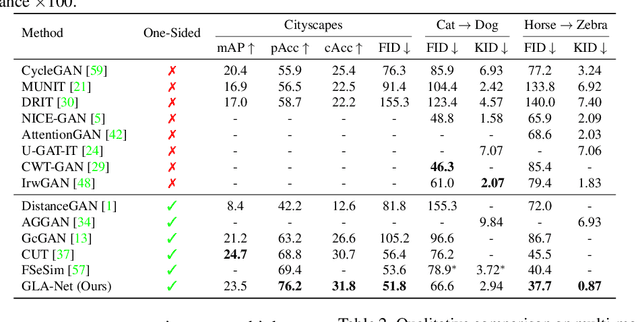
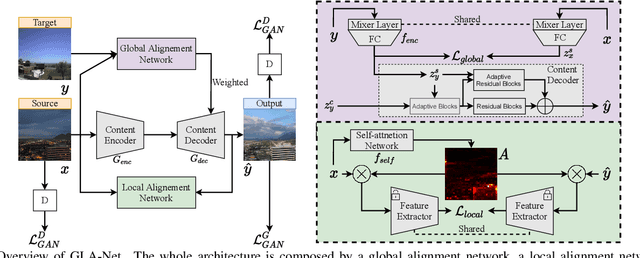
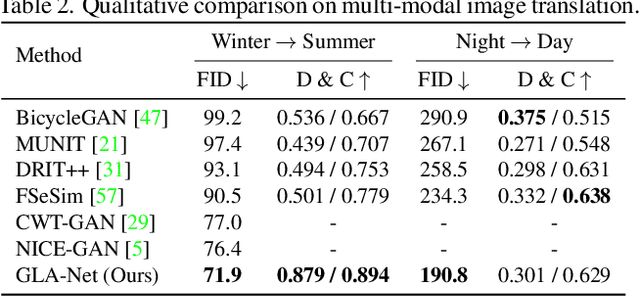
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
Cross-layer Navigation Convolutional Neural Network for Fine-grained Visual Classification
Jun 21, 2021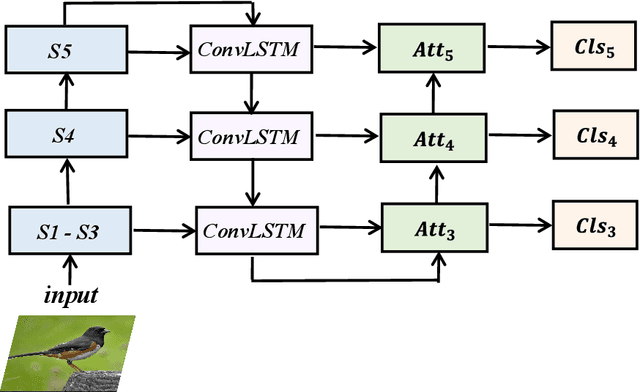
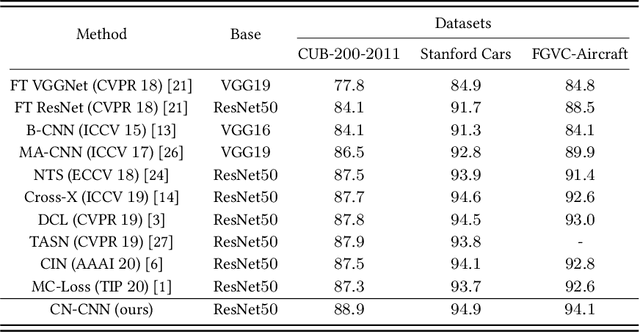
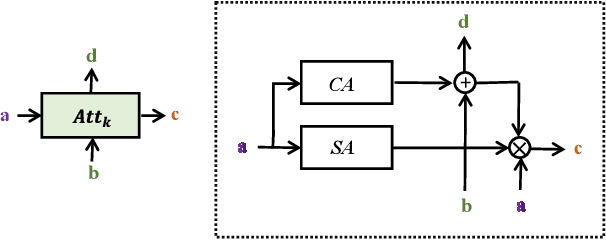

Fine-grained visual classification (FGVC) aims to classify sub-classes of objects in the same super-class (e.g., species of birds, models of cars). For the FGVC tasks, the essential solution is to find discriminative subtle information of the target from local regions. TraditionalFGVC models preferred to use the refined features,i.e., high-level semantic information for recognition and rarely use low-level in-formation. However, it turns out that low-level information which contains rich detail information also has effect on improving performance. Therefore, in this paper, we propose cross-layer navigation convolutional neural network for feature fusion. First, the feature maps extracted by the backbone network are fed into a convolutional long short-term memory model sequentially from high-level to low-level to perform feature aggregation. Then, attention mechanisms are used after feature fusion to extract spatial and channel information while linking the high-level semantic information and the low-level texture features, which can better locate the discriminative regions for the FGVC. In the experiments, three commonly used FGVC datasets, including CUB-200-2011, Stanford-Cars, andFGVC-Aircraft datasets, are used for evaluation and we demonstrate the superiority of the proposed method by comparing it with other referred FGVC methods to show that this method achieves superior results.
Dynamic Sequential Graph Learning for Click-Through Rate Prediction
Sep 26, 2021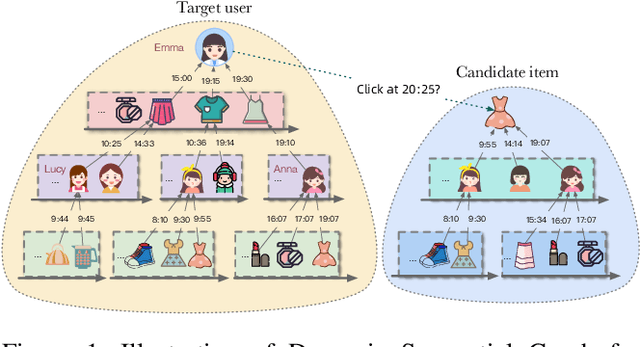
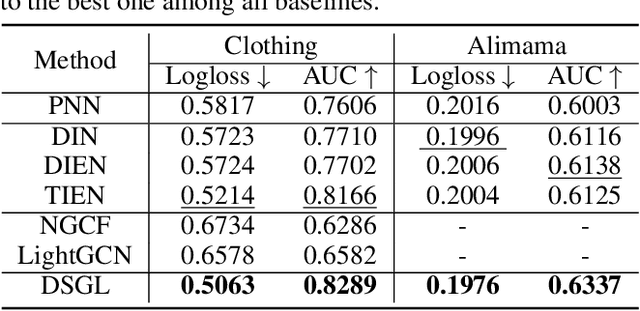
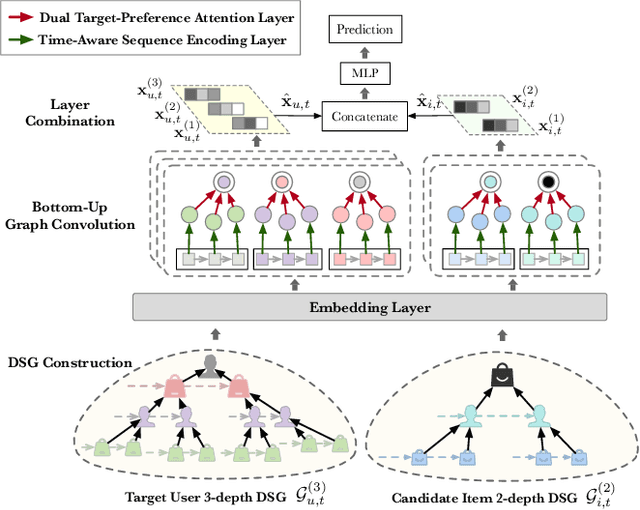
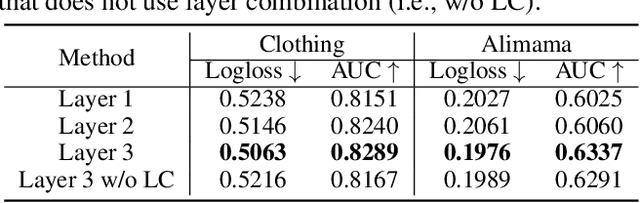
Click-through rate prediction plays an important role in the field of recommender system and many other applications. Existing methods mainly extract user interests from user historical behaviors. However, behavioral sequences only contain users' directly interacted items, which are limited by the system's exposure, thus they are often not rich enough to reflect all the potential interests. In this paper, we propose a novel method, named Dynamic Sequential Graph Learning (DSGL), to enhance users or items' representations by utilizing collaborative information from the local sub-graphs associated with users or items. Specifically, we design the Dynamic Sequential Graph (DSG), i.e., a lightweight ego subgraph with timestamps induced from historical interactions. At every scoring moment, we construct DSGs for the target user and the candidate item respectively. Based on the DSGs, we perform graph convolutional operations iteratively in a bottom-up manner to obtain the final representations of the target user and the candidate item. As for the graph convolution, we design a Time-aware Sequential Encoding Layer that leverages the interaction time information as well as temporal dependencies to learn evolutionary user and item dynamics. Besides, we propose a Target-Preference Dual Attention Layer, composed of a preference-aware attention module and a target-aware attention module, to automatically search for parts of behaviors that are relevant to the target and alleviate the noise from unreliable neighbors. Results on real-world CTR prediction benchmarks demonstrate the improvements brought by DSGL.
SSMF: Shifting Seasonal Matrix Factorization
Oct 25, 2021
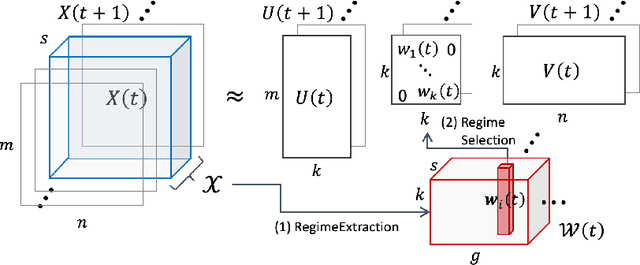

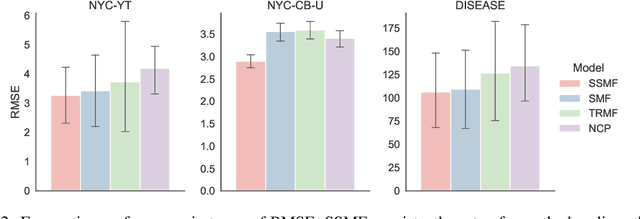
Given taxi-ride counts information between departure and destination locations, how can we forecast their future demands? In general, given a data stream of events with seasonal patterns that innovate over time, how can we effectively and efficiently forecast future events? In this paper, we propose Shifting Seasonal Matrix Factorization approach, namely SSMF, that can adaptively learn multiple seasonal patterns (called regimes), as well as switching between them. Our proposed method has the following properties: (a) it accurately forecasts future events by detecting regime shifts in seasonal patterns as the data stream evolves; (b) it works in an online setting, i.e., processes each observation in constant time and memory; (c) it effectively realizes regime shifts without human intervention by using a lossless data compression scheme. We demonstrate that our algorithm outperforms state-of-the-art baseline methods by accurately forecasting upcoming events on three real-world data streams.
Interpretable Visual Understanding with Cognitive Attention Network
Aug 14, 2021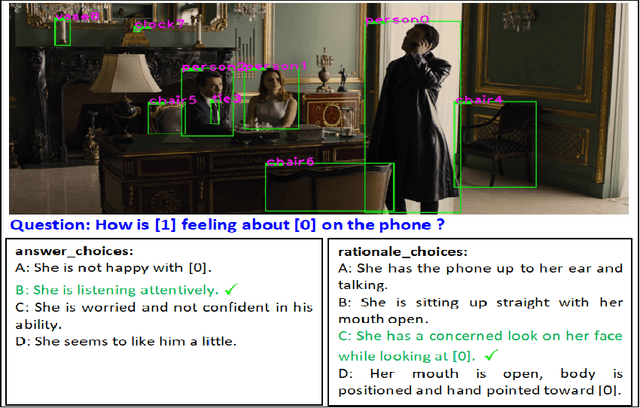
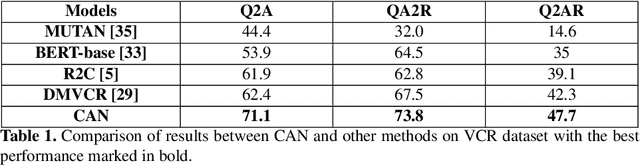
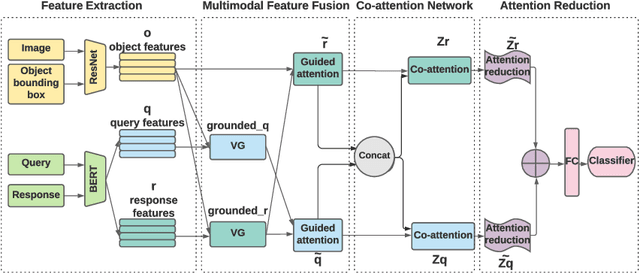
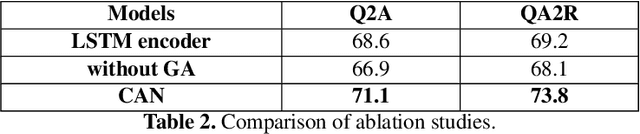
While image understanding on recognition-level has achieved remarkable advancements, reliable visual scene understanding requires comprehensive image understanding on recognition-level but also cognition-level, which calls for exploiting the multi-source information as well as learning different levels of understanding and extensive commonsense knowledge. In this paper, we propose a novel Cognitive Attention Network (CAN) for visual commonsense reasoning to achieve interpretable visual understanding. Specifically, we first introduce an image-text fusion module to fuse information from images and text collectively. Second, a novel inference module is designed to encode commonsense among image, query and response. Extensive experiments on large-scale Visual Commonsense Reasoning (VCR) benchmark dataset demonstrate the effectiveness of our approach. The implementation is publicly available at https://github.com/tanjatang/CAN
Learning to Ask for Data-Efficient Event Argument Extraction
Oct 01, 2021
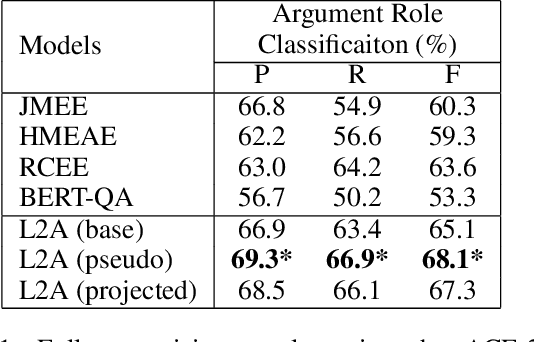
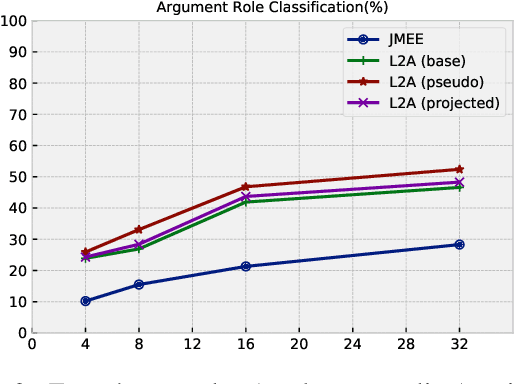
Event argument extraction (EAE) is an important task for information extraction to discover specific argument roles. In this study, we cast EAE as a question-based cloze task and empirically analyze fixed discrete token template performance. As generating human-annotated question templates is often time-consuming and labor-intensive, we further propose a novel approach called "Learning to Ask," which can learn optimized question templates for EAE without human annotations. Experiments using the ACE-2005 dataset demonstrate that our method based on optimized questions achieves state-of-the-art performance in both the few-shot and supervised settings.
Task-Oriented Multi-User Semantic Communications for Multimodal Data
Aug 16, 2021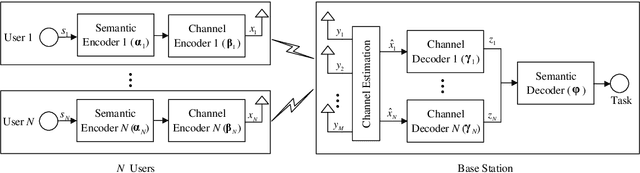
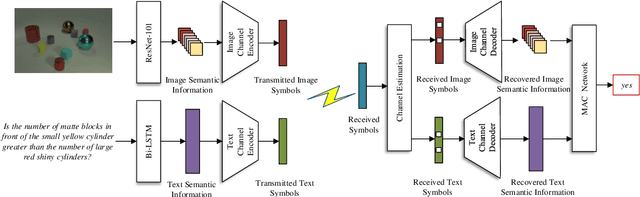
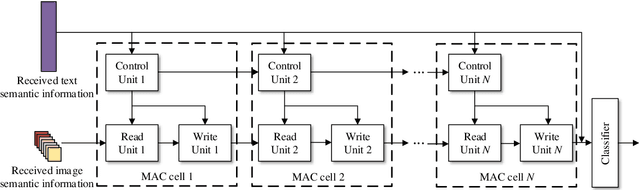
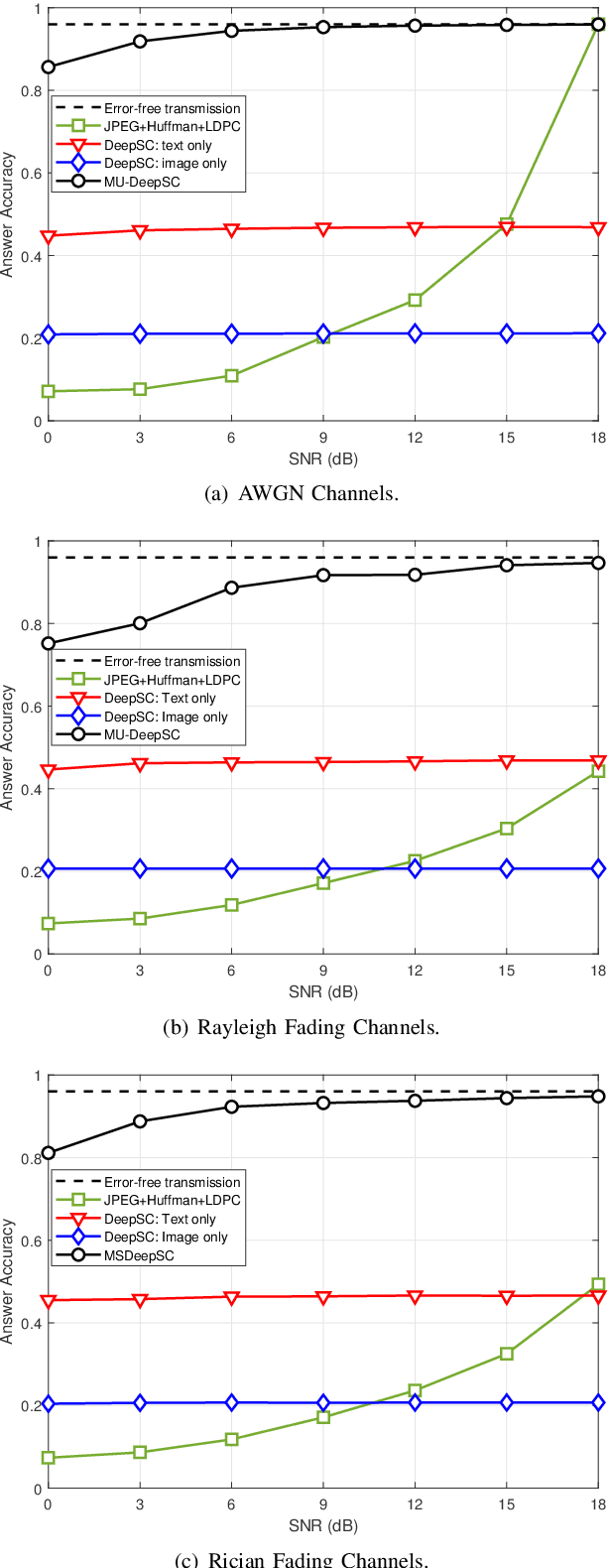
Semantic communications focus on the successful transmission of information relevant to the transmission task. In this paper, we investigate multi-users transmission for multimodal data in a task semantic communication system. We take the vision-answering as the semantic transmission task, in which part of the users transmit images and the other users transmit text to inquiry the information about the images. The receiver will provide answers based on the image and text from multiple users in the considered system. To exploit the correlation between the multimodal data from multiple users, we proposed a deep neural network enabled multi-user semantic communication system, named MU-DeepSC, for the visual question answering (VQA) task, in which the answer is highly dependent on the related image and text from the multiple users. Particularly, based on the memory, attention, and composition (MAC) neural network, we jointly design the transceiver and merge the MAC network to capture the features from the correlated multimodal data for serving the transmission task. The MU-DeepSC extracts the semantic information of image and text from different users and then generates the corresponding answers. Simulation results validate the feasibility of the proposed MU-DeepSC, which is more robust to various channel conditions than the traditional communication systems, especially in the low signal-to-noise (SNR) regime.