 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Keypoint Message Passing for Video-based Person Re-Identification
Nov 16, 2021
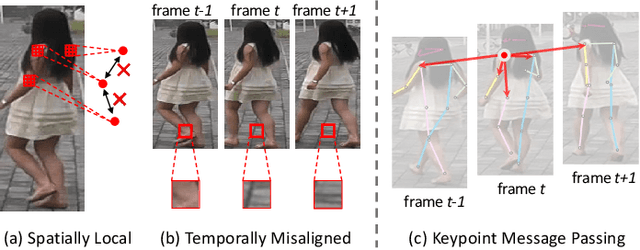
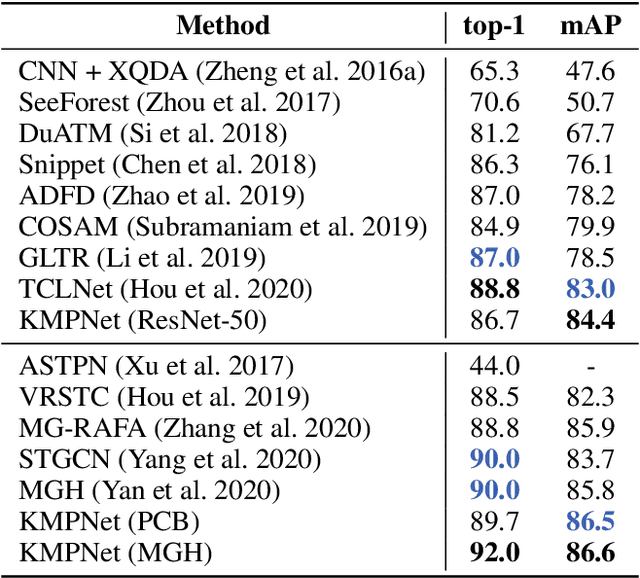
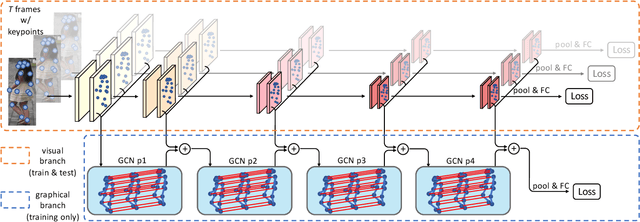
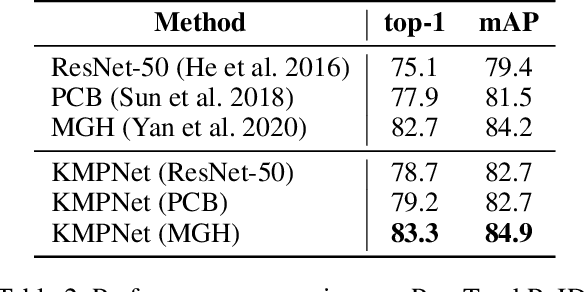
Video-based person re-identification (re-ID) is an important technique in visual surveillance systems which aims to match video snippets of people captured by different cameras. Existing methods are mostly based on convolutional neural networks (CNNs), whose building blocks either process local neighbor pixels at a time, or, when 3D convolutions are used to model temporal information, suffer from the misalignment problem caused by person movement. In this paper, we propose to overcome the limitations of normal convolutions with a human-oriented graph method. Specifically, features located at person joint keypoints are extracted and connected as a spatial-temporal graph. These keypoint features are then updated by message passing from their connected nodes with a graph convolutional network (GCN). During training, the GCN can be attached to any CNN-based person re-ID model to assist representation learning on feature maps, whilst it can be dropped after training for better inference speed. Our method brings significant improvements over the CNN-based baseline model on the MARS dataset with generated person keypoints and a newly annotated dataset: PoseTrackReID. It also defines a new state-of-the-art method in terms of top-1 accuracy and mean average precision in comparison to prior works.
Multi-phase Liver Tumor Segmentation with Spatial Aggregation and Uncertain Region Inpainting
Aug 02, 2021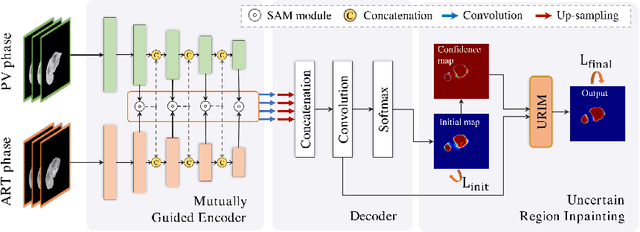
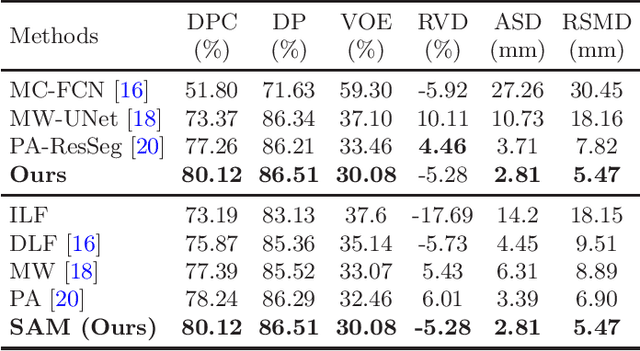
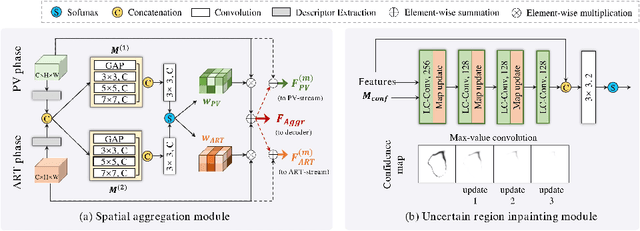
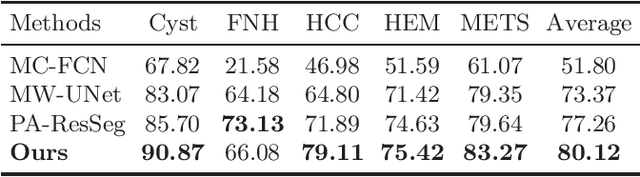
Multi-phase computed tomography (CT) images provide crucial complementary information for accurate liver tumor segmentation (LiTS). State-of-the-art multi-phase LiTS methods usually fused cross-phase features through phase-weighted summation or channel-attention based concatenation. However, these methods ignored the spatial (pixel-wise) relationships between different phases, hence leading to insufficient feature integration. In addition, the performance of existing methods remains subject to the uncertainty in segmentation, which is particularly acute in tumor boundary regions. In this work, we propose a novel LiTS method to adequately aggregate multi-phase information and refine uncertain region segmentation. To this end, we introduce a spatial aggregation module (SAM), which encourages per-pixel interactions between different phases, to make full use of cross-phase information. Moreover, we devise an uncertain region inpainting module (URIM) to refine uncertain pixels using neighboring discriminative features. Experiments on an in-house multi-phase CT dataset of focal liver lesions (MPCT-FLLs) demonstrate that our method achieves promising liver tumor segmentation and outperforms state-of-the-arts.
GeoVectors: A Linked Open Corpus of OpenStreetMap Embeddings on World Scale
Aug 30, 2021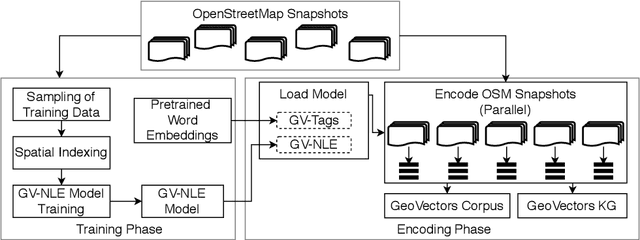
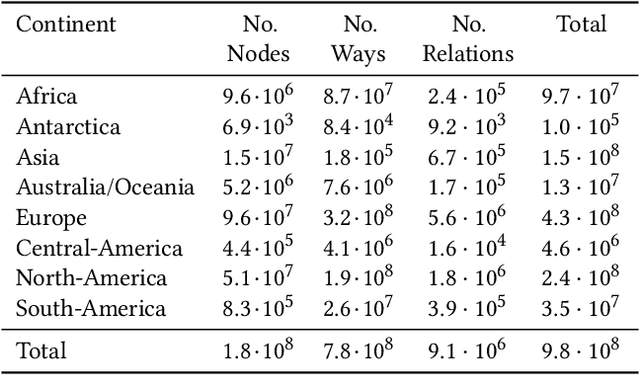
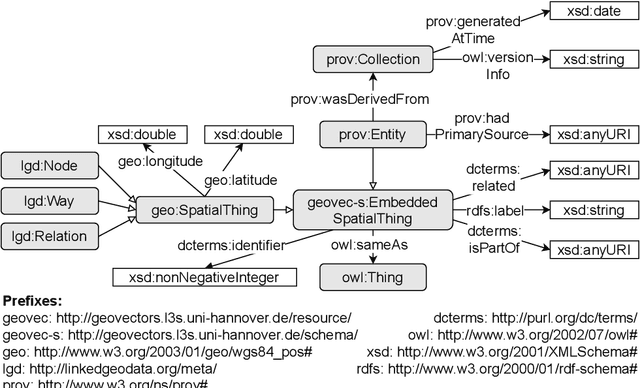

OpenStreetMap (OSM) is currently the richest publicly available information source on geographic entities (e.g., buildings and roads) worldwide. However, using OSM entities in machine learning models and other applications is challenging due to the large scale of OSM, the extreme heterogeneity of entity annotations, and a lack of a well-defined ontology to describe entity semantics and properties. This paper presents GeoVectors - a unique, comprehensive world-scale linked open corpus of OSM entity embeddings covering the entire OSM dataset and providing latent representations of over 980 million geographic entities in 180 countries. The GeoVectors corpus captures semantic and geographic dimensions of OSM entities and makes these entities directly accessible to machine learning algorithms and semantic applications. We create a semantic description of the GeoVectors corpus, including identity links to the Wikidata and DBpedia knowledge graphs to supply context information. Furthermore, we provide a SPARQL endpoint - a semantic interface that offers direct access to the semantic and latent representations of geographic entities in OSM.
Traffic4cast -- Large-scale Traffic Prediction using 3DResNet and Sparse-UNet
Nov 10, 2021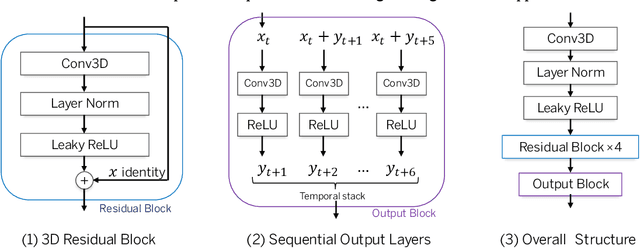
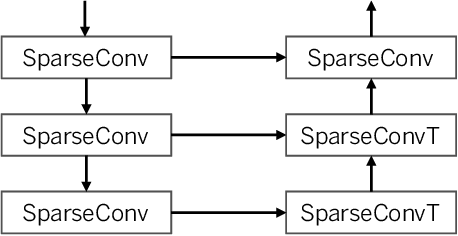
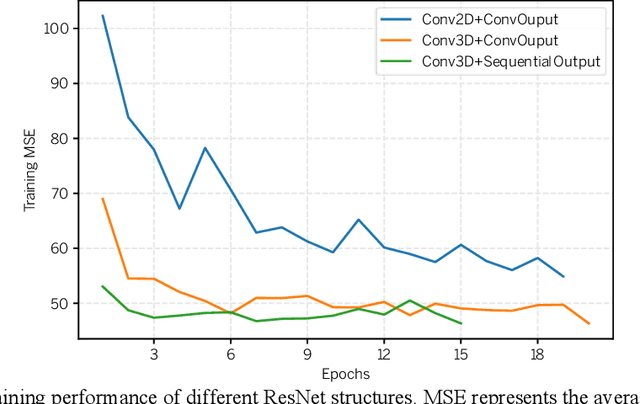

The IARAI competition Traffic4cast 2021 aims to predict short-term city-wide high-resolution traffic states given the static and dynamic traffic information obtained previously. The aim is to build a machine learning model for predicting the normalized average traffic speed and flow of the subregions of multiple large-scale cities using historical data points. The model is supposed to be generic, in a way that it can be applied to new cities. By considering spatiotemporal feature learning and modeling efficiency, we explore 3DResNet and Sparse-UNet approaches for the tasks in this competition. The 3DResNet based models use 3D convolution to learn the spatiotemporal features and apply sequential convolutional layers to enhance the temporal relationship of the outputs. The Sparse-UNet model uses sparse convolutions as the backbone for spatiotemporal feature learning. Since the latter algorithm mainly focuses on non-zero data points of the inputs, it dramatically reduces the computation time, while maintaining a competitive accuracy. Our results show that both of the proposed models achieve much better performance than the baseline algorithms. The codes and pretrained models are available at https://github.com/resuly/Traffic4Cast-2021.
Data Context Adaptation for Accurate Recommendation with Additional Information
Aug 22, 2019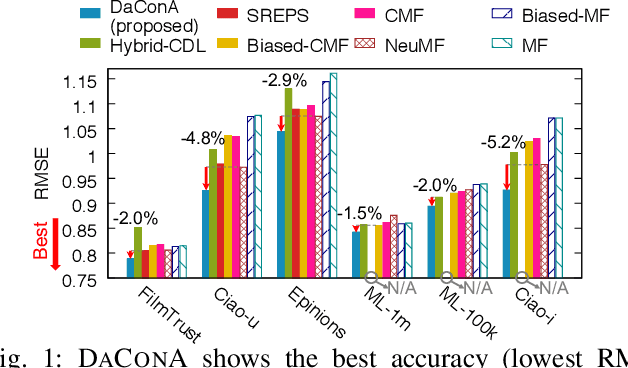
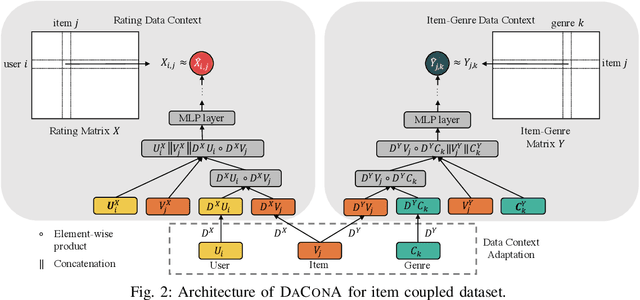
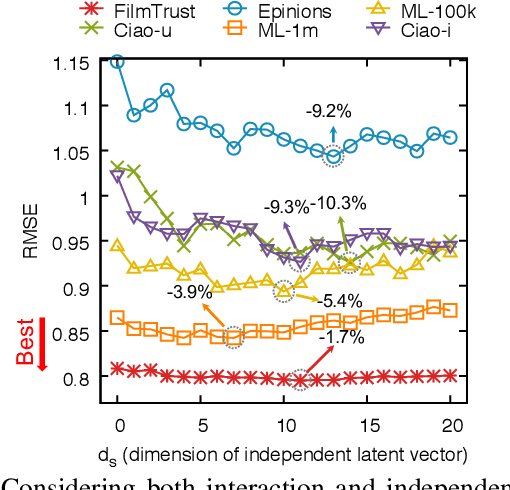
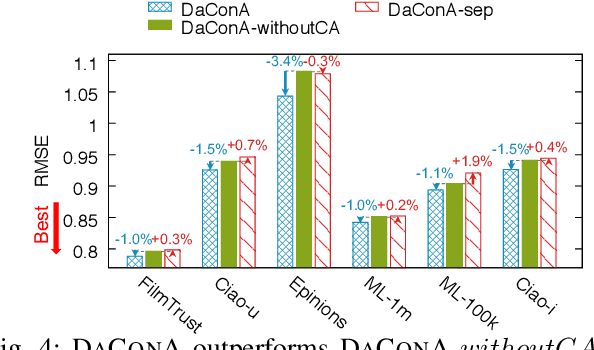
Given a sparse rating matrix and an auxiliary matrix of users or items, how can we accurately predict missing ratings considering different data contexts of entities? Many previous studies proved that utilizing the additional information with rating data is helpful to improve the performance. However, existing methods are limited in that 1) they ignore the fact that data contexts of rating and auxiliary matrices are different, 2) they have restricted capability of expressing independence information of users or items, and 3) they assume the relation between a user and an item is linear. We propose DaConA, a neural network based method for recommendation with a rating matrix and an auxiliary matrix. DaConA is designed with the following three main ideas. First, we propose a data context adaptation layer to extract pertinent features for different data contexts. Second, DaConA represents each entity with latent interaction vector and latent independence vector. Unlike previous methods, both of the two vectors are not limited in size. Lastly, while previous matrix factorization based methods predict missing values through the inner-product of latent vectors, DaConA learns a non-linear function of them via a neural network. We show that DaConA is a generalized algorithm including the standard matrix factorization and the collective matrix factorization as special cases. Through comprehensive experiments on real-world datasets, we show that DaConA provides the state-of-the-art accuracy.
Dynamic Causal Bayesian Optimization
Oct 26, 2021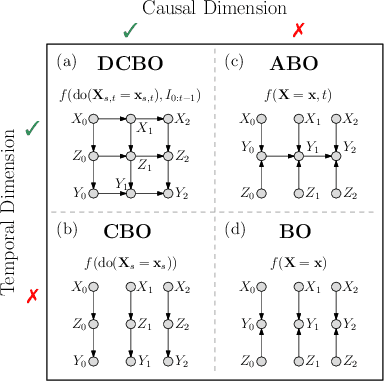
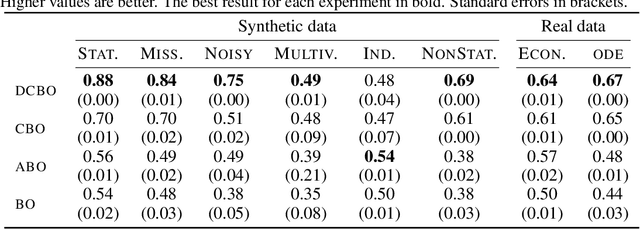
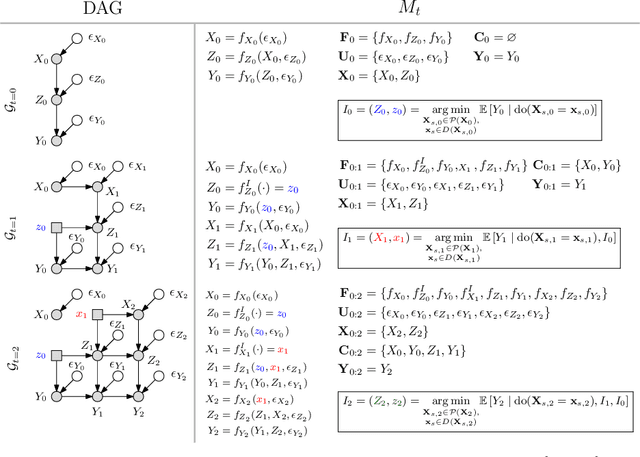
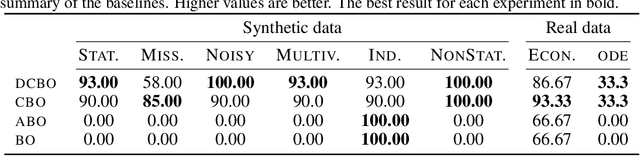
This paper studies the problem of performing a sequence of optimal interventions in a causal dynamical system where both the target variable of interest and the inputs evolve over time. This problem arises in a variety of domains e.g. system biology and operational research. Dynamic Causal Bayesian Optimization (DCBO) brings together ideas from sequential decision making, causal inference and Gaussian process (GP) emulation. DCBO is useful in scenarios where all causal effects in a graph are changing over time. At every time step DCBO identifies a local optimal intervention by integrating both observational and past interventional data collected from the system. We give theoretical results detailing how one can transfer interventional information across time steps and define a dynamic causal GP model which can be used to quantify uncertainty and find optimal interventions in practice. We demonstrate how DCBO identifies optimal interventions faster than competing approaches in multiple settings and applications.
Deep Neural Network Voice Activity Detector for Downsampled Audio Data: An Experiment Report
Aug 12, 2021
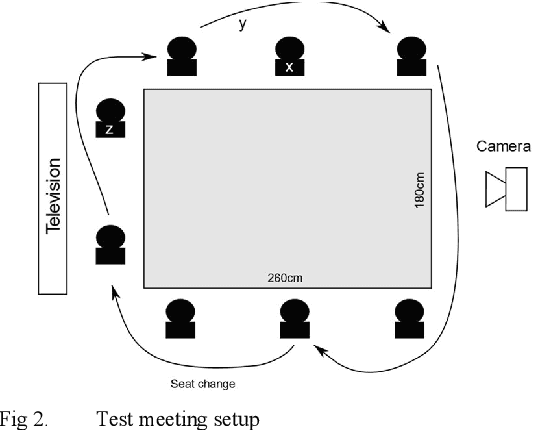
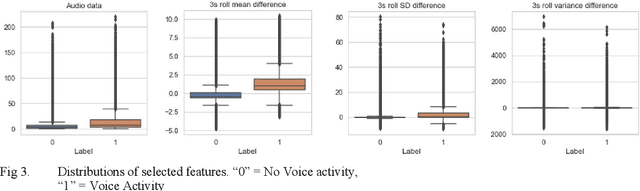

Sociometric badges are an emerging technology for study how teams interact in physical places. Audio data recorded by sociometric badges is often downsampled to not record discussions of the sociometric badges holders. To gain more information about interactions inside teams with sociometric badges a Voice Activity Detector (VAD) is deployed to measure verbal activity of the interaction. Detecting voice activity from downsampled audio data is challenging because down-sampling destroys information from the data. We developed a VAD using deep learning techniques that achieves only moderate accuracy in a low noise meeting setting and in across variable noise levels despite excellent validation performance. Experiences and lessons learned while developing the VAD are discussed.
Word-level Sign Language Recognition with Multi-stream Neural Networks Focusing on Local Regions
Jun 30, 2021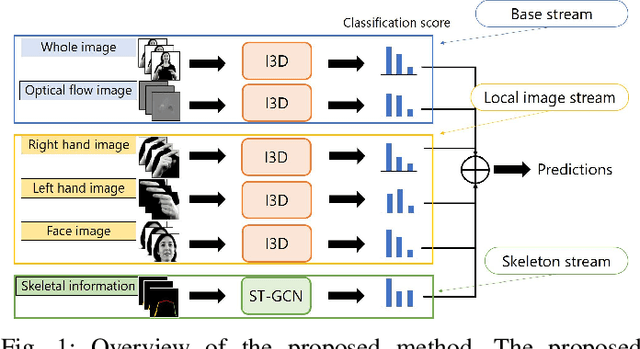
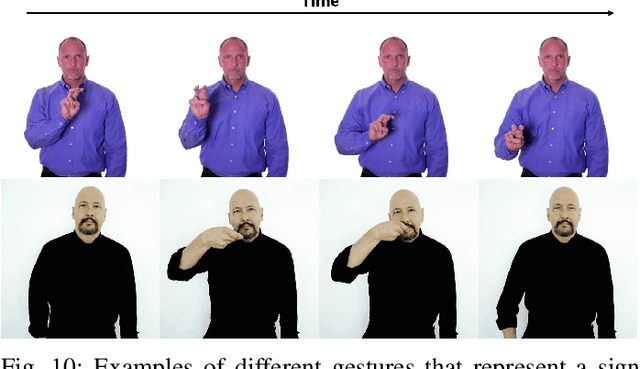
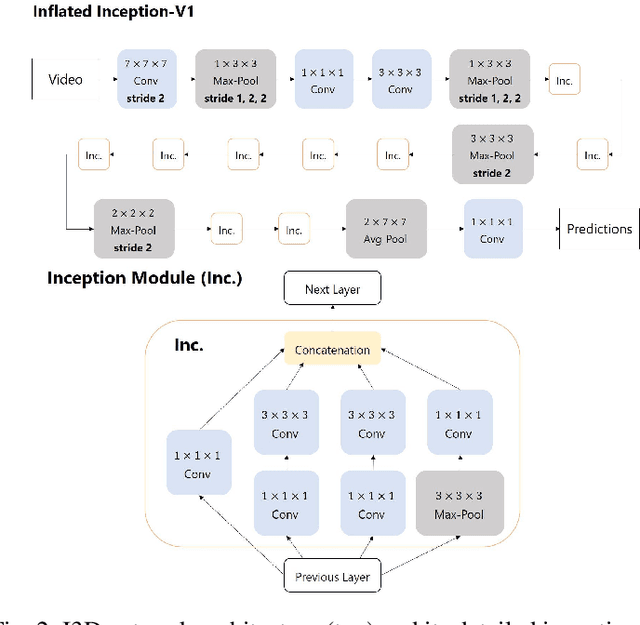
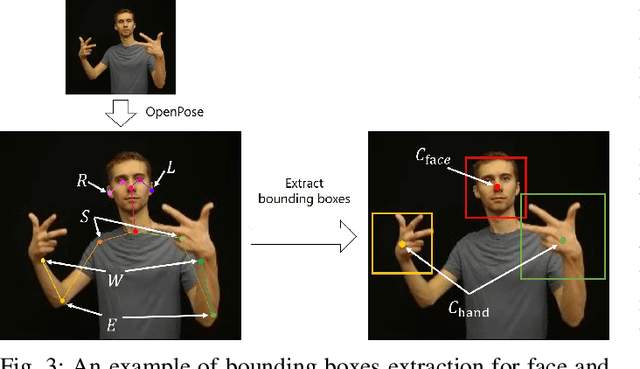
In recent years, Word-level Sign Language Recognition (WSLR) research has gained popularity in the computer vision community, and thus various approaches have been proposed. Among these approaches, the method using I3D network achieves the highest recognition accuracy on large public datasets for WSLR. However, the method with I3D only utilizes appearance information of the upper body of the signers to recognize sign language words. On the other hand, in WSLR, the information of local regions, such as the hand shape and facial expression, and the positional relationship among the body and both hands are important. Thus in this work, we utilized local region images of both hands and face, along with skeletal information to capture local information and the positions of both hands relative to the body, respectively. In other words, we propose a novel multi-stream WSLR framework, in which a stream with local region images and a stream with skeletal information are introduced by extending I3D network to improve the recognition accuracy of WSLR. From the experimental results on WLASL dataset, it is evident that the proposed method has achieved about 15% improvement in the Top-1 accuracy than the existing conventional methods.
Theoretical Limit of Radar Parameter Estimation
Jul 11, 2021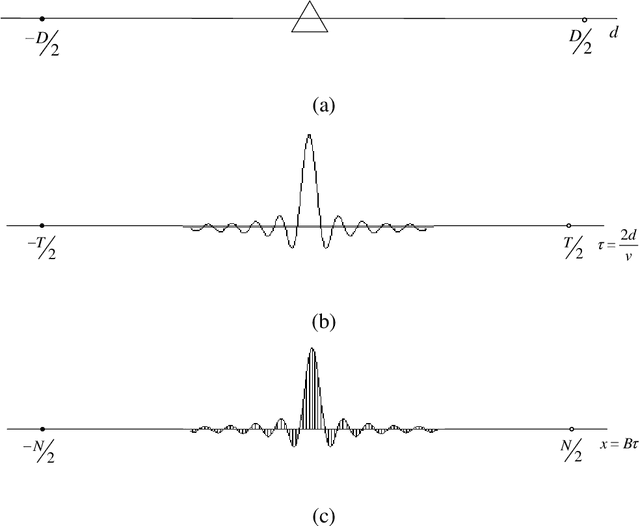



In the field of radar parameter estimation, Cramer-Rao bound (CRB) is a commonly used theoretical limit. However, CRB is only achievable under high signal-to-noise (SNR) and does not adequately characterize performance in low and medium SNRs. In this paper, we employ the thoughts and methodologies of Shannon's information theory to study the theoretical limit of radar parameter estimation. Based on the posteriori probability density function of targets' parameters, joint range-scattering information and entropy error (EE) are defined to evaluate the performance. The closed-form approximation of EE is derived, which indicates that EE degenerates to the CRB in the high SNR region. For radar ranging, it is proved that the range information and the entropy error can be achieved by the sampling a posterior probability estimator, whose performance is entirely determined by the theoretical posteriori probability density function of the radar parameter estimation system. The range information and the entropy error are simulated with sampling a posterior probability estimator, where they are shown to outperform the CRB as they can be achieved under all SNR conditions
Click-Based Student Performance Prediction: A Clustering Guided Meta-Learning Approach
Nov 16, 2021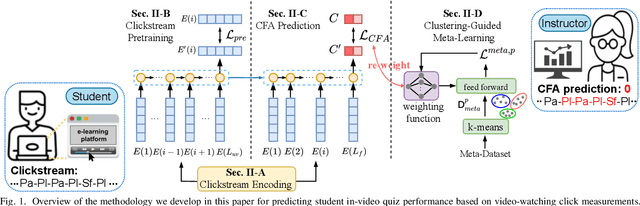
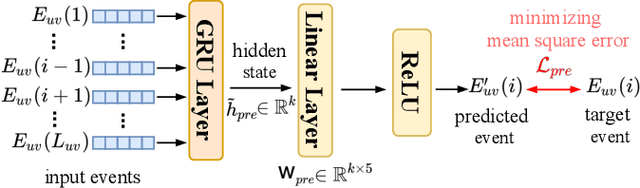
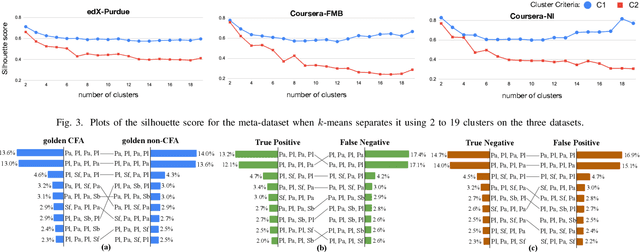
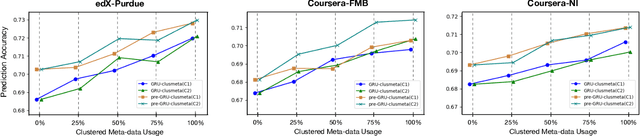
We study the problem of predicting student knowledge acquisition in online courses from clickstream behavior. Motivated by the proliferation of eLearning lecture delivery, we specifically focus on student in-video activity in lectures videos, which consist of content and in-video quizzes. Our methodology for predicting in-video quiz performance is based on three key ideas we develop. First, we model students' clicking behavior via time-series learning architectures operating on raw event data, rather than defining hand-crafted features as in existing approaches that may lose important information embedded within the click sequences. Second, we develop a self-supervised clickstream pre-training to learn informative representations of clickstream events that can initialize the prediction model effectively. Third, we propose a clustering guided meta-learning-based training that optimizes the prediction model to exploit clusters of frequent patterns in student clickstream sequences. Through experiments on three real-world datasets, we demonstrate that our method obtains substantial improvements over two baseline models in predicting students' in-video quiz performance. Further, we validate the importance of the pre-training and meta-learning components of our framework through ablation studies. Finally, we show how our methodology reveals insights on video-watching behavior associated with knowledge acquisition for useful learning analytics.