 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Global and Local Alignment Networks for Unpaired Image-to-Image Translation
Nov 19, 2021

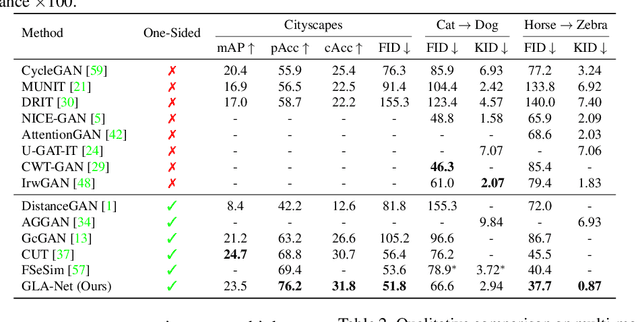
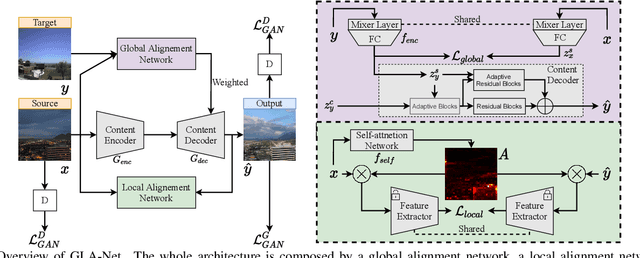
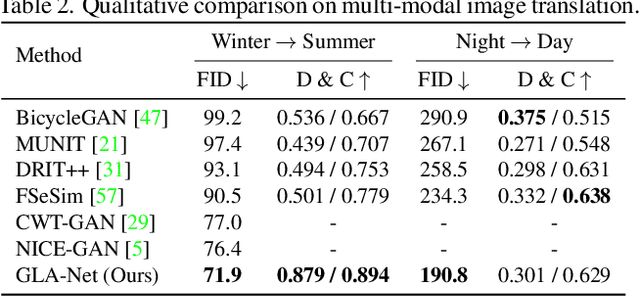
The goal of unpaired image-to-image translation is to produce an output image reflecting the target domain's style while keeping unrelated contents of the input source image unchanged. However, due to the lack of attention to the content change in existing methods, the semantic information from source images suffers from degradation during translation. In the paper, to address this issue, we introduce a novel approach, Global and Local Alignment Networks (GLA-Net). The global alignment network aims to transfer the input image from the source domain to the target domain. To effectively do so, we learn the parameters (mean and standard deviation) of multivariate Gaussian distributions as style features by using an MLP-Mixer based style encoder. To transfer the style more accurately, we employ an adaptive instance normalization layer in the encoder, with the parameters of the target multivariate Gaussian distribution as input. We also adopt regularization and likelihood losses to further reduce the domain gap and produce high-quality outputs. Additionally, we introduce a local alignment network, which employs a pretrained self-supervised model to produce an attention map via a novel local alignment loss, ensuring that the translation network focuses on relevant pixels. Extensive experiments conducted on five public datasets demonstrate that our method effectively generates sharper and more realistic images than existing approaches. Our code is available at https://github.com/ygjwd12345/GLANet.
Automatic Impact-sounding Acoustic Inspection of Concrete Structure
Oct 25, 2021
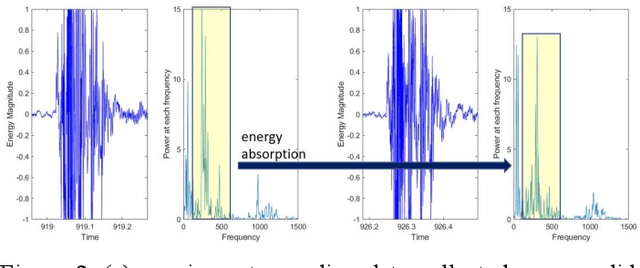
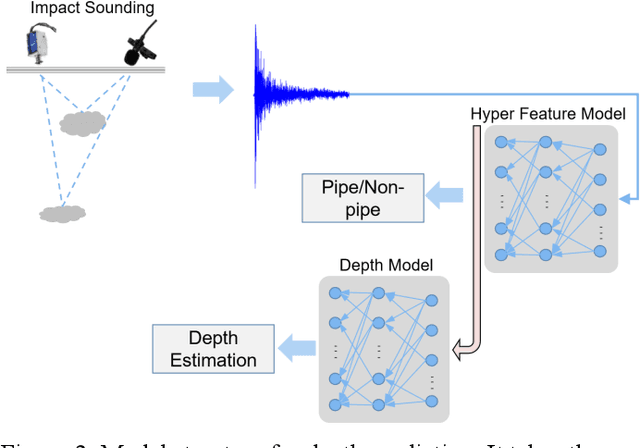

Impact sounding signal has been shown to contain information about structural integrity flaws and subsurface objects from previous research. As non-destructive testing (NDT) method, one of the biggest challenges in impact sounding based inspection is the subsurface targets detection and reconstruction. This paper presents the importance and practicability of using solenoids to trigger impact sounding signal and using acoustic data to reconstruct subsurface objects to address this issue. First, by taking advantage of Visual Simultaneous Localization and Mapping (V-SLAM), we could obtain the 3D position of the robot during the inspection. Second, our NDE method is based on Frequency Density (FD) analysis for the Fast Fourier Transform (FFT) of the impact sounding signal. At last, by combining the 3D position data and acoustic data, this paper creates a 3D map to highlight the possible subsurface objects. The experimental results demonstrate the feasibility of the method.
Single image deep defocus estimation and its applications
Jul 30, 2021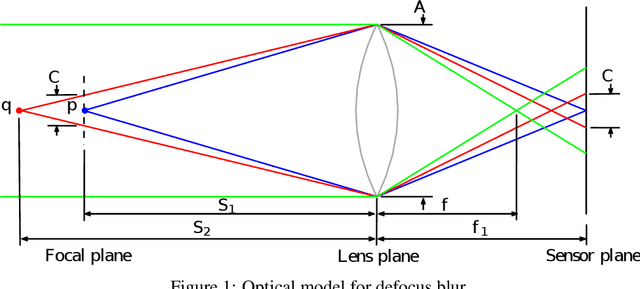


The depth information is useful in many image processing applications. However, since taking a picture is a process of projection of a 3D scene onto a 2D imaging sensor, the depth information is embedded in the image. Extracting the depth information from the image is a challenging task. A guiding principle is that the level of blurriness due to defocus is related to the distance between the object and the focal plane. Based on this principle and the widely used assumption that Gaussian blur is a good model for defocus blur, we formulate the problem of estimating the spatially varying defocus blurriness as a Gaussian blur classification problem. We solved the problem by training a deep neural network to classify image patches into one of the 20 levels of blurriness. We have created a dataset of more than 500000 image patches of size 32x32 which are used to train and test several well-known network models. We find that MobileNetV2 is suitable for this application due to its low memory requirement and high accuracy. The trained model is used to determine the patch blurriness which is then refined by applying an iterative weighted guided filter. The result is a defocus map that carries the information of the degree of blurriness for each pixel. We compare the proposed method with state-of-the-art techniques and we demonstrate its successful applications in adaptive image enhancement, defocus magnification, and multi-focus image fusion.
Locality-Sensitive Hashing for f-Divergences: Mutual Information Loss and Beyond
Oct 28, 2019
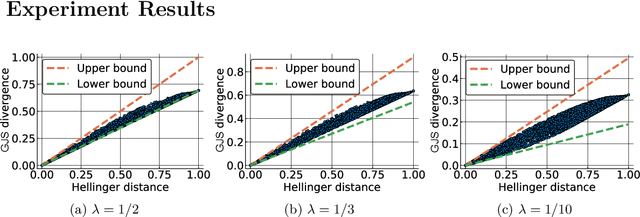
Computing approximate nearest neighbors in high dimensional spaces is a central problem in large-scale data mining with a wide range of applications in machine learning and data science. A popular and effective technique in computing nearest neighbors approximately is the locality-sensitive hashing (LSH) scheme. In this paper, we aim to develop LSH schemes for distance functions that measure the distance between two probability distributions, particularly for f-divergences as well as a generalization to capture mutual information loss. First, we provide a general framework to design LHS schemes for f-divergence distance functions and develop LSH schemes for the generalized Jensen-Shannon divergence and triangular discrimination in this framework. We show a two-sided approximation result for approximation of the generalized Jensen-Shannon divergence by the Hellinger distance, which may be of independent interest. Next, we show a general method of reducing the problem of designing an LSH scheme for a Krein kernel (which can be expressed as the difference of two positive definite kernels) to the problem of maximum inner product search. We exemplify this method by applying it to the mutual information loss, due to its several important applications such as model compression.
Autonomous Curiosity for Real-Time Training Onboard Robotic Agents
Aug 29, 2021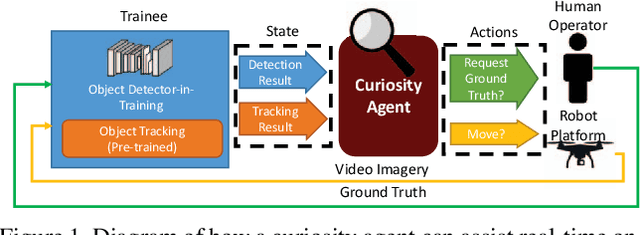
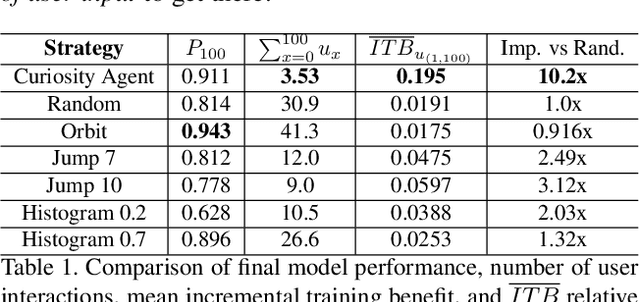
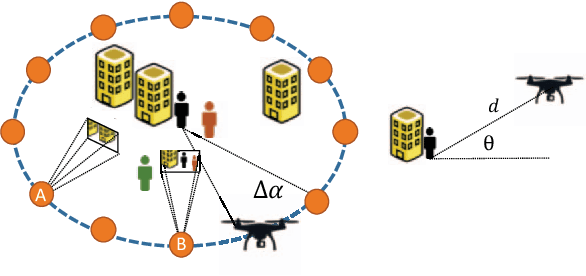
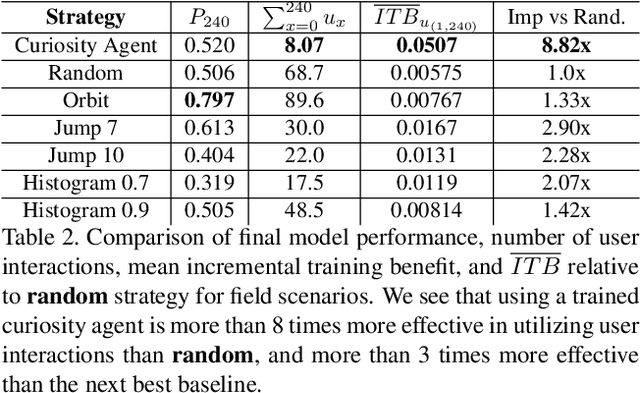
Learning requires both study and curiosity. A good learner is not only good at extracting information from the data given to it, but also skilled at finding the right new information to learn from. This is especially true when a human operator is required to provide the ground truth - such a source should only be queried sparingly. In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a robotic platform, one where motion produces new views of the subject. We propose a deep reinforcement learning approach that decides when to ask the human user for ground truth, and when to move. Through a series of experiments, we demonstrate that our agent learns a movement and request policy that is at least 3x more effective at using human user interactions to train an object detector than untrained approaches, and is generalizable to a variety of subjects and environments.
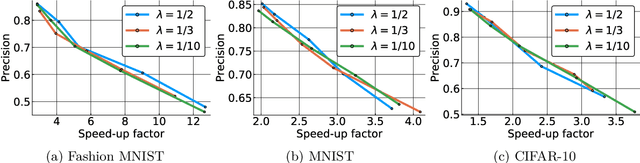
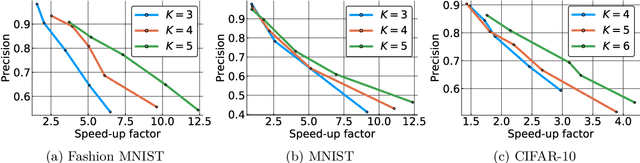
* 10 pages, 9 figures. Accepted in IEEE Winter Conference on Applications of Computer Vision (WACV), 2019. arXiv admin note: text overlap with arXiv:1902.01569
Optimal Discrete Constellation Inputs for Aggregated LiFi-WiFi Networks
Nov 04, 2021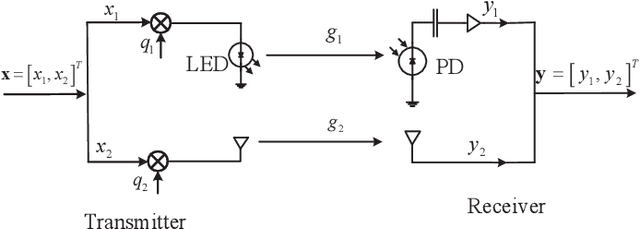

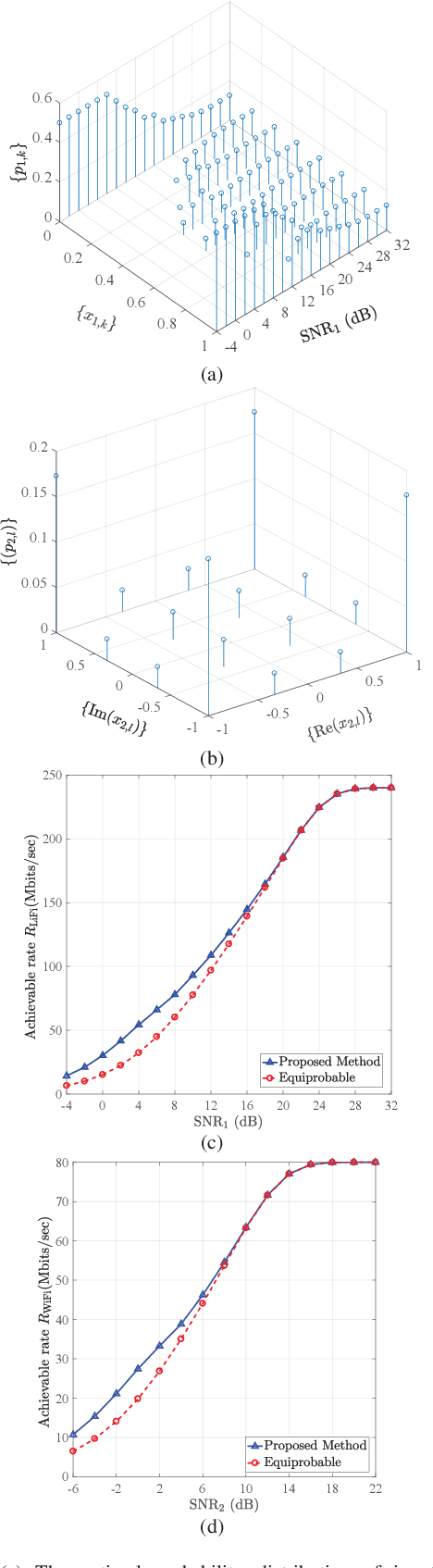

In this paper, we investigate the performance of a practical aggregated LiFi-WiFi system with the discrete constellation inputs from a practical view. We derive the achievable rate expressions of the aggregated LiFi-WiFi system for the first time. Then, we study the rate maximization problem via optimizing the constellation distribution and power allocation jointly. Specifically, a multilevel mercy-filling power allocation scheme is proposed by exploiting the relationship between the mutual information and minimum mean-squared error (MMSE) of discrete inputs. Meanwhile, an inexact gradient descent method is proposed for obtaining the optimal probability distributions. To strike a balance between the computational complexity and the transmission performance, we further develop a framework that maximizes the lower bound of the achievable rate where the optimal power allocation can be obtained in closed forms and the constellation distributions problem can be solved efficiently by Frank-Wolfe method. Extensive numerical results show that the optimized strategies are able to provide significant gains over the state-of-the-art schemes in terms of the achievable rate.
Explainable multiple abnormality classification of chest CT volumes with AxialNet and HiResCAM
Nov 24, 2021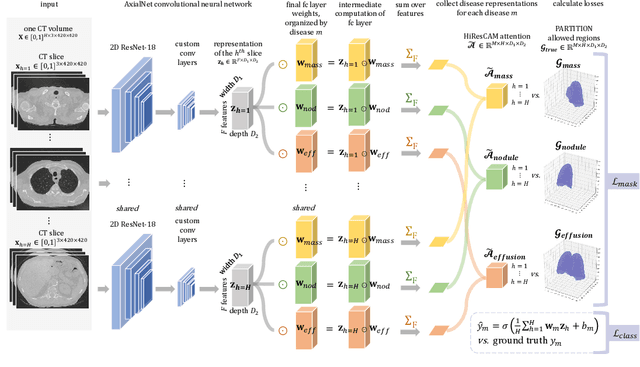
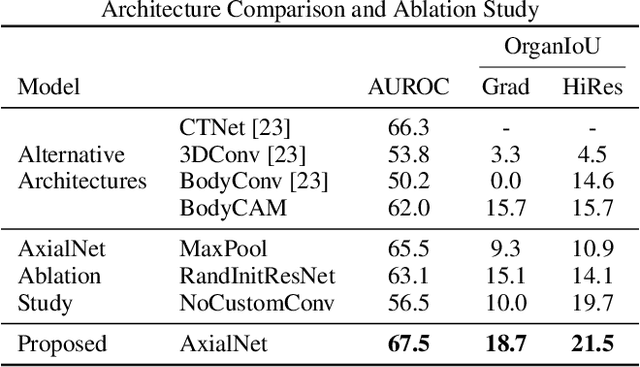
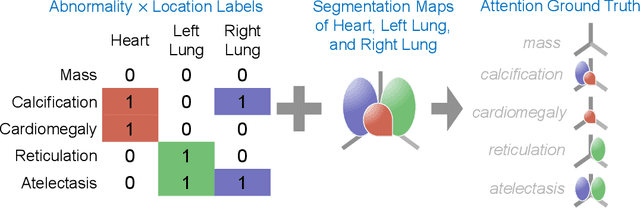

Understanding model predictions is critical in healthcare, to facilitate rapid verification of model correctness and to guard against use of models that exploit confounding variables. We introduce the challenging new task of explainable multiple abnormality classification in volumetric medical images, in which a model must indicate the regions used to predict each abnormality. To solve this task, we propose a multiple instance learning convolutional neural network, AxialNet, that allows identification of top slices for each abnormality. Next we incorporate HiResCAM, an attention mechanism, to identify sub-slice regions. We prove that for AxialNet, HiResCAM explanations are guaranteed to reflect the locations the model used, unlike Grad-CAM which sometimes highlights irrelevant locations. Armed with a model that produces faithful explanations, we then aim to improve the model's learning through a novel mask loss that leverages HiResCAM and 3D allowed regions to encourage the model to predict abnormalities based only on the organs in which those abnormalities appear. The 3D allowed regions are obtained automatically through a new approach, PARTITION, that combines location information extracted from radiology reports with organ segmentation maps obtained through morphological image processing. Overall, we propose the first model for explainable multi-abnormality prediction in volumetric medical images, and then use the mask loss to achieve a 33% improvement in organ localization of multiple abnormalities in the RAD-ChestCT data set of 36,316 scans, representing the state of the art. This work advances the clinical applicability of multiple abnormality modeling in chest CT volumes.
Theoretical Limit of Radar Parameter Estimation
Jul 11, 2021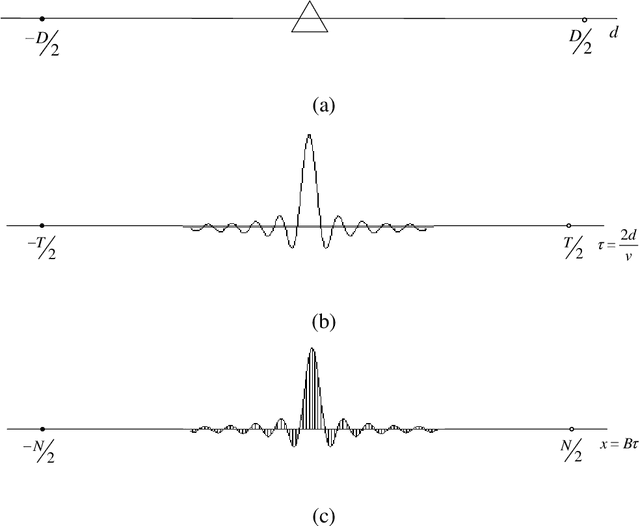



In the field of radar parameter estimation, Cramer-Rao bound (CRB) is a commonly used theoretical limit. However, CRB is only achievable under high signal-to-noise (SNR) and does not adequately characterize performance in low and medium SNRs. In this paper, we employ the thoughts and methodologies of Shannon's information theory to study the theoretical limit of radar parameter estimation. Based on the posteriori probability density function of targets' parameters, joint range-scattering information and entropy error (EE) are defined to evaluate the performance. The closed-form approximation of EE is derived, which indicates that EE degenerates to the CRB in the high SNR region. For radar ranging, it is proved that the range information and the entropy error can be achieved by the sampling a posterior probability estimator, whose performance is entirely determined by the theoretical posteriori probability density function of the radar parameter estimation system. The range information and the entropy error are simulated with sampling a posterior probability estimator, where they are shown to outperform the CRB as they can be achieved under all SNR conditions
Fusing Heterogeneous Factors with Triaffine Mechanism for Nested Named Entity Recognition
Oct 14, 2021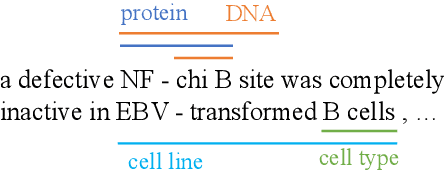
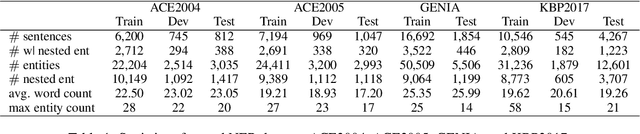
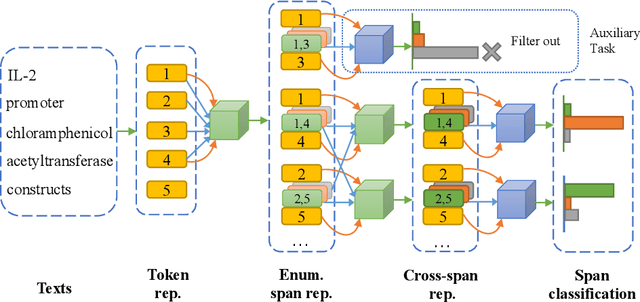
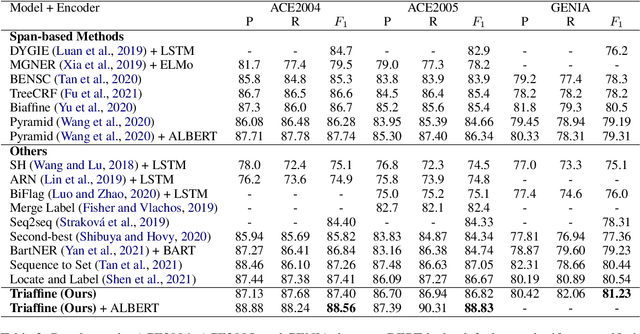
Nested entities are observed in many domains due to their compositionality, which cannot be easily recognized by the widely-used sequence labeling framework. A natural solution is to treat the task as a span classification problem. To increase performance on span representation and classification, it is crucial to effectively integrate all useful information of different formats, which we refer to heterogeneous factors including tokens, labels, boundaries, and related spans. To fuse these heterogeneous factors, we propose a novel triaffine mechanism including triaffine attention and scoring, which interacts with multiple factors in both the stages of representation and classification. Experiments results show that our proposed method achieves the state-of-the-art F1 scores on four nested NER datasets: ACE2004, ACE2005, GENIA, and KBP2017.
Temporal Network Embedding via Tensor Factorization
Aug 22, 2021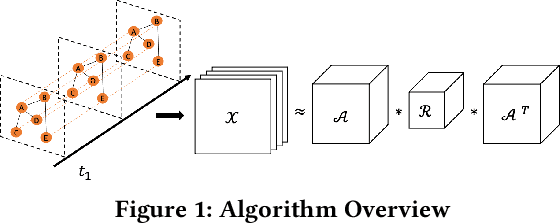
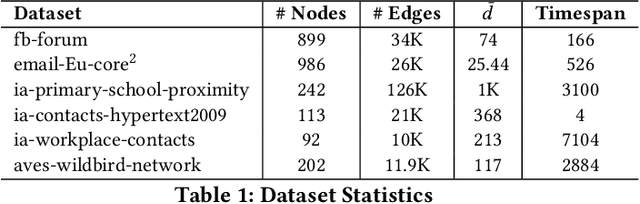
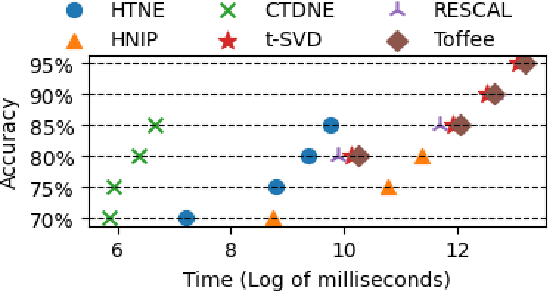
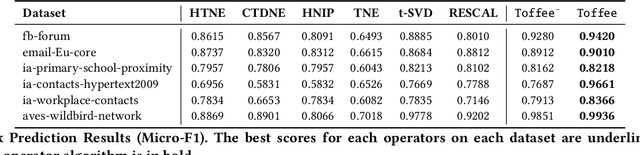
Representation learning on static graph-structured data has shown a significant impact on many real-world applications. However, less attention has been paid to the evolving nature of temporal networks, in which the edges are often changing over time. The embeddings of such temporal networks should encode both graph-structured information and the temporally evolving pattern. Existing approaches in learning temporally evolving network representations fail to capture the temporal interdependence. In this paper, we propose Toffee, a novel approach for temporal network representation learning based on tensor decomposition. Our method exploits the tensor-tensor product operator to encode the cross-time information, so that the periodic changes in the evolving networks can be captured. Experimental results demonstrate that Toffee outperforms existing methods on multiple real-world temporal networks in generating effective embeddings for the link prediction tasks.