 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Crash Report Data Analysis for Creating Scenario-Wise, Spatio-Temporal Attention Guidance to Support Computer Vision-based Perception of Fatal Crash Risks
Sep 06, 2021

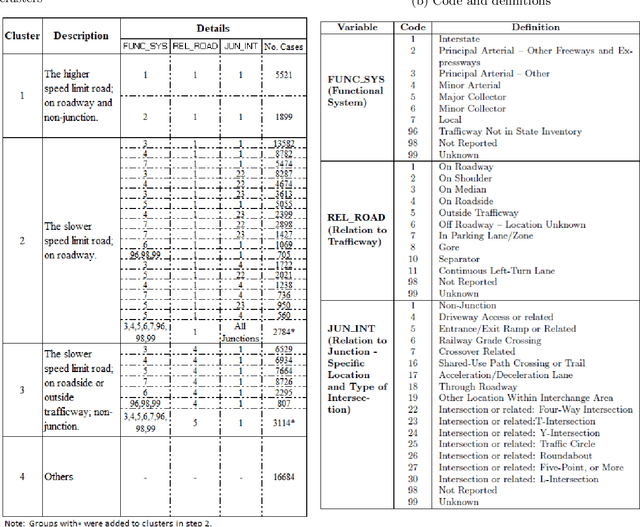
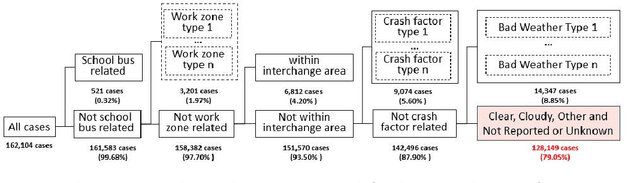
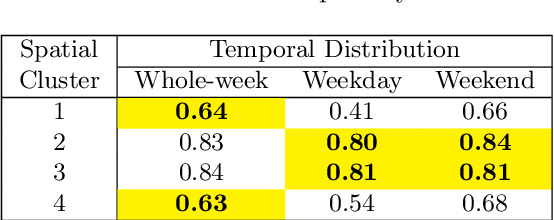
Reducing traffic fatalities and serious injuries is a top priority of the US Department of Transportation. The computer vision (CV)-based crash anticipation in the near-crash phase is receiving growing attention. The ability to perceive fatal crash risks earlier is also critical because it will improve the reliability of crash anticipation. Yet, annotated image data for training a reliable AI model for the early visual perception of crash risks are not abundant. The Fatality Analysis Reporting System contains big data of fatal crashes. It is a reliable data source for learning the relationship between driving scene characteristics and fatal crashes to compensate for the limitation of CV. Therefore, this paper develops a data analytics model, named scenario-wise, Spatio-temporal attention guidance, from fatal crash report data, which can estimate the relevance of detected objects to fatal crashes from their environment and context information. First, the paper identifies five sparse variables that allow for decomposing the 5-year fatal crash dataset to develop scenario-wise attention guidance. Then, exploratory analysis of location- and time-related variables of the crash report data suggests reducing fatal crashes to spatially defined groups. The group's temporal pattern is an indicator of the similarity of fatal crashes in the group. Hierarchical clustering and K-means clustering merge the spatially defined groups into six clusters according to the similarity of their temporal patterns. After that, association rule mining discovers the statistical relationship between the temporal information of driving scenes with crash features, for each cluster. The paper shows how the developed attention guidance supports the design and implementation of a preliminary CV model that can identify objects of a possibility to involve in fatal crashes from their environment and context information.
* 20 pages, 14 figures, submitted and accepted by Accident Analysis & Prevention
Automated Remote Sensing Forest Inventory Using Satelite Imagery
Oct 16, 2021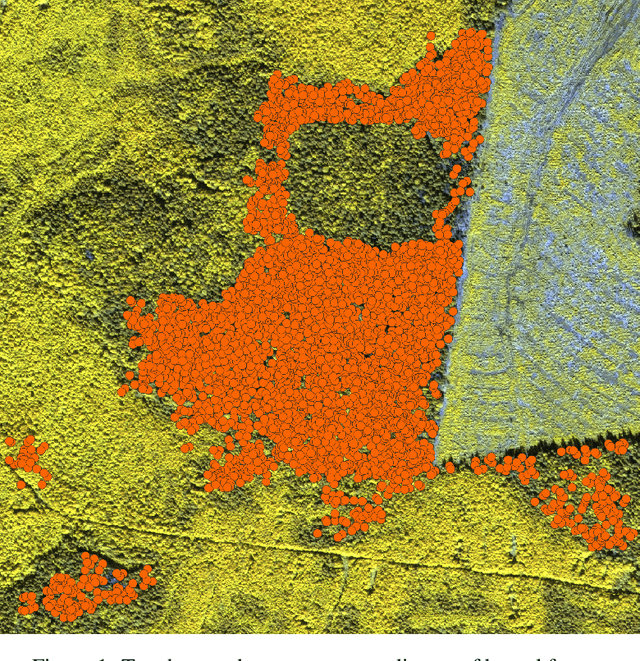
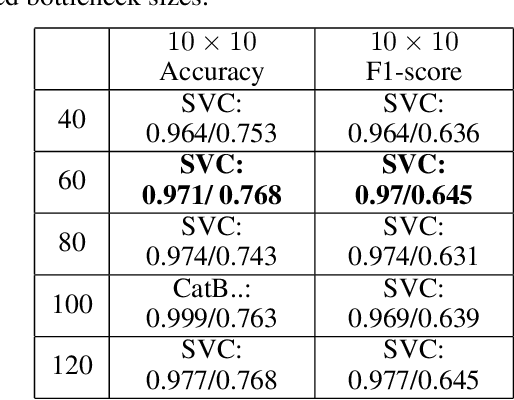
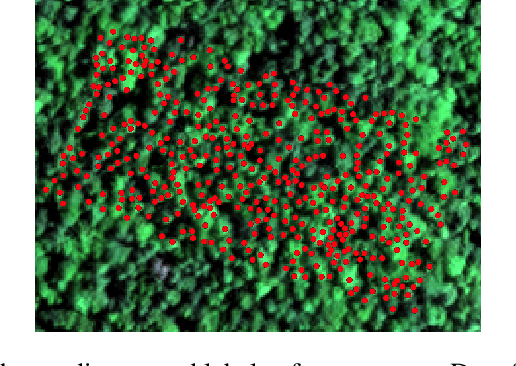
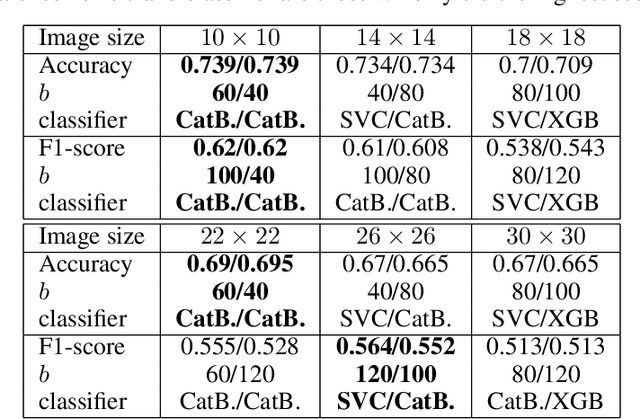
For many countries like Russia, Canada, or the USA, a robust and detailed tree species inventory is essential to manage their forests sustainably. Since one can not apply unmanned aerial vehicle (UAV) imagery-based approaches to large-scale forest inventory applications, the utilization of machine learning algorithms on satellite imagery is a rising topic of research. Although satellite imagery quality is relatively low, additional spectral channels provide a sufficient amount of information for tree crown classification tasks. Assuming that tree crowns are detected already, we use embeddings of tree crowns generated by Autoencoders as a data set to train classical Machine Learning algorithms. We compare our Autoencoder (AE) based approach to traditional convolutional neural networks (CNN) end-to-end classifiers.
TraVLR: Now You See It, Now You Don't! Evaluating Cross-Modal Transfer of Visio-Linguistic Reasoning
Nov 21, 2021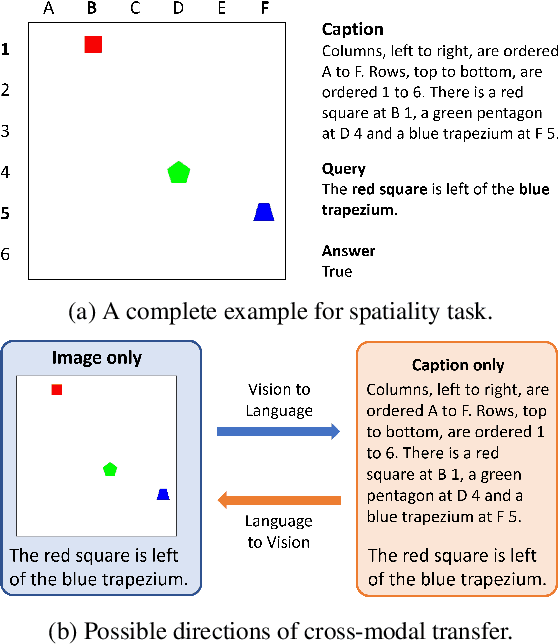

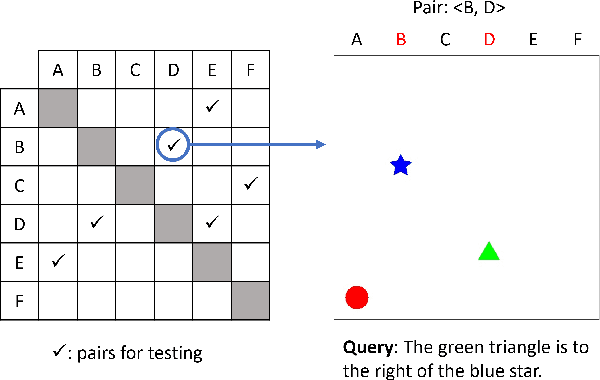
Numerous visio-linguistic (V+L) representation learning methods have been developed, yet existing datasets do not evaluate the extent to which they represent visual and linguistic concepts in a unified space. Inspired by the crosslingual transfer and psycholinguistics literature, we propose a novel evaluation setting for V+L models: zero-shot cross-modal transfer. Existing V+L benchmarks also often report global accuracy scores on the entire dataset, rendering it difficult to pinpoint the specific reasoning tasks that models fail and succeed at. To address this issue and enable the evaluation of cross-modal transfer, we present TraVLR, a synthetic dataset comprising four V+L reasoning tasks. Each example encodes the scene bimodally such that either modality can be dropped during training/testing with no loss of relevant information. TraVLR's training and testing distributions are also constrained along task-relevant dimensions, enabling the evaluation of out-of-distribution generalisation. We evaluate four state-of-the-art V+L models and find that although they perform well on the test set from the same modality, all models fail to transfer cross-modally and have limited success accommodating the addition or deletion of one modality. In alignment with prior work, we also find these models to require large amounts of data to learn simple spatial relationships. We release TraVLR as an open challenge for the research community.
Global Interaction Modelling in Vision Transformer via Super Tokens
Nov 25, 2021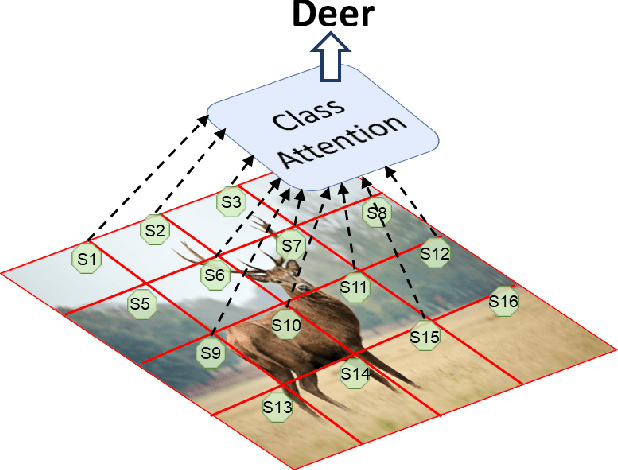
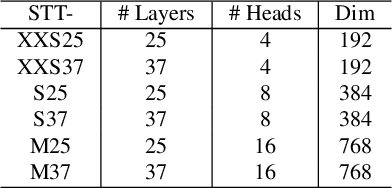
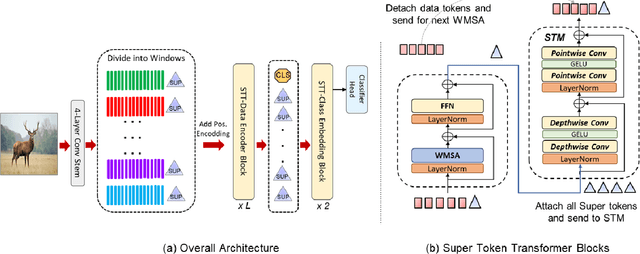
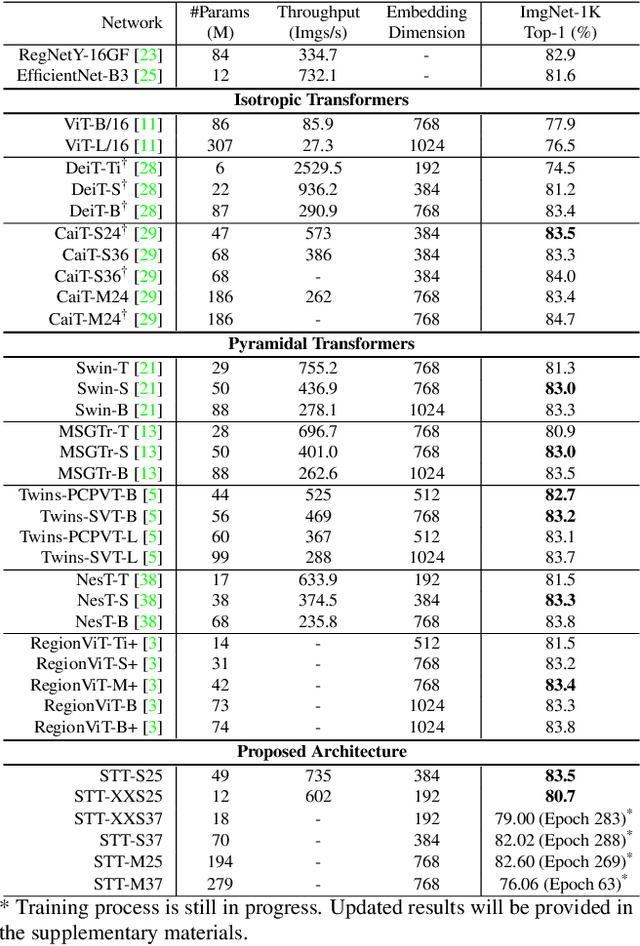
With the popularity of Transformer architectures in computer vision, the research focus has shifted towards developing computationally efficient designs. Window-based local attention is one of the major techniques being adopted in recent works. These methods begin with very small patch size and small embedding dimensions and then perform strided convolution (patch merging) in order to reduce the feature map size and increase embedding dimensions, hence, forming a pyramidal Convolutional Neural Network (CNN) like design. In this work, we investigate local and global information modelling in transformers by presenting a novel isotropic architecture that adopts local windows and special tokens, called Super tokens, for self-attention. Specifically, a single Super token is assigned to each image window which captures the rich local details for that window. These tokens are then employed for cross-window communication and global representation learning. Hence, most of the learning is independent of the image patches $(N)$ in the higher layers, and the class embedding is learned solely based on the Super tokens $(N/M^2)$ where $M^2$ is the window size. In standard image classification on Imagenet-1K, the proposed Super tokens based transformer (STT-S25) achieves 83.5\% accuracy which is equivalent to Swin transformer (Swin-B) with circa half the number of parameters (49M) and double the inference time throughput. The proposed Super token transformer offers a lightweight and promising backbone for visual recognition tasks.
Blind Channel Estimation for MIMO Systems via Variational Inference
Nov 16, 2021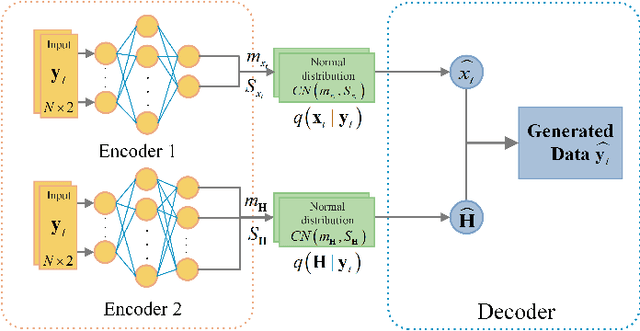
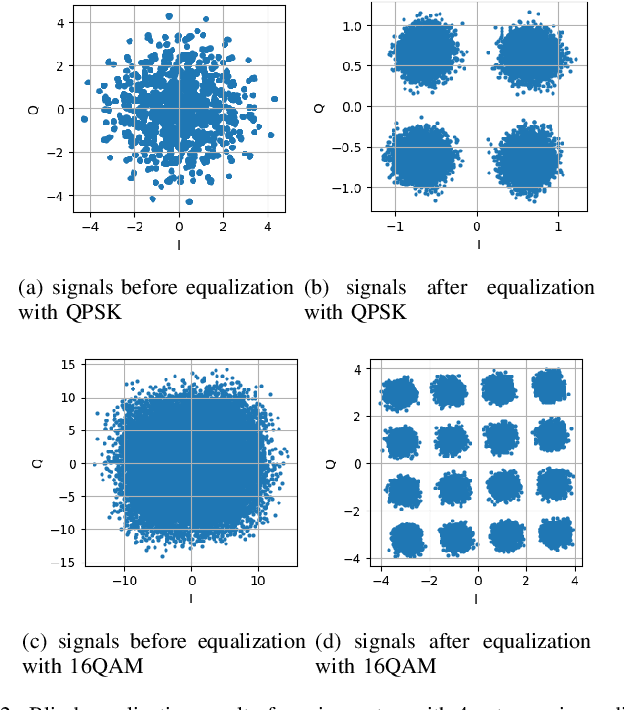
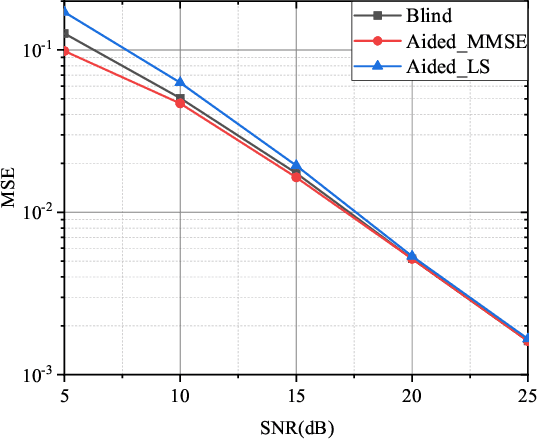
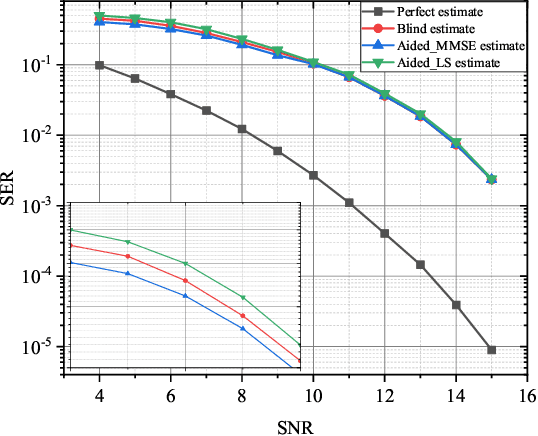
In this paper, we investigate the blind channel estimation problem for MIMO systems under Rayleigh fading channel. Conventional MIMO communication techniques require transmitting a considerable amount of training symbols as pilots in each data block to obtain the channel state information (CSI) such that the transmitted signals can be successfully recovered. However, the pilot overhead and contamination become a bottleneck for the practical application of MIMO systems with the increase of the number of antennas. To overcome this obstacle, we propose a blind channel estimation framework, where we introduce an auxiliary posterior distribution of CSI and the transmitted signals given the received signals to derive a lower bound to the intractable likelihood function of the received signal. Meanwhile, we generate this auxiliary distribution by a neural network based variational inference framework, which is trained by maximizing the lower bound. The optimal auxiliary distribution which approaches real prior distribution is then leveraged to obtain the maximum a posterior (MAP) estimation of channel matrix and transmitted data. The simulation results demonstrate that the performance of the proposed blind channel estimation method closely approaches that of the conventional pilot-aided methods in terms of the channel estimation error and symbol error rate (SER) of the detected signals even without the help of pilots.
Image-specific Convolutional Kernel Modulation for Single Image Super-resolution
Nov 16, 2021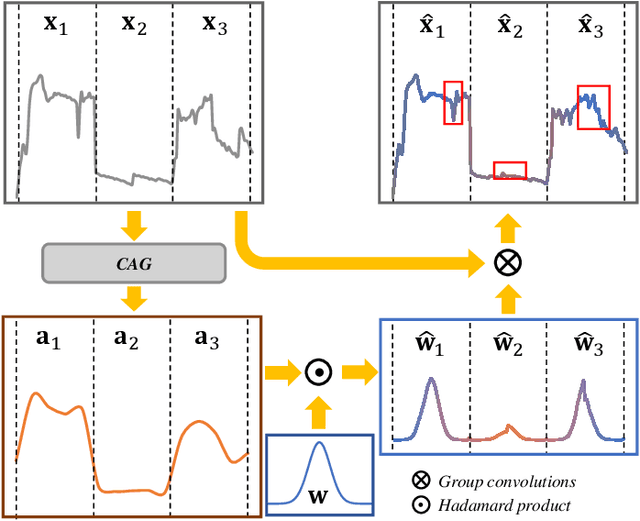
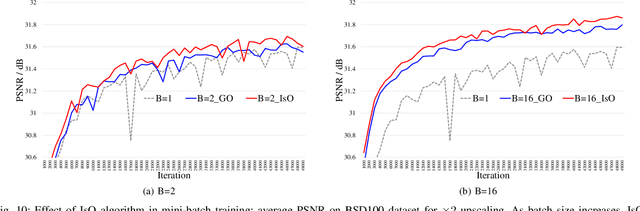
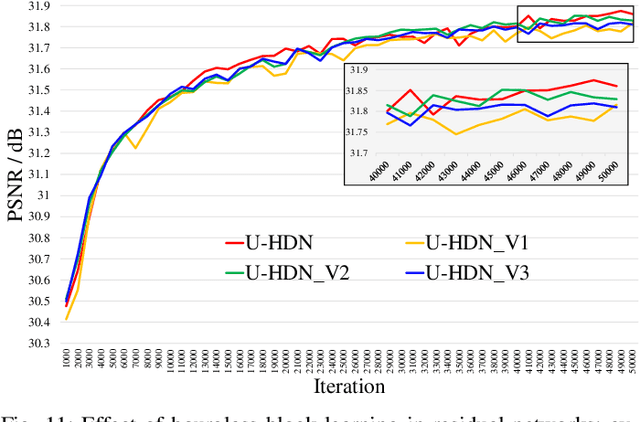
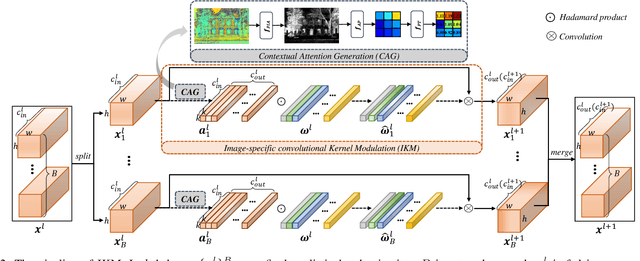
Recently, deep-learning-based super-resolution methods have achieved excellent performances, but mainly focus on training a single generalized deep network by feeding numerous samples. Yet intuitively, each image has its representation, and is expected to acquire an adaptive model. For this issue, we propose a novel image-specific convolutional kernel modulation (IKM) by exploiting the global contextual information of image or feature to generate an attention weight for adaptively modulating the convolutional kernels, which outperforms the vanilla convolution and several existing attention mechanisms while embedding into the state-of-the-art architectures without any additional parameters. Particularly, to optimize our IKM in mini-batch training, we introduce an image-specific optimization (IsO) algorithm, which is more effective than the conventional mini-batch SGD optimization. Furthermore, we investigate the effect of IKM on the state-of-the-art architectures and exploit a new backbone with U-style residual learning and hourglass dense block learning, terms U-Hourglass Dense Network (U-HDN), which is an appropriate architecture to utmost improve the effectiveness of IKM theoretically and experimentally. Extensive experiments on single image super-resolution show that the proposed methods achieve superior performances over state-of-the-art methods. Code is available at github.com/YuanfeiHuang/IKM.
An Improved Positioning Accuracy Method of a Robot Based on Particle Filter
Oct 27, 2021This paper aims to improve the performance and positioning accuracy of a robot by using the particle filter method. The laser range information is a wireless navigation system mainly used to measure, position, and control autonomous robots. Its localization is more flexible to control than wired guidance systems. However, the navigation through the laser range finder occurs with a large positioning error while it moves or turns fast. For solving this problem, the paper proposes a method to improve the positioning accuracy of a robot in an indoor environment by using a particle filter with robust characteristics in a nonlinear or non-Gaussian system. In this experiment, a robot is equipped with a laser range finder, two encoders, and a gyro for navigation to verify the positioning accuracy and performance. The positioning accuracy and performance could improve by approximately 85.5% in this proposed method.
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021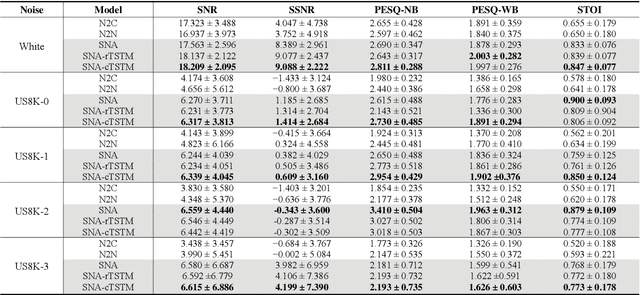
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
May 09, 2019
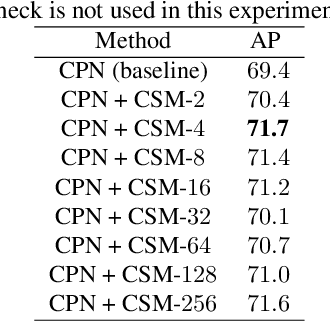
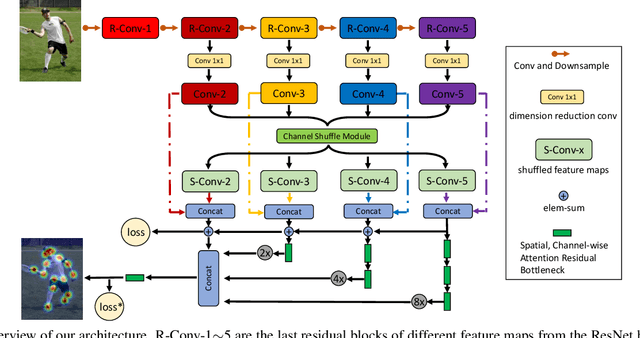
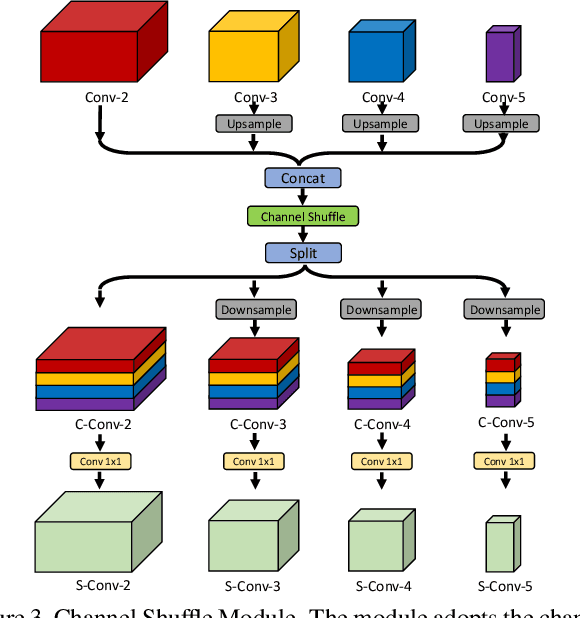
Multi-person pose estimation is an important but challenging problem in computer vision. Although current approaches have achieved significant progress by fusing the multi-scale feature maps, they pay little attention to enhancing the channel-wise and spatial information of the feature maps. In this paper, we propose two novel modules to perform the enhancement of the information for the multi-person pose estimation. First, a Channel Shuffle Module (CSM) is proposed to adopt the channel shuffle operation on the feature maps with different levels, promoting cross-channel information communication among the pyramid feature maps. Second, a Spatial, Channel-wise Attention Residual Bottleneck (SCARB) is designed to boost the original residual unit with attention mechanism, adaptively highlighting the information of the feature maps both in the spatial and channel-wise context. The effectiveness of our proposed modules is evaluated on the COCO keypoint benchmark, and experimental results show that our approach achieves the state-of-the-art results.
Autonomous Robot Navigation with Rich Information Mapping in Nuclear Storage Environments
Apr 11, 2019

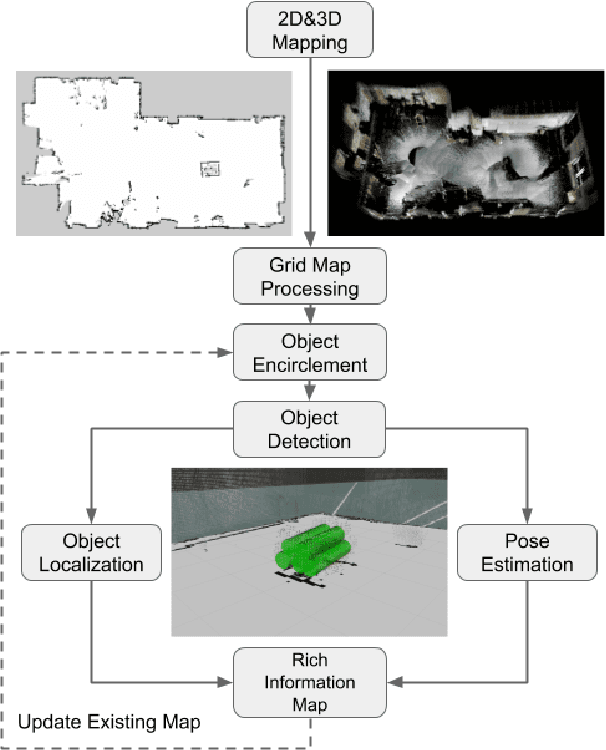
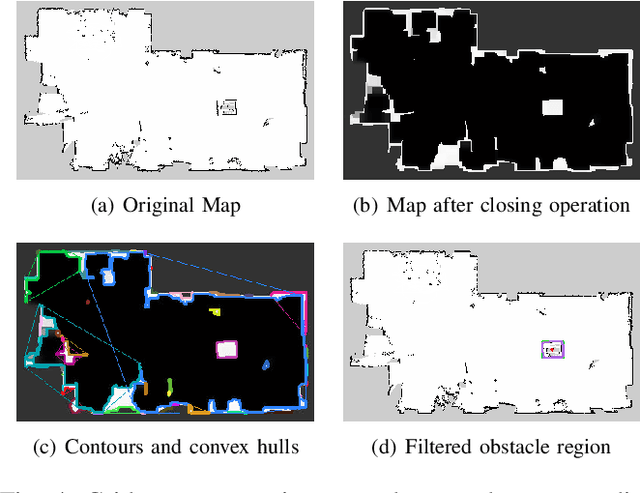
This paper presents our approach to develop a method for an unmanned ground vehicle (UGV) to perform inspection tasks in nuclear environments using rich information maps. To reduce inspectors' exposure to elevated radiation levels, an autonomous navigation framework for the UGV has been developed to perform routine inspections such as counting containers, recording their ID tags and performing gamma measurements on some of them. In order to achieve autonomy, a rich information map is generated which includes not only the 2D global cost map consisting of obstacle locations for path planning, but also the location and orientation information for the objects of interest from the inspector's perspective. The UGV's autonomy framework utilizes this information to prioritize locations to navigate to perform the inspections. In this paper, we present our method of generating this rich information map, originally developed to meet the requirements of the International Atomic Energy Agency (IAEA) Robotics Challenge. We demonstrate the performance of our method in a simulated testbed environment containing uranium hexafluoride (UF6) storage container mock ups.