 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic learning rate using Mutual Information
Jun 26, 2018
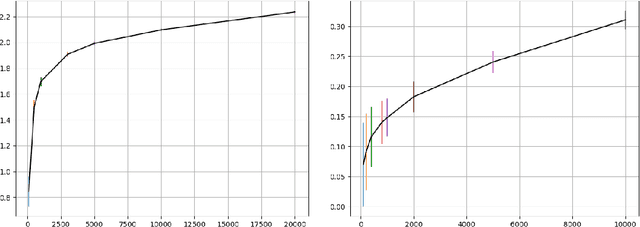

This paper demonstrates dynamic hyper-parameter setting, for deep neural network training, using Mutual Information (MI). The specific hyper-parameter studied in this paper is the learning rate. MI between the output layer and true outcomes is used to dynamically set the learning rate of the network through the training cycle; the idea is also extended to layer-wise setting of learning rate. Two approaches are demonstrated - tracking relative change in mutual information and, additionally tracking its value relative to a reference measure. The paper does not attempt to recommend a specific learning rate policy. Experiments demonstrate that mutual information may be effectively used to dynamically set learning rate and achieve competitive to better outcomes in competitive to better time.
Epidemic inference through generative neural networks
Nov 05, 2021
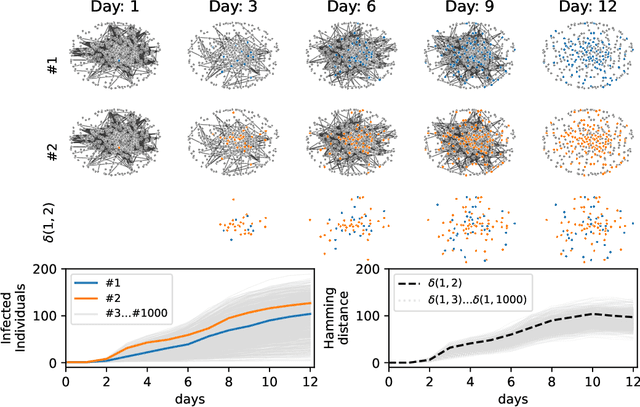
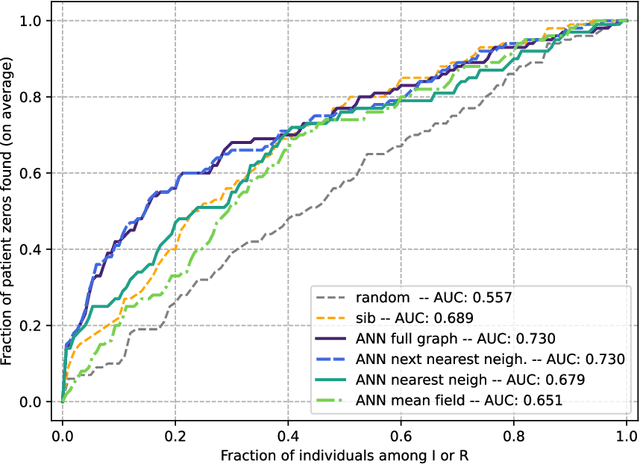
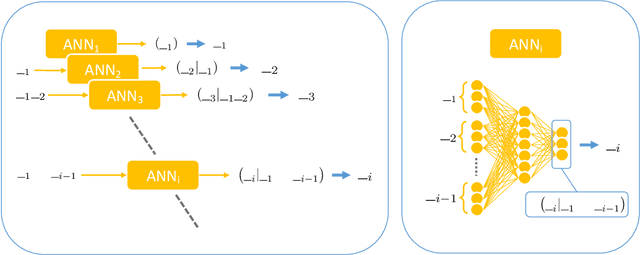
Reconstructing missing information in epidemic spreading on contact networks can be essential in prevention and containment strategies. For instance, identifying and warning infective but asymptomatic individuals (e.g., manual contact tracing) helped contain outbreaks in the COVID-19 pandemic. The number of possible epidemic cascades typically grows exponentially with the number of individuals involved. The challenge posed by inference problems in the epidemics processes originates from the difficulty of identifying the almost negligible subset of those compatible with the evidence (for instance, medical tests). Here we present a new generative neural networks framework that can sample the most probable infection cascades compatible with observations. Moreover, the framework can infer the parameters governing the spreading of infections. The proposed method obtains better or comparable results with existing methods on the patient zero problem, risk assessment, and inference of infectious parameters in synthetic and real case scenarios like spreading infections in workplaces and hospitals.
Feature Selective Likelihood Ratio Estimator for Low- and Zero-frequency N-grams
Nov 05, 2021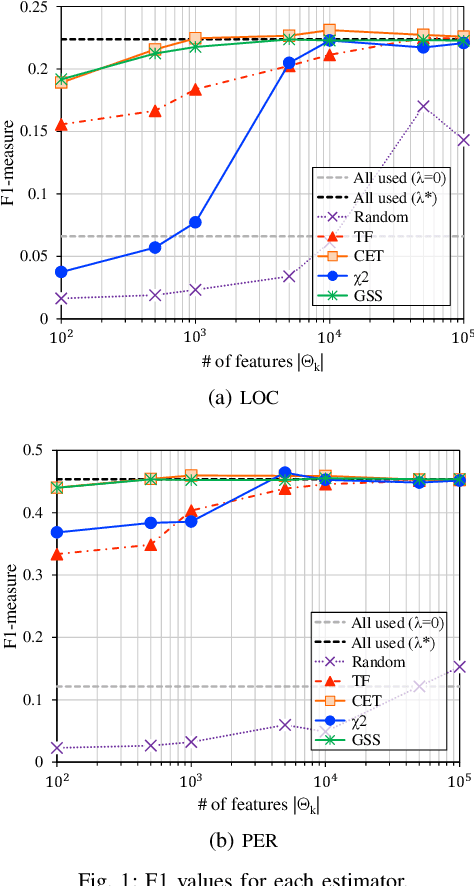
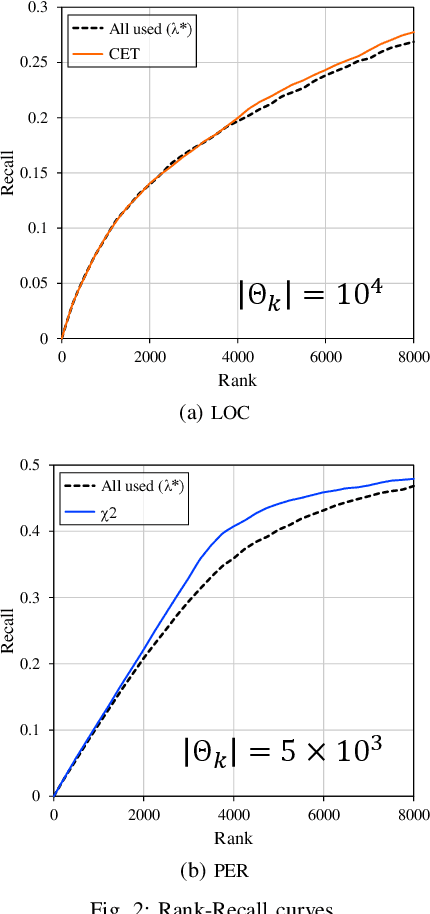
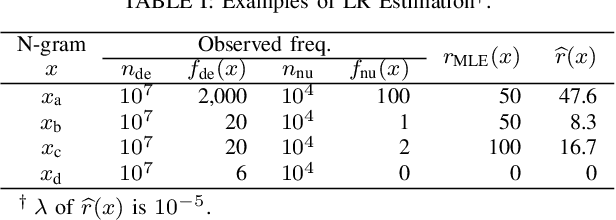
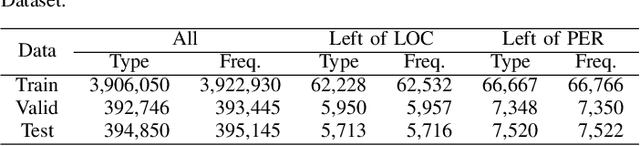
In natural language processing (NLP), the likelihood ratios (LRs) of N-grams are often estimated from the frequency information. However, a corpus contains only a fraction of the possible N-grams, and most of them occur infrequently. Hence, we desire an LR estimator for low- and zero-frequency N-grams. One way to achieve this is to decompose the N-grams into discrete values, such as letters and words, and take the product of the LRs for the values. However, because this method deals with a large number of discrete values, the running time and memory usage for estimation are problematic. Moreover, use of unnecessary discrete values causes deterioration of the estimation accuracy. Therefore, this paper proposes combining the aforementioned method with the feature selection method used in document classification, and shows that our estimator provides effective and efficient estimation results for low- and zero-frequency N-grams.
It's Easier to Translate out of English than into it: Measuring Neural Translation Difficulty by Cross-Mutual Information
May 05, 2020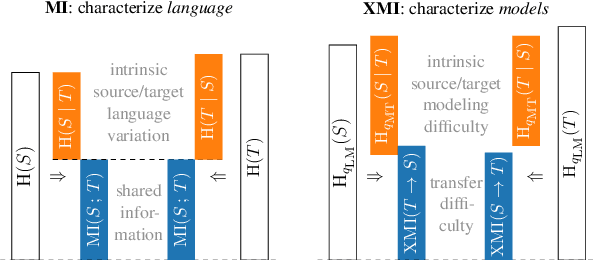
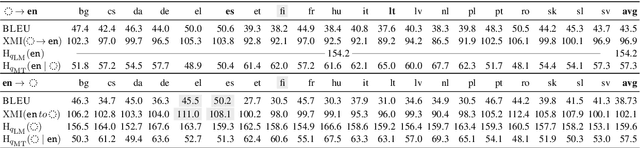
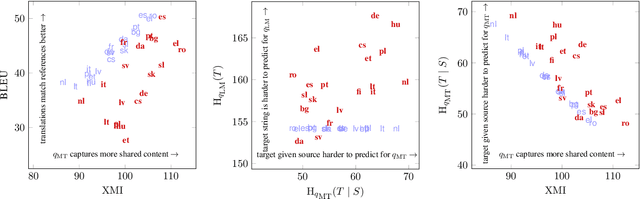
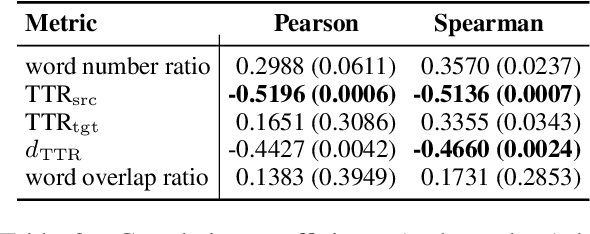
The performance of neural machine translation systems is commonly evaluated in terms of BLEU. However, due to its reliance on target language properties and generation, the BLEU metric does not allow an assessment of which translation directions are more difficult to model. In this paper, we propose cross-mutual information (XMI): an asymmetric information-theoretic metric of machine translation difficulty that exploits the probabilistic nature of most neural machine translation models. XMI allows us to better evaluate the difficulty of translating text into the target language while controlling for the difficulty of the target-side generation component independent of the translation task. We then present the first systematic and controlled study of cross-lingual translation difficulties using modern neural translation systems. Code for replicating our experiments is available online at https://github.com/e-bug/nmt-difficulty.
Graph-augmented Learning to Rank for Querying Large-scale Knowledge Graph
Nov 20, 2021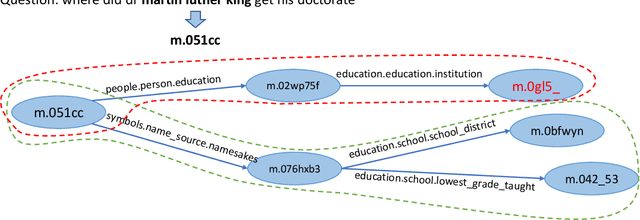

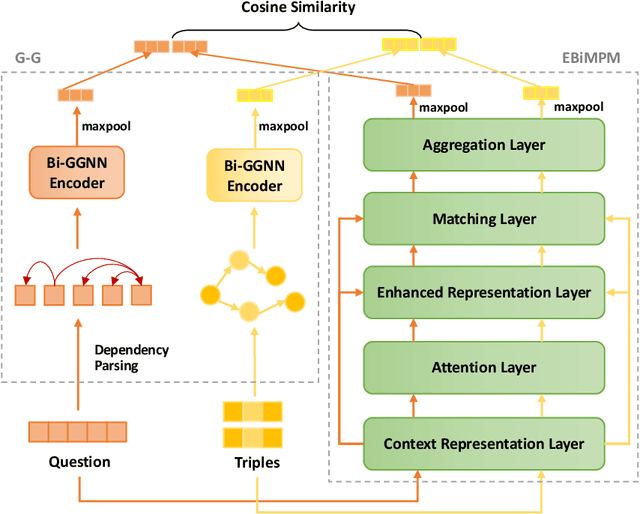
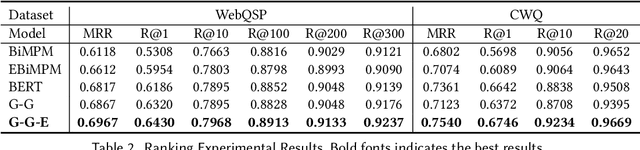
Knowledge graph question answering (i.e., KGQA) based on information retrieval aims to answer a question by retrieving answer from a large-scale knowledge graph. Most existing methods first roughly retrieve the knowledge subgraphs (KSG) that may contain candidate answer, and then search for the exact answer in the subgraph. However, the coarsely retrieved KSG may contain thousands of candidate nodes since the knowledge graph involved in querying is often of large scale. To tackle this problem, we first propose to partition the retrieved KSG to several smaller sub-KSGs via a new subgraph partition algorithm and then present a graph-augmented learning to rank model to select the top-ranked sub-KSGs from them. Our proposed model combines a novel subgraph matching networks to capture global interactions in both question and subgraphs and an Enhanced Bilateral Multi-Perspective Matching model to capture local interactions. Finally, we apply an answer selection model on the full KSG and the top-ranked sub-KSGs respectively to validate the effectiveness of our proposed graph-augmented learning to rank method. The experimental results on multiple benchmark datasets have demonstrated the effectiveness of our approach.
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning
Nov 20, 2021
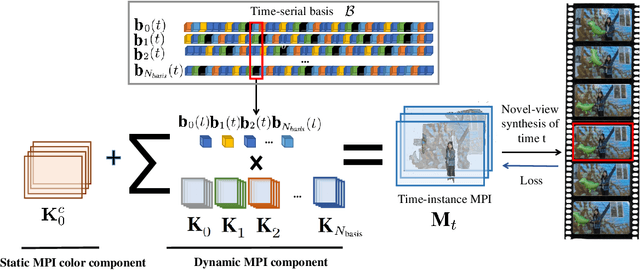

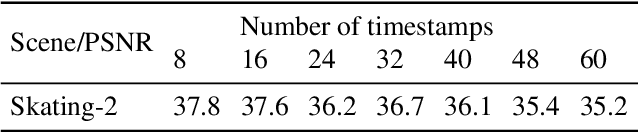
Novel view synthesis of static scenes has achieved remarkable advancements in producing photo-realistic results. However, key challenges remain for immersive rendering for dynamic contents. For example, one of the seminal image-based rendering frameworks, the multi-plane image (MPI) produces high novel-view synthesis quality for static scenes but faces difficulty in modeling dynamic parts. In addition, modeling dynamic variations through MPI may require huge storage space and long inference time, which hinders its application in real-time scenarios. In this paper, we propose a novel Temporal-MPI representation which is able to encode the rich 3D and dynamic variation information throughout the entire video as compact temporal basis. Novel-views at arbitrary time-instance will be able to be rendered real-time with high visual quality due to the highly compact and expressive latent basis and the coefficients jointly learned. We show that given comparable memory consumption, our proposed Temporal-MPI framework is able to generate a time-instance MPI with only 0.002 seconds, which is up to 3000 times faster, with 3dB higher average view-synthesis PSNR as compared with other state-of-the-art dynamic scene modelling frameworks.
Intelligence, physics and information -- the tradeoff between accuracy and simplicity in machine learning
Jan 20, 2020How can we enable machines to make sense of the world, and become better at learning? To approach this goal, I believe viewing intelligence in terms of many integral aspects, and also a universal two-term tradeoff between task performance and complexity, provides two feasible perspectives. In this thesis, I address several key questions in some aspects of intelligence, and study the phase transitions in the two-term tradeoff, using strategies and tools from physics and information. Firstly, how can we make the learning models more flexible and efficient, so that agents can learn quickly with fewer examples? Inspired by how physicists model the world, we introduce a paradigm and an AI Physicist agent for simultaneously learning many small specialized models (theories) and the domain they are accurate, which can then be simplified, unified and stored, facilitating few-shot learning in a continual way. Secondly, for representation learning, when can we learn a good representation, and how does learning depend on the structure of the dataset? We approach this question by studying phase transitions when tuning the tradeoff hyperparameter. In the information bottleneck, we theoretically show that these phase transitions are predictable and reveal structure in the relationships between the data, the model, the learned representation and the loss landscape. Thirdly, how can agents discover causality from observations? We address part of this question by introducing an algorithm that combines prediction and minimizing information from the input, for exploratory causal discovery from observational time series. Fourthly, to make models more robust to label noise, we introduce Rank Pruning, a robust algorithm for classification with noisy labels. I believe that building on the work of my thesis we will be one step closer to enable more intelligent machines that can make sense of the world.
Robust Edge-Direct Visual Odometry based on CNN edge detection and Shi-Tomasi corner optimization
Oct 21, 2021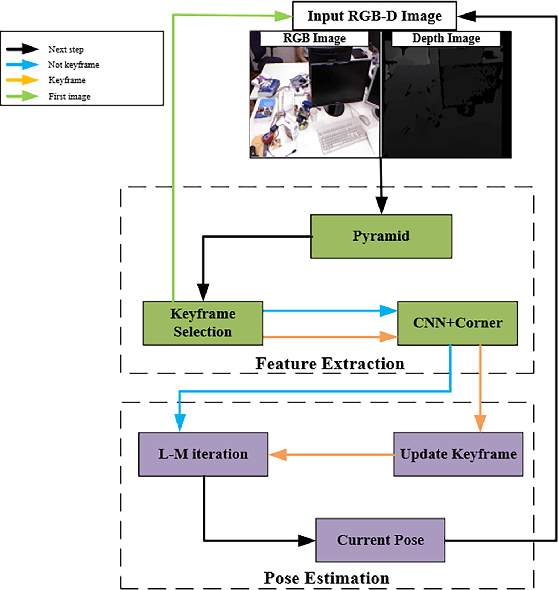
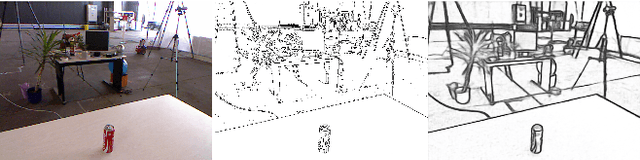
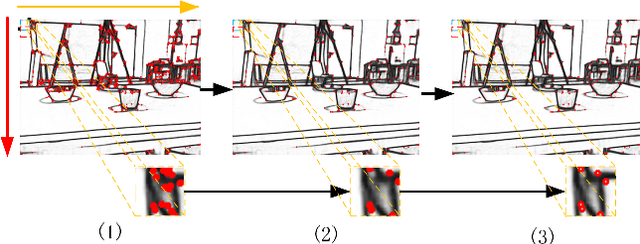
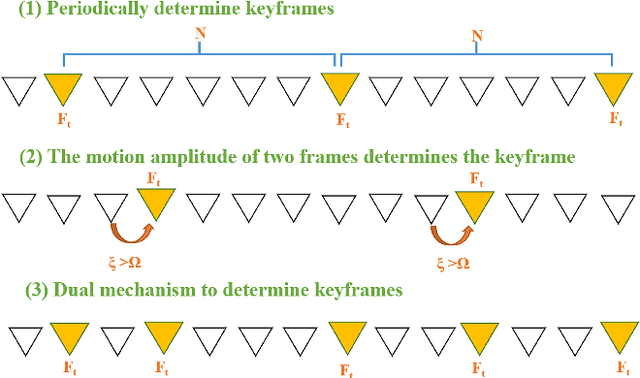
In this paper, we propose a robust edge-direct visual odometry (VO) based on CNN edge detection and Shi-Tomasi corner optimization. Four layers of pyramids were extracted from the image in the proposed method to reduce the motion error between frames. This solution used CNN edge detection and Shi-Tomasi corner optimization to extract information from the image. Then, the pose estimation is performed using the Levenberg-Marquardt (LM) algorithm and updating the keyframes. Our method was compared with the dense direct method, the improved direct method of Canny edge detection, and ORB-SLAM2 system on the RGB-D TUM benchmark. The experimental results indicate that our method achieves better robustness and accuracy.
Efficient Coding Approach Towards Non-Linear Spectro-Temporal Receptive Fields
Oct 21, 2021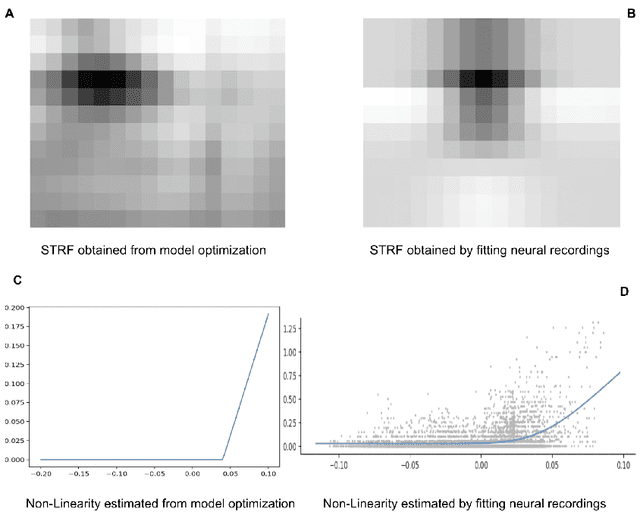
Linear Non-Linear(LN) models are widely used to characterize the receptive fields of early-stage auditory processing. We apply the principle of efficient coding to the LN model of Spectro-Temporal Receptive Fields(STRFs) of the neurons in primary auditory cortex. The Efficient Coding Principle has been previously used to understand early visual receptive fields and linear STRFs in auditory processing. Efficient coding is realized by jointly optimizing the mutual information between stimuli and neural responses subjected to the metabolic cost of firing spikes. We compare the predictions of the efficient coding principle with the physiological observations, which match qualitatively under realistic conditions of noise in stimuli and the spike generation process.
Deep Structured Instance Graph for Distilling Object Detectors
Sep 27, 2021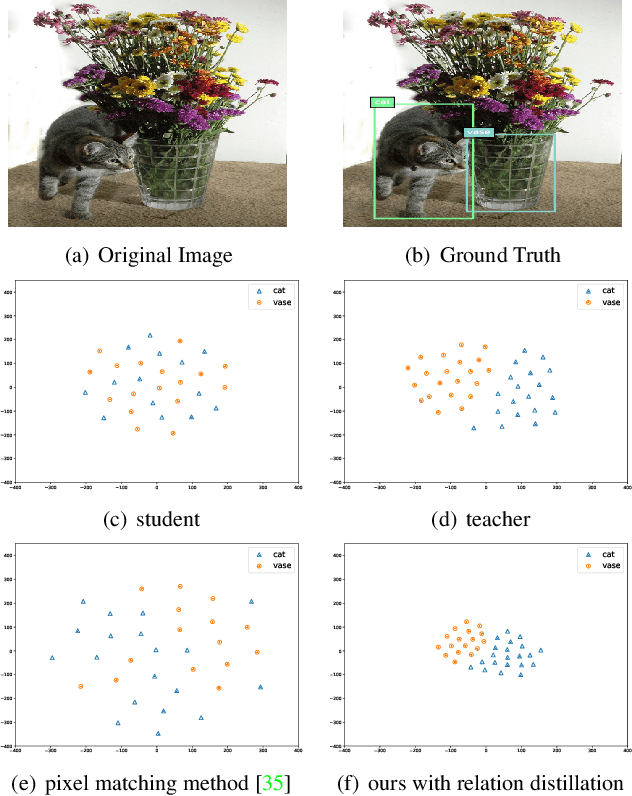
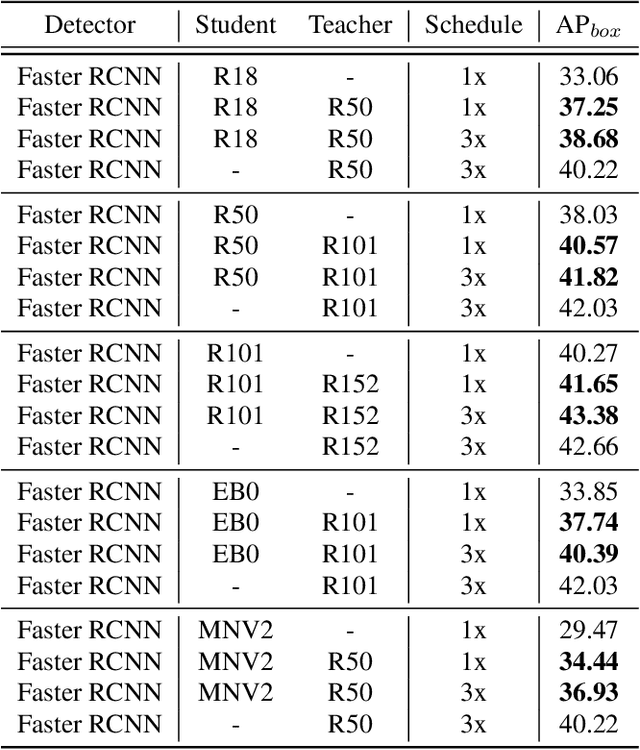

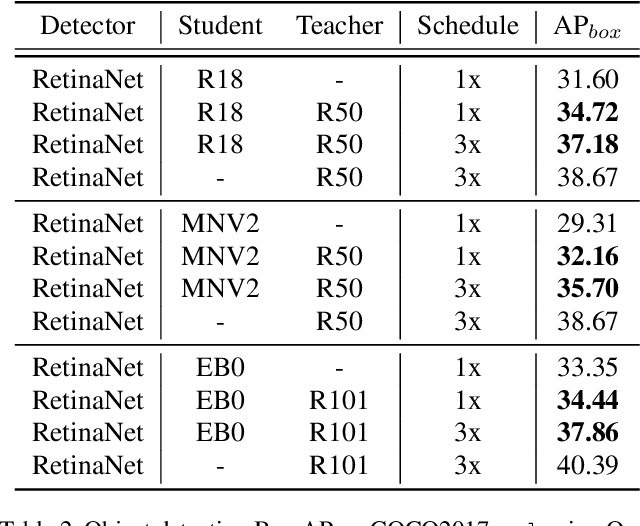
Effectively structuring deep knowledge plays a pivotal role in transfer from teacher to student, especially in semantic vision tasks. In this paper, we present a simple knowledge structure to exploit and encode information inside the detection system to facilitate detector knowledge distillation. Specifically, aiming at solving the feature imbalance problem while further excavating the missing relation inside semantic instances, we design a graph whose nodes correspond to instance proposal-level features and edges represent the relation between nodes. To further refine this graph, we design an adaptive background loss weight to reduce node noise and background samples mining to prune trivial edges. We transfer the entire graph as encoded knowledge representation from teacher to student, capturing local and global information simultaneously. We achieve new state-of-the-art results on the challenging COCO object detection task with diverse student-teacher pairs on both one- and two-stage detectors. We also experiment with instance segmentation to demonstrate robustness of our method. It is notable that distilled Faster R-CNN with ResNet18-FPN and ResNet50-FPN yields 38.68 and 41.82 Box AP respectively on the COCO benchmark, Faster R-CNN with ResNet101-FPN significantly achieves 43.38 AP, which outperforms ResNet152-FPN teacher about 0.7 AP. Code: https://github.com/dvlab-research/Dsig.