 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hand Image Understanding via Deep Multi-Task Learning
Jul 28, 2021
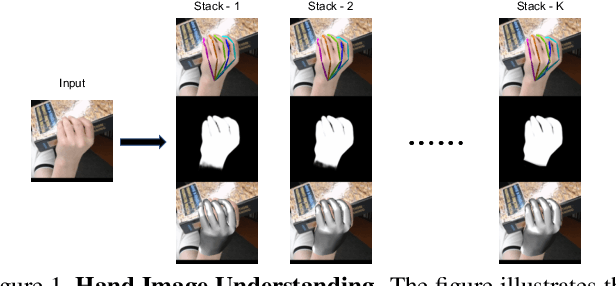

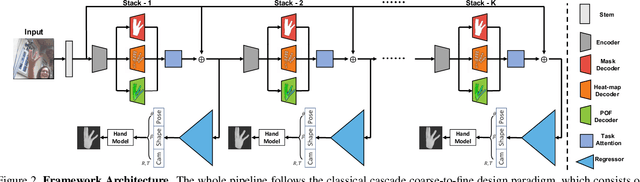
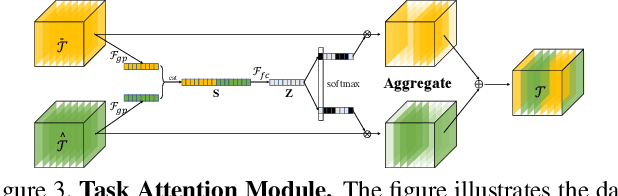
Analyzing and understanding hand information from multimedia materials like images or videos is important for many real world applications and remains active in research community. There are various works focusing on recovering hand information from single image, however, they usually solve a single task, for example, hand mask segmentation, 2D/3D hand pose estimation, or hand mesh reconstruction and perform not well in challenging scenarios. To further improve the performance of these tasks, we propose a novel Hand Image Understanding (HIU) framework to extract comprehensive information of the hand object from a single RGB image, by jointly considering the relationships between these tasks. To achieve this goal, a cascaded multi-task learning (MTL) backbone is designed to estimate the 2D heat maps, to learn the segmentation mask, and to generate the intermediate 3D information encoding, followed by a coarse-to-fine learning paradigm and a self-supervised learning strategy. Qualitative experiments demonstrate that our approach is capable of recovering reasonable mesh representations even in challenging situations. Quantitatively, our method significantly outperforms the state-of-the-art approaches on various widely-used datasets, in terms of diverse evaluation metrics.
A Probit Tensor Factorization Model For Relational Learning
Nov 09, 2021
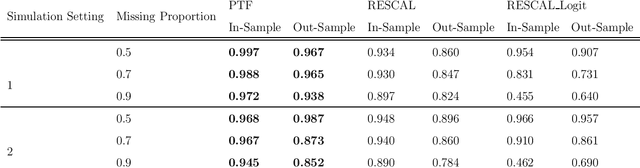
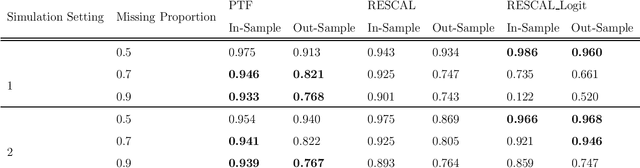

With the proliferation of knowledge graphs, modeling data with complex multirelational structure has gained increasing attention in the area of statistical relational learning. One of the most important goals of statistical relational learning is link prediction, i.e., predicting whether certain relations exist in the knowledge graph. A large number of models and algorithms have been proposed to perform link prediction, among which tensor factorization method has proven to achieve state-of-the-art performance in terms of computation efficiency and prediction accuracy. However, a common drawback of the existing tensor factorization models is that the missing relations and non-existing relations are treated in the same way, which results in a loss of information. To address this issue, we propose a binary tensor factorization model with probit link, which not only inherits the computation efficiency from the classic tensor factorization model but also accounts for the binary nature of relational data. Our proposed probit tensor factorization (PTF) model shows advantages in both the prediction accuracy and interpretability
Simple End-to-end Deep Learning Model for CDR-H3 Loop Structure Prediction
Nov 20, 2021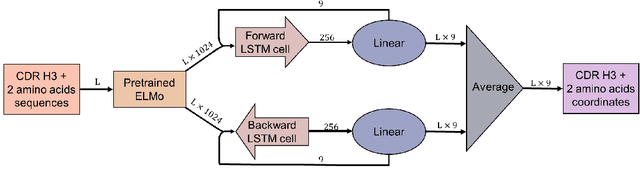
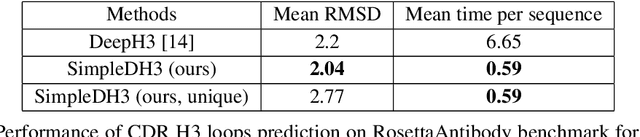
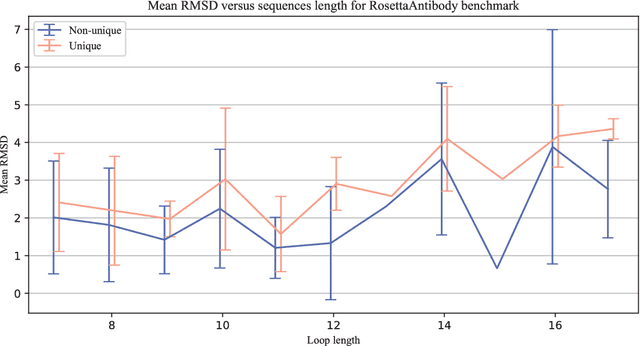
Predicting a structure of an antibody from its sequence is important since it allows for a better design process of synthetic antibodies that play a vital role in the health industry. Most of the structure of an antibody is conservative. The most variable and hard-to-predict part is the {\it third complementarity-determining region of the antibody heavy chain} (CDR H3). Lately, deep learning has been employed to solve the task of CDR H3 prediction. However, current state-of-the-art methods are not end-to-end, but rather they output inter-residue distances and orientations to the RosettaAntibody package that uses this additional information alongside statistical and physics-based methods to predict the 3D structure. This does not allow a fast screening process and, therefore, inhibits the development of targeted synthetic antibodies. In this work, we present an end-to-end model to predict CDR H3 loop structure, that performs on par with state-of-the-art methods in terms of accuracy but an order of magnitude faster. We also raise an issue with a commonly used RosettaAntibody benchmark that leads to data leaks, i.e., the presence of identical sequences in the train and test datasets.
Genre as Weak Supervision for Cross-lingual Dependency Parsing
Sep 10, 2021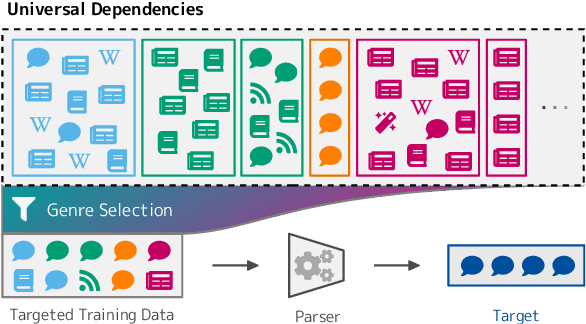
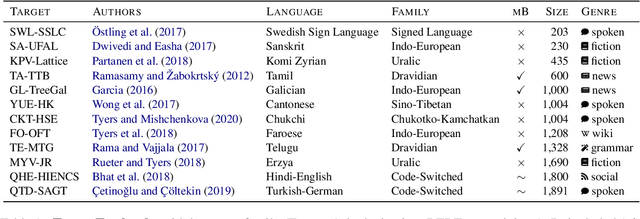
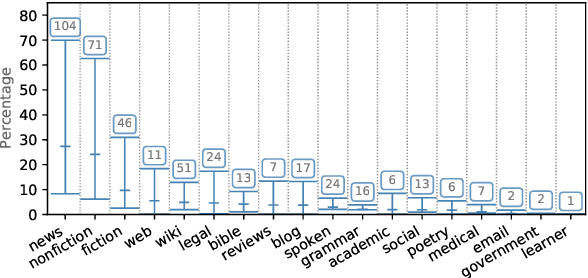
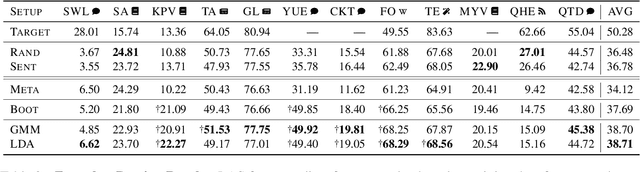
Recent work has shown that monolingual masked language models learn to represent data-driven notions of language variation which can be used for domain-targeted training data selection. Dataset genre labels are already frequently available, yet remain largely unexplored in cross-lingual setups. We harness this genre metadata as a weak supervision signal for targeted data selection in zero-shot dependency parsing. Specifically, we project treebank-level genre information to the finer-grained sentence level, with the goal to amplify information implicitly stored in unsupervised contextualized representations. We demonstrate that genre is recoverable from multilingual contextual embeddings and that it provides an effective signal for training data selection in cross-lingual, zero-shot scenarios. For 12 low-resource language treebanks, six of which are test-only, our genre-specific methods significantly outperform competitive baselines as well as recent embedding-based methods for data selection. Moreover, genre-based data selection provides new state-of-the-art results for three of these target languages.
AutoTriggER: Named Entity Recognition with Auxiliary Trigger Extraction
Sep 10, 2021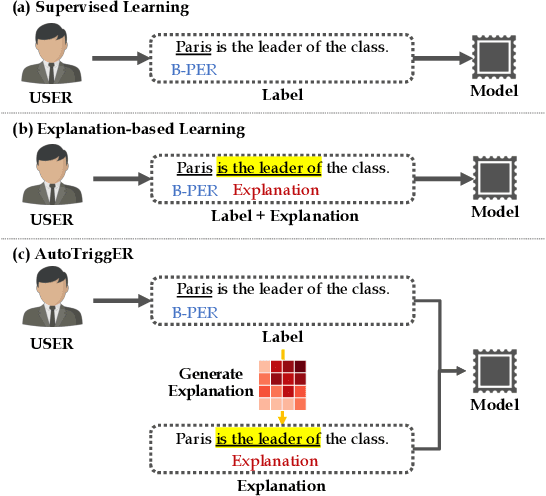
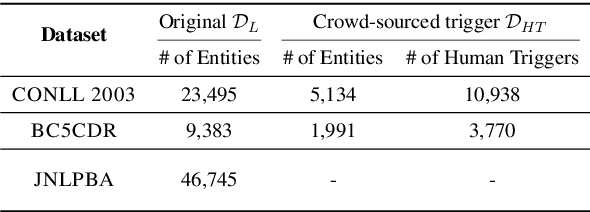

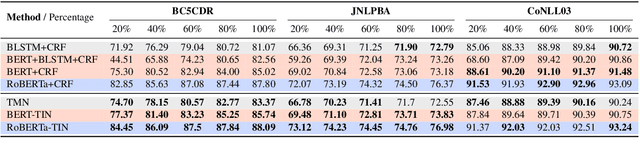
Deep neural models for low-resource named entity recognition (NER) have shown impressive results by leveraging distant super-vision or other meta-level information (e.g. explanation). However, the costs of acquiring such additional information are generally prohibitive, especially in domains where existing resources (e.g. databases to be used for distant supervision) may not exist. In this paper, we present a novel two-stage framework (AutoTriggER) to improve NER performance by automatically generating and leveraging "entity triggers" which are essentially human-readable clues in the text that can help guide the model to make better decisions. Thus, the framework is able to both create and leverage auxiliary supervision by itself. Through experiments on three well-studied NER datasets, we show that our automatically extracted triggers are well-matched to human triggers, and AutoTriggER improves performance over a RoBERTa-CRFarchitecture by nearly 0.5 F1 points on average and much more in a low resource setting.
Multi-Branch Deep Radial Basis Function Networks for Facial Emotion Recognition
Sep 07, 2021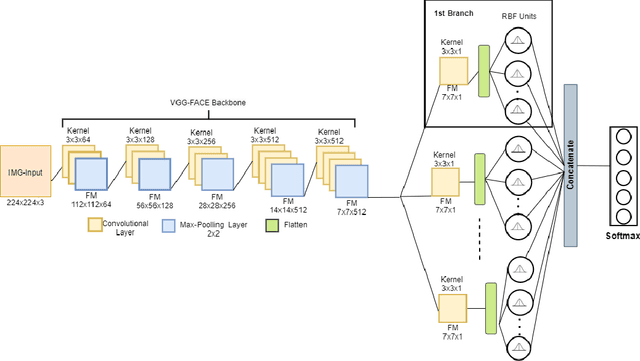
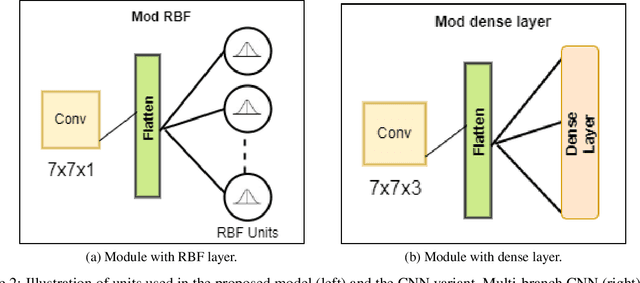
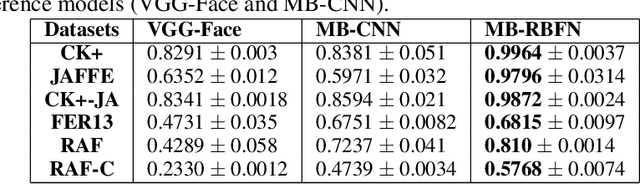
Emotion recognition (ER) from facial images is one of the landmark tasks in affective computing with major developments in the last decade. Initial efforts on ER relied on handcrafted features that were used to characterize facial images and then feed to standard predictive models. Recent methodologies comprise end-to-end trainable deep learning methods that simultaneously learn both, features and predictive model. Perhaps the most successful models are based on convolutional neural networks (CNNs). While these models have excelled at this task, they still fail at capturing local patterns that could emerge in the learning process. We hypothesize these patterns could be captured by variants based on locally weighted learning. Specifically, in this paper we propose a CNN based architecture enhanced with multiple branches formed by radial basis function (RBF) units that aims at exploiting local information at the final stage of the learning process. Intuitively, these RBF units capture local patterns shared by similar instances using an intermediate representation, then the outputs of the RBFs are feed to a softmax layer that exploits this information to improve the predictive performance of the model. This feature could be particularly advantageous in ER as cultural / ethnicity differences may be identified by the local units. We evaluate the proposed method in several ER datasets and show the proposed methodology achieves state-of-the-art in some of them, even when we adopt a pre-trained VGG-Face model as backbone. We show it is the incorporation of local information what makes the proposed model competitive.
Feature-Level Fusion of Super-App and Telecommunication Alternative Data Sources for Credit Card Fraud Detection
Nov 05, 2021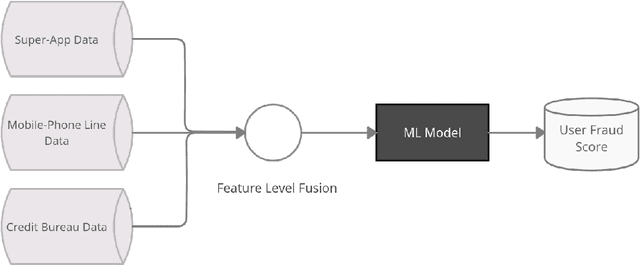
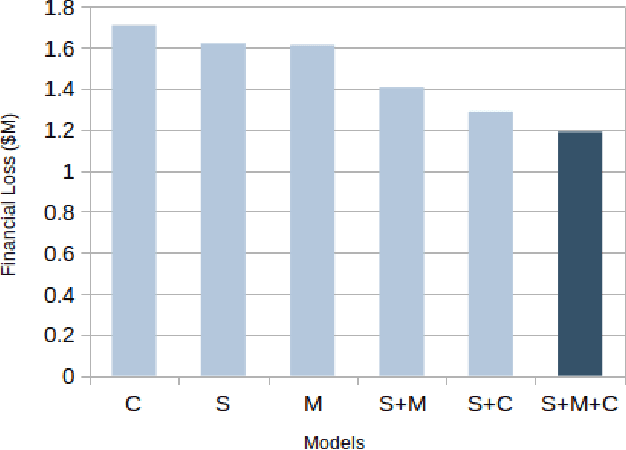
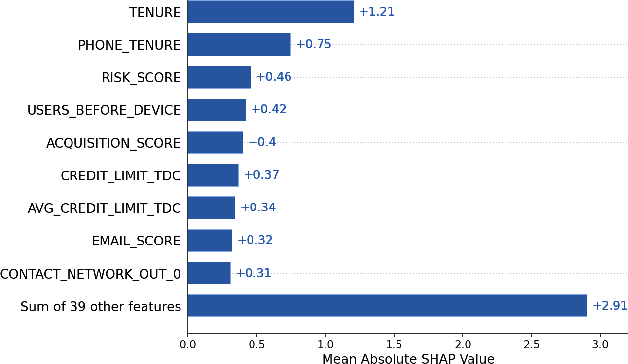

Identity theft is a major problem for credit lenders when there's not enough data to corroborate a customer's identity. Among super-apps large digital platforms that encompass many different services this problem is even more relevant; losing a client in one branch can often mean losing them in other services. In this paper, we review the effectiveness of a feature-level fusion of super-app customer information, mobile phone line data, and traditional credit risk variables for the early detection of identity theft credit card fraud. Through the proposed framework, we achieved better performance when using a model whose input is a fusion of alternative data and traditional credit bureau data, achieving a ROC AUC score of 0.81. We evaluate our approach over approximately 90,000 users from a credit lender's digital platform database. The evaluation was performed using not only traditional ML metrics but the financial costs as well.
MHFC: Multi-Head Feature Collaboration for Few-Shot Learning
Sep 16, 2021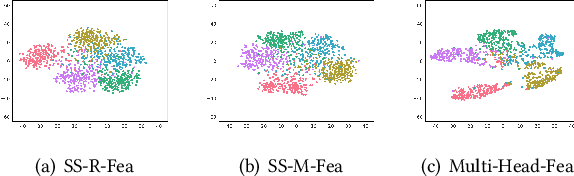
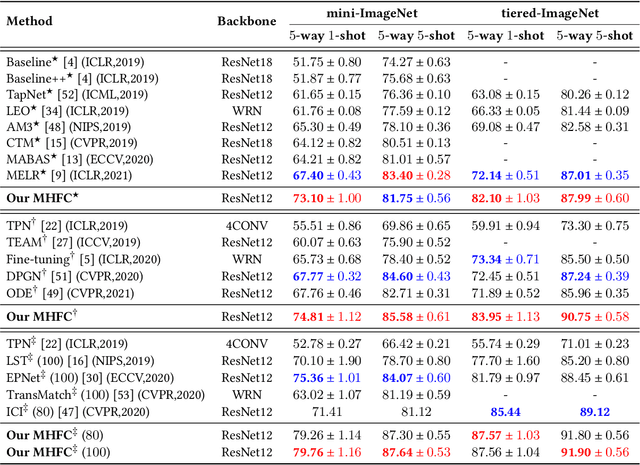
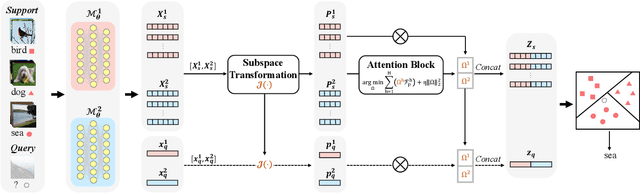
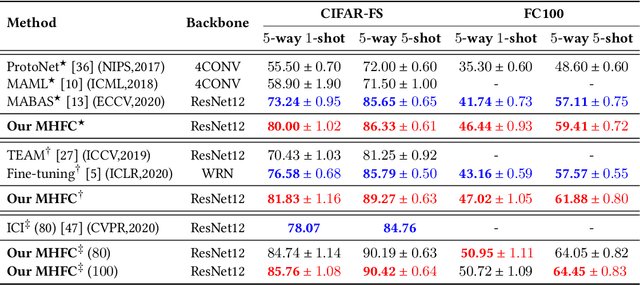
Few-shot learning (FSL) aims to address the data-scarce problem. A standard FSL framework is composed of two components: (1) Pre-train. Employ the base data to generate a CNN-based feature extraction model (FEM). (2) Meta-test. Apply the trained FEM to acquire the novel data's features and recognize them. FSL relies heavily on the design of the FEM. However, various FEMs have distinct emphases. For example, several may focus more attention on the contour information, whereas others may lay particular emphasis on the texture information. The single-head feature is only a one-sided representation of the sample. Besides the negative influence of cross-domain (e.g., the trained FEM can not adapt to the novel class flawlessly), the distribution of novel data may have a certain degree of deviation compared with the ground truth distribution, which is dubbed as distribution-shift-problem (DSP). To address the DSP, we propose Multi-Head Feature Collaboration (MHFC) algorithm, which attempts to project the multi-head features (e.g., multiple features extracted from a variety of FEMs) to a unified space and fuse them to capture more discriminative information. Typically, first, we introduce a subspace learning method to transform the multi-head features to aligned low-dimensional representations. It corrects the DSP via learning the feature with more powerful discrimination and overcomes the problem of inconsistent measurement scales from different head features. Then, we design an attention block to update combination weights for each head feature automatically. It comprehensively considers the contribution of various perspectives and further improves the discrimination of features. We evaluate the proposed method on five benchmark datasets (including cross-domain experiments) and achieve significant improvements of 2.1%-7.8% compared with state-of-the-arts.
Combining Machine Learning with Physics: A Framework for Tracking and Sorting Multiple Dark Solitons
Nov 08, 2021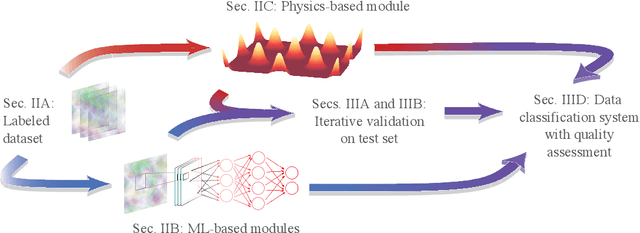
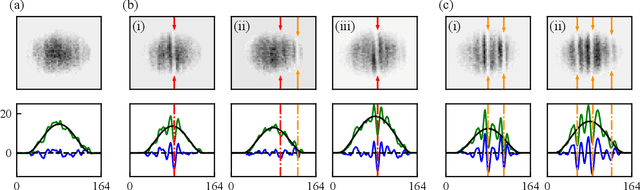
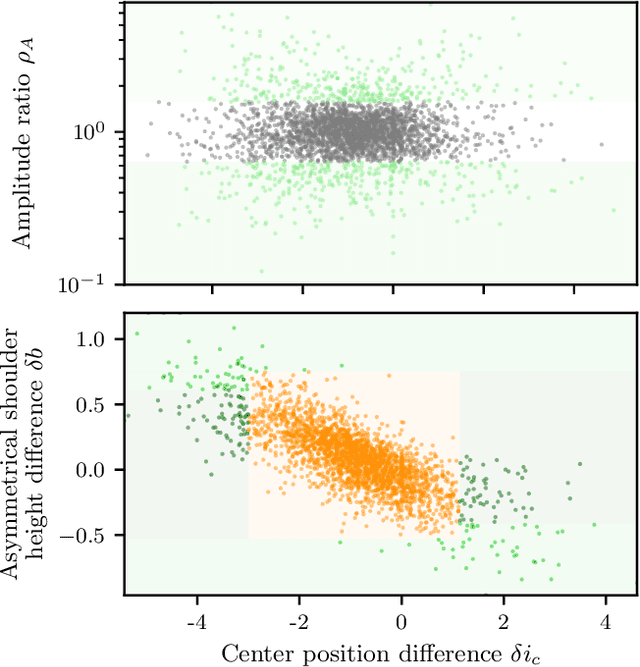
In ultracold atom experiments, data often comes in the form of images which suffer information loss inherent in the techniques used to prepare and measure the system. This is particularly problematic when the processes of interest are complicated, such as interactions among excitations in Bose-Einstein condensates (BECs). In this paper, we describe a framework combining machine learning (ML) models with physics-based traditional analyses to identify and track multiple solitonic excitations in images of BECs. We use an ML-based object detector to locate the solitonic excitations and develop a physics-informed classifier to sort solitonic excitations into physically motivated sub-categories. Lastly, we introduce a quality metric quantifying the likelihood that a specific feature is a kink soliton. Our trained implementation of this framework -- SolDet -- is publicly available as an open-source python package. SolDet is broadly applicable to feature identification in cold atom images when trained on a suitable user-provided dataset.
Forecasting sales with Bayesian networks: a case study of a supermarket product in the presence of promotions
Dec 16, 2021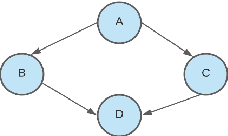

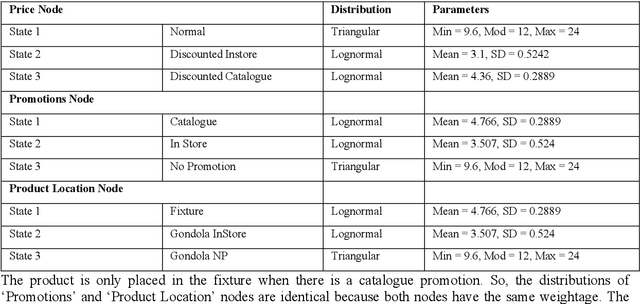
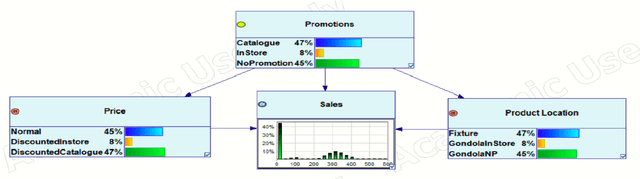
Sales forecasting is the prerequisite for a lot of managerial decisions such as production planning, material resource planning and budgeting in the supply chain. Promotions are one of the most important business strategies that are often used to boost sales. While promotions are attractive for generating demand, it is often difficult to forecast demand in their presence. In the past few decades, several quantitative models have been developed to forecast sales including statistical and machine learning models. However, these methods may not be adequate to account for all the internal and external factors that may impact sales. As a result, qualitative models have been adopted along with quantitative methods as consulting experts has been proven to improve forecast accuracy by providing contextual information. Such models are being used extensively to account for factors that can lead to a rapid change in sales, such as during promotions. In this paper, we aim to use Bayesian Networks to forecast promotional sales where a combination of factors such as price, type of promotions, and product location impacts sales. We choose to develop a BN model because BN models essentially have the capability to combine various qualitative and quantitative factors with causal forms, making it an attractive tool for sales forecasting during promotions. This can be used to adjust a company's promotional strategy in the context of this case study. We gather sales data for a particular product from a retailer that sells products in Australia. We develop a Bayesian Network for this product and validate our results by empirical analysis. This paper confirms that BNs can be effectively used to forecast sales, especially during promotions. In the end, we provide some research avenues for using BNs in forecasting sales.