 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MassFormer: Tandem Mass Spectrum Prediction with Graph Transformers
Nov 15, 2021
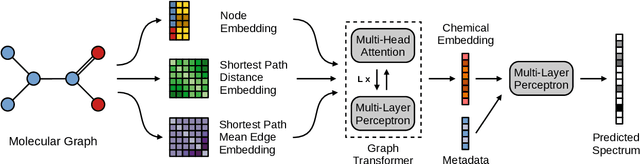
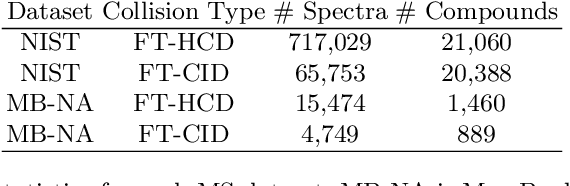
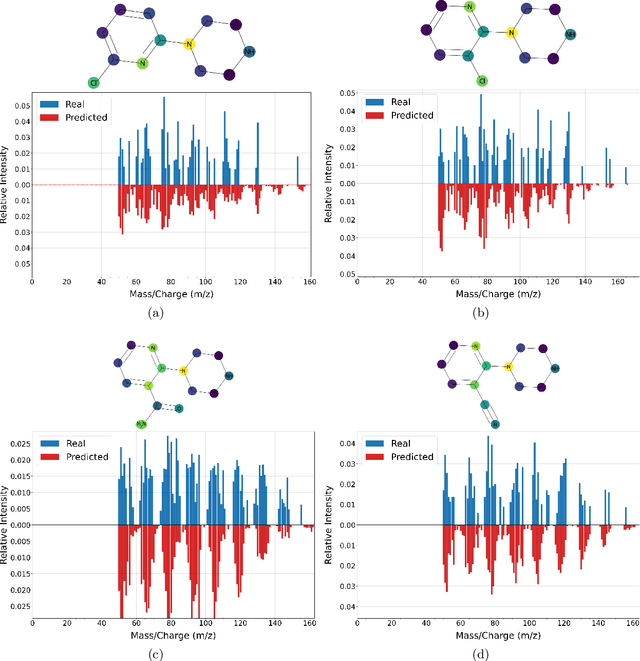
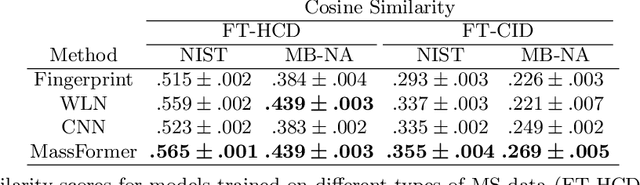
Mass spectrometry is a key tool in the study of small molecules, playing an important role in metabolomics, drug discovery, and environmental chemistry. Tandem mass spectra capture fragmentation patterns that provide key structural information about a molecule and help with its identification. Practitioners often rely on spectral library searches to match unknown spectra with known compounds. However, such search-based methods are limited by availability of reference experimental data. In this work we show that graph transformers can be used to accurately predict tandem mass spectra. Our model, MassFormer, outperforms competing deep learning approaches for spectrum prediction, and includes an interpretable attention mechanism to help explain predictions. We demonstrate that our model can be used to improve reference library coverage on a synthetic molecule identification task. Through quantitative analysis and visual inspection, we verify that our model recovers prior knowledge about the effect of collision energy on the generated spectrum. We evaluate our model on different types of mass spectra from two independent MS datasets and show that its performance generalizes. Code available at github.com/Roestlab/massformer.
NIF: A Framework for Quantifying Neural Information Flow in Deep Networks
Jan 20, 2019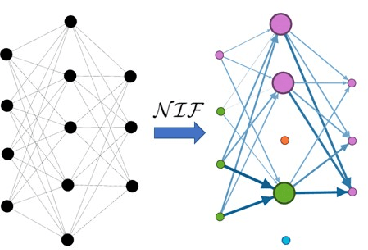

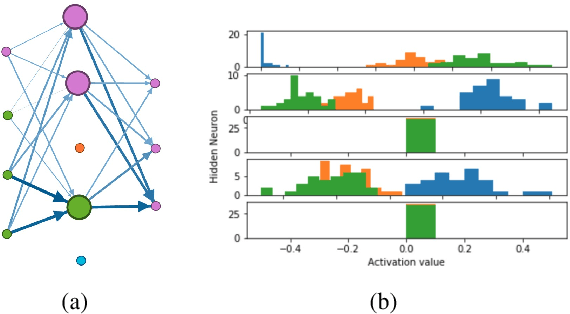
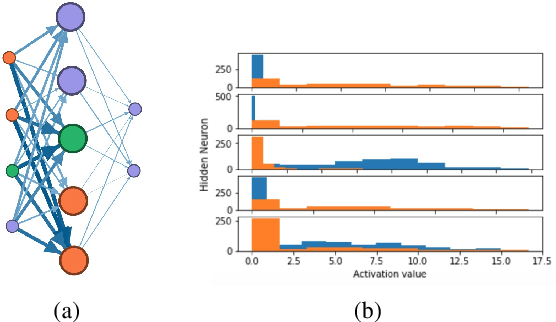
In this paper, we present a new approach to interpreting deep learning models. More precisely, by coupling mutual information with network science, we explore how information flows through feed forward networks. We show that efficiently approximating mutual information via the dual representation of Kullback-Leibler divergence allows us to create an information measure that quantifies how much information flows between any two neurons of a deep learning model. To that end, we propose NIF, Neural Information Flow, a new metric for codifying information flow which exposes the internals of a deep learning model while providing feature attributions.
Uncertainty-Aware Multiple Instance Learning from Large-Scale Long Time Series Data
Nov 21, 2021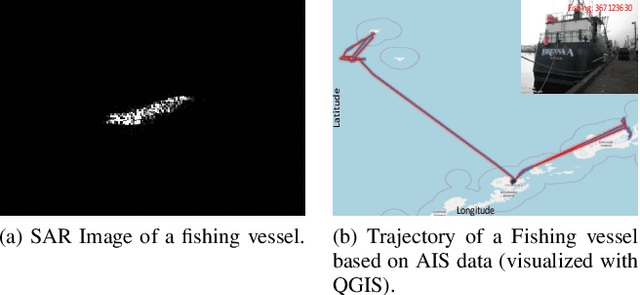
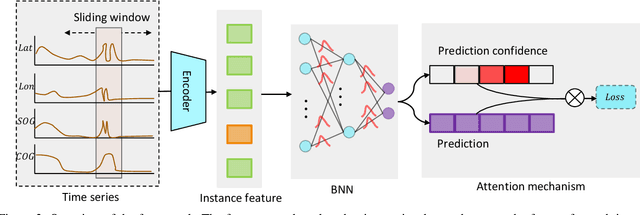
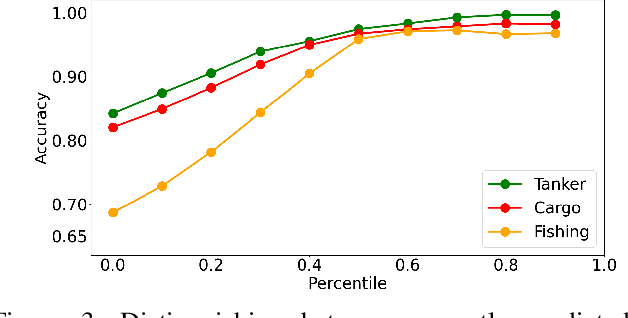
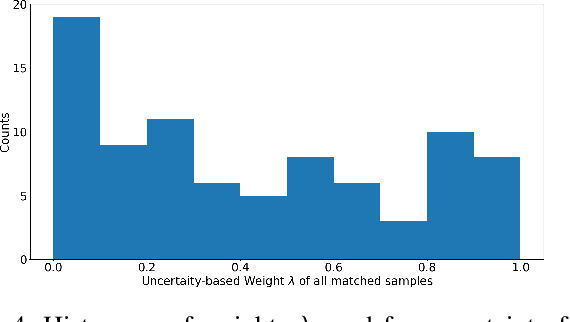
We propose a novel framework to classify large-scale time series data with long duration. Long time seriesclassification (L-TSC) is a challenging problem because the dataoften contains a large amount of irrelevant information to theclassification target. The irrelevant period degrades the classifica-tion performance while the relevance is unknown to the system.This paper proposes an uncertainty-aware multiple instancelearning (MIL) framework to identify the most relevant periodautomatically. The predictive uncertainty enables designing anattention mechanism that forces the MIL model to learn from thepossibly discriminant period. Moreover, the predicted uncertaintyyields a principled estimator to identify whether a prediction istrustworthy or not. We further incorporate another modality toaccommodate unreliable predictions by training a separate modelbased on its availability and conduct uncertainty aware fusion toproduce the final prediction. Systematic evaluation is conductedon the Automatic Identification System (AIS) data, which is col-lected to identify and track real-world vessels. Empirical resultsdemonstrate that the proposed method can effectively detect thetypes of vessels based on the trajectory and the uncertainty-awarefusion with other available data modality (Synthetic-ApertureRadar or SAR imagery is used in our experiments) can furtherimprove the detection accuracy.
Examining Cross-lingual Contextual Embeddings with Orthogonal Structural Probes
Sep 10, 2021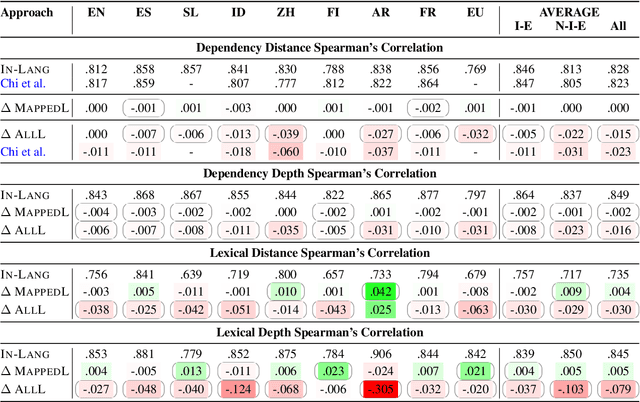
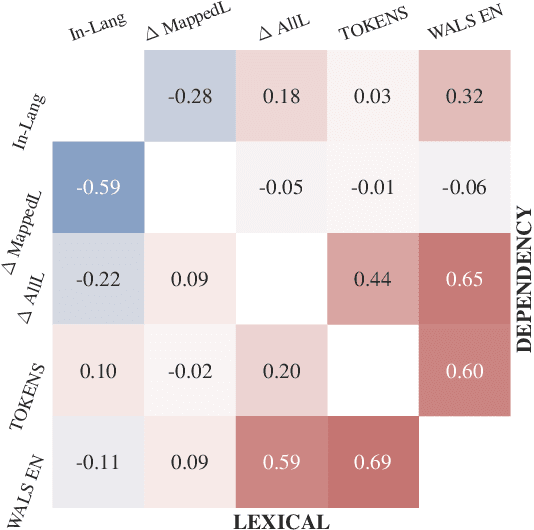
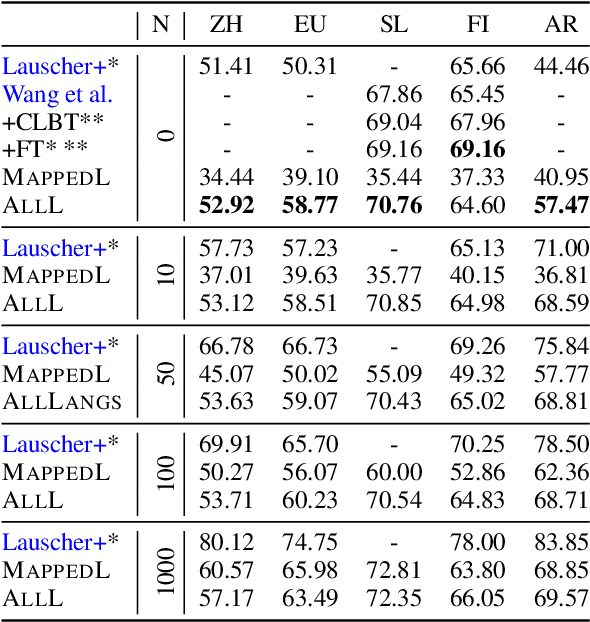
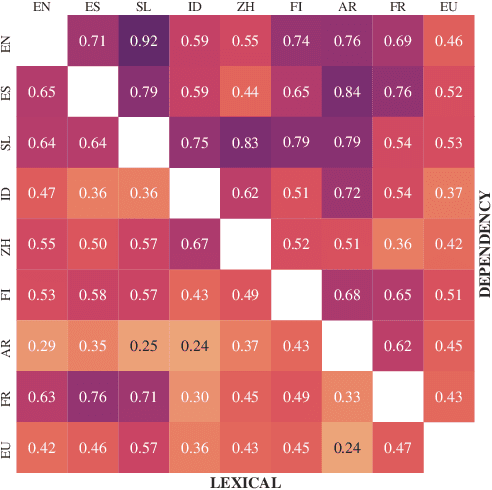
State-of-the-art contextual embeddings are obtained from large language models available only for a few languages. For others, we need to learn representations using a multilingual model. There is an ongoing debate on whether multilingual embeddings can be aligned in a space shared across many languages. The novel Orthogonal Structural Probe (Limisiewicz and Mare\v{c}ek, 2021) allows us to answer this question for specific linguistic features and learn a projection based only on mono-lingual annotated datasets. We evaluate syntactic (UD) and lexical (WordNet) structural information encoded inmBERT's contextual representations for nine diverse languages. We observe that for languages closely related to English, no transformation is needed. The evaluated information is encoded in a shared cross-lingual embedding space. For other languages, it is beneficial to apply orthogonal transformation learned separately for each language. We successfully apply our findings to zero-shot and few-shot cross-lingual parsing.
DeepGOMIMO: Deep Learning-Aided Generalized Optical MIMO with CSI-Free Blind Detection
Oct 08, 2021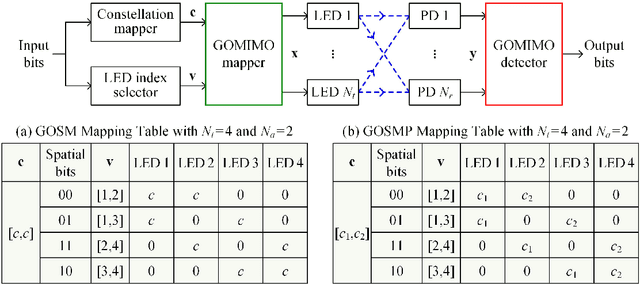
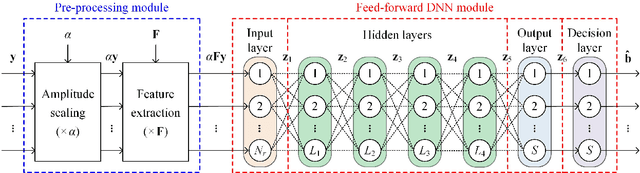
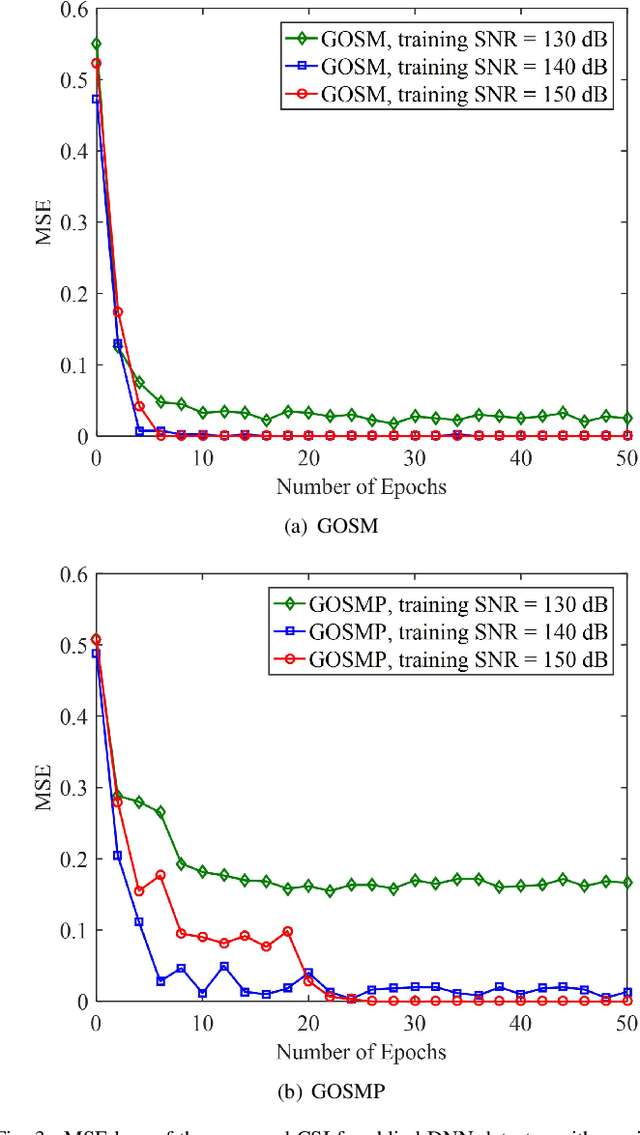
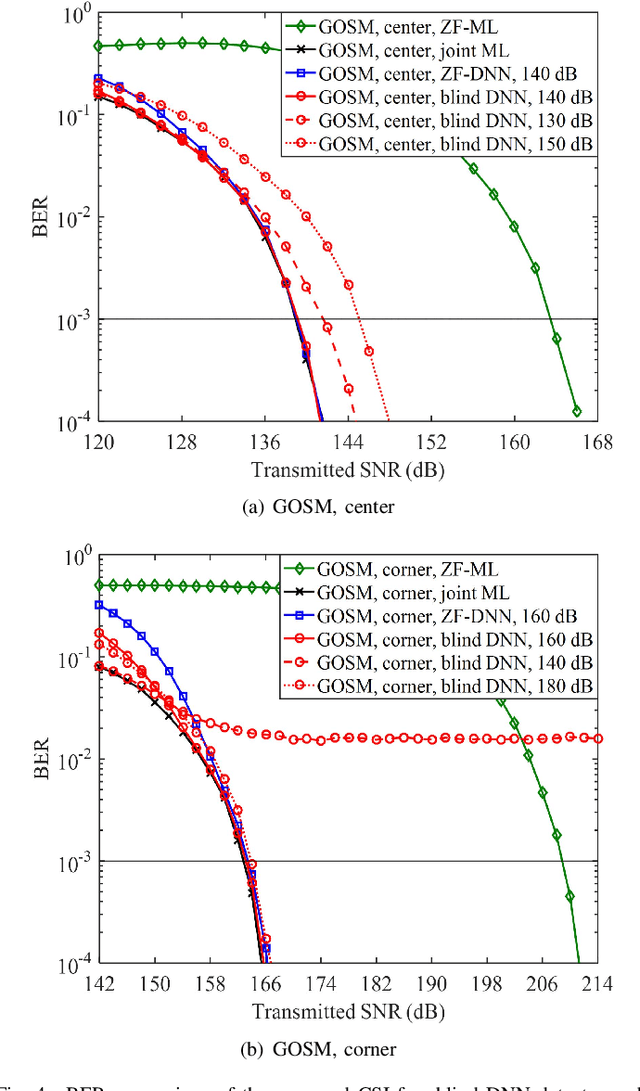
Generalized optical multiple-input multiple-output (GOMIMO) techniques have been recently shown to be promising for high-speed optical wireless communication (OWC) systems. In this paper, we propose a novel deep learning-aided GOMIMO (DeepGOMIMO) framework for GOMIMO systems, where channel state information (CSI)-free blind detection can be enabled by employing a specially designed deep neural network (DNN)-based MIMO detector. The CSI-free blind DNN detector mainly consists of two modules: one is the pre-processing module which is designed to address both the path loss and channel crosstalk issues caused by MIMO transmission, and the other is the feed-forward DNN module which is used for joint detection of spatial and constellation information by learning the statistics of both the input signal and the additive noise. Our simulation results clearly verify that, in a typical indoor 4 $\times$ 4 MIMO-OWC system using both generalized optical spatial modulation (GOSM) and generalized optical spatial multiplexing (GOSMP) with unipolar non-zero 4-ary pulse amplitude modulation (4-PAM) modulation, the proposed CSI-free blind DNN detector achieves near the same bit error rate (BER) performance as the optimal joint maximum-likelihood (ML) detector, but with much reduced computational complexity. Moreover, since the CSI-free blind DNN detector does not require instantaneous channel estimation to obtain accurate CSI, it enjoys the unique advantages of improved achievable data rate and reduced communication time delay in comparison to the CSI-based zero-forcing DNN (ZF-DNN) detector.
Concept-Aware Denoising Graph Neural Network for Micro-Video Recommendation
Sep 28, 2021

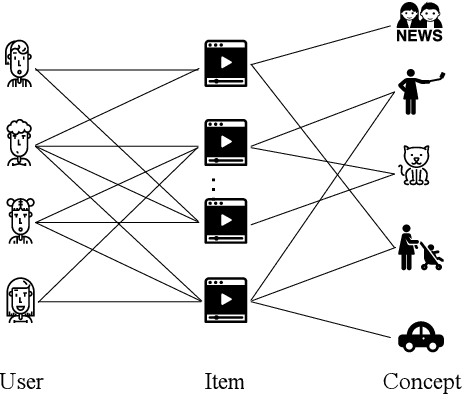
Recently, micro-video sharing platforms such as Kuaishou and Tiktok have become a major source of information for people's lives. Thanks to the large traffic volume, short video lifespan and streaming fashion of these services, it has become more and more pressing to improve the existing recommender systems to accommodate these challenges in a cost-effective way. In this paper, we propose a novel concept-aware denoising graph neural network (named CONDE) for micro-video recommendation. CONDE consists of a three-phase graph convolution process to derive user and micro-video representations: warm-up propagation, graph denoising and preference refinement. A heterogeneous tripartite graph is constructed by connecting user nodes with video nodes, and video nodes with associated concept nodes, extracted from captions and comments of the videos. To address the noisy information in the graph, we introduce a user-oriented graph denoising phase to extract a subgraph which can better reflect the user's preference. Despite the main focus of micro-video recommendation in this paper, we also show that our method can be generalized to other types of tasks. Therefore, we also conduct empirical studies on a well-known public E-commerce dataset. The experimental results suggest that the proposed CONDE achieves significantly better recommendation performance than the existing state-of-the-art solutions.
Exploiting full Resolution Feature Context for Liver Tumor and Vessel Segmentation via Fusion Encoder: Application to Liver Tumor and Vessel 3D reconstruction
Nov 26, 2021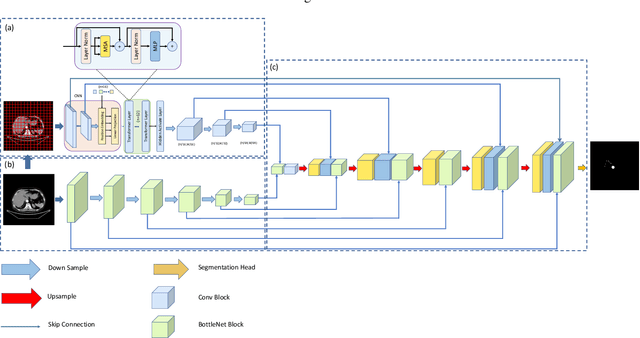
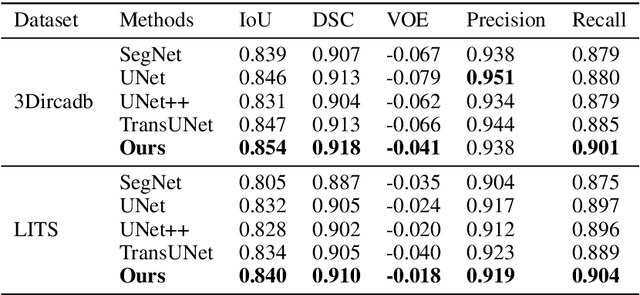
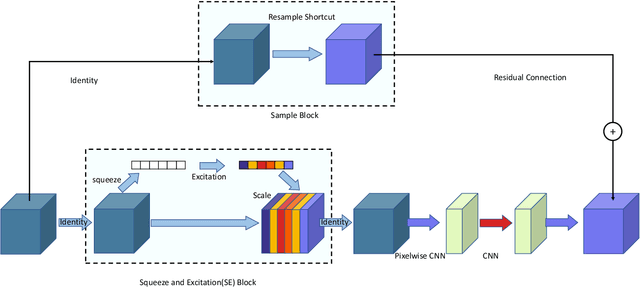
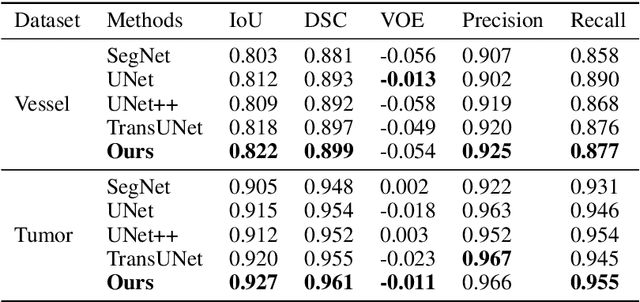
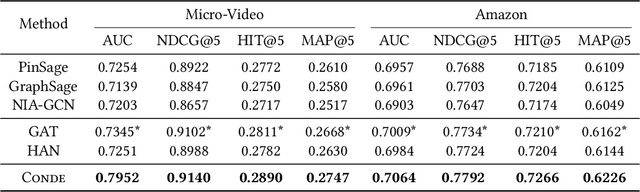
Liver cancer is one of the most common malignant diseases in the world. Segmentation and labeling of liver tumors and blood vessels in CT images can provide convenience for doctors in liver tumor diagnosis and surgical intervention. In the past decades, automatic CT segmentation methods based on deep learning have received widespread attention in the medical field. Many state-of-the-art segmentation algorithms appeared during this period. Yet, most of the existing segmentation methods only care about the local feature context and have a perception defect in the global relevance of medical images, which significantly affects the segmentation effect of liver tumors and blood vessels. We introduce a multi-scale feature context fusion network called TransFusionNet based on Transformer and SEBottleNet. This network can accurately detect and identify the details of the region of interest of the liver vessel, meanwhile it can improve the recognition of morphologic margins of liver tumors by exploiting the global information of CT images. Experiments show that TransFusionNet is better than the state-of-the-art method on both the public dataset LITS and 3Dircadb and our clinical dataset. Finally, we propose an automatic 3D reconstruction algorithm based on the trained model. The algorithm can complete the reconstruction quickly and accurately in 1 second.
Understanding Character Recognition using Visual Explanations Derived from the Human Visual System and Deep Networks
Aug 29, 2021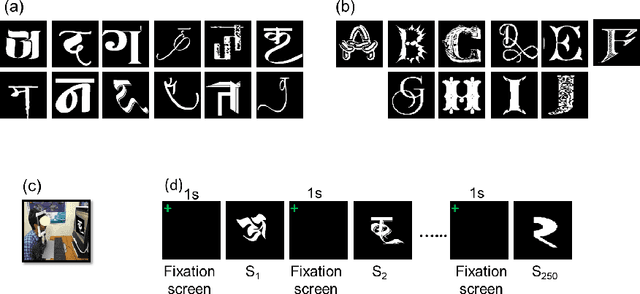
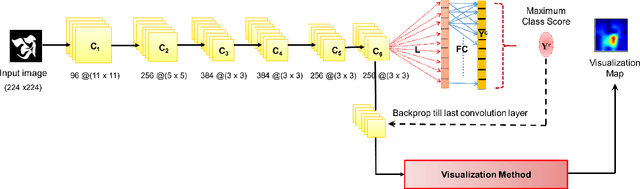
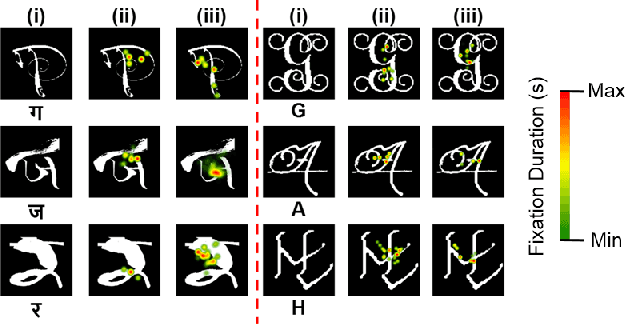
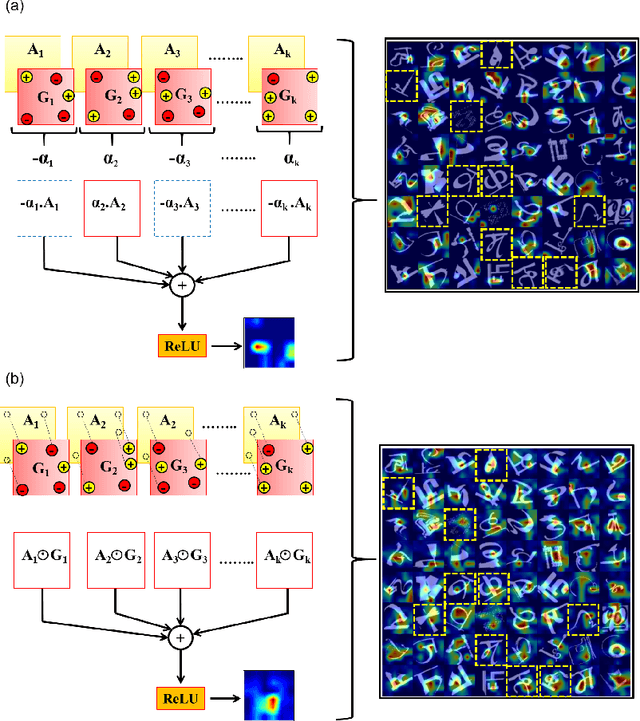
Human observers engage in selective information uptake when classifying visual patterns. The same is true of deep neural networks, which currently constitute the best performing artificial vision systems. Our goal is to examine the congruence, or lack thereof, in the information-gathering strategies of the two systems. We have operationalized our investigation as a character recognition task. We have used eye-tracking to assay the spatial distribution of information hotspots for humans via fixation maps and an activation mapping technique for obtaining analogous distributions for deep networks through visualization maps. Qualitative comparison between visualization maps and fixation maps reveals an interesting correlate of congruence. The deep learning model considered similar regions in character, which humans have fixated in the case of correctly classified characters. On the other hand, when the focused regions are different for humans and deep nets, the characters are typically misclassified by the latter. Hence, we propose to use the visual fixation maps obtained from the eye-tracking experiment as a supervisory input to align the model's focus on relevant character regions. We find that such supervision improves the model's performance significantly and does not require any additional parameters. This approach has the potential to find applications in diverse domains such as medical analysis and surveillance in which explainability helps to determine system fidelity.
Hand Image Understanding via Deep Multi-Task Learning
Jul 28, 2021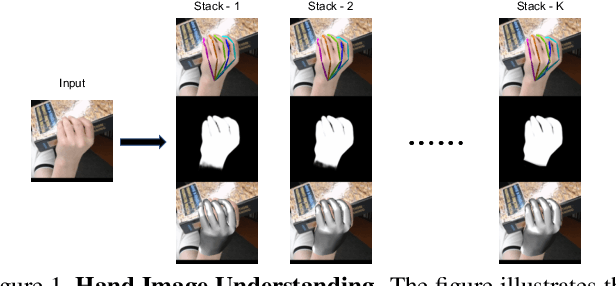

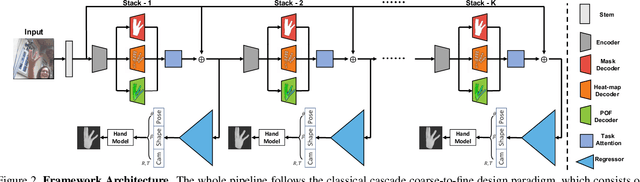
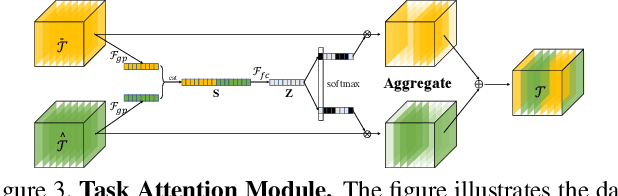
Analyzing and understanding hand information from multimedia materials like images or videos is important for many real world applications and remains active in research community. There are various works focusing on recovering hand information from single image, however, they usually solve a single task, for example, hand mask segmentation, 2D/3D hand pose estimation, or hand mesh reconstruction and perform not well in challenging scenarios. To further improve the performance of these tasks, we propose a novel Hand Image Understanding (HIU) framework to extract comprehensive information of the hand object from a single RGB image, by jointly considering the relationships between these tasks. To achieve this goal, a cascaded multi-task learning (MTL) backbone is designed to estimate the 2D heat maps, to learn the segmentation mask, and to generate the intermediate 3D information encoding, followed by a coarse-to-fine learning paradigm and a self-supervised learning strategy. Qualitative experiments demonstrate that our approach is capable of recovering reasonable mesh representations even in challenging situations. Quantitatively, our method significantly outperforms the state-of-the-art approaches on various widely-used datasets, in terms of diverse evaluation metrics.
Learning Deep Context-Sensitive Decomposition for Low-Light Image Enhancement
Dec 09, 2021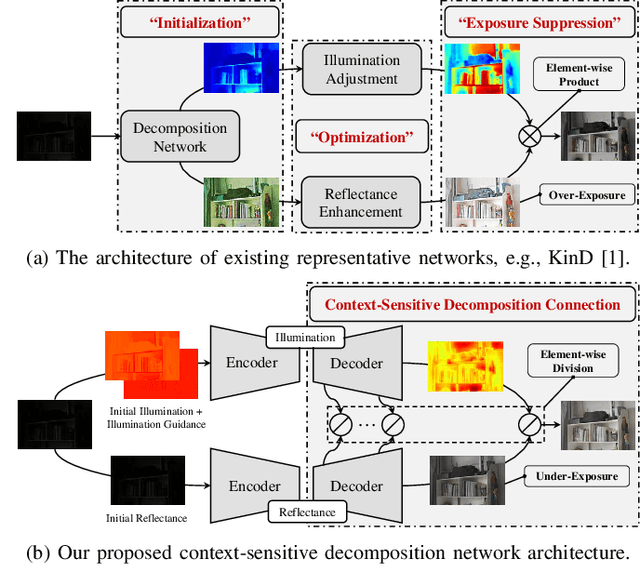
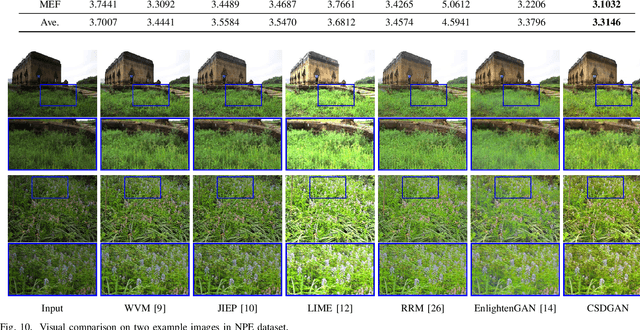

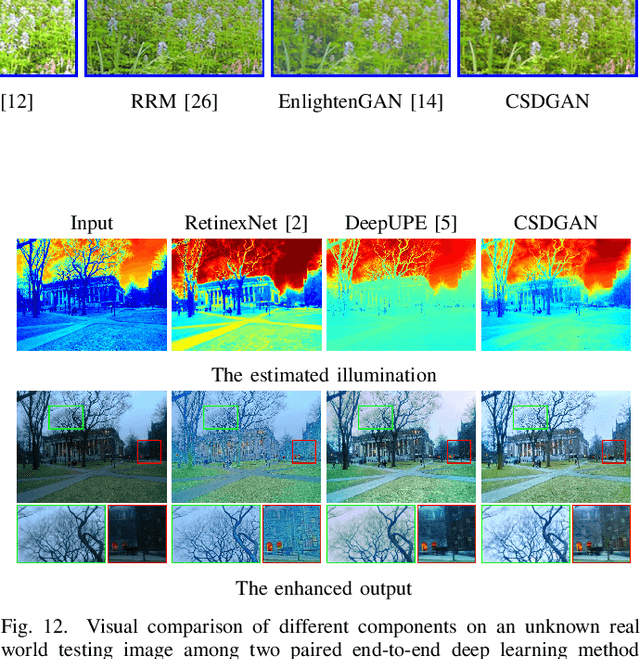
Enhancing the quality of low-light images plays a very important role in many image processing and multimedia applications. In recent years, a variety of deep learning techniques have been developed to address this challenging task. A typical framework is to simultaneously estimate the illumination and reflectance, but they disregard the scene-level contextual information encapsulated in feature spaces, causing many unfavorable outcomes, e.g., details loss, color unsaturation, artifacts, and so on. To address these issues, we develop a new context-sensitive decomposition network architecture to exploit the scene-level contextual dependencies on spatial scales. More concretely, we build a two-stream estimation mechanism including reflectance and illumination estimation network. We design a novel context-sensitive decomposition connection to bridge the two-stream mechanism by incorporating the physical principle. The spatially-varying illumination guidance is further constructed for achieving the edge-aware smoothness property of the illumination component. According to different training patterns, we construct CSDNet (paired supervision) and CSDGAN (unpaired supervision) to fully evaluate our designed architecture. We test our method on seven testing benchmarks to conduct plenty of analytical and evaluated experiments. Thanks to our designed context-sensitive decomposition connection, we successfully realized excellent enhanced results, which fully indicates our superiority against existing state-of-the-art approaches. Finally, considering the practical needs for high-efficiency, we develop a lightweight CSDNet (named LiteCSDNet) by reducing the number of channels. Further, by sharing an encoder for these two components, we obtain a more lightweight version (SLiteCSDNet for short). SLiteCSDNet just contains 0.0301M parameters but achieves the almost same performance as CSDNet.