 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rethink Dilated Convolution for Real-time Semantic Segmentation
Nov 18, 2021
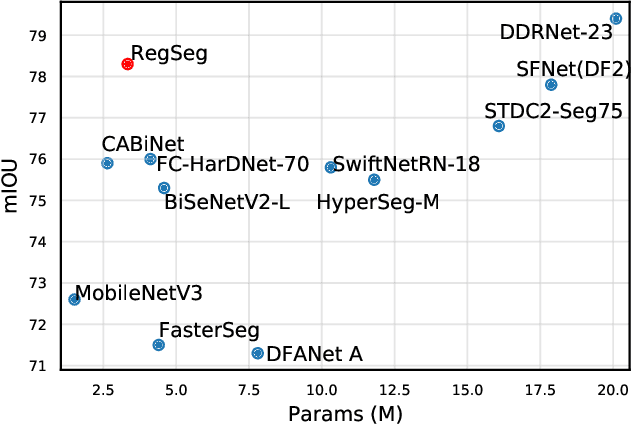
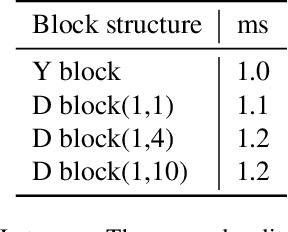
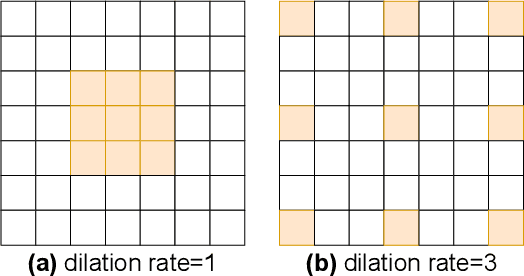
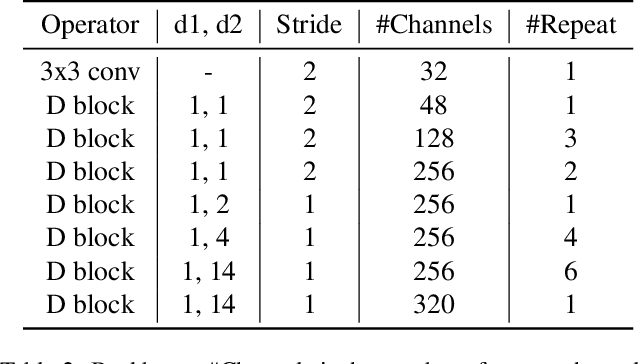
Recent advances in semantic segmentation generally adapt an ImageNet pretrained backbone with a special context module after it to quickly increase the field-of-view. Although successful, the backbone, in which most of the computation lies, does not have a large enough field-of-view to make the best decisions. Some recent advances tackle this problem by rapidly downsampling the resolution in the backbone while also having one or more parallel branches with higher resolutions. We take a different approach by designing a ResNeXt inspired block structure that uses two parallel 3x3 convolutional layers with different dilation rates to increase the field-of-view while also preserving the local details. By repeating this block structure in the backbone, we do not need to append any special context module after it. In addition, we propose a lightweight decoder that restores local information better than common alternatives. To demonstrate the effectiveness of our approach, our model RegSeg achieves state-of-the-art results on real-time Cityscapes and CamVid datasets. Using a T4 GPU with mixed precision, RegSeg achieves 78.3 mIOU on Cityscapes test set at 30 FPS, and 80.9 mIOU on CamVid test set at 70 FPS, both without ImageNet pretraining.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.
Temporal Clustering with External Memory Network for Disease Progression Modeling
Oct 09, 2021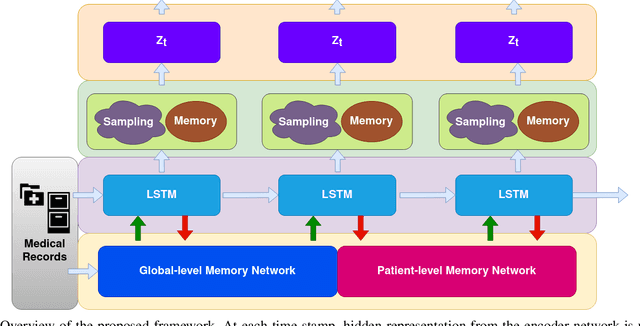
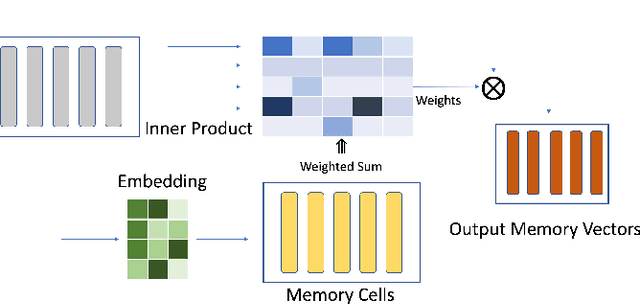
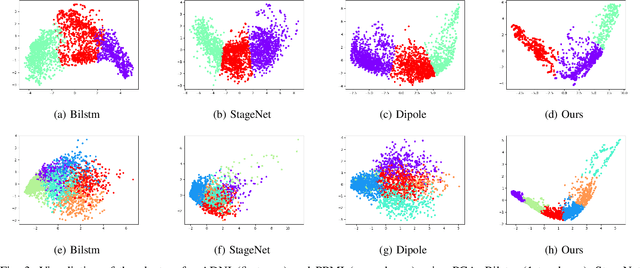
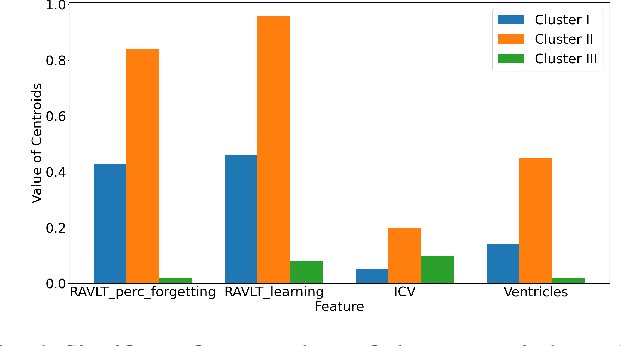
Disease progression modeling (DPM) involves using mathematical frameworks to quantitatively measure the severity of how certain disease progresses. DPM is useful in many ways such as predicting health state, categorizing disease stages, and assessing patients disease trajectory etc. Recently, with wider availability of electronic health records (EHR) and the broad application of data-driven machine learning method, DPM has attracted much attention yet remains two major challenges: (i) Due to the existence of irregularity, heterogeneity and long-term dependency in EHRs, most existing DPM methods might not be able to provide comprehensive patient representations. (ii) Lots of records in EHRs might be irrelevant to the target disease. Most existing models learn to automatically focus on the relevant information instead of explicitly capture the target-relevant events, which might make the learned model suboptimal. To address these two issues, we propose Temporal Clustering with External Memory Network (TC-EMNet) for DPM that groups patients with similar trajectories to form disease clusters/stages. TC-EMNet uses a variational autoencoder (VAE) to capture internal complexity from the input data and utilizes an external memory work to capture long term distance information, both of which are helpful for producing comprehensive patient states. Last but not least, k-means algorithm is adopted to cluster the extracted comprehensive patient states to capture disease progression. Experiments on two real-world datasets show that our model demonstrates competitive clustering performance against state-of-the-art methods and is able to identify clinically meaningful clusters. The visualization of the extracted patient states shows that the proposed model can generate better patient states than the baselines.
On Architectures for Including Visual Information in Neural Language Models for Image Description
Nov 09, 2019

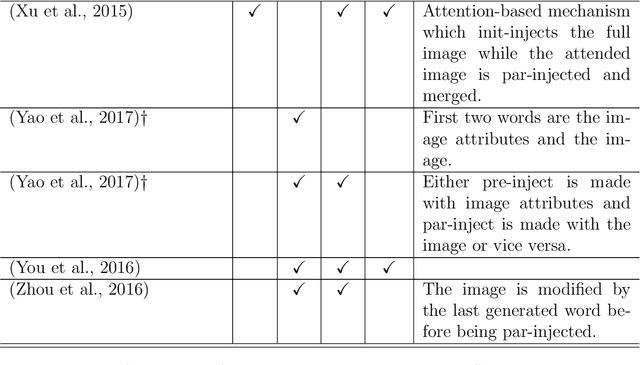
A neural language model can be conditioned into generating descriptions for images by providing visual information apart from the sentence prefix. This visual information can be included into the language model through different points of entry resulting in different neural architectures. We identify four main architectures which we call init-inject, pre-inject, par-inject, and merge. We analyse these four architectures and conclude that the best performing one is init-inject, which is when the visual information is injected into the initial state of the recurrent neural network. We confirm this using both automatic evaluation measures and human annotation. We then analyse how much influence the images have on each architecture. This is done by measuring how different the output probabilities of a model are when a partial sentence is combined with a completely different image from the one it is meant to be combined with. We find that init-inject tends to quickly become less influenced by the image as more words are generated. A different architecture called merge, which is when the visual information is merged with the recurrent neural network's hidden state vector prior to output, loses visual influence much more slowly, suggesting that it would work better for generating longer sentences. We also observe that the merge architecture can have its recurrent neural network pre-trained in a text-only language model (transfer learning) rather than be initialised randomly as usual. This results in even better performance than the other architectures, provided that the source language model is not too good at language modelling or it will overspecialise and be less effective at image description generation. Our work opens up new avenues of research in neural architectures, explainable AI, and transfer learning.
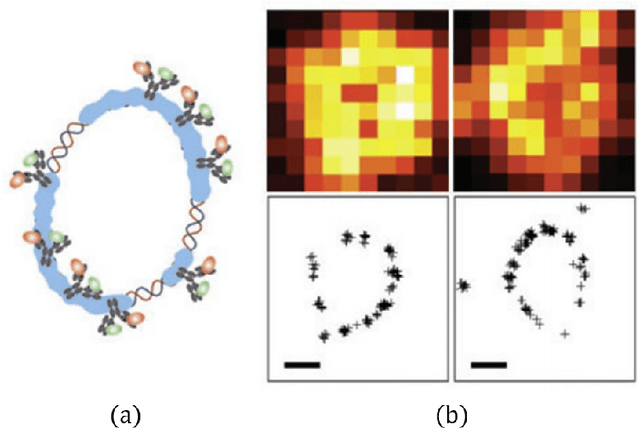
Generation mechanism of cell assembly to store information about hand recognition
Sep 18, 2019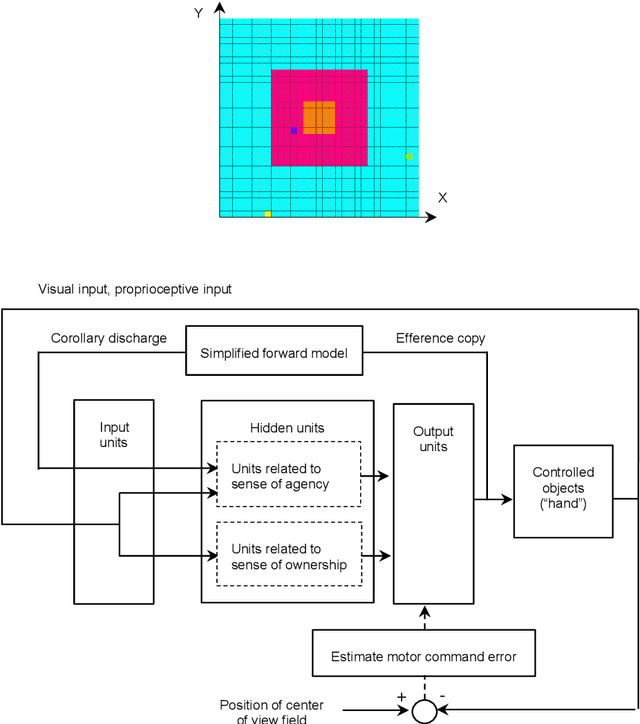
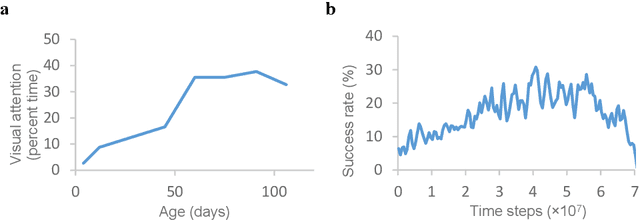
A specific memory is stored in a cell assembly that is activated during fear learning in mice; however, research regarding cell assemblies associated with procedural and habit learning processes is lacking. In modeling studies, simulations of the learning process for hand regard, which is a type of procedural learning, resulted in the formation of cell assemblies. However, the mechanisms through which the cell assemblies form and the information stored in these cell assemblies remain unknown. In this paper, the relationship between hand movements and weight changes during the simulated learning process for hand regard was used to elucidate the mechanism through which inhibitory weights are generated, which plays an important role in the formation of cell assemblies. During the early training phase, trial and error attempts to bring the hand into the field of view caused the generation of inhibitory weights, and the cell assemblies self-organized from these inhibitory weights. The information stored in the cell assemblies was estimated by examining the contributions of the cell assemblies outputs to hand movements. During sustained hand regard, the outputs from these cell assemblies moved the hand into the field of view, using hand-related inputs almost exclusively. Therefore, infants are likely able to select the inputs associated with their hand (that is, distinguish between their hand and others), based on the information stored in the cell assembly, and move their hands into the field of view during sustained hand regard.
Deep Unrolled Recovery in Sparse Biological Imaging
Sep 28, 2021

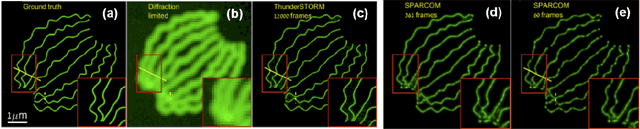
Deep algorithm unrolling has emerged as a powerful model-based approach to develop deep architectures that combine the interpretability of iterative algorithms with the performance gains of supervised deep learning, especially in cases of sparse optimization. This framework is well-suited to applications in biological imaging, where physics-based models exist to describe the measurement process and the information to be recovered is often highly structured. Here, we review the method of deep unrolling, and show how it improves source localization in several biological imaging settings.
Automated volumetric and statistical shape assessment of cam-type morphology of the femoral head-neck region from 3D magnetic resonance images
Dec 06, 2021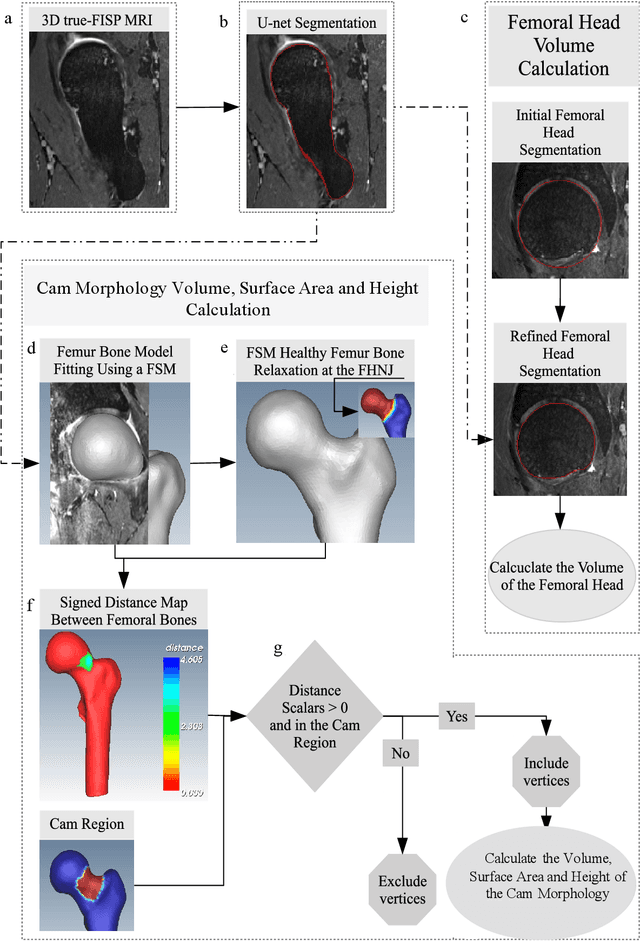
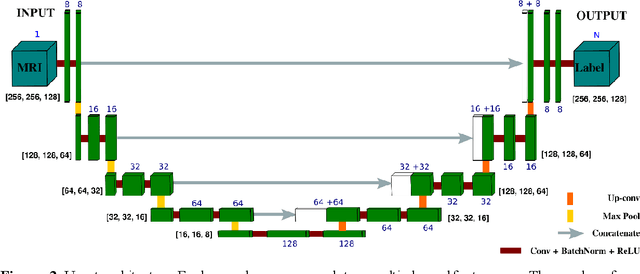

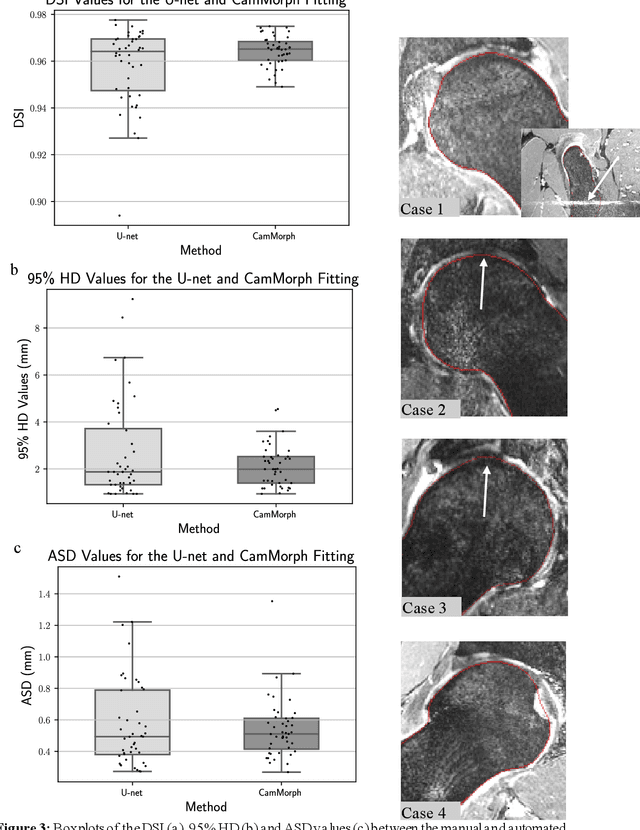
Femoroacetabular impingement (FAI) cam morphology is routinely assessed using two-dimensional alpha angles which do not provide specific data on cam size characteristics. The purpose of this study is to implement a novel, automated three-dimensional (3D) pipeline, CamMorph, for segmentation and measurement of cam volume, surface area and height from magnetic resonance (MR) images in patients with FAI. The CamMorph pipeline involves two processes: i) proximal femur segmentation using an approach integrating 3D U-net with focused shape modelling (FSM); ii) use of patient-specific anatomical information from 3D FSM to simulate healthy femoral bone models and pathological region constraints to identify cam bone mass. Agreement between manual and automated segmentation of the proximal femur was evaluated with the Dice similarity index (DSI) and surface distance measures. Independent t-tests or Mann-Whitney U rank tests were used to compare the femoral head volume, cam volume, surface area and height data between female and male patients with FAI. There was a mean DSI value of 0.964 between manual and automated segmentation of proximal femur volume. Compared to female FAI patients, male patients had a significantly larger mean femoral head volume (66.12cm3 v 46.02cm3, p<0.001). Compared to female FAI patients, male patients had a significantly larger mean cam volume (1136.87mm3 v 337.86mm3, p<0.001), surface area (657.36mm2 v 306.93mm2 , p<0.001), maximum-height (3.89mm v 2.23mm, p<0.001) and average-height (1.94mm v 1.00mm, p<0.001). Automated analyses of 3D MR images from patients with FAI using the CamMorph pipeline showed that, in comparison with female patients, male patients had significantly greater cam volume, surface area and height.
Lookup or Exploratory: What is Your Search Intent?
Oct 09, 2021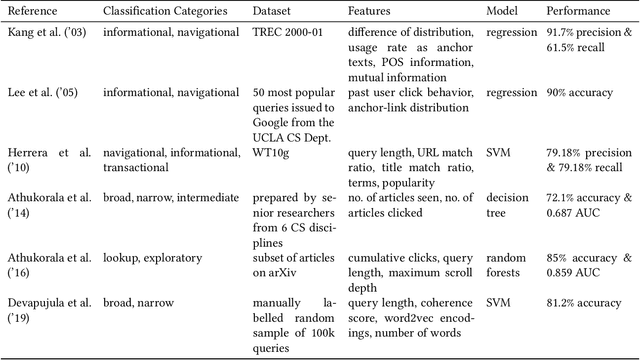
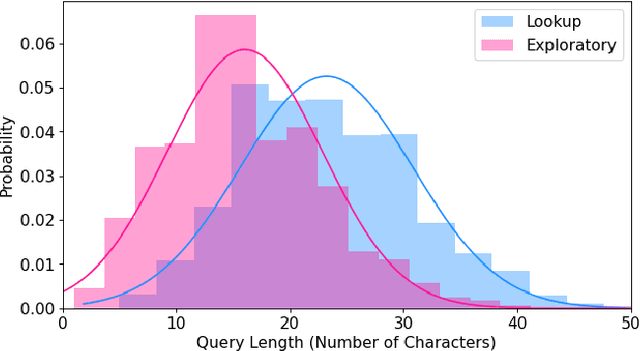
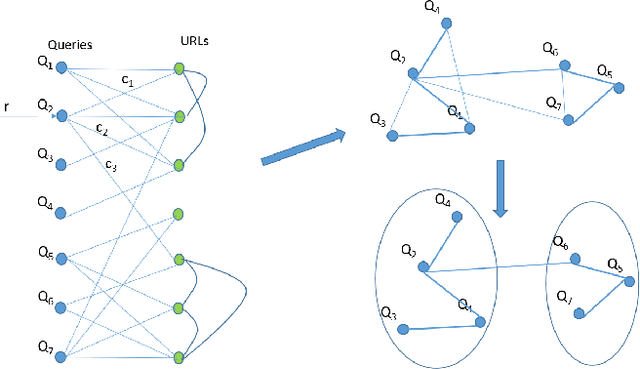

Search query specificity is broadly divided into two categories - Exploratory or Lookup. If a query specificity can be identified at the run time, it can be used to significantly improve the search results as well as quality of suggestions to alter the query. However, with millions of queries coming every day on a commercial search engine, it is non-trivial to develop a horizontal technique to determine query specificity at run time. Existing techniques suffer either from lack of enough training data or are dependent on information such as query length or session information. In this paper, we show that such methodologies are inadequate or at times misleading. We propose a novel methodology, to overcome these limitations. First, we demonstrate a heuristic-based method to identify Exploratory or Lookup intent queries at scale, classifying millions of queries into the two classes with a high accuracy, as shown in our experiments. Our methodology is not dependent on session data or on query length. Next, we train a transformer-based deep neural network to classify the queries into one of the two classes at run time. Our method uses a bidirectional GRU initialized with pretrained BERT-base-uncased embeddings and an augmented triplet loss to classify the intent of queries without using any session data. We also introduce a novel Semi-Greedy Iterative Training approach to fine-tune our model. Our model is deployable for real time query specificity identification with response time of less than one millisecond. Our technique is generic, and the results have valuable implications for improving the quality of search results and suggestions.
Sequential Bayesian Experimental Design for Implicit Models via Mutual Information
Mar 20, 2020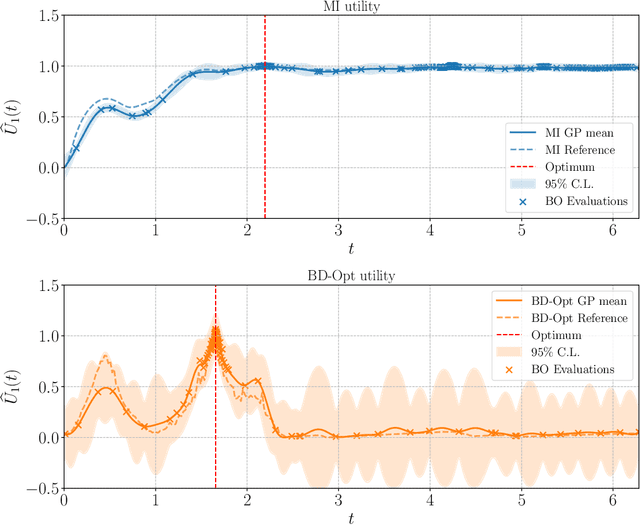
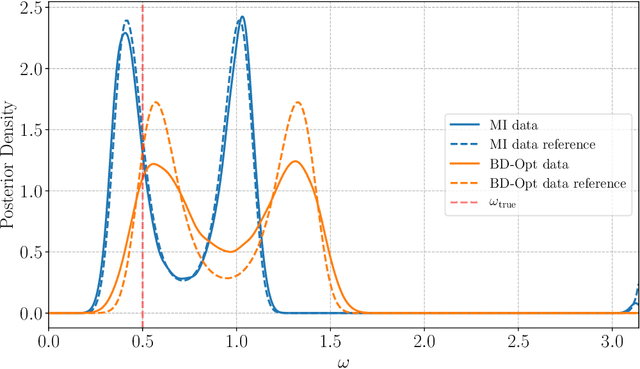
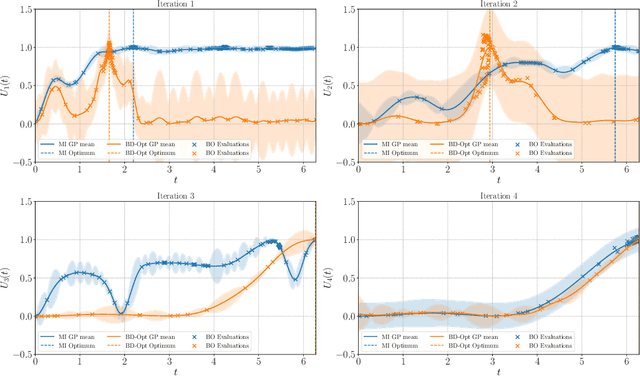
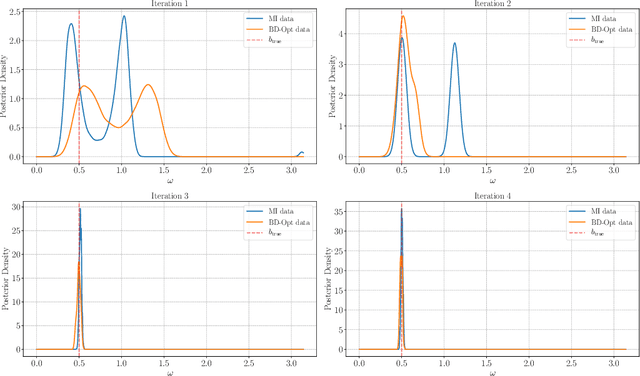
Bayesian experimental design (BED) is a framework that uses statistical models and decision making under uncertainty to optimise the cost and performance of a scientific experiment. Sequential BED, as opposed to static BED, considers the scenario where we can sequentially update our beliefs about the model parameters through data gathered in the experiment. A class of models of particular interest for the natural and medical sciences are implicit models, where the data generating distribution is intractable, but sampling from it is possible. Even though there has been a lot of work on static BED for implicit models in the past few years, the notoriously difficult problem of sequential BED for implicit models has barely been touched upon. We address this gap in the literature by devising a novel sequential design framework for parameter estimation that uses the Mutual Information (MI) between model parameters and simulated data as a utility function to find optimal experimental designs, which has not been done before for implicit models. Our approach uses likelihood-free inference by ratio estimation to simultaneously estimate posterior distributions and the MI. During the sequential BED procedure we utilise Bayesian optimisation to help us optimise the MI utility. We find that our framework is efficient for the various implicit models tested, yielding accurate parameter estimates after only a few iterations.
Context-Aware Online Client Selection for Hierarchical Federated Learning
Dec 02, 2021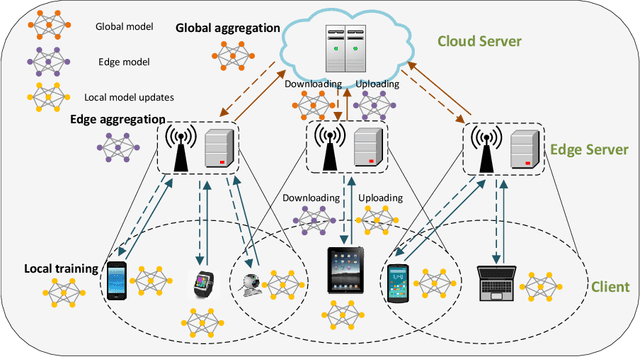
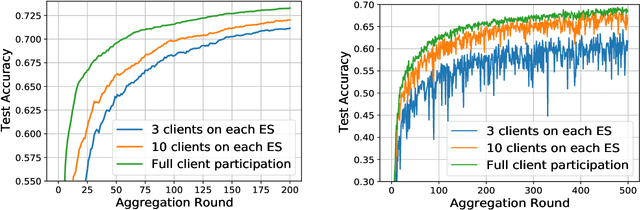
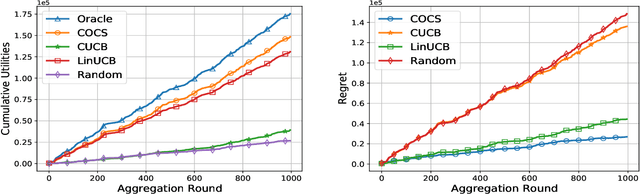
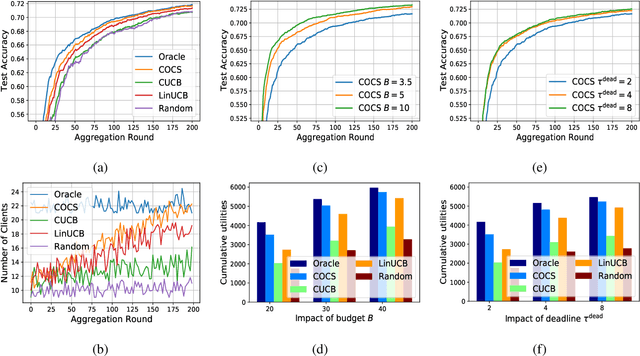
Federated Learning (FL) has been considered as an appealing framework to tackle data privacy issues of mobile devices compared to conventional Machine Learning (ML). Using Edge Servers (ESs) as intermediaries to perform model aggregation in proximity can reduce the transmission overhead, and it enables great potentials in low-latency FL, where the hierarchical architecture of FL (HFL) has been attracted more attention. Designing a proper client selection policy can significantly improve training performance, and it has been extensively used in FL studies. However, to the best of our knowledge, there are no studies focusing on HFL. In addition, client selection for HFL faces more challenges than conventional FL, e.g., the time-varying connection of client-ES pairs and the limited budget of the Network Operator (NO). In this paper, we investigate a client selection problem for HFL, where the NO learns the number of successful participating clients to improve the training performance (i.e., select as many clients in each round) as well as under the limited budget on each ES. An online policy, called Context-aware Online Client Selection (COCS), is developed based on Contextual Combinatorial Multi-Armed Bandit (CC-MAB). COCS observes the side-information (context) of local computing and transmission of client-ES pairs and makes client selection decisions to maximize NO's utility given a limited budget. Theoretically, COCS achieves a sublinear regret compared to an Oracle policy on both strongly convex and non-convex HFL. Simulation results also support the efficiency of the proposed COCS policy on real-world datasets.