 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DAE-GAN: Dynamic Aspect-aware GAN for Text-to-Image Synthesis
Aug 27, 2021

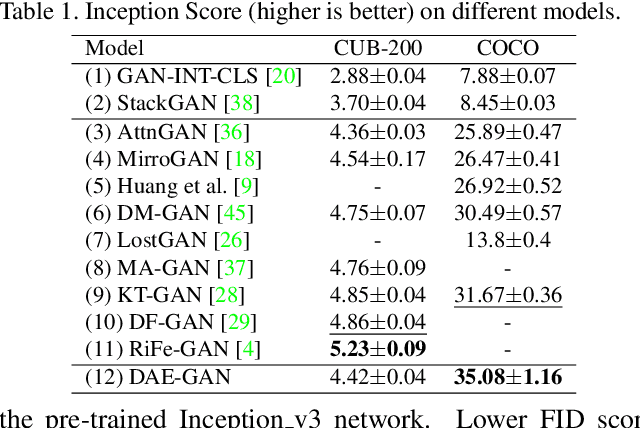
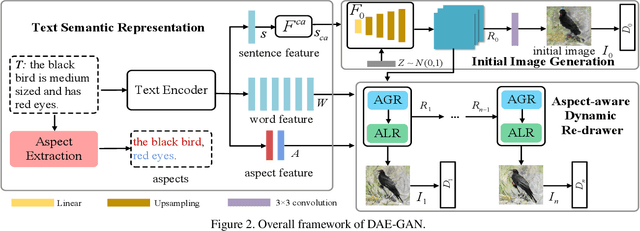
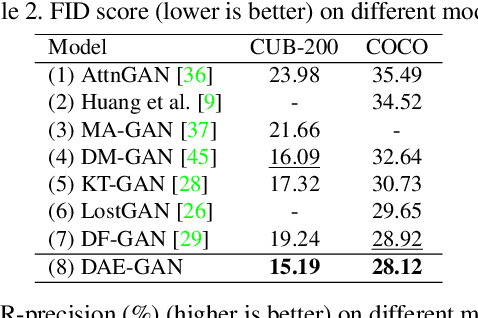
Text-to-image synthesis refers to generating an image from a given text description, the key goal of which lies in photo realism and semantic consistency. Previous methods usually generate an initial image with sentence embedding and then refine it with fine-grained word embedding. Despite the significant progress, the 'aspect' information (e.g., red eyes) contained in the text, referring to several words rather than a word that depicts 'a particular part or feature of something', is often ignored, which is highly helpful for synthesizing image details. How to make better utilization of aspect information in text-to-image synthesis still remains an unresolved challenge. To address this problem, in this paper, we propose a Dynamic Aspect-awarE GAN (DAE-GAN) that represents text information comprehensively from multiple granularities, including sentence-level, word-level, and aspect-level. Moreover, inspired by human learning behaviors, we develop a novel Aspect-aware Dynamic Re-drawer (ADR) for image refinement, in which an Attended Global Refinement (AGR) module and an Aspect-aware Local Refinement (ALR) module are alternately employed. AGR utilizes word-level embedding to globally enhance the previously generated image, while ALR dynamically employs aspect-level embedding to refine image details from a local perspective. Finally, a corresponding matching loss function is designed to ensure the text-image semantic consistency at different levels. Extensive experiments on two well-studied and publicly available datasets (i.e., CUB-200 and COCO) demonstrate the superiority and rationality of our method.
Minimax Optimal Quantile and Semi-Adversarial Regret via Root-Logarithmic Regularizers
Nov 07, 2021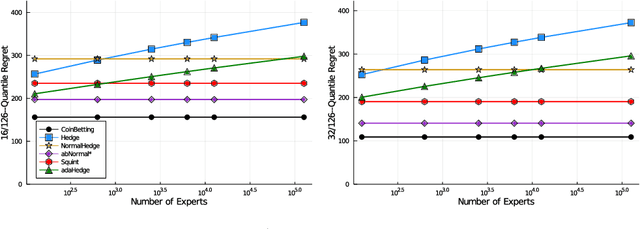
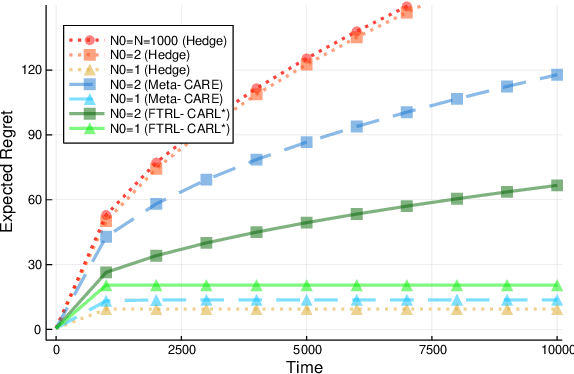
Quantile (and, more generally, KL) regret bounds, such as those achieved by NormalHedge (Chaudhuri, Freund, and Hsu 2009) and its variants, relax the goal of competing against the best individual expert to only competing against a majority of experts on adversarial data. More recently, the semi-adversarial paradigm (Bilodeau, Negrea, and Roy 2020) provides an alternative relaxation of adversarial online learning by considering data that may be neither fully adversarial nor stochastic (i.i.d.). We achieve the minimax optimal regret in both paradigms using FTRL with separate, novel, root-logarithmic regularizers, both of which can be interpreted as yielding variants of NormalHedge. We extend existing KL regret upper bounds, which hold uniformly over target distributions, to possibly uncountable expert classes with arbitrary priors; provide the first full-information lower bounds for quantile regret on finite expert classes (which are tight); and provide an adaptively minimax optimal algorithm for the semi-adversarial paradigm that adapts to the true, unknown constraint faster, leading to uniformly improved regret bounds over existing methods.
* 30 pages, 2 figures. Jeffrey Negrea and Blair Bilodeau are equal-contribution authors. Updated citations
Belief propagation for permutations, rankings, and partial orders
Oct 01, 2021
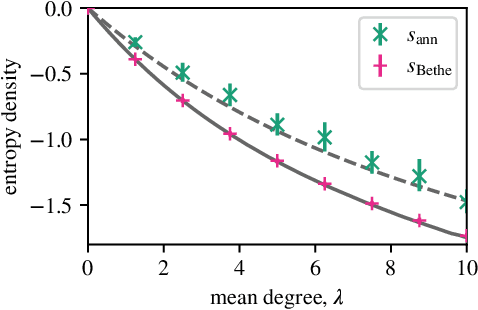
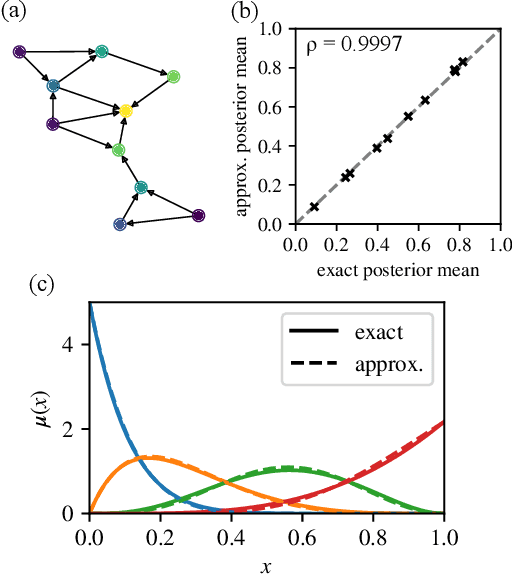
Many datasets give partial information about an ordering or ranking by indicating which team won a game, which item a user prefers, or who infected whom. We define a continuous spin system whose Gibbs distribution is the posterior distribution on permutations, given a probabilistic model of these interactions. Using the cavity method we derive a belief propagation algorithm that computes the marginal distribution of each node's position. In addition, the Bethe free energy lets us approximate the number of linear extensions of a partial order and perform model selection.
FLAME: Facial Landmark Heatmap Activated Multimodal Gaze Estimation
Oct 10, 2021

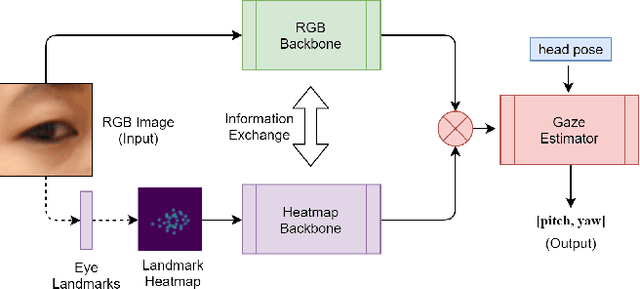
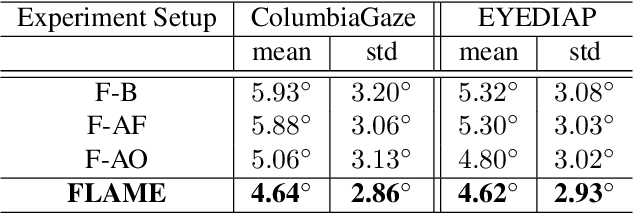
3D gaze estimation is about predicting the line of sight of a person in 3D space. Person-independent models for the same lack precision due to anatomical differences of subjects, whereas person-specific calibrated techniques add strict constraints on scalability. To overcome these issues, we propose a novel technique, Facial Landmark Heatmap Activated Multimodal Gaze Estimation (FLAME), as a way of combining eye anatomical information using eye landmark heatmaps to obtain precise gaze estimation without any person-specific calibration. Our evaluation demonstrates a competitive performance of about 10% improvement on benchmark datasets ColumbiaGaze and EYEDIAP. We also conduct an ablation study to validate our method.
Improving Transferability of Representations via Augmentation-Aware Self-Supervision
Nov 18, 2021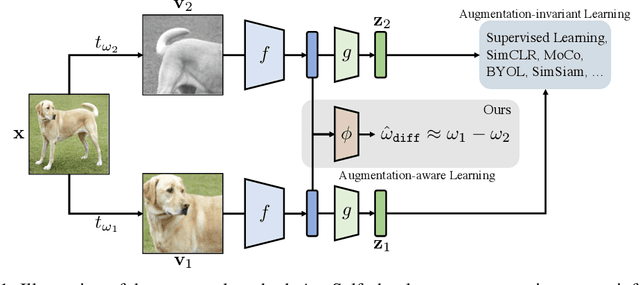
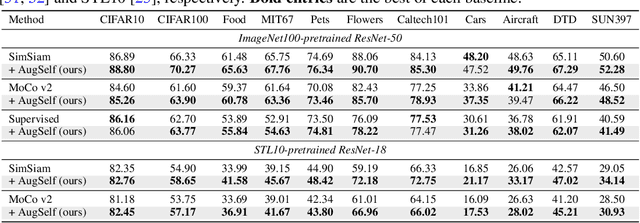
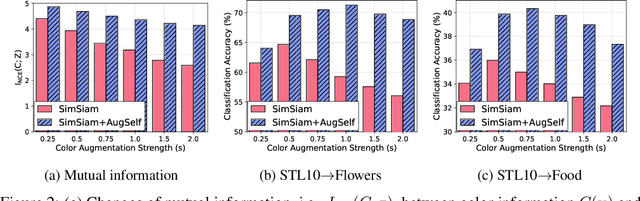
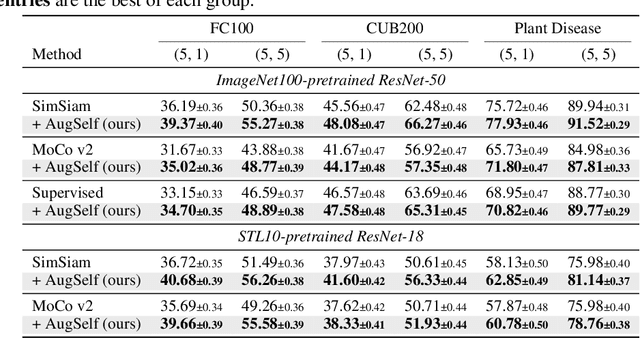
Recent unsupervised representation learning methods have shown to be effective in a range of vision tasks by learning representations invariant to data augmentations such as random cropping and color jittering. However, such invariance could be harmful to downstream tasks if they rely on the characteristics of the data augmentations, e.g., location- or color-sensitive. This is not an issue just for unsupervised learning; we found that this occurs even in supervised learning because it also learns to predict the same label for all augmented samples of an instance. To avoid such failures and obtain more generalizable representations, we suggest to optimize an auxiliary self-supervised loss, coined AugSelf, that learns the difference of augmentation parameters (e.g., cropping positions, color adjustment intensities) between two randomly augmented samples. Our intuition is that AugSelf encourages to preserve augmentation-aware information in learned representations, which could be beneficial for their transferability. Furthermore, AugSelf can easily be incorporated into recent state-of-the-art representation learning methods with a negligible additional training cost. Extensive experiments demonstrate that our simple idea consistently improves the transferability of representations learned by supervised and unsupervised methods in various transfer learning scenarios. The code is available at https://github.com/hankook/AugSelf.
Bolstering Stochastic Gradient Descent with Model Building
Nov 13, 2021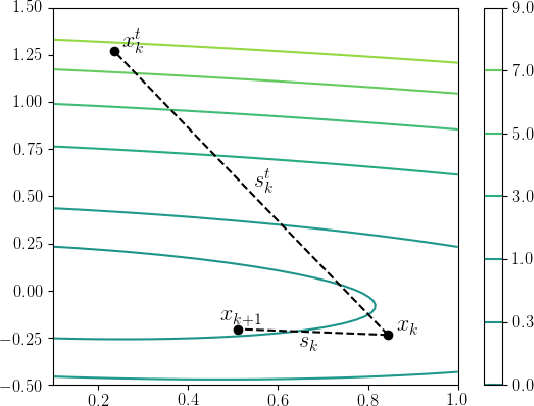
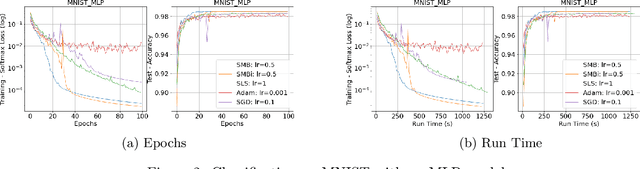
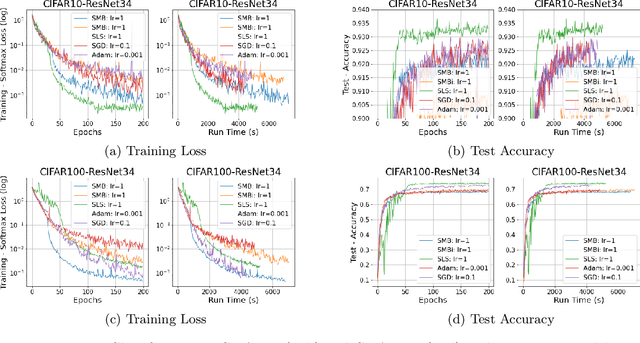
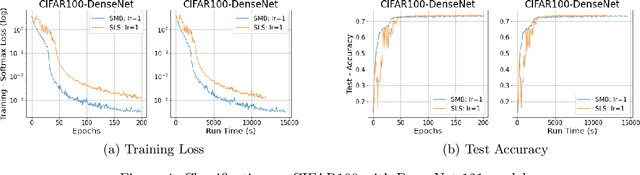
Stochastic gradient descent method and its variants constitute the core optimization algorithms that achieve good convergence rates for solving machine learning problems. These rates are obtained especially when these algorithms are fine-tuned for the application at hand. Although this tuning process can require large computational costs, recent work has shown that these costs can be reduced by line search methods that iteratively adjust the stepsize. We propose an alternative approach to stochastic line search by using a new algorithm based on forward step model building. This model building step incorporates a second-order information that allows adjusting not only the stepsize but also the search direction. Noting that deep learning model parameters come in groups (layers of tensors), our method builds its model and calculates a new step for each parameter group. This novel diagonalization approach makes the selected step lengths adaptive. We provide convergence rate analysis, and experimentally show that the proposed algorithm achieves faster convergence and better generalization in most problems. Moreover, our experiments show that the proposed method is quite robust as it converges for a wide range of initial stepsizes.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.
Temporal Clustering with External Memory Network for Disease Progression Modeling
Oct 09, 2021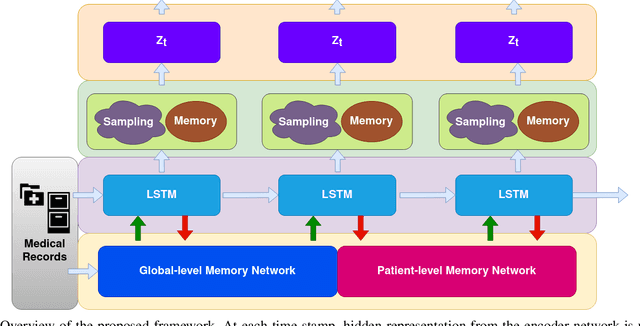
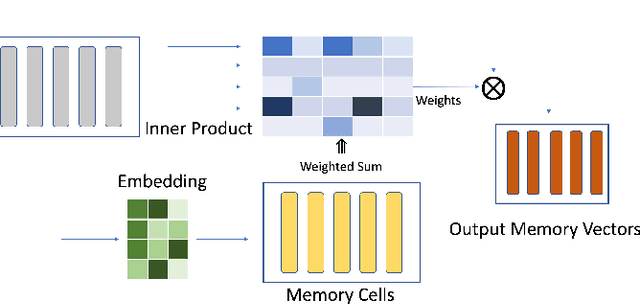
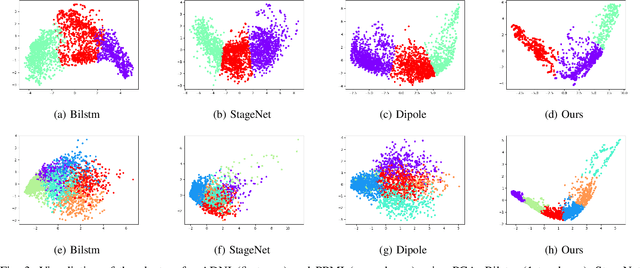
Disease progression modeling (DPM) involves using mathematical frameworks to quantitatively measure the severity of how certain disease progresses. DPM is useful in many ways such as predicting health state, categorizing disease stages, and assessing patients disease trajectory etc. Recently, with wider availability of electronic health records (EHR) and the broad application of data-driven machine learning method, DPM has attracted much attention yet remains two major challenges: (i) Due to the existence of irregularity, heterogeneity and long-term dependency in EHRs, most existing DPM methods might not be able to provide comprehensive patient representations. (ii) Lots of records in EHRs might be irrelevant to the target disease. Most existing models learn to automatically focus on the relevant information instead of explicitly capture the target-relevant events, which might make the learned model suboptimal. To address these two issues, we propose Temporal Clustering with External Memory Network (TC-EMNet) for DPM that groups patients with similar trajectories to form disease clusters/stages. TC-EMNet uses a variational autoencoder (VAE) to capture internal complexity from the input data and utilizes an external memory work to capture long term distance information, both of which are helpful for producing comprehensive patient states. Last but not least, k-means algorithm is adopted to cluster the extracted comprehensive patient states to capture disease progression. Experiments on two real-world datasets show that our model demonstrates competitive clustering performance against state-of-the-art methods and is able to identify clinically meaningful clusters. The visualization of the extracted patient states shows that the proposed model can generate better patient states than the baselines.
Information criteria for non-normalized models
May 15, 2019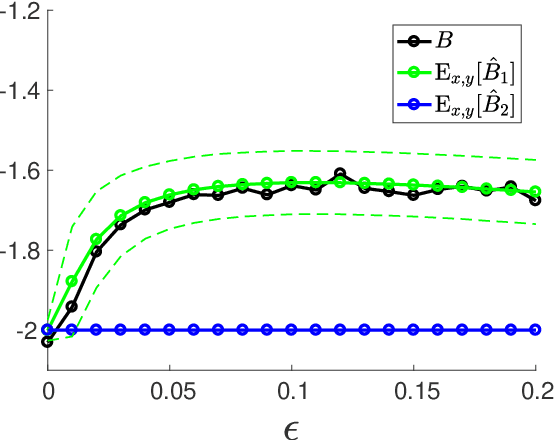

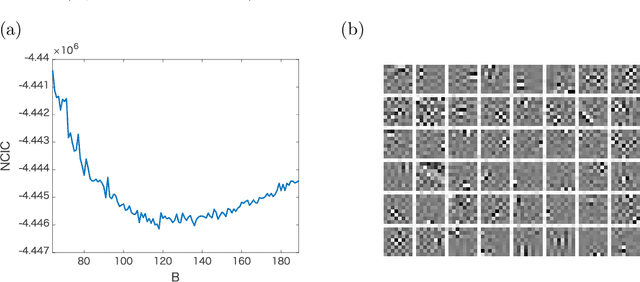
Many statistical models are given in the form of non-normalized densities with an intractable normalization constant. Since maximum likelihood estimation is computationally intensive for these models, several estimation methods have been developed which do not require explicit computation of the normalization constant, such as noise contrastive estimation (NCE) and score matching. However, model selection methods for general non-normalized models have not been proposed so far. In this study, we develop information criteria for non-normalized models estimated by NCE or score matching. They are derived as approximately unbiased estimators of discrepancy measures for non-normalized models. Experimental results demonstrate that the proposed criteria enable selection of the appropriate non-normalized model in a data-driven manner. Extension to a finite mixture of non-normalized models is also discussed.
Constrained Sparse Subspace Clustering with Side-Information
May 22, 2018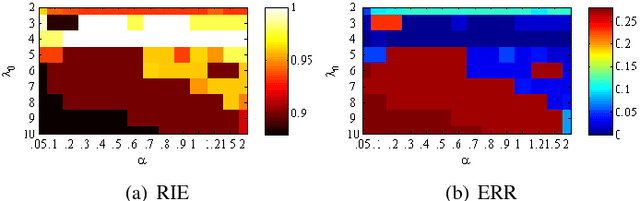
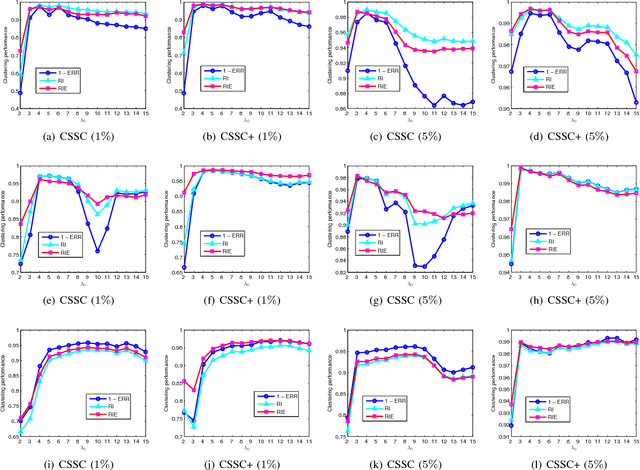

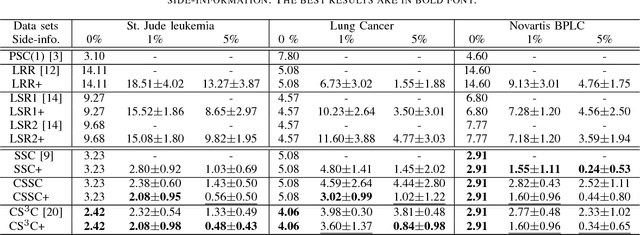
Subspace clustering refers to the problem of segmenting high dimensional data drawn from a union of subspaces into the respective subspaces. In some applications, partial side-information to indicate "must-link" or "cannot-link" in clustering is available. This leads to the task of subspace clustering with side-information. However, in prior work the supervision value of the side-information for subspace clustering has not been fully exploited. To this end, in this paper, we present an enhanced approach for constrained subspace clustering with side-information, termed Constrained Sparse Subspace Clustering plus (CSSC+), in which the side-information is used not only in the stage of learning an affinity matrix but also in the stage of spectral clustering. Moreover, we propose to estimate clustering accuracy based on the partial side-information and theoretically justify the connection to the ground-truth clustering accuracy in terms of the Rand index. We conduct experiments on three cancer gene expression datasets to validate the effectiveness of our proposals.