 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A new weakly supervised approach for ALS point cloud semantic segmentation
Oct 06, 2021
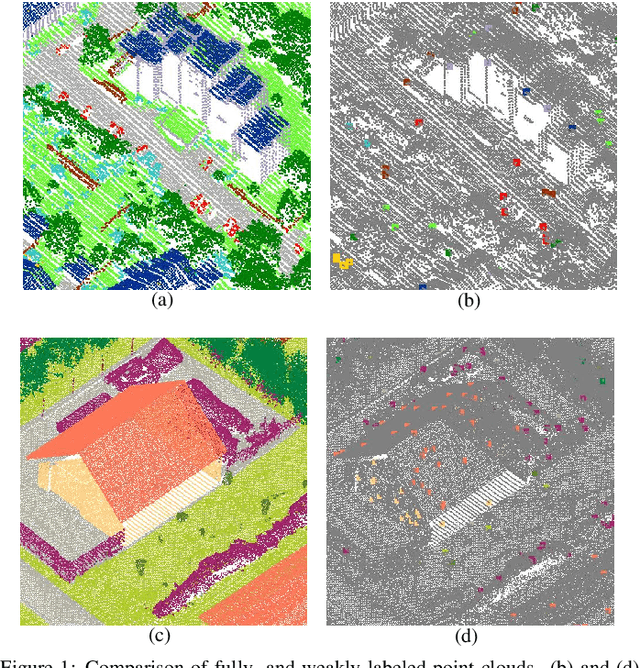
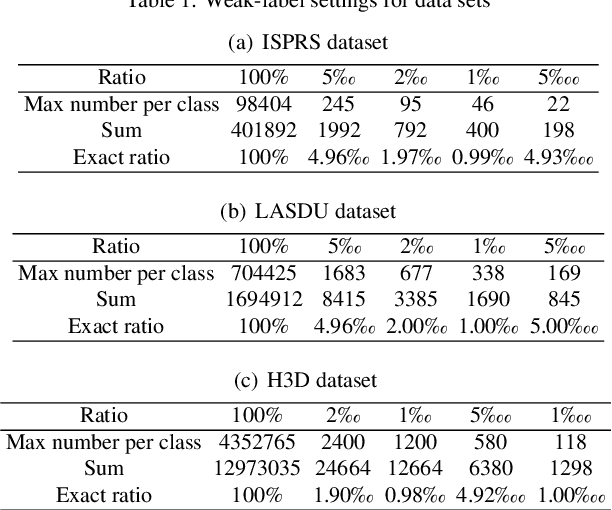
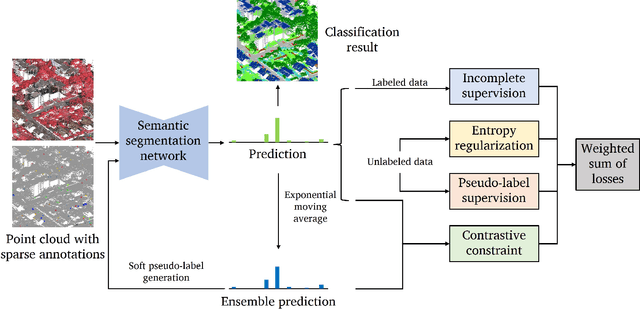
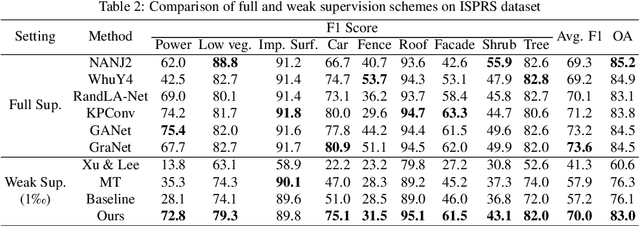
While there are novel point cloud semantic segmentation schemes that continuously surpass state-of-the-art results, the success of learning an effective model usually rely on the availability of abundant labeled data. However, data annotation is a time-consuming and labor-intensive task, particularly for large-scale airborne laser scanning (ALS) point clouds involving multiple classes in urban areas. Thus, how to attain promising results while largely reducing labeling works become an essential issue. In this study, we propose a deep-learning based weakly supervised framework for semantic segmentation of ALS point clouds, exploiting potential information from unlabeled data subject to incomplete and sparse labels. Entropy regularization is introduced to penalize the class overlap in predictive probability. Additionally, a consistency constraint by minimizing the discrepancy distance between instant and ensemble predictions is designed to improve the robustness of predictions. Finally, we propose an online soft pseudo-labeling strategy to create extra supervisory sources in an efficient and nonpaprametric way. Extensive experimental analysis using three benchmark datasets demonstrates that in case of sparse point annotations, our proposed method significantly boosts the classification performance without compromising the computational efficiency. It outperforms current weakly supervised methods and achieves a comparable result against full supervision competitors. For the ISPRS 3D Labeling Vaihingen data, by using only 0.1% of labels, our method achieves an overall accuracy of 83.0% and an average F1 score of 70.0%, which have increased by 6.9% and 12.8% respectively, compared to model trained by sparse label information only.
FIBA: Frequency-Injection based Backdoor Attack in Medical Image Analysis
Dec 02, 2021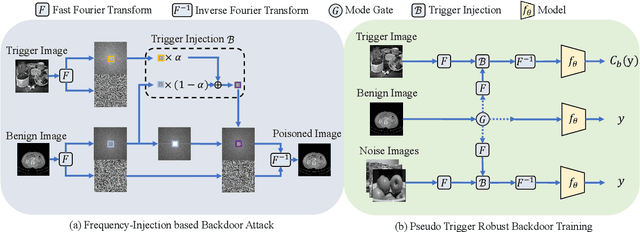
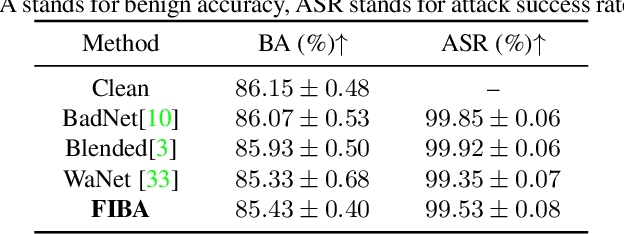
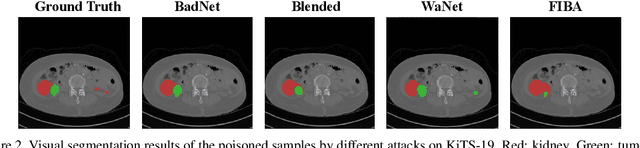

In recent years, the security of AI systems has drawn increasing research attention, especially in the medical imaging realm. To develop a secure medical image analysis (MIA) system, it is a must to study possible backdoor attacks (BAs), which can embed hidden malicious behaviors into the system. However, designing a unified BA method that can be applied to various MIA systems is challenging due to the diversity of imaging modalities (e.g., X-Ray, CT, and MRI) and analysis tasks (e.g., classification, detection, and segmentation). Most existing BA methods are designed to attack natural image classification models, which apply spatial triggers to training images and inevitably corrupt the semantics of poisoned pixels, leading to the failures of attacking dense prediction models. To address this issue, we propose a novel Frequency-Injection based Backdoor Attack method (FIBA) that is capable of delivering attacks in various MIA tasks. Specifically, FIBA leverages a trigger function in the frequency domain that can inject the low-frequency information of a trigger image into the poisoned image by linearly combining the spectral amplitude of both images. Since it preserves the semantics of the poisoned image pixels, FIBA can perform attacks on both classification and dense prediction models. Experiments on three benchmarks in MIA (i.e., ISIC-2019 for skin lesion classification, KiTS-19 for kidney tumor segmentation, and EAD-2019 for endoscopic artifact detection), validate the effectiveness of FIBA and its superiority over state-of-the-art methods in attacking MIA models as well as bypassing backdoor defense. The code will be available at https://github.com/HazardFY/FIBA.
Information criteria for non-normalized models
May 15, 2019

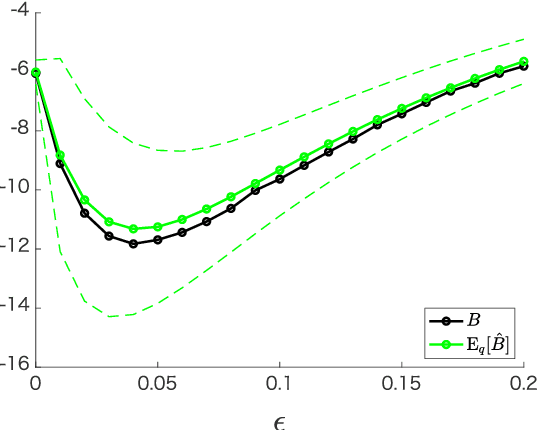
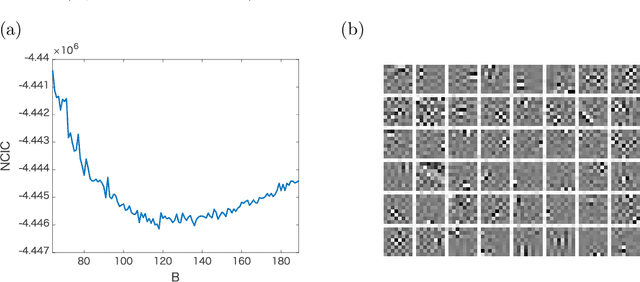
Many statistical models are given in the form of non-normalized densities with an intractable normalization constant. Since maximum likelihood estimation is computationally intensive for these models, several estimation methods have been developed which do not require explicit computation of the normalization constant, such as noise contrastive estimation (NCE) and score matching. However, model selection methods for general non-normalized models have not been proposed so far. In this study, we develop information criteria for non-normalized models estimated by NCE or score matching. They are derived as approximately unbiased estimators of discrepancy measures for non-normalized models. Experimental results demonstrate that the proposed criteria enable selection of the appropriate non-normalized model in a data-driven manner. Extension to a finite mixture of non-normalized models is also discussed.
Contrastive Adaptive Propagation Graph Neural Networks for Efficient Graph Learning
Dec 02, 2021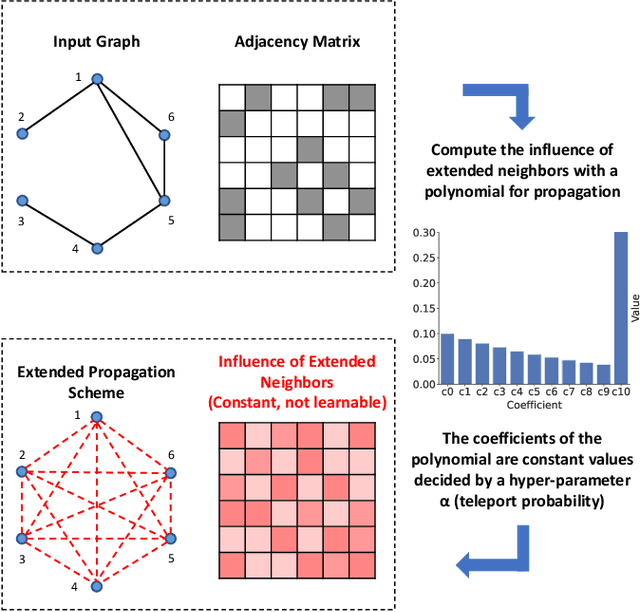
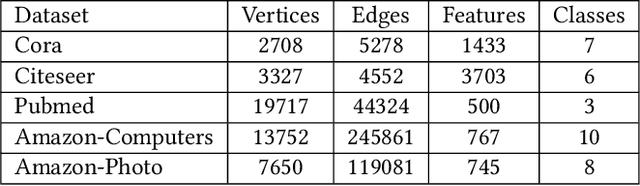
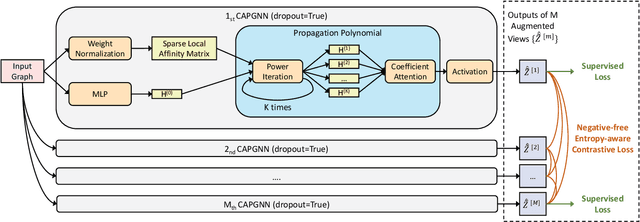

Graph Neural Networks (GNNs) have achieved great success in processing graph data by extracting and propagating structure-aware features. Existing GNN research designs various propagation schemes to guide the aggregation of neighbor information. Recently the field has advanced from local propagation schemes that focus on local neighbors towards extended propagation schemes that can directly deal with extended neighbors consisting of both local and high-order neighbors. Despite the impressive performance, existing approaches are still insufficient to build an efficient and learnable extended propagation scheme that can adaptively adjust the influence of local and high-order neighbors. This paper proposes an efficient yet effective end-to-end framework, namely Contrastive Adaptive Propagation Graph Neural Networks (CAPGNN), to address these issues by combining Personalized PageRank and attention techniques. CAPGNN models the learnable extended propagation scheme with a polynomial of a sparse local affinity matrix, where the polynomial relies on Personalized PageRank to provide superior initial coefficients. In order to adaptively adjust the influence of both local and high-order neighbors, a coefficient-attention model is introduced to learn to adjust the coefficients of the polynomial. In addition, we leverage self-supervised learning techniques and design a negative-free entropy-aware contrastive loss to explicitly take advantage of unlabeled data for training. We implement CAPGNN as two different versions named CAPGCN and CAPGAT, which use static and dynamic sparse local affinity matrices, respectively. Experiments on graph benchmark datasets suggest that CAPGNN can consistently outperform or match state-of-the-art baselines. The source code is publicly available at https://github.com/hujunxianligong/CAPGNN.
A Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021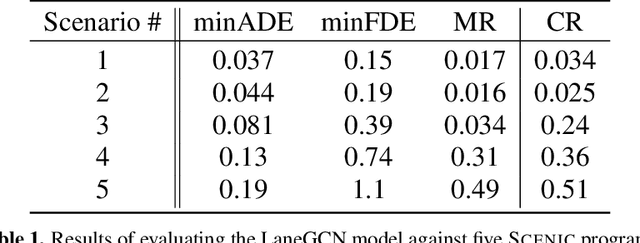

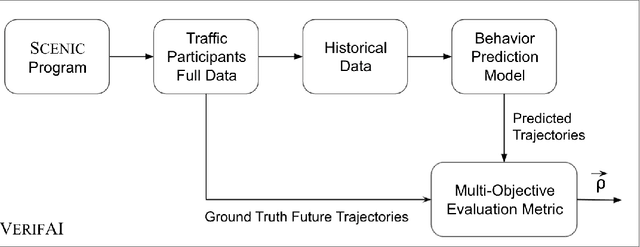
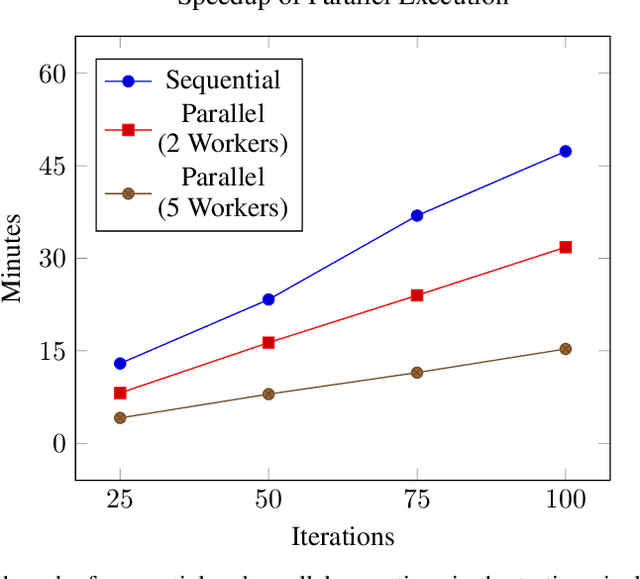
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
Illumination and Temperature-Aware Multispectral Networks for Edge-Computing-Enabled Pedestrian Detection
Dec 09, 2021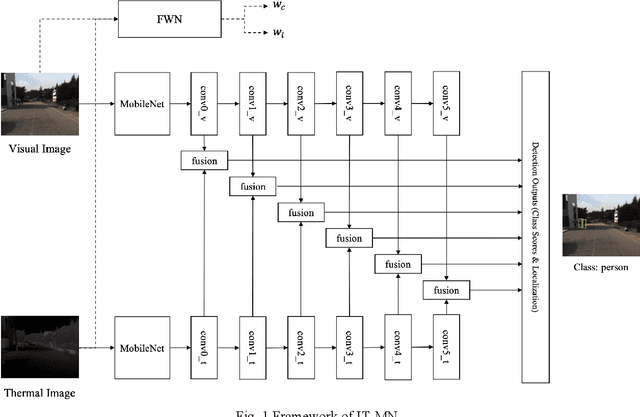
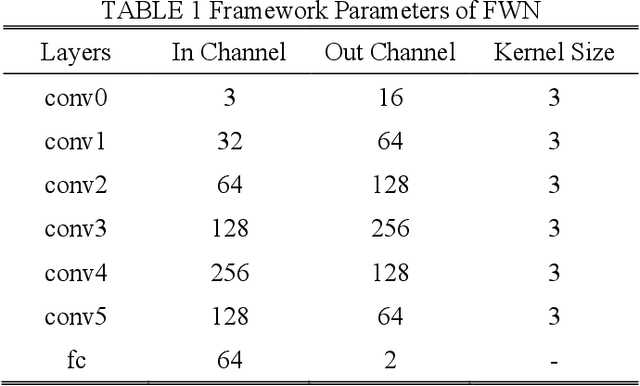
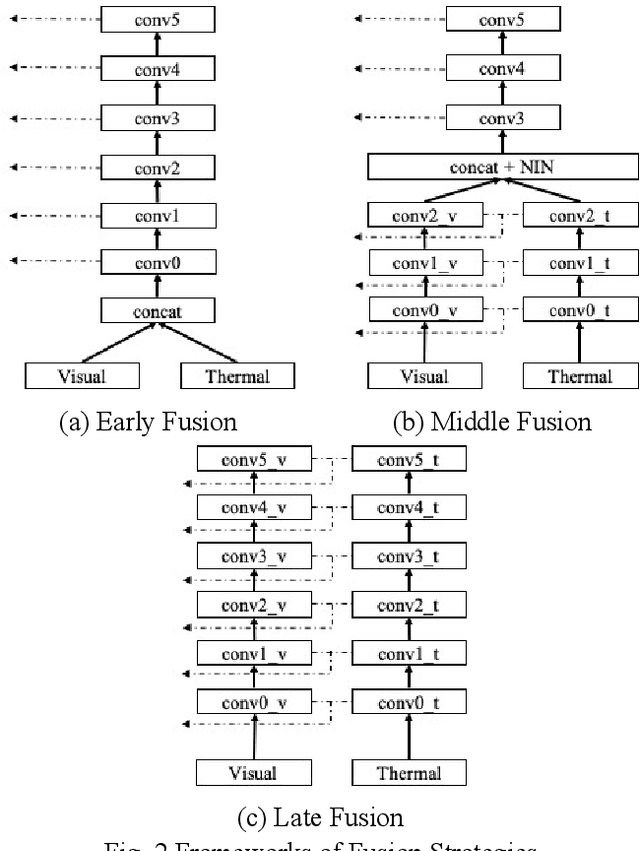
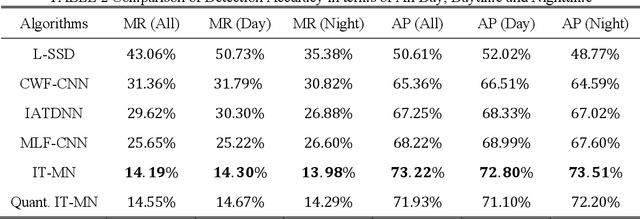
Accurate and efficient pedestrian detection is crucial for the intelligent transportation system regarding pedestrian safety and mobility, e.g., Advanced Driver Assistance Systems, and smart pedestrian crosswalk systems. Among all pedestrian detection methods, vision-based detection method is demonstrated to be the most effective in previous studies. However, the existing vision-based pedestrian detection algorithms still have two limitations that restrict their implementations, those being real-time performance as well as the resistance to the impacts of environmental factors, e.g., low illumination conditions. To address these issues, this study proposes a lightweight Illumination and Temperature-aware Multispectral Network (IT-MN) for accurate and efficient pedestrian detection. The proposed IT-MN is an efficient one-stage detector. For accommodating the impacts of environmental factors and enhancing the sensing accuracy, thermal image data is fused by the proposed IT-MN with visual images to enrich useful information when visual image quality is limited. In addition, an innovative and effective late fusion strategy is also developed to optimize the image fusion performance. To make the proposed model implementable for edge computing, the model quantization is applied to reduce the model size by 75% while shortening the inference time significantly. The proposed algorithm is evaluated by comparing with the selected state-of-the-art algorithms using a public dataset collected by in-vehicle cameras. The results show that the proposed algorithm achieves a low miss rate and inference time at 14.19% and 0.03 seconds per image pair on GPU. Besides, the quantized IT-MN achieves an inference time of 0.21 seconds per image pair on the edge device, which also demonstrates the potentiality of deploying the proposed model on edge devices as a highly efficient pedestrian detection algorithm.
A Light-weight contextual spelling correction model for customizing transducer-based speech recognition systems
Aug 17, 2021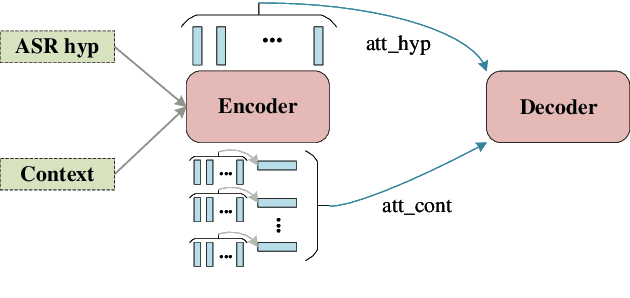


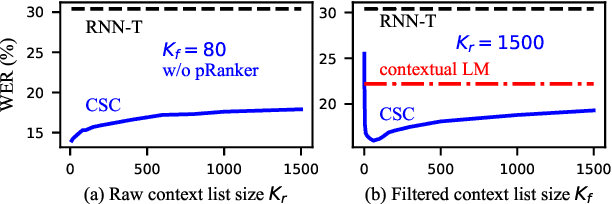
It's challenging to customize transducer-based automatic speech recognition (ASR) system with context information which is dynamic and unavailable during model training. In this work, we introduce a light-weight contextual spelling correction model to correct context-related recognition errors in transducer-based ASR systems. We incorporate the context information into the spelling correction model with a shared context encoder and use a filtering algorithm to handle large-size context lists. Experiments show that the model improves baseline ASR model performance with about 50% relative word error rate reduction, which also significantly outperforms the baseline method such as contextual LM biasing. The model also shows excellent performance for out-of-vocabulary terms not seen during training.
Gaussian Mean Field Regularizes by Limiting Learned Information
Feb 12, 2019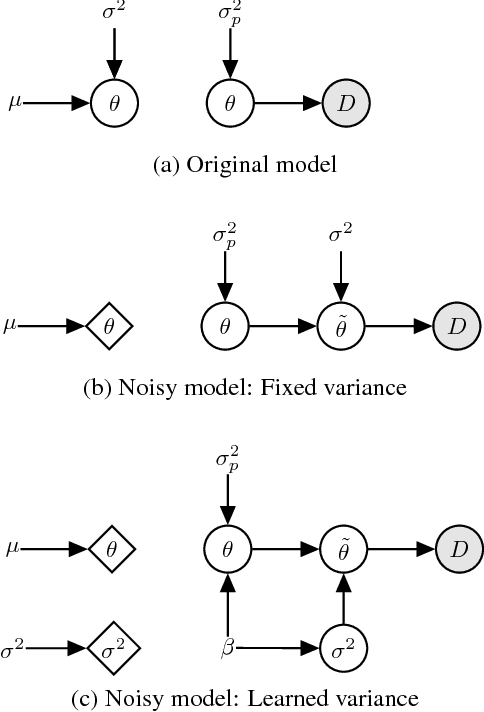
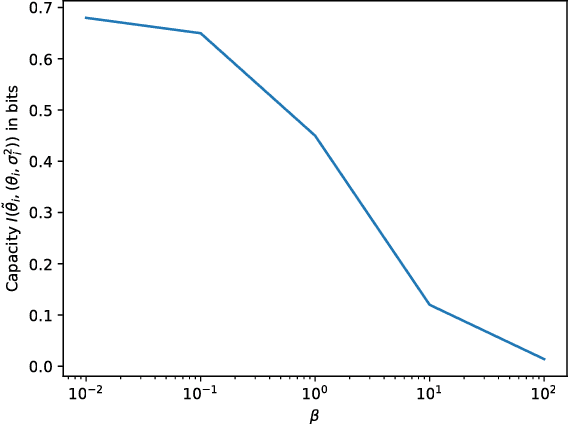
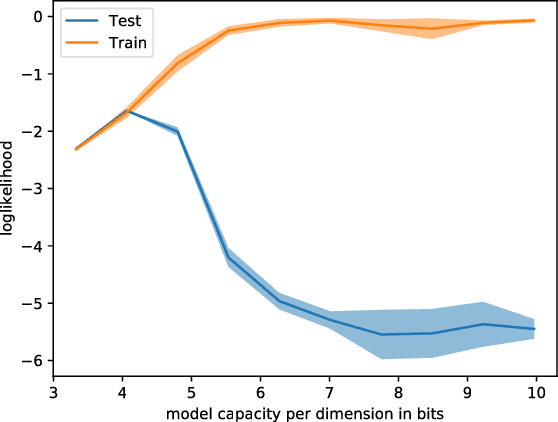
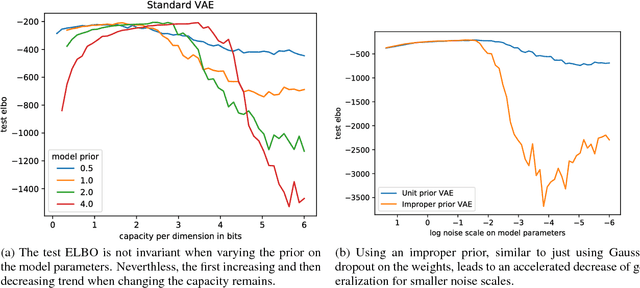
Variational inference with a factorized Gaussian posterior estimate is a widely used approach for learning parameters and hidden variables. Empirically, a regularizing effect can be observed that is poorly understood. In this work, we show how mean field inference improves generalization by limiting mutual information between learned parameters and the data through noise. We quantify a maximum capacity when the posterior variance is either fixed or learned and connect it to generalization error, even when the KL-divergence in the objective is rescaled. Our experiments demonstrate that bounding information between parameters and data effectively regularizes neural networks on both supervised and unsupervised tasks.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021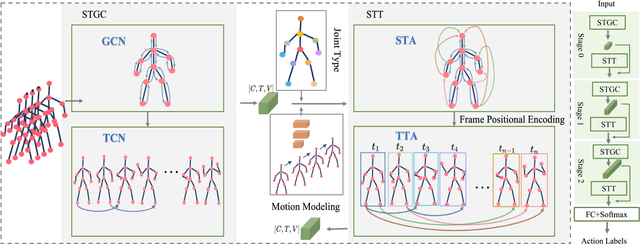
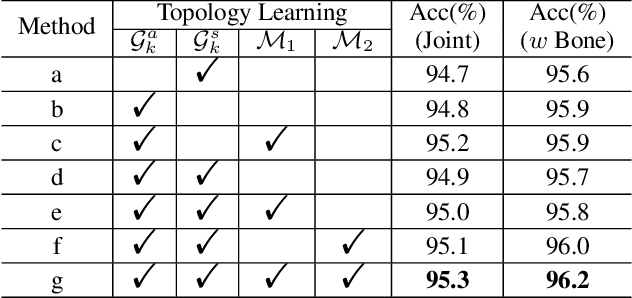
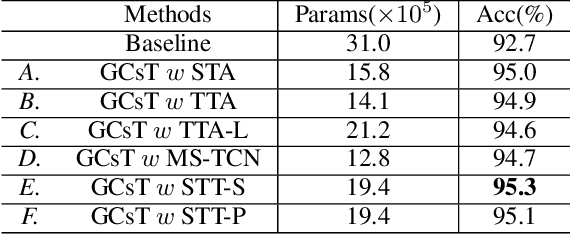
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.
Open-domain clarification question generation without question examples
Oct 19, 2021
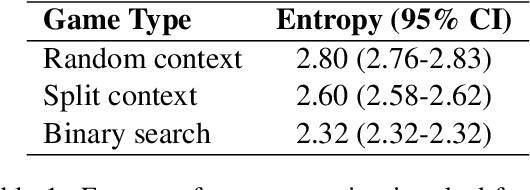
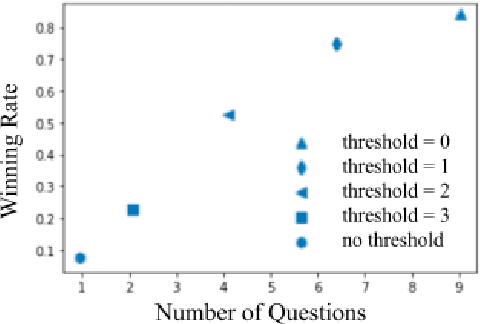

An overarching goal of natural language processing is to enable machines to communicate seamlessly with humans. However, natural language can be ambiguous or unclear. In cases of uncertainty, humans engage in an interactive process known as repair: asking questions and seeking clarification until their uncertainty is resolved. We propose a framework for building a visually grounded question-asking model capable of producing polar (yes-no) clarification questions to resolve misunderstandings in dialogue. Our model uses an expected information gain objective to derive informative questions from an off-the-shelf image captioner without requiring any supervised question-answer data. We demonstrate our model's ability to pose questions that improve communicative success in a goal-oriented 20 questions game with synthetic and human answerers.