 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021
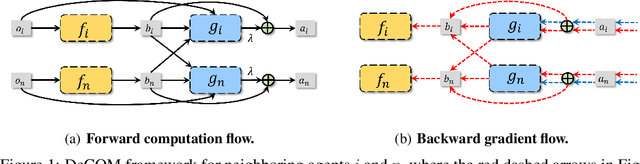

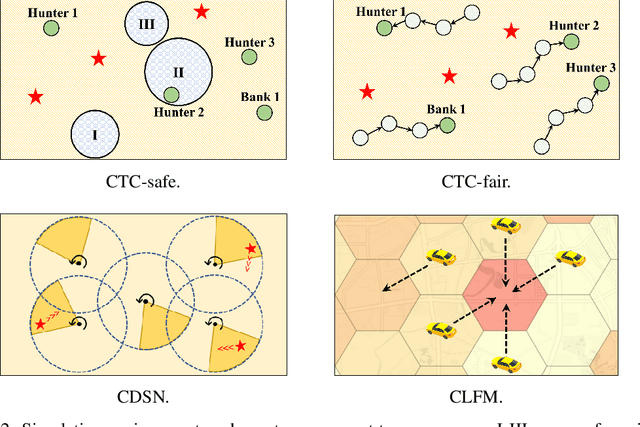
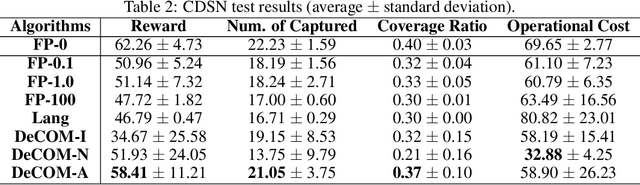
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.
Adaptive Time-Channel Beamforming for Time-of-Flight Correction
Oct 17, 2021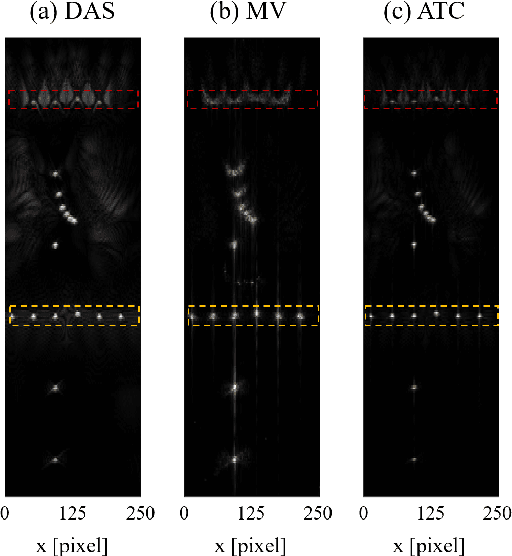
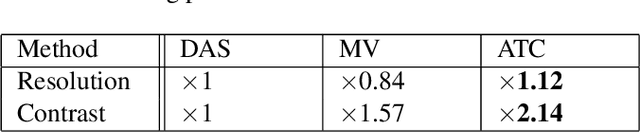
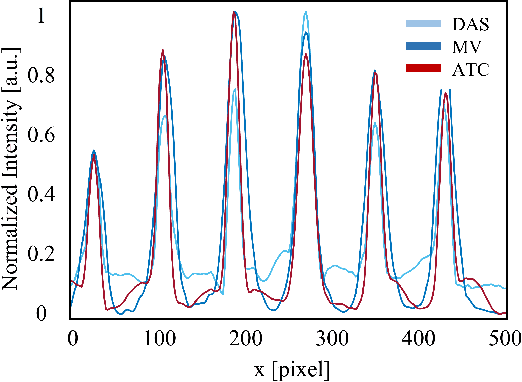
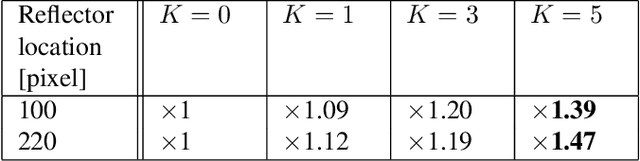
Adaptive beamforming can lead to substantial improvement in resolution and contrast of ultrasound images over standard delay and sum beamforming. Here we introduce the adaptive time-channel (ATC) beamformer, a data-driven approach that combines spatial and temporal information simultaneously, thus generalizing minimum variance beamformers. Moreover, we broaden the concept of apodization to the temporal dimension. Our approach reduces noises by allowing for the weights to adapt in both the temporal and spatial dimensions, thereby reducing artifacts caused by the media's inhomogeneities. We apply our method to in-silico data and show 12% resolution enhancement along with 2-fold contrast improvement, and significant noise reduction with respect to delay and sum and minimum variance beamformers.
Information Seeking in the Spirit of Learning: a Dataset for Conversational Curiosity
May 01, 2020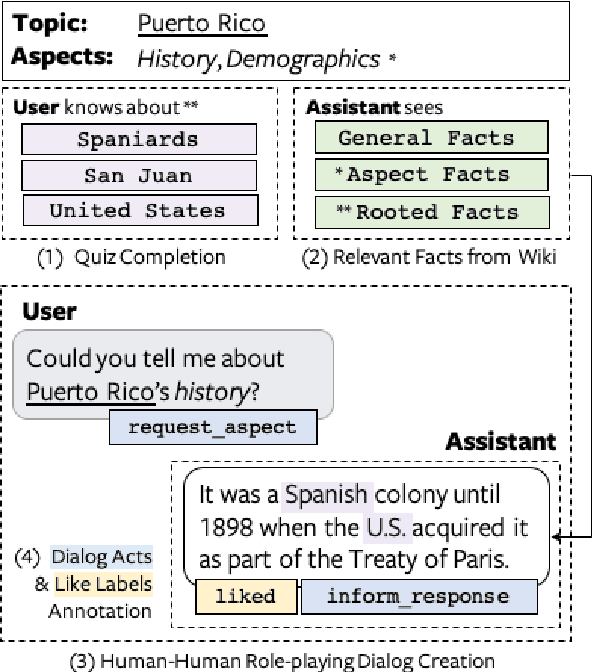
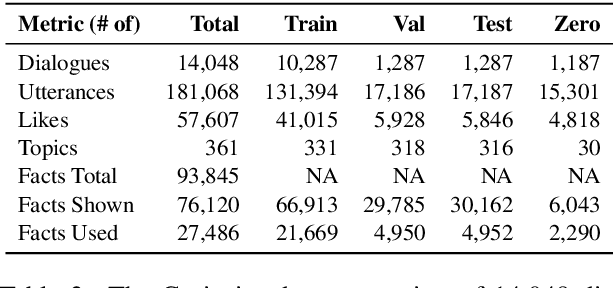
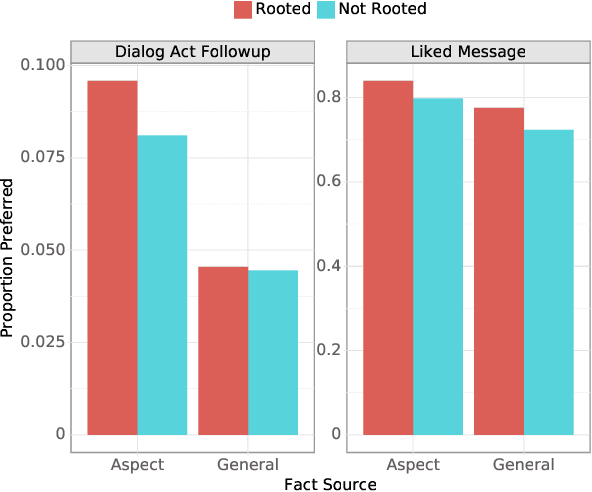
Open-ended human learning and information-seeking are increasingly mediated by technologies like digital assistants. However, such systems often fail to account for the user's pre-existing knowledge, which is a powerful way to increase engagement and to improve retention. Assuming a correlation between engagement and user responses such as "liking" messages or asking followup questions, we design a Wizard of Oz dialog task that tests the hypothesis that engagement increases when users are presented with facts that relate to their existing knowledge. Through crowd-sourcing of this experimental task we collected and now open-source 14K dialogs (181K utterances) where users and assistants converse about various aspects related to geographic entities. This dataset is annotated with pre-existing user knowledge, message-level dialog acts, message grounding to Wikipedia, user reactions to messages, and per-dialog ratings. Our analysis shows that responses which incorporate a user's prior knowledge do increase engagement. We incorporate this knowledge into a state-of-the-art multi-task model that reproduces human assistant policies, improving over content selection baselines by 13 points.
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Mar 27, 2019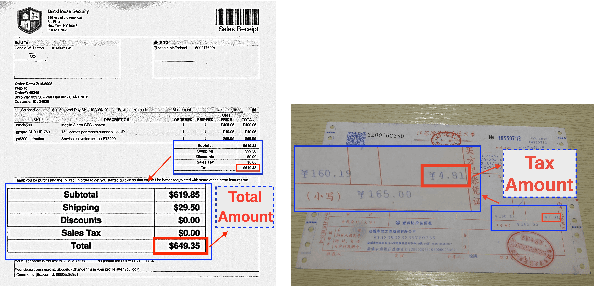
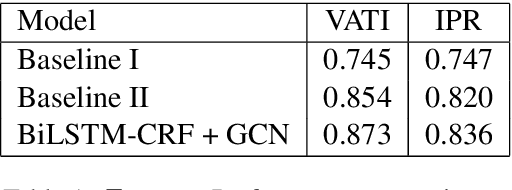
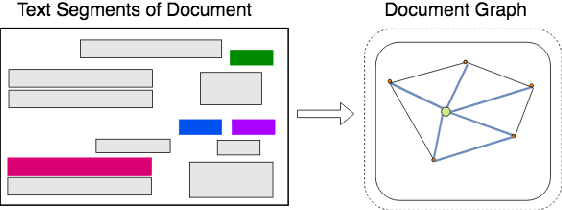
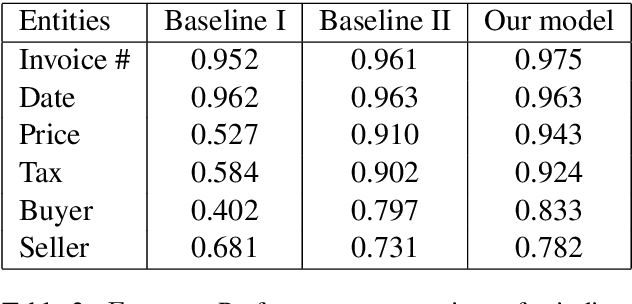
Visually rich documents (VRDs) are ubiquitous in daily business and life. Examples are purchase receipts, insurance policy documents, custom declaration forms and so on. In VRDs, visual and layout information is critical for document understanding, and texts in such documents cannot be serialized into the one-dimensional sequence without losing information. Classic information extraction models such as BiLSTM-CRF typically operate on text sequences and do not incorporate visual features. In this paper, we introduce a graph convolution based model to combine textual and visual information presented in VRDs. Graph embeddings are trained to summarize the context of a text segment in the document, and further combined with text embeddings for entity extraction. Extensive experiments have been conducted to show that our method outperforms BiLSTM-CRF baselines by significant margins, on two real-world datasets. Additionally, ablation studies are also performed to evaluate the effectiveness of each component of our model.
Contextual Information Enhanced Convolutional Neural Networks for Retinal Vessel Segmentation in Color Fundus Images
Mar 25, 2021

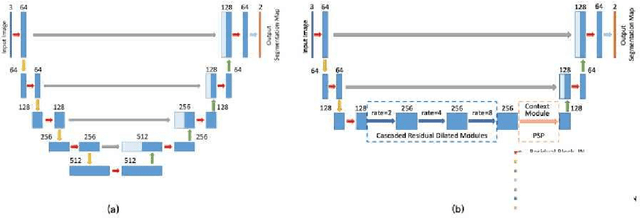
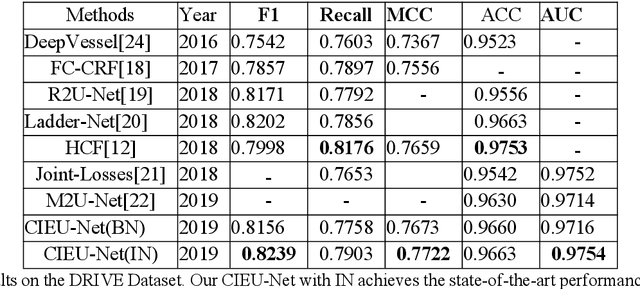
Accurate retinal vessel segmentation is a challenging problem in color fundus image analysis. An automatic retinal vessel segmentation system can effectively facilitate clinical diagnosis and ophthalmological research. Technically, this problem suffers from various degrees of vessel thickness, perception of details, and contextual feature fusion. For addressing these challenges, a deep learning based method has been proposed and several customized modules have been integrated into the well-known encoder-decoder architecture U-net, which is mainly employed in medical image segmentation. Structurally, cascaded dilated convolutional modules have been integrated into the intermediate layers, for obtaining larger receptive field and generating denser encoded feature maps. Also, the advantages of the pyramid module with spatial continuity have been taken, for multi-thickness perception, detail refinement, and contextual feature fusion. Additionally, the effectiveness of different normalization approaches has been discussed in network training for different datasets with specific properties. Experimentally, sufficient comparative experiments have been enforced on three retinal vessel segmentation datasets, DRIVE, CHASEDB1, and the unhealthy dataset STARE. As a result, the proposed method outperforms the work of predecessors and achieves state-of-the-art performance in Sensitivity/Recall, F1-score and MCC.
Detecting Potentially Harmful and Protective Suicide-related Content on Twitter: A Machine Learning Approach
Dec 11, 2021
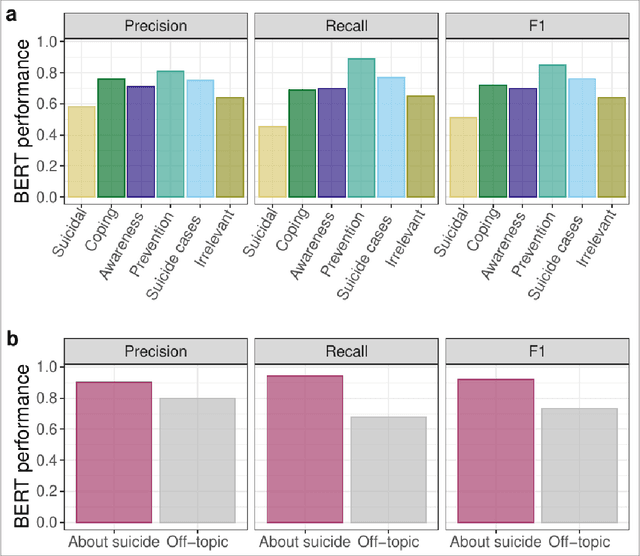
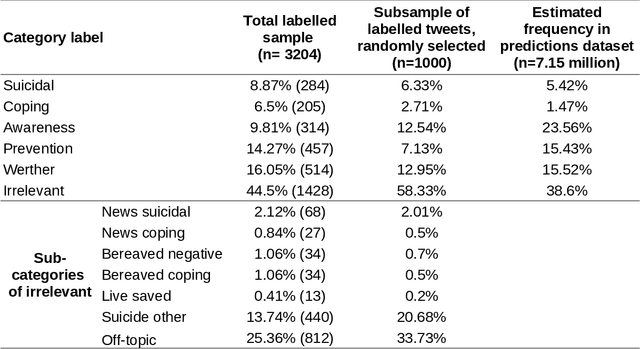
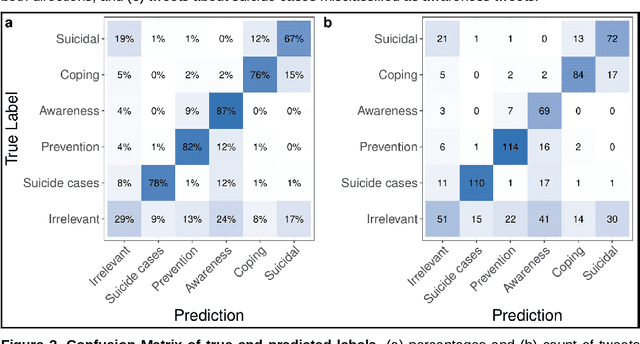
Research shows that exposure to suicide-related news media content is associated with suicide rates, with some content characteristics likely having harmful and others potentially protective effects. Although good evidence exists for a few selected characteristics, systematic large scale investigations are missing in general, and in particular for social media data. We apply machine learning methods to automatically label large quantities of Twitter data. We developed a novel annotation scheme that classifies suicide-related tweets into different message types and problem- vs. solution-focused perspectives. We then trained a benchmark of machine learning models including a majority classifier, an approach based on word frequency (TF-IDF with a linear SVM) and two state-of-the-art deep learning models (BERT, XLNet). The two deep learning models achieved the best performance in two classification tasks: First, we classified six main content categories, including personal stories about either suicidal ideation and attempts or coping, calls for action intending to spread either problem awareness or prevention-related information, reportings of suicide cases, and other suicide-related and off-topic tweets. The deep learning models reach accuracy scores above 73% on average across the six categories, and F1-scores in between 69% and 85% for all but the suicidal ideation and attempts category (55%). Second, in separating postings referring to actual suicide from off-topic tweets, they correctly labelled around 88% of tweets, with BERT achieving F1-scores of 93% and 74% for the two categories. These classification performances are comparable to the state-of-the-art on similar tasks. By making data labeling more efficient, this work enables future large-scale investigations on harmful and protective effects of various kinds of social media content on suicide rates and on help-seeking behavior.
Gradient Inversion Attack: Leaking Private Labels in Two-Party Split Learning
Nov 25, 2021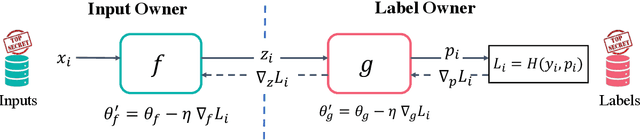
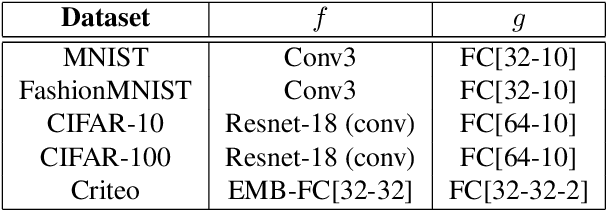
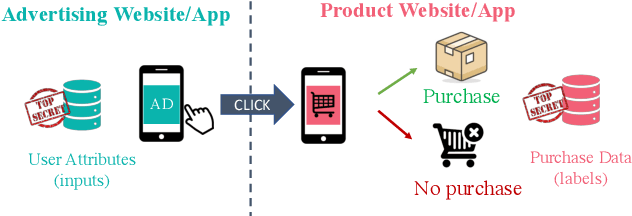
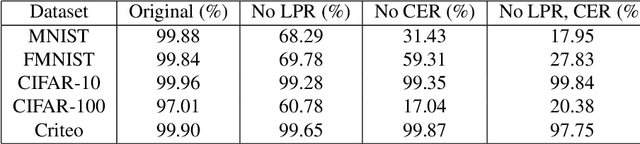
Split learning is a popular technique used to perform vertical federated learning, where the goal is to jointly train a model on the private input and label data held by two parties. To preserve privacy of the input and label data, this technique uses a split model and only requires the exchange of intermediate representations (IR) of the inputs and gradients of the IR between the two parties during the learning process. In this paper, we propose Gradient Inversion Attack (GIA), a label leakage attack that allows an adversarial input owner to learn the label owner's private labels by exploiting the gradient information obtained during split learning. GIA frames the label leakage attack as a supervised learning problem by developing a novel loss function using certain key properties of the dataset and models. Our attack can uncover the private label data on several multi-class image classification problems and a binary conversion prediction task with near-perfect accuracy (97.01% - 99.96%), demonstrating that split learning provides negligible privacy benefits to the label owner. Furthermore, we evaluate the use of gradient noise to defend against GIA. While this technique is effective for simpler datasets, it significantly degrades utility for datasets with higher input dimensionality. Our findings underscore the need for better privacy-preserving training techniques for vertically split data.
SPDCinv: Inverse Quantum-Optical Design of High-Dimensional Qudits
Dec 11, 2021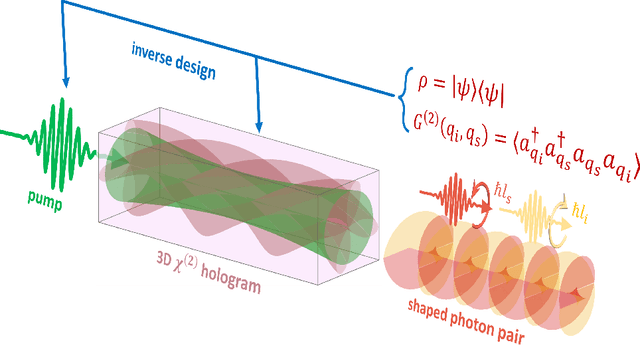
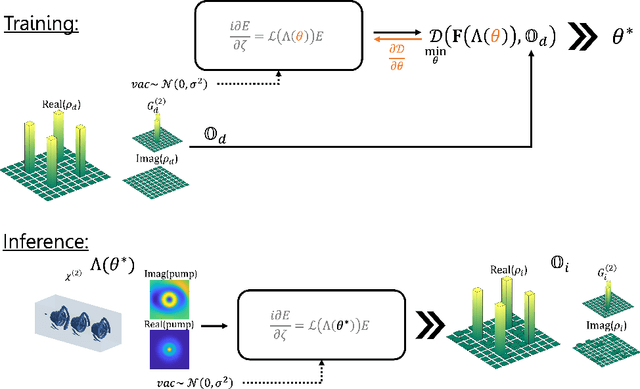
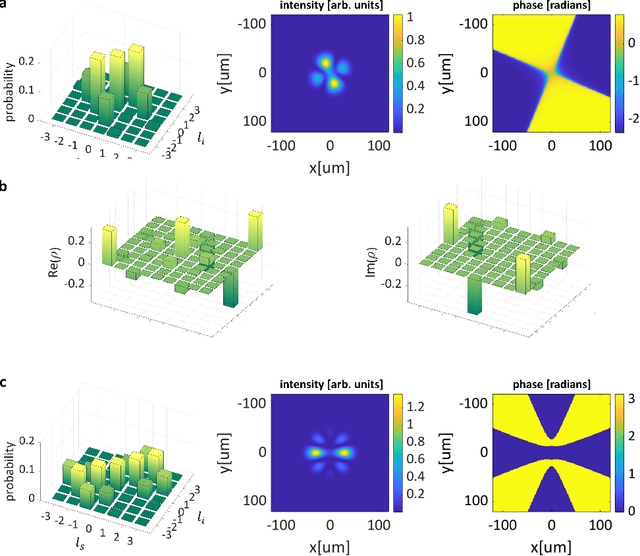
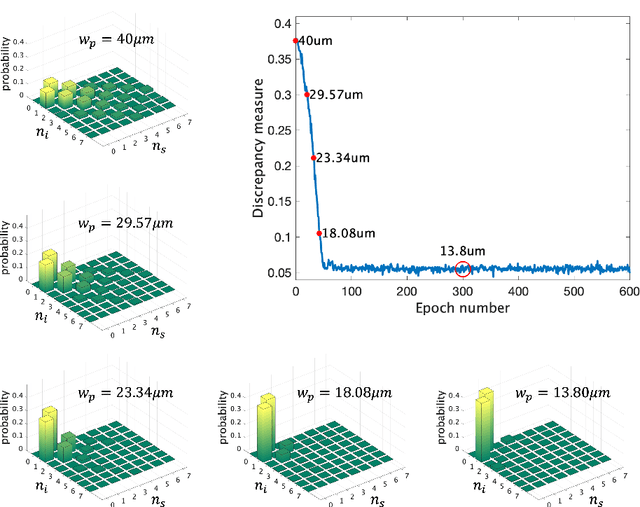
Spontaneous parametric down-conversion in quantum optics is an invaluable resource for the realization of high-dimensional qudits with spatial modes of light. One of the main open challenges is how to directly generate a desirable qudit state in the SPDC process. This problem can be addressed through advanced computational learning methods; however, due to difficulties in modeling the SPDC process by a fully differentiable algorithm that takes into account all interaction effects, progress has been limited. Here, we overcome these limitations and introduce a physically-constrained and differentiable model, validated against experimental results for shaped pump beams and structured crystals, capable of learning every interaction parameter in the process. We avoid any restrictions induced by the stochastic nature of our physical model and integrate the dynamic equations governing the evolution under the SPDC Hamiltonian. We solve the inverse problem of designing a nonlinear quantum optical system that achieves the desired quantum state of down-converted photon pairs. The desired states are defined using either the second-order correlations between different spatial modes or by specifying the required density matrix. By learning nonlinear volume holograms as well as different pump shapes, we successfully show how to generate maximally entangled states. Furthermore, we simulate all-optical coherent control over the generated quantum state by actively changing the profile of the pump beam. Our work can be useful for applications such as novel designs of high-dimensional quantum key distribution and quantum information processing protocols. In addition, our method can be readily applied for controlling other degrees of freedom of light in the SPDC process, such as the spectral and temporal properties, and may even be used in condensed-matter systems having a similar interaction Hamiltonian.
WaveCorr: Correlation-savvy Deep Reinforcement Learning for Portfolio Management
Sep 28, 2021

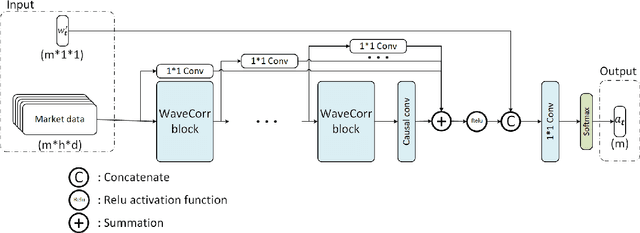
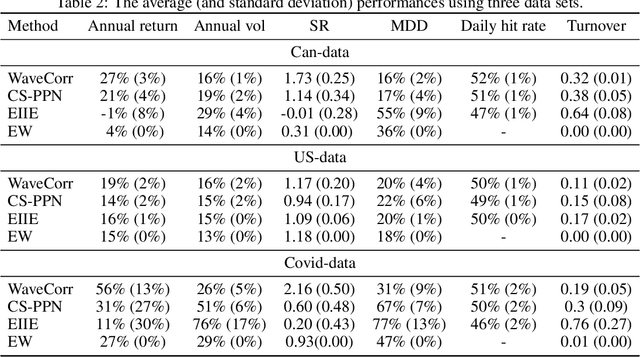
The problem of portfolio management represents an important and challenging class of dynamic decision making problems, where rebalancing decisions need to be made over time with the consideration of many factors such as investors preferences, trading environments, and market conditions. In this paper, we present a new portfolio policy network architecture for deep reinforcement learning (DRL)that can exploit more effectively cross-asset dependency information and achieve better performance than state-of-the-art architectures. In particular, we introduce a new property, referred to as \textit{asset permutation invariance}, for portfolio policy networks that exploit multi-asset time series data, and design the first portfolio policy network, named WaveCorr, that preserves this invariance property when treating asset correlation information. At the core of our design is an innovative permutation invariant correlation processing layer. An extensive set of experiments are conducted using data from both Canadian (TSX) and American stock markets (S&P 500), and WaveCorr consistently outperforms other architectures with an impressive 3%-25% absolute improvement in terms of average annual return, and up to more than 200% relative improvement in average Sharpe ratio. We also measured an improvement of a factor of up to 5 in the stability of performance under random choices of initial asset ordering and weights. The stability of the network has been found as particularly valuable by our industrial partner.
MARViN -- Multiple Arithmetic Resolutions Vacillating in Neural Networks
Aug 09, 2021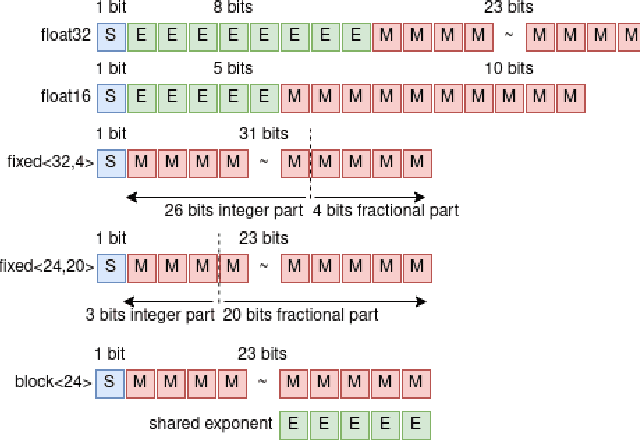
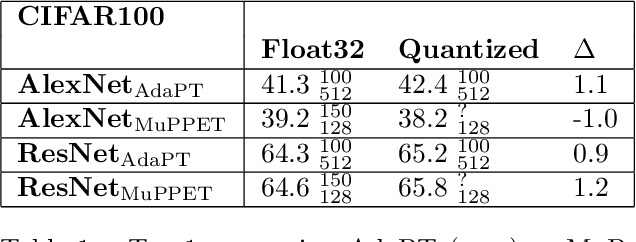

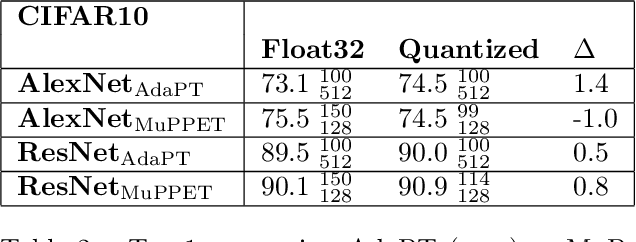
Quantization is a technique for reducing deep neural networks (DNNs) training and inference times, which is crucial for training in resource constrained environments or time critical inference applications. State-of-the-art (SOTA) quantization approaches focus on post-training quantization, i.e. quantization of pre-trained DNNs for speeding up inference. Very little work on quantized training exists, which neither al-lows dynamic intra-epoch precision switches nor em-ploys an information theory based switching heuristic. Usually, existing approaches require full precision refinement afterwards and enforce a global word length across the whole DNN. This leads to suboptimal quantization mappings and resource usage. Recognizing these limits, we introduce MARViN, a new quantized training strategy using information theory-based intra-epoch precision switching, which decides on a per-layer basis which precision should be used in order to minimize quantization-induced information loss. Note that any quantization must leave enough precision such that future learning steps do not suffer from vanishing gradients. We achieve an average speedup of 1.86 compared to a float32 basis while limiting mean accuracy degradation on AlexNet/ResNet to only -0.075%.