 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pansharpening by convolutional neural networks in the full resolution framework
Nov 16, 2021
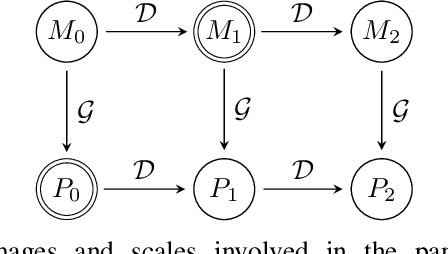
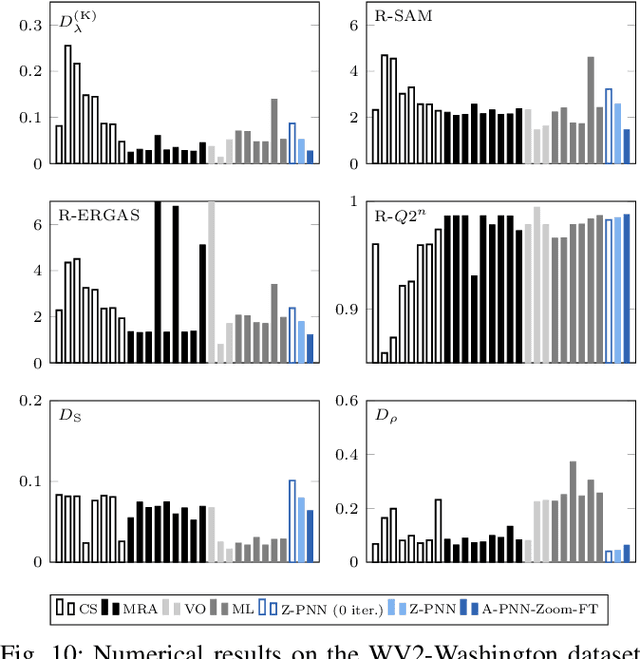
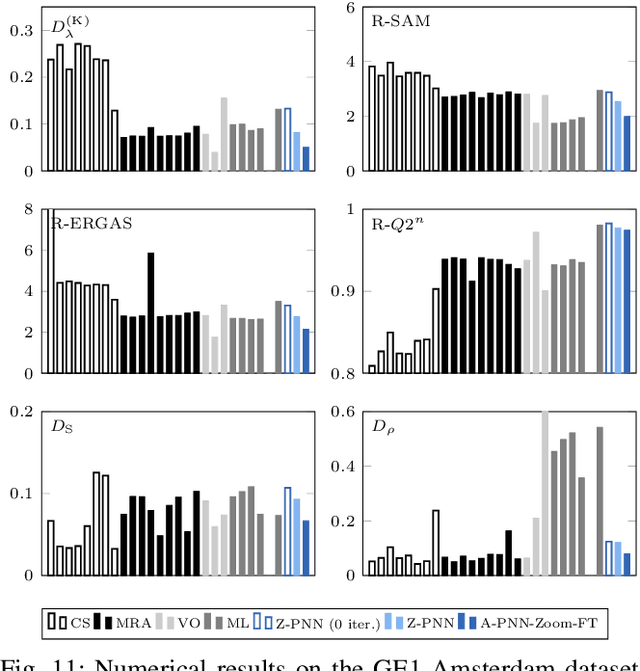

In recent years, there has been a growing interest on deep learning-based pansharpening. Research has mainly focused on architectures. However, lacking a ground truth, model training is also a major issue. A popular approach is to train networks in a reduced resolution domain, using the original data as ground truths. The trained networks are then used on full resolution data, relying on an implicit scale invariance hypothesis. Results are generally good at reduced resolution, but more questionable at full resolution. Here, we propose a full-resolution training framework for deep learning-based pansharpening. Training takes place in the high resolution domain, relying only on the original data, with no loss of information. To ensure spectral and spatial fidelity, suitable losses are defined, which force the pansharpened output to be consistent with the available panchromatic and multispectral input. Experiments carried out on WorldView-3, WorldView-2, and GeoEye-1 images show that methods trained with the proposed framework guarantee an excellent performance in terms of both full-resolution numerical indexes and visual quality. The framework is fully general, and can be used to train and fine-tune any deep learning-based pansharpening network.
Towards Integrative Multi-Modal Personal Health Navigation Systems: Framework and Application
Nov 16, 2021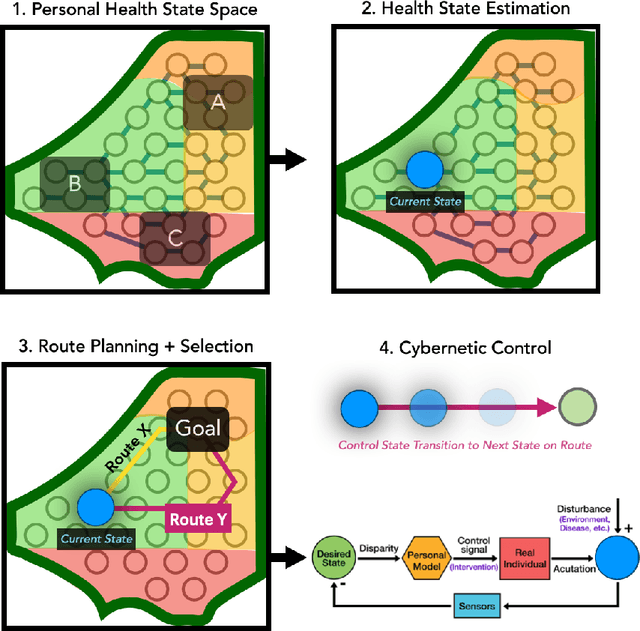
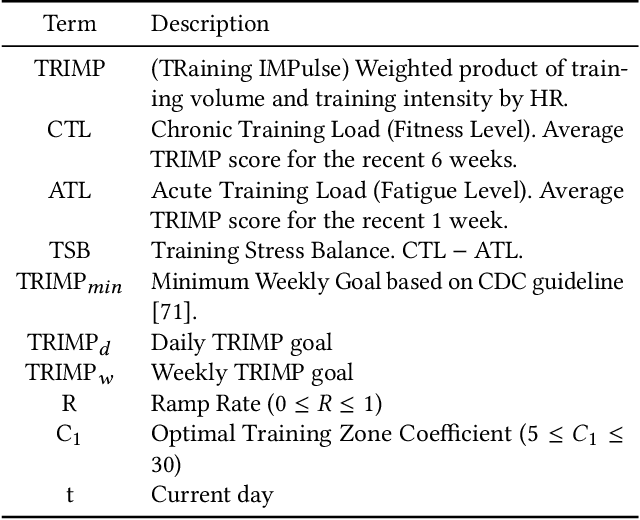
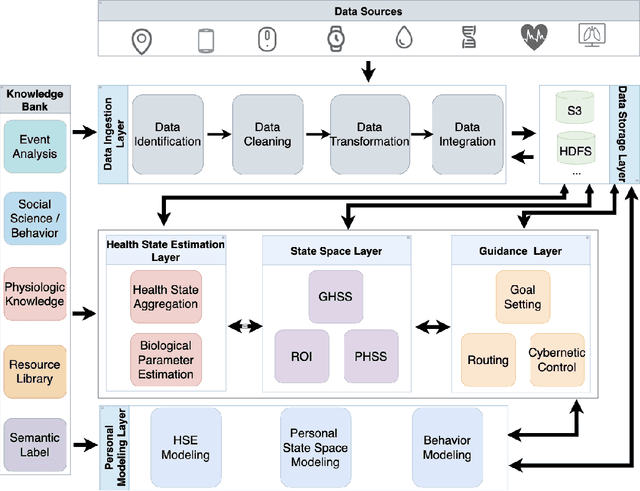
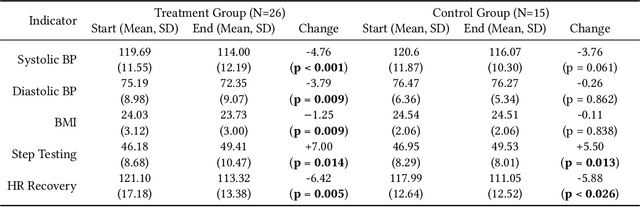
It is well understood that an individual's health trajectory is influenced by choices made in each moment, such as from lifestyle or medical decisions. With the advent of modern sensing technologies, individuals have more data and information about themselves than any other time in history. How can we use this data to make the best decisions to keep the health state optimal? We propose a generalized Personal Health Navigation (PHN) framework. PHN takes individuals towards their personal health goals through a system which perpetually digests data streams, estimates current health status, computes the best route through intermediate states utilizing personal models, and guides the best inputs that carry a user towards their goal. In addition to describing the general framework, we test the PHN system in two experiments within the field of cardiology. First, we prospectively test a knowledge-infused cardiovascular PHN system with a pilot clinical trial of 41 users. Second, we build a data-driven personalized model on cardiovascular exercise response variability on a smartwatch data-set of 33,269 real-world users. We conclude with critical challenges in health computing for PHN systems that require deep future investigation.
Learning Personal Food Preferences via Food Logs Embedding
Oct 29, 2021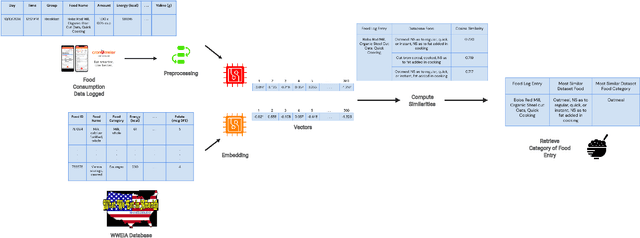
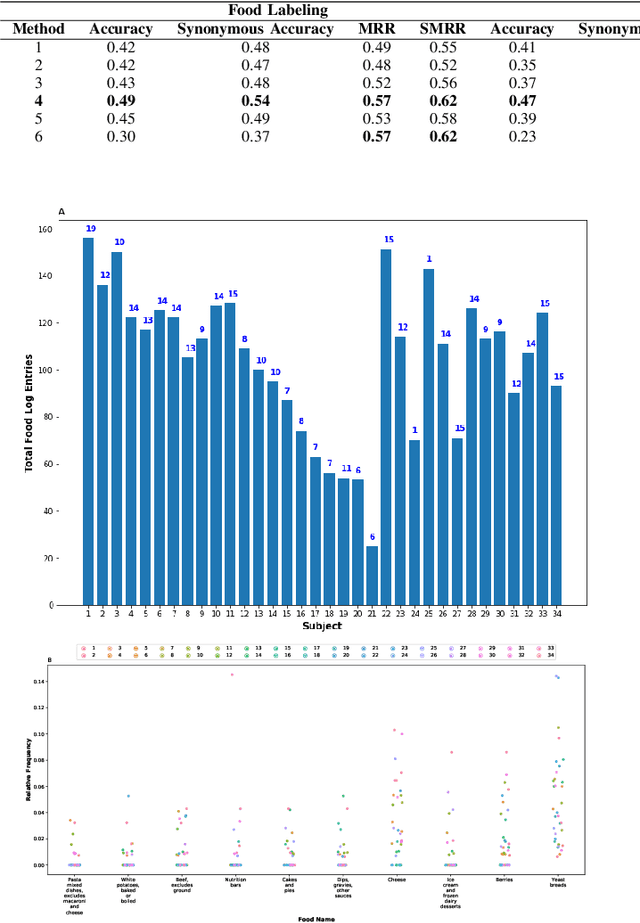

Diet management is key to managing chronic diseases such as diabetes. Automated food recommender systems may be able to assist by providing meal recommendations that conform to a user's nutrition goals and food preferences. Current recommendation systems suffer from a lack of accuracy that is in part due to a lack of knowledge of food preferences, namely foods users like to and are able to eat frequently. In this work, we propose a method for learning food preferences from food logs, a comprehensive but noisy source of information about users' dietary habits. We also introduce accompanying metrics. The method generates and compares word embeddings to identify the parent food category of each food entry and then calculates the most popular. Our proposed approach identifies 82% of a user's ten most frequently eaten foods. Our method is publicly available on (https://github.com/aametwally/LearningFoodPreferences)
Multimodal End-to-End Group Emotion Recognition using Cross-Modal Attention
Nov 10, 2021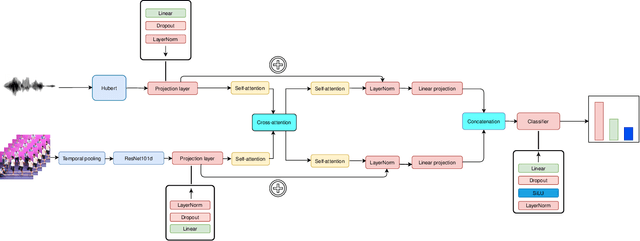
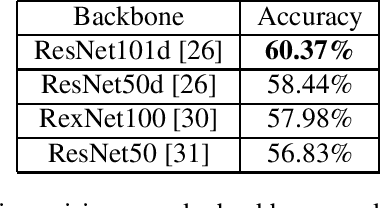
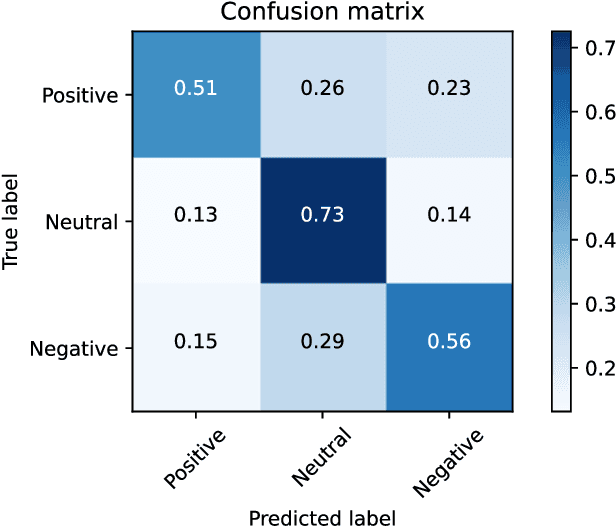
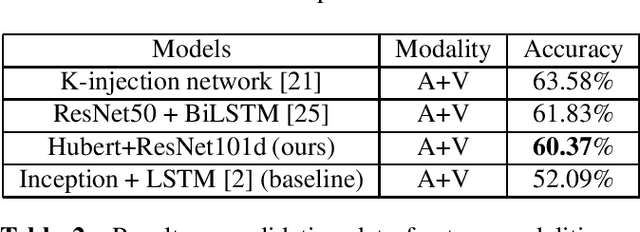
Classifying group-level emotions is a challenging task due to complexity of video, in which not only visual, but also audio information should be taken into consideration. Existing works on multimodal emotion recognition are using bulky approach, where pretrained neural networks are used as a feature extractors and then extracted features are being fused. However, this approach does not consider attributes of multimodal data and feature extractors cannot be fine-tuned for specific task which can be disadvantageous for overall model accuracy. To this end, our impact is twofold: (i) we train model end-to-end, which allows early layers of neural network to be adapted with taking into account later, fusion layers, of two modalities; (ii) all layers of our model was fine-tuned for downstream task of emotion recognition, so there were no need to train neural networks from scratch. Our model achieves best validation accuracy of 60.37% which is approximately 8.5% higher, than VGAF dataset baseline and is competitive with existing works, audio and video modalities.
Adversarial Representation Learning With Closed-Form Solvers
Sep 12, 2021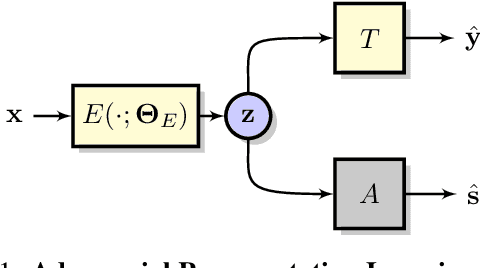
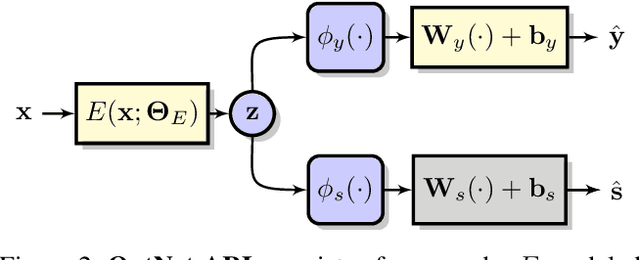
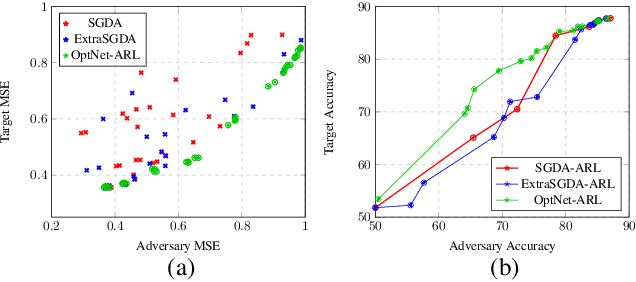
Adversarial representation learning aims to learn data representations for a target task while removing unwanted sensitive information at the same time. Existing methods learn model parameters iteratively through stochastic gradient descent-ascent, which is often unstable and unreliable in practice. To overcome this challenge, we adopt closed-form solvers for the adversary and target task. We model them as kernel ridge regressors and analytically determine an upper-bound on the optimal dimensionality of representation. Our solution, dubbed OptNet-ARL, reduces to a stable one one-shot optimization problem that can be solved reliably and efficiently. OptNet-ARL can be easily generalized to the case of multiple target tasks and sensitive attributes. Numerical experiments, on both small and large scale datasets, show that, from an optimization perspective, OptNet-ARL is stable and exhibits three to five times faster convergence. Performance wise, when the target and sensitive attributes are dependent, OptNet-ARL learns representations that offer a better trade-off front between (a) utility and bias for fair classification and (b) utility and privacy by mitigating leakage of private information than existing solutions.
MC-SSL0.0: Towards Multi-Concept Self-Supervised Learning
Nov 30, 2021
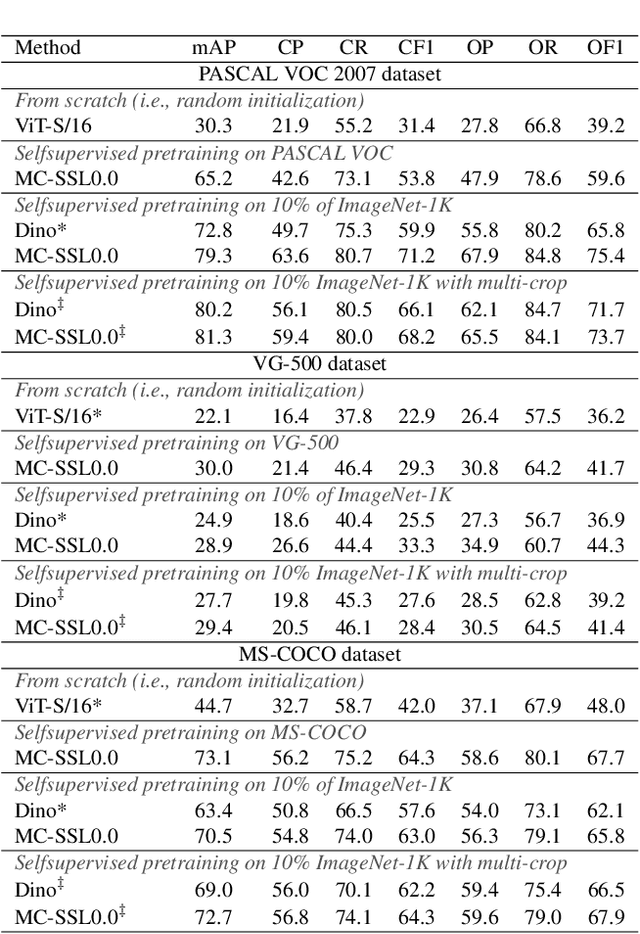
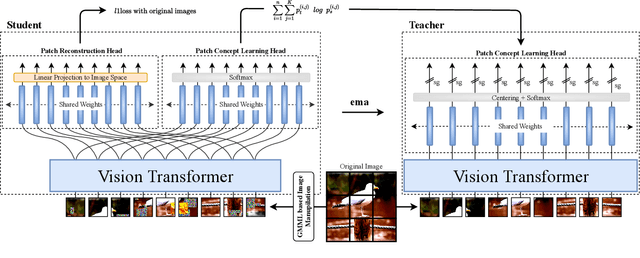
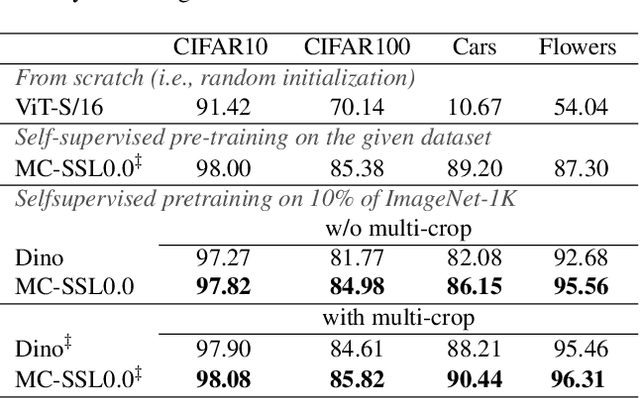
Self-supervised pretraining is the method of choice for natural language processing models and is rapidly gaining popularity in many vision tasks. Recently, self-supervised pretraining has shown to outperform supervised pretraining for many downstream vision applications, marking a milestone in the area. This superiority is attributed to the negative impact of incomplete labelling of the training images, which convey multiple concepts, but are annotated using a single dominant class label. Although Self-Supervised Learning (SSL), in principle, is free of this limitation, the choice of pretext task facilitating SSL is perpetuating this shortcoming by driving the learning process towards a single concept output. This study aims to investigate the possibility of modelling all the concepts present in an image without using labels. In this aspect the proposed SSL frame-work MC-SSL0.0 is a step towards Multi-Concept Self-Supervised Learning (MC-SSL) that goes beyond modelling single dominant label in an image to effectively utilise the information from all the concepts present in it. MC-SSL0.0 consists of two core design concepts, group masked model learning and learning of pseudo-concept for data token using a momentum encoder (teacher-student) framework. The experimental results on multi-label and multi-class image classification downstream tasks demonstrate that MC-SSL0.0 not only surpasses existing SSL methods but also outperforms supervised transfer learning. The source code will be made publicly available for community to train on bigger corpus.
CropDefender: deep watermark which is more convenient to train and more robust against cropping
Sep 12, 2021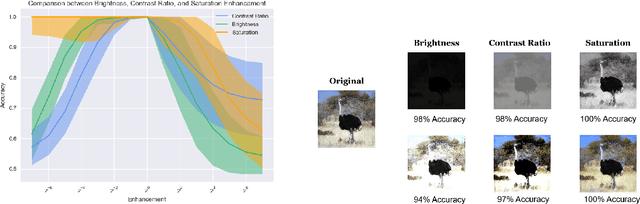
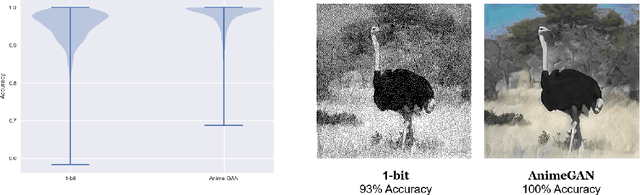
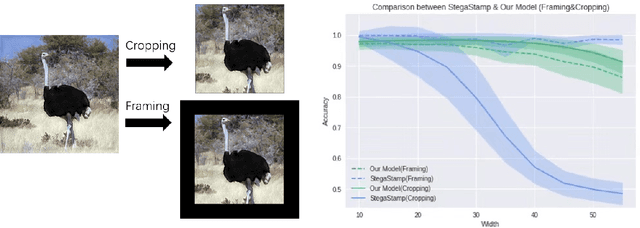
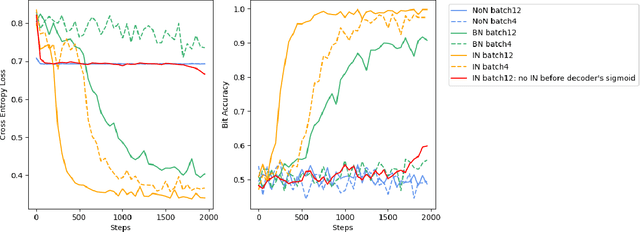
Digital image watermarking, which is a technique for invisibly embedding information into an image, is used in fields such as property rights protection. In recent years, some research has proposed the use of neural networks to add watermarks to natural images. We take StegaStamp as an example for our research. Whether facing traditional image editing methods, such as brightness, contrast, saturation adjustment, or style change like 1-bit conversion, GAN, StegaStamp has robustness far beyond traditional watermarking techniques, but it still has two drawbacks: it is vulnerable to cropping and is hard to train. We found that the causes of vulnerability to cropping is not the loss of information on the edge, but the movement of watermark position. By explicitly introducing the perturbation of cropping into the training, the cropping resistance is significantly improved. For the problem of difficult training, we introduce instance normalization to solve the vanishing gradient, set losses' weights as learnable parameters to reduce the number of hyperparameters, and use sigmoid to restrict pixel values of the generated image.
Explainable AI for engineering design: A unified approach of systems engineering and component-based deep learning
Aug 30, 2021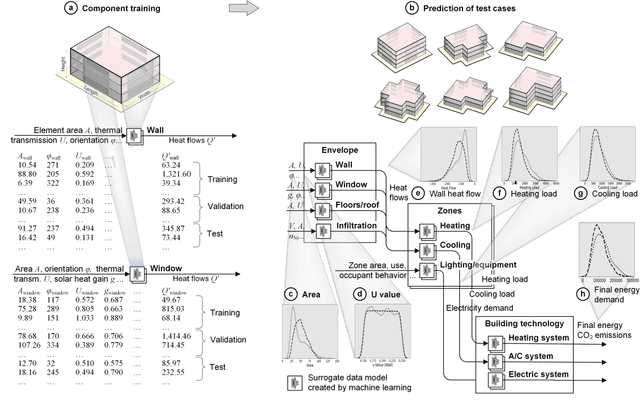
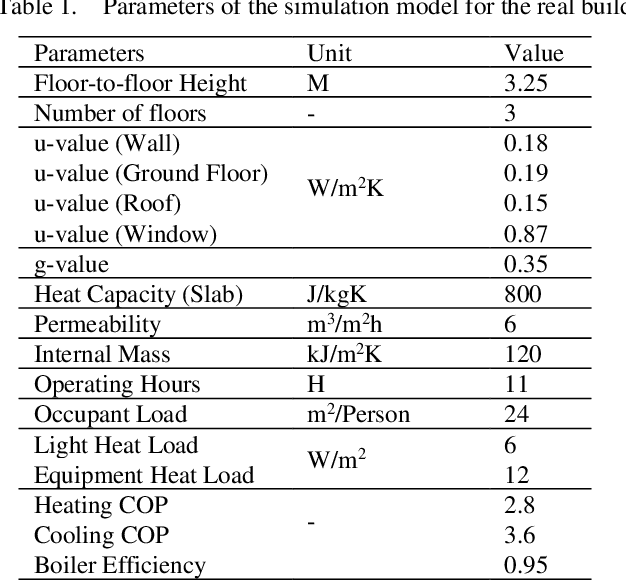
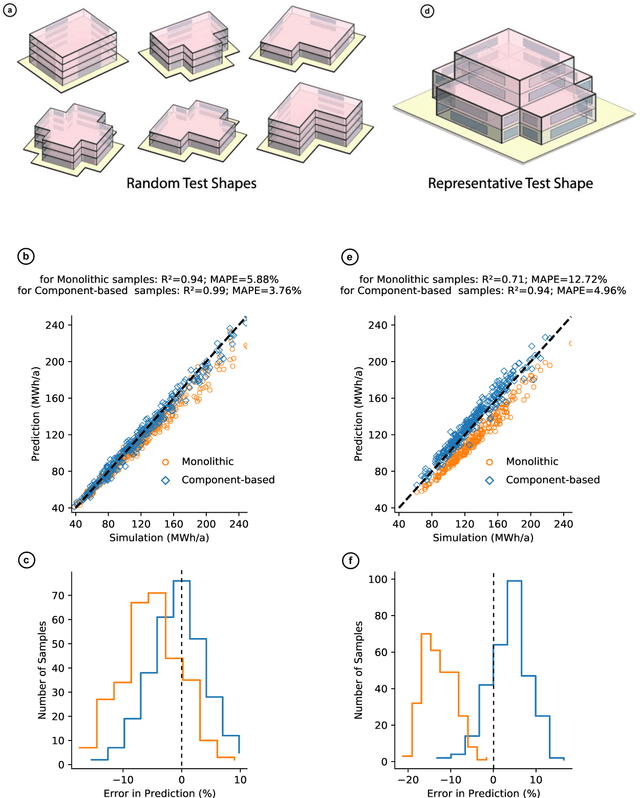
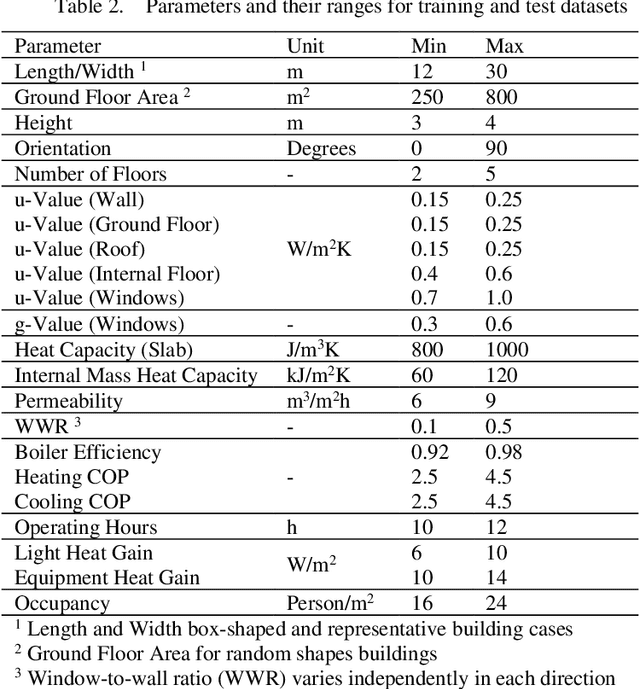
Data-driven models created by machine learning gain in importance in all fields of design and engineering. They have high potential to assists decision-makers in creating novel artefacts with a better performance and sustainability. However, limited generalization and the black-box nature of these models induce limited explainability and reusability. These drawbacks provide significant barriers retarding adoption in engineering design. To overcome this situation, we propose a component-based approach to create partial component models by machine learning (ML). This component-based approach aligns deep learning to systems engineering (SE). By means of the example of energy efficient building design, we first demonstrate generalization of the component-based method by accurately predicting the performance of designs with random structure different from training data. Second, we illustrate explainability by local sampling, sensitivity information and rules derived from low-depth decision trees and by evaluating this information from an engineering design perspective. The key for explainability is that activations at interfaces between the components are interpretable engineering quantities. In this way, the hierarchical component system forms a deep neural network (DNN) that directly integrates information for engineering explainability. The large range of possible configurations in composing components allows the examination of novel unseen design cases with understandable data-driven models. The matching of parameter ranges of components by similar probability distribution produces reusable, well-generalizing, and trustworthy models. The approach adapts the model structure to engineering methods of systems engineering and domain knowledge.
Edge-augmented Graph Transformers: Global Self-attention is Enough for Graphs
Aug 07, 2021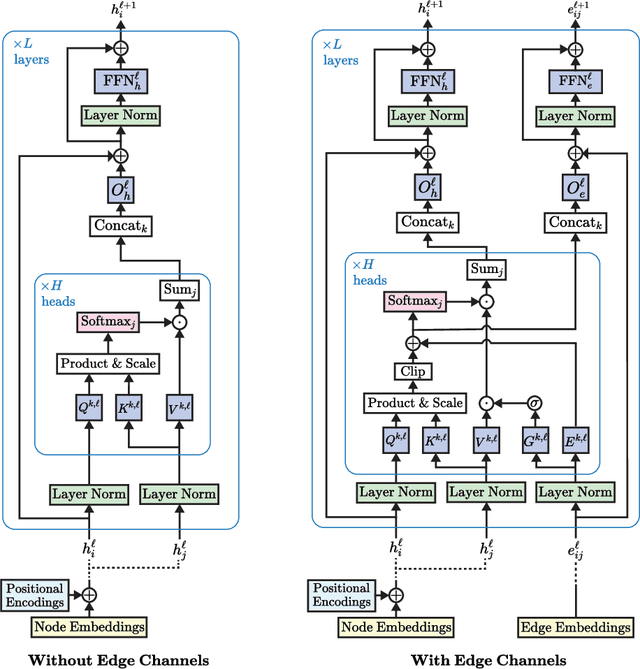
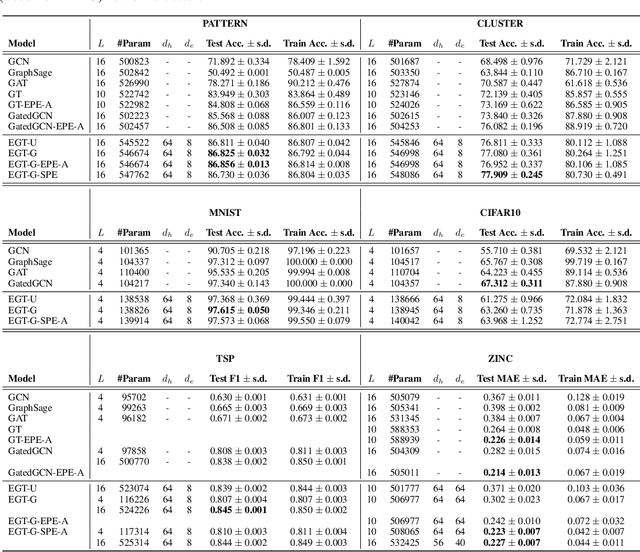
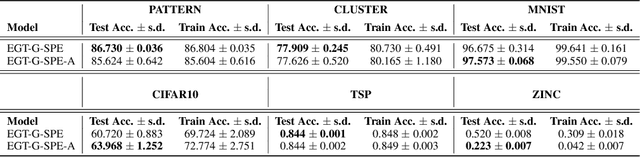
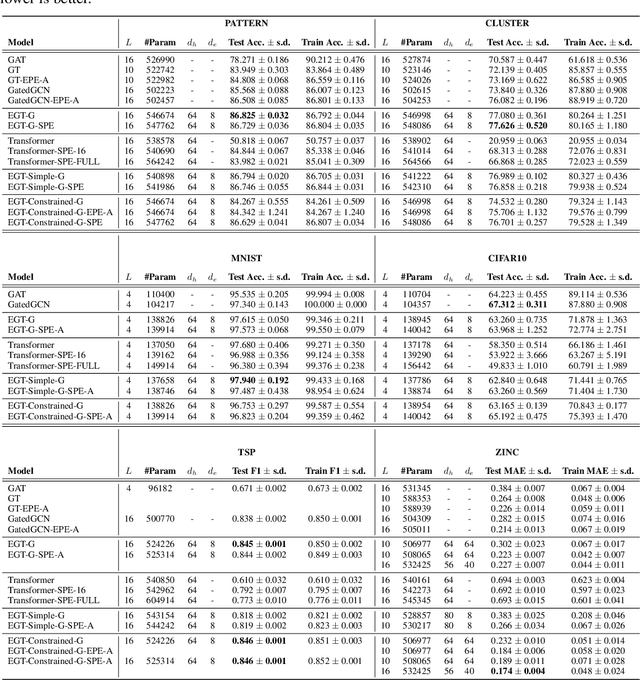
Transformer neural networks have achieved state-of-the-art results for unstructured data such as text and images but their adoption for graph-structured data has been limited. This is partly due to the difficulty in incorporating complex structural information in the basic transformer framework. We propose a simple yet powerful extension to the transformer - residual edge channels. The resultant framework, which we call Edge-augmented Graph Transformer (EGT), can directly accept, process and output structural information as well as node information. This simple addition allows us to use global self-attention, the key element of transformers, directly for graphs and comes with the benefit of long-range interaction among nodes. Moreover, the edge channels allow the structural information to evolve from layer to layer, and prediction tasks on edges can be derived directly from these channels. In addition to that, we introduce positional encodings based on Singular Value Decomposition which can improve the performance of EGT. Our framework, which relies on global node feature aggregation, achieves better performance compared to Graph Convolutional Networks (GCN), which rely on local feature aggregation within a neighborhood. We verify the performance of EGT in a supervised learning setting on a wide range of experiments on benchmark datasets. Our findings indicate that convolutional aggregation is not an essential inductive bias for graphs and global self-attention can serve as a flexible and adaptive alternative to graph convolution.
Contextual Information Enhanced Convolutional Neural Networks for Retinal Vessel Segmentation in Color Fundus Images
Mar 25, 2021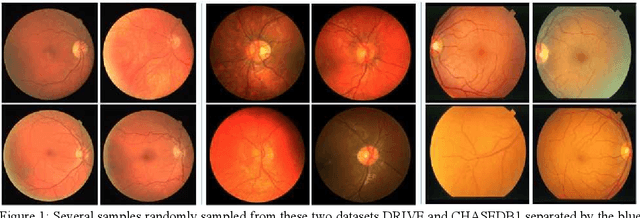

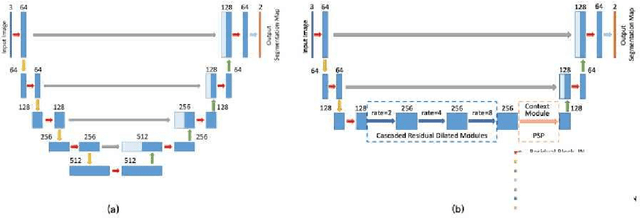
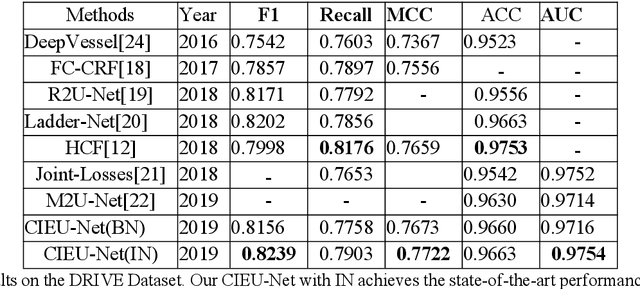
Accurate retinal vessel segmentation is a challenging problem in color fundus image analysis. An automatic retinal vessel segmentation system can effectively facilitate clinical diagnosis and ophthalmological research. Technically, this problem suffers from various degrees of vessel thickness, perception of details, and contextual feature fusion. For addressing these challenges, a deep learning based method has been proposed and several customized modules have been integrated into the well-known encoder-decoder architecture U-net, which is mainly employed in medical image segmentation. Structurally, cascaded dilated convolutional modules have been integrated into the intermediate layers, for obtaining larger receptive field and generating denser encoded feature maps. Also, the advantages of the pyramid module with spatial continuity have been taken, for multi-thickness perception, detail refinement, and contextual feature fusion. Additionally, the effectiveness of different normalization approaches has been discussed in network training for different datasets with specific properties. Experimentally, sufficient comparative experiments have been enforced on three retinal vessel segmentation datasets, DRIVE, CHASEDB1, and the unhealthy dataset STARE. As a result, the proposed method outperforms the work of predecessors and achieves state-of-the-art performance in Sensitivity/Recall, F1-score and MCC.