 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HYPERION: Hyperspectral Penetrating-type Ellipsoidal Reconstruction for Terahertz Blind Source Separation
Sep 12, 2021
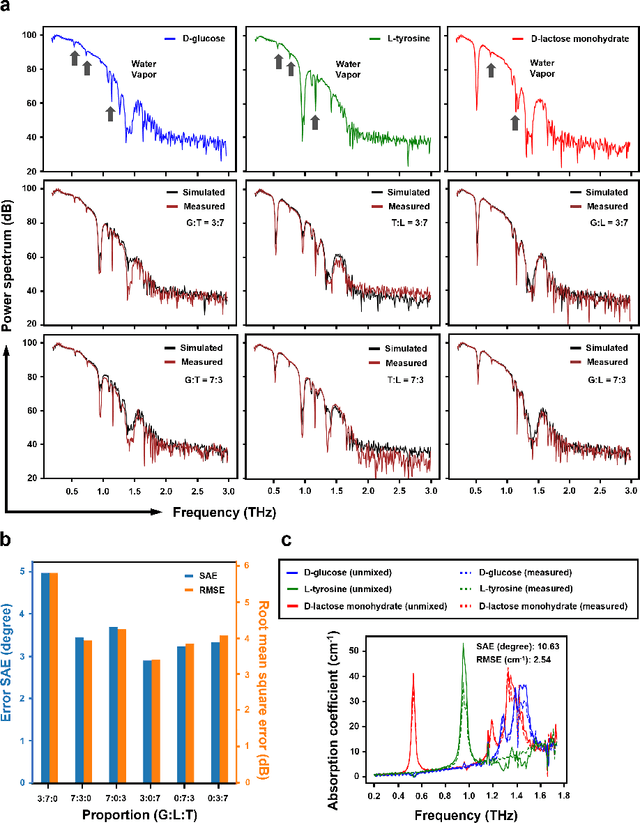
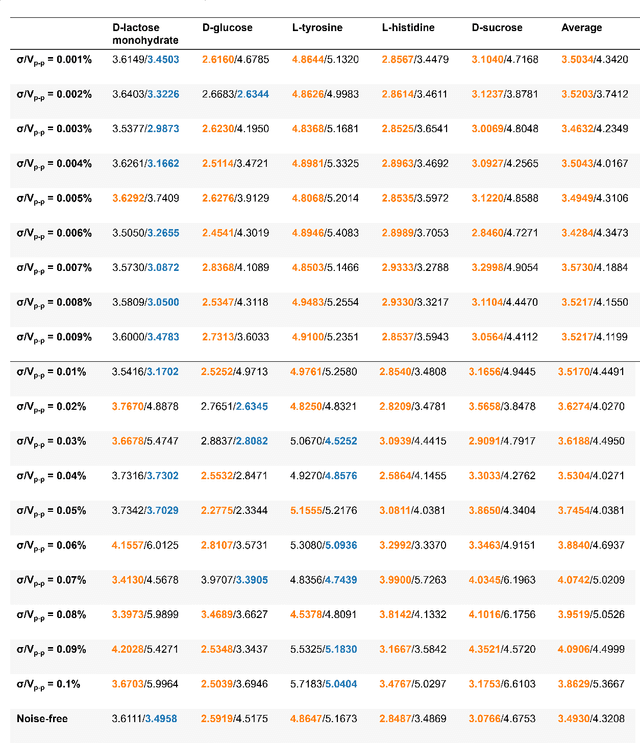
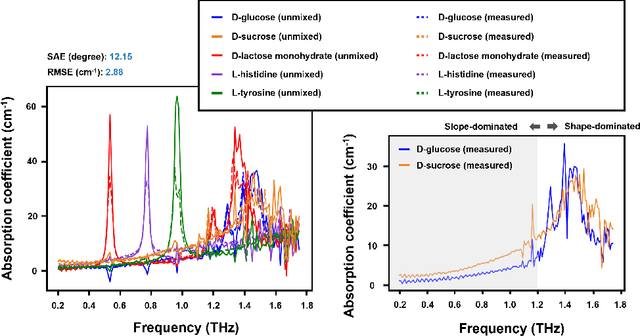

Terahertz (THz) technology has been a great candidate for applications, including pharmaceutic analysis, chemical identification, and remote sensing and imaging due to its non-invasive and non-destructive properties. Among those applications, penetrating-type hyperspectral THz signals, which provide crucial material information, normally involve a noisy, complex mixture system. Additionally, the measured THz signals could be ill-conditioned due to the overlap of the material absorption peak in the measured bands. To address those issues, we consider penetrating-type signal mixtures and aim to develop a \textit{blind} hyperspectral unmixing (HU) method without requiring any information from a prebuilt database. The proposed HYperspectral Penetrating-type Ellipsoidal ReconstructION (HYPERION) algorithm is unsupervised, not relying on collecting extensive data or sophisticated model training. Instead, it is developed based on elegant ellipsoidal geometry under a very mild requirement on data purity, whose excellent efficacy is experimentally demonstrated.
Fusing Visuo-Tactile Perception into Kernelized Synergies for Robust Grasping and Fine Manipulation of Non-rigid Objects
Sep 15, 2021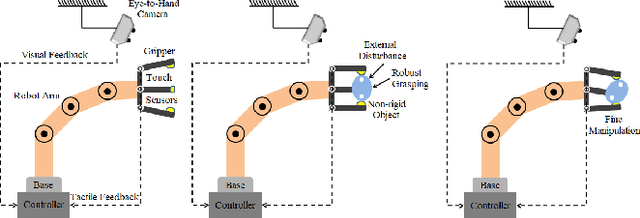
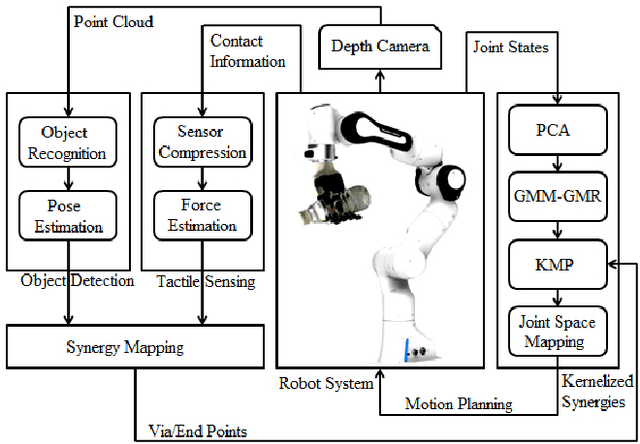
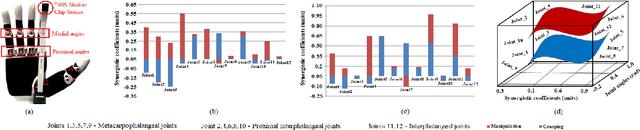
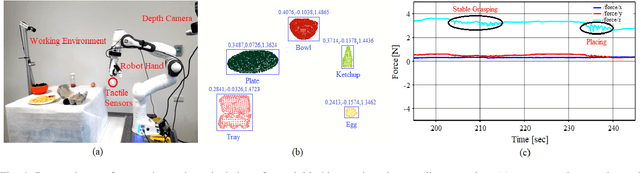
Handling non-rigid objects using robot hands necessities a framework that does not only incorporate human-level dexterity and cognition but also the multi-sensory information and system dynamics for robust and fine interactions. In this research, our previously developed kernelized synergies framework, inspired from human behaviour on reusing same subspace for grasping and manipulation, is augmented with visuo-tactile perception for autonomous and flexible adaptation to unknown objects. To detect objects and estimate their poses, a simplified visual pipeline using RANSAC algorithm with Euclidean clustering and SVM classifier is exploited. To modulate interaction efforts while grasping and manipulating non-rigid objects, the tactile feedback using T40S shokac chip sensor, generating 3D force information, is incorporated. Moreover, different kernel functions are examined in the kernelized synergies framework, to evaluate its performance and potential against task reproducibility, execution, generalization and synergistic re-usability. Experiments performed with robot arm-hand system validates the capability and usability of upgraded framework on stably grasping and dexterously manipulating the non-rigid objects.
New Performance Measures for Object Tracking under Complex Environments
Nov 13, 2021Various performance measures based on the ground truth and without ground truth exist to evaluate the quality of a developed tracking algorithm. The existing popular measures - average center location error (ACLE) and average tracking accuracy (ATA) based on ground truth, may sometimes create confusion to quantify the quality of a developed algorithm for tracking an object under some complex environments (e.g., scaled or oriented or both scaled and oriented object). In this article, we propose three new auxiliary performance measures based on ground truth information to evaluate the quality of a developed tracking algorithm under such complex environments. Moreover, one performance measure is developed by combining both two existing measures ACLE and ATA and three new proposed measures for better quantifying the developed tracking algorithm under such complex conditions. Some examples and experimental results conclude that the proposed measure is better than existing measures to quantify one developed algorithm for tracking objects under such complex environments.
$\infty$-former: Infinite Memory Transformer
Sep 15, 2021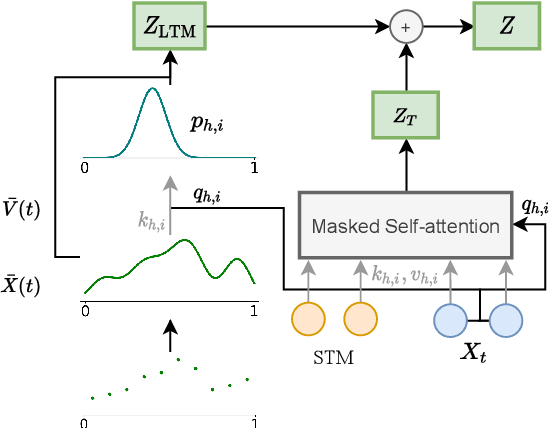

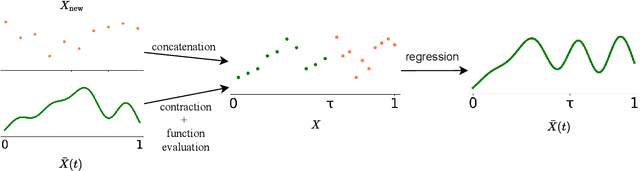

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.
Knowledge Distillation for Object Detection via Rank Mimicking and Prediction-guided Feature Imitation
Dec 09, 2021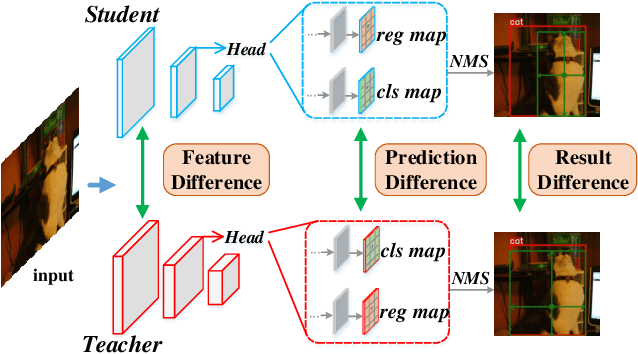
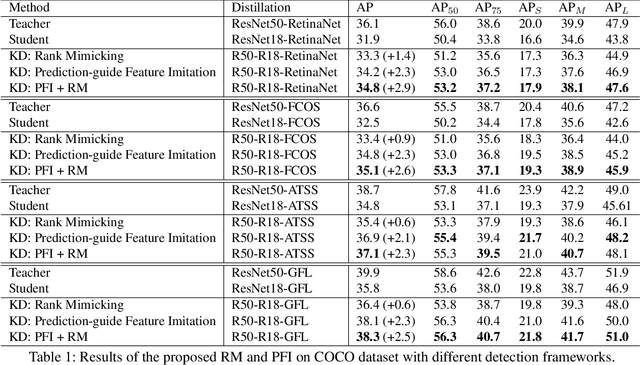
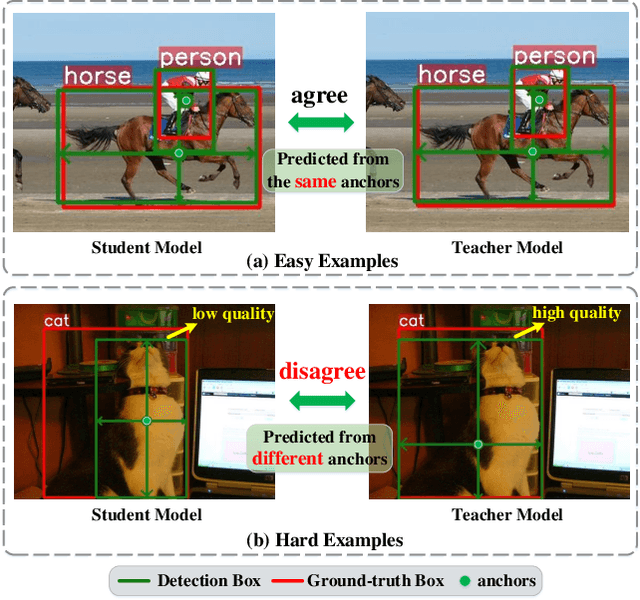
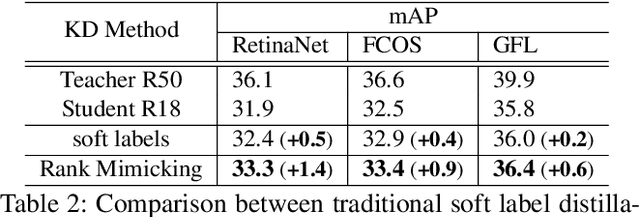
Knowledge Distillation (KD) is a widely-used technology to inherit information from cumbersome teacher models to compact student models, consequently realizing model compression and acceleration. Compared with image classification, object detection is a more complex task, and designing specific KD methods for object detection is non-trivial. In this work, we elaborately study the behaviour difference between the teacher and student detection models, and obtain two intriguing observations: First, the teacher and student rank their detected candidate boxes quite differently, which results in their precision discrepancy. Second, there is a considerable gap between the feature response differences and prediction differences between teacher and student, indicating that equally imitating all the feature maps of the teacher is the sub-optimal choice for improving the student's accuracy. Based on the two observations, we propose Rank Mimicking (RM) and Prediction-guided Feature Imitation (PFI) for distilling one-stage detectors, respectively. RM takes the rank of candidate boxes from teachers as a new form of knowledge to distill, which consistently outperforms the traditional soft label distillation. PFI attempts to correlate feature differences with prediction differences, making feature imitation directly help to improve the student's accuracy. On MS COCO and PASCAL VOC benchmarks, extensive experiments are conducted on various detectors with different backbones to validate the effectiveness of our method. Specifically, RetinaNet with ResNet50 achieves 40.4% mAP in MS COCO, which is 3.5% higher than its baseline, and also outperforms previous KD methods.
Will bots take over the supply chain? Revisiting Agent-based supply chain automation
Sep 03, 2021Agent-based systems have the capability to fuse information from many distributed sources and create better plans faster. This feature makes agent-based systems naturally suitable to address the challenges in Supply Chain Management (SCM). Although agent-based supply chains systems have been proposed since early 2000; industrial uptake of them has been lagging. The reasons quoted include the immaturity of the technology, a lack of interoperability with supply chain information systems, and a lack of trust in Artificial Intelligence (AI). In this paper, we revisit the agent-based supply chain and review the state of the art. We find that agent-based technology has matured, and other supporting technologies that are penetrating supply chains; are filling in gaps, leaving the concept applicable to a wider range of functions. For example, the ubiquity of IoT technology helps agents "sense" the state of affairs in a supply chain and opens up new possibilities for automation. Digital ledgers help securely transfer data between third parties, making agent-based information sharing possible, without the need to integrate Enterprise Resource Planning (ERP) systems. Learning functionality in agents enables agents to move beyond automation and towards autonomy. We note this convergence effect through conceptualising an agent-based supply chain framework, reviewing its components, and highlighting research challenges that need to be addressed in moving forward.
* 38 pages, 5 figures
Multimodal Pre-Training Model for Sequence-based Prediction of Protein-Protein Interaction
Dec 09, 2021

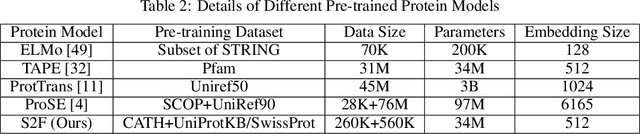
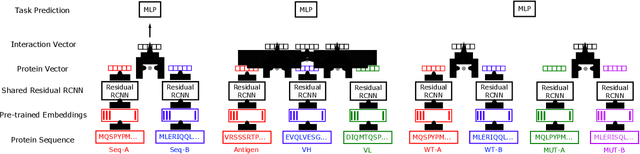
Protein-protein interactions (PPIs) are essentials for many biological processes where two or more proteins physically bind together to achieve their functions. Modeling PPIs is useful for many biomedical applications, such as vaccine design, antibody therapeutics, and peptide drug discovery. Pre-training a protein model to learn effective representation is critical for PPIs. Most pre-training models for PPIs are sequence-based, which naively adopt the language models used in natural language processing to amino acid sequences. More advanced works utilize the structure-aware pre-training technique, taking advantage of the contact maps of known protein structures. However, neither sequences nor contact maps can fully characterize structures and functions of the proteins, which are closely related to the PPI problem. Inspired by this insight, we propose a multimodal protein pre-training model with three modalities: sequence, structure, and function (S2F). Notably, instead of using contact maps to learn the amino acid-level rigid structures, we encode the structure feature with the topology complex of point clouds of heavy atoms. It allows our model to learn structural information about not only the backbones but also the side chains. Moreover, our model incorporates the knowledge from the functional description of proteins extracted from literature or manual annotations. Our experiments show that the S2F learns protein embeddings that achieve good performances on a variety of PPIs tasks, including cross-species PPI, antibody-antigen affinity prediction, antibody neutralization prediction for SARS-CoV-2, and mutation-driven binding affinity change prediction.
An Energy Consumption Model for Electrical Vehicle Networks via Extended Federated-learning
Nov 13, 2021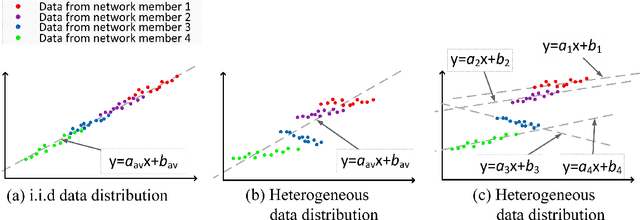

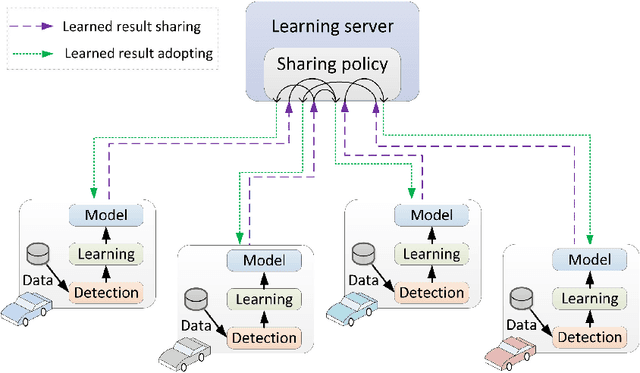
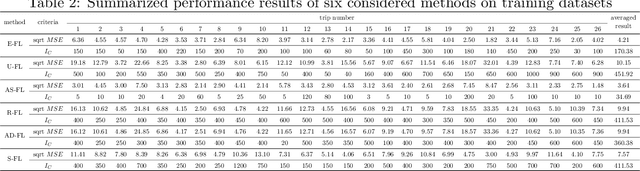
Electrical vehicle (EV) raises to promote an eco-sustainable society. Nevertheless, the ``range anxiety'' of EV hinders its wider acceptance among customers. This paper proposes a novel solution to range anxiety based on a federated-learning model, which is capable of estimating battery consumption and providing energy-efficient route planning for vehicle networks. Specifically, the new approach extends the federated-learning structure with two components: anomaly detection and sharing policy. The first component identifies preventing factors in model learning, while the second component offers guidelines for information sharing amongst vehicle networks when the sharing is necessary to preserve learning efficiency. The two components collaborate to enhance learning robustness against data heterogeneities in networks. Numerical experiments are conducted, and the results show that compared with considered solutions, the proposed approach could provide higher accuracy of battery-consumption estimation for vehicles under heterogeneous data distributions, without increasing the time complexity or transmitting raw data among vehicle networks.
OW-DETR: Open-world Detection Transformer
Dec 09, 2021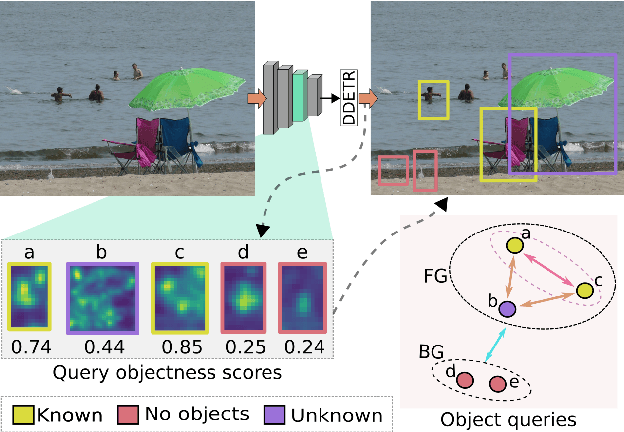
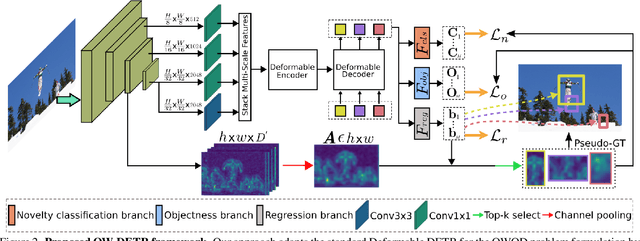
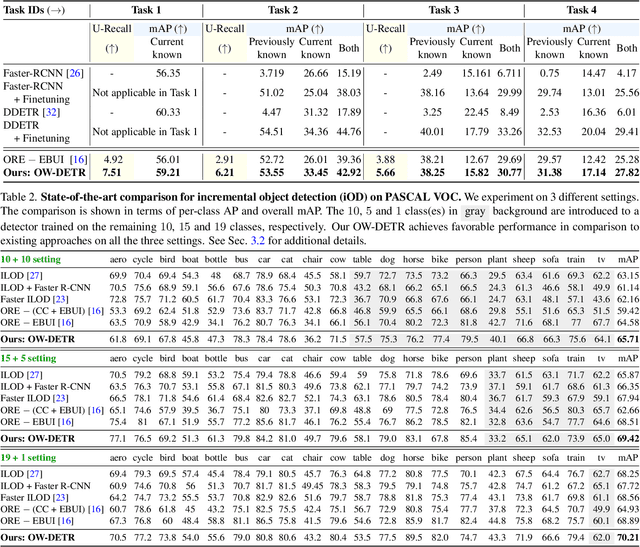
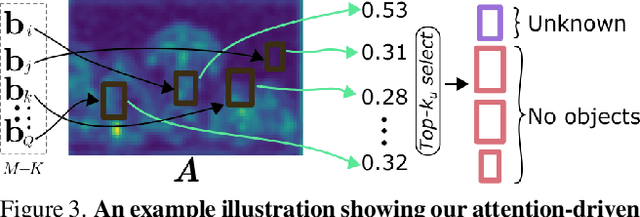
Open-world object detection (OWOD) is a challenging computer vision problem, where the task is to detect a known set of object categories while simultaneously identifying unknown objects. Additionally, the model must incrementally learn new classes that become known in the next training episodes. Distinct from standard object detection, the OWOD setting poses significant challenges for generating quality candidate proposals on potentially unknown objects, separating the unknown objects from the background and detecting diverse unknown objects. Here, we introduce a novel end-to-end transformer-based framework, OW-DETR, for open-world object detection. The proposed OW-DETR comprises three dedicated components namely, attention-driven pseudo-labeling, novelty classification and objectness scoring to explicitly address the aforementioned OWOD challenges. Our OW-DETR explicitly encodes multi-scale contextual information, possesses less inductive bias, enables knowledge transfer from known classes to the unknown class and can better discriminate between unknown objects and background. Comprehensive experiments are performed on two benchmarks: MS-COCO and PASCAL VOC. The extensive ablations reveal the merits of our proposed contributions. Further, our model outperforms the recently introduced OWOD approach, ORE, with absolute gains ranging from 1.8% to 3.3% in terms of unknown recall on the MS-COCO benchmark. In the case of incremental object detection, OW-DETR outperforms the state-of-the-art for all settings on the PASCAL VOC benchmark. Our codes and models will be publicly released.
The JDDC 2.0 Corpus: A Large-Scale Multimodal Multi-Turn Chinese Dialogue Dataset for E-commerce Customer Service
Sep 27, 2021
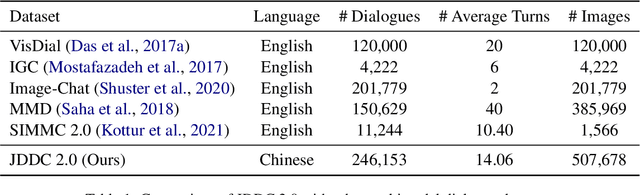
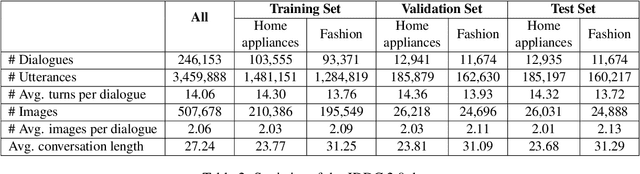
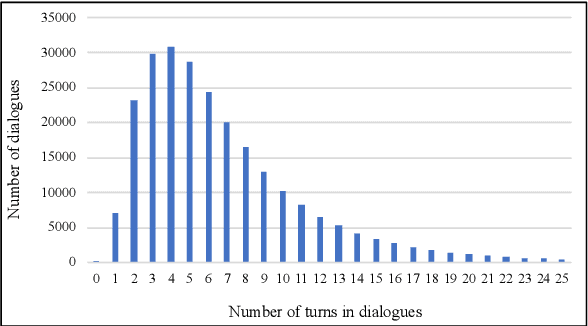
With the development of the Internet, more and more people get accustomed to online shopping. When communicating with customer service, users may express their requirements by means of text, images, and videos, which precipitates the need for understanding these multimodal information for automatic customer service systems. Images usually act as discriminators for product models, or indicators of product failures, which play important roles in the E-commerce scenario. On the other hand, detailed information provided by the images is limited, and typically, customer service systems cannot understand the intents of users without the input text. Thus, bridging the gap of the image and text is crucial for the multimodal dialogue task. To handle this problem, we construct JDDC 2.0, a large-scale multimodal multi-turn dialogue dataset collected from a mainstream Chinese E-commerce platform (JD.com), containing about 246 thousand dialogue sessions, 3 million utterances, and 507 thousand images, along with product knowledge bases and image category annotations. We present the solutions of top-5 teams participating in the JDDC multimodal dialogue challenge based on this dataset, which provides valuable insights for further researches on the multimodal dialogue task.