 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Robust Partial-to-Partial Point Cloud Registration in a Full Range
Nov 30, 2021
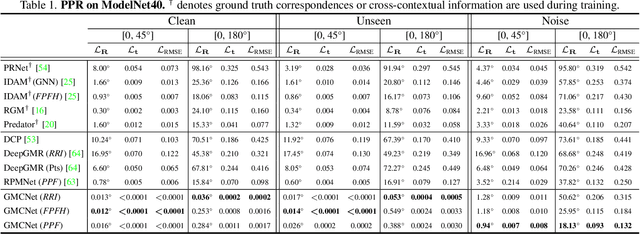
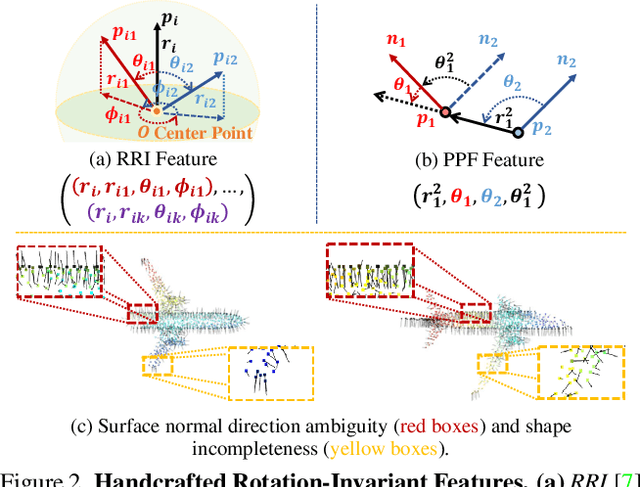
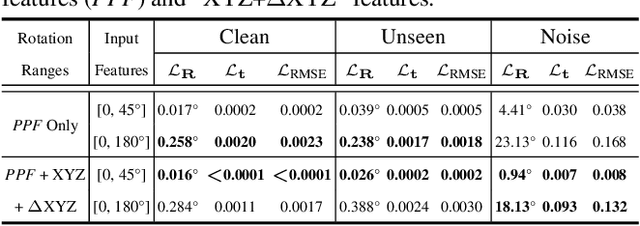
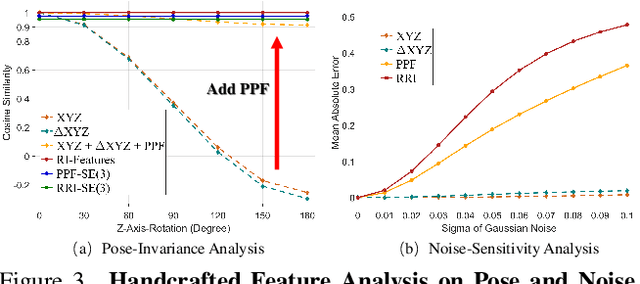
Point cloud registration for 3D objects is very challenging due to sparse and noisy measurements, incomplete observations and large transformations. In this work, we propose Graph Matching Consensus Network (GMCNet), which estimates pose-invariant correspondences for fullrange 1 Partial-to-Partial point cloud Registration (PPR). To encode robust point descriptors, 1) we first comprehensively investigate transformation-robustness and noiseresilience of various geometric features. 2) Then, we employ a novel Transformation-robust Point Transformer (TPT) modules to adaptively aggregate local features regarding the structural relations, which takes advantage from both handcrafted rotation-invariant ($RI$) features and noise-resilient spatial coordinates. 3) Based on a synergy of hierarchical graph networks and graphical modeling, we propose the Hierarchical Graphical Modeling (HGM) architecture to encode robust descriptors consisting of i) a unary term learned from $RI$ features; and ii) multiple smoothness terms encoded from neighboring point relations at different scales through our TPT modules. Moreover, we construct a challenging PPR dataset (MVP-RG) with virtual scans. Extensive experiments show that GMCNet outperforms previous state-of-the-art methods for PPR. Remarkably, GMCNet encodes point descriptors for each point cloud individually without using crosscontextual information, or ground truth correspondences for training. Our code and datasets will be available at https://github.com/paul007pl/GMCNet.
Technology Fitness Landscape and the Future of Innovation
Oct 27, 2021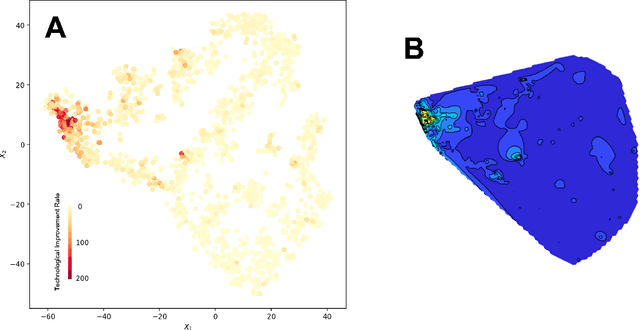
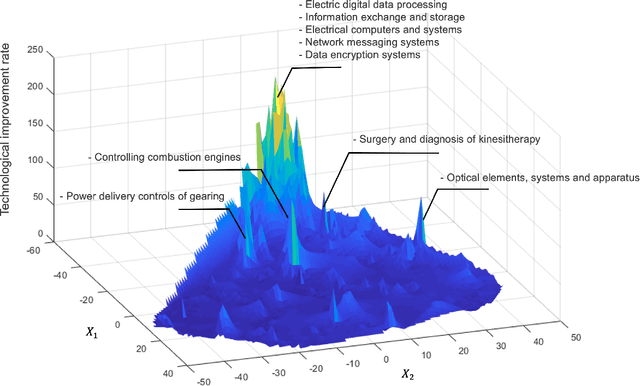
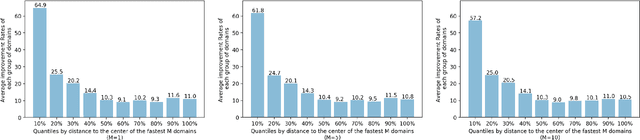
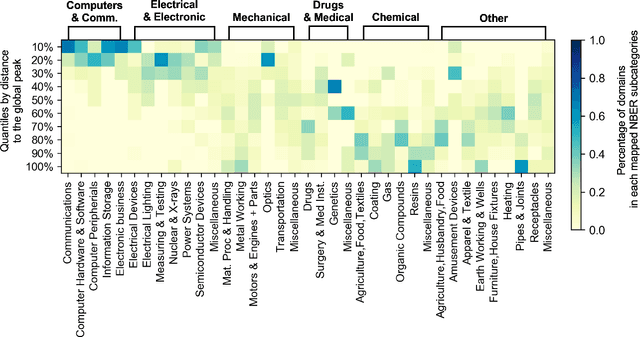
We present a deep learning-based technology fitness landscape premised on a neural embedding space of 1,757 technology domains and their respective improvement rates. The technology embedding space is a high-dimensional vector space trained via applying neural embedding techniques to patent data. The improvement rates of respective technology domains are drawn from a prior study. The technology fitness landscape exhibits a high hill related to information and communication technologies (ICT) and a vast low plain of the remaining domains. The technology fitness landscape presents a bird's eye view of the structure of the total technology space, a new way to interpret technology evolution with a biological analogy, and a biologically-inspired inference to next innovation.
An Extensive Study of User Identification via Eye Movements across Multiple Datasets
Nov 10, 2021
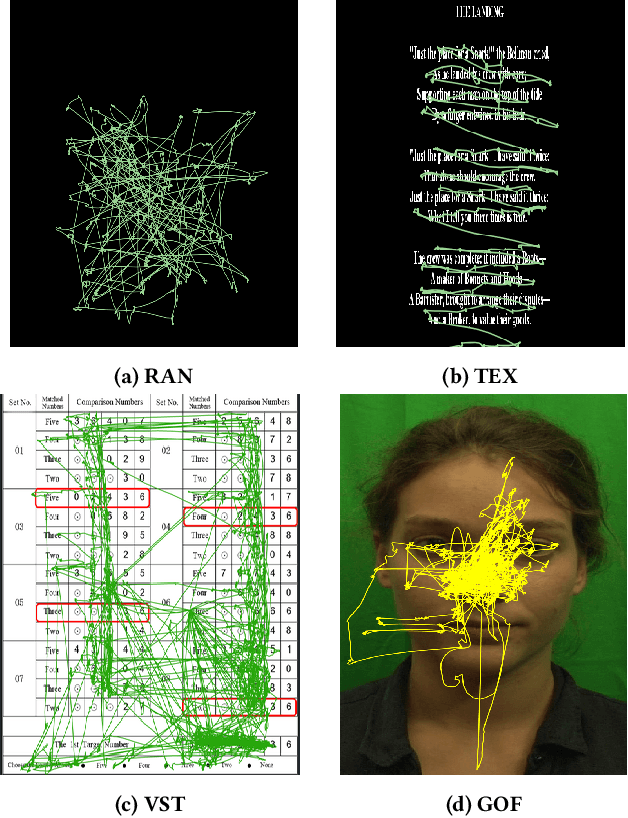


Several studies have reported that biometric identification based on eye movement characteristics can be used for authentication. This paper provides an extensive study of user identification via eye movements across multiple datasets based on an improved version of method originally proposed by George and Routray. We analyzed our method with respect to several factors that affect the identification accuracy, such as the type of stimulus, the IVT parameters (used for segmenting the trajectories into fixation and saccades), adding new features such as higher-order derivatives of eye movements, the inclusion of blink information, template aging, age and gender.We find that three methods namely selecting optimal IVT parameters, adding higher-order derivatives features and including an additional blink classifier have a positive impact on the identification accuracy. The improvements range from a few percentage points, up to an impressive 9 % increase on one of the datasets.
An Exact Algorithm for Semi-supervised Minimum Sum-of-Squares Clustering
Nov 30, 2021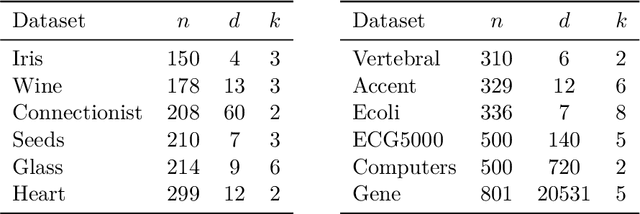
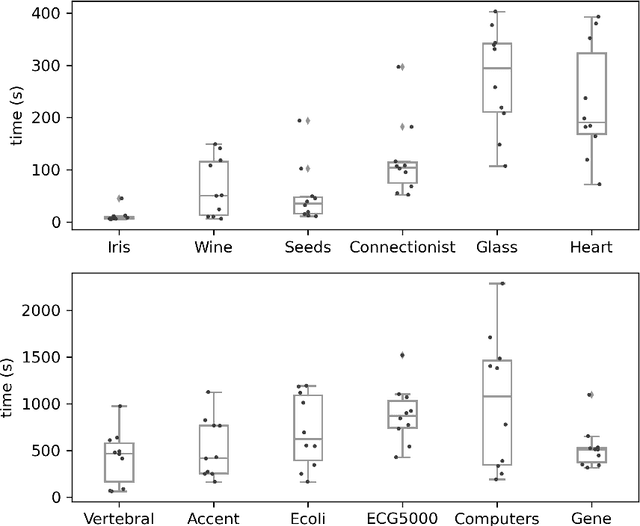
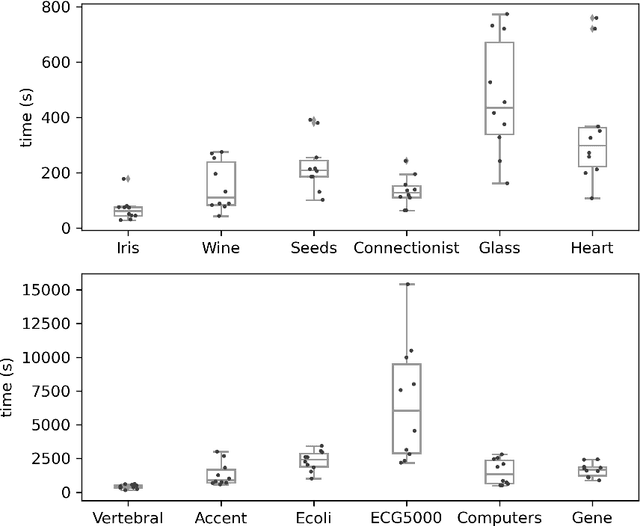
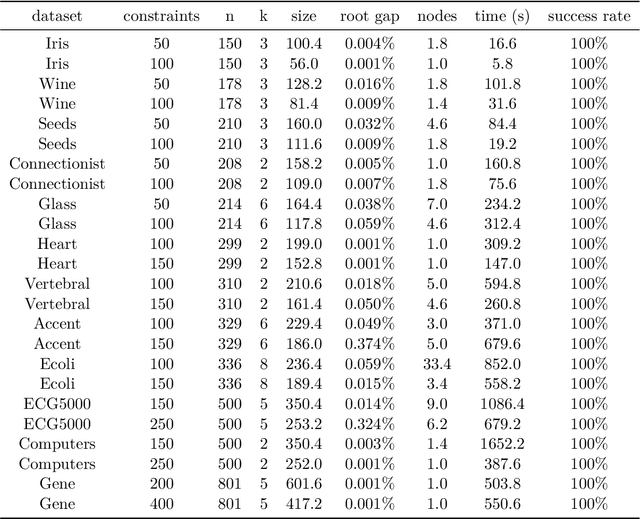
The minimum sum-of-squares clustering (MSSC), or k-means type clustering, is traditionally considered an unsupervised learning task. In recent years, the use of background knowledge to improve the cluster quality and promote interpretability of the clustering process has become a hot research topic at the intersection of mathematical optimization and machine learning research. The problem of taking advantage of background information in data clustering is called semi-supervised or constrained clustering. In this paper, we present a new branch-and-bound algorithm for semi-supervised MSSC, where background knowledge is incorporated as pairwise must-link and cannot-link constraints. For the lower bound procedure, we solve the semidefinite programming relaxation of the MSSC discrete optimization model, and we use a cutting-plane procedure for strengthening the bound. For the upper bound, instead, by using integer programming tools, we propose an adaptation of the k-means algorithm to the constrained case. For the first time, the proposed global optimization algorithm efficiently manages to solve real-world instances up to 800 data points with different combinations of must-link and cannot-link constraints and with a generic number of features. This problem size is about four times larger than the one of the instances solved by state-of-the-art exact algorithms.
Exploiting the Intrinsic Neighborhood Structure for Source-free Domain Adaptation
Oct 08, 2021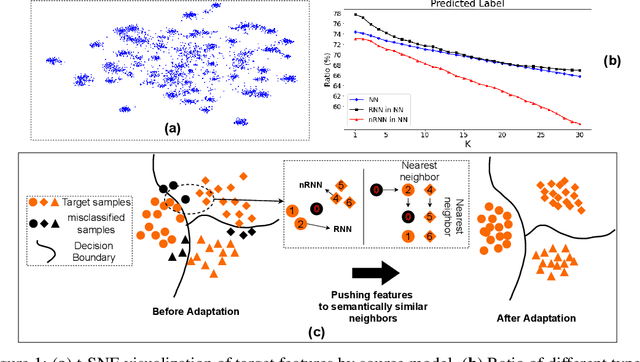
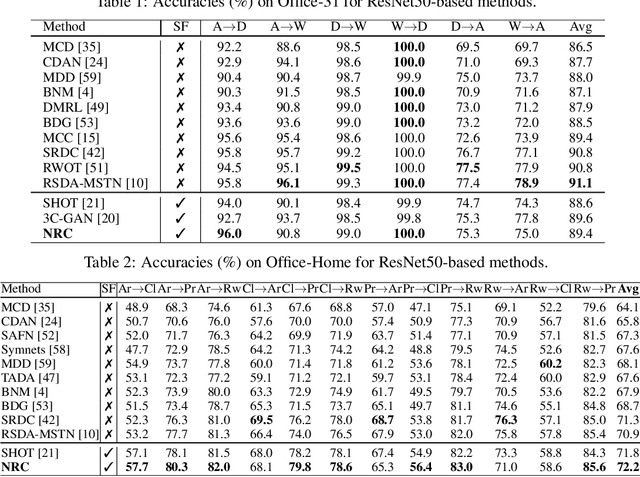
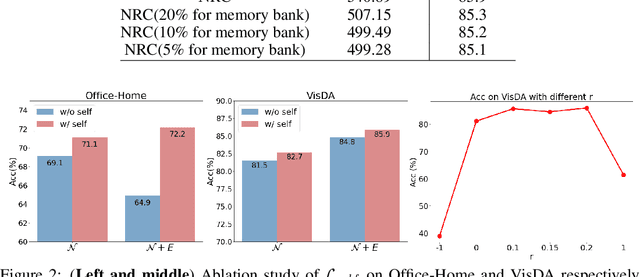
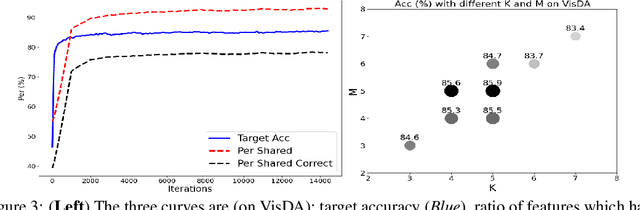
Domain adaptation (DA) aims to alleviate the domain shift between source domain and target domain. Most DA methods require access to the source data, but often that is not possible (e.g. due to data privacy or intellectual property). In this paper, we address the challenging source-free domain adaptation (SFDA) problem, where the source pretrained model is adapted to the target domain in the absence of source data. Our method is based on the observation that target data, which might no longer align with the source domain classifier, still forms clear clusters. We capture this intrinsic structure by defining local affinity of the target data, and encourage label consistency among data with high local affinity. We observe that higher affinity should be assigned to reciprocal neighbors, and propose a self regularization loss to decrease the negative impact of noisy neighbors. Furthermore, to aggregate information with more context, we consider expanded neighborhoods with small affinity values. In the experimental results we verify that the inherent structure of the target features is an important source of information for domain adaptation. We demonstrate that this local structure can be efficiently captured by considering the local neighbors, the reciprocal neighbors, and the expanded neighborhood. Finally, we achieve state-of-the-art performance on several 2D image and 3D point cloud recognition datasets. Code is available in https://github.com/Albert0147/SFDA_neighbors.
TiWS-iForest: Isolation Forest in Weakly Supervised and Tiny ML scenarios
Nov 30, 2021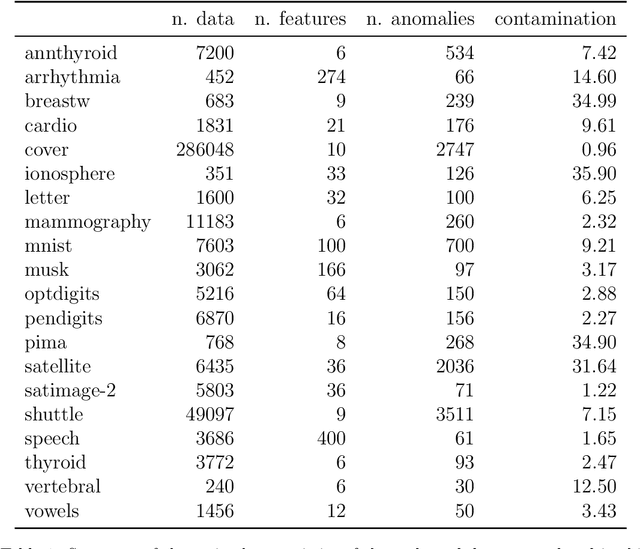
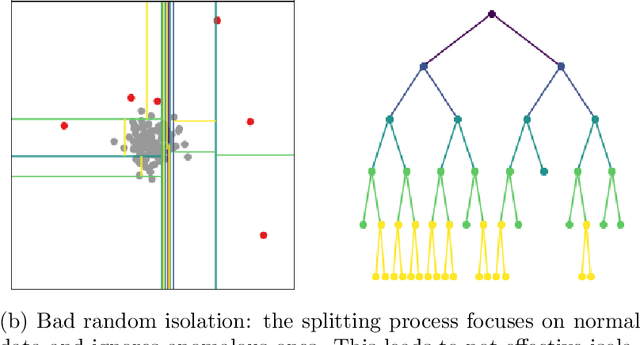
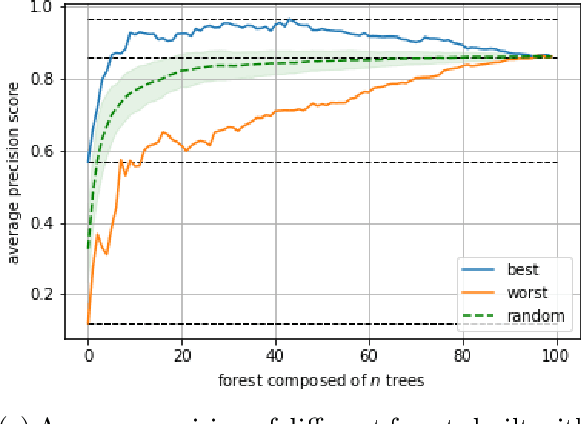
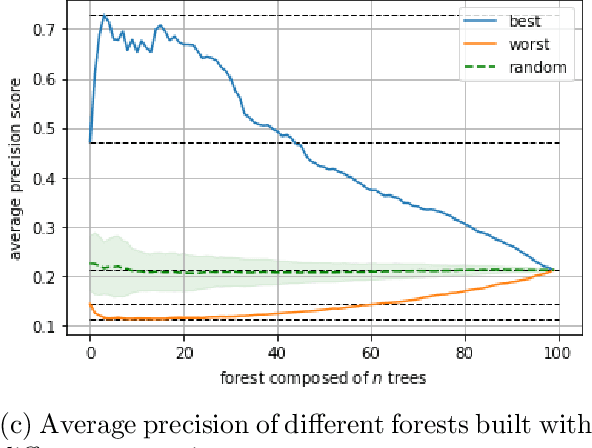
Unsupervised anomaly detection tackles the problem of finding anomalies inside datasets without the labels availability; since data tagging is typically hard or expensive to obtain, such approaches have seen huge applicability in recent years. In this context, Isolation Forest is a popular algorithm able to define an anomaly score by means of an ensemble of peculiar trees called isolation trees. These are built using a random partitioning procedure that is extremely fast and cheap to train. However, we find that the standard algorithm might be improved in terms of memory requirements, latency and performances; this is of particular importance in low resources scenarios and in TinyML implementations on ultra-constrained microprocessors. Moreover, Anomaly Detection approaches currently do not take advantage of weak supervisions: being typically consumed in Decision Support Systems, feedback from the users, even if rare, can be a valuable source of information that is currently unexplored. Beside showing iForest training limitations, we propose here TiWS-iForest, an approach that, by leveraging weak supervision is able to reduce Isolation Forest complexity and to enhance detection performances. We showed the effectiveness of TiWS-iForest on real word datasets and we share the code in a public repository to enhance reproducibility.
Robust Weakly Supervised Learning for COVID-19 Recognition Using Multi-Center CT Images
Dec 09, 2021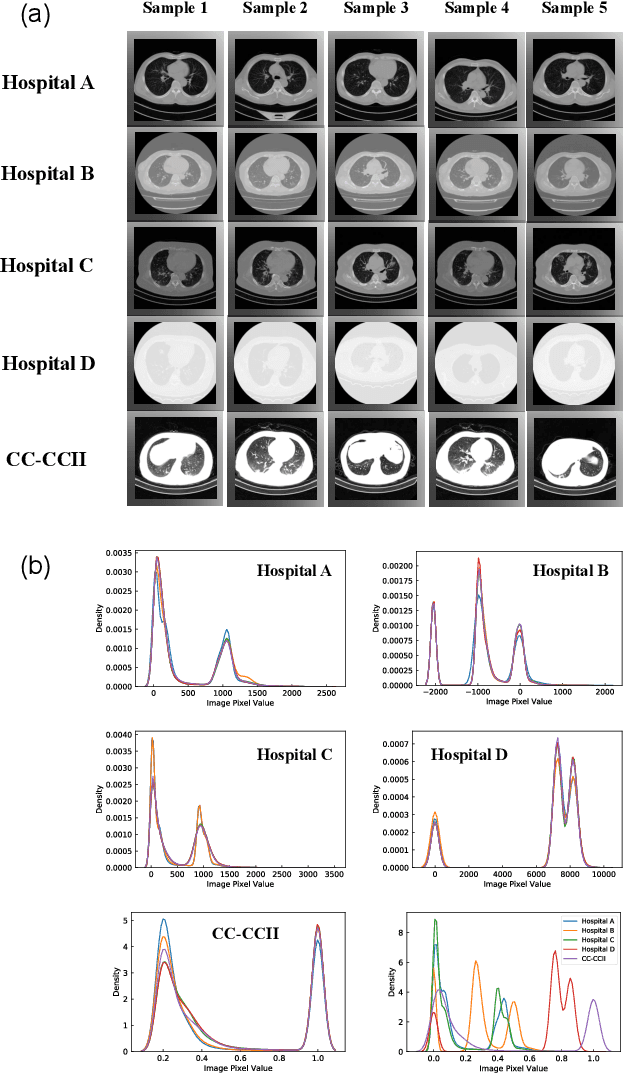
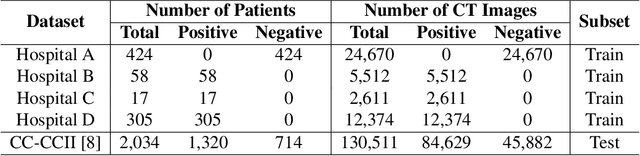
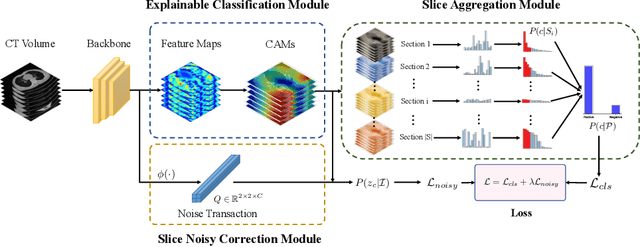
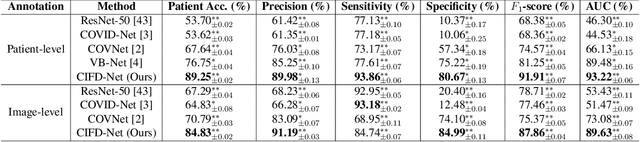
The world is currently experiencing an ongoing pandemic of an infectious disease named coronavirus disease 2019 (i.e., COVID-19), which is caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). Computed Tomography (CT) plays an important role in assessing the severity of the infection and can also be used to identify those symptomatic and asymptomatic COVID-19 carriers. With a surge of the cumulative number of COVID-19 patients, radiologists are increasingly stressed to examine the CT scans manually. Therefore, an automated 3D CT scan recognition tool is highly in demand since the manual analysis is time-consuming for radiologists and their fatigue can cause possible misjudgment. However, due to various technical specifications of CT scanners located in different hospitals, the appearance of CT images can be significantly different leading to the failure of many automated image recognition approaches. The multi-domain shift problem for the multi-center and multi-scanner studies is therefore nontrivial that is also crucial for a dependable recognition and critical for reproducible and objective diagnosis and prognosis. In this paper, we proposed a COVID-19 CT scan recognition model namely coronavirus information fusion and diagnosis network (CIFD-Net) that can efficiently handle the multi-domain shift problem via a new robust weakly supervised learning paradigm. Our model can resolve the problem of different appearance in CT scan images reliably and efficiently while attaining higher accuracy compared to other state-of-the-art methods.
Multimodal-Boost: Multimodal Medical Image Super-Resolution using Multi-Attention Network with Wavelet Transform
Oct 22, 2021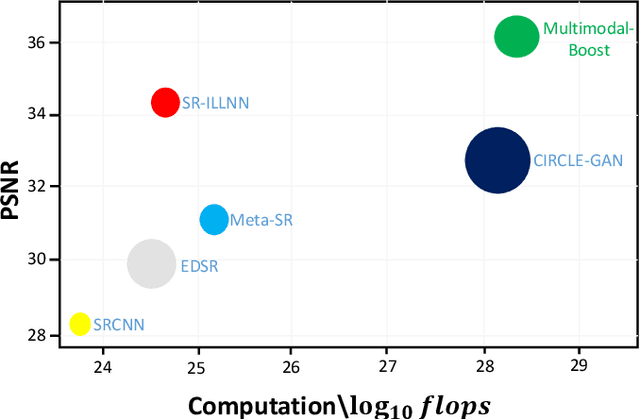
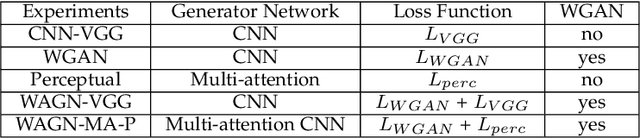
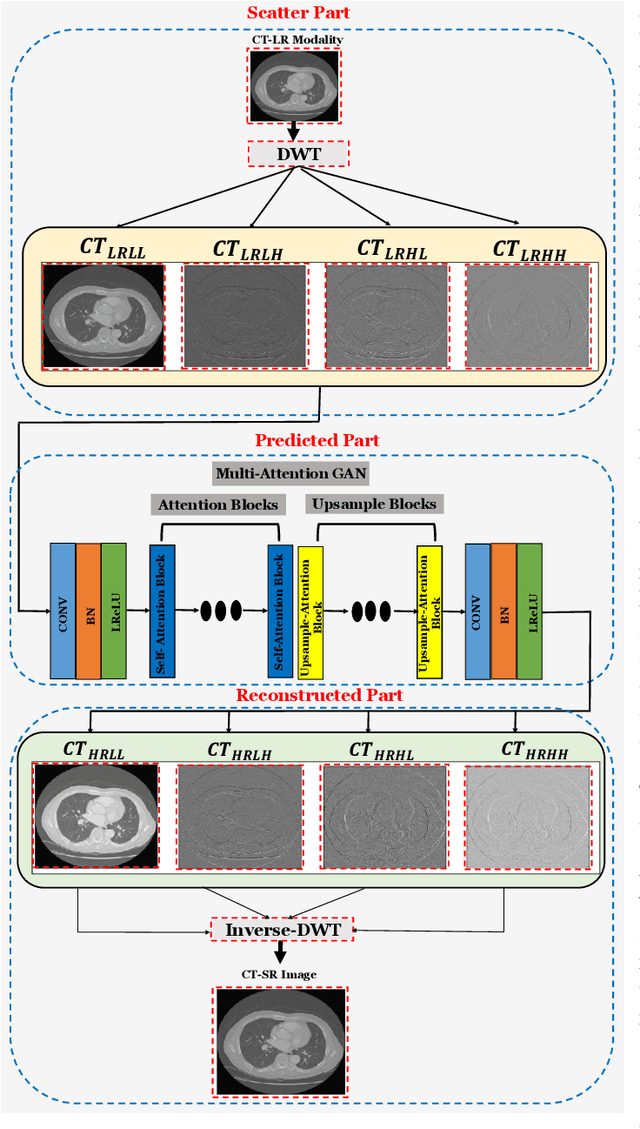

Multimodal medical images are widely used by clinicians and physicians to analyze and retrieve complementary information from high-resolution images in a non-invasive manner. The loss of corresponding image resolution degrades the overall performance of medical image diagnosis. Deep learning based single image super resolution (SISR) algorithms has revolutionized the overall diagnosis framework by continually improving the architectural components and training strategies associated with convolutional neural networks (CNN) on low-resolution images. However, existing work lacks in two ways: i) the SR output produced exhibits poor texture details, and often produce blurred edges, ii) most of the models have been developed for a single modality, hence, require modification to adapt to a new one. This work addresses (i) by proposing generative adversarial network (GAN) with deep multi-attention modules to learn high-frequency information from low-frequency data. Existing approaches based on the GAN have yielded good SR results; however, the texture details of their SR output have been experimentally confirmed to be deficient for medical images particularly. The integration of wavelet transform (WT) and GANs in our proposed SR model addresses the aforementioned limitation concerning textons. The WT divides the LR image into multiple frequency bands, while the transferred GAN utilizes multiple attention and upsample blocks to predict high-frequency components. Moreover, we present a learning technique for training a domain-specific classifier as a perceptual loss function. Combining multi-attention GAN loss with a perceptual loss function results in a reliable and efficient performance. Applying the same model for medical images from diverse modalities is challenging, our work addresses (ii) by training and performing on several modalities via transfer learning.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021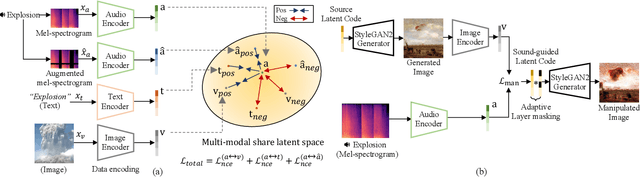
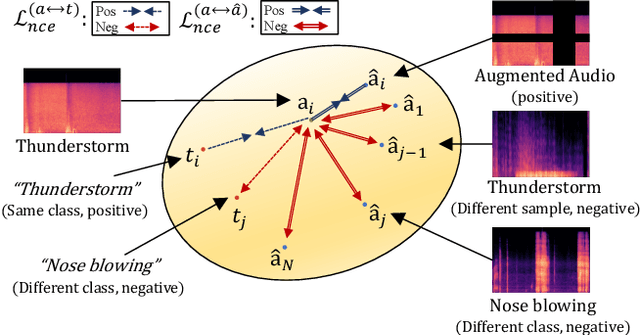


The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
Fast and Real-time End to End Control in Autonomous Racing Cars Through Representation Learning
Nov 30, 2021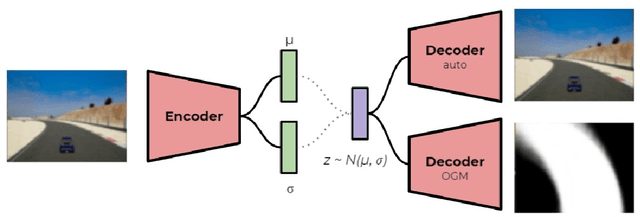

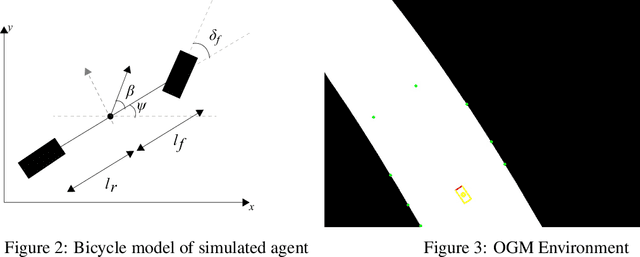
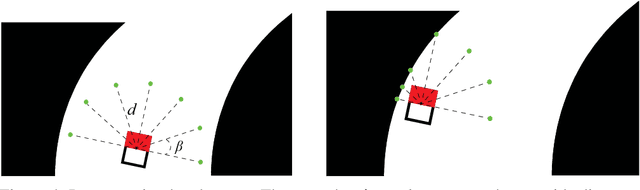
The challenges presented in an autonomous racing situation are distinct from those faced in regular autonomous driving and require faster end-to-end algorithms and consideration of a longer horizon in determining optimal current actions keeping in mind upcoming maneuvers and situations. In this paper, we propose an end-to-end method for autonomous racing that takes in as inputs video information from an onboard camera and determines final steering and throttle control actions. We use the following split to construct such a method (1) learning a low dimensional representation of the scene, (2) pre-generating the optimal trajectory for the given scene, and (3) tracking the predicted trajectory using a classical control method. In learning a low-dimensional representation of the scene, we use intermediate representations with a novel unsupervised trajectory planner to generate expert trajectories, and hence utilize them to directly predict race lines from a given front-facing input image. Thus, the proposed algorithm employs the best of two worlds - the robustness of learning-based approaches to perception and the accuracy of optimization-based approaches for trajectory generation in an end-to-end learning-based framework. We deploy and demonstrate our framework on CARLA, a photorealistic simulator for testing self-driving cars in realistic environments.