 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Report-Guided Automatic Lesion Annotation for Deep Learning-Based Prostate Cancer Detection in bpMRI
Dec 09, 2021
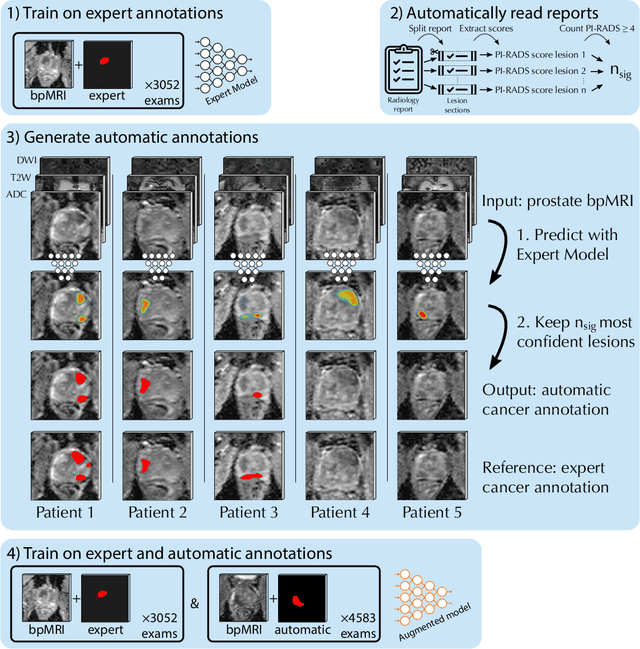

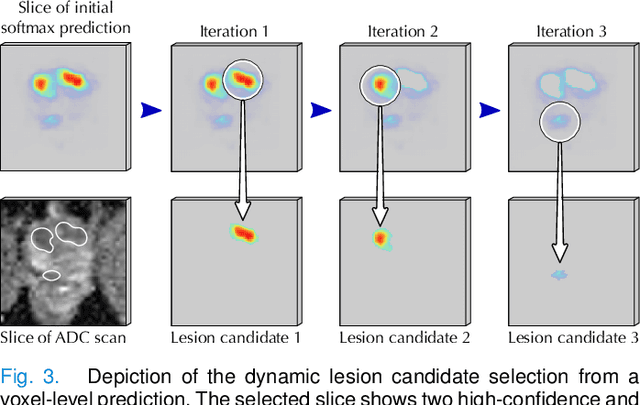
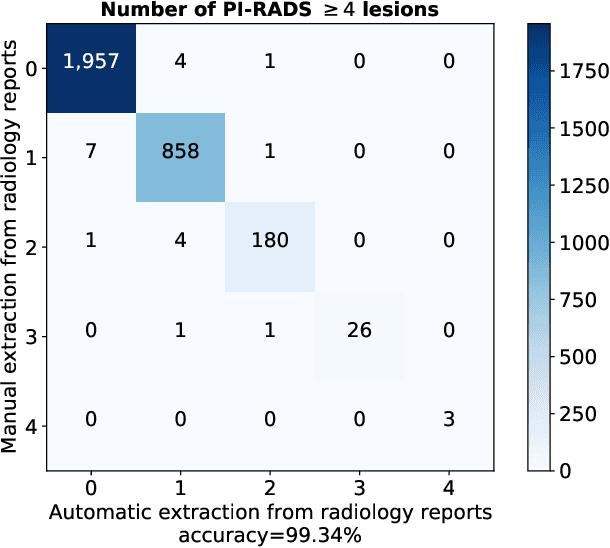
Deep learning-based diagnostic performance increases with more annotated data, but manual annotation is a bottleneck in most fields. Experts evaluate diagnostic images during clinical routine, and write their findings in reports. Automatic annotation based on clinical reports could overcome the manual labelling bottleneck. We hypothesise that dense annotations for detection tasks can be generated using model predictions, guided by sparse information from these reports. To demonstrate efficacy, we generated clinically significant prostate cancer (csPCa) annotations, guided by the number of clinically significant findings in the radiology reports. We included 7,756 prostate MRI examinations, of which 3,050 were manually annotated and 4,706 were automatically annotated. We evaluated the automatic annotation quality on the manually annotated subset: our score extraction correctly identified the number of csPCa lesions for $99.3\%$ of the reports and our csPCa segmentation model correctly localised $83.8 \pm 1.1\%$ of the lesions. We evaluated prostate cancer detection performance on 300 exams from an external centre with histopathology-confirmed ground truth. Augmenting the training set with automatically labelled exams improved patient-based diagnostic area under the receiver operating characteristic curve from $88.1\pm 1.1\%$ to $89.8\pm 1.0\%$ ($P = 1.2 \cdot 10^{-4}$) and improved lesion-based sensitivity at one false positive per case from $79.2 \pm 2.8\%$ to $85.4 \pm 1.9\%$ ($P<10^{-4}$), with $mean \pm std.$ over 15 independent runs. This improved performance demonstrates the feasibility of our report-guided automatic annotations. Source code is made publicly available at https://github.com/DIAGNijmegen/Report-Guided-Annotation. Best csPCa detection algorithm is made available at https://grand-challenge.org/algorithms/bpmri-cspca-detection-report-guided-annotations/.
Patient Outcome and Zero-shot Diagnosis Prediction with Hypernetwork-guided Multitask Learning
Sep 07, 2021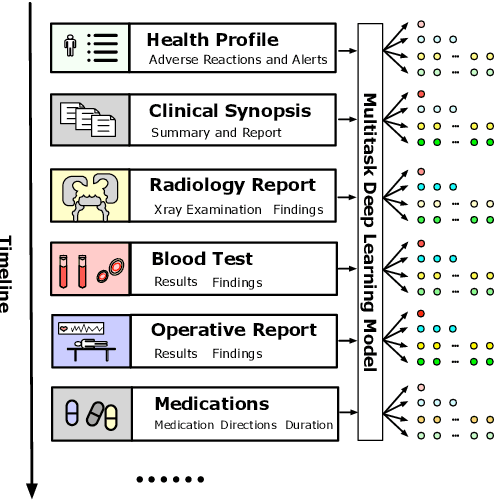

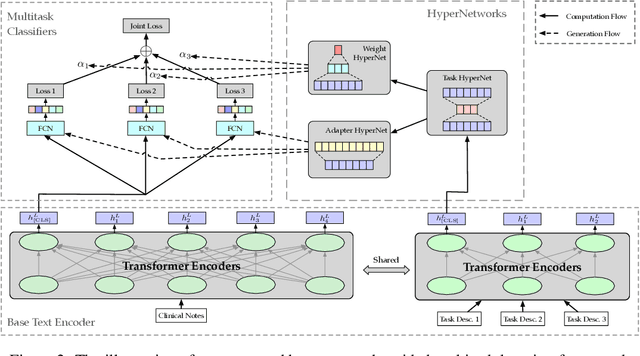
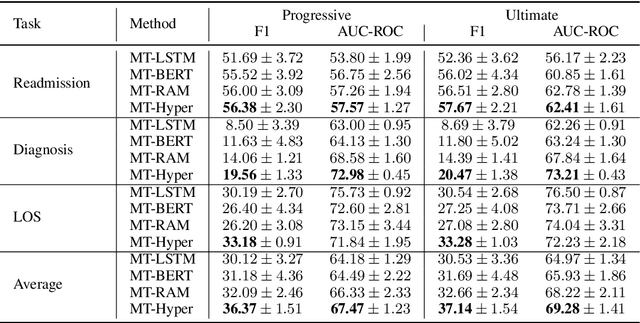
Multitask deep learning has been applied to patient outcome prediction from text, taking clinical notes as input and training deep neural networks with a joint loss function of multiple tasks. However, the joint training scheme of multitask learning suffers from inter-task interference, and diagnosis prediction among the multiple tasks has the generalizability issue due to rare diseases or unseen diagnoses. To solve these challenges, we propose a hypernetwork-based approach that generates task-conditioned parameters and coefficients of multitask prediction heads to learn task-specific prediction and balance the multitask learning. We also incorporate semantic task information to improves the generalizability of our task-conditioned multitask model. Experiments on early and discharge notes extracted from the real-world MIMIC database show our method can achieve better performance on multitask patient outcome prediction than strong baselines in most cases. Besides, our method can effectively handle the scenario with limited information and improve zero-shot prediction on unseen diagnosis categories.
Deep Self-Adaptive Hashing for Image Retrieval
Aug 16, 2021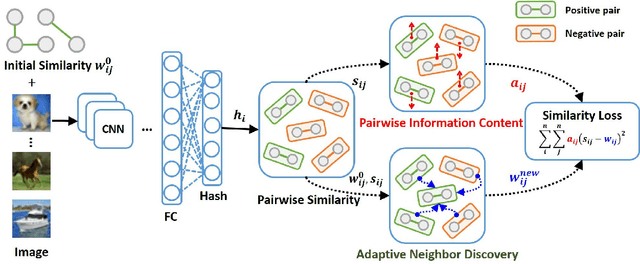
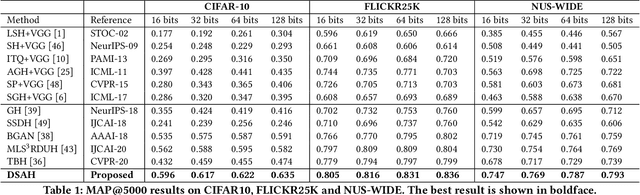
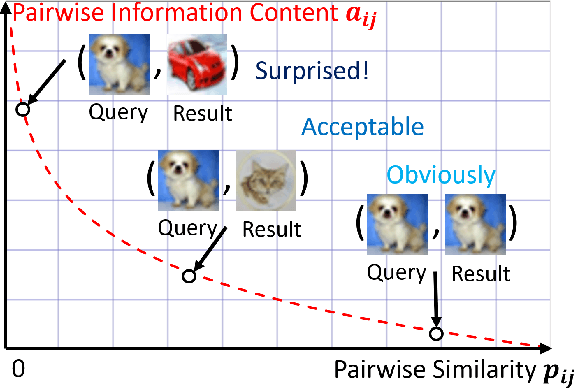
Hashing technology has been widely used in image retrieval due to its computational and storage efficiency. Recently, deep unsupervised hashing methods have attracted increasing attention due to the high cost of human annotations in the real world and the superiority of deep learning technology. However, most deep unsupervised hashing methods usually pre-compute a similarity matrix to model the pairwise relationship in the pre-trained feature space. Then this similarity matrix would be used to guide hash learning, in which most of the data pairs are treated equivalently. The above process is confronted with the following defects: 1) The pre-computed similarity matrix is inalterable and disconnected from the hash learning process, which cannot explore the underlying semantic information. 2) The informative data pairs may be buried by the large number of less-informative data pairs. To solve the aforementioned problems, we propose a \textbf{Deep Self-Adaptive Hashing~(DSAH)} model to adaptively capture the semantic information with two special designs: \textbf{Adaptive Neighbor Discovery~(AND)} and \textbf{Pairwise Information Content~(PIC)}. Firstly, we adopt the AND to initially construct a neighborhood-based similarity matrix, and then refine this initial similarity matrix with a novel update strategy to further investigate the semantic structure behind the learned representation. Secondly, we measure the priorities of data pairs with PIC and assign adaptive weights to them, which is relies on the assumption that more dissimilar data pairs contain more discriminative information for hash learning. Extensive experiments on several benchmark datasets demonstrate that the above two technologies facilitate the deep hashing model to achieve superior performance in a self-adaptive manner.
The Generalized Cascade Click Model: A Unified Framework for Estimating Click Models
Nov 22, 2021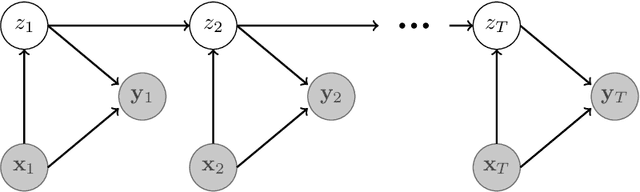
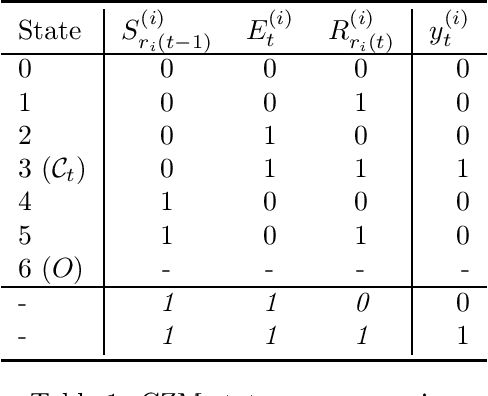
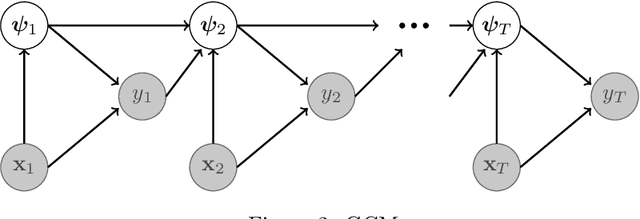
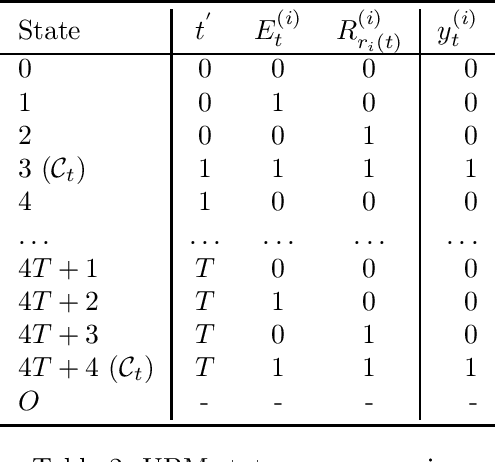
Given the vital importance of search engines to find digital information, there has been much scientific attention on how users interact with search engines, and how such behavior can be modeled. Many models on user - search engine interaction, which in the literature are known as click models, come in the form of Dynamic Bayesian Networks. Although many authors have used the resemblance between the different click models to derive estimation procedures for these models, in particular in the form of expectation maximization (EM), still this commonly requires considerable work, in particular when it comes to deriving the E-step. What we propose in this paper, is that this derivation is commonly unnecessary: many existing click models can in fact, under certain assumptions, be optimized as they were Input-Output Hidden Markov Models (IO-HMMs), for which the forward-backward equations immediately provide this E-step. To arrive at that conclusion, we will present the Generalized Cascade Model (GCM) and show how this model can be estimated using the IO-HMM EM framework, and provide two examples of how existing click models can be mapped to GCM. Our GCM approach to estimating click models has also been implemented in the gecasmo Python package.
Network Generation with Differential Privacy
Nov 17, 2021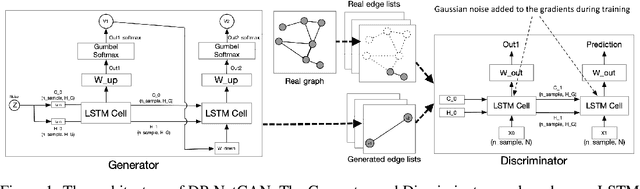
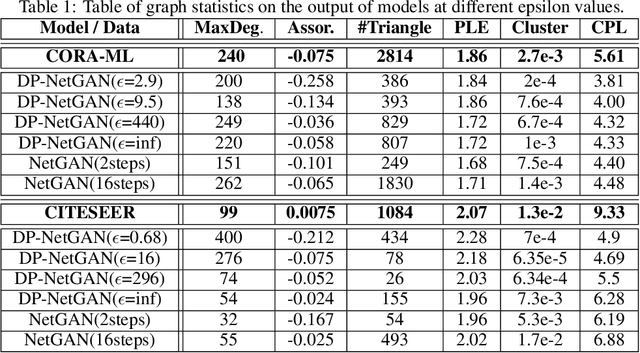
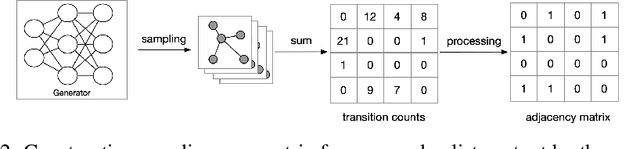
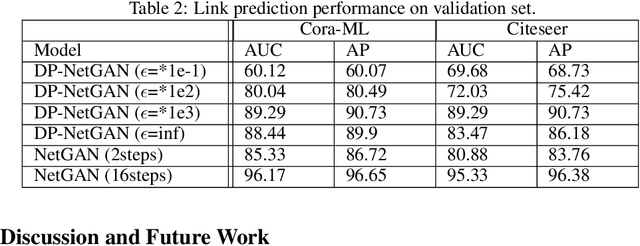
We consider the problem of generating private synthetic versions of real-world graphs containing private information while maintaining the utility of generated graphs. Differential privacy is a gold standard for data privacy, and the introduction of the differentially private stochastic gradient descent (DP-SGD) algorithm has facilitated the training of private neural models in a number of domains. Recent advances in graph generation via deep generative networks have produced several high performing models. We evaluate and compare state-of-the-art models including adjacency matrix based models and edge based models, and show a practical implementation that favours the edge-list approach utilizing the Gaussian noise mechanism when evaluated on commonly used graph datasets. Based on our findings, we propose a generative model that can reproduce the properties of real-world networks while maintaining edge-differential privacy. The proposed model is based on a stochastic neural network that generates discrete edge-list samples and is trained using the Wasserstein GAN objective with the DP-SGD optimizer. Being the first approach to combine these beneficial properties, our model contributes to further research on graph data privacy.
Green CWS: Extreme Distillation and Efficient Decode Method Towards Industrial Application
Nov 17, 2021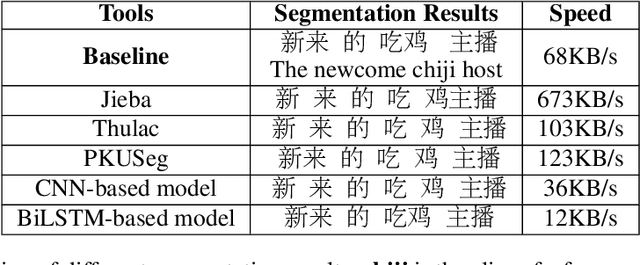
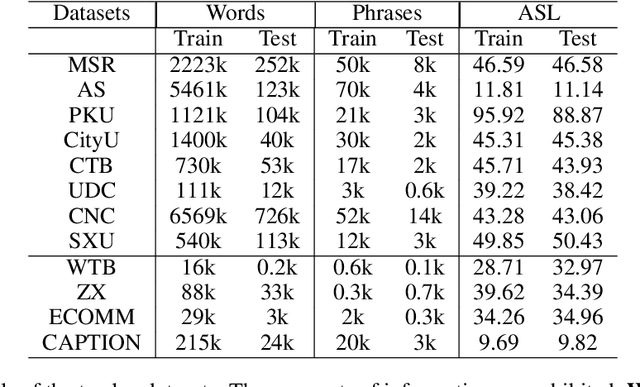
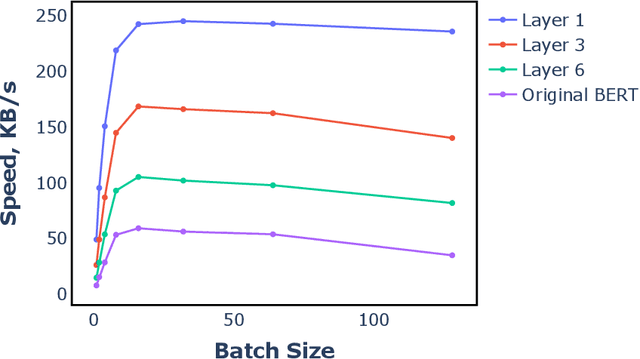
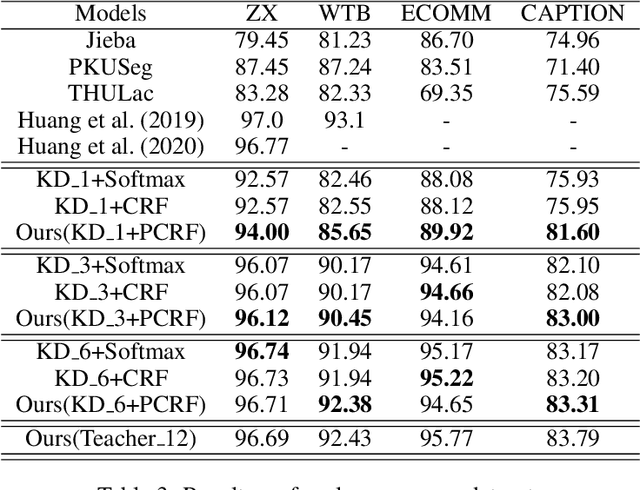
Benefiting from the strong ability of the pre-trained model, the research on Chinese Word Segmentation (CWS) has made great progress in recent years. However, due to massive computation, large and complex models are incapable of empowering their ability for industrial use. On the other hand, for low-resource scenarios, the prevalent decode method, such as Conditional Random Field (CRF), fails to exploit the full information of the training data. This work proposes a fast and accurate CWS framework that incorporates a light-weighted model and an upgraded decode method (PCRF) towards industrially low-resource CWS scenarios. First, we distill a Transformer-based student model as an encoder, which not only accelerates the inference speed but also combines open knowledge and domain-specific knowledge. Second, the perplexity score to evaluate the language model is fused into the CRF module to better identify the word boundaries. Experiments show that our work obtains relatively high performance on multiple datasets with as low as 14\% of time consumption compared with the original BERT-based model. Moreover, under the low-resource setting, we get superior results in comparison with the traditional decoding methods.
Trajectory Prediction using Generative Adversarial Network in Multi-Class Scenarios
Oct 18, 2021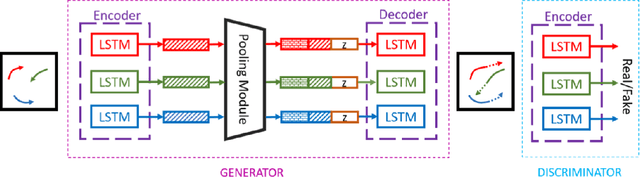
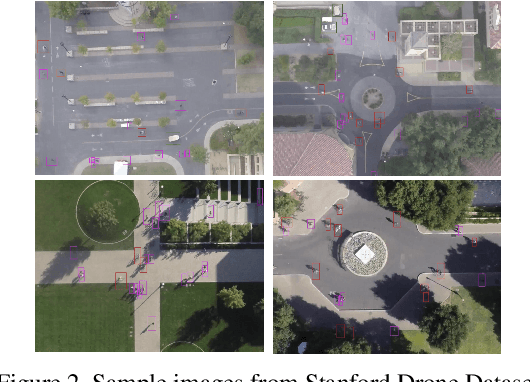
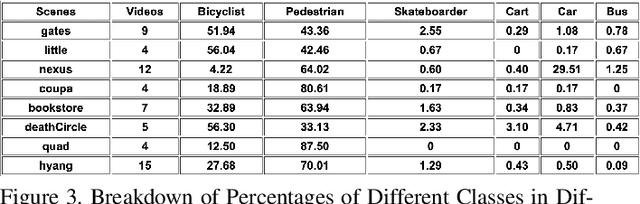
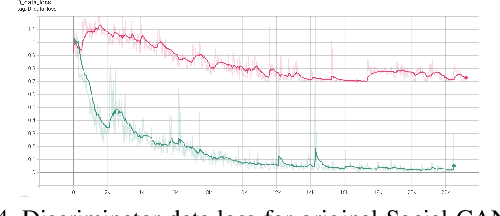
Predicting traffic agents' trajectories is an important task for auto-piloting. Most previous work on trajectory prediction only considers a single class of road agents. We use a sequence-to-sequence model to predict future paths from observed paths and we incorporate class information into the model by concatenating extracted label representations with traditional location inputs. We experiment with both LSTM and transformer encoders and we use generative adversarial network as introduced in Social GAN to learn the multi-modal behavior of traffic agents. We train our model on Stanford Drone dataset which includes 6 classes of road agents and evaluate the impact of different model components on the prediction performance in multi-class scenes.
Resource Allocation for IRS-Enabled Secure Multiuser Multi-Carrier Downlink URLLC Systems
Nov 27, 2021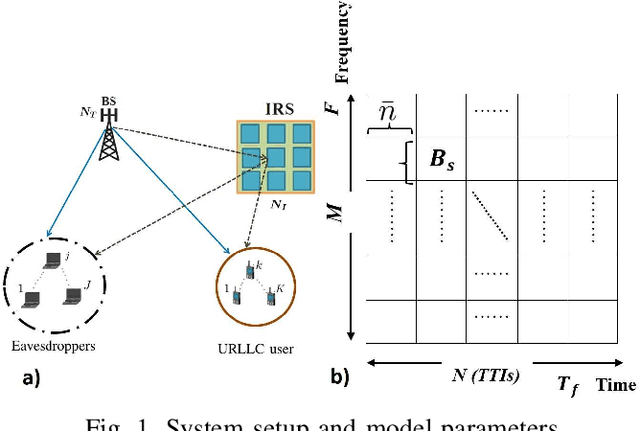
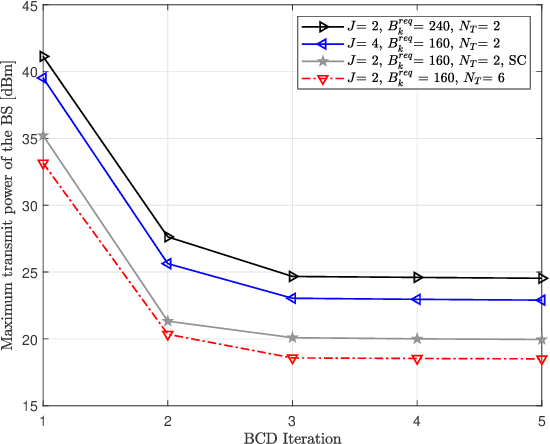
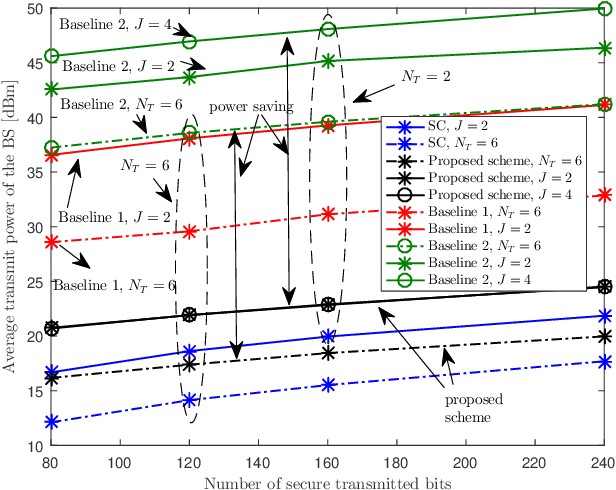
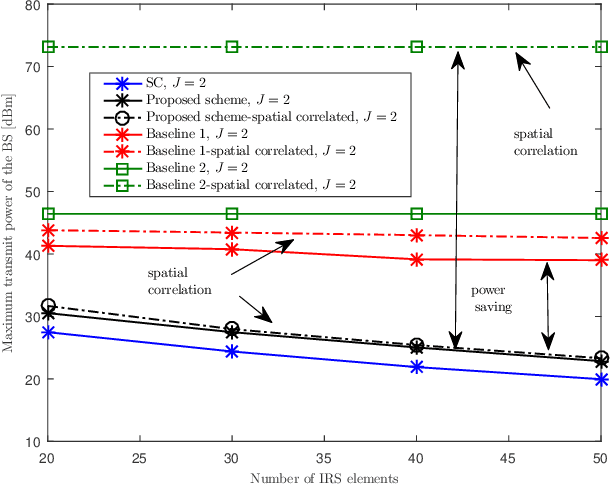
Secure ultra-reliable low-latency communication (URLLC) has been recently investigated with the fundamental limits of finite block length (FBL) regime in mind. Analysis has revealed that when eavesdroppers outnumber BS antennas or enjoy a more favorable channel condition compared to the legitimate users, base station (BS) transmit power should increase exorbitantly to meet quality of service (QoS) constraints. Channel-induced impairments such as shadowing and/or blockage pose a similar challenge. These practical considerations can drastically limit secure URLLC performance in FBL regime. Deployment of an intelligent reflecting surface (IRS) can endow such systems with much-needed resiliency and robustness to satisfy stringent latency, availability, and reliability requirements. We address this problem and propose a joint design of IRS platform and secure URLLC network. We minimize the total BS transmit power by simultaneously designing the beamformers and artificial noise at the BS and phase-shifts at the IRS, while guaranteeing the required number of securely transmitted bits with the desired packet error probability, information leakage, and maximum affordable delay. The proposed optimization problem is non-convex and we apply block coordinate descent and successive convex approximation to iteratively solve a series of convex sub-problems instead. The proposed algorithm converges to a sub-optimal solution in a few iterations and attains substantial power saving and robustness compared to baseline schemes.
Why Propagate Alone? Parallel Use of Labels and Features on Graphs
Oct 14, 2021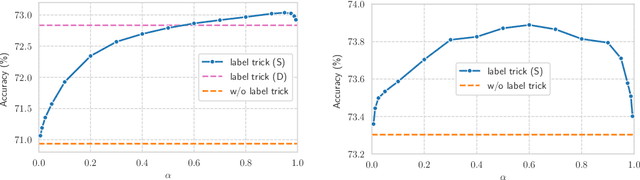



Graph neural networks (GNNs) and label propagation represent two interrelated modeling strategies designed to exploit graph structure in tasks such as node property prediction. The former is typically based on stacked message-passing layers that share neighborhood information to transform node features into predictive embeddings. In contrast, the latter involves spreading label information to unlabeled nodes via a parameter-free diffusion process, but operates independently of the node features. Given then that the material difference is merely whether features or labels are smoothed across the graph, it is natural to consider combinations of the two for improving performance. In this regard, it has recently been proposed to use a randomly-selected portion of the training labels as GNN inputs, concatenated with the original node features for making predictions on the remaining labels. This so-called label trick accommodates the parallel use of features and labels, and is foundational to many of the top-ranking submissions on the Open Graph Benchmark (OGB) leaderboard. And yet despite its wide-spread adoption, thus far there has been little attempt to carefully unpack exactly what statistical properties the label trick introduces into the training pipeline, intended or otherwise. To this end, we prove that under certain simplifying assumptions, the stochastic label trick can be reduced to an interpretable, deterministic training objective composed of two factors. The first is a data-fitting term that naturally resolves potential label leakage issues, while the second serves as a regularization factor conditioned on graph structure that adapts to graph size and connectivity. Later, we leverage this perspective to motivate a broader range of label trick use cases, and provide experiments to verify the efficacy of these extensions.
AoI-minimizing Scheduling in UAV-relayed IoT Networks
Jul 30, 2021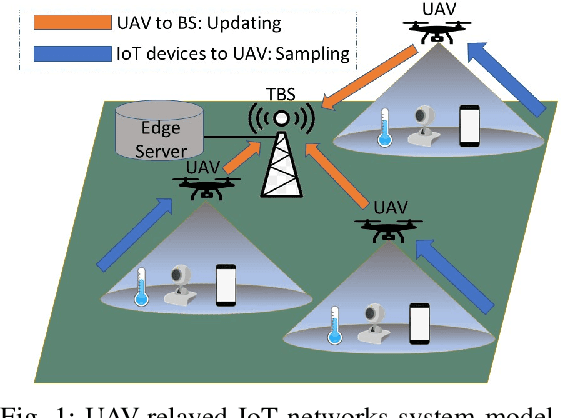
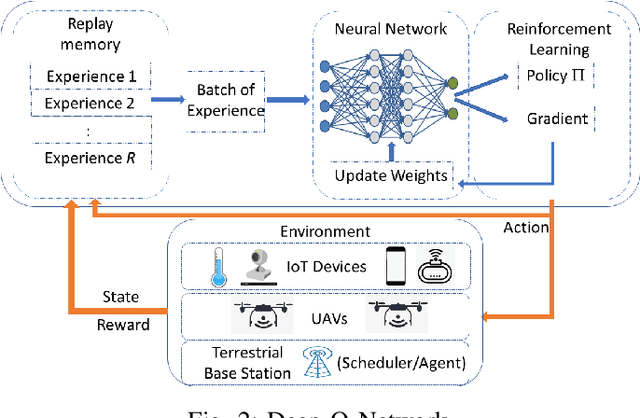
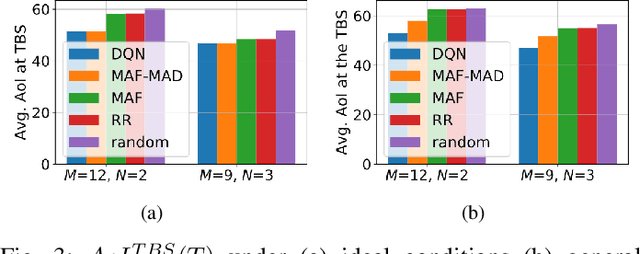
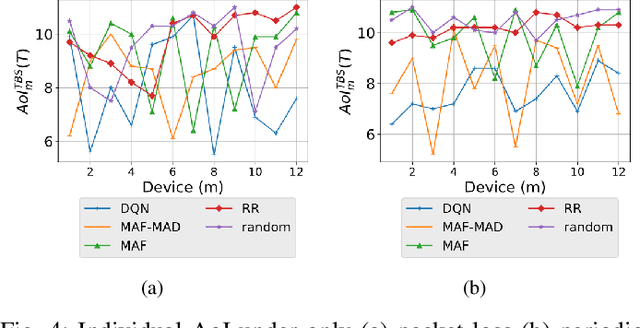
Due to flexibility, autonomy and low operational cost, unmanned aerial vehicles (UAVs), as fixed aerial base stations, are increasingly being used as \textit{relays} to collect time-sensitive information (i.e., status updates) from IoT devices and deliver it to the nearby terrestrial base station (TBS), where the information gets processed. In order to ensure timely delivery of information to the TBS (from all IoT devices), optimal scheduling of time-sensitive information over two hop UAV-relayed IoT networks (i.e., IoT device to the UAV [hop 1], and UAV to the TBS [hop 2]) becomes a critical challenge. To address this, we propose scheduling policies for Age of Information (AoI) minimization in such two-hop UAV-relayed IoT networks. To this end, we present a low-complexity MAF-MAD scheduler, that employs Maximum AoI First (MAF) policy for sampling of IoT devices at UAV (hop 1) and Maximum AoI Difference (MAD) policy for updating sampled packets from UAV to the TBS (hop 2). We show that MAF-MAD is the optimal scheduler under ideal conditions, i.e., error-free channels and generate-at-will traffic generation at IoT devices. On the contrary, for realistic conditions, we propose a Deep-Q-Networks (DQN) based scheduler. Our simulation results show that DQN-based scheduler outperforms MAF-MAD scheduler and three other baseline schedulers, i.e., Maximal AoI First (MAF), Round Robin (RR) and Random, employed at both hops under general conditions when the network is small (with 10's of IoT devices). However, it does not scale well with network size whereas MAF-MAD outperforms all other schedulers under all considered scenarios for larger networks.