 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CaT: Weakly Supervised Object Detection with Category Transfer
Aug 17, 2021
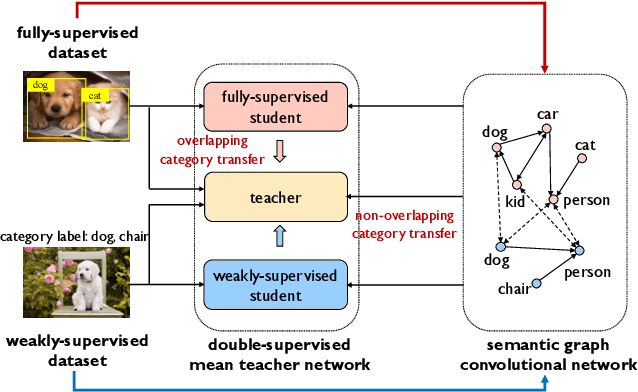
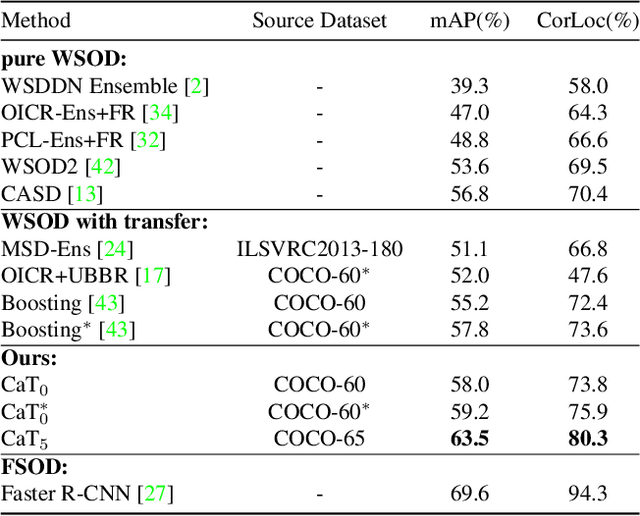
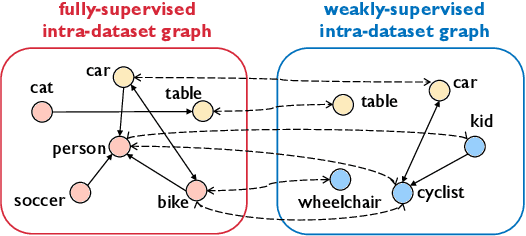
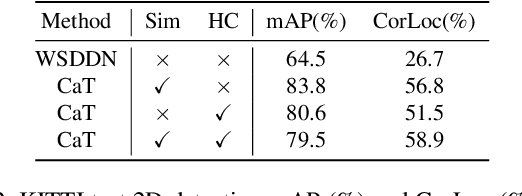
A large gap exists between fully-supervised object detection and weakly-supervised object detection. To narrow this gap, some methods consider knowledge transfer from additional fully-supervised dataset. But these methods do not fully exploit discriminative category information in the fully-supervised dataset, thus causing low mAP. To solve this issue, we propose a novel category transfer framework for weakly supervised object detection. The intuition is to fully leverage both visually-discriminative and semantically-correlated category information in the fully-supervised dataset to enhance the object-classification ability of a weakly-supervised detector. To handle overlapping category transfer, we propose a double-supervision mean teacher to gather common category information and bridge the domain gap between two datasets. To handle non-overlapping category transfer, we propose a semantic graph convolutional network to promote the aggregation of semantic features between correlated categories. Experiments are conducted with Pascal VOC 2007 as the target weakly-supervised dataset and COCO as the source fully-supervised dataset. Our category transfer framework achieves 63.5% mAP and 80.3% CorLoc with 5 overlapping categories between two datasets, which outperforms the state-of-the-art methods. Codes are avaliable at https://github.com/MediaBrain-SJTU/CaT.
Merging Models with Fisher-Weighted Averaging
Nov 18, 2021

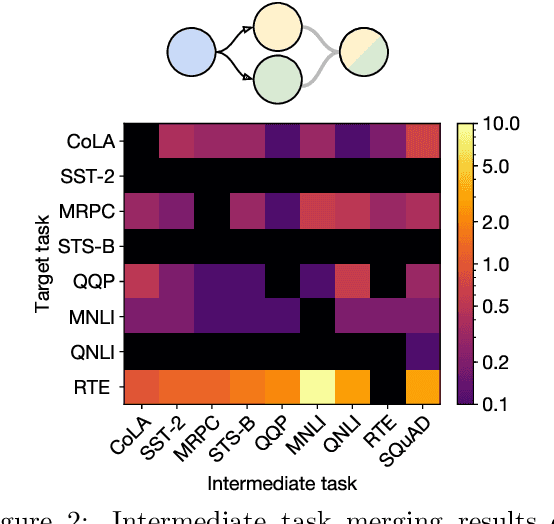
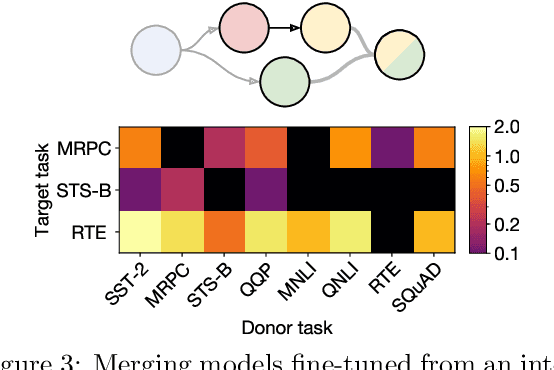
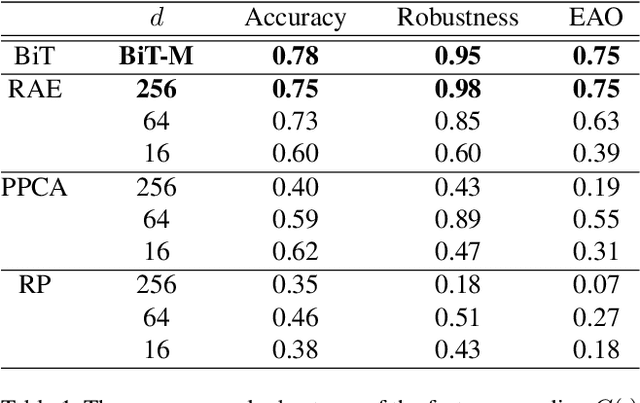
Transfer learning provides a way of leveraging knowledge from one task when learning another task. Performing transfer learning typically involves iteratively updating a model's parameters through gradient descent on a training dataset. In this paper, we introduce a fundamentally different method for transferring knowledge across models that amounts to "merging" multiple models into one. Our approach effectively involves computing a weighted average of the models' parameters. We show that this averaging is equivalent to approximately sampling from the posteriors of the model weights. While using an isotropic Gaussian approximation works well in some cases, we also demonstrate benefits by approximating the precision matrix via the Fisher information. In sum, our approach makes it possible to combine the "knowledge" in multiple models at an extremely low computational cost compared to standard gradient-based training. We demonstrate that model merging achieves comparable performance to gradient descent-based transfer learning on intermediate-task training and domain adaptation problems. We also show that our merging procedure makes it possible to combine models in previously unexplored ways. To measure the robustness of our approach, we perform an extensive ablation on the design of our algorithm.
Development of an R-Mode Simulator Using MF DGNSS Signals
Aug 21, 2021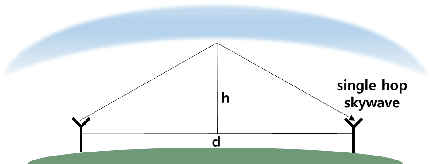
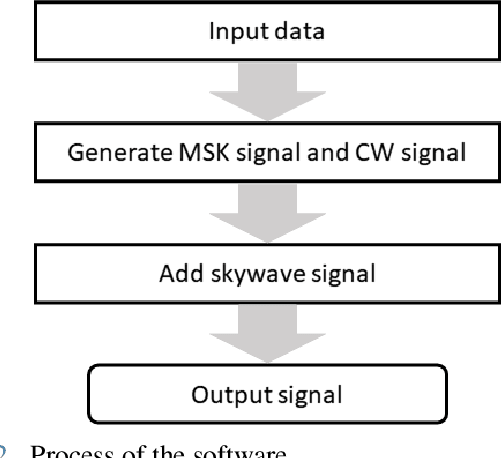
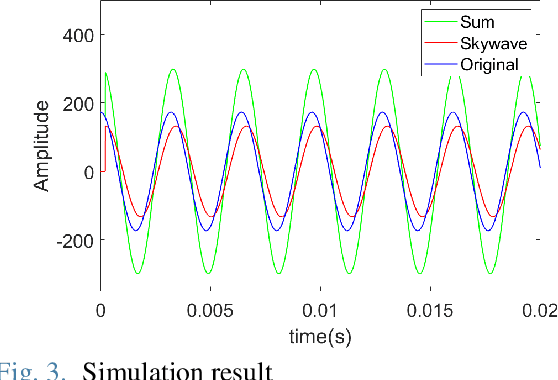
With the development of positioning, navigation, and timing (PNT) information-based industries, PNT information is becoming increasingly important. Therefore, various navigation studies have been actively conducted to back up global positioning system (GPS) in scenarios in which it is disabled. Ranging using signals of opportunity (SoOP) has the advantage of infrastructure already being in place. Among them, the ranging mode (R-Mode) is a technology that uses available SoOPs such as a medium frequency (MF) differential global navigation satellite System (DGNSS) signal that has recently been recognized for its potential for navigation and is currently under research. In this study, we developed a signal simulator that considers the characteristics of MF DGNSS signals and skywaves used in R-Mode.
Using Deep Learning to Identify Patients with Cognitive Impairment in Electronic Health Records
Nov 13, 2021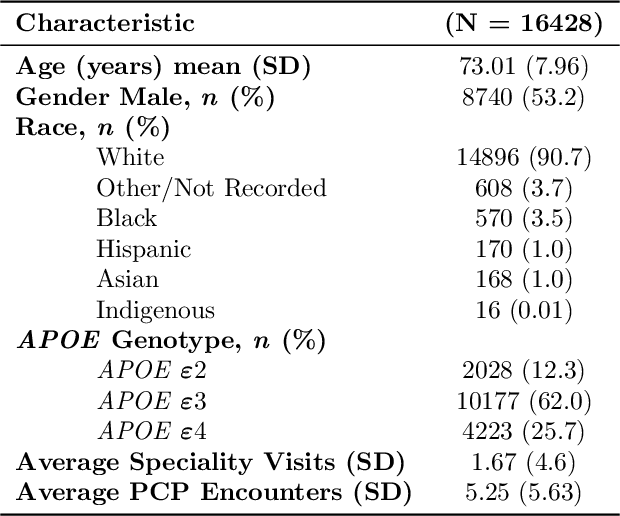



Dementia is a neurodegenerative disorder that causes cognitive decline and affects more than 50 million people worldwide. Dementia is under-diagnosed by healthcare professionals - only one in four people who suffer from dementia are diagnosed. Even when a diagnosis is made, it may not be entered as a structured International Classification of Diseases (ICD) diagnosis code in a patient's charts. Information relevant to cognitive impairment (CI) is often found within electronic health records (EHR), but manual review of clinician notes by experts is both time consuming and often prone to errors. Automated mining of these notes presents an opportunity to label patients with cognitive impairment in EHR data. We developed natural language processing (NLP) tools to identify patients with cognitive impairment and demonstrate that linguistic context enhances performance for the cognitive impairment classification task. We fine-tuned our attention based deep learning model, which can learn from complex language structures, and substantially improved accuracy (0.93) relative to a baseline NLP model (0.84). Further, we show that deep learning NLP can successfully identify dementia patients without dementia-related ICD codes or medications.
Q-Net: A Quantitative Susceptibility Mapping-based Deep Neural Network for Differential Diagnosis of Brain Iron Deposition in Hemochromatosis
Oct 01, 2021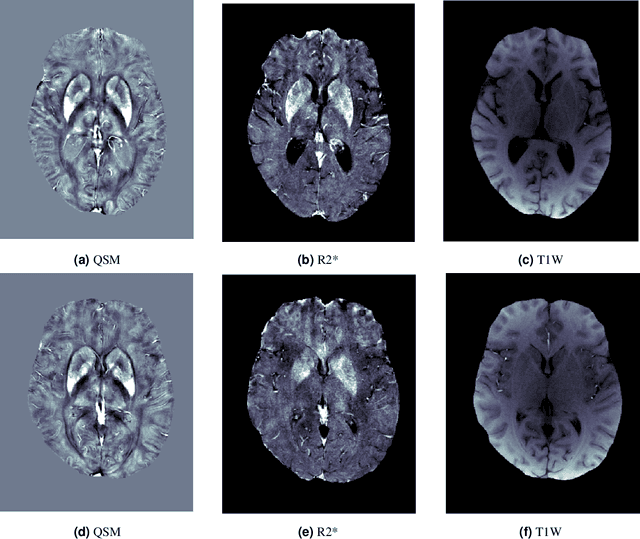

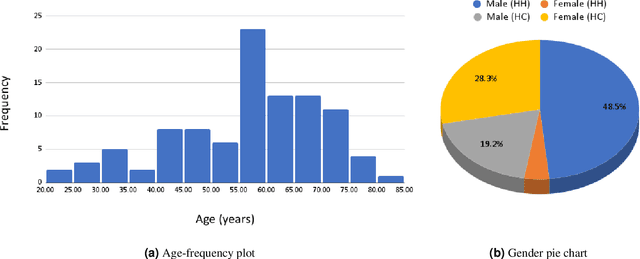
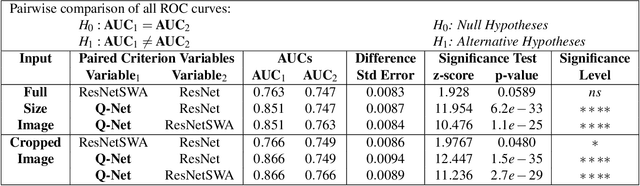
Brain iron deposition, in particular deep gray matter nuclei, increases with advancing age. Hereditary Hemochromatosis (HH) is the most common inherited disorder of systemic iron excess in Europeans and recent studies claimed high brain iron accumulation in patient with Hemochromatosis. In this study, we focus on Artificial Intelligence (AI)-based differential diagnosis of brain iron deposition in HH via Quantitative Susceptibility Mapping (QSM), which is an established Magnetic Resonance Imaging (MRI) technique to study the distribution of iron in the brain. Our main objective is investigating potentials of AI-driven frameworks to accurately and efficiently differentiate individuals with Hemochromatosis from those of the healthy control group. More specifically, we developed the Q-Net framework, which is a data-driven model that processes information on iron deposition in the brain obtained from multi-echo gradient echo imaging data and anatomical information on T1-Weighted images of the brain. We illustrate that the Q-Net framework can assist in differentiating between someone with HH and Healthy control (HC) of the same age, something that is not possible by just visualizing images. The study is performed based on a unique dataset that was collected from 52 subjects with HH and 47 HC. The Q-Net provides a differential diagnosis accuracy of 83.16% and 80.37% in the scan-level and image-level classification, respectively.
Dense Deep Unfolding Network with 3D-CNN Prior for Snapshot Compressive Imaging
Sep 14, 2021
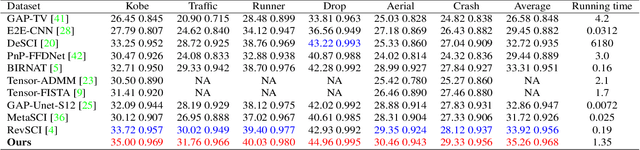
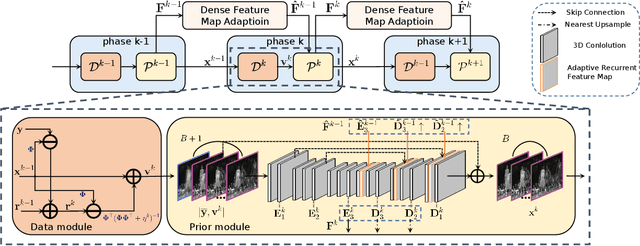
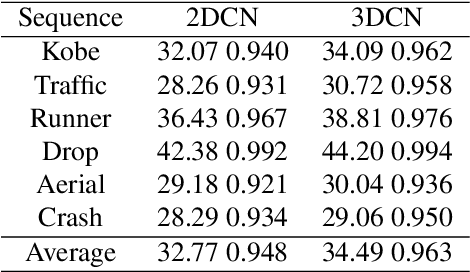
Snapshot compressive imaging (SCI) aims to record three-dimensional signals via a two-dimensional camera. For the sake of building a fast and accurate SCI recovery algorithm, we incorporate the interpretability of model-based methods and the speed of learning-based ones and present a novel dense deep unfolding network (DUN) with 3D-CNN prior for SCI, where each phase is unrolled from an iteration of Half-Quadratic Splitting (HQS). To better exploit the spatial-temporal correlation among frames and address the problem of information loss between adjacent phases in existing DUNs, we propose to adopt the 3D-CNN prior in our proximal mapping module and develop a novel dense feature map (DFM) strategy, respectively. Besides, in order to promote network robustness, we further propose a dense feature map adaption (DFMA) module to allow inter-phase information to fuse adaptively. All the parameters are learned in an end-to-end fashion. Extensive experiments on simulation data and real data verify the superiority of our method. The source code is available at https://github.com/jianzhangcs/SCI3D.
Multi-Cue Adaptive Emotion Recognition Network
Nov 03, 2021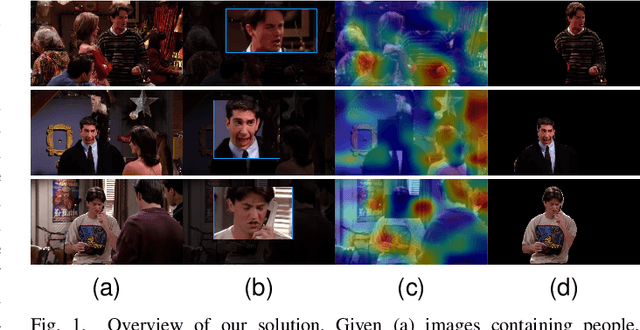
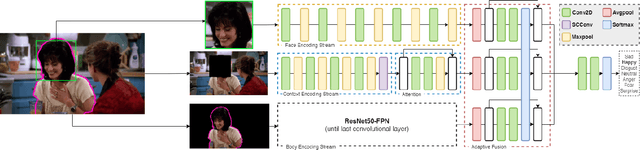
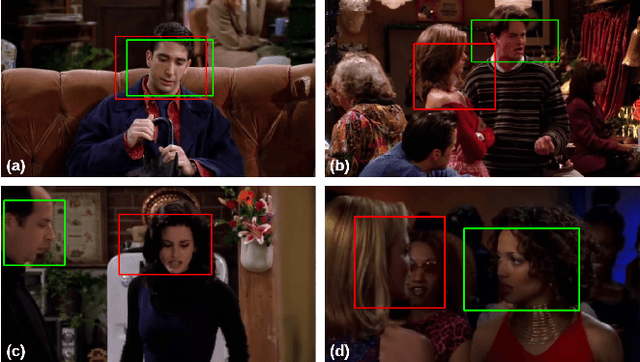

Expressing and identifying emotions through facial and physical expressions is a significant part of social interaction. Emotion recognition is an essential task in computer vision due to its various applications and mainly for allowing a more natural interaction between humans and machines. The common approaches for emotion recognition focus on analyzing facial expressions and requires the automatic localization of the face in the image. Although these methods can correctly classify emotion in controlled scenarios, such techniques are limited when dealing with unconstrained daily interactions. We propose a new deep learning approach for emotion recognition based on adaptive multi-cues that extract information from context and body poses, which humans commonly use in social interaction and communication. We compare the proposed approach with the state-of-art approaches in the CAER-S dataset, evaluating different components in a pipeline that reached an accuracy of 89.30%
Probabilistic Tracking with Deep Factors
Dec 02, 2021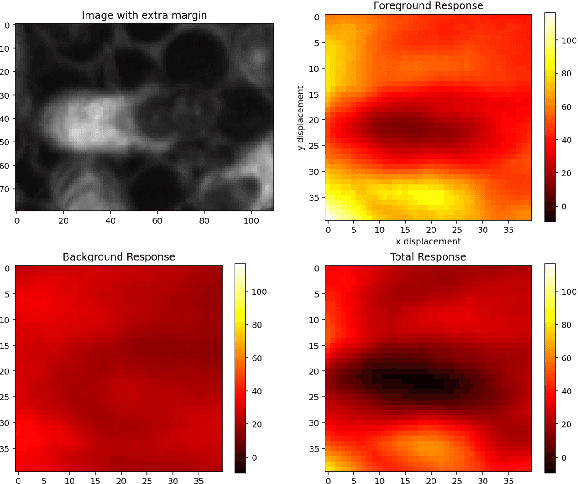
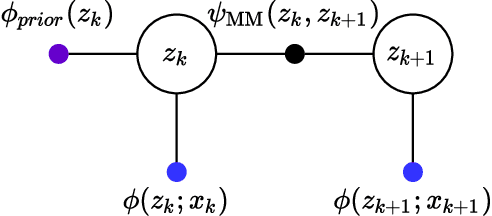

In many applications of computer vision it is important to accurately estimate the trajectory of an object over time by fusing data from a number of sources, of which 2D and 3D imagery is only one. In this paper, we show how to use a deep feature encoding in conjunction with generative densities over the features in a factor-graph based, probabilistic tracking framework. We present a likelihood model that combines a learned feature encoder with generative densities over them, both trained in a supervised manner. We also experiment with directly inferring probability through the use of image classification models that feed into the likelihood formulation. These models are used to implement deep factors that are added to the factor graph to complement other factors that represent domain-specific knowledge such as motion models and/or other prior information. Factors are then optimized together in a non-linear least-squares tracking framework that takes the form of an Extended Kalman Smoother with a Gaussian prior. A key feature of our likelihood model is that it leverages the Lie group properties of the tracked target's pose to apply the feature encoding on an image patch, extracted through a differentiable warp function inspired by spatial transformer networks. To illustrate the proposed approach we evaluate it on a challenging social insect behavior dataset, and show that using deep features does outperform these earlier linear appearance models used in this setting.
Empowerment-driven Exploration using Mutual Information Estimation
Oct 11, 2018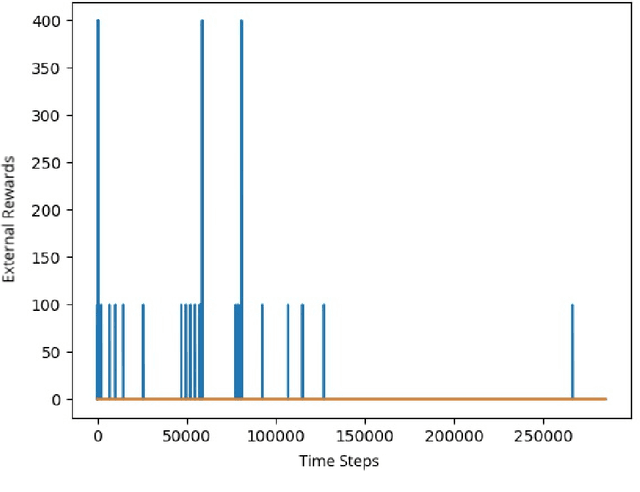
Exploration is a difficult challenge in reinforcement learning and is of prime importance in sparse reward environments. However, many of the state of the art deep reinforcement learning algorithms, that rely on epsilon-greedy, fail on these environments. In such cases, empowerment can serve as an intrinsic reward signal to enable the agent to maximize the influence it has over the near future. We formulate empowerment as the channel capacity between states and actions and is calculated by estimating the mutual information between the actions and the following states. The mutual information is estimated using Mutual Information Neural Estimator and a forward dynamics model. We demonstrate that an empowerment driven agent is able to improve significantly the score of a baseline DQN agent on the game of Montezuma's Revenge.
Learnable Adaptive Cosine Estimator (LACE) for Image Classification
Oct 15, 2021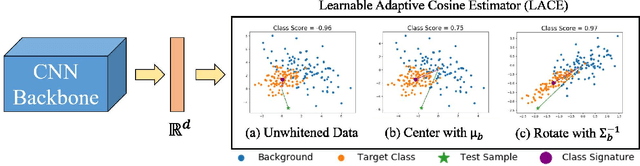
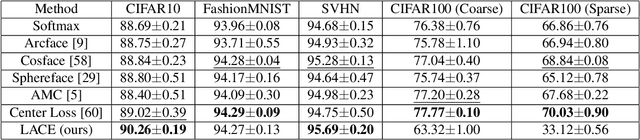
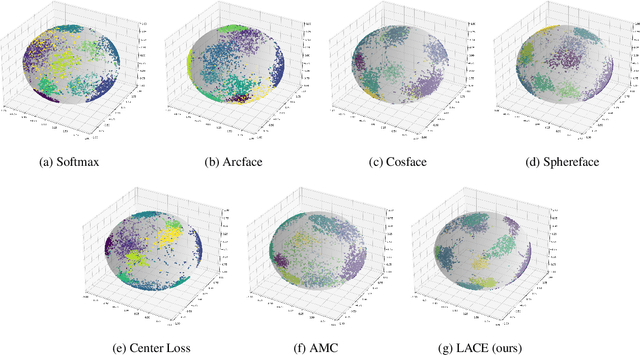
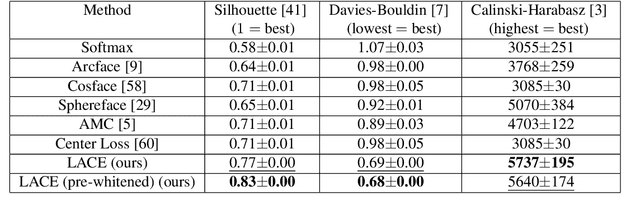
In this work, we propose a new loss to improve feature discriminability and classification performance. Motivated by the adaptive cosine/coherence estimator (ACE), our proposed method incorporates angular information that is inherently learned by artificial neural networks. Our learnable ACE (LACE) transforms the data into a new "whitened" space that improves the inter-class separability and intra-class compactness. We compare our LACE to alternative state-of-the art softmax-based and feature regularization approaches. Our results show that the proposed method can serve as a viable alternative to cross entropy and angular softmax approaches. Our code is publicly available: https://github.com/GatorSense/LACE.