 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Source Free Unsupervised Graph Domain Adaptation
Dec 03, 2021
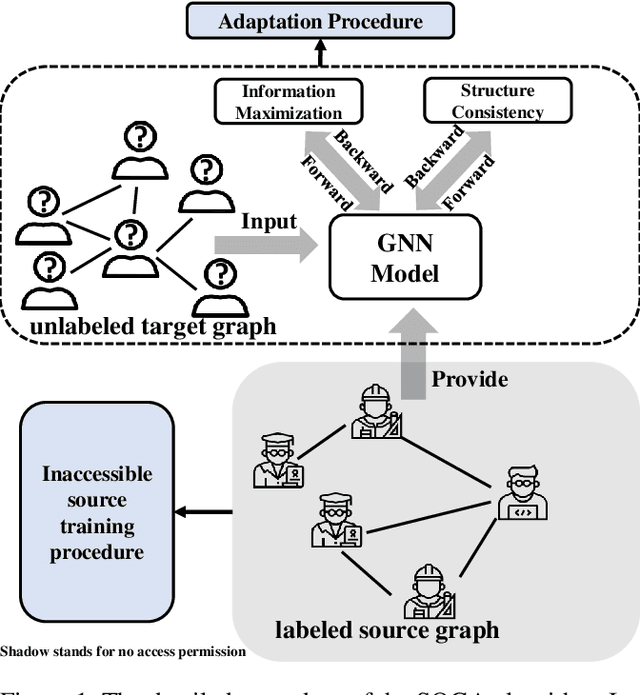
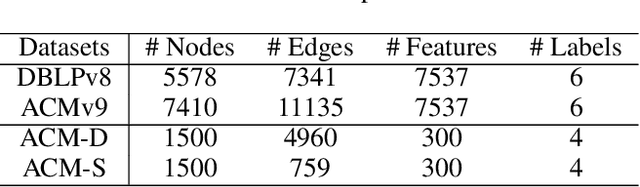
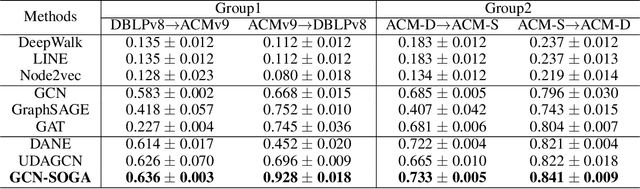
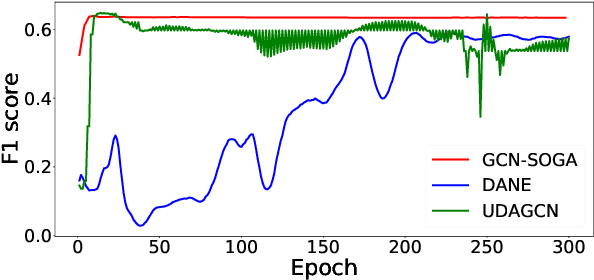
Graph Neural Networks (GNNs) have achieved great success on a variety of tasks with graph-structural data, among which node classification is an essential one. Unsupervised Graph Domain Adaptation (UGDA) shows its practical value of reducing the labeling cost for node classification. It leverages knowledge from a labeled graph (i.e., source domain) to tackle the same task on another unlabeled graph (i.e., target domain). Most existing UGDA methods heavily rely on the labeled graph in the source domain. They utilize labels from the source domain as the supervision signal and are jointly trained on both the source graph and the target graph. However, in some real-world scenarios, the source graph is inaccessible because of either unavailability or privacy issues. Therefore, we propose a novel scenario named Source Free Unsupervised Graph Domain Adaptation (SFUGDA). In this scenario, the only information we can leverage from the source domain is the well-trained source model, without any exposure to the source graph and its labels. As a result, existing UGDA methods are not feasible anymore. To address the non-trivial adaptation challenges in this practical scenario, we propose a model-agnostic algorithm for domain adaptation to fully exploit the discriminative ability of the source model while preserving the consistency of structural proximity on the target graph. We prove the effectiveness of the proposed algorithm both theoretically and empirically. The experimental results on four cross-domain tasks show consistent improvements of the Macro-F1 score up to 0.17.
Improving Predictions of Tail-end Labels using Concatenated BioMed-Transformers for Long Medical Documents
Dec 03, 2021
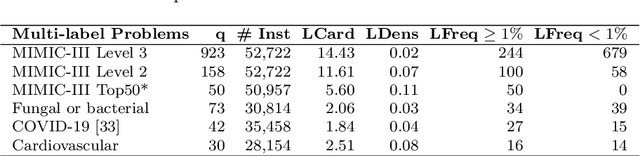
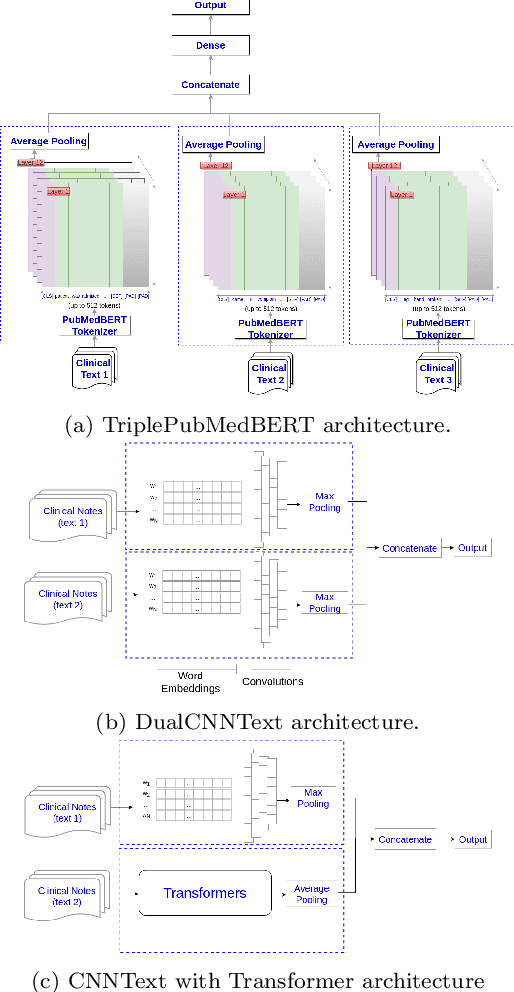
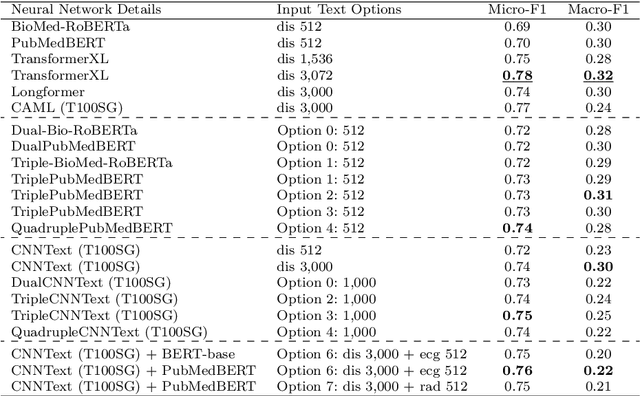
Multi-label learning predicts a subset of labels from a given label set for an unseen instance while considering label correlations. A known challenge with multi-label classification is the long-tailed distribution of labels. Many studies focus on improving the overall predictions of the model and thus do not prioritise tail-end labels. Improving the tail-end label predictions in multi-label classifications of medical text enables the potential to understand patients better and improve care. The knowledge gained by one or more infrequent labels can impact the cause of medical decisions and treatment plans. This research presents variations of concatenated domain-specific language models, including multi-BioMed-Transformers, to achieve two primary goals. First, to improve F1 scores of infrequent labels across multi-label problems, especially with long-tail labels; second, to handle long medical text and multi-sourced electronic health records (EHRs), a challenging task for standard transformers designed to work on short input sequences. A vital contribution of this research is new state-of-the-art (SOTA) results obtained using TransformerXL for predicting medical codes. A variety of experiments are performed on the Medical Information Mart for Intensive Care (MIMIC-III) database. Results show that concatenated BioMed-Transformers outperform standard transformers in terms of overall micro and macro F1 scores and individual F1 scores of tail-end labels, while incurring lower training times than existing transformer-based solutions for long input sequences.
An Analytical Lidar Sensor Model Based on Ray Path Information
Oct 23, 2019
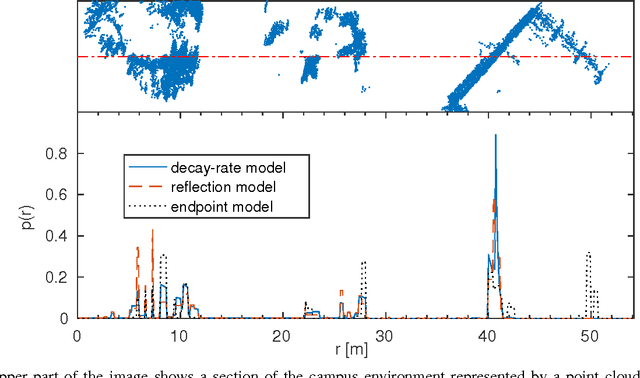


Two core competencies of a mobile robot are to build a map of the environment and to estimate its own pose on the basis of this map and incoming sensor readings. To account for the uncertainties in this process, one typically employs probabilistic state estimation approaches combined with a model of the specific sensor. Over the past years, lidar sensors have become a popular choice for mapping and localization. However, many common lidar models perform poorly in unstructured, unpredictable environments, they lack a consistent physical model for both mapping and localization, and they do not exploit all the information the sensor provides, e.g. out-of-range measurements. In this paper, we introduce a consistent physical model that can be applied to mapping as well as to localization. It naturally deals with unstructured environments and makes use of both out-of-range measurements and information about the ray path. The approach can be seen as a generalization of the well-established reflection model, but in addition to counting ray reflections and traversals in a specific map cell, it considers the distances that all rays travel inside this cell. We prove that the resulting map maximizes the data likelihood and demonstrate that our model outperforms state-of-the-art sensor models in extensive real-world experiments.
* 8 pages
Improving Text-Independent Speaker Verification with Auxiliary Speakers Using Graph
Sep 20, 2021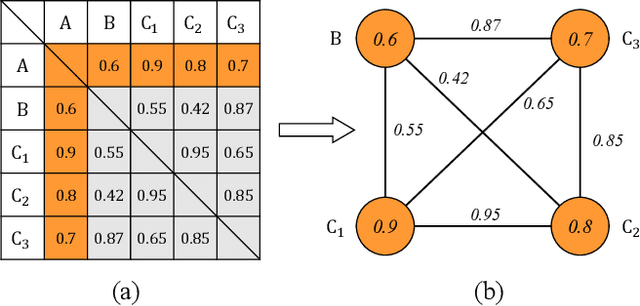
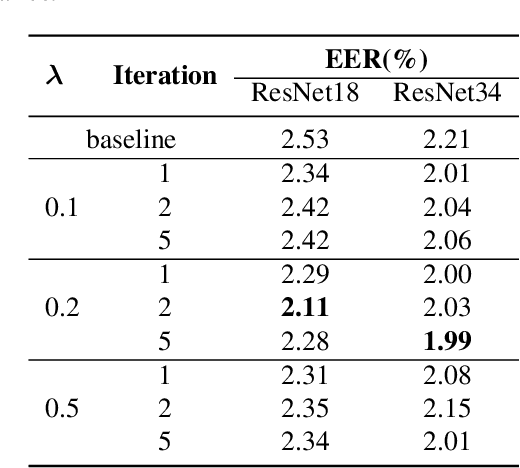
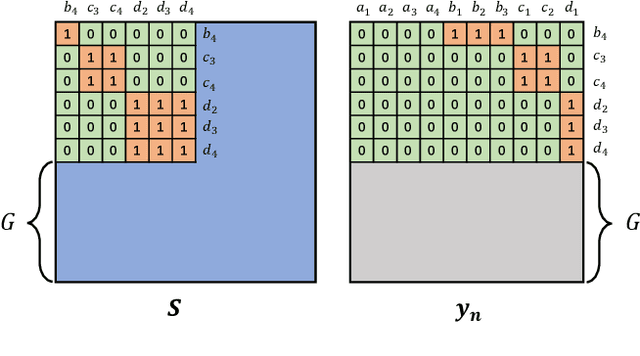
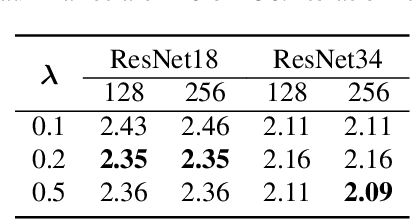
The paper presents a novel approach to refining similarity scores between input utterances for robust speaker verification. Given the embeddings from a pair of input utterances, a graph model is designed to incorporate additional information from a group of embeddings representing the so-called auxiliary speakers. The relations between the input utterances and the auxiliary speakers are represented by the edges and vertices in the graph. The similarity scores are refined by iteratively updating the values of the graph's vertices using an algorithm similar to the random walk algorithm on graphs. Through this updating process, the information of auxiliary speakers is involved in determining the relation between input utterances and hence contributing to the verification process. We propose to create a set of artificial embeddings through the model training process. Utilizing the generated embeddings as auxiliary speakers, no extra data are required for the graph model in the verification stage. The proposed model is trained in an end-to-end manner within the whole system. Experiments are carried out with the Voxceleb datasets. The results indicate that involving auxiliary speakers with graph is effective to improve speaker verification performance.
A study on information behavior of scholars for article keywords selection
Jan 27, 2021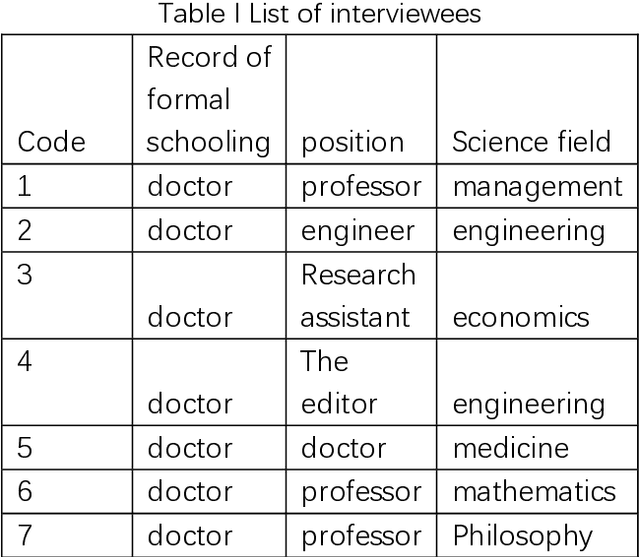
This project takes the factors of keyword selection behavior as the research object. Qualitative analysis methods such as interview and grounded theory were used to construct causal influence path model. Combined with computer simulation technology such as multi-agent simulation experiment method was used to study the factors of keyword selection from two dimensions of individual to group. The research was carried out according to the path of factor analysis at individual level macro situation simulation optimization of scientific research data management. Based on the aforementioned review of existing researches and explanations of keywords selection, this study adopts a qualitative research design to expand the explanation, and macro simulation based on the results of qualitative research. There are two steps in this study, one is do interview with authors and then design macro simulation according the deductive and qualitative content analysis results.
Intelligence, physics and information -- the tradeoff between accuracy and simplicity in machine learning
Jan 20, 2020How can we enable machines to make sense of the world, and become better at learning? To approach this goal, I believe viewing intelligence in terms of many integral aspects, and also a universal two-term tradeoff between task performance and complexity, provides two feasible perspectives. In this thesis, I address several key questions in some aspects of intelligence, and study the phase transitions in the two-term tradeoff, using strategies and tools from physics and information. Firstly, how can we make the learning models more flexible and efficient, so that agents can learn quickly with fewer examples? Inspired by how physicists model the world, we introduce a paradigm and an AI Physicist agent for simultaneously learning many small specialized models (theories) and the domain they are accurate, which can then be simplified, unified and stored, facilitating few-shot learning in a continual way. Secondly, for representation learning, when can we learn a good representation, and how does learning depend on the structure of the dataset? We approach this question by studying phase transitions when tuning the tradeoff hyperparameter. In the information bottleneck, we theoretically show that these phase transitions are predictable and reveal structure in the relationships between the data, the model, the learned representation and the loss landscape. Thirdly, how can agents discover causality from observations? We address part of this question by introducing an algorithm that combines prediction and minimizing information from the input, for exploratory causal discovery from observational time series. Fourthly, to make models more robust to label noise, we introduce Rank Pruning, a robust algorithm for classification with noisy labels. I believe that building on the work of my thesis we will be one step closer to enable more intelligent machines that can make sense of the world.
Combining 3D Image and Tabular Data via the Dynamic Affine Feature Map Transform
Jul 13, 2021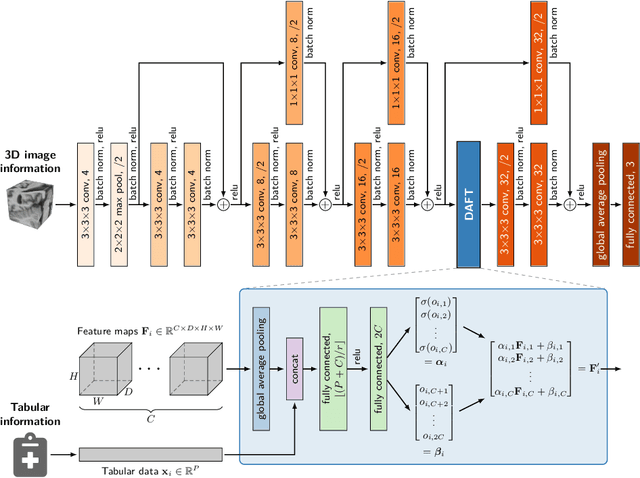

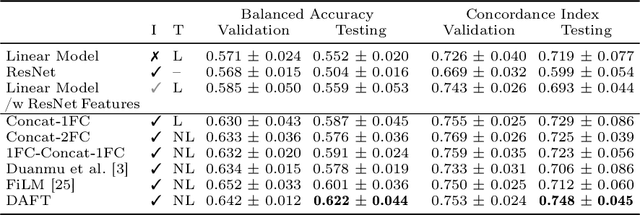
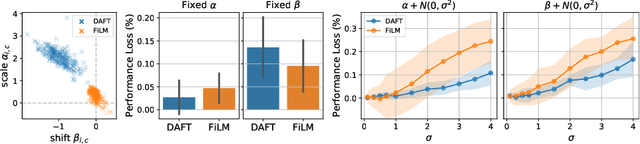
Prior work on diagnosing Alzheimer's disease from magnetic resonance images of the brain established that convolutional neural networks (CNNs) can leverage the high-dimensional image information for classifying patients. However, little research focused on how these models can utilize the usually low-dimensional tabular information, such as patient demographics or laboratory measurements. We introduce the Dynamic Affine Feature Map Transform (DAFT), a general-purpose module for CNNs that dynamically rescales and shifts the feature maps of a convolutional layer, conditional on a patient's tabular clinical information. We show that DAFT is highly effective in combining 3D image and tabular information for diagnosis and time-to-dementia prediction, where it outperforms competing CNNs with a mean balanced accuracy of 0.622 and mean c-index of 0.748, respectively. Our extensive ablation study provides valuable insights into the architectural properties of DAFT. Our implementation is available at https://github.com/ai-med/DAFT.
Merging Models with Fisher-Weighted Averaging
Nov 18, 2021

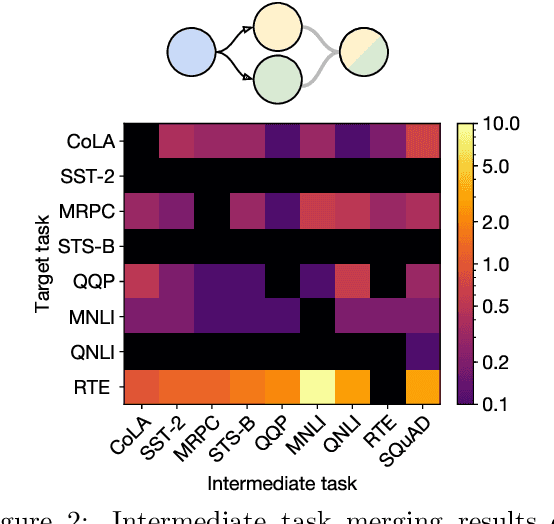
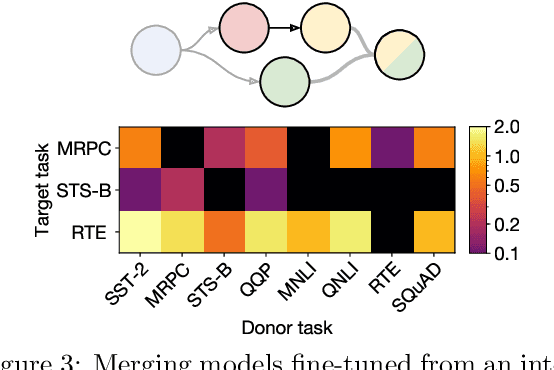
Transfer learning provides a way of leveraging knowledge from one task when learning another task. Performing transfer learning typically involves iteratively updating a model's parameters through gradient descent on a training dataset. In this paper, we introduce a fundamentally different method for transferring knowledge across models that amounts to "merging" multiple models into one. Our approach effectively involves computing a weighted average of the models' parameters. We show that this averaging is equivalent to approximately sampling from the posteriors of the model weights. While using an isotropic Gaussian approximation works well in some cases, we also demonstrate benefits by approximating the precision matrix via the Fisher information. In sum, our approach makes it possible to combine the "knowledge" in multiple models at an extremely low computational cost compared to standard gradient-based training. We demonstrate that model merging achieves comparable performance to gradient descent-based transfer learning on intermediate-task training and domain adaptation problems. We also show that our merging procedure makes it possible to combine models in previously unexplored ways. To measure the robustness of our approach, we perform an extensive ablation on the design of our algorithm.
CaT: Weakly Supervised Object Detection with Category Transfer
Aug 17, 2021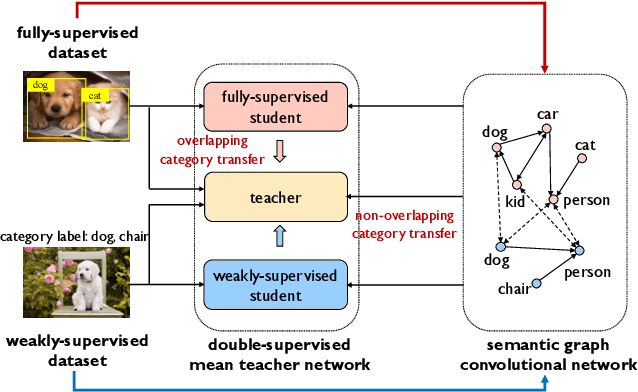
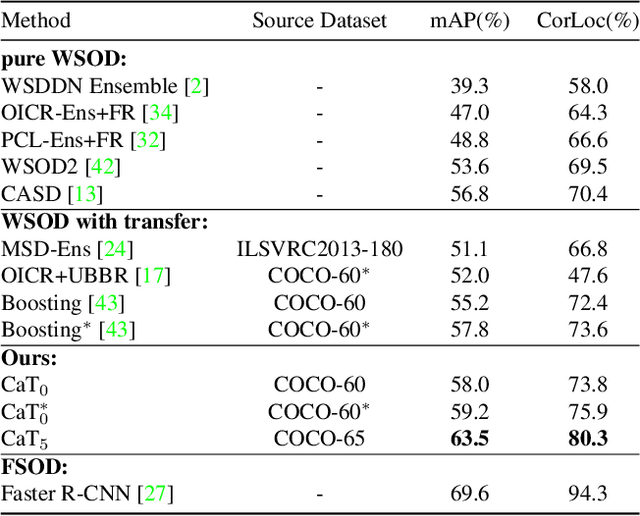
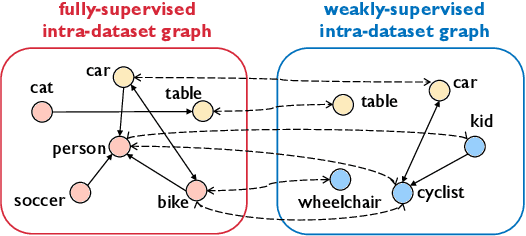
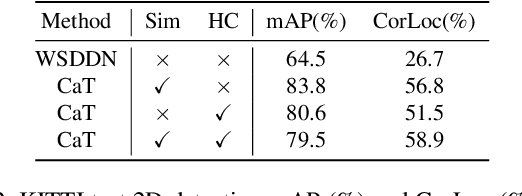
A large gap exists between fully-supervised object detection and weakly-supervised object detection. To narrow this gap, some methods consider knowledge transfer from additional fully-supervised dataset. But these methods do not fully exploit discriminative category information in the fully-supervised dataset, thus causing low mAP. To solve this issue, we propose a novel category transfer framework for weakly supervised object detection. The intuition is to fully leverage both visually-discriminative and semantically-correlated category information in the fully-supervised dataset to enhance the object-classification ability of a weakly-supervised detector. To handle overlapping category transfer, we propose a double-supervision mean teacher to gather common category information and bridge the domain gap between two datasets. To handle non-overlapping category transfer, we propose a semantic graph convolutional network to promote the aggregation of semantic features between correlated categories. Experiments are conducted with Pascal VOC 2007 as the target weakly-supervised dataset and COCO as the source fully-supervised dataset. Our category transfer framework achieves 63.5% mAP and 80.3% CorLoc with 5 overlapping categories between two datasets, which outperforms the state-of-the-art methods. Codes are avaliable at https://github.com/MediaBrain-SJTU/CaT.
Using Deep Learning to Identify Patients with Cognitive Impairment in Electronic Health Records
Nov 13, 2021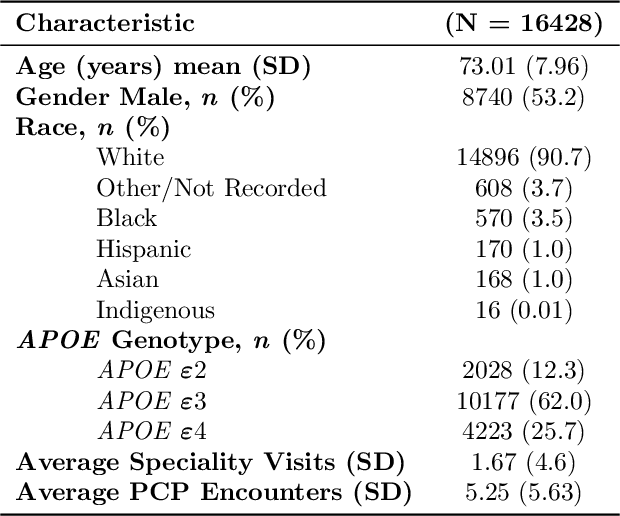



Dementia is a neurodegenerative disorder that causes cognitive decline and affects more than 50 million people worldwide. Dementia is under-diagnosed by healthcare professionals - only one in four people who suffer from dementia are diagnosed. Even when a diagnosis is made, it may not be entered as a structured International Classification of Diseases (ICD) diagnosis code in a patient's charts. Information relevant to cognitive impairment (CI) is often found within electronic health records (EHR), but manual review of clinician notes by experts is both time consuming and often prone to errors. Automated mining of these notes presents an opportunity to label patients with cognitive impairment in EHR data. We developed natural language processing (NLP) tools to identify patients with cognitive impairment and demonstrate that linguistic context enhances performance for the cognitive impairment classification task. We fine-tuned our attention based deep learning model, which can learn from complex language structures, and substantially improved accuracy (0.93) relative to a baseline NLP model (0.84). Further, we show that deep learning NLP can successfully identify dementia patients without dementia-related ICD codes or medications.