 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Not All Models Localize Linguistic Knowledge in the Same Place: A Layer-wise Probing on BERToids' Representations
Sep 15, 2021
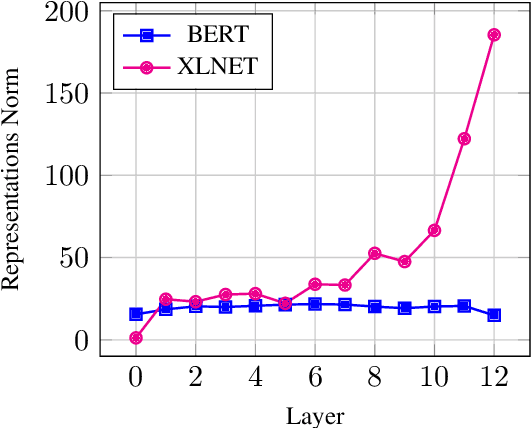

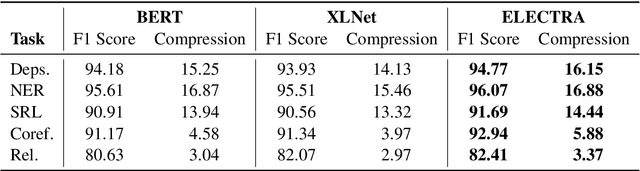
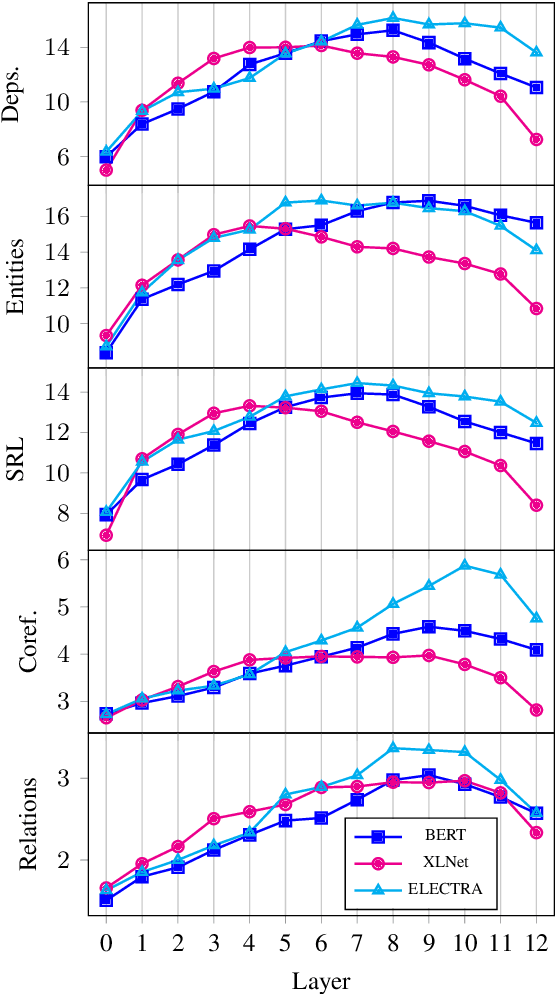
Most of the recent works on probing representations have focused on BERT, with the presumption that the findings might be similar to the other models. In this work, we extend the probing studies to two other models in the family, namely ELECTRA and XLNet, showing that variations in the pre-training objectives or architectural choices can result in different behaviors in encoding linguistic information in the representations. Most notably, we observe that ELECTRA tends to encode linguistic knowledge in the deeper layers, whereas XLNet instead concentrates that in the earlier layers. Also, the former model undergoes a slight change during fine-tuning, whereas the latter experiences significant adjustments. Moreover, we show that drawing conclusions based on the weight mixing evaluation strategy -- which is widely used in the context of layer-wise probing -- can be misleading given the norm disparity of the representations across different layers. Instead, we adopt an alternative information-theoretic probing with minimum description length, which has recently been proven to provide more reliable and informative results.
DeMFI: Deep Joint Deblurring and Multi-Frame Interpolation with Flow-Guided Attentive Correlation and Recursive Boosting
Nov 19, 2021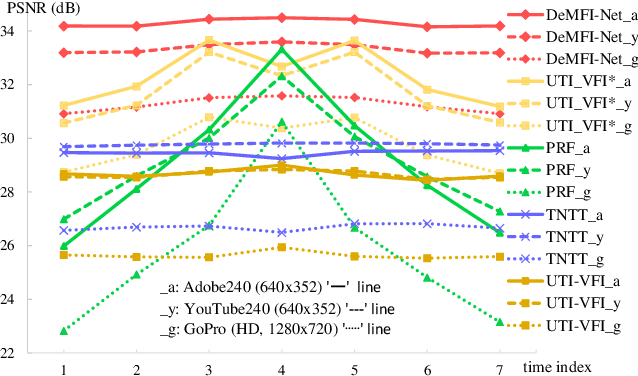
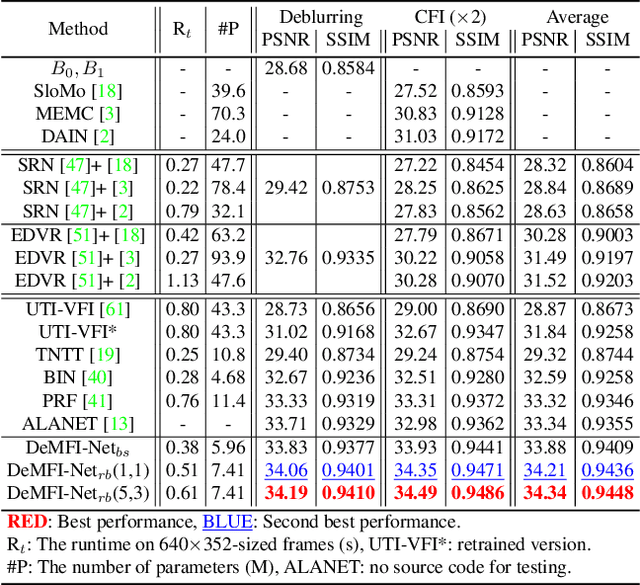
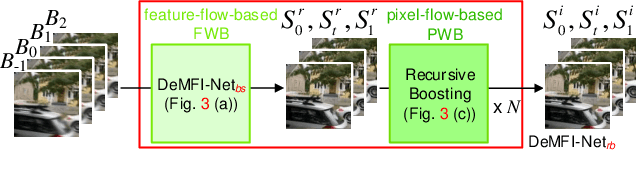

In this paper, we propose a novel joint deblurring and multi-frame interpolation (DeMFI) framework, called DeMFI-Net, which accurately converts blurry videos of lower-frame-rate to sharp videos at higher-frame-rate based on flow-guided attentive-correlation-based feature bolstering (FAC-FB) module and recursive boosting (RB), in terms of multi-frame interpolation (MFI). The DeMFI-Net jointly performs deblurring and MFI where its baseline version performs feature-flow-based warping with FAC-FB module to obtain a sharp-interpolated frame as well to deblur two center-input frames. Moreover, its extended version further improves the joint task performance based on pixel-flow-based warping with GRU-based RB. Our FAC-FB module effectively gathers the distributed blurry pixel information over blurry input frames in feature-domain to improve the overall joint performances, which is computationally efficient since its attentive correlation is only focused pointwise. As a result, our DeMFI-Net achieves state-of-the-art (SOTA) performances for diverse datasets with significant margins compared to the recent SOTA methods, for both deblurring and MFI. All source codes including pretrained DeMFI-Net are publicly available at https://github.com/JihyongOh/DeMFI.
V2X Communication Between Connected and Automated Vehicles (CAVs) and Unmanned Aerial Vehicles (UAVs)
Sep 02, 2021



Connectivity between ground vehicles can be utilized and expanded to include aerial vehicles for coordinated missions. Using Vehicle-to-Everything (V2X) communication technologies, a communication link can be established between Connected and Autonomous vehicles (CAVs) and Unmanned Aerial vehicles (UAVs). Hardware implementation and testing of a ground to air communication link is crucial for real-life applications. Two different communication links were established, Dedicated Short Range communication (DSRC) and 4G internet based WebSocket communication. Both links were tested separately both for stationary and dynamic test cases. One step further, both links were used together for a real-life use case scenario called Quick Clear demonstration. The aim was to first send ground vehicle location information from the CAV to the UAV through DSRC communication. On the UAV side, the connection between the DSRC modem and Raspberry Pi companion computer was established through User Datagram Protocol (UDP) to get the CAV location information to the companion computer. Raspberry Pi handles 2 different connection, it first connects to a traffic contingency management system (CMP) through Transmission Control Protocol (TCP) to send CAV and UAV location information to the CMP. Secondly, Raspberry Pi uses a WebSocket communication to connect to a web server to send photos taken by an on-board camera the UAV has. Quick Clear demo was conducted both for stationary test and dynamic flight tests. The results show that this communication structure can be utilized for real-life scenarios.
Behavioral assessment of a humanoid robot when attracting pedestrians in a mall
Sep 06, 2021

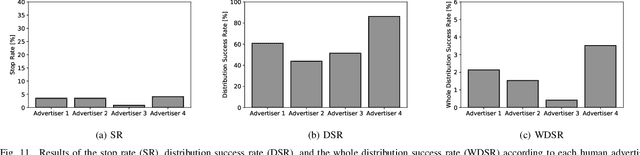
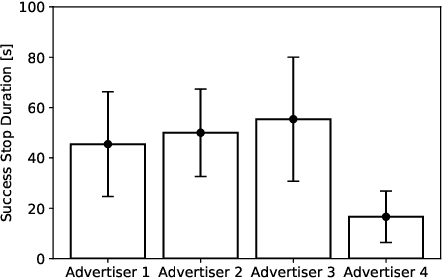
Research currently being conducted on the use of robots as human labor support technology. In particular, the service industry needs to allocate more manpower, and it will be important for robots to support people. This study focuses on using a humanoid robot as a social service robot to convey information in a shopping mall, and the robot's behavioral concepts were analyzed. In order to convey the information, two processes must occur. Pedestrians must stop in front of the robot, and the robot must continue the engagement with them. For the purpose of this study, three types of autonomous behavioral concepts of the robot for the general use were analyzed and compared in these processes in the experiment: active, passive-negative, and passive-positive concepts. After interactions were attempted with 65,000+ pedestrians, this study revealed that the passive-negative concept can make pedestrians stop more and stay longer. In order to evaluate the effectiveness of the robot in a real environment, the comparative results between three behaviors and human advertisers revealed that (1) the results of the active and passive-positive concepts of the robot are comparable to those of the humans, and (2) the performance of the passive-negative concept is higher than that of all participants. These findings demonstrate that the performance of robots is comparable to that of humans in providing information tasks in a limited environment; therefore, it is expected that service robots as a labor support technology will be able to perform well in the real world.
Multivariate feature ranking of gene expression data
Nov 07, 2021
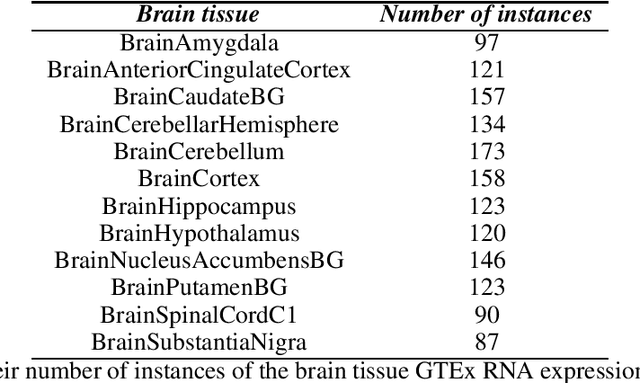
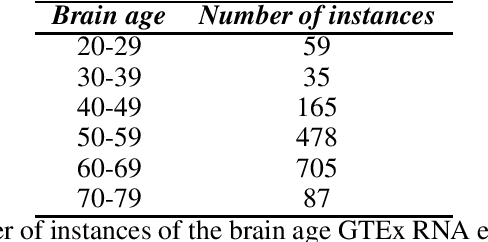

Gene expression datasets are usually of high dimensionality and therefore require efficient and effective methods for identifying the relative importance of their attributes. Due to the huge size of the search space of the possible solutions, the attribute subset evaluation feature selection methods tend to be not applicable, so in these scenarios feature ranking methods are used. Most of the feature ranking methods described in the literature are univariate methods, so they do not detect interactions between factors. In this paper we propose two new multivariate feature ranking methods based on pairwise correlation and pairwise consistency, which we have applied in three gene expression classification problems. We statistically prove that the proposed methods outperform the state of the art feature ranking methods Clustering Variation, Chi Squared, Correlation, Information Gain, ReliefF and Significance, as well as feature selection methods of attribute subset evaluation based on correlation and consistency with multi-objective evolutionary search strategy.
Deep Learning for Rain Fade Prediction in Satellite Communications
Oct 02, 2021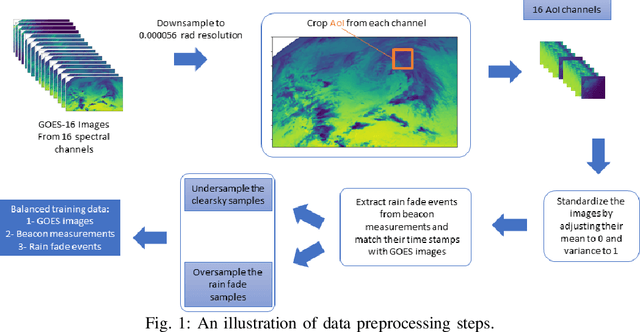
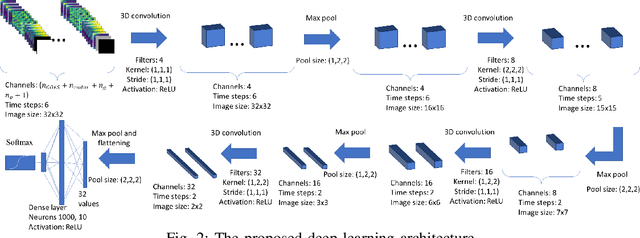
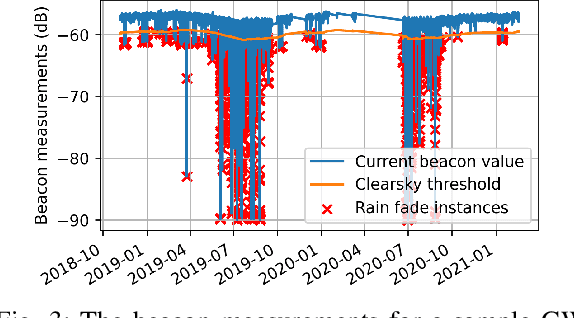
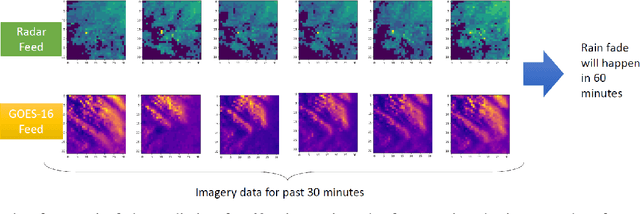
Line of sight satellite systems, unmanned aerial vehicles, high-altitude platforms, and microwave links that operate on frequency bands such as Ka-band or higher are extremely susceptible to rain. Thus, rain fade forecasting for these systems is critical because it allows the system to switch between ground gateways proactively before a rain fade event to maintain seamless service. Although empirical, statistical, and fade slope models can predict rain fade to some extent, they typically require statistical measurements of rain characteristics in a given area and cannot be generalized to a large scale system. Furthermore, such models typically predict near-future rain fade events but are incapable of forecasting far into the future, making proactive resource management more difficult. In this paper, a deep learning (DL)-based architecture is proposed that forecasts future rain fade using satellite and radar imagery data as well as link power measurements. Furthermore, the data preprocessing and architectural design have been thoroughly explained and multiple experiments have been conducted. Experiments show that the proposed DL architecture outperforms current state-of-the-art machine learning-based algorithms in rain fade forecasting in the near and long term. Moreover, the results indicate that radar data with weather condition information is more effective for short-term prediction, while satellite data with cloud movement information is more effective for long-term predictions.
BANANA at WNUT-2020 Task 2: Identifying COVID-19 Information on Twitter by Combining Deep Learning and Transfer Learning Models
Sep 06, 2020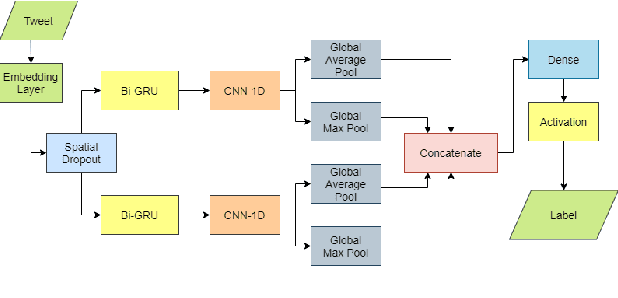

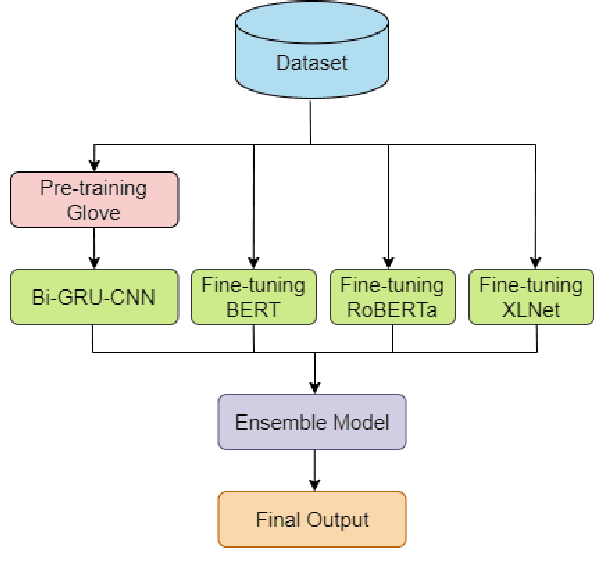

The outbreak COVID-19 virus caused a significant impact on the health of people all over the world. Therefore, it is essential to have a piece of constant and accurate information about the disease with everyone. This paper describes our prediction system for WNUT-2020 Task 2: Identification of Informative COVID-19 English Tweets. The dataset for this task contains size 10,000 tweets in English labeled by humans. The ensemble model from our three transformer and deep learning models is used for the final prediction. The experimental result indicates that we have achieved F1 for the INFORMATIVE label on our systems at 88.81% on the test set.
Probabilistic Tracking with Deep Factors
Dec 02, 2021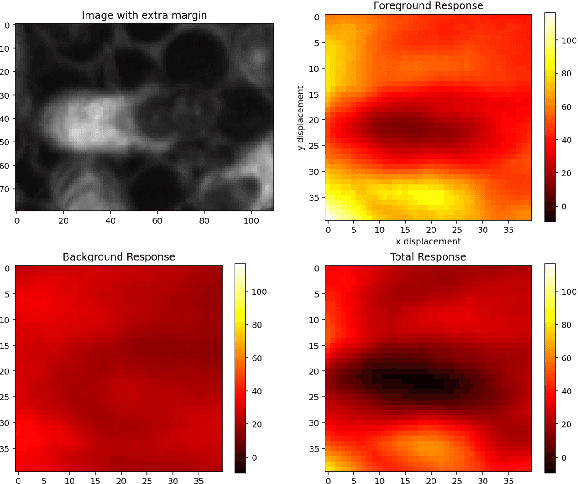
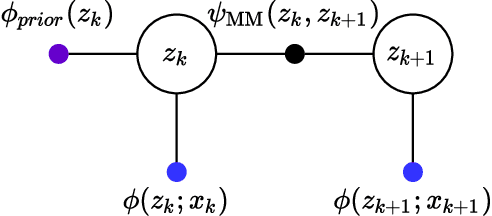

In many applications of computer vision it is important to accurately estimate the trajectory of an object over time by fusing data from a number of sources, of which 2D and 3D imagery is only one. In this paper, we show how to use a deep feature encoding in conjunction with generative densities over the features in a factor-graph based, probabilistic tracking framework. We present a likelihood model that combines a learned feature encoder with generative densities over them, both trained in a supervised manner. We also experiment with directly inferring probability through the use of image classification models that feed into the likelihood formulation. These models are used to implement deep factors that are added to the factor graph to complement other factors that represent domain-specific knowledge such as motion models and/or other prior information. Factors are then optimized together in a non-linear least-squares tracking framework that takes the form of an Extended Kalman Smoother with a Gaussian prior. A key feature of our likelihood model is that it leverages the Lie group properties of the tracked target's pose to apply the feature encoding on an image patch, extracted through a differentiable warp function inspired by spatial transformer networks. To illustrate the proposed approach we evaluate it on a challenging social insect behavior dataset, and show that using deep features does outperform these earlier linear appearance models used in this setting.
Merging Models with Fisher-Weighted Averaging
Nov 18, 2021

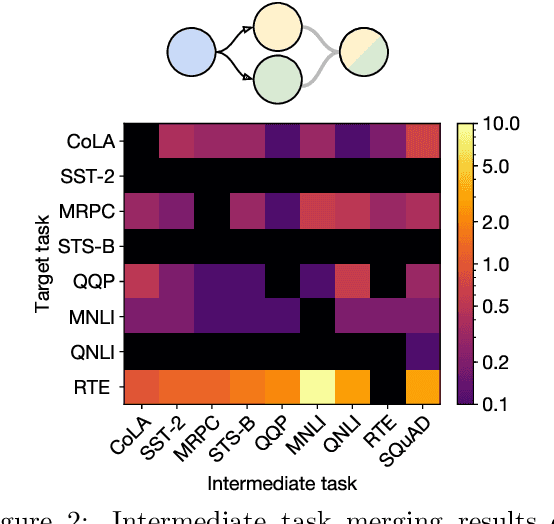
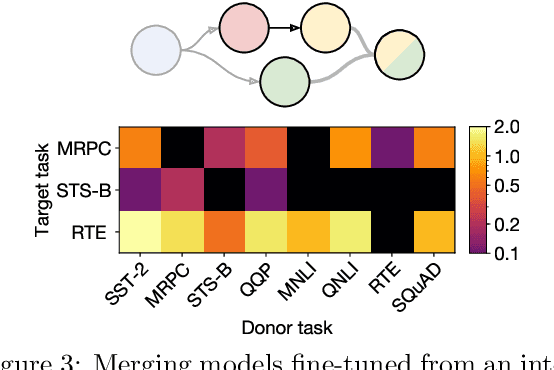
Transfer learning provides a way of leveraging knowledge from one task when learning another task. Performing transfer learning typically involves iteratively updating a model's parameters through gradient descent on a training dataset. In this paper, we introduce a fundamentally different method for transferring knowledge across models that amounts to "merging" multiple models into one. Our approach effectively involves computing a weighted average of the models' parameters. We show that this averaging is equivalent to approximately sampling from the posteriors of the model weights. While using an isotropic Gaussian approximation works well in some cases, we also demonstrate benefits by approximating the precision matrix via the Fisher information. In sum, our approach makes it possible to combine the "knowledge" in multiple models at an extremely low computational cost compared to standard gradient-based training. We demonstrate that model merging achieves comparable performance to gradient descent-based transfer learning on intermediate-task training and domain adaptation problems. We also show that our merging procedure makes it possible to combine models in previously unexplored ways. To measure the robustness of our approach, we perform an extensive ablation on the design of our algorithm.
OW-DETR: Open-world Detection Transformer
Dec 02, 2021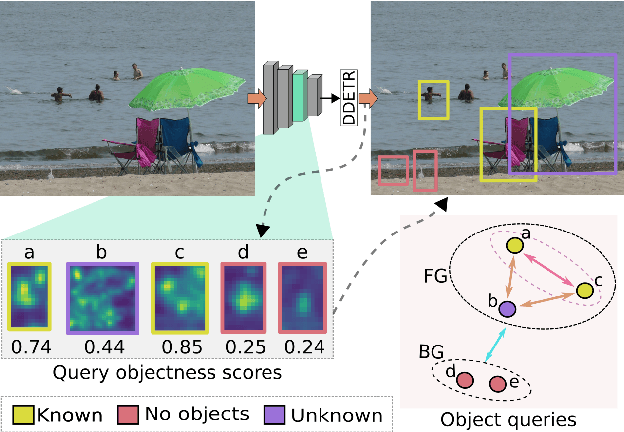
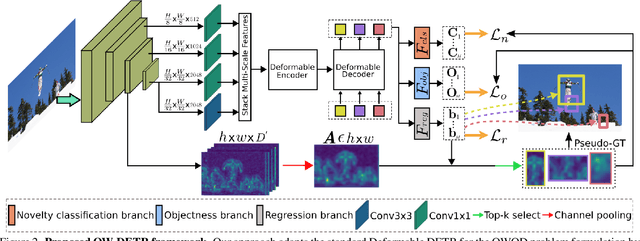
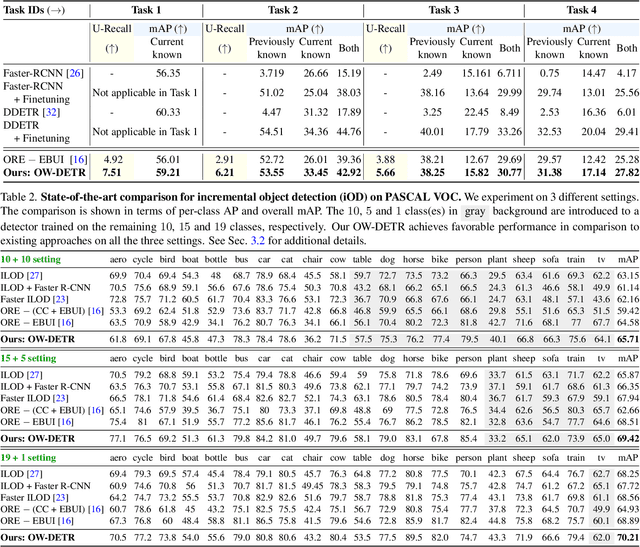
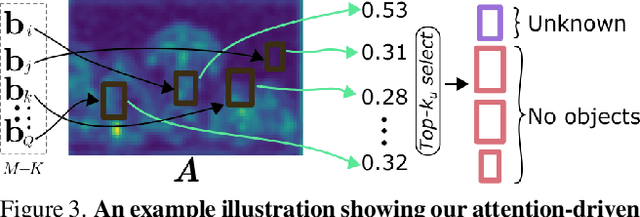
Open-world object detection (OWOD) is a challenging computer vision problem, where the task is to detect a known set of object categories while simultaneously identifying unknown objects. Additionally, the model must incrementally learn new classes that become known in the next training episodes. Distinct from standard object detection, the OWOD setting poses significant challenges for generating quality candidate proposals on potentially unknown objects, separating the unknown objects from the background and detecting diverse unknown objects. Here, we introduce a novel end-to-end transformer-based framework, OW-DETR, for open-world object detection. The proposed OW-DETR comprises three dedicated components namely, attention-driven pseudo-labeling, novelty classification and objectness scoring to explicitly address the aforementioned OWOD challenges. Our OW-DETR explicitly encodes multi-scale contextual information, possesses less inductive bias, enables knowledge transfer from known classes to the unknown class and can better discriminate between unknown objects and background. Comprehensive experiments are performed on two benchmarks: MS-COCO and PASCAL VOC. The extensive ablations reveal the merits of our proposed contributions. Further, our model outperforms the recently introduced OWOD approach, ORE, with absolute gains ranging from 1.8% to 3.3% in terms of unknown recall on the MS-COCO benchmark. In the case of incremental object detection, OW-DETR outperforms the state-of-the-art for all settings on the PASCAL VOC benchmark. Our codes and models will be publicly released.