 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Coding Approach Towards Non-Linear Spectro-Temporal Receptive Fields
Oct 21, 2021
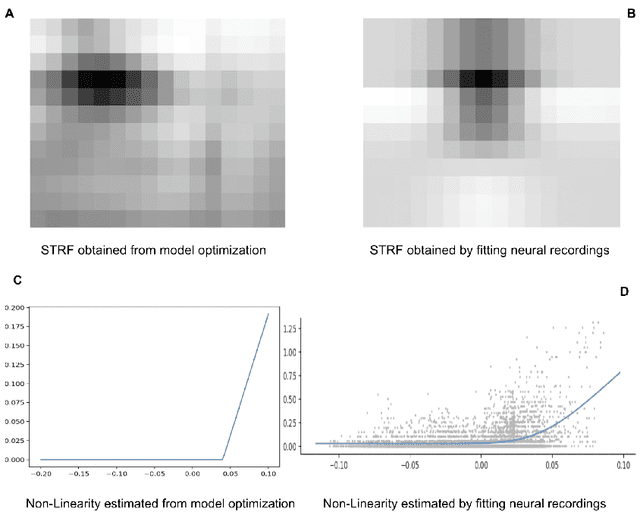
Linear Non-Linear(LN) models are widely used to characterize the receptive fields of early-stage auditory processing. We apply the principle of efficient coding to the LN model of Spectro-Temporal Receptive Fields(STRFs) of the neurons in primary auditory cortex. The Efficient Coding Principle has been previously used to understand early visual receptive fields and linear STRFs in auditory processing. Efficient coding is realized by jointly optimizing the mutual information between stimuli and neural responses subjected to the metabolic cost of firing spikes. We compare the predictions of the efficient coding principle with the physiological observations, which match qualitatively under realistic conditions of noise in stimuli and the spike generation process.
Morph Detection Enhanced by Structured Group Sparsity
Nov 29, 2021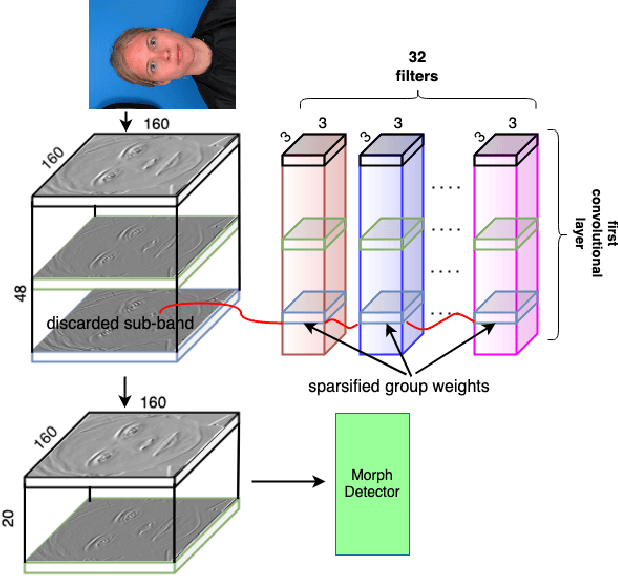
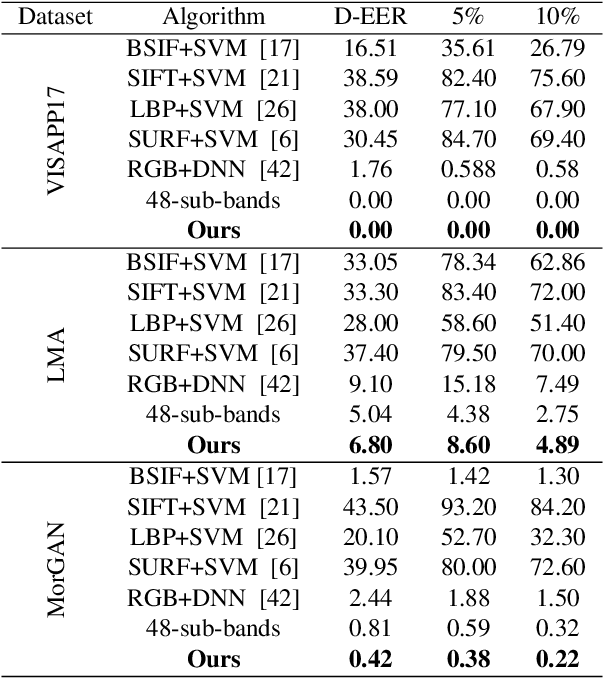
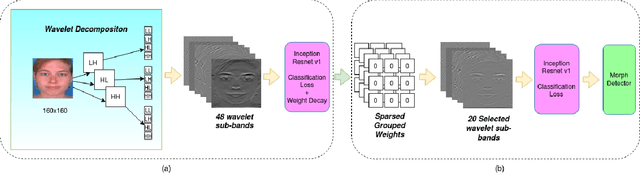
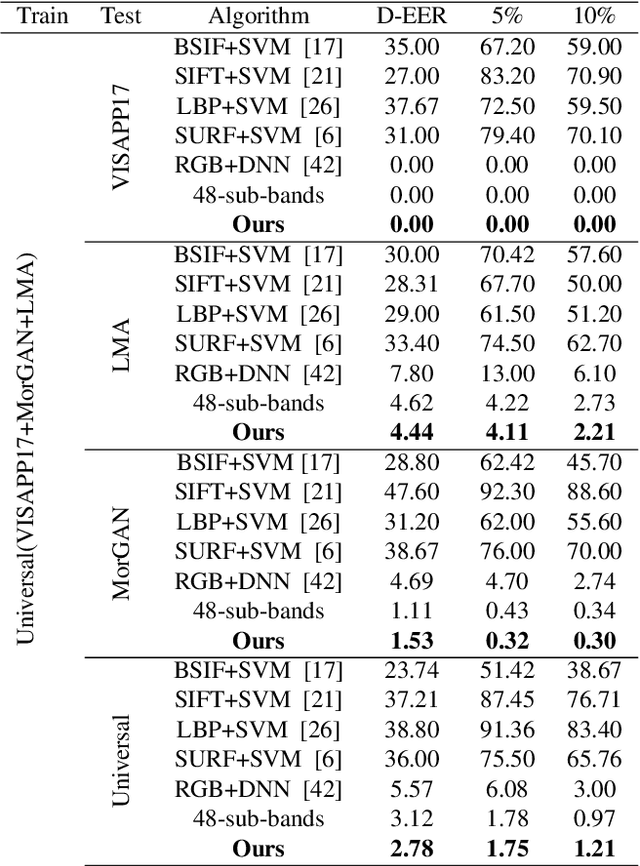
In this paper, we consider the challenge of face morphing attacks, which substantially undermine the integrity of face recognition systems such as those adopted for use in border protection agencies. Morph detection can be formulated as extracting fine-grained representations, where local discriminative features are harnessed for learning a hypothesis. To acquire discriminative features at different granularity as well as a decoupled spectral information, we leverage wavelet domain analysis to gain insight into the spatial-frequency content of a morphed face. As such, instead of using images in the RGB domain, we decompose every image into its wavelet sub-bands using 2D wavelet decomposition and a deep supervised feature selection scheme is employed to find the most discriminative wavelet sub-bands of input images. To this end, we train a Deep Neural Network (DNN) morph detector using the decomposed wavelet sub-bands of the morphed and bona fide images. In the training phase, our structured group sparsity-constrained DNN picks the most discriminative wavelet sub-bands out of all the sub-bands, with which we retrain our DNN, resulting in a precise detection of morphed images when inference is achieved on a probe image. The efficacy of our deep morph detector which is enhanced by structured group lasso is validated through experiments on three facial morph image databases, i.e., VISAPP17, LMA, and MorGAN.
Content Filtering Enriched GNN Framework for News Recommendation
Oct 25, 2021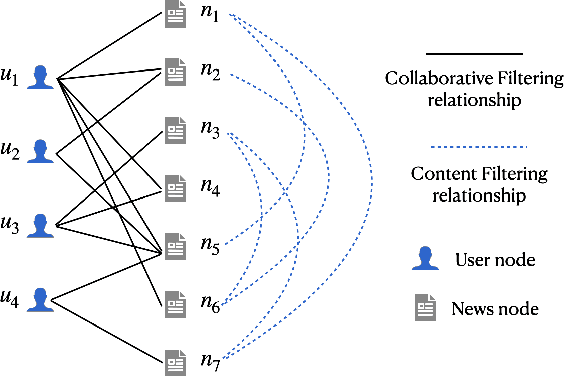
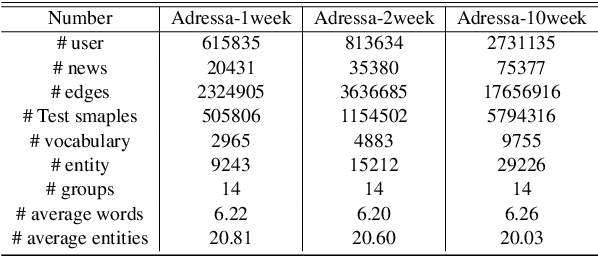
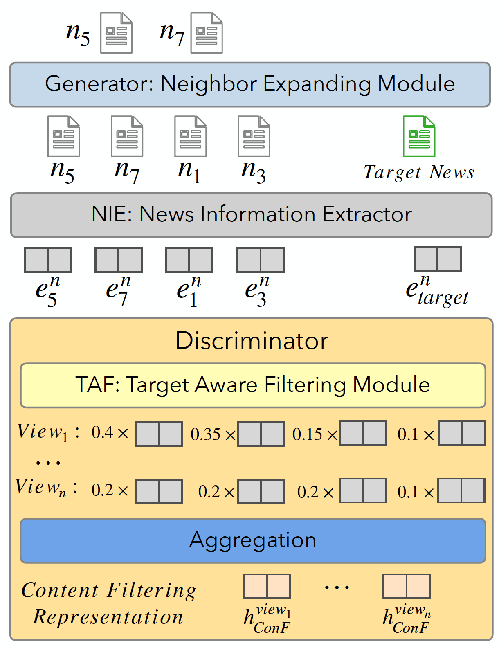
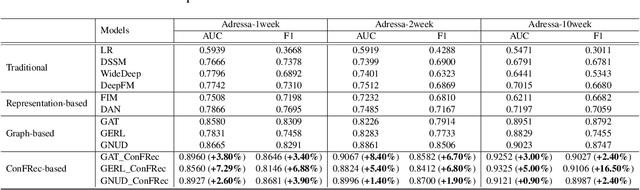
Learning accurate users and news representations is critical for news recommendation. Despite great progress, existing methods seem to have a strong bias towards content representation or just capture collaborative filtering relationship. However, these approaches may suffer from the data sparsity problem (user-news interactive behavior sparsity problem) or maybe affected more by news (or user) with high popularity. In this paper, to address such limitations, we propose content filtering enriched GNN framework for news recommendation, ConFRec in short. It is compatible with existing GNN-based approaches for news recommendation and can capture both collaborative and content filtering information simultaneously. Comprehensive experiments are conducted to demonstrate the effectiveness of ConFRec over the state-of-the-art baseline models for news recommendation on real-world datasets for news recommendation.
Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling
Nov 29, 2021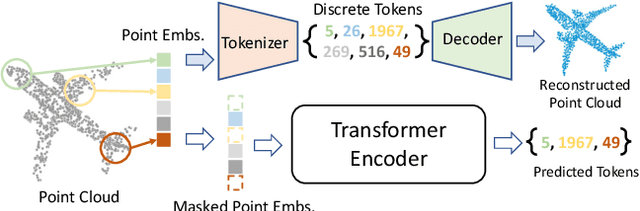
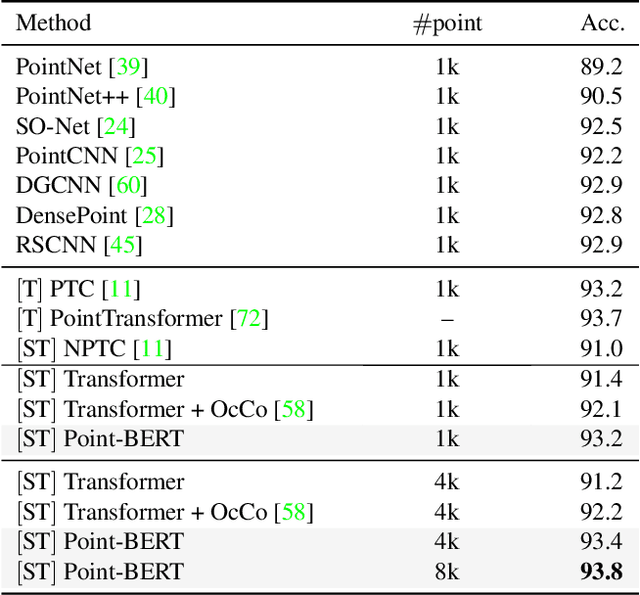
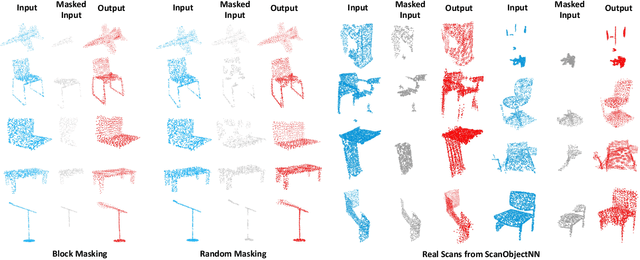
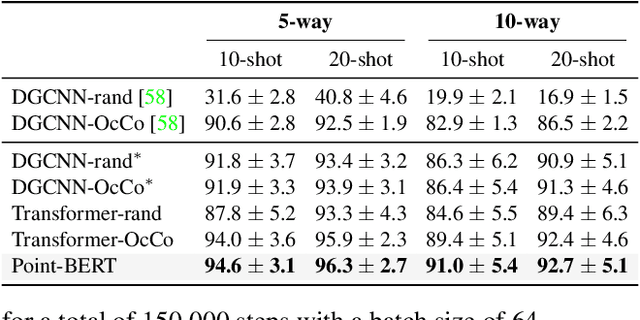
We present Point-BERT, a new paradigm for learning Transformers to generalize the concept of BERT to 3D point cloud. Inspired by BERT, we devise a Masked Point Modeling (MPM) task to pre-train point cloud Transformers. Specifically, we first divide a point cloud into several local point patches, and a point cloud Tokenizer with a discrete Variational AutoEncoder (dVAE) is designed to generate discrete point tokens containing meaningful local information. Then, we randomly mask out some patches of input point clouds and feed them into the backbone Transformers. The pre-training objective is to recover the original point tokens at the masked locations under the supervision of point tokens obtained by the Tokenizer. Extensive experiments demonstrate that the proposed BERT-style pre-training strategy significantly improves the performance of standard point cloud Transformers. Equipped with our pre-training strategy, we show that a pure Transformer architecture attains 93.8% accuracy on ModelNet40 and 83.1% accuracy on the hardest setting of ScanObjectNN, surpassing carefully designed point cloud models with much fewer hand-made designs. We also demonstrate that the representations learned by Point-BERT transfer well to new tasks and domains, where our models largely advance the state-of-the-art of few-shot point cloud classification task. The code and pre-trained models are available at https://github.com/lulutang0608/Point-BERT
Deep Structured Instance Graph for Distilling Object Detectors
Sep 27, 2021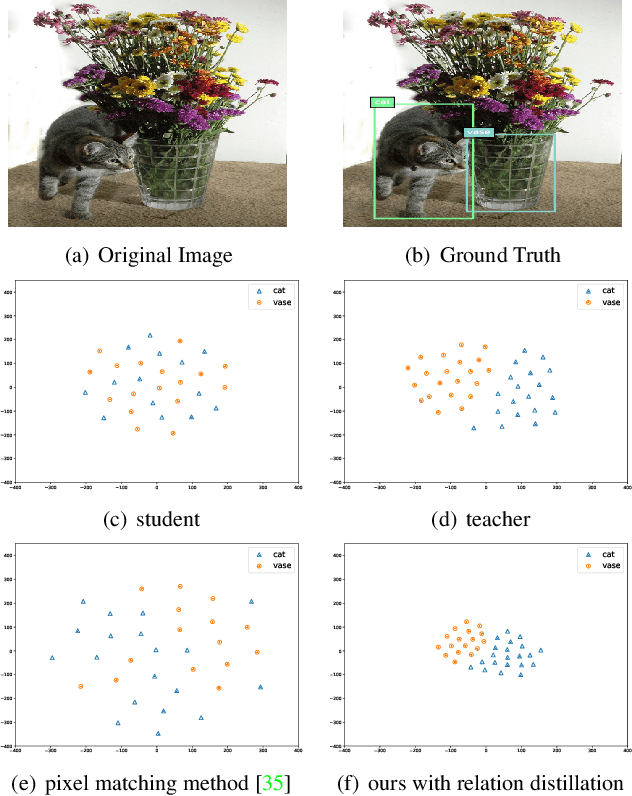
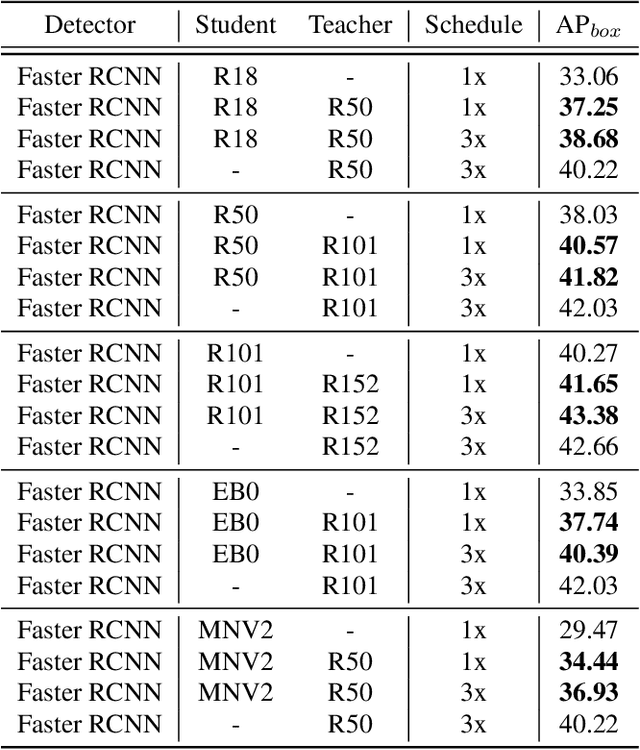

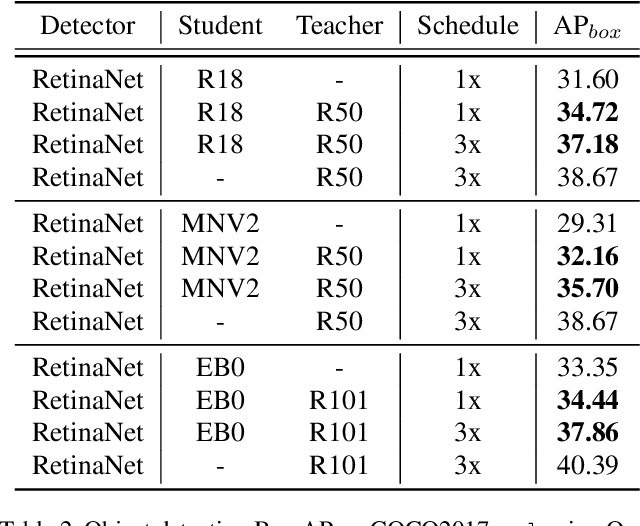
Effectively structuring deep knowledge plays a pivotal role in transfer from teacher to student, especially in semantic vision tasks. In this paper, we present a simple knowledge structure to exploit and encode information inside the detection system to facilitate detector knowledge distillation. Specifically, aiming at solving the feature imbalance problem while further excavating the missing relation inside semantic instances, we design a graph whose nodes correspond to instance proposal-level features and edges represent the relation between nodes. To further refine this graph, we design an adaptive background loss weight to reduce node noise and background samples mining to prune trivial edges. We transfer the entire graph as encoded knowledge representation from teacher to student, capturing local and global information simultaneously. We achieve new state-of-the-art results on the challenging COCO object detection task with diverse student-teacher pairs on both one- and two-stage detectors. We also experiment with instance segmentation to demonstrate robustness of our method. It is notable that distilled Faster R-CNN with ResNet18-FPN and ResNet50-FPN yields 38.68 and 41.82 Box AP respectively on the COCO benchmark, Faster R-CNN with ResNet101-FPN significantly achieves 43.38 AP, which outperforms ResNet152-FPN teacher about 0.7 AP. Code: https://github.com/dvlab-research/Dsig.
PhishMatch: A Layered Approach for Effective Detection of Phishing URLs
Dec 04, 2021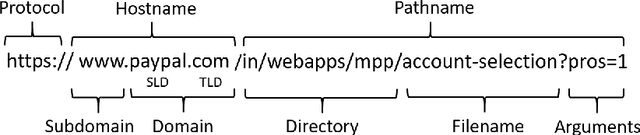

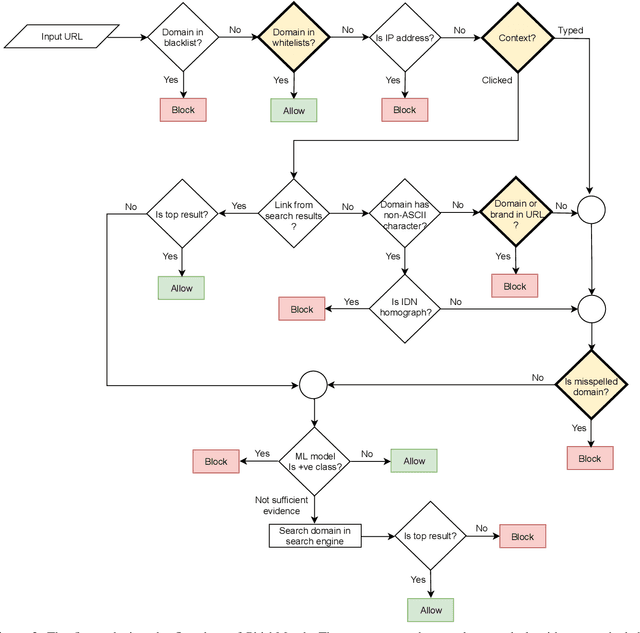
Phishing attacks continue to be a significant threat on the Internet. Prior studies show that it is possible to determine whether a website is phishing or not just by analyzing its URL more carefully. A major advantage of the URL based approach is that it can identify a phishing website even before the web page is rendered in the browser, thus avoiding other potential problems such as cryptojacking and drive-by downloads. However, traditional URL based approaches have their limitations. Blacklist based approaches are prone to zero-hour phishing attacks, advanced machine learning based approaches consume high resources, and other approaches send the URL to a remote server which compromises user's privacy. In this paper, we present a layered anti-phishing defense, PhishMatch, which is robust, accurate, inexpensive, and client-side. We design a space-time efficient Aho-Corasick algorithm for exact string matching and n-gram based indexing technique for approximate string matching to detect various cybersquatting techniques in the phishing URL. To reduce false positives, we use a global whitelist and personalized user whitelists. We also determine the context in which the URL is visited and use that information to classify the input URL more accurately. The last component of PhishMatch involves a machine learning model and controlled search engine queries to classify the URL. A prototype plugin of PhishMatch, developed for the Chrome browser, was found to be fast and lightweight. Our evaluation shows that PhishMatch is both efficient and effective.
A Simple Long-Tailed Recognition Baseline via Vision-Language Model
Nov 29, 2021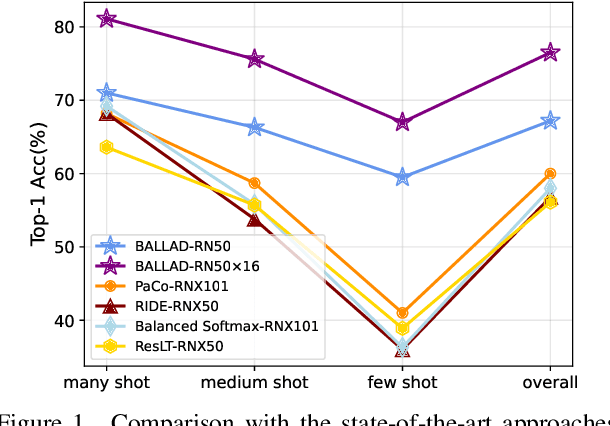
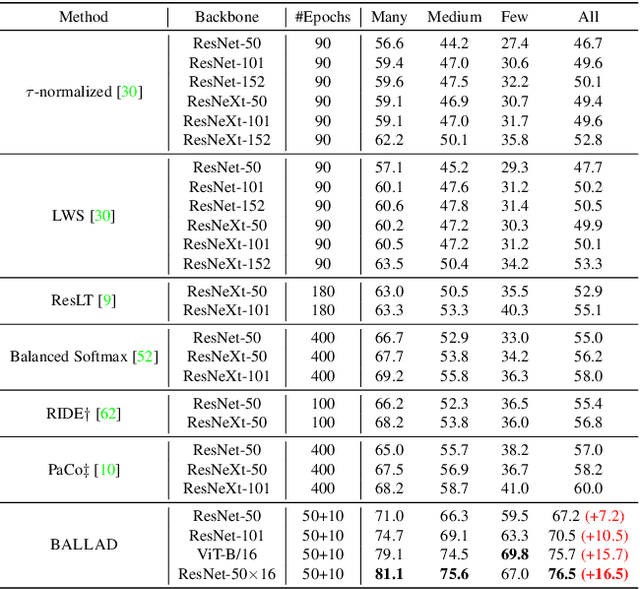
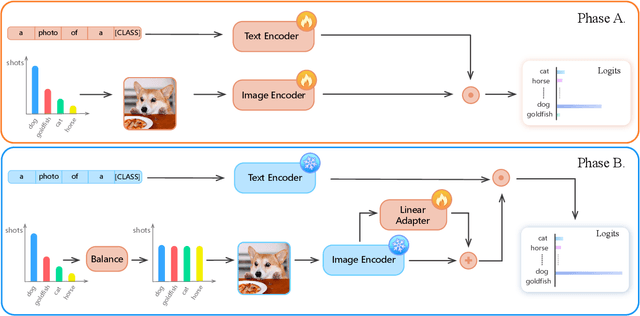
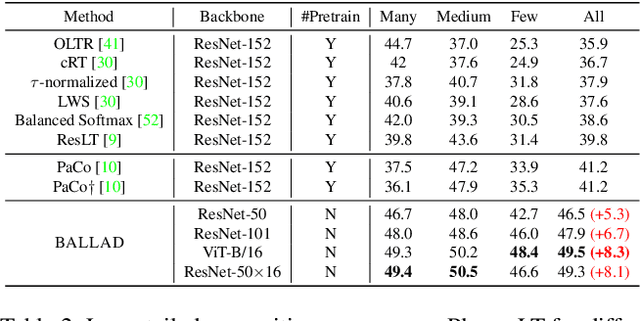
The visual world naturally exhibits a long-tailed distribution of open classes, which poses great challenges to modern visual systems. Existing approaches either perform class re-balancing strategies or directly improve network modules to address the problem. However, they still train models with a finite set of predefined labels, limiting their supervision information and restricting their transferability to novel instances. Recent advances in large-scale contrastive visual-language pretraining shed light on a new pathway for visual recognition. With open-vocabulary supervisions, pretrained contrastive vision-language models learn powerful multimodal representations that are promising to handle data deficiency and unseen concepts. By calculating the semantic similarity between visual and text inputs, visual recognition is converted to a vision-language matching problem. Inspired by this, we propose BALLAD to leverage contrastive vision-language models for long-tailed recognition. We first continue pretraining the vision-language backbone through contrastive learning on a specific long-tailed target dataset. Afterward, we freeze the backbone and further employ an additional adapter layer to enhance the representations of tail classes on balanced training samples built with re-sampling strategies. Extensive experiments have been conducted on three popular long-tailed recognition benchmarks. As a result, our simple and effective approach sets the new state-of-the-art performances and outperforms competitive baselines with a large margin. Code is released at https://github.com/gaopengcuhk/BALLAD.
Attention on Classification for Fire Segmentation
Nov 04, 2021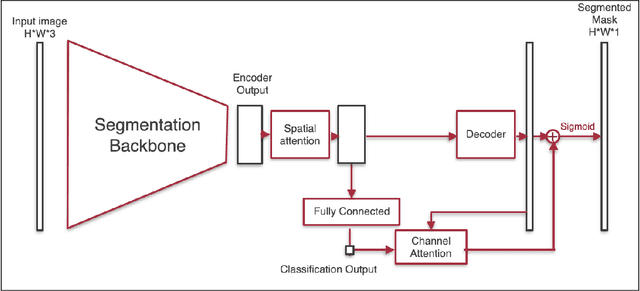


Detection and localization of fire in images and videos are important in tackling fire incidents. Although semantic segmentation methods can be used to indicate the location of pixels with fire in the images, their predictions are localized, and they often fail to consider global information of the existence of fire in the image which is implicit in the image labels. We propose a Convolutional Neural Network (CNN) for joint classification and segmentation of fire in images which improves the performance of the fire segmentation. We use a spatial self-attention mechanism to capture long-range dependency between pixels, and a new channel attention module which uses the classification probability as an attention weight. The network is jointly trained for both segmentation and classification, leading to improvement in the performance of the single-task image segmentation methods, and the previous methods proposed for fire segmentation.
V2X Communication Between Connected and Automated Vehicles (CAVs) and Unmanned Aerial Vehicles (UAVs)
Sep 02, 2021



Connectivity between ground vehicles can be utilized and expanded to include aerial vehicles for coordinated missions. Using Vehicle-to-Everything (V2X) communication technologies, a communication link can be established between Connected and Autonomous vehicles (CAVs) and Unmanned Aerial vehicles (UAVs). Hardware implementation and testing of a ground to air communication link is crucial for real-life applications. Two different communication links were established, Dedicated Short Range communication (DSRC) and 4G internet based WebSocket communication. Both links were tested separately both for stationary and dynamic test cases. One step further, both links were used together for a real-life use case scenario called Quick Clear demonstration. The aim was to first send ground vehicle location information from the CAV to the UAV through DSRC communication. On the UAV side, the connection between the DSRC modem and Raspberry Pi companion computer was established through User Datagram Protocol (UDP) to get the CAV location information to the companion computer. Raspberry Pi handles 2 different connection, it first connects to a traffic contingency management system (CMP) through Transmission Control Protocol (TCP) to send CAV and UAV location information to the CMP. Secondly, Raspberry Pi uses a WebSocket communication to connect to a web server to send photos taken by an on-board camera the UAV has. Quick Clear demo was conducted both for stationary test and dynamic flight tests. The results show that this communication structure can be utilized for real-life scenarios.
Generating synthetic transactional profiles
Oct 28, 2021



Financial institutions use clients' payment transactions in numerous banking applications. Transactions are very personal and rich in behavioural patterns, often unique to individuals, which make them equivalent to personally identifiable information in some cases. In this paper, we generate synthetic transactional profiles using machine learning techniques with the goal to preserve both data utility and privacy. A challenge we faced was to deal with sparse vectors due to the few spending categories a client uses compared to all the ones available. We measured data utility by calculating common insights used by the banking industry on both the original and the synthetic data-set. Our approach shows that neural network models can generate valuable synthetic data in such context. Finally, we tried privacy-preserving techniques and observed its effect on models' performances.