 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
Oct 25, 2021
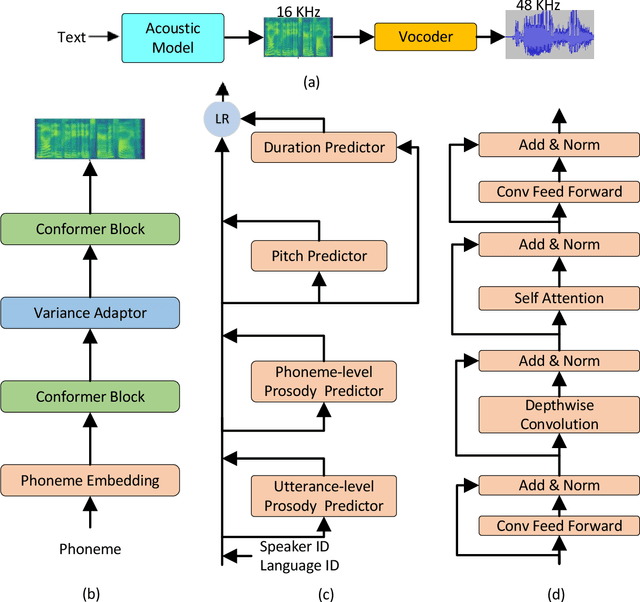
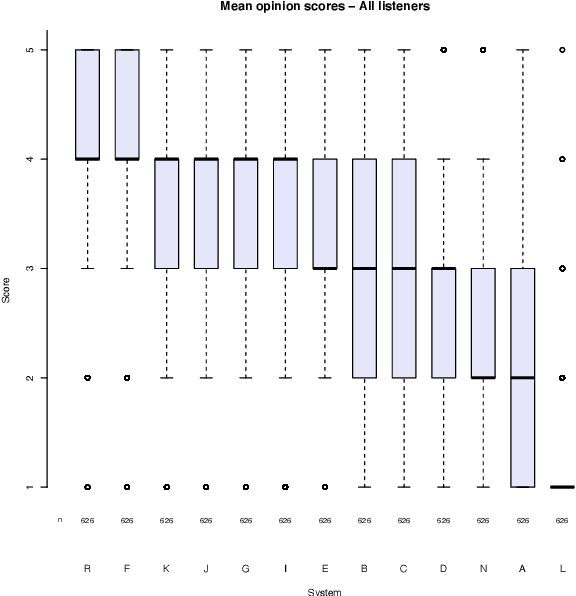
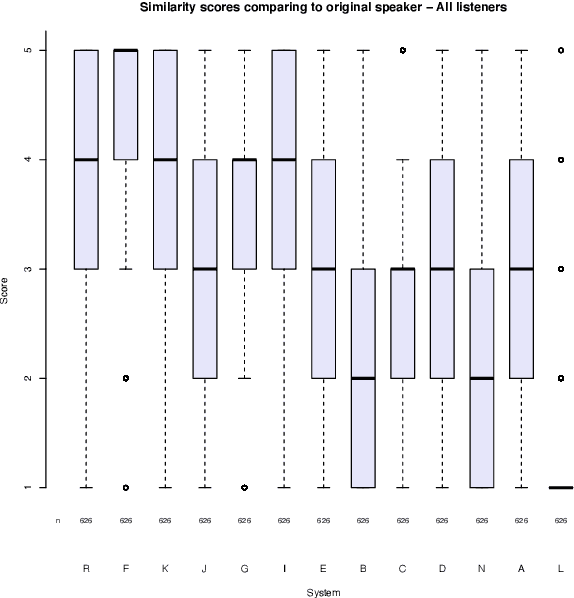
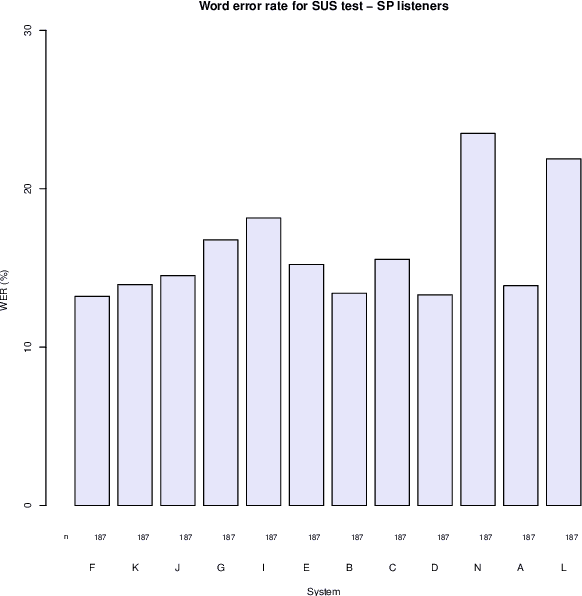
This paper describes the Microsoft end-to-end neural text to speech (TTS) system: DelightfulTTS for Blizzard Challenge 2021. The goal of this challenge is to synthesize natural and high-quality speech from text, and we approach this goal in two perspectives: The first is to directly model and generate waveform in 48 kHz sampling rate, which brings higher perception quality than previous systems with 16 kHz or 24 kHz sampling rate; The second is to model the variation information in speech through a systematic design, which improves the prosody and naturalness. Specifically, for 48 kHz modeling, we predict 16 kHz mel-spectrogram in acoustic model, and propose a vocoder called HiFiNet to directly generate 48 kHz waveform from predicted 16 kHz mel-spectrogram, which can better trade off training efficiency, modelling stability and voice quality. We model variation information systematically from both explicit (speaker ID, language ID, pitch and duration) and implicit (utterance-level and phoneme-level prosody) perspectives: 1) For speaker and language ID, we use lookup embedding in training and inference; 2) For pitch and duration, we extract the values from paired text-speech data in training and use two predictors to predict the values in inference; 3) For utterance-level and phoneme-level prosody, we use two reference encoders to extract the values in training, and use two separate predictors to predict the values in inference. Additionally, we introduce an improved Conformer block to better model the local and global dependency in acoustic model. For task SH1, DelightfulTTS achieves 4.17 mean score in MOS test and 4.35 in SMOS test, which indicates the effectiveness of our proposed system
Literature-Augmented Clinical Outcome Prediction
Nov 16, 2021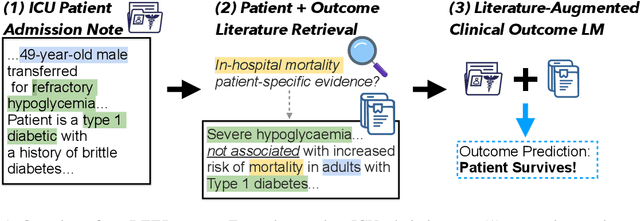
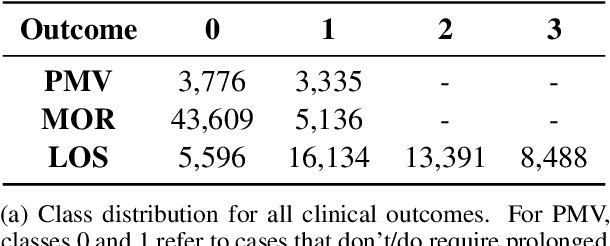
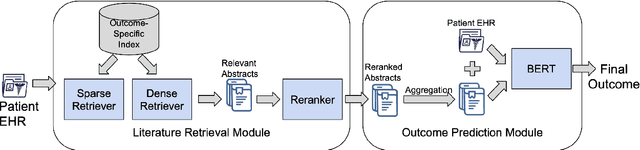
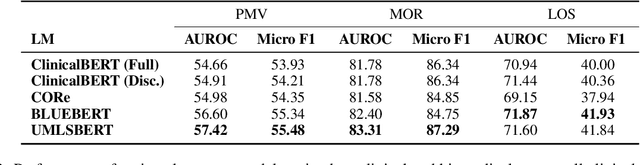
Predictive models for medical outcomes hold great promise for enhancing clinical decision-making. These models are trained on rich patient data such as clinical notes, aggregating many patient signals into an outcome prediction. However, AI-based clinical models have typically been developed in isolation from the prominent paradigm of Evidence Based Medicine (EBM), in which medical decisions are based on explicit evidence from existing literature. In this work, we introduce techniques to help bridge this gap between EBM and AI-based clinical models, and show that these methods can improve predictive accuracy. We propose a novel system that automatically retrieves patient-specific literature based on intensive care (ICU) patient information, aggregates relevant papers and fuses them with internal admission notes to form outcome predictions. Our model is able to substantially boost predictive accuracy on three challenging tasks in comparison to strong recent baselines; for in-hospital mortality, we are able to boost top-10% precision by a large margin of over 25%.
Indexability and Rollout Policy for Multi-State Partially Observable Restless Bandits
Jul 30, 2021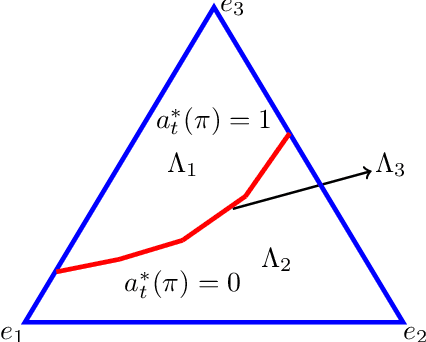
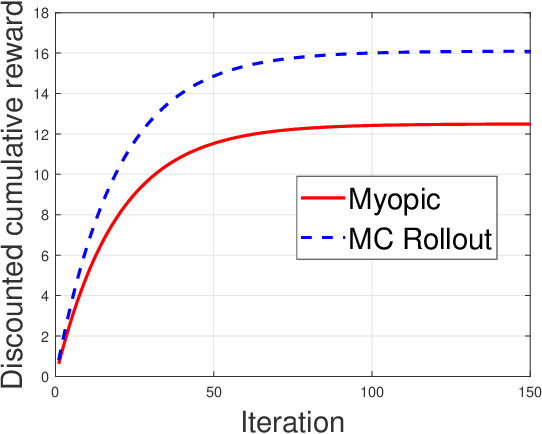
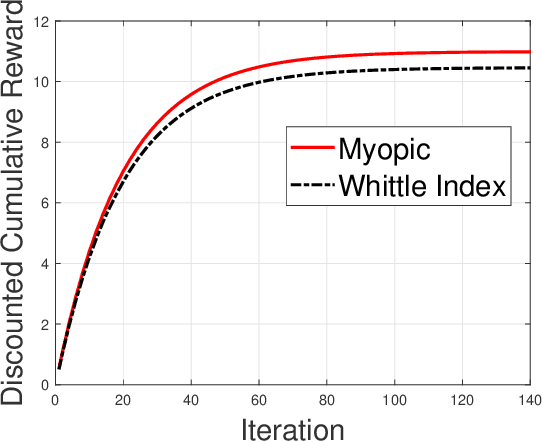
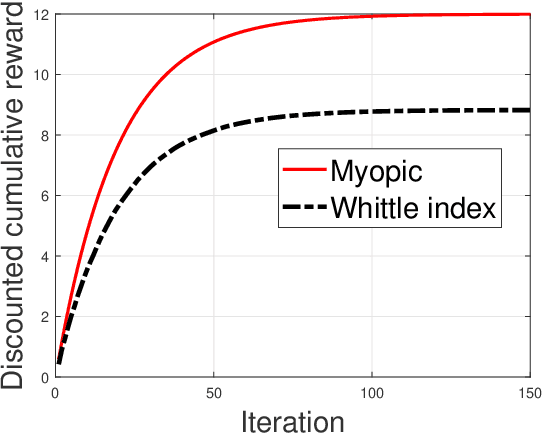
Restless multi-armed bandits with partially observable states has applications in communication systems, age of information and recommendation systems. In this paper, we study multi-state partially observable restless bandit models. We consider three different models based on information observable to decision maker -- 1) no information is observable from actions of a bandit 2) perfect information from bandit is observable only for one action on bandit, there is a fixed restart state, i.e., transition occurs from all other states to that state 3) perfect state information is available to decision maker for both actions on a bandit and there are two restart state for two actions. We develop the structural properties. We also show a threshold type policy and indexability for model 2 and 3. We present Monte Carlo (MC) rollout policy. We use it for whittle index computation in case of model 2. We obtain the concentration bound on value function in terms of horizon length and number of trajectories for MC rollout policy. We derive explicit index formula for model 3. We finally describe Monte Carlo rollout policy for model 1 when it is difficult to show indexability. We demonstrate the numerical examples using myopic policy, Monte Carlo rollout policy and Whittle index policy. We observe that Monte Carlo rollout policy is good competitive policy to myopic.
Dual Progressive Prototype Network for Generalized Zero-Shot Learning
Nov 22, 2021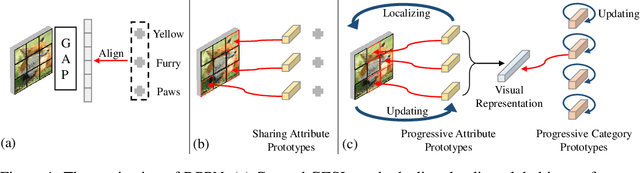
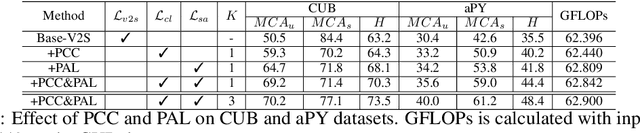
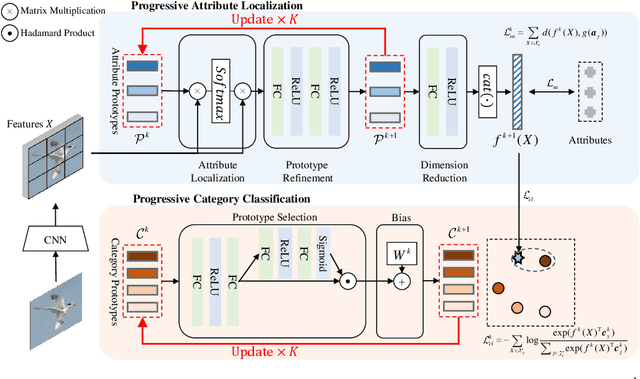
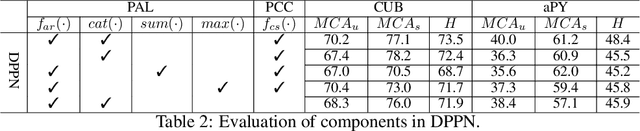
Generalized Zero-Shot Learning (GZSL) aims to recognize new categories with auxiliary semantic information,e.g., category attributes. In this paper, we handle the critical issue of domain shift problem, i.e., confusion between seen and unseen categories, by progressively improving cross-domain transferability and category discriminability of visual representations. Our approach, named Dual Progressive Prototype Network (DPPN), constructs two types of prototypes that record prototypical visual patterns for attributes and categories, respectively. With attribute prototypes, DPPN alternately searches attribute-related local regions and updates corresponding attribute prototypes to progressively explore accurate attribute-region correspondence. This enables DPPN to produce visual representations with accurate attribute localization ability, which benefits the semantic-visual alignment and representation transferability. Besides, along with progressive attribute localization, DPPN further projects category prototypes into multiple spaces to progressively repel visual representations from different categories, which boosts category discriminability. Both attribute and category prototypes are collaboratively learned in a unified framework, which makes visual representations of DPPN transferable and distinctive. Experiments on four benchmarks prove that DPPN effectively alleviates the domain shift problem in GZSL.
Hierarchy Decoder is All You Need To Text Classification
Nov 22, 2021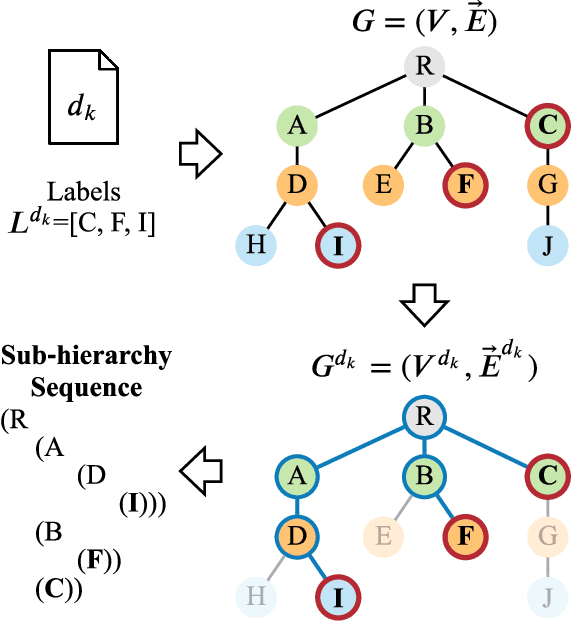
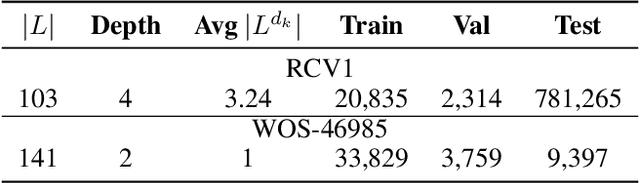
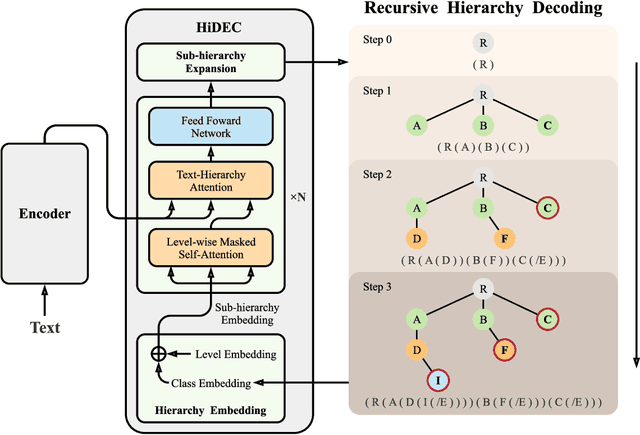
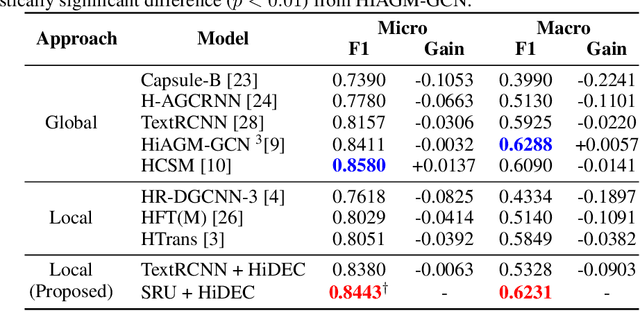
Hierarchical text classification (HTC) to a taxonomy is essential for various real applications butchallenging since HTC models often need to process a large volume of data that are severelyimbalanced and have hierarchy dependencies. Existing local and global approaches use deep learningto improve HTC by reducing the time complexity and incorporating the hierarchy dependencies.However, it is difficult to satisfy both conditions in a single HTC model. This paper proposes ahierarchy decoder (HiDEC) that uses recursive hierarchy decoding based on an encoder-decoderarchitecture. The key idea of the HiDEC involves decoding a context matrix into a sub-hierarchysequence using recursive hierarchy decoding, while staying aware of hierarchical dependenciesand level information. The HiDEC is a unified model that incorporates the benefits of existingapproaches, thereby alleviating the aforementioned difficulties without any trade-off. In addition, itcan be applied to both single- and multi-label classification with a minor modification. The superiorityof the proposed model was verified on two benchmark datasets (WOS-46985 and RCV1) with anexplanation of the reasons for its success
Multivariate feature ranking of gene expression data
Nov 16, 2021
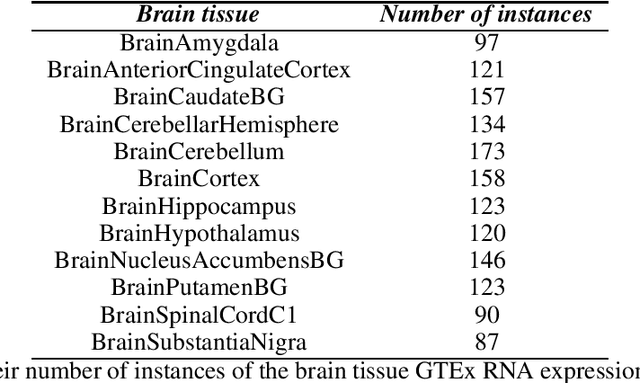
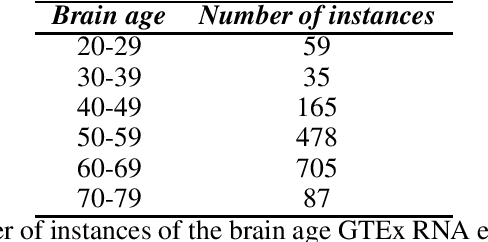

Gene expression datasets are usually of high dimensionality and therefore require efficient and effective methods for identifying the relative importance of their attributes. Due to the huge size of the search space of the possible solutions, the attribute subset evaluation feature selection methods tend to be not applicable, so in these scenarios feature ranking methods are used. Most of the feature ranking methods described in the literature are univariate methods, so they do not detect interactions between factors. In this paper we propose two new multivariate feature ranking methods based on pairwise correlation and pairwise consistency, which we have applied in three gene expression classification problems. We statistically prove that the proposed methods outperform the state of the art feature ranking methods Clustering Variation, Chi Squared, Correlation, Information Gain, ReliefF and Significance, as well as feature selection methods of attribute subset evaluation based on correlation and consistency with multi-objective evolutionary search strategy.
Pre-training Co-evolutionary Protein Representation via A Pairwise Masked Language Model
Oct 29, 2021

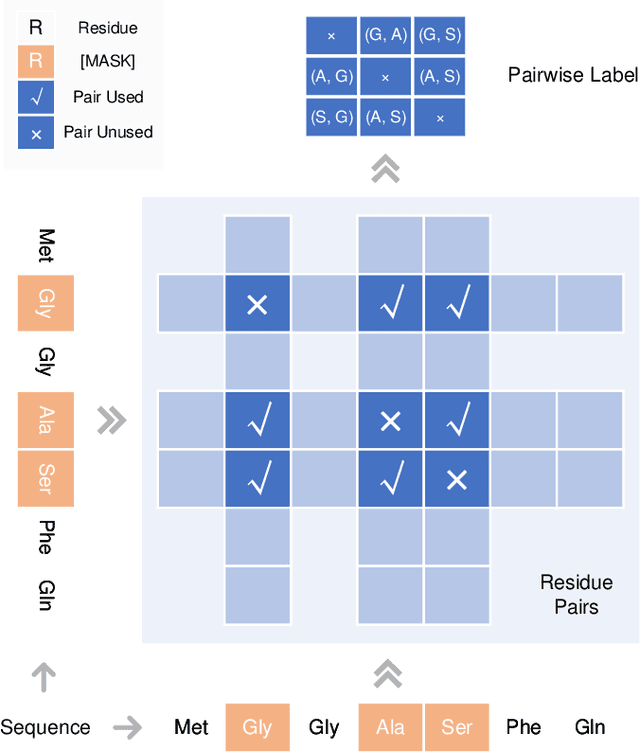

Understanding protein sequences is vital and urgent for biology, healthcare, and medicine. Labeling approaches are expensive yet time-consuming, while the amount of unlabeled data is increasing quite faster than that of the labeled data due to low-cost, high-throughput sequencing methods. In order to extract knowledge from these unlabeled data, representation learning is of significant value for protein-related tasks and has great potential for helping us learn more about protein functions and structures. The key problem in the protein sequence representation learning is to capture the co-evolutionary information reflected by the inter-residue co-variation in the sequences. Instead of leveraging multiple sequence alignment as is usually done, we propose a novel method to capture this information directly by pre-training via a dedicated language model, i.e., Pairwise Masked Language Model (PMLM). In a conventional masked language model, the masked tokens are modeled by conditioning on the unmasked tokens only, but processed independently to each other. However, our proposed PMLM takes the dependency among masked tokens into consideration, i.e., the probability of a token pair is not equal to the product of the probability of the two tokens. By applying this model, the pre-trained encoder is able to generate a better representation for protein sequences. Our result shows that the proposed method can effectively capture the inter-residue correlations and improves the performance of contact prediction by up to 9% compared to the MLM baseline under the same setting. The proposed model also significantly outperforms the MSA baseline by more than 7% on the TAPE contact prediction benchmark when pre-trained on a subset of the sequence database which the MSA is generated from, revealing the potential of the sequence pre-training method to surpass MSA based methods in general.
DILF-EN framework for Class-Incremental Learning
Dec 23, 2021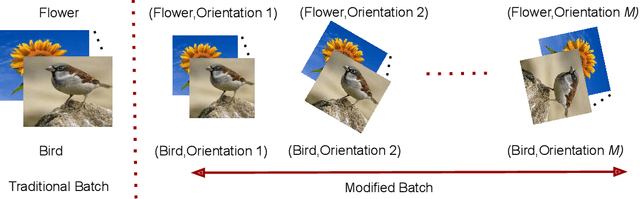
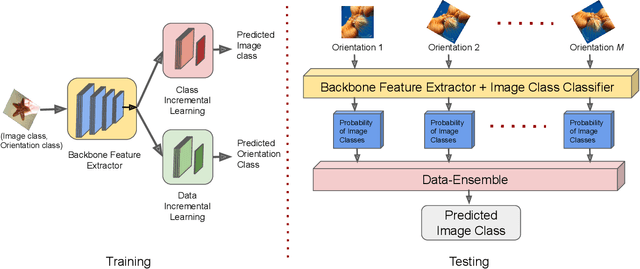


Deep learning models suffer from catastrophic forgetting of the classes in the older phases as they get trained on the classes introduced in the new phase in the class-incremental learning setting. In this work, we show that the effect of catastrophic forgetting on the model prediction varies with the change in orientation of the same image, which is a novel finding. Based on this, we propose a novel data-ensemble approach that combines the predictions for the different orientations of the image to help the model retain further information regarding the previously seen classes and thereby reduce the effect of forgetting on the model predictions. However, we cannot directly use the data-ensemble approach if the model is trained using traditional techniques. Therefore, we also propose a novel dual-incremental learning framework that involves jointly training the network with two incremental learning objectives, i.e., the class-incremental learning objective and our proposed data-incremental learning objective. In the dual-incremental learning framework, each image belongs to two classes, i.e., the image class (for class-incremental learning) and the orientation class (for data-incremental learning). In class-incremental learning, each new phase introduces a new set of classes, and the model cannot access the complete training data from the older phases. In our proposed data-incremental learning, the orientation classes remain the same across all the phases, and the data introduced by the new phase in class-incremental learning acts as new training data for these orientation classes. We empirically demonstrate that the dual-incremental learning framework is vital to the data-ensemble approach. We apply our proposed approach to state-of-the-art class-incremental learning methods and empirically show that our framework significantly improves the performance of these methods.
DRINet++: Efficient Voxel-as-point Point Cloud Segmentation
Nov 16, 2021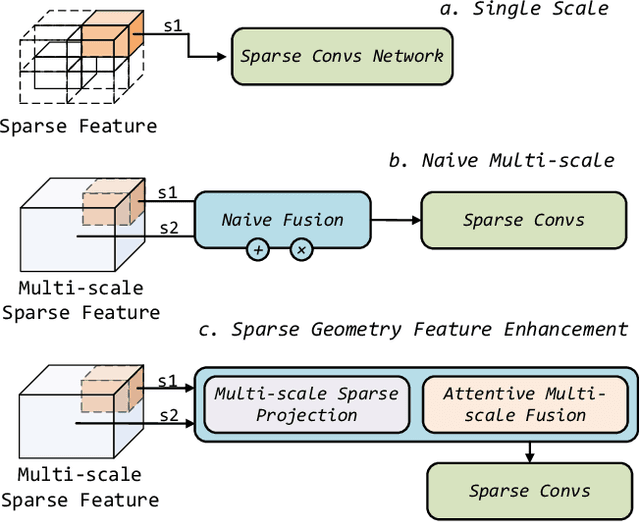
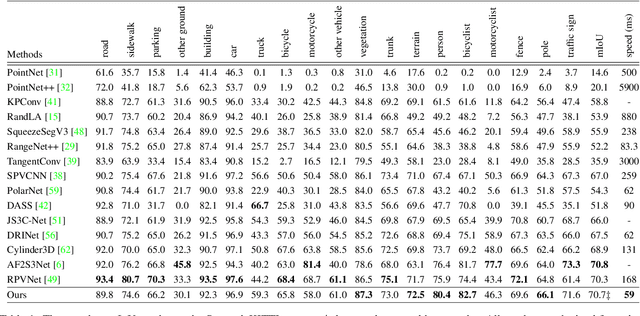
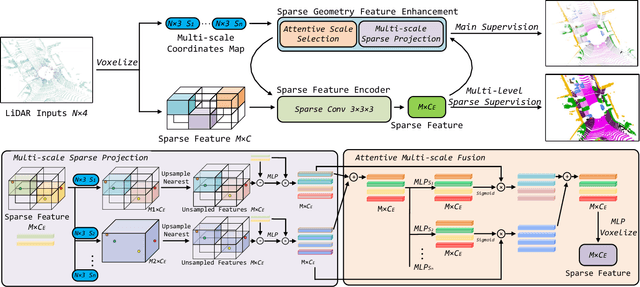
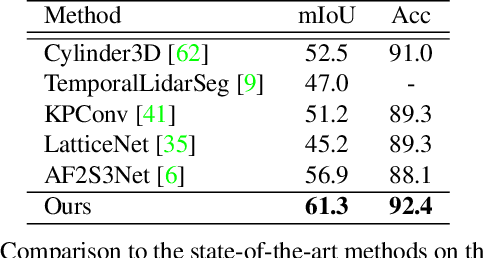
Recently, many approaches have been proposed through single or multiple representations to improve the performance of point cloud semantic segmentation. However, these works do not maintain a good balance among performance, efficiency, and memory consumption. To address these issues, we propose DRINet++ that extends DRINet by enhancing the sparsity and geometric properties of a point cloud with a voxel-as-point principle. To improve efficiency and performance, DRINet++ mainly consists of two modules: Sparse Feature Encoder and Sparse Geometry Feature Enhancement. The Sparse Feature Encoder extracts the local context information for each point, and the Sparse Geometry Feature Enhancement enhances the geometric properties of a sparse point cloud via multi-scale sparse projection and attentive multi-scale fusion. In addition, we propose deep sparse supervision in the training phase to help convergence and alleviate the memory consumption problem. Our DRINet++ achieves state-of-the-art outdoor point cloud segmentation on both SemanticKITTI and Nuscenes datasets while running significantly faster and consuming less memory.
Smart Fashion: A Review of AI Applications in the Fashion & Apparel Industry
Nov 02, 2021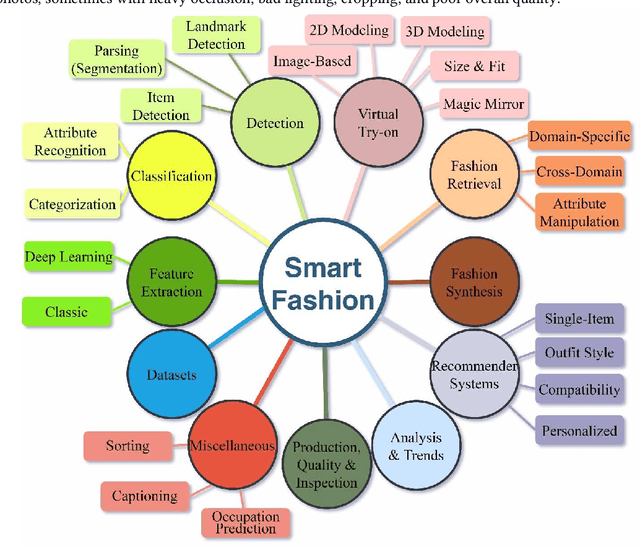
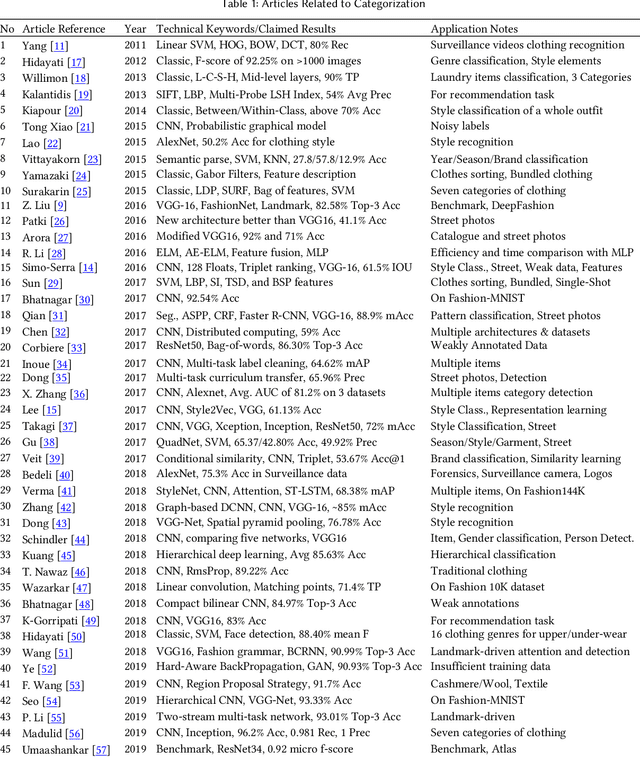

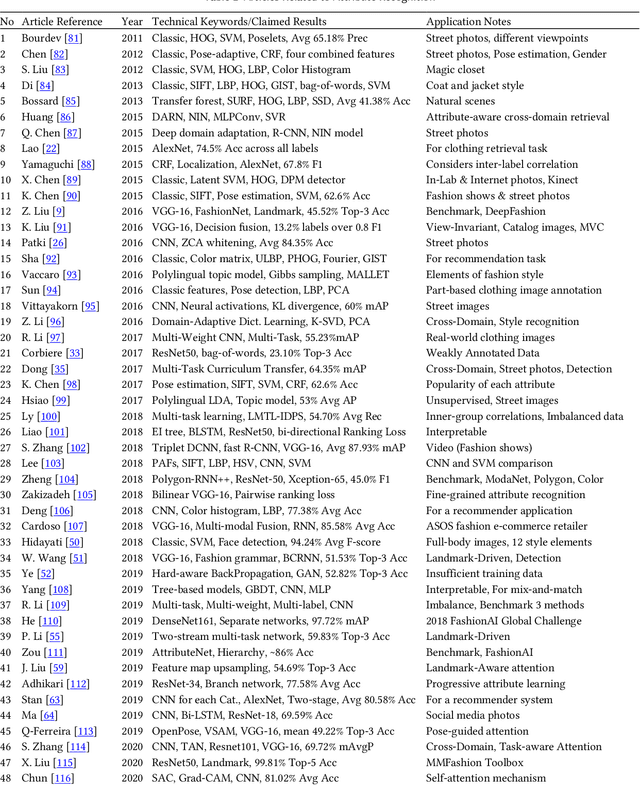
The fashion industry is on the verge of an unprecedented change. The implementation of machine learning, computer vision, and artificial intelligence (AI) in fashion applications is opening lots of new opportunities for this industry. This paper provides a comprehensive survey on this matter, categorizing more than 580 related articles into 22 well-defined fashion-related tasks. Such structured task-based multi-label classification of fashion research articles provides researchers with explicit research directions and facilitates their access to the related studies, improving the visibility of studies simultaneously. For each task, a time chart is provided to analyze the progress through the years. Furthermore, we provide a list of 86 public fashion datasets accompanied by a list of suggested applications and additional information for each.