 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIF: Complementary Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
Feb 08, 2024
Spiking neural networks (SNNs) are promising brain-inspired energy-efficient models. Compared to conventional deep Artificial Neural Networks (ANNs), SNNs exhibit superior efficiency and capability to process temporal information. However, it remains a challenge to train SNNs due to their undifferentiable spiking mechanism. The surrogate gradients method is commonly used to train SNNs, but often comes with an accuracy disadvantage over ANNs counterpart. We link the degraded accuracy to the vanishing of gradient on the temporal dimension through the analytical and experimental study of the training process of Leaky Integrate-and-Fire (LIF) Neuron-based SNNs. Moreover, we propose the Complementary Leaky Integrate-and-Fire (CLIF) Neuron. CLIF creates extra paths to facilitate the backpropagation in computing temporal gradient while keeping binary output. CLIF is hyperparameter-free and features broad applicability. Extensive experiments on a variety of datasets demonstrate CLIF's clear performance advantage over other neuron models. Moreover, the CLIF's performance even slightly surpasses superior ANNs with identical network structure and training conditions.
Binding Dynamics in Rotating Features
Feb 08, 2024In human cognition, the binding problem describes the open question of how the brain flexibly integrates diverse information into cohesive object representations. Analogously, in machine learning, there is a pursuit for models capable of strong generalization and reasoning by learning object-centric representations in an unsupervised manner. Drawing from neuroscientific theories, Rotating Features learn such representations by introducing vector-valued features that encapsulate object characteristics in their magnitudes and object affiliation in their orientations. The "$\chi$-binding" mechanism, embedded in every layer of the architecture, has been shown to be crucial, but remains poorly understood. In this paper, we propose an alternative "cosine binding" mechanism, which explicitly computes the alignment between features and adjusts weights accordingly, and we show that it achieves equivalent performance. This allows us to draw direct connections to self-attention and biological neural processes, and to shed light on the fundamental dynamics for object-centric representations to emerge in Rotating Features.
Read to Play (R2-Play): Decision Transformer with Multimodal Game Instruction
Feb 08, 2024Developing a generalist agent is a longstanding objective in artificial intelligence. Previous efforts utilizing extensive offline datasets from various tasks demonstrate remarkable performance in multitasking scenarios within Reinforcement Learning. However, these works encounter challenges in extending their capabilities to new tasks. Recent approaches integrate textual guidance or visual trajectory into decision networks to provide task-specific contextual cues, representing a promising direction. However, it is observed that relying solely on textual guidance or visual trajectory is insufficient for accurately conveying the contextual information of tasks. This paper explores enhanced forms of task guidance for agents, enabling them to comprehend gameplay instructions, thereby facilitating a "read-to-play" capability. Drawing inspiration from the success of multimodal instruction tuning in visual tasks, we treat the visual-based RL task as a long-horizon vision task and construct a set of multimodal game instructions to incorporate instruction tuning into a decision transformer. Experimental results demonstrate that incorporating multimodal game instructions significantly enhances the decision transformer's multitasking and generalization capabilities.
Function Aligned Regression: A Method Explicitly Learns Functional Derivatives from Data
Feb 08, 2024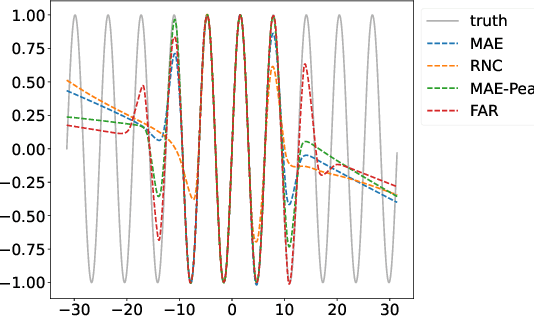
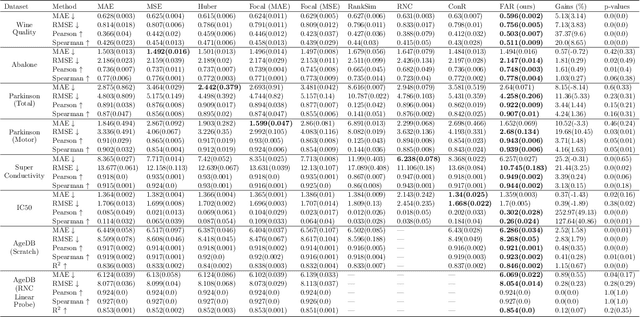
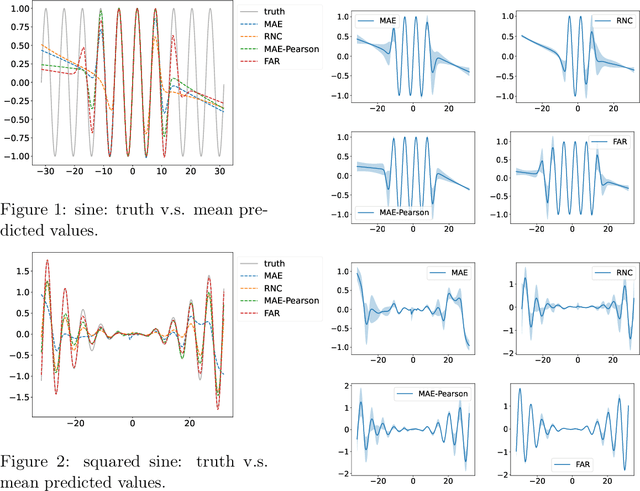
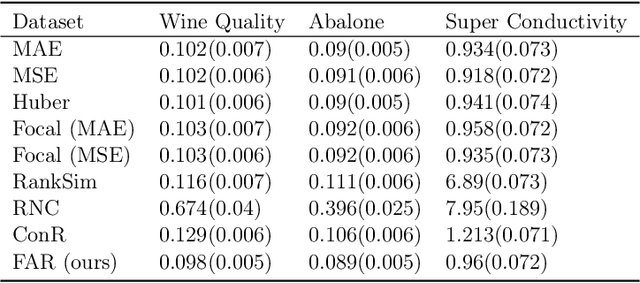
Regression is a fundamental task in machine learning that has garnered extensive attention over the past decades. The conventional approach for regression involves employing loss functions that primarily concentrate on aligning model prediction with the ground truth for each individual data sample, which, as we show, can result in sub-optimal prediction of the relationships between the different samples. Recent research endeavors have introduced novel perspectives by incorporating label similarity information to regression. However, a notable gap persists in these approaches when it comes to fully capturing the intricacies of the underlying ground truth function. In this work, we propose FAR (Function Aligned Regression) as a arguably better and more efficient solution to fit the underlying function of ground truth by capturing functional derivatives. We demonstrate the effectiveness of the proposed method practically on 2 synthetic datasets and on 8 extensive real-world tasks from 6 benchmark datasets with other 8 competitive baselines. The code is open-sourced at \url{https://github.com/DixianZhu/FAR}.
An Interactive Agent Foundation Model
Feb 08, 2024The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Improving importance estimation in covariate shift for providing accurate prediction error
Feb 02, 2024In traditional Machine Learning, the algorithms predictions are based on the assumption that the data follows the same distribution in both the training and the test datasets. However, in real world data this condition does not hold and, for instance, the distribution of the covariates changes whereas the conditional distribution of the targets remains unchanged. This situation is called covariate shift problem where standard error estimation may be no longer accurate. In this context, the importance is a measure commonly used to alleviate the influence of covariate shift on error estimations. The main drawback is that it is not easy to compute. The Kullback-Leibler Importance Estimation Procedure (KLIEP) is capable of estimating importance in a promising way. Despite its good performance, it fails to ignore target information, since it only includes the covariates information for computing the importance. In this direction, this paper explores the potential performance improvement if target information is considered in the computation of the importance. Then, a redefinition of the importance arises in order to be generalized in this way. Besides the potential improvement in performance, including target information make possible the application to a real application about plankton classification that motivates this research and characterized by its great dimensionality, since considering targets rather than covariates reduces the computation and the noise in the covariates. The impact of taking target information is also explored when Logistic Regression (LR), Kernel Mean Matching (KMM), Ensemble Kernel Mean Matching (EKMM) and the naive predecessor of KLIEP called Kernel Density Estimation (KDE) methods estimate the importance. The experimental results lead to a more accurate error estimation using target information, especially in case of the more promising method KLIEP.
Mastering Zero-Shot Interactions in Cooperative and Competitive Simultaneous Games
Feb 05, 2024The combination of self-play and planning has achieved great successes in sequential games, for instance in Chess and Go. However, adapting algorithms such as AlphaZero to simultaneous games poses a new challenge. In these games, missing information about concurrent actions of other agents is a limiting factor as they may select different Nash equilibria or do not play optimally at all. Thus, it is vital to model the behavior of the other agents when interacting with them in simultaneous games. To this end, we propose Albatross: AlphaZero for Learning Bounded-rational Agents and Temperature-based Response Optimization using Simulated Self-play. Albatross learns to play the novel equilibrium concept of a Smooth Best Response Logit Equilibrium (SBRLE), which enables cooperation and competition with agents of any playing strength. We perform an extensive evaluation of Albatross on a set of cooperative and competitive simultaneous perfect-information games. In contrast to AlphaZero, Albatross is able to exploit weak agents in the competitive game of Battlesnake. Additionally, it yields an improvement of 37.6% compared to previous state of the art in the cooperative Overcooked benchmark.
Lossy Compression of Adjacency Matrices by Graph Filter Banks
Feb 05, 2024This paper proposes a compression framework for adjacency matrices of weighted graphs based on graph filter banks. Adjacency matrices are widely used mathematical representations of graphs and are used in various applications in signal processing, machine learning, and data mining. In many problems of interest, these adjacency matrices can be large, so efficient compression methods are crucial. In this paper, we propose a lossy compression of weighted adjacency matrices, where the binary adjacency information is encoded losslessly (so the topological information of the graph is preserved) while the edge weights are compressed lossily. For the edge weight compression, the target graph is converted into a line graph, whose nodes correspond to the edges of the original graph, and where the original edge weights are regarded as a graph signal on the line graph. We then transform the edge weights on the line graph with a graph filter bank for sparse representation. Experiments on synthetic data validate the effectiveness of the proposed method by comparing it with existing lossy matrix compression methods.
Fast and Accurate Cooperative Radio Map Estimation Enabled by GAN
Feb 05, 2024In the 6G era, real-time radio resource monitoring and management are urged to support diverse wireless-empowered applications. This calls for fast and accurate estimation on the distribution of the radio resources, which is usually represented by the spatial signal power strength over the geographical environment, known as a radio map. In this paper, we present a cooperative radio map estimation (CRME) approach enabled by the generative adversarial network (GAN), called as GAN-CRME, which features fast and accurate radio map estimation without the transmitters' information. The radio map is inferred by exploiting the interaction between distributed received signal strength (RSS) measurements at mobile users and the geographical map using a deep neural network estimator, resulting in low data-acquisition cost and computational complexity. Moreover, a GAN-based learning algorithm is proposed to boost the inference capability of the deep neural network estimator by exploiting the power of generative AI. Simulation results showcase that the proposed GAN-CRME is even capable of coarse error-correction when the geographical map information is inaccurate.
EXGC: Bridging Efficiency and Explainability in Graph Condensation
Feb 05, 2024Graph representation learning on vast datasets, like web data, has made significant strides. However, the associated computational and storage overheads raise concerns. In sight of this, Graph condensation (GCond) has been introduced to distill these large real datasets into a more concise yet information-rich synthetic graph. Despite acceleration efforts, existing GCond methods mainly grapple with efficiency, especially on expansive web data graphs. Hence, in this work, we pinpoint two major inefficiencies of current paradigms: (1) the concurrent updating of a vast parameter set, and (2) pronounced parameter redundancy. To counteract these two limitations correspondingly, we first (1) employ the Mean-Field variational approximation for convergence acceleration, and then (2) propose the objective of Gradient Information Bottleneck (GDIB) to prune redundancy. By incorporating the leading explanation techniques (e.g., GNNExplainer and GSAT) to instantiate the GDIB, our EXGC, the Efficient and eXplainable Graph Condensation method is proposed, which can markedly boost efficiency and inject explainability. Our extensive evaluations across eight datasets underscore EXGC's superiority and relevance. Code is available at https://github.com/MangoKiller/EXGC.