 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding the Effectiveness of Reviews in E-commerce Top-N Recommendation
Jun 17, 2021

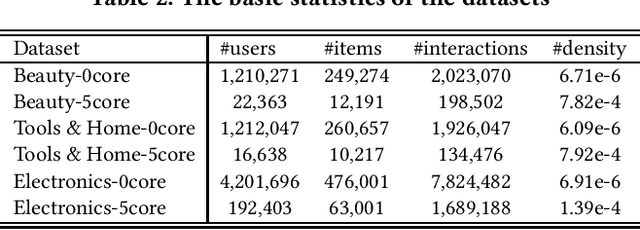
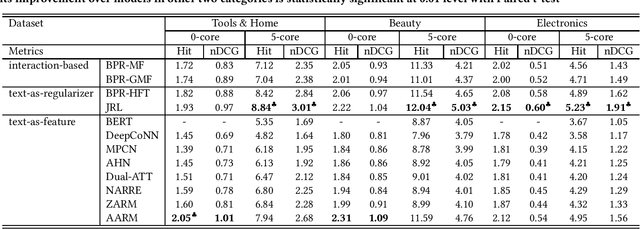
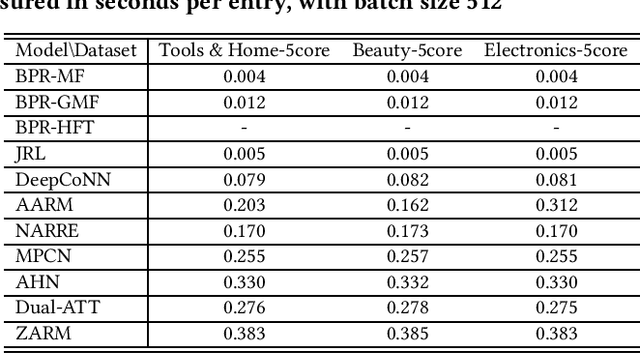
Modern E-commerce websites contain heterogeneous sources of information, such as numerical ratings, textual reviews and images. These information can be utilized to assist recommendation. Through textual reviews, a user explicitly express her affinity towards the item. Previous researchers found that by using the information extracted from these reviews, we can better profile the users' explicit preferences as well as the item features, leading to the improvement of recommendation performance. However, most of the previous algorithms were only utilizing the review information for explicit-feedback problem i.e. rating prediction, and when it comes to implicit-feedback ranking problem such as top-N recommendation, the usage of review information has not been fully explored. Seeing this gap, in this work, we investigate the effectiveness of textual review information for top-N recommendation under E-commerce settings. We adapt several SOTA review-based rating prediction models for top-N recommendation tasks and compare them to existing top-N recommendation models from both performance and efficiency. We find that models utilizing only review information can not achieve better performances than vanilla implicit-feedback matrix factorization method. When utilizing review information as a regularizer or auxiliary information, the performance of implicit-feedback matrix factorization method can be further improved. However, the optimal model structure to utilize textual reviews for E-commerce top-N recommendation is yet to be determined.
DeepGOMIMO: Deep Learning-Aided Generalized Optical MIMO with CSI-Free Blind Detection
Oct 08, 2021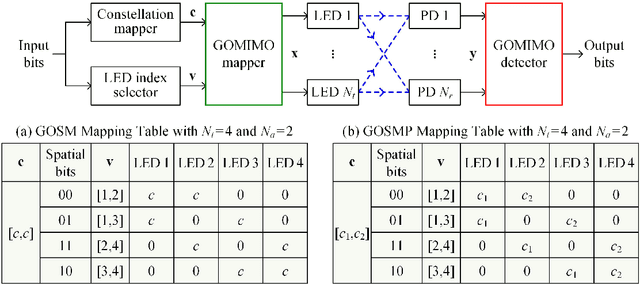
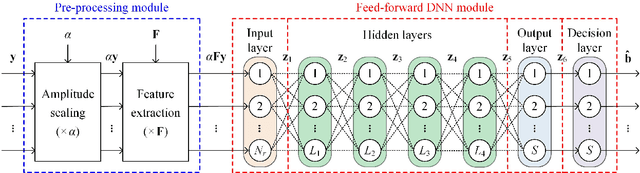
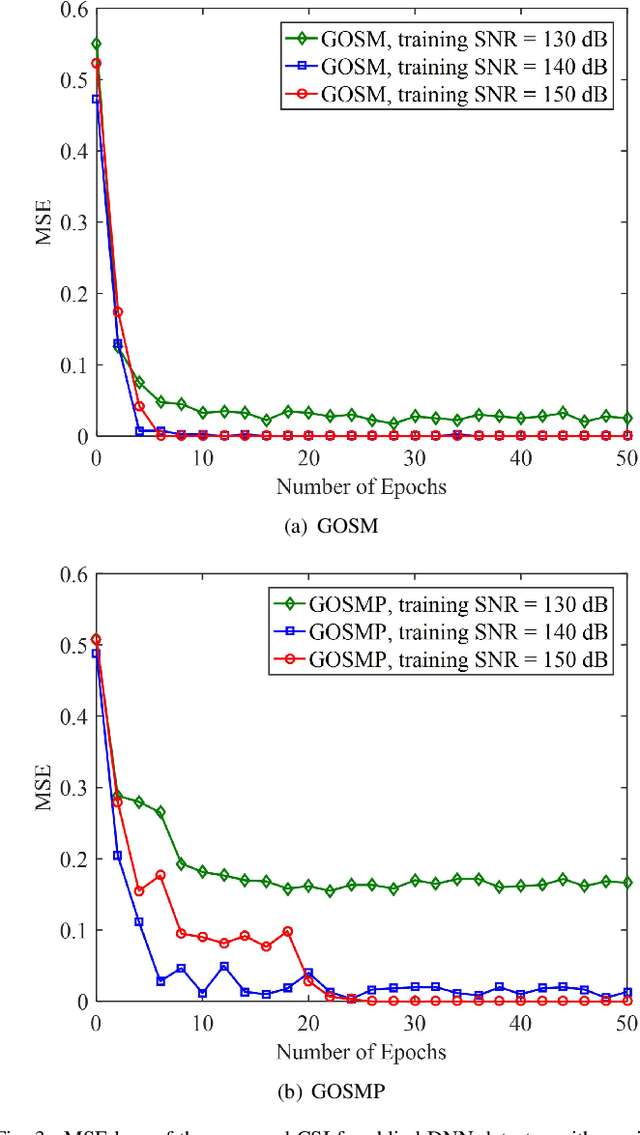
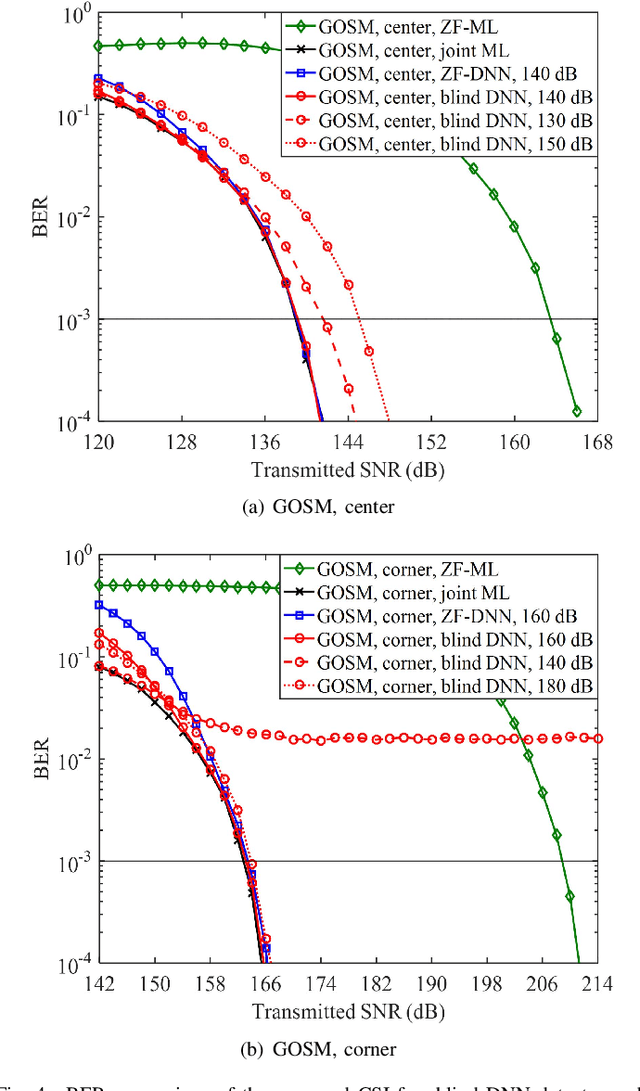
Generalized optical multiple-input multiple-output (GOMIMO) techniques have been recently shown to be promising for high-speed optical wireless communication (OWC) systems. In this paper, we propose a novel deep learning-aided GOMIMO (DeepGOMIMO) framework for GOMIMO systems, where channel state information (CSI)-free blind detection can be enabled by employing a specially designed deep neural network (DNN)-based MIMO detector. The CSI-free blind DNN detector mainly consists of two modules: one is the pre-processing module which is designed to address both the path loss and channel crosstalk issues caused by MIMO transmission, and the other is the feed-forward DNN module which is used for joint detection of spatial and constellation information by learning the statistics of both the input signal and the additive noise. Our simulation results clearly verify that, in a typical indoor 4 $\times$ 4 MIMO-OWC system using both generalized optical spatial modulation (GOSM) and generalized optical spatial multiplexing (GOSMP) with unipolar non-zero 4-ary pulse amplitude modulation (4-PAM) modulation, the proposed CSI-free blind DNN detector achieves near the same bit error rate (BER) performance as the optimal joint maximum-likelihood (ML) detector, but with much reduced computational complexity. Moreover, since the CSI-free blind DNN detector does not require instantaneous channel estimation to obtain accurate CSI, it enjoys the unique advantages of improved achievable data rate and reduced communication time delay in comparison to the CSI-based zero-forcing DNN (ZF-DNN) detector.
Deep network for rolling shutter rectification
Dec 12, 2021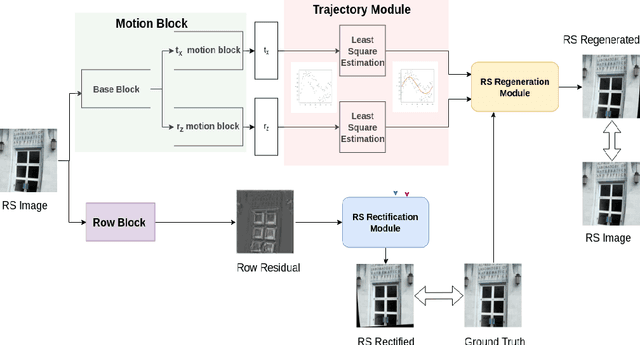



CMOS sensors employ row-wise acquisition mechanism while imaging a scene, which can result in undesired motion artifacts known as rolling shutter (RS) distortions in the captured image. Existing single image RS rectification methods attempt to account for these distortions by either using algorithms tailored for specific class of scenes which warrants information of intrinsic camera parameters or a learning-based framework with known ground truth motion parameters. In this paper, we propose an end-to-end deep neural network for the challenging task of single image RS rectification. Our network consists of a motion block, a trajectory module, a row block, an RS rectification module and an RS regeneration module (which is used only during training). The motion block predicts camera pose for every row of the input RS distorted image while the trajectory module fits estimated motion parameters to a third-order polynomial. The row block predicts the camera motion that must be associated with every pixel in the target i.e, RS rectified image. Finally, the RS rectification module uses motion trajectory and the output of row block to warp the input RS image to arrive at a distortionfree image. For faster convergence during training, we additionally use an RS regeneration module which compares the input RS image with the ground truth image distorted by estimated motion parameters. The end-to-end formulation in our model does not constrain the estimated motion to ground-truth motion parameters, thereby successfully rectifying the RS images with complex real-life camera motion. Experiments on synthetic and real datasets reveal that our network outperforms prior art both qualitatively and quantitatively.
Feature matching for multi-epoch historical aerial images
Dec 08, 2021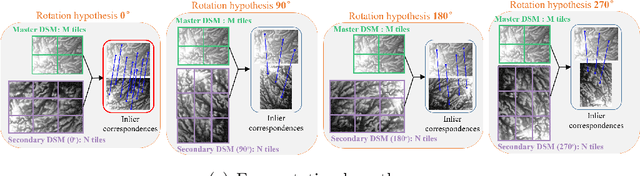
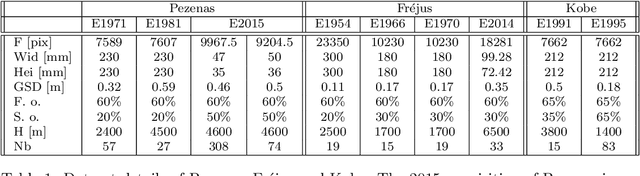
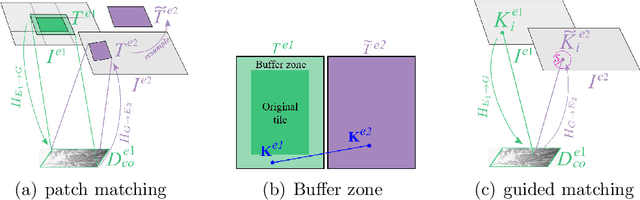
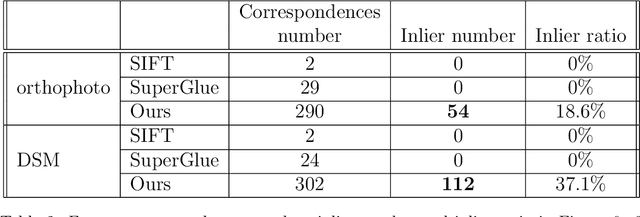
Historical imagery is characterized by high spatial resolution and stereo-scopic acquisitions, providing a valuable resource for recovering 3D land-cover information. Accurate geo-referencing of diachronic historical images by means of self-calibration remains a bottleneck because of the difficulty to find sufficient amount of feature correspondences under evolving landscapes. In this research, we present a fully automatic approach to detecting feature correspondences between historical images taken at different times (i.e., inter-epoch), without auxiliary data required. Based on relative orientations computed within the same epoch (i.e., intra-epoch), we obtain DSMs (Digital Surface Model) and incorporate them in a rough-to-precise matching. The method consists of: (1) an inter-epoch DSMs matching to roughly co-register the orientations and DSMs (i.e, the 3D Helmert transformation), followed by (2) a precise inter-epoch feature matching using the original RGB images. The innate ambiguity of the latter is largely alleviated by narrowing down the search space using the co-registered data. With the inter-epoch features, we refine the image orientations and quantitatively evaluate the results (1) with DoD (Difference of DSMs), (2) with ground check points, and (3) by quantifying ground displacement due to an earthquake. We demonstrate that our method: (1) can automatically georeference diachronic historical images; (2) can effectively mitigate systematic errors induced by poorly estimated camera parameters; (3) is robust to drastic scene changes. Compared to the state-of-the-art, our method improves the image georeferencing accuracy by a factor of 2. The proposed methods are implemented in MicMac, a free, open-source photogrammetric software.
* 34 pages
Graph-augmented Learning to Rank for Querying Large-scale Knowledge Graph
Nov 20, 2021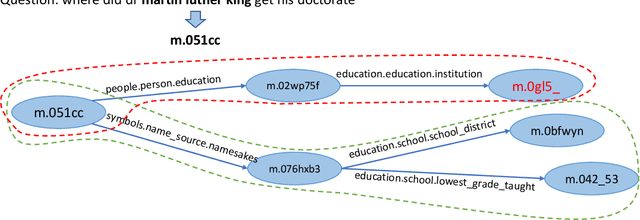

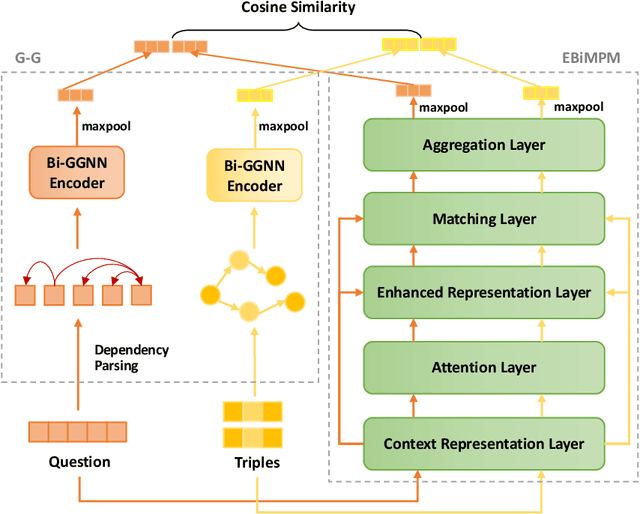
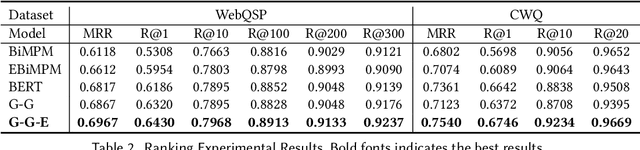
Knowledge graph question answering (i.e., KGQA) based on information retrieval aims to answer a question by retrieving answer from a large-scale knowledge graph. Most existing methods first roughly retrieve the knowledge subgraphs (KSG) that may contain candidate answer, and then search for the exact answer in the subgraph. However, the coarsely retrieved KSG may contain thousands of candidate nodes since the knowledge graph involved in querying is often of large scale. To tackle this problem, we first propose to partition the retrieved KSG to several smaller sub-KSGs via a new subgraph partition algorithm and then present a graph-augmented learning to rank model to select the top-ranked sub-KSGs from them. Our proposed model combines a novel subgraph matching networks to capture global interactions in both question and subgraphs and an Enhanced Bilateral Multi-Perspective Matching model to capture local interactions. Finally, we apply an answer selection model on the full KSG and the top-ranked sub-KSGs respectively to validate the effectiveness of our proposed graph-augmented learning to rank method. The experimental results on multiple benchmark datasets have demonstrated the effectiveness of our approach.
Temporal-MPI: Enabling Multi-Plane Images for Dynamic Scene Modelling via Temporal Basis Learning
Nov 20, 2021
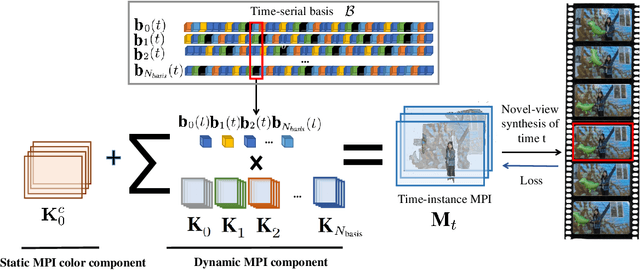

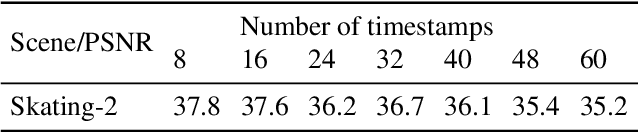
Novel view synthesis of static scenes has achieved remarkable advancements in producing photo-realistic results. However, key challenges remain for immersive rendering for dynamic contents. For example, one of the seminal image-based rendering frameworks, the multi-plane image (MPI) produces high novel-view synthesis quality for static scenes but faces difficulty in modeling dynamic parts. In addition, modeling dynamic variations through MPI may require huge storage space and long inference time, which hinders its application in real-time scenarios. In this paper, we propose a novel Temporal-MPI representation which is able to encode the rich 3D and dynamic variation information throughout the entire video as compact temporal basis. Novel-views at arbitrary time-instance will be able to be rendered real-time with high visual quality due to the highly compact and expressive latent basis and the coefficients jointly learned. We show that given comparable memory consumption, our proposed Temporal-MPI framework is able to generate a time-instance MPI with only 0.002 seconds, which is up to 3000 times faster, with 3dB higher average view-synthesis PSNR as compared with other state-of-the-art dynamic scene modelling frameworks.
A Deep Reinforcement Learning Approach for Audio-based Navigation and Audio Source Localization in Multi-speaker Environments
Nov 08, 2021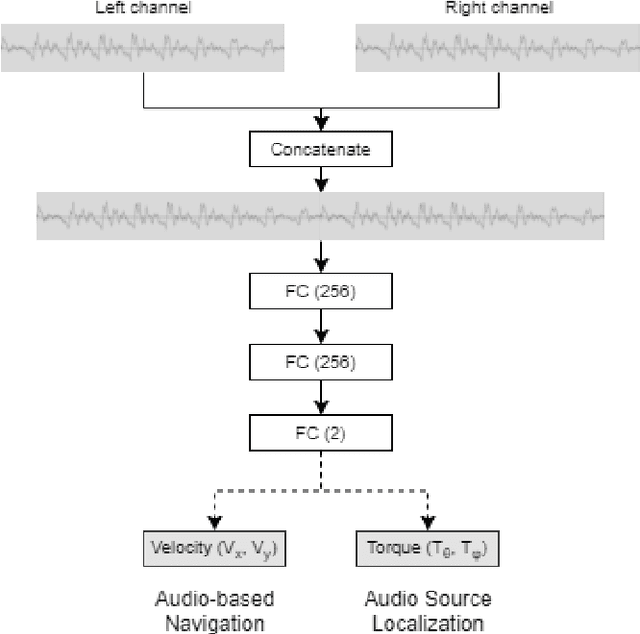
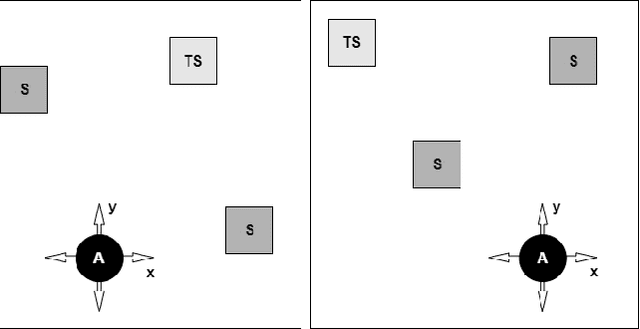
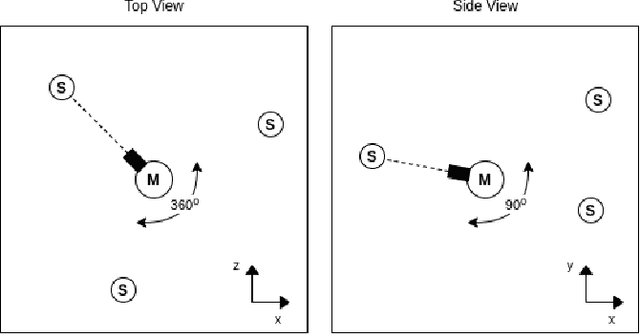
In this work we apply deep reinforcement learning to the problems of navigating a three-dimensional environment and inferring the locations of human speaker audio sources within, in the case where the only available information is the raw sound from the environment, as a simulated human listener placed in the environment would hear it. For this purpose we create two virtual environments using the Unity game engine, one presenting an audio-based navigation problem and one presenting an audio source localization problem. We also create an autonomous agent based on PPO online reinforcement learning algorithm and attempt to train it to solve these environments. Our experiments show that our agent achieves adequate performance and generalization ability in both environments, measured by quantitative metrics, even when a limited amount of training data are available or the environment parameters shift in ways not encountered during training. We also show that a degree of agent knowledge transfer is possible between the environments.
Maximize the Exploration of Congeneric Semantics for Weakly Supervised Semantic Segmentation
Oct 08, 2021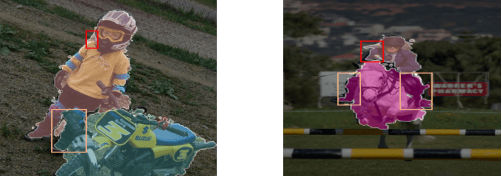

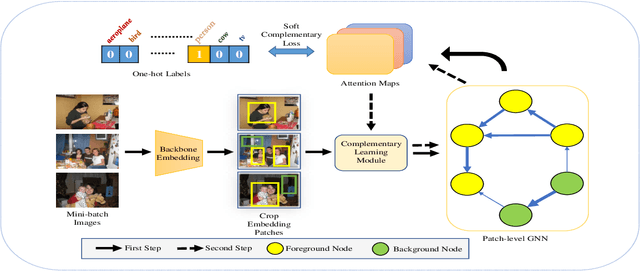

With the increase in the number of image data and the lack of corresponding labels, weakly supervised learning has drawn a lot of attention recently in computer vision tasks, especially in the fine-grained semantic segmentation problem. To alleviate human efforts from expensive pixel-by-pixel annotations, our method focuses on weakly supervised semantic segmentation (WSSS) with image-level tags, which are much easier to obtain. As a huge gap exists between pixel-level segmentation and image-level labels, how to reflect the image-level semantic information on each pixel is an important question. To explore the congeneric semantic regions from the same class to the maximum, we construct the patch-level graph neural network (P-GNN) based on the self-detected patches from different images that contain the same class labels. Patches can frame the objects as much as possible and include as little background as possible. The graph network that is established with patches as the nodes can maximize the mutual learning of similar objects. We regard the embedding vectors of patches as nodes, and use transformer-based complementary learning module to construct weighted edges according to the embedding similarity between different nodes. Moreover, to better supplement semantic information, we propose soft-complementary loss functions matched with the whole network structure. We conduct experiments on the popular PASCAL VOC 2012 benchmarks, and our model yields state-of-the-art performance.
Multi-Level Visual Similarity Based Personalized Tourist Attraction Recommendation Using Geo-Tagged Photos
Sep 17, 2021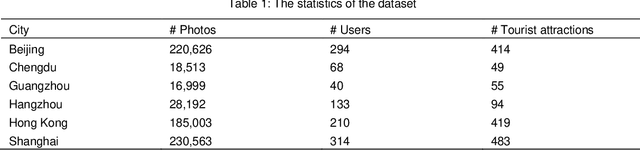
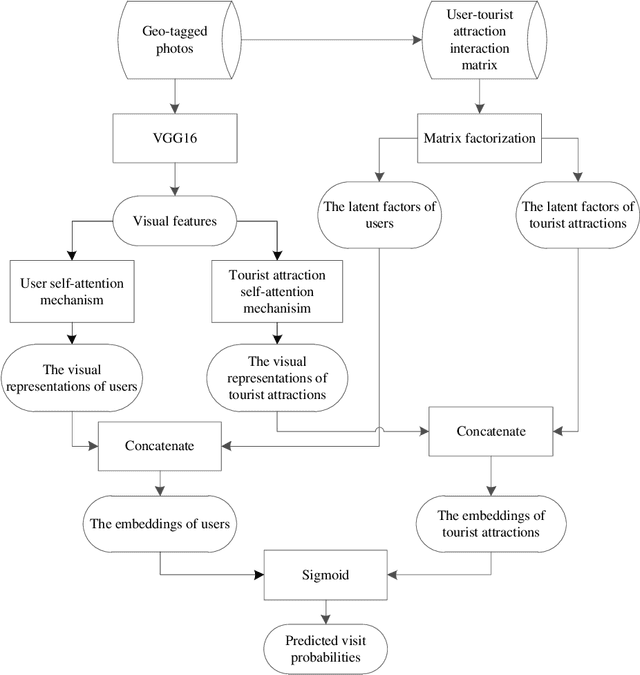
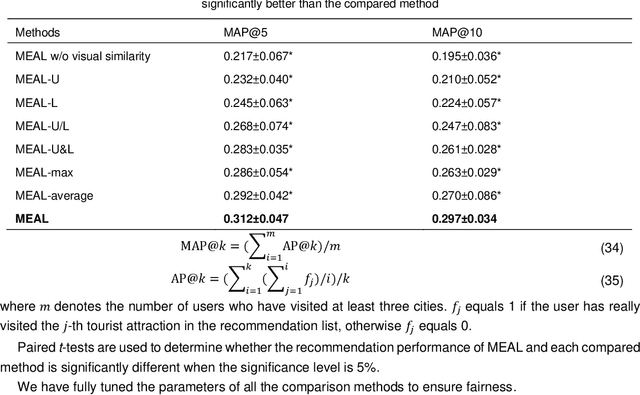
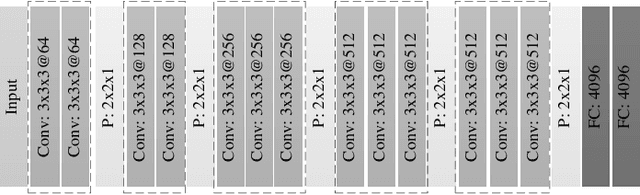
Geo-tagged photo based tourist attraction recommendation can discover users' travel preferences from their taken photos, so as to recommend suitable tourist attractions to them. However, existing visual content based methods cannot fully exploit the user and tourist attraction information of photos to extract visual features, and do not differentiate the significances of different photos. In this paper, we propose multi-level visual similarity based personalized tourist attraction recommendation using geo-tagged photos (MEAL). MEAL utilizes the visual contents of photos and interaction behavior data to obtain the final embeddings of users and tourist attractions, which are then used to predict the visit probabilities. Specifically, by crossing the user and tourist attraction information of photos, we define four visual similarity levels and introduce a corresponding quintuplet loss to embed the visual contents of photos. In addition, to capture the significances of different photos, we exploit the self-attention mechanism to obtain the visual representations of users and tourist attractions. We conducted experiments on a dataset crawled from Flickr, and the experimental results proved the advantage of this method.
Concept-Aware Denoising Graph Neural Network for Micro-Video Recommendation
Sep 28, 2021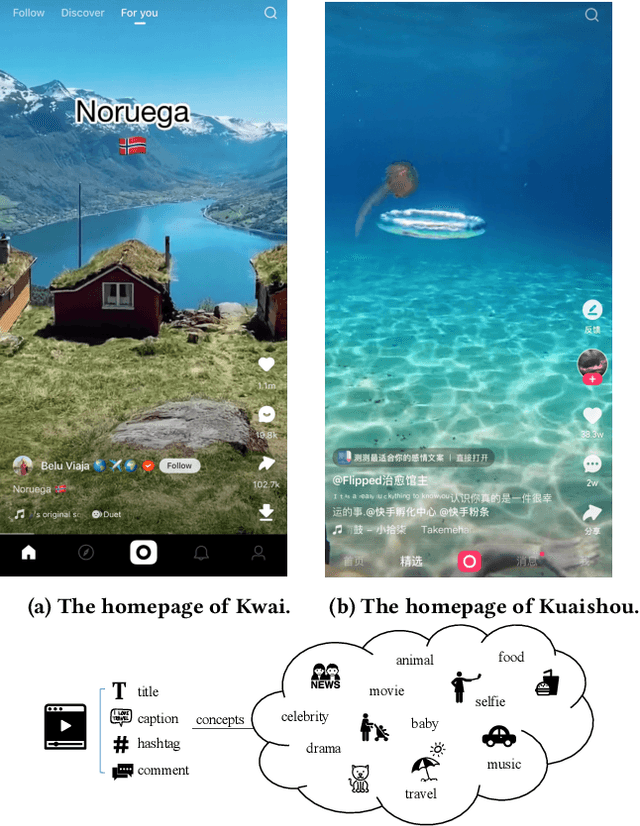

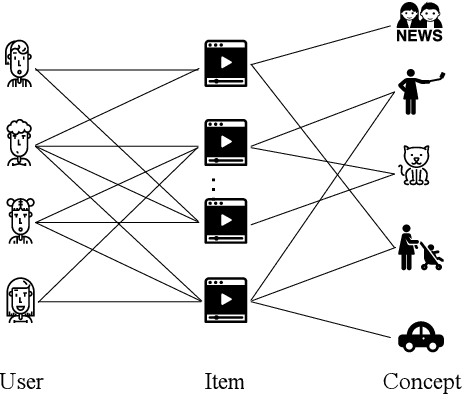
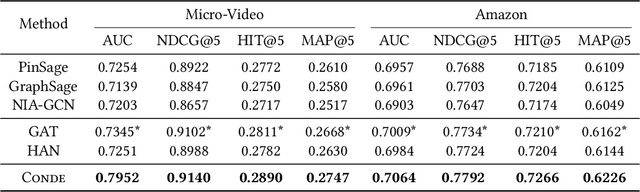
Recently, micro-video sharing platforms such as Kuaishou and Tiktok have become a major source of information for people's lives. Thanks to the large traffic volume, short video lifespan and streaming fashion of these services, it has become more and more pressing to improve the existing recommender systems to accommodate these challenges in a cost-effective way. In this paper, we propose a novel concept-aware denoising graph neural network (named CONDE) for micro-video recommendation. CONDE consists of a three-phase graph convolution process to derive user and micro-video representations: warm-up propagation, graph denoising and preference refinement. A heterogeneous tripartite graph is constructed by connecting user nodes with video nodes, and video nodes with associated concept nodes, extracted from captions and comments of the videos. To address the noisy information in the graph, we introduce a user-oriented graph denoising phase to extract a subgraph which can better reflect the user's preference. Despite the main focus of micro-video recommendation in this paper, we also show that our method can be generalized to other types of tasks. Therefore, we also conduct empirical studies on a well-known public E-commerce dataset. The experimental results suggest that the proposed CONDE achieves significantly better recommendation performance than the existing state-of-the-art solutions.