 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two-stage Visual Cues Enhancement Network for Referring Image Segmentation
Oct 09, 2021
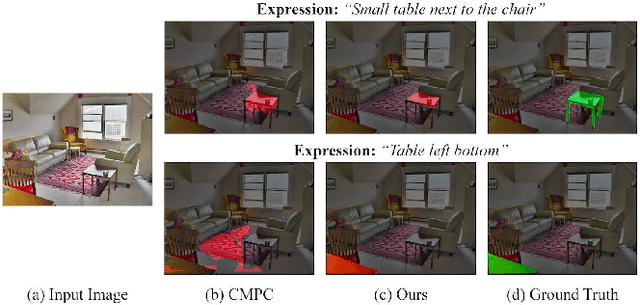
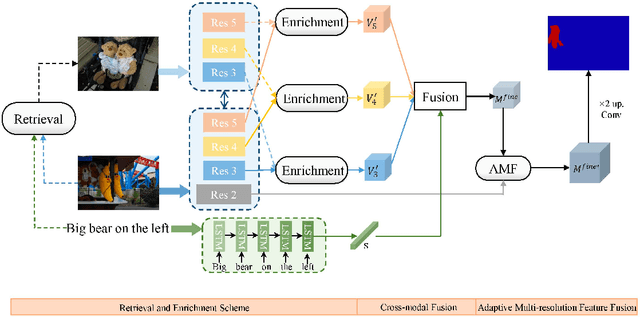
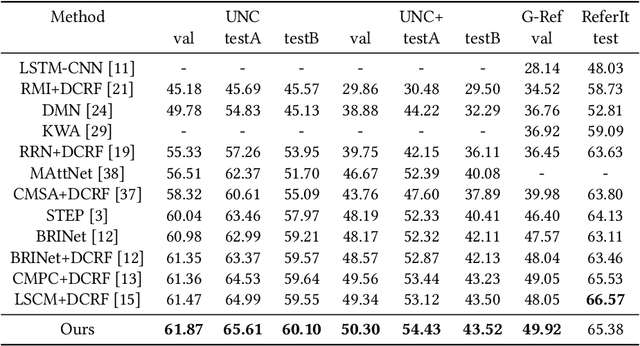
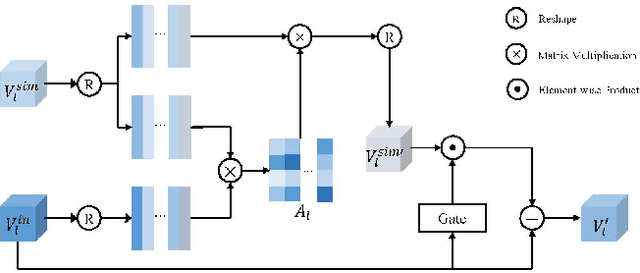
Referring Image Segmentation (RIS) aims at segmenting the target object from an image referred by one given natural language expression. The diverse and flexible expressions as well as complex visual contents in the images raise the RIS model with higher demands for investigating fine-grained matching behaviors between words in expressions and objects presented in images. However, such matching behaviors are hard to be learned and captured when the visual cues of referents (i.e. referred objects) are insufficient, as the referents with weak visual cues tend to be easily confused by cluttered background at boundary or even overwhelmed by salient objects in the image. And the insufficient visual cues issue can not be handled by the cross-modal fusion mechanisms as done in previous work. In this paper, we tackle this problem from a novel perspective of enhancing the visual information for the referents by devising a Two-stage Visual cues enhancement Network (TV-Net), where a novel Retrieval and Enrichment Scheme (RES) and an Adaptive Multi-resolution feature Fusion (AMF) module are proposed. Through the two-stage enhancement, our proposed TV-Net enjoys better performances in learning fine-grained matching behaviors between the natural language expression and image, especially when the visual information of the referent is inadequate, thus produces better segmentation results. Extensive experiments are conducted to validate the effectiveness of the proposed method on the RIS task, with our proposed TV-Net surpassing the state-of-the-art approaches on four benchmark datasets.
Soliciting User Preferences in Conversational Recommender Systems via Usage-related Questions
Nov 26, 2021

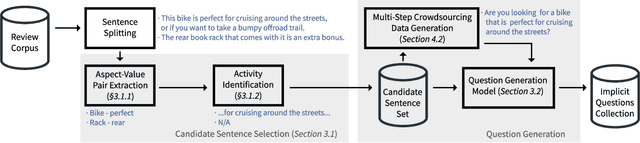
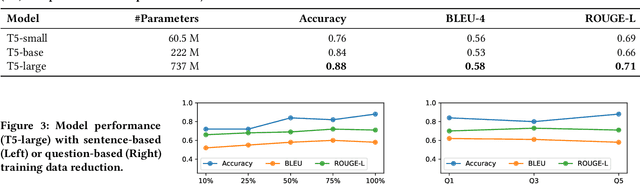
A key distinguishing feature of conversational recommender systems over traditional recommender systems is their ability to elicit user preferences using natural language. Currently, the predominant approach to preference elicitation is to ask questions directly about items or item attributes. These strategies do not perform well in cases where the user does not have sufficient knowledge of the target domain to answer such questions. Conversely, in a shopping setting, talking about the planned use of items does not present any difficulties, even for those that are new to a domain. In this paper, we propose a novel approach to preference elicitation by asking implicit questions based on item usage. Our approach consists of two main steps. First, we identify the sentences from a large review corpus that contain information about item usage. Then, we generate implicit preference elicitation questions from those sentences using a neural text-to-text model. The main contributions of this work also include a multi-stage data annotation protocol using crowdsourcing for collecting high-quality labeled training data for the neural model. We show that our approach is effective in selecting review sentences and transforming them to elicitation questions, even with limited training data. Additionally, we provide an analysis of patterns where the model does not perform optimally.
Common Language for Goal-Oriented Semantic Communications: A Curriculum Learning Framework
Nov 15, 2021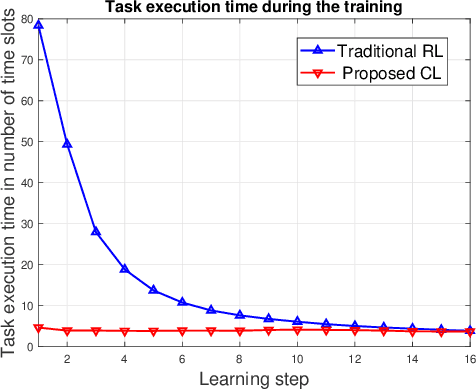
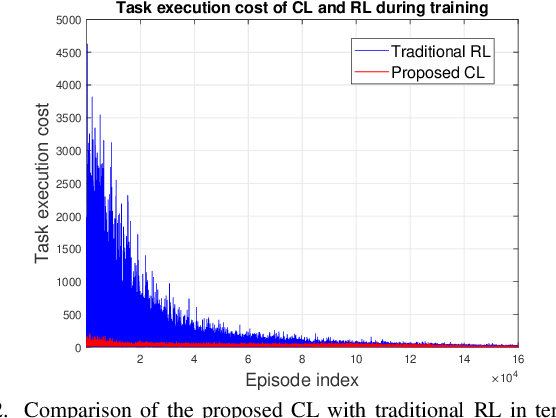
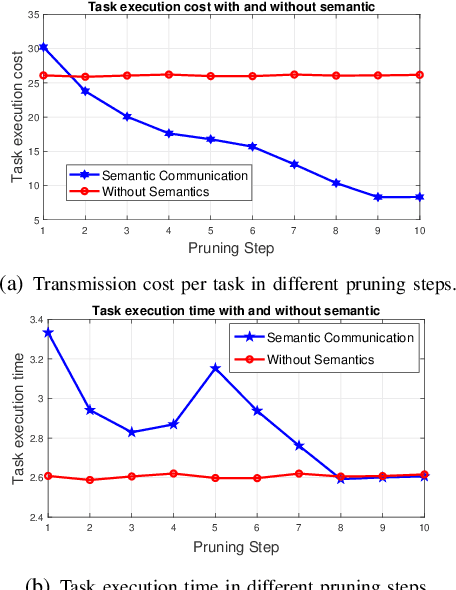
Semantic communications will play a critical role in enabling goal-oriented services over next-generation wireless systems. However, most prior art in this domain is restricted to specific applications (e.g., text or image), and it does not enable goal-oriented communications in which the effectiveness of the transmitted information must be considered along with the semantics so as to execute a certain task. In this paper, a comprehensive semantic communications framework is proposed for enabling goal-oriented task execution. To capture the semantics between a speaker and a listener, a common language is defined using the concept of beliefs to enable the speaker to describe the environment observations to the listener. Then, an optimization problem is posed to choose the minimum set of beliefs that perfectly describes the observation while minimizing the task execution time and transmission cost. A novel top-down framework that combines curriculum learning (CL) and reinforcement learning (RL) is proposed to solve this problem. Simulation results show that the proposed CL method outperforms traditional RL in terms of convergence time, task execution time, and transmission cost during training.
DGL-GAN: Discriminator Guided Learning for GAN Compression
Dec 13, 2021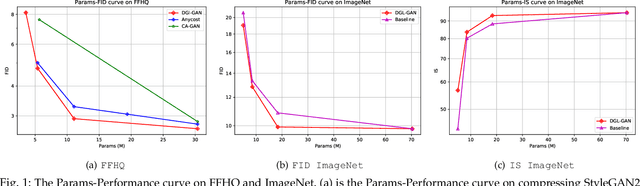
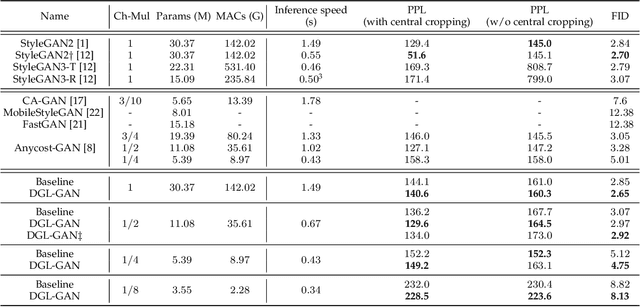
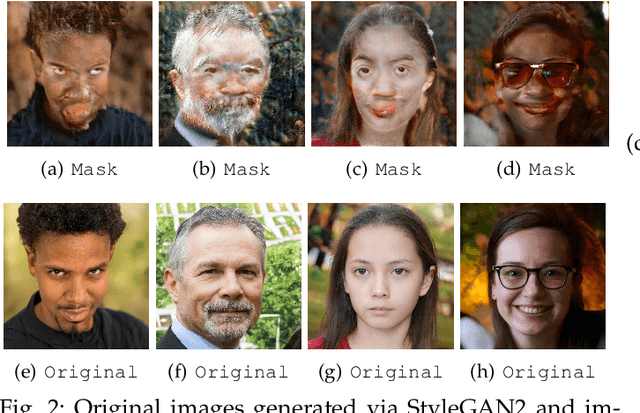
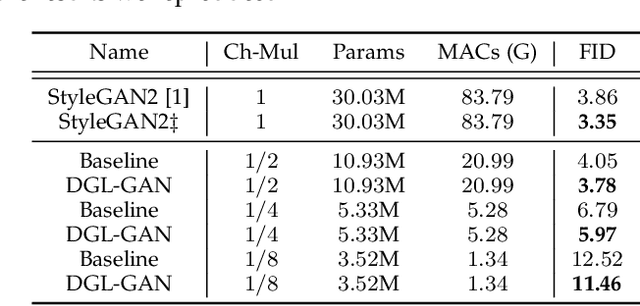
Generative Adversarial Networks (GANs) with high computation costs, e.g., BigGAN and StyleGAN2, have achieved remarkable results in synthesizing high resolution and diverse images with high fidelity from random noises. Reducing the computation cost of GANs while keeping generating photo-realistic images is an urgent and challenging field for their broad applications on computational resource-limited devices. In this work, we propose a novel yet simple {\bf D}iscriminator {\bf G}uided {\bf L}earning approach for compressing vanilla {\bf GAN}, dubbed {\bf DGL-GAN}. Motivated by the phenomenon that the teacher discriminator may contain some meaningful information, we transfer the knowledge merely from the teacher discriminator via the adversarial function. We show DGL-GAN is valid since empirically, learning from the teacher discriminator could facilitate the performance of student GANs, verified by extensive experimental findings. Furthermore, we propose a two-stage training strategy for training DGL-GAN, which can largely stabilize its training process and achieve superior performance when we apply DGL-GAN to compress the two most representative large-scale vanilla GANs, i.e., StyleGAN2 and BigGAN. Experiments show that DGL-GAN achieves state-of-the-art (SOTA) results on both StyleGAN2 (FID 2.92 on FFHQ with nearly $1/3$ parameters of StyleGAN2) and BigGAN (IS 93.29 and FID 9.92 on ImageNet with nearly $1/4$ parameters of BigGAN) and also outperforms several existing vanilla GAN compression techniques. Moreover, DGL-GAN is also effective in boosting the performance of original uncompressed GANs, original uncompressed StyleGAN2 boosted with DGL-GAN achieves FID 2.65 on FFHQ, which achieves a new state-of-the-art performance. Code and models are available at \url{https://github.com/yuesongtian/DGL-GAN}.
AutoPhaseNN: Unsupervised Physics-aware Deep Learning of 3D Nanoscale Coherent Imaging
Sep 28, 2021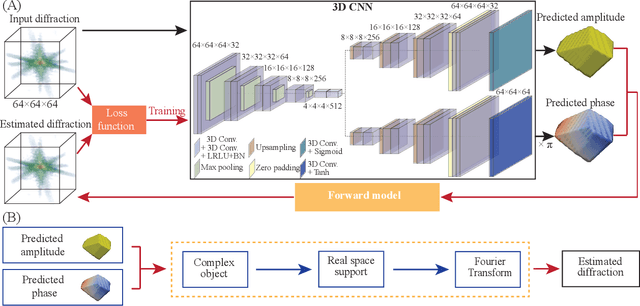
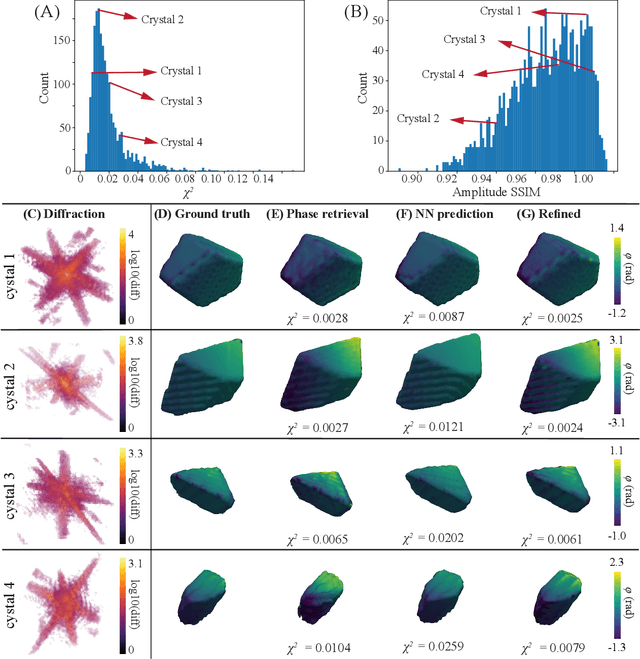
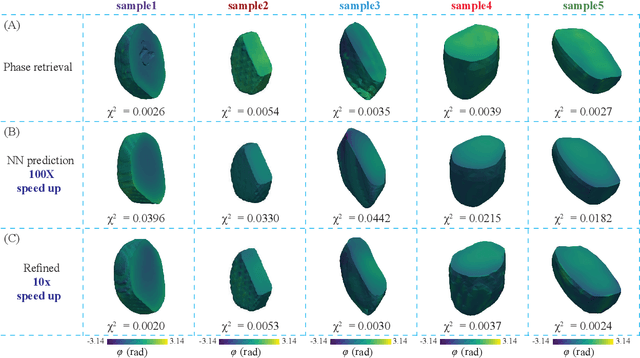
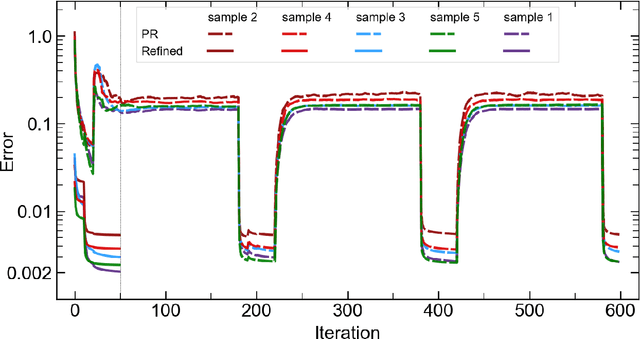
The problem of phase retrieval, or the algorithmic recovery of lost phase information from measured intensity alone, underlies various imaging methods from astronomy to nanoscale imaging. Traditional methods of phase retrieval are iterative in nature, and are therefore computationally expensive and time consuming. More recently, deep learning (DL) models have been developed to either provide learned priors to iterative phase retrieval or in some cases completely replace phase retrieval with networks that learn to recover the lost phase information from measured intensity alone. However, such models require vast amounts of labeled data, which can only be obtained through simulation or performing computationally prohibitive phase retrieval on hundreds of or even thousands of experimental datasets. Using a 3D nanoscale X-ray imaging modality (Bragg Coherent Diffraction Imaging or BCDI) as a representative technique, we demonstrate AutoPhaseNN, a DL-based approach which learns to solve the phase problem without labeled data. By incorporating the physics of the imaging technique into the DL model during training, AutoPhaseNN learns to invert 3D BCDI data from reciprocal space to real space in a single shot without ever being shown real space images. Once trained, AutoPhaseNN is about one hundred times faster than traditional iterative phase retrieval methods while providing comparable image quality.
Explaining a black-box using Deep Variational Information Bottleneck Approach
Feb 19, 2019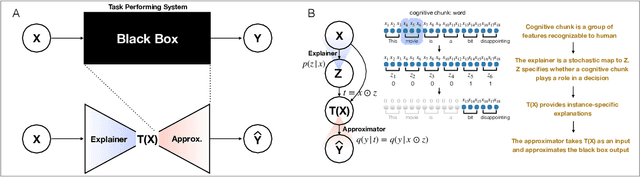
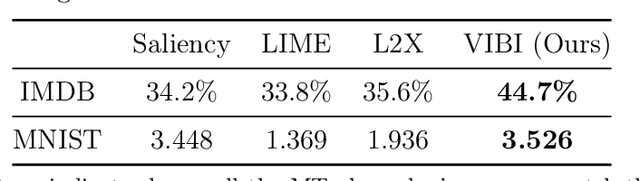

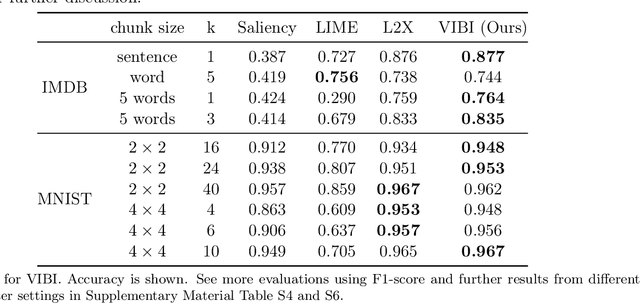
Briefness and comprehensiveness are necessary in order to give a lot of information concisely in explaining a black-box decision system. However, existing interpretable machine learning methods fail to consider briefness and comprehensiveness simultaneously, which may lead to redundant explanations. We propose a system-agnostic interpretable method that provides a brief but comprehensive explanation by adopting the inspiring information theoretic principle, information bottleneck principle. Using an information theoretic objective, VIBI selects instance-wise key features that are maximally compressed about an input (briefness), and informative about a decision made by a black-box on that input (comprehensive). The selected key features act as an information bottleneck that serves as a concise explanation for each black-box decision. We show that VIBI outperforms other interpretable machine learning methods in terms of both interpretability and fidelity evaluated by human and quantitative metrics.
Accessible Visualization via Natural Language Descriptions: A Four-Level Model of Semantic Content
Oct 08, 2021
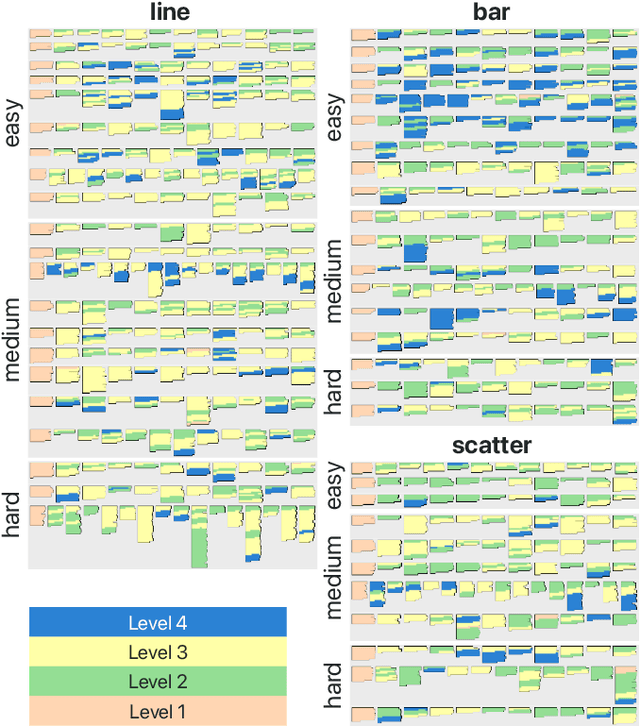
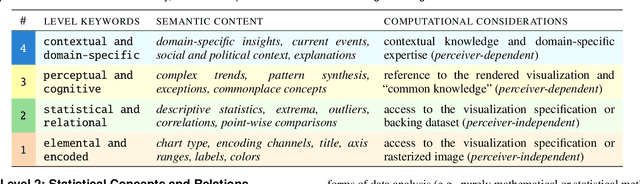
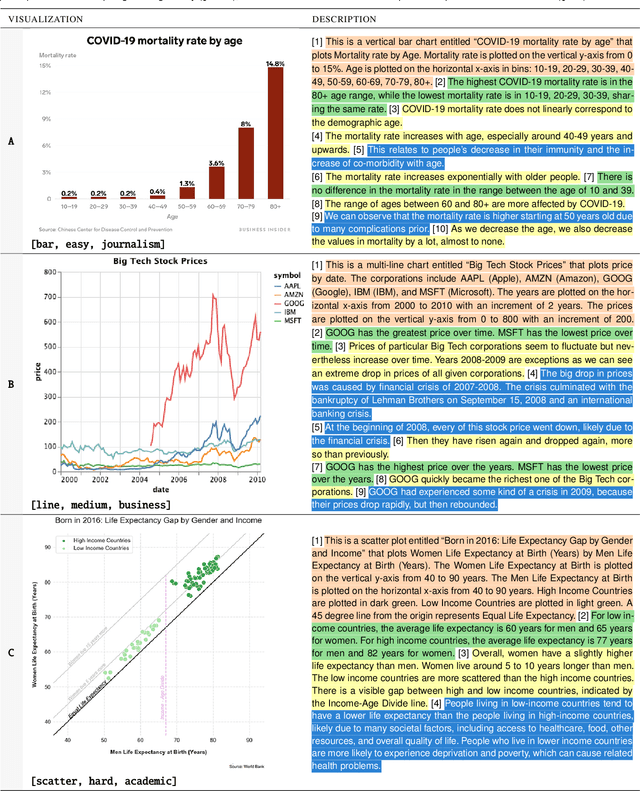
Natural language descriptions sometimes accompany visualizations to better communicate and contextualize their insights, and to improve their accessibility for readers with disabilities. However, it is difficult to evaluate the usefulness of these descriptions, and how effectively they improve access to meaningful information, because we have little understanding of the semantic content they convey, and how different readers receive this content. In response, we introduce a conceptual model for the semantic content conveyed by natural language descriptions of visualizations. Developed through a grounded theory analysis of 2,147 sentences, our model spans four levels of semantic content: enumerating visualization construction properties (e.g., marks and encodings); reporting statistical concepts and relations (e.g., extrema and correlations); identifying perceptual and cognitive phenomena (e.g., complex trends and patterns); and elucidating domain-specific insights (e.g., social and political context). To demonstrate how our model can be applied to evaluate the effectiveness of visualization descriptions, we conduct a mixed-methods evaluation with 30 blind and 90 sighted readers, and find that these reader groups differ significantly on which semantic content they rank as most useful. Together, our model and findings suggest that access to meaningful information is strongly reader-specific, and that research in automatic visualization captioning should orient toward descriptions that more richly communicate overall trends and statistics, sensitive to reader preferences. Our work further opens a space of research on natural language as a data interface coequal with visualization.
* An accessible HTML version of the article is available at: http://vis.csail.mit.edu/pubs/vis-text-model/
Graph Neural Networks in Real-Time Fraud Detection with Lambda Architecture
Oct 09, 2021
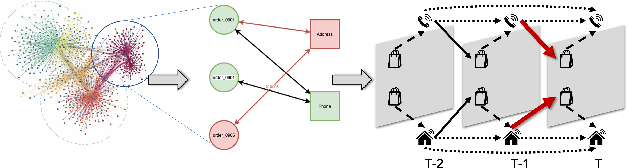

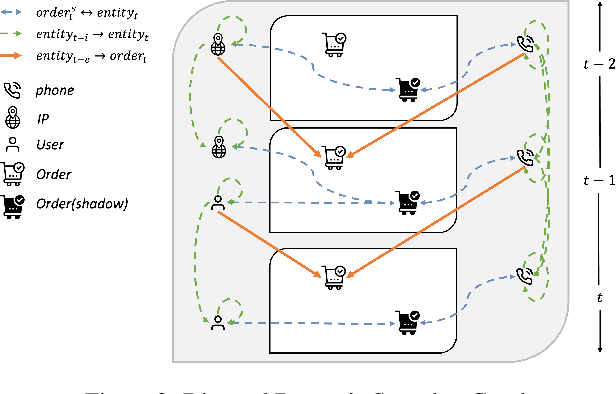
Transaction checkout fraud detection is an essential risk control components for E-commerce marketplaces. In order to leverage graph networks to decrease fraud rate efficiently and guarantee the information flow passed through neighbors only from the past of the checkouts, we first present a novel Directed Dynamic Snapshot (DDS) linkage design for graph construction and a Lambda Neural Networks (LNN) architecture for effective inference with Graph Neural Networks embeddings. Experiments show that our LNN on DDS graph, outperforms baseline models significantly and is computational efficient for real-time fraud detection.
Building Information Modeling and Classification by Visual Learning At A City Scale
Oct 14, 2019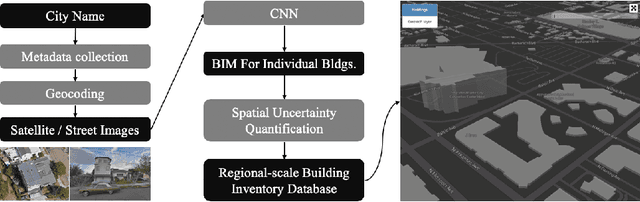
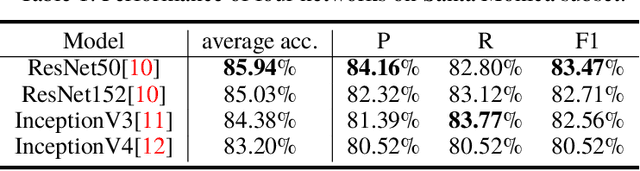

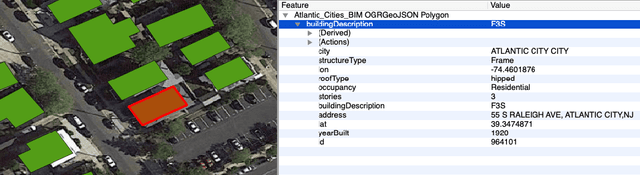
In this paper, we provide two case studies to demonstrate how artificial intelligence can empower civil engineering. In the first case, a machine learning-assisted framework, BRAILS, is proposed for city-scale building information modeling. Building information modeling (BIM) is an efficient way of describing buildings, which is essential to architecture, engineering, and construction. Our proposed framework employs deep learning technique to extract visual information of buildings from satellite/street view images. Further, a novel machine learning (ML)-based statistical tool, SURF, is proposed to discover the spatial patterns in building metadata. The second case focuses on the task of soft-story building classification. Soft-story buildings are a type of buildings prone to collapse during a moderate or severe earthquake. Hence, identifying and retrofitting such buildings is vital in the current earthquake preparedness efforts. For this task, we propose an automated deep learning-based procedure for identifying soft-story buildings from street view images at a regional scale. We also create a large-scale building image database and a semi-automated image labeling approach that effectively annotates new database entries. Through extensive computational experiments, we demonstrate the effectiveness of the proposed method.
Improving Domain Adaptation Translation with Domain Invariant and Specific Information
Apr 08, 2019
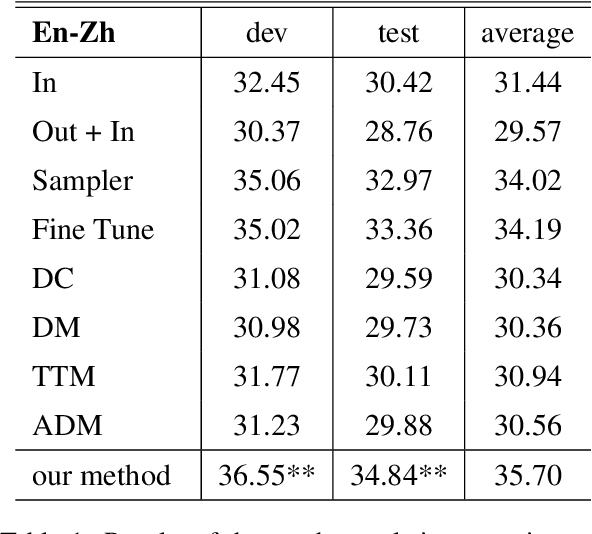
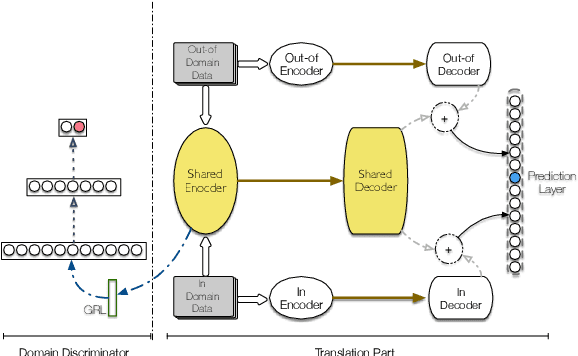
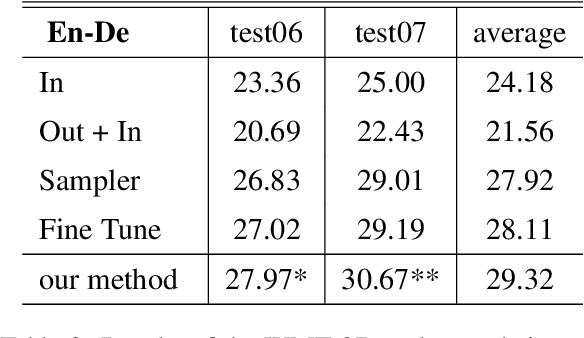
In domain adaptation for neural machine translation, translation performance can benefit from separating features into domain-specific features and common features. In this paper, we propose a method to explicitly model the two kinds of information in the encoder-decoder framework so as to exploit out-of-domain data in in-domain training. In our method, we maintain a private encoder and a private decoder for each domain which are used to model domain-specific information. In the meantime, we introduce a common encoder and a common decoder shared by all the domains which can only have domain-independent information flow through. Besides, we add a discriminator to the shared encoder and employ adversarial training for the whole model to reinforce the performance of information separation and machine translation simultaneously. Experiment results show that our method can outperform competitive baselines greatly on multiple data sets.