 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Navigate from Simulation via Spatial and Semantic Information Synthesis
Oct 30, 2019
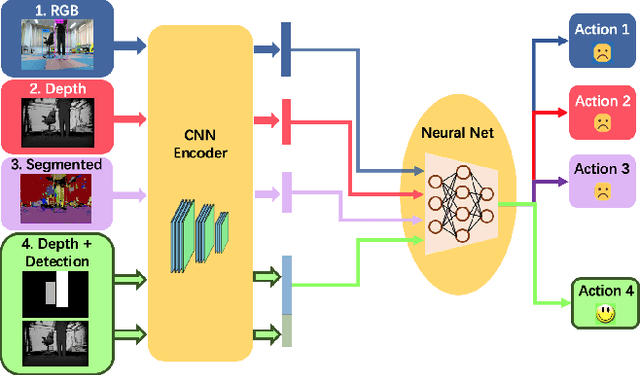
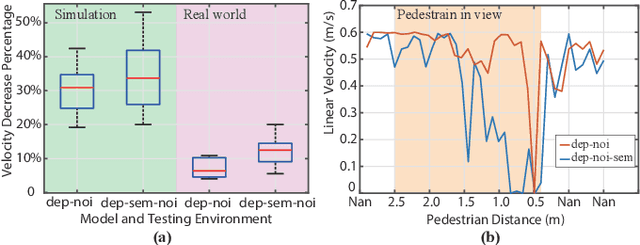

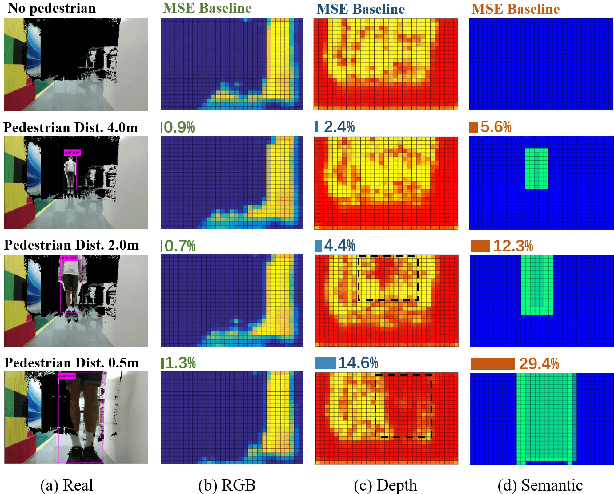
While training an end-to-end navigation network in the real world is usually of high cost, simulations provide a safe and cheap environment in this training stage. However, training neural network models in simulations brings up the problem of how to effectively transfer the model from simulations to the real world (sim-to-real). In this work, we regard the environment representation as a crucial element in this transfer process and propose a visual information pyramid (VIP) model to systematically investigate a practical environment representation. A novel representation composed of spatial and semantic information synthesis is then established accordingly. To explore the effectiveness of this representation, we compared the performance with representations popularly used in the literature in both simulated and real-world scenarios. Results suggest that our proposed environment representation behaves best. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.
Role of Human-AI Interaction in Selective Prediction
Dec 13, 2021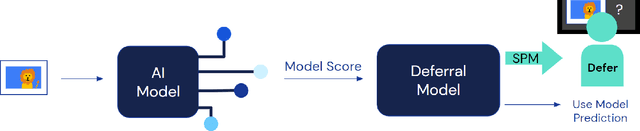
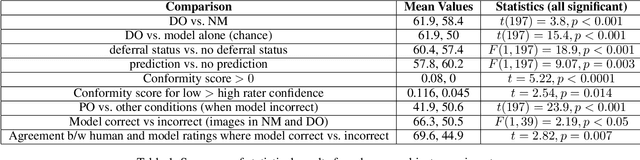

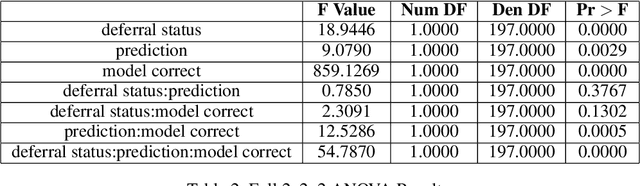
Recent work has shown the potential benefit of selective prediction systems that can learn to defer to a human when the predictions of the AI are unreliable, particularly to improve the reliability of AI systems in high-stakes applications like healthcare or conservation. However, most prior work assumes that human behavior remains unchanged when they solve a prediction task as part of a human-AI team as opposed to by themselves. We show that this is not the case by performing experiments to quantify human-AI interaction in the context of selective prediction. In particular, we study the impact of communicating different types of information to humans about the AI system's decision to defer. Using real-world conservation data and a selective prediction system that improves expected accuracy over that of the human or AI system working individually, we show that this messaging has a significant impact on the accuracy of human judgements. Our results study two components of the messaging strategy: 1) Whether humans are informed about the prediction of the AI system and 2) Whether they are informed about the decision of the selective prediction system to defer. By manipulating these messaging components, we show that it is possible to significantly boost human performance by informing the human of the decision to defer, but not revealing the prediction of the AI. We therefore show that it is vital to consider how the decision to defer is communicated to a human when designing selective prediction systems, and that the composite accuracy of a human-AI team must be carefully evaluated using a human-in-the-loop framework.
Waiting but not Aging: Age-of-Information and Utility Optimization Under the Pull Model
Dec 17, 2019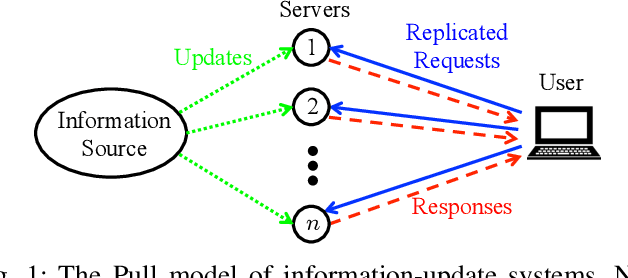
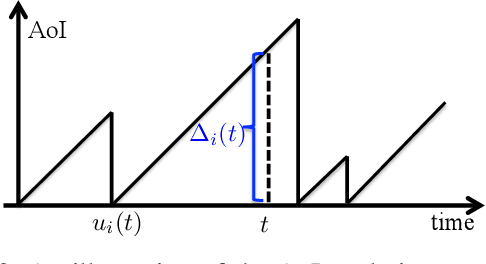
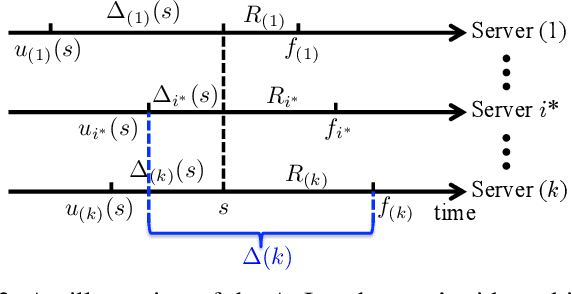
The Age-of-Information (AoI) has recently been proposed as an important metric for investigating the timeliness performance in information-update systems. In this paper, we introduce a new Pull model and study the AoI optimization problem under replication schemes. Interestingly, we find that under this new Pull model, replication schemes capture a novel tradeoff between different levels of information freshness and different response times across the servers, which can be exploited to minimize the expected AoI at the user's side. Specifically, assuming Poisson updating process for the servers and exponentially distributed response time, we derive a closed-form formula for computing the expected AoI and obtain the optimal number of responses to wait for to minimize the expected AoI. Then, we extend our analysis to the setting where the user aims to maximize the AoI-based utility, which represents the user's satisfaction level with respect to freshness of the received information. Furthermore, we consider a more realistic scenario where the user has no knowledge of the system. In this case, we reformulate the utility maximization problem as a stochastic Multi-Armed Bandit problem with side observations and leverage the unique structure of the problem to design learning algorithms with improved performance guarantees. Finally, we conduct extensive simulations to elucidate our theoretical results and compare the performance of different algorithms. Our findings reveal that under the Pull model, waiting for more than one response can significantly reduce the AoI and improve the AoI-based utility in most scenarios.
An Optimal Algorithm for Finding Champions in Tournament Graphs
Nov 26, 2021
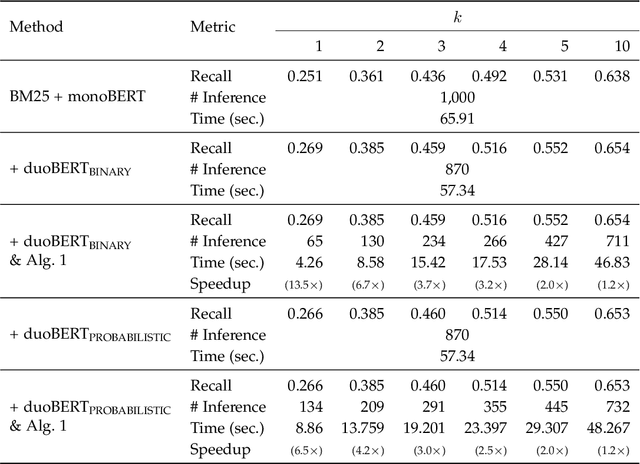

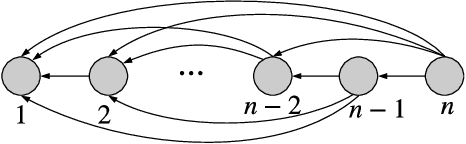
A tournament graph $T = \left(V, E \right)$ is an oriented complete graph, which can be used to model a round-robin tournament between $n$ players. In this paper, we address the problem of finding a champion of the tournament, also known as Copeland winner, which is a player that wins the highest number of matches. Solving this problem has important implications on several Information Retrieval applications, including Web search, conversational IR, machine translation, question answering, recommender systems, etc. Our goal is to solve the problem by minimizing the number of times we probe the adjacency matrix, i.e., the number of matches played. We prove that any deterministic/randomized algorithm finding a champion with constant success probability requires $\Omega(\ell n)$ comparisons, where $\ell$ is the number of matches lost by the champion. We then present an optimal deterministic algorithm matching this lower bound without knowing $\ell$ and we extend our analysis to three strictly related problems. Lastly, we conduct a comprehensive experimental assessment of the proposed algorithms to speed up a state-of-the-art solution for ranking on public data. Results show that our proposals speed up the retrieval of the champion up to $13\times$ in this scenario.
Acceleration based PSO for Multi-UAV Source-Seeking
Sep 23, 2021
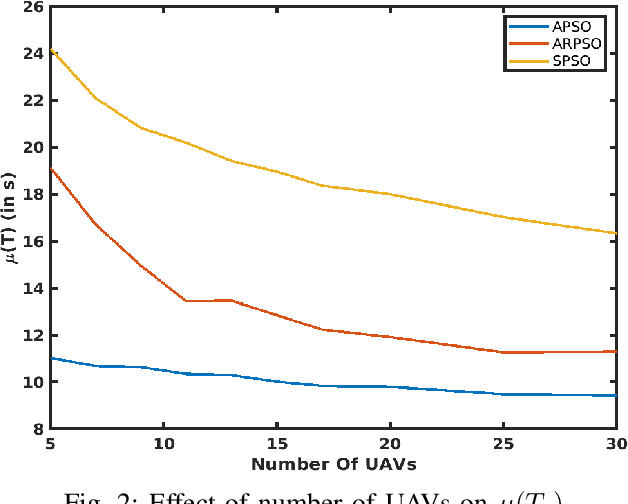
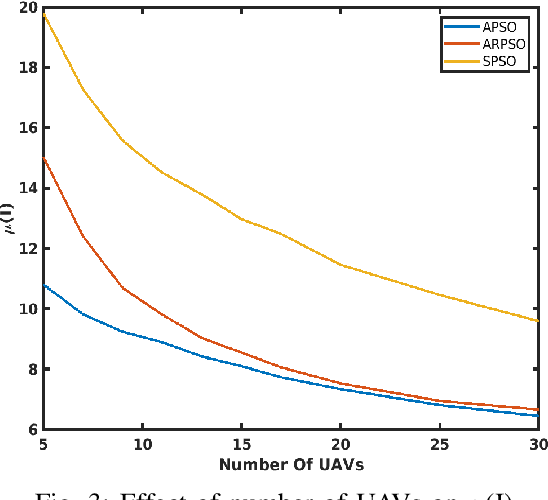
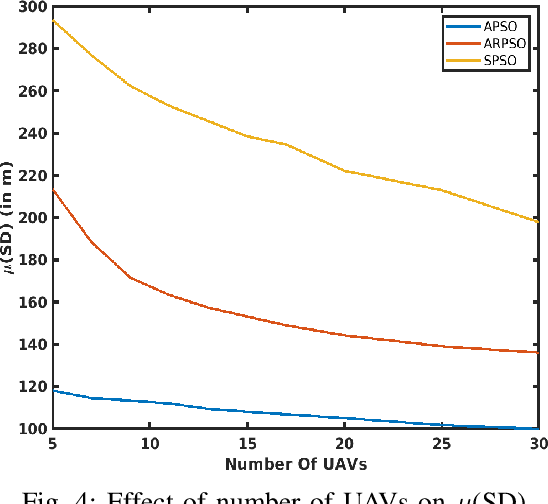
This paper presents a novel algorithm for a swarm of unmanned aerial vehicles (UAVs) to search for an unknown source. The proposed method is inspired by the well-known PSO algorithm and is called acceleration-based particle swarm optimization (APSO) to address the source-seeking problem with no a priori information. Unlike the conventional PSO algorithm, where the particle velocity is updated based on the self-cognition and social-cognition information, here the update is performed on the particle acceleration. A theoretical analysis is provided, showing the stability and convergence of the proposed APSO algorithm. Conditions on the parameters of the resulting third order update equations are obtained using Jurys stability test. High fidelity simulations performed in CoppeliaSim, shows the improved performance of the proposed APSO algorithm for searching an unknown source when compared with the state-of-the-art particle swarm-based source seeking algorithms. From the obtained results, it is observed that the proposed method performs better than the existing methods under scenarios like different inter-UAV communication network topologies, varying number of UAVs in the swarm, different sizes of search region, restricted source movement and in the presence of measurements noise.
Bi-directional Beamforming Feedback-based Firmware-agnostic WiFi Sensing
Dec 13, 2021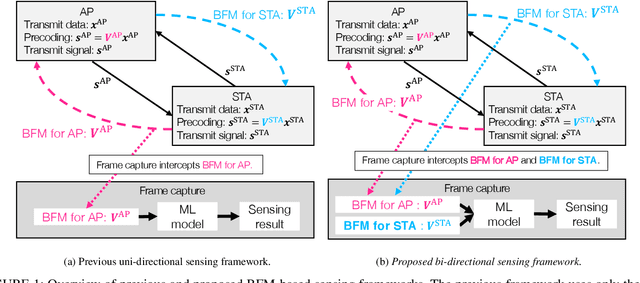

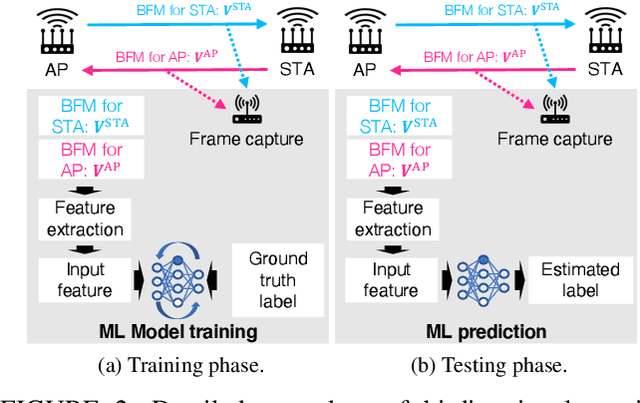
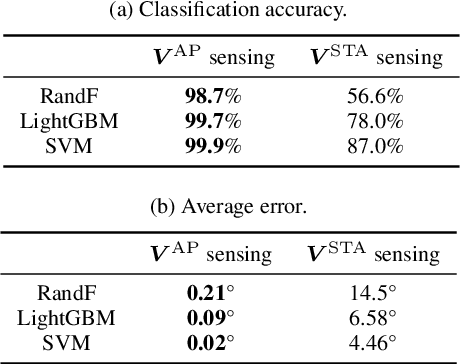
In the field of WiFi sensing, as an alternative sensing source of the channel state information (CSI) matrix, the use of a beamforming feedback matrix (BFM)that is a right singular matrix of the CSI matrix has attracted significant interest owing to its wide availability regarding the underlying WiFi systems. In the IEEE 802.11ac/ax standard, the station (STA) transmits a BFM to an access point (AP), which uses the BFM for precoded multiple-input and multiple-output communications. In addition, in the same way, the AP transmits a BFM to the STA, and the STA uses the received BFM. Regarding BFM-based sensing, extensive real-world experiments were conducted as part of this study, and two key insights were reported: Firstly, this report identified a potential issue related to accuracy in existing uni-directional BFM-based sensing frameworks that leverage only BFMs transmitted for the AP or STA. Such uni-directionality introduces accuracy concerns when there is a sensing capability gap between the uni-directional BFMs for the AP and STA. Thus, this report experimentally evaluates the sensing ability disparity between the uni-directional BFMs, and shows that the BFMs transmitted for an AP achieve higher sensing accuracy compared to the BFMs transmitted from the STA when the sensing target values are estimated depending on the angle of departure of the AP. Secondly, to complement the sensing gap, this paper proposes a bi-directional sensing framework, which simultaneously leverages the BFMs transmitted from the AP and STA. The experimental evaluations reveal that bi-directional sensing achieves higher accuracy than uni-directional sensing in terms of the human localization task.
Lightweight Image Super-Resolution with Information Multi-distillation Network
Sep 26, 2019
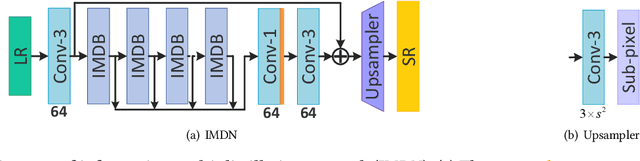
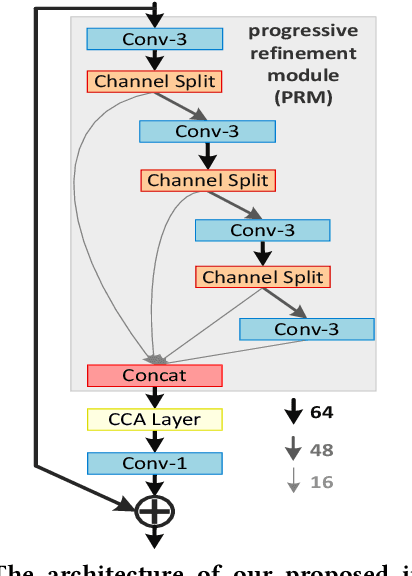

In recent years, single image super-resolution (SISR) methods using deep convolution neural network (CNN) have achieved impressive results. Thanks to the powerful representation capabilities of the deep networks, numerous previous ways can learn the complex non-linear mapping between low-resolution (LR) image patches and their high-resolution (HR) versions. However, excessive convolutions will limit the application of super-resolution technology in low computing power devices. Besides, super-resolution of any arbitrary scale factor is a critical issue in practical applications, which has not been well solved in the previous approaches. To address these issues, we propose a lightweight information multi-distillation network (IMDN) by constructing the cascaded information multi-distillation blocks (IMDB), which contains distillation and selective fusion parts. Specifically, the distillation module extracts hierarchical features step-by-step, and fusion module aggregates them according to the importance of candidate features, which is evaluated by the proposed contrast-aware channel attention mechanism. To process real images with any sizes, we develop an adaptive cropping strategy (ACS) to super-resolve block-wise image patches using the same well-trained model. Extensive experiments suggest that the proposed method performs favorably against the state-of-the-art SR algorithms in term of visual quality, memory footprint, and inference time. Code is available at \url{https://github.com/Zheng222/IMDN}.
Two-dimensional Deep Regression for Early Yield Prediction of Winter Wheat
Nov 15, 2021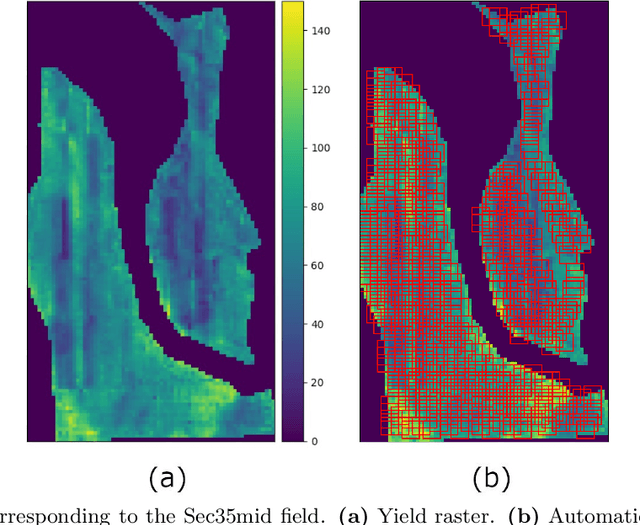
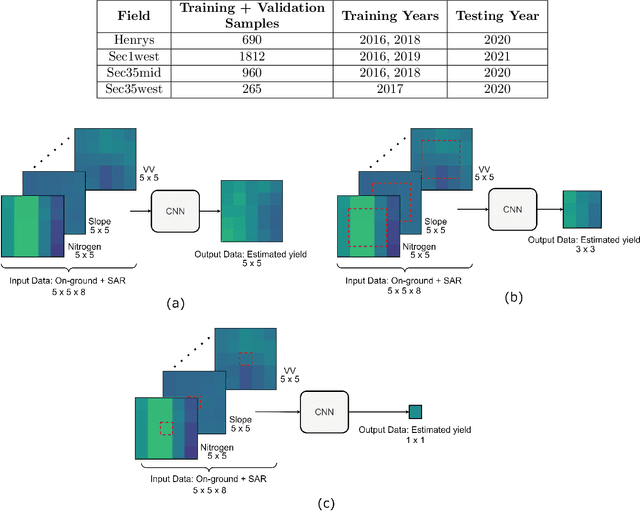
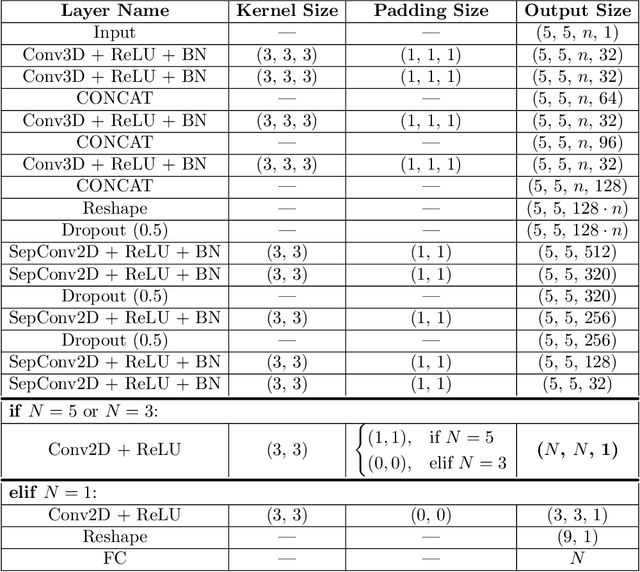
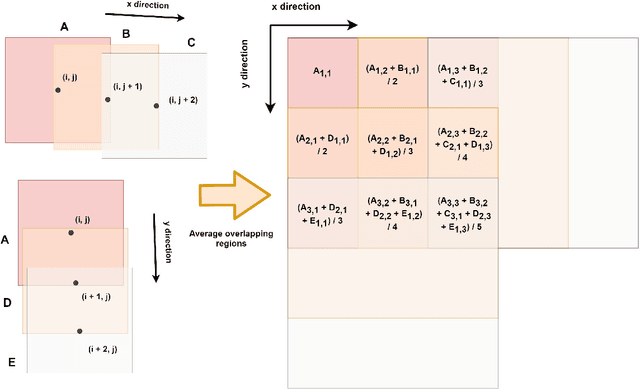
Crop yield prediction is one of the tasks of Precision Agriculture that can be automated based on multi-source periodic observations of the fields. We tackle the yield prediction problem using a Convolutional Neural Network (CNN) trained on data that combines radar satellite imagery and on-ground information. We present a CNN architecture called Hyper3DNetReg that takes in a multi-channel input image and outputs a two-dimensional raster, where each pixel represents the predicted yield value of the corresponding input pixel. We utilize radar data acquired from the Sentinel-1 satellites, while the on-ground data correspond to a set of six raster features: nitrogen rate applied, precipitation, slope, elevation, topographic position index (TPI), and aspect. We use data collected during the early stage of the winter wheat growing season (March) to predict yield values during the harvest season (August). We present experiments over four fields of winter wheat and show that our proposed methodology yields better results than five compared methods, including multiple linear regression, an ensemble of feedforward networks using AdaBoost, a stacked autoencoder, and two other CNN architectures.
Soliciting User Preferences in Conversational Recommender Systems via Usage-related Questions
Nov 26, 2021

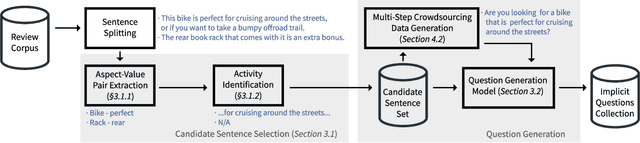
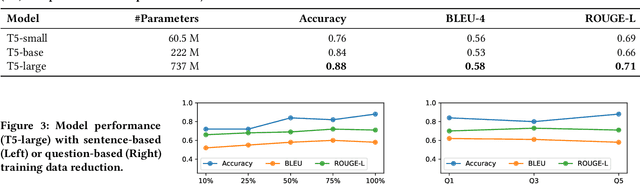
A key distinguishing feature of conversational recommender systems over traditional recommender systems is their ability to elicit user preferences using natural language. Currently, the predominant approach to preference elicitation is to ask questions directly about items or item attributes. These strategies do not perform well in cases where the user does not have sufficient knowledge of the target domain to answer such questions. Conversely, in a shopping setting, talking about the planned use of items does not present any difficulties, even for those that are new to a domain. In this paper, we propose a novel approach to preference elicitation by asking implicit questions based on item usage. Our approach consists of two main steps. First, we identify the sentences from a large review corpus that contain information about item usage. Then, we generate implicit preference elicitation questions from those sentences using a neural text-to-text model. The main contributions of this work also include a multi-stage data annotation protocol using crowdsourcing for collecting high-quality labeled training data for the neural model. We show that our approach is effective in selecting review sentences and transforming them to elicitation questions, even with limited training data. Additionally, we provide an analysis of patterns where the model does not perform optimally.
Deep Learning Approach Protecting Privacy in Camera-Based Critical Applications
Oct 04, 2021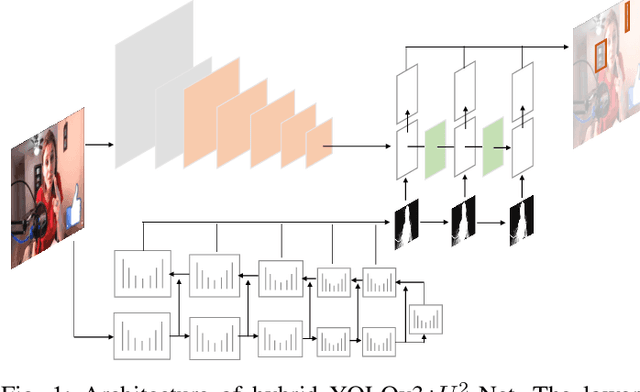

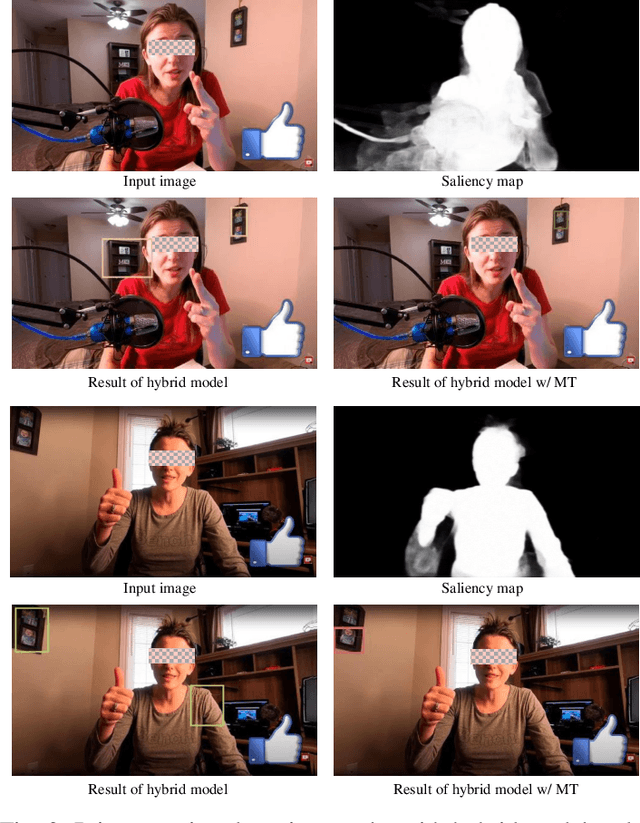

Many critical applications rely on cameras to capture video footage for analytical purposes. This has led to concerns about these cameras accidentally capturing more information than is necessary. In this paper, we propose a deep learning approach towards protecting privacy in camera-based systems. Instead of specifying specific objects (e.g. faces) are privacy sensitive, our technique distinguishes between salient (visually prominent) and non-salient objects based on the intuition that the latter is unlikely to be needed by the application.