 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Nonnegative Tucker Decomposition with Beta-divergence for Music Structure Analysis of audio signals
Oct 27, 2021
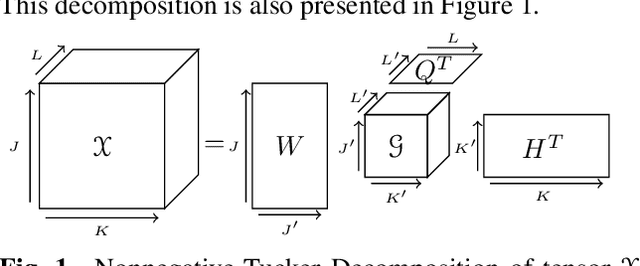
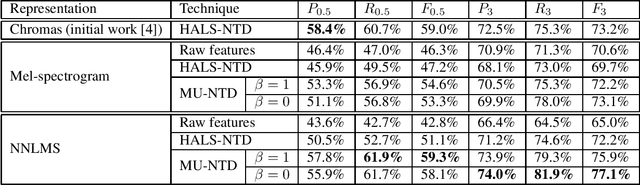

Nonnegative Tucker Decomposition (NTD), a tensor decomposition model, has received increased interest in the recent years because of its ability to blindly extract meaningful patterns in tensor data. Nevertheless, existing algorithms to compute NTD are mostly designed for the Euclidean loss. On the other hand, NTD has recently proven to be a powerful tool in Music Information Retrieval. This work proposes a Multiplicative Updates algorithm to compute NTD with the beta-divergence loss, often considered a better loss for audio processing. We notably show how to implement efficiently the multiplicative rules using tensor algebra, a naive approach being intractable. Finally, we show on a Music Structure Analysis task that unsupervised NTD fitted with beta-divergence loss outperforms earlier results obtained with the Euclidean loss.
Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation
Dec 17, 2021
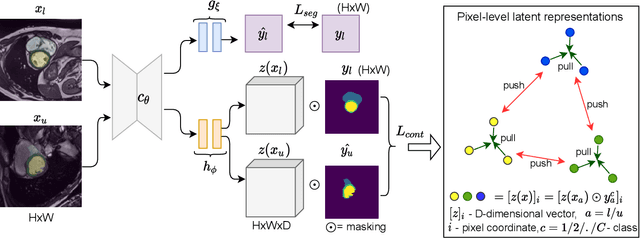
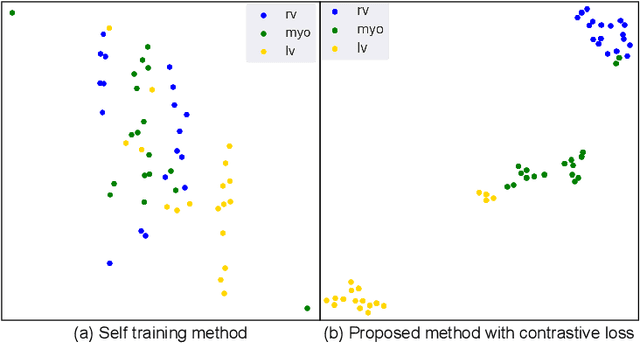
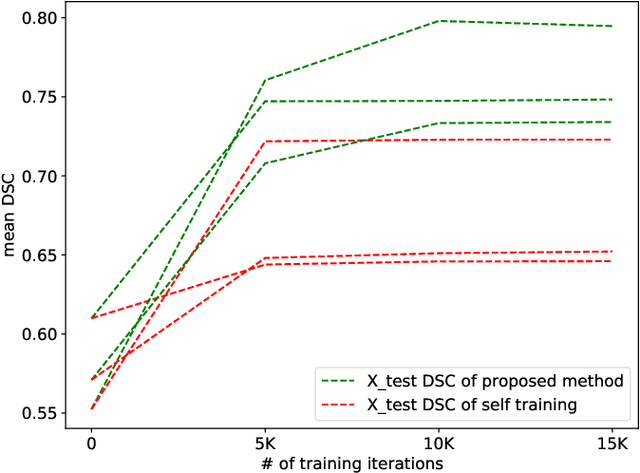
Supervised deep learning-based methods yield accurate results for medical image segmentation. However, they require large labeled datasets for this, and obtaining them is a laborious task that requires clinical expertise. Semi/self-supervised learning-based approaches address this limitation by exploiting unlabeled data along with limited annotated data. Recent self-supervised learning methods use contrastive loss to learn good global level representations from unlabeled images and achieve high performance in classification tasks on popular natural image datasets like ImageNet. In pixel-level prediction tasks such as segmentation, it is crucial to also learn good local level representations along with global representations to achieve better accuracy. However, the impact of the existing local contrastive loss-based methods remains limited for learning good local representations because similar and dissimilar local regions are defined based on random augmentations and spatial proximity; not based on the semantic label of local regions due to lack of large-scale expert annotations in the semi/self-supervised setting. In this paper, we propose a local contrastive loss to learn good pixel level features useful for segmentation by exploiting semantic label information obtained from pseudo-labels of unlabeled images alongside limited annotated images. In particular, we define the proposed loss to encourage similar representations for the pixels that have the same pseudo-label/ label while being dissimilar to the representation of pixels with different pseudo-label/label in the dataset. We perform pseudo-label based self-training and train the network by jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets and segmentation loss on only the limited labeled set. We evaluated on three public cardiac and prostate datasets, and obtain high segmentation performance.
Augmenting Part-of-speech Tagging with Syntactic Information for Vietnamese and Chinese
Feb 24, 2021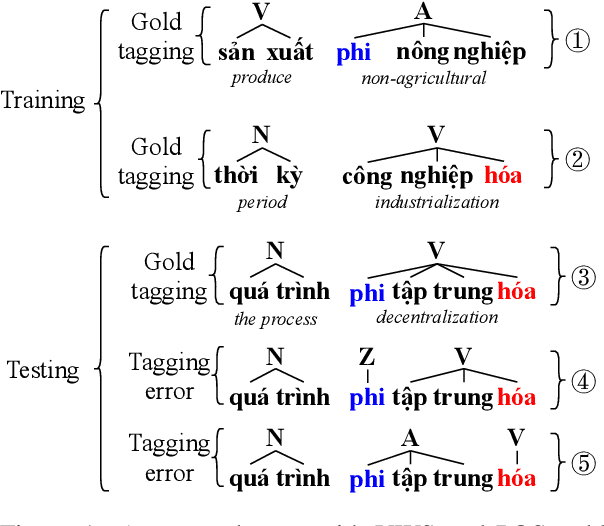
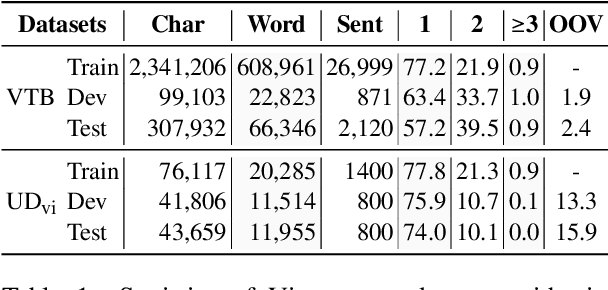
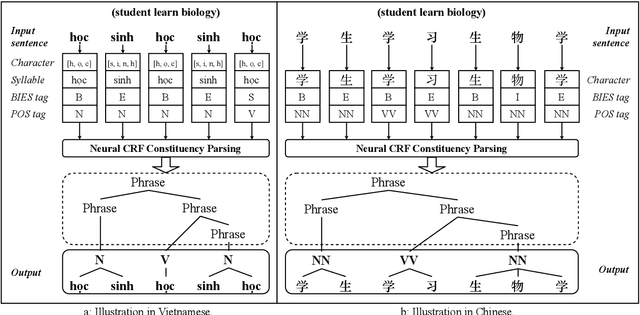
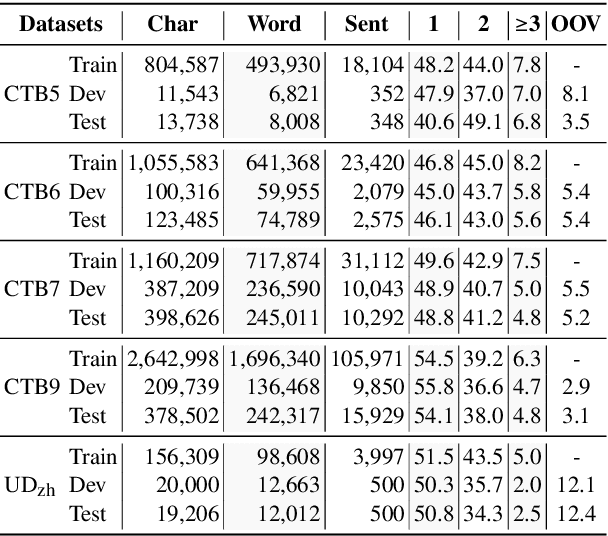
Word segmentation and part-of-speech tagging are two critical preliminary steps for downstream tasks in Vietnamese natural language processing. In reality, people tend to consider also the phrase boundary when performing word segmentation and part of speech tagging rather than solely process word by word from left to right. In this paper, we implement this idea to improve word segmentation and part of speech tagging the Vietnamese language by employing a simplified constituency parser. Our neural model for joint word segmentation and part-of-speech tagging has the architecture of the syllable-based CRF constituency parser. To reduce the complexity of parsing, we replace all constituent labels with a single label indicating for phrases. This model can be augmented with predicted word boundary and part-of-speech tags by other tools. Because Vietnamese and Chinese have some similar linguistic phenomena, we evaluated the proposed model and its augmented versions on three Vietnamese benchmark datasets and six Chinese benchmark datasets. Our experimental results show that the proposed model achieves higher performances than previous works for both languages.
Understanding the Effectiveness of Reviews in E-commerce Top-N Recommendation
Jun 17, 2021
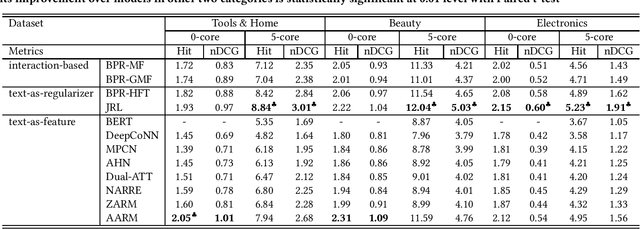
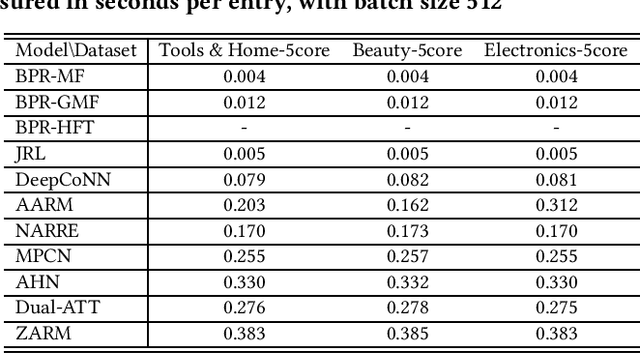
Modern E-commerce websites contain heterogeneous sources of information, such as numerical ratings, textual reviews and images. These information can be utilized to assist recommendation. Through textual reviews, a user explicitly express her affinity towards the item. Previous researchers found that by using the information extracted from these reviews, we can better profile the users' explicit preferences as well as the item features, leading to the improvement of recommendation performance. However, most of the previous algorithms were only utilizing the review information for explicit-feedback problem i.e. rating prediction, and when it comes to implicit-feedback ranking problem such as top-N recommendation, the usage of review information has not been fully explored. Seeing this gap, in this work, we investigate the effectiveness of textual review information for top-N recommendation under E-commerce settings. We adapt several SOTA review-based rating prediction models for top-N recommendation tasks and compare them to existing top-N recommendation models from both performance and efficiency. We find that models utilizing only review information can not achieve better performances than vanilla implicit-feedback matrix factorization method. When utilizing review information as a regularizer or auxiliary information, the performance of implicit-feedback matrix factorization method can be further improved. However, the optimal model structure to utilize textual reviews for E-commerce top-N recommendation is yet to be determined.
Roadmap on Signal Processing for Next Generation Measurement Systems
Nov 03, 2021
Signal processing is a fundamental component of almost any sensor-enabled system, with a wide range of applications across different scientific disciplines. Time series data, images, and video sequences comprise representative forms of signals that can be enhanced and analysed for information extraction and quantification. The recent advances in artificial intelligence and machine learning are shifting the research attention towards intelligent, data-driven, signal processing. This roadmap presents a critical overview of the state-of-the-art methods and applications aiming to highlight future challenges and research opportunities towards next generation measurement systems. It covers a broad spectrum of topics ranging from basic to industrial research, organized in concise thematic sections that reflect the trends and the impacts of current and future developments per research field. Furthermore, it offers guidance to researchers and funding agencies in identifying new prospects.
Hybrid Imitative Planning with Geometric and Predictive Costs in Off-road Environments
Nov 22, 2021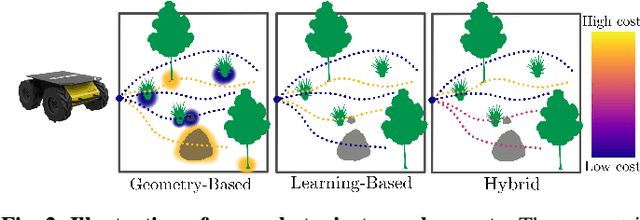
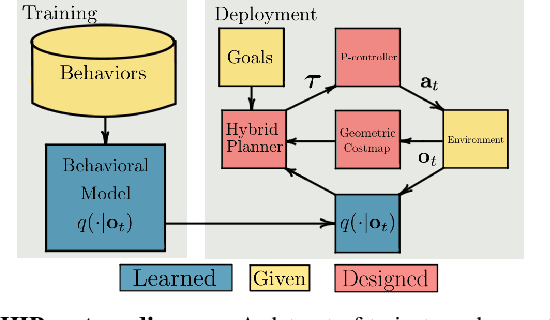
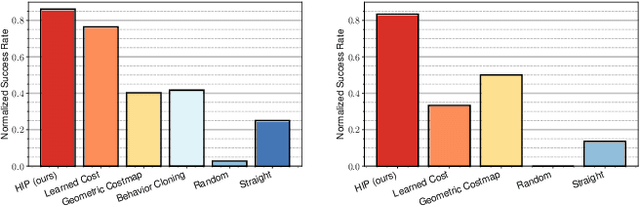

Geometric methods for solving open-world off-road navigation tasks, by learning occupancy and metric maps, provide good generalization but can be brittle in outdoor environments that violate their assumptions (e.g., tall grass). Learning-based methods can directly learn collision-free behavior from raw observations, but are difficult to integrate with standard geometry-based pipelines. This creates an unfortunate conflict -- either use learning and lose out on well-understood geometric navigational components, or do not use it, in favor of extensively hand-tuned geometry-based cost maps. In this work, we reject this dichotomy by designing the learning and non-learning-based components in a way such that they can be effectively combined in a self-supervised manner. Both components contribute to a planning criterion: the learned component contributes predicted traversability as rewards, while the geometric component contributes obstacle cost information. We instantiate and comparatively evaluate our system in both in-distribution and out-of-distribution environments, showing that this approach inherits complementary gains from the learned and geometric components and significantly outperforms either of them. Videos of our results are hosted at https://sites.google.com/view/hybrid-imitative-planning
Automatic ultrasound vessel segmentation with deep spatiotemporal context learning
Nov 03, 2021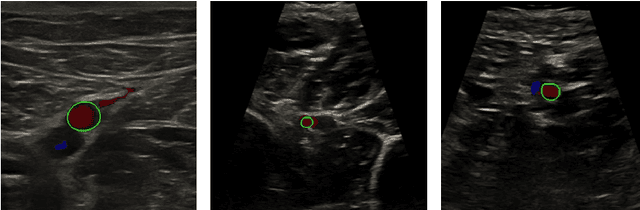
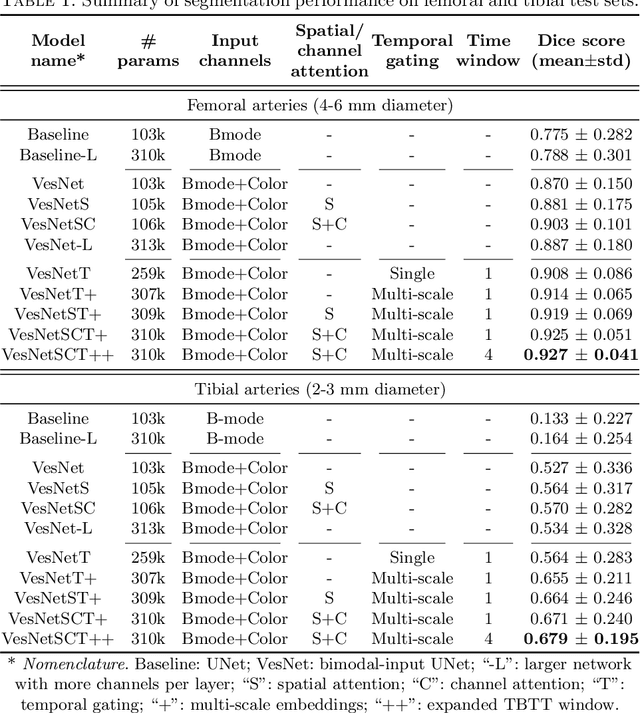
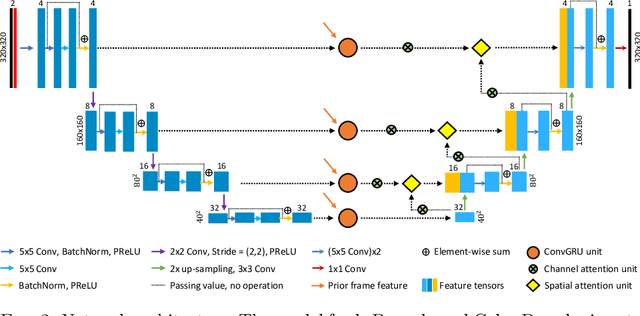
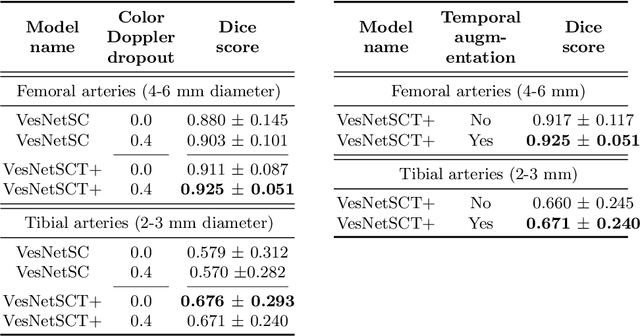
Accurate, real-time segmentation of vessel structures in ultrasound image sequences can aid in the measurement of lumen diameters and assessment of vascular diseases. This, however, remains a challenging task, particularly for extremely small vessels that are difficult to visualize. We propose to leverage the rich spatiotemporal context available in ultrasound to improve segmentation of small-scale lower-extremity arterial vasculature. We describe efficient deep learning methods that incorporate temporal, spatial, and feature-aware contextual embeddings at multiple resolution scales while jointly utilizing information from B-mode and Color Doppler signals. Evaluating on femoral and tibial artery scans performed on healthy subjects by an expert ultrasonographer, and comparing to consensus expert ground-truth annotations of inner lumen boundaries, we demonstrate real-time segmentation using the context-aware models and show that they significantly outperform comparable baseline approaches.
Inferring User Facial Affect in Work-like Settings
Nov 22, 2021
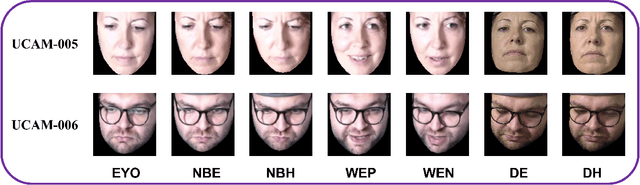

Unlike the six basic emotions of happiness, sadness, fear, anger, disgust and surprise, modelling and predicting dimensional affect in terms of valence (positivity - negativity) and arousal (intensity) has proven to be more flexible, applicable and useful for naturalistic and real-world settings. In this paper, we aim to infer user facial affect when the user is engaged in multiple work-like tasks under varying difficulty levels (baseline, easy, hard and stressful conditions), including (i) an office-like setting where they undertake a task that is less physically demanding but requires greater mental strain; (ii) an assembly-line-like setting that requires the usage of fine motor skills; and (iii) an office-like setting representing teleworking and teleconferencing. In line with this aim, we first design a study with different conditions and gather multimodal data from 12 subjects. We then perform several experiments with various machine learning models and find that: (i) the display and prediction of facial affect vary from non-working to working settings; (ii) prediction capability can be boosted by using datasets captured in a work-like context; and (iii) segment-level (spectral representation) information is crucial in improving the facial affect prediction.
Learning to Navigate from Simulation via Spatial and Semantic Information Synthesis
Oct 30, 2019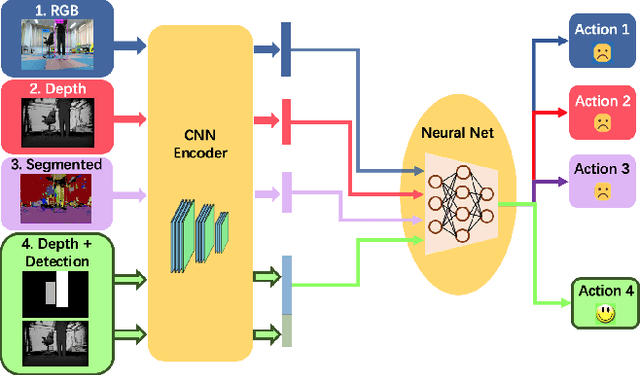
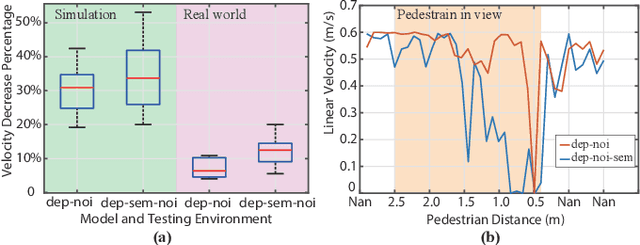

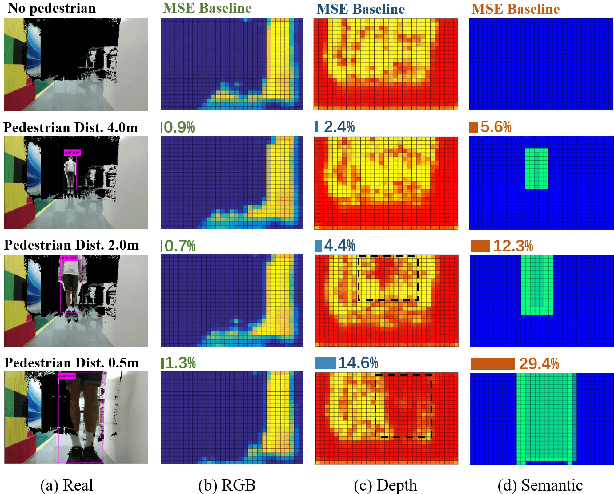
While training an end-to-end navigation network in the real world is usually of high cost, simulations provide a safe and cheap environment in this training stage. However, training neural network models in simulations brings up the problem of how to effectively transfer the model from simulations to the real world (sim-to-real). In this work, we regard the environment representation as a crucial element in this transfer process and propose a visual information pyramid (VIP) model to systematically investigate a practical environment representation. A novel representation composed of spatial and semantic information synthesis is then established accordingly. To explore the effectiveness of this representation, we compared the performance with representations popularly used in the literature in both simulated and real-world scenarios. Results suggest that our proposed environment representation behaves best. Furthermore, an analysis on the feature map is implemented to investigate the effectiveness through inner reaction, which could be irradiative for future researches on end-to-end navigation.
Multi-frequency image completion via a biologically-inspired sub-Riemannian model with frequency and phase
Oct 27, 2021
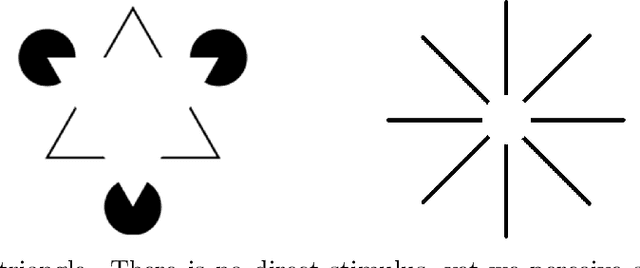
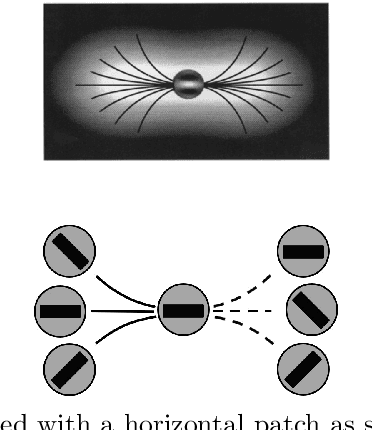

We present a novel cortically-inspired image completion algorithm. It uses a five dimensional sub-Riemannian cortical geometry modelling the orientation, spatial frequency and phase selective behavior of the cells in the visual cortex. The algorithm extracts the orientation, frequency and phase information existing in a given two dimensional corrupted input image via a Gabor transform and represent those values in terms of cortical cell output responses in the model geometry. Then it performs completion via a diffusion concentrated in a neighbourhood along the neural connections within the model geometry. The diffusion models the activity propagation integrating orientation, frequency and phase features along the neural connections. Finally, the algorithm transforms back the diffused and completed output responses back to the two dimensional image plane.