 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local contrastive loss with pseudo-label based self-training for semi-supervised medical image segmentation
Dec 17, 2021

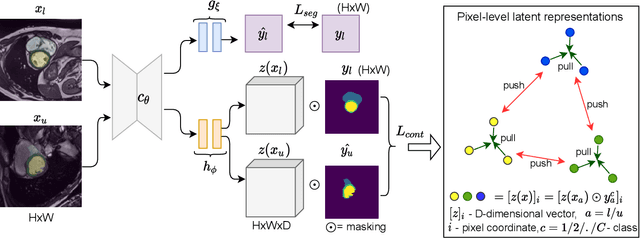
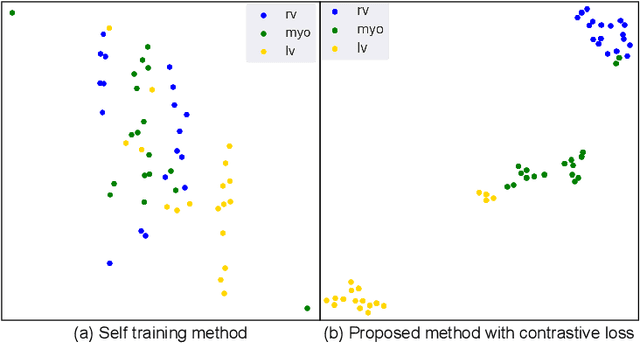
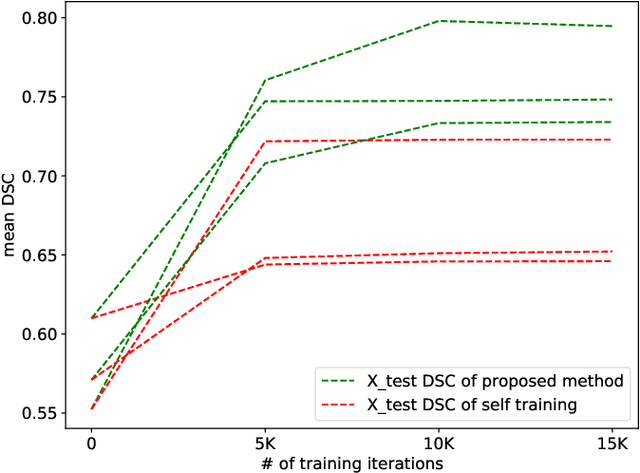
Supervised deep learning-based methods yield accurate results for medical image segmentation. However, they require large labeled datasets for this, and obtaining them is a laborious task that requires clinical expertise. Semi/self-supervised learning-based approaches address this limitation by exploiting unlabeled data along with limited annotated data. Recent self-supervised learning methods use contrastive loss to learn good global level representations from unlabeled images and achieve high performance in classification tasks on popular natural image datasets like ImageNet. In pixel-level prediction tasks such as segmentation, it is crucial to also learn good local level representations along with global representations to achieve better accuracy. However, the impact of the existing local contrastive loss-based methods remains limited for learning good local representations because similar and dissimilar local regions are defined based on random augmentations and spatial proximity; not based on the semantic label of local regions due to lack of large-scale expert annotations in the semi/self-supervised setting. In this paper, we propose a local contrastive loss to learn good pixel level features useful for segmentation by exploiting semantic label information obtained from pseudo-labels of unlabeled images alongside limited annotated images. In particular, we define the proposed loss to encourage similar representations for the pixels that have the same pseudo-label/ label while being dissimilar to the representation of pixels with different pseudo-label/label in the dataset. We perform pseudo-label based self-training and train the network by jointly optimizing the proposed contrastive loss on both labeled and unlabeled sets and segmentation loss on only the limited labeled set. We evaluated on three public cardiac and prostate datasets, and obtain high segmentation performance.
Unsupervised Learning to Subphenotype Delirium Patients from Electronic Health Records
Oct 31, 2021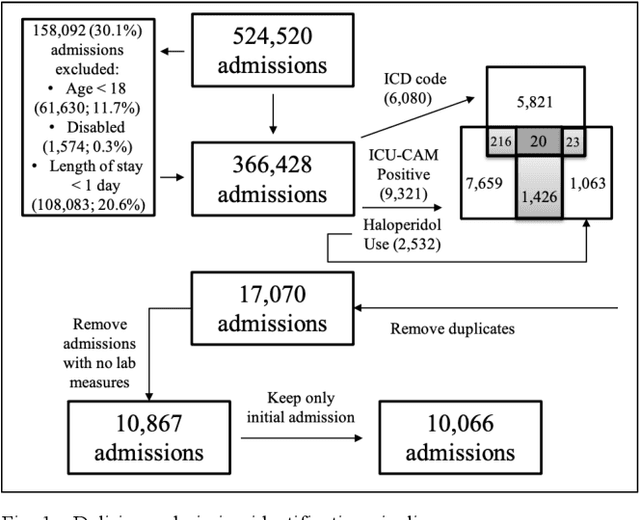
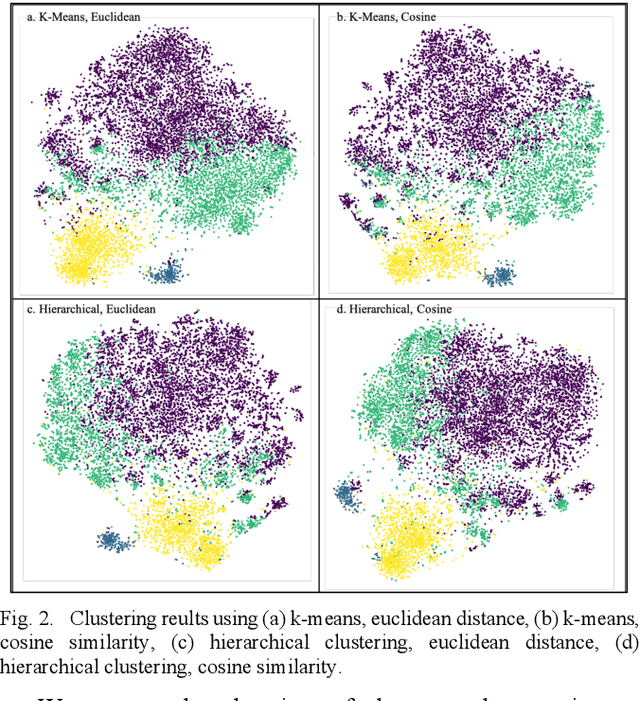
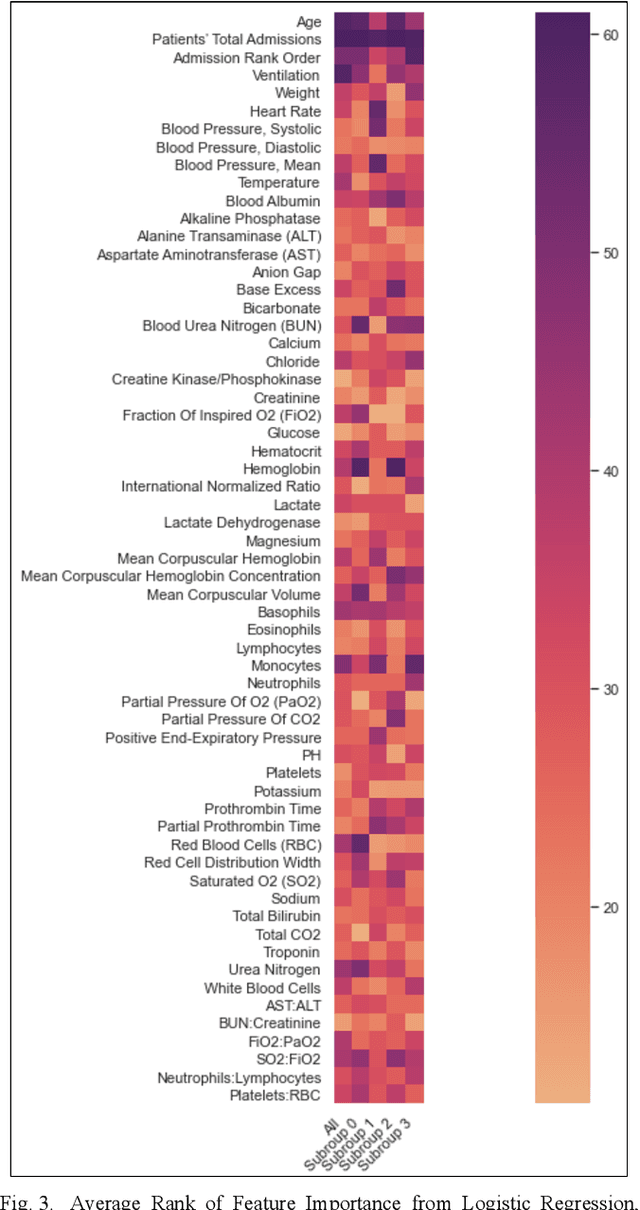
Delirium is a common acute onset brain dysfunction in the emergency setting and is associated with higher mortality. It is difficult to detect and monitor since its presentations and risk factors can be different depending on the underlying medical condition of patients. In our study, we aimed to identify subtypes within the delirium population and build subgroup-specific predictive models to detect delirium using Medical Information Mart for Intensive Care IV (MIMIC-IV) data. We showed that clusters exist within the delirium population. Differences in feature importance were also observed for subgroup-specific predictive models. Our work could recalibrate existing delirium prediction models for each delirium subgroup and improve the precision of delirium detection and monitoring for ICU or emergency department patients who had highly heterogeneous medical conditions.
Meta-Learning the Search Distribution of Black-Box Random Search Based Adversarial Attacks
Nov 22, 2021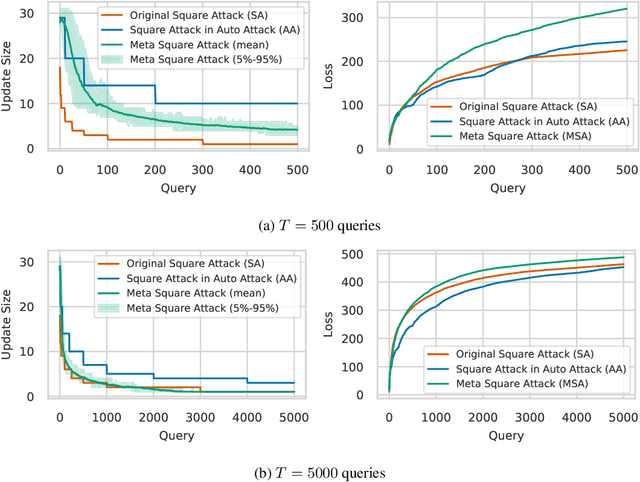
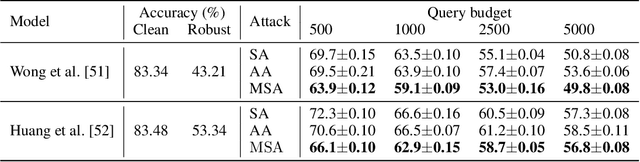

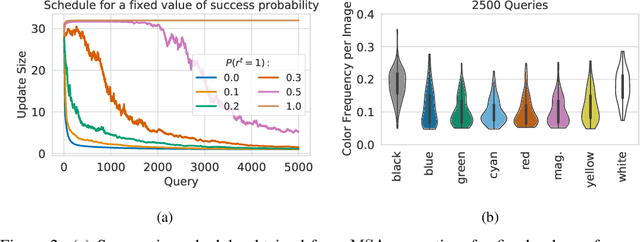
Adversarial attacks based on randomized search schemes have obtained state-of-the-art results in black-box robustness evaluation recently. However, as we demonstrate in this work, their efficiency in different query budget regimes depends on manual design and heuristic tuning of the underlying proposal distributions. We study how this issue can be addressed by adapting the proposal distribution online based on the information obtained during the attack. We consider Square Attack, which is a state-of-the-art score-based black-box attack, and demonstrate how its performance can be improved by a learned controller that adjusts the parameters of the proposal distribution online during the attack. We train the controller using gradient-based end-to-end training on a CIFAR10 model with white box access. We demonstrate that plugging the learned controller into the attack consistently improves its black-box robustness estimate in different query regimes by up to 20% for a wide range of different models with black-box access. We further show that the learned adaptation principle transfers well to the other data distributions such as CIFAR100 or ImageNet and to the targeted attack setting.
CEM: Commonsense-aware Empathetic Response Generation
Sep 13, 2021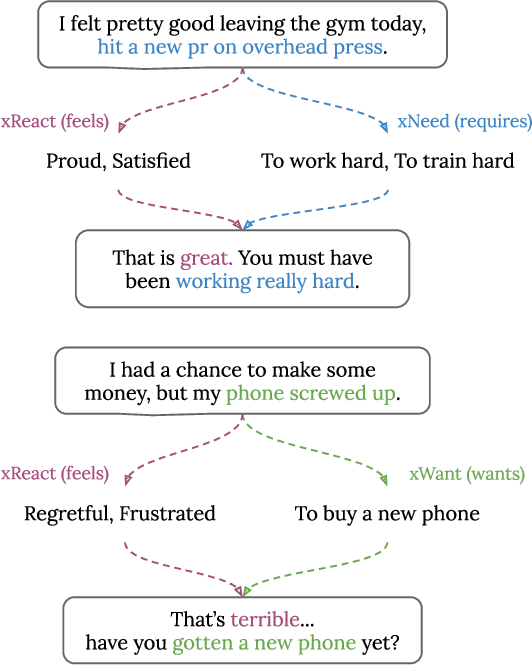

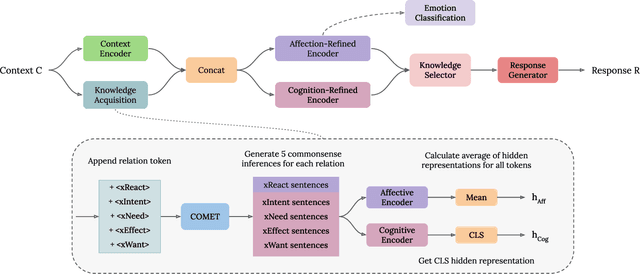
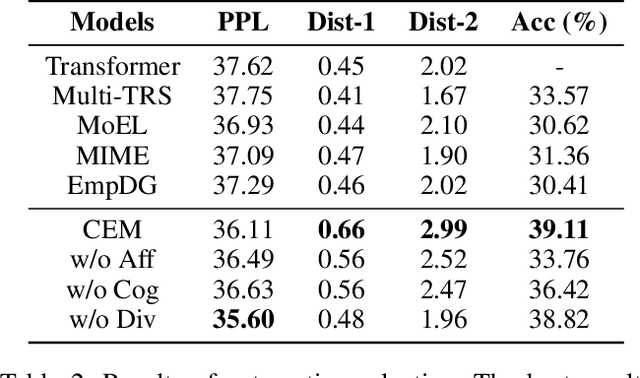
A key trait of daily conversations between individuals is the ability to express empathy towards others, and exploring ways to implement empathy is a crucial step towards human-like dialogue systems. Previous approaches on this topic mainly focus on detecting and utilizing the user's emotion for generating empathetic responses. However, since empathy includes both aspects of affection and cognition, we argue that in addition to identifying the user's emotion, cognitive understanding of the user's situation should also be considered. To this end, we propose a novel approach for empathetic response generation, which leverages commonsense to draw more information about the user's situation and uses this additional information to further enhance the empathy expression in generated responses. We evaluate our approach on EmpatheticDialogues, which is a widely-used benchmark dataset for empathetic response generation. Empirical results demonstrate that our approach outperforms the baseline models in both automatic and human evaluations and can generate more informative and empathetic responses.
Human Age Estimation from Gene Expression Data using Artificial Neural Networks
Nov 04, 2021
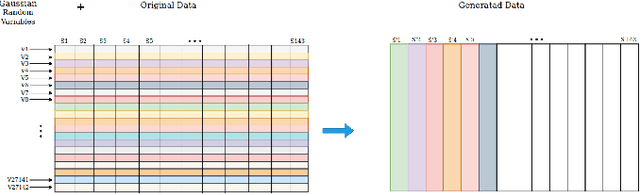
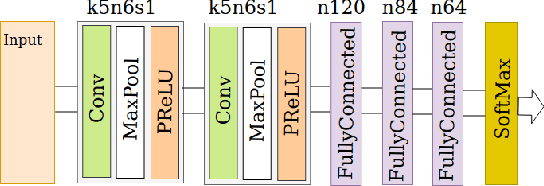
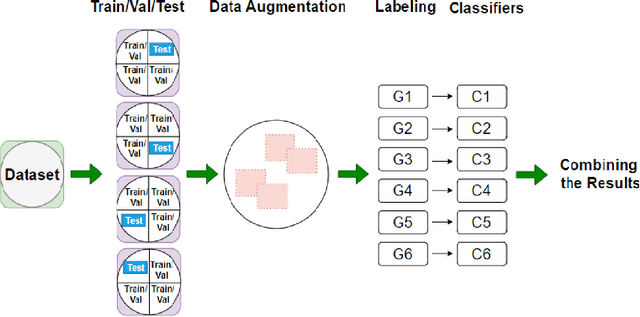
The study of signatures of aging in terms of genomic biomarkers can be uniquely helpful in understanding the mechanisms of aging and developing models to accurately predict the age. Prior studies have employed gene expression and DNA methylation data aiming at accurate prediction of age. In this line, we propose a new framework for human age estimation using information from human dermal fibroblast gene expression data. First, we propose a new spatial representation as well as a data augmentation approach for gene expression data. Next in order to predict the age, we design an architecture of neural network and apply it to this new representation of the original and augmented data, as an ensemble classification approach. Our experimental results suggest the superiority of the proposed framework over state-of-the-art age estimation methods using DNA methylation and gene expression data.
Ballistic Multibody Estimator for 2D Open Kinematic Chain
Nov 07, 2021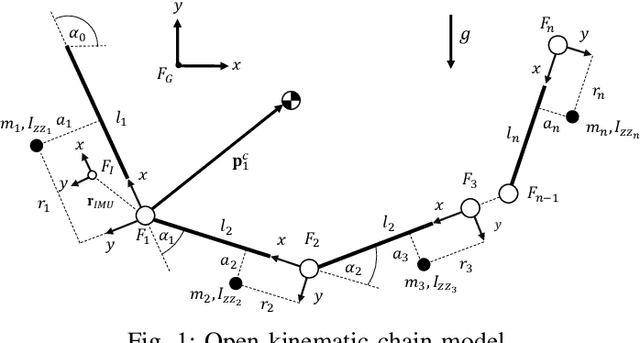
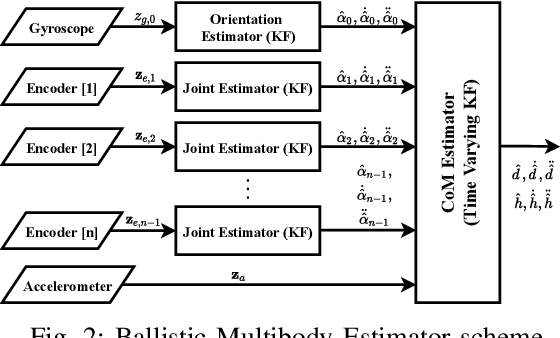
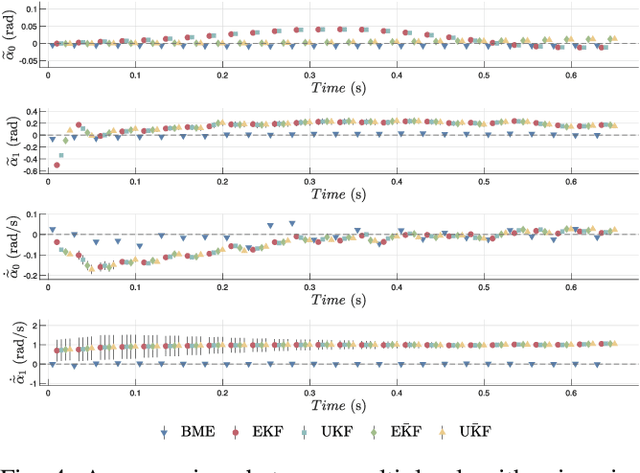
Applications of free-flying robots range from entertainment purposes to aerospace applications. The control algorithm for such systems requires accurate estimation of their states based on sensor feedback. The objective of this paper is to design and verify a lightweight state estimation algorithm for a free-flying open kinematic chain that estimates the state of its center-of-mass and its posture. Instead of utilizing a nonlinear dynamics model, this research proposes a cascade structure of two Kalman filters (KF), which relies on the information from the ballistic motion of free-falling multibody systems together with feedback from an inertial measurement unit (IMU) and encoders. Multiple algorithms are verified in the simulation that mimics real-world circumstances with Simulink. Several uncertain physical parameters are varied, and the result shows that the proposed estimator outperforms EKF and UKF in terms of tracking performance and computational time.
An Approach to Inference-Driven Dialogue Management within a Social Chatbot
Oct 31, 2021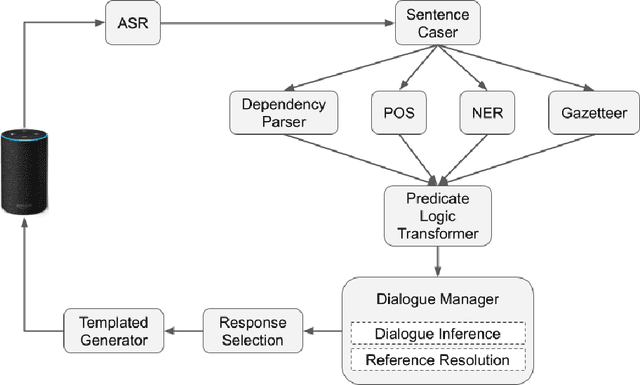
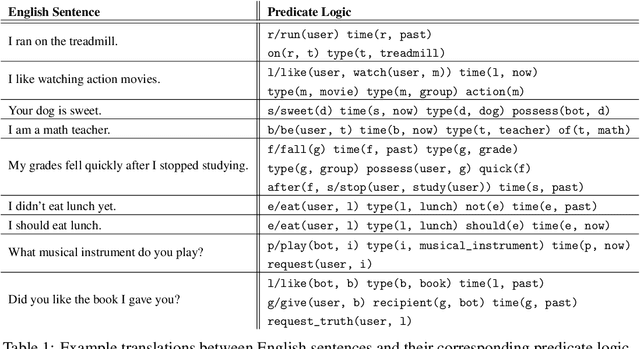
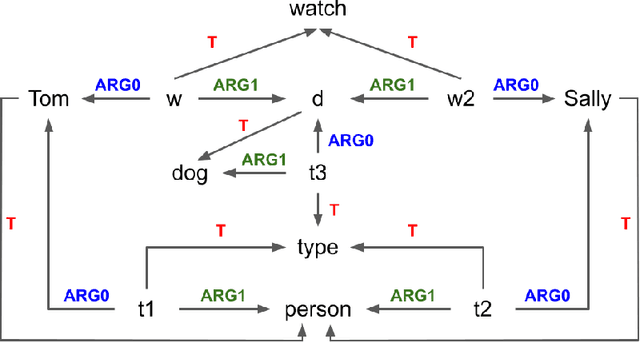
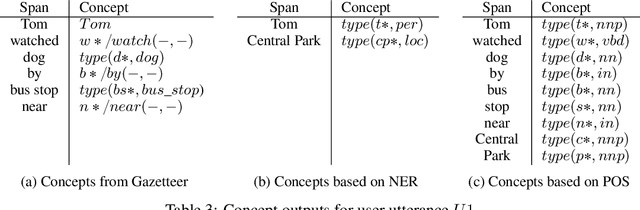
We present a chatbot implementing a novel dialogue management approach based on logical inference. Instead of framing conversation a sequence of response generation tasks, we model conversation as a collaborative inference process in which speakers share information to synthesize new knowledge in real time. Our chatbot pipeline accomplishes this modelling in three broad stages. The first stage translates user utterances into a symbolic predicate representation. The second stage then uses this structured representation in conjunction with a larger knowledge base to synthesize new predicates using efficient graph matching. In the third and final stage, our bot selects a small subset of predicates and translates them into an English response. This approach lends itself to understanding latent semantics of user inputs, flexible initiative taking, and responses that are novel and coherent with the dialogue context.
Computer Vision for Supporting Image Search
Nov 16, 2021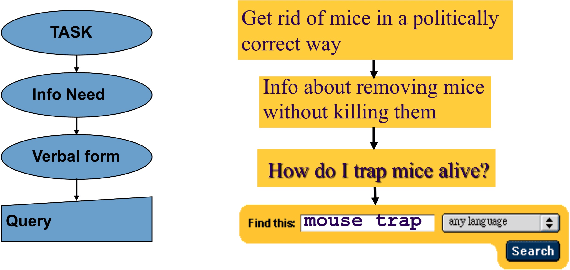
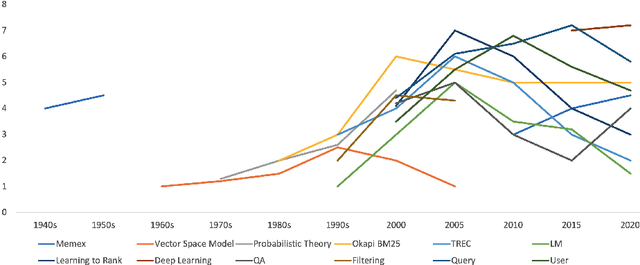
Computer vision and multimedia information processing have made extreme progress within the last decade and many tasks can be done with a level of accuracy as if done by humans, or better. This is because we leverage the benefits of huge amounts of data available for training, we have enormous computer processing available and we have seen the evolution of machine learning as a suite of techniques to process data and deliver accurate vision-based systems. What kind of applications do we use this processing for ? We use this in autonomous vehicle navigation or in security applications, searching CCTV for example, and in medical image analysis for healthcare diagnostics. One application which is not widespread is image or video search directly by users. In this paper we present the need for such image finding or re-finding by examining human memory and when it fails, thus motivating the need for a different approach to image search which is outlined, along with the requirements of computer vision to support it.
* 10 pages
Seeing BDD100K in dark: Single-Stage Night-time Object Detection via Continual Fourier Contrastive Learning
Dec 06, 2021

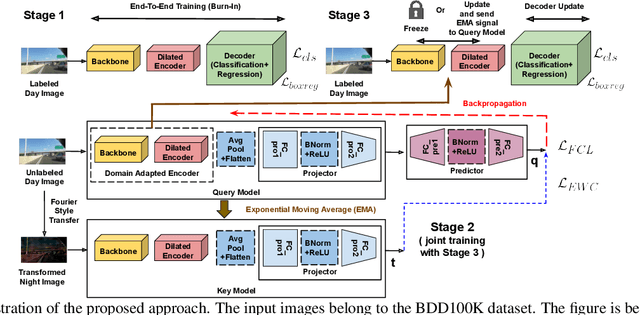
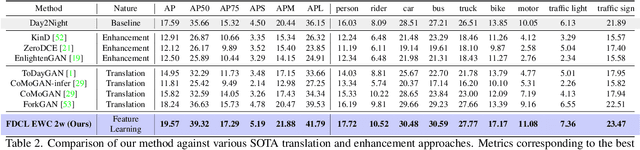
Despite tremendous improvements in state-of-the-art object detectors, addressing object detection in the night-time has been studied only sparsely, that too, via non-uniform evaluation protocols among the limited available papers. In addition to the lack of methods to address this problem, there was also a lack of an adequately large benchmark dataset to study night-time object detection. Recently, the large scale BDD100K was introduced, which, in our opinion, should be chosen as the benchmark, to kickstart research in this area. Now, coming to the methods, existing approaches (limited in number), are mainly either generative image translation based, or image enhancement/ illumination based, neither of which is natural, conforming to how humans see objects in the night time (by focusing on object contours). In this paper, we bridge these 3 gaps: 1. Lack of an uniform evaluation protocol (using a single-stage detector, due to its efficacy, and efficiency), 2. Choice of dataset for benchmarking night-time object detection, and 3. A novel method to address the limitations of current alternatives. Our method leverages a Contrastive Learning based feature extractor, borrowing information from the frequency domain via Fourier transformation, and trained in a continual learning based fashion. The learned features when used for object detection (after fine-tuning the classification and regression layers), help achieve a new state-of-the-art empirical performance, comfortably outperforming an extensive number of competitors.
Exploiting Segment-level Semantics for Online Phase Recognition from Surgical Videos
Nov 22, 2021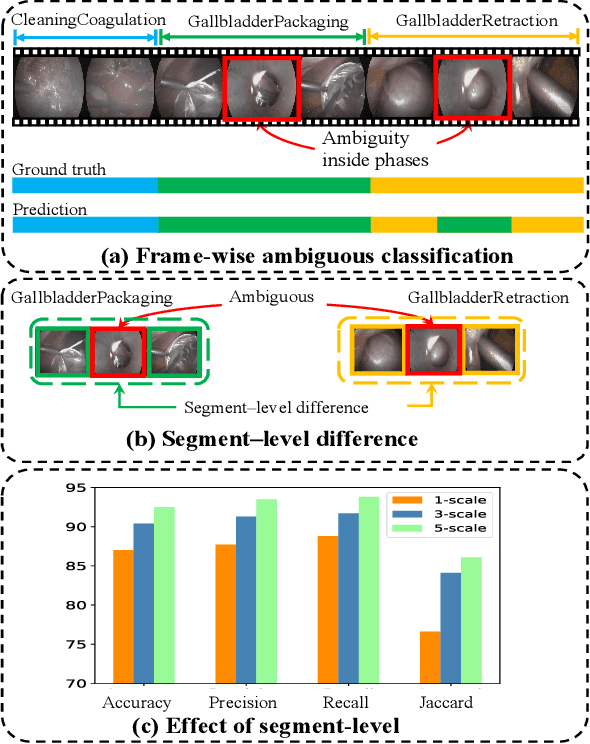
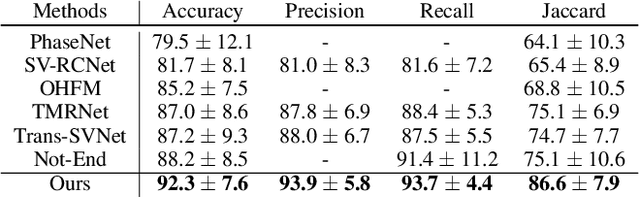
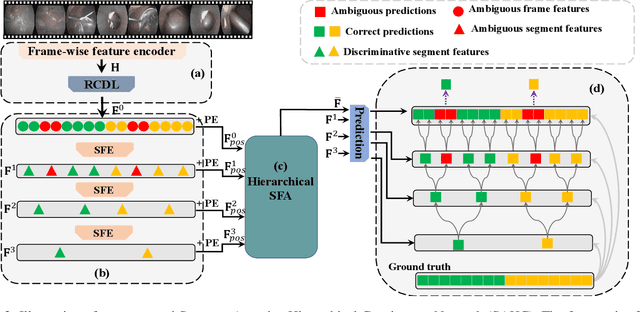
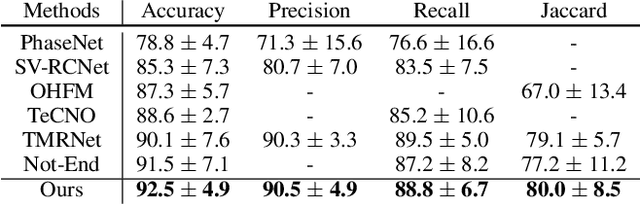
Automatic surgical phase recognition plays an important role in robot-assisted surgeries. Existing methods ignored a pivotal problem that surgical phases should be classified by learning segment-level semantics instead of solely relying on frame-wise information. In this paper, we present a segment-attentive hierarchical consistency network (SAHC) for surgical phase recognition from videos. The key idea is to extract hierarchical high-level semantic-consistent segments and use them to refine the erroneous predictions caused by ambiguous frames. To achieve it, we design a temporal hierarchical network to generate hierarchical high-level segments. Then, we introduce a hierarchical segment-frame attention (SFA) module to capture relations between the low-level frames and high-level segments. By regularizing the predictions of frames and their corresponding segments via a consistency loss, the network can generate semantic-consistent segments and then rectify the misclassified predictions caused by ambiguous low-level frames. We validate SAHC on two public surgical video datasets, i.e., the M2CAI16 challenge dataset and the Cholec80 dataset. Experimental results show that our method outperforms previous state-of-the-arts by a large margin, notably reaches 4.1% improvements on M2CAI16. Code will be released at GitHub upon acceptance.