 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Representation learning through cross-modal conditional teacher-student training for speech emotion recognition
Nov 30, 2021
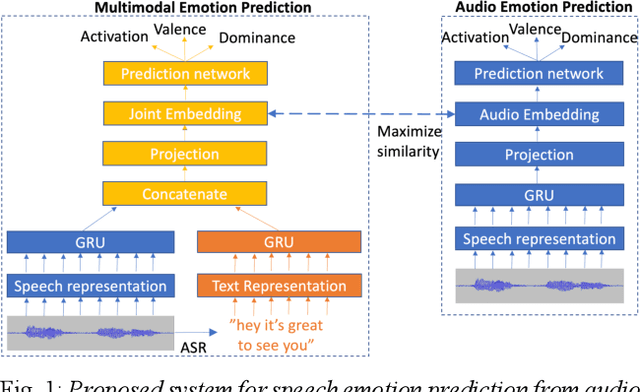
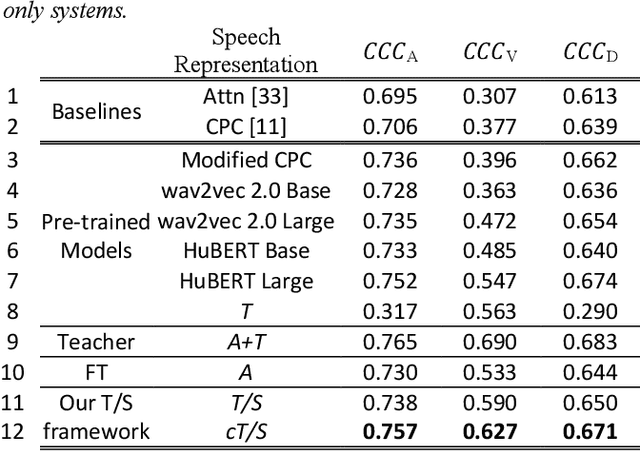
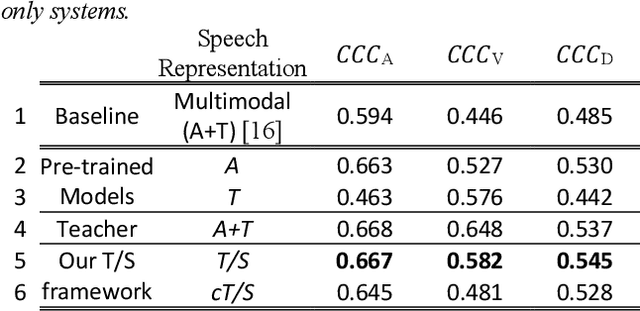
Generic pre-trained speech and text representations promise to reduce the need for large labeled datasets on specific speech and language tasks. However, it is not clear how to effectively adapt these representations for speech emotion recognition. Recent public benchmarks show the efficacy of several popular self-supervised speech representations for emotion classification. In this study, we show that the primary difference between the top-performing representations is in predicting valence while the differences in predicting activation and dominance dimensions are less pronounced. However, we show that even the best-performing HuBERT representation underperforms on valence prediction compared to a multimodal model that also incorporates text representation. We address this shortcoming by injecting lexical information into the speech representation using the multimodal model as a teacher. To improve the efficacy of our approach, we propose a novel estimate of the quality of the emotion predictions, to condition teacher-student training. We report new audio-only state-of-the-art concordance correlation coefficient (CCC) values of 0.757, 0.627, 0.671 for activation, valence and dominance predictions, respectively, on the MSP-Podcast corpus, and also state-of-the-art values of 0.667, 0.582, 0.545 on the IEMOCAP corpus.
Interactive Machine Comprehension with Dynamic Knowledge Graphs
Aug 31, 2021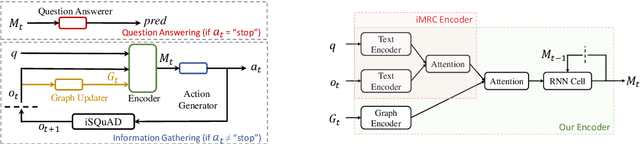
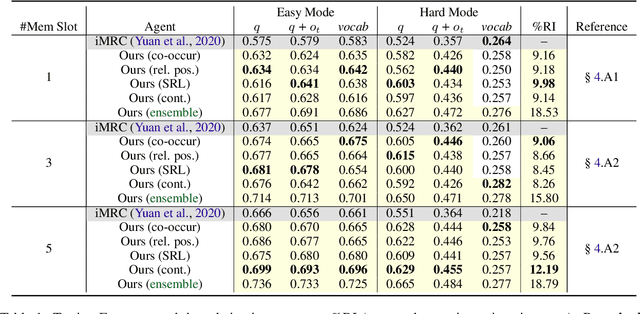
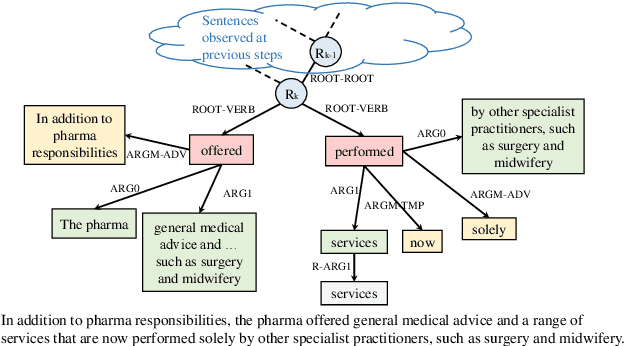
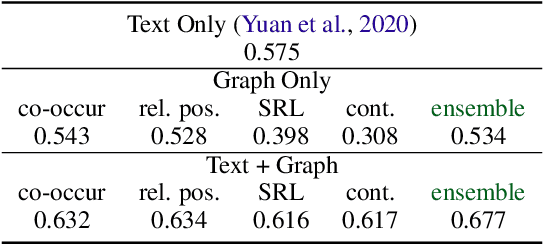
Interactive machine reading comprehension (iMRC) is machine comprehension tasks where knowledge sources are partially observable. An agent must interact with an environment sequentially to gather necessary knowledge in order to answer a question. We hypothesize that graph representations are good inductive biases, which can serve as an agent's memory mechanism in iMRC tasks. We explore four different categories of graphs that can capture text information at various levels. We describe methods that dynamically build and update these graphs during information gathering, as well as neural models to encode graph representations in RL agents. Extensive experiments on iSQuAD suggest that graph representations can result in significant performance improvements for RL agents.
Exploiting a Zoo of Checkpoints for Unseen Tasks
Nov 05, 2021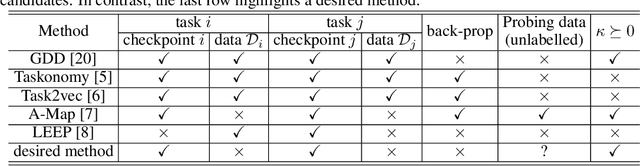
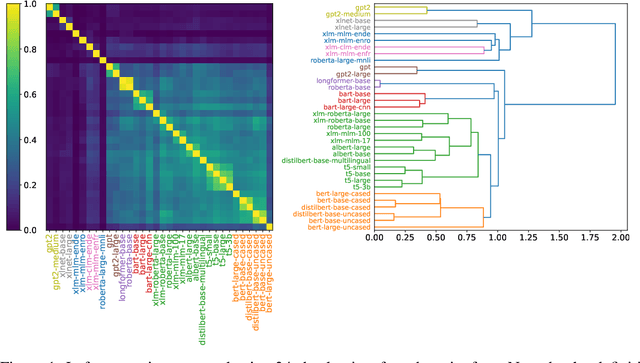
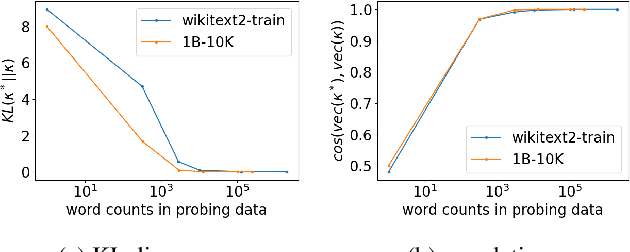

There are so many models in the literature that it is difficult for practitioners to decide which combinations are likely to be effective for a new task. This paper attempts to address this question by capturing relationships among checkpoints published on the web. We model the space of tasks as a Gaussian process. The covariance can be estimated from checkpoints and unlabeled probing data. With the Gaussian process, we can identify representative checkpoints by a maximum mutual information criterion. This objective is submodular. A greedy method identifies representatives that are likely to "cover" the task space. These representatives generalize to new tasks with superior performance. Empirical evidence is provided for applications from both computational linguistics as well as computer vision.
Towards autonomous artificial agents with an active self: modeling sense of control in situated action
Dec 10, 2021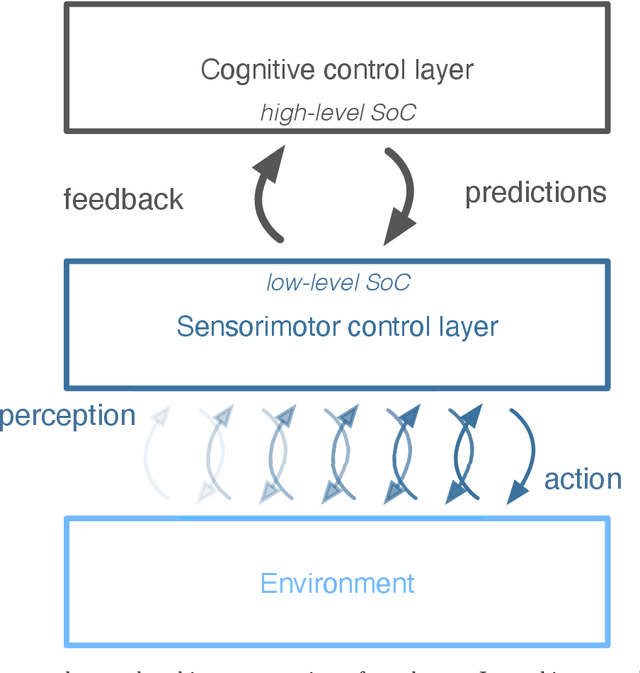
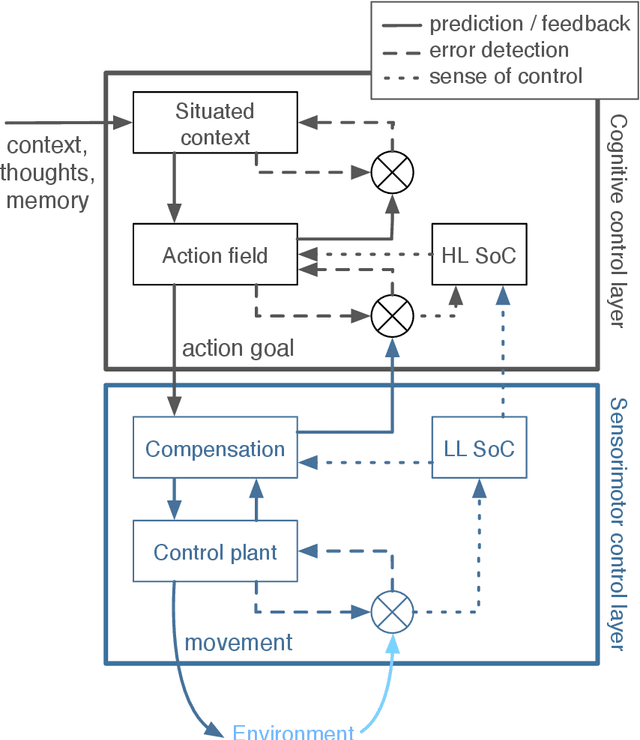
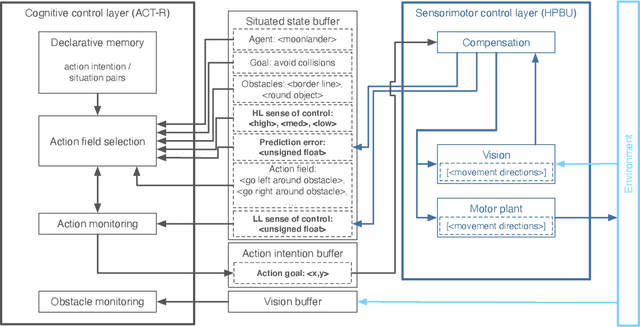
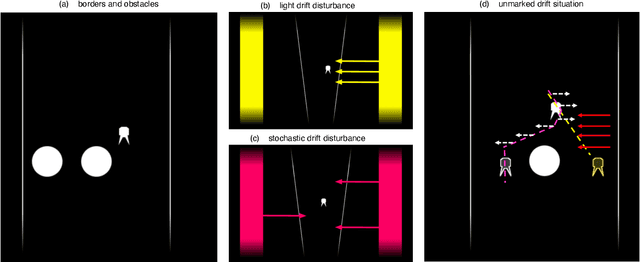
In this paper we present a computational modeling account of an active self in artificial agents. In particular we focus on how an agent can be equipped with a sense of control and how it arises in autonomous situated action and, in turn, influences action control. We argue that this requires laying out an embodied cognitive model that combines bottom-up processes (sensorimotor learning and fine-grained adaptation of control) with top-down processes (cognitive processes for strategy selection and decision-making). We present such a conceptual computational architecture based on principles of predictive processing and free energy minimization. Using this general model, we describe how a sense of control can form across the levels of a control hierarchy and how this can support action control in an unpredictable environment. We present an implementation of this model as well as first evaluations in a simulated task scenario, in which an autonomous agent has to cope with un-/predictable situations and experiences corresponding sense of control. We explore different model parameter settings that lead to different ways of combining low-level and high-level action control. The results show the importance of appropriately weighting information in situations where the need for low/high-level action control varies and they demonstrate how the sense of control can facilitate this.
Mitigating Information Leakage in Image Representations: A Maximum Entropy Approach
Apr 11, 2019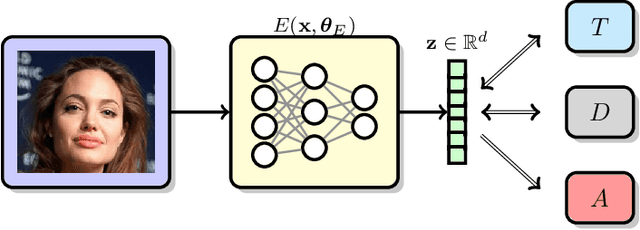
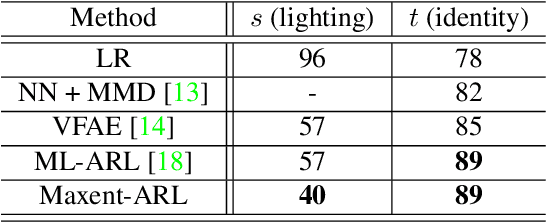
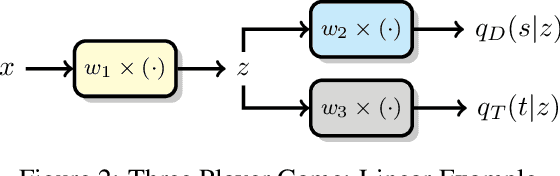
Image recognition systems have demonstrated tremendous progress over the past few decades thanks, in part, to our ability of learning compact and robust representations of images. As we witness the wide spread adoption of these systems, it is imperative to consider the problem of unintended leakage of information from an image representation, which might compromise the privacy of the data owner. This paper investigates the problem of learning an image representation that minimizes such leakage of user information. We formulate the problem as an adversarial non-zero sum game of finding a good embedding function with two competing goals: to retain as much task dependent discriminative image information as possible, while simultaneously minimizing the amount of information, as measured by entropy, about other sensitive attributes of the user. We analyze the stability and convergence dynamics of the proposed formulation using tools from non-linear systems theory and compare to that of the corresponding adversarial zero-sum game formulation that optimizes likelihood as a measure of information content. Numerical experiments on UCI, Extended Yale B, CIFAR-10 and CIFAR-100 datasets indicate that our proposed approach is able to learn image representations that exhibit high task performance while mitigating leakage of predefined sensitive information.
Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction
Oct 28, 2021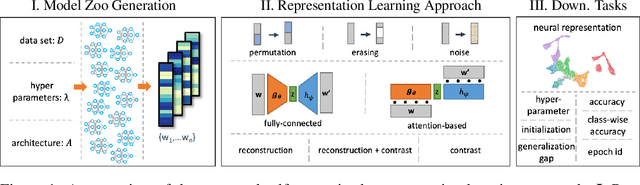
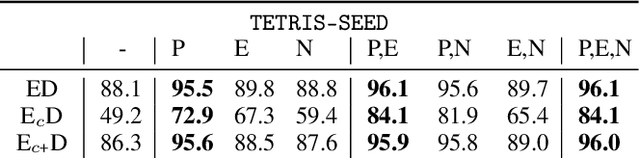
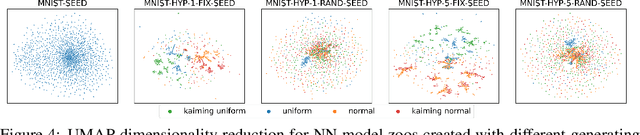
Self-Supervised Learning (SSL) has been shown to learn useful and information-preserving representations. Neural Networks (NNs) are widely applied, yet their weight space is still not fully understood. Therefore, we propose to use SSL to learn neural representations of the weights of populations of NNs. To that end, we introduce domain specific data augmentations and an adapted attention architecture. Our empirical evaluation demonstrates that self-supervised representation learning in this domain is able to recover diverse NN model characteristics. Further, we show that the proposed learned representations outperform prior work for predicting hyper-parameters, test accuracy, and generalization gap as well as transfer to out-of-distribution settings.
Hierarchical transfer learning with applications for electricity load forecasting
Nov 19, 2021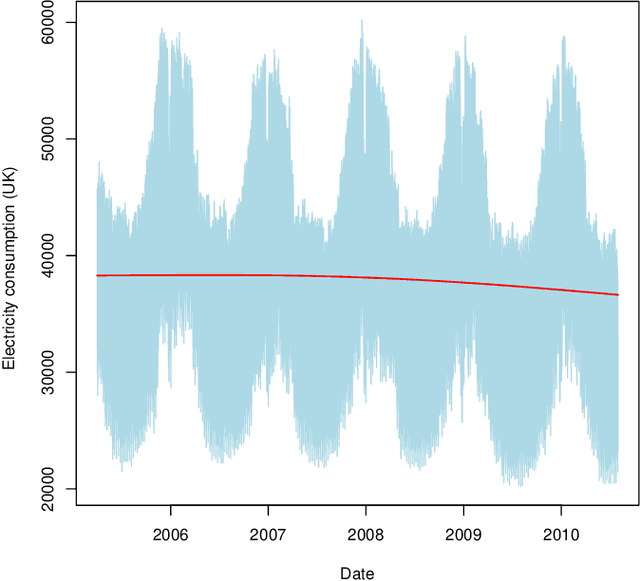

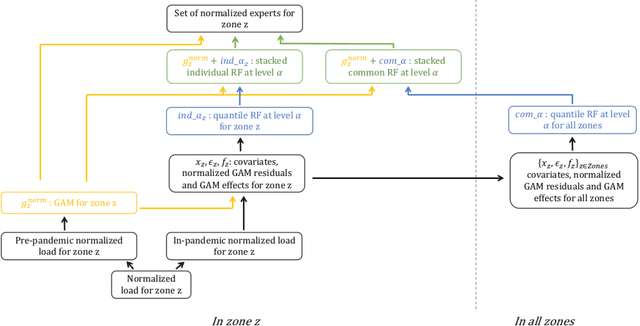

The recent abundance of data on electricity consumption at different scales opens new challenges and highlights the need for new techniques to leverage information present at finer scales in order to improve forecasts at wider scales. In this work, we take advantage of the similarity between this hierarchical prediction problem and multi-scale transfer learning. We develop two methods for hierarchical transfer learning, based respectively on the stacking of generalized additive models and random forests, and on the use of aggregation of experts. We apply these methods to two problems of electricity load forecasting at national scale, using smart meter data in the first case, and regional data in the second case. For these two usecases, we compare the performances of our methods to that of benchmark algorithms, and we investigate their behaviour using variable importance analysis. Our results demonstrate the interest of both methods, which lead to a significant improvement of the predictions.
Multi-label Classification of Aircraft Heading Changes Using Neural Network to Resolve Conflicts
Sep 10, 2021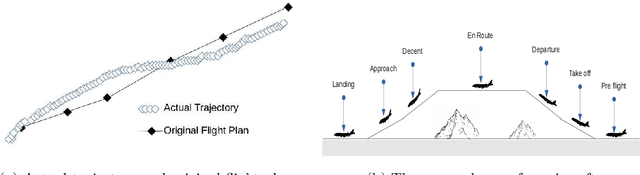

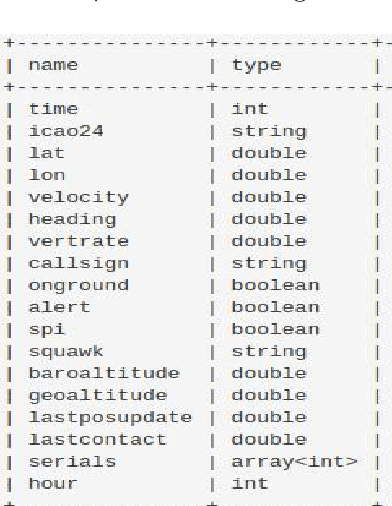
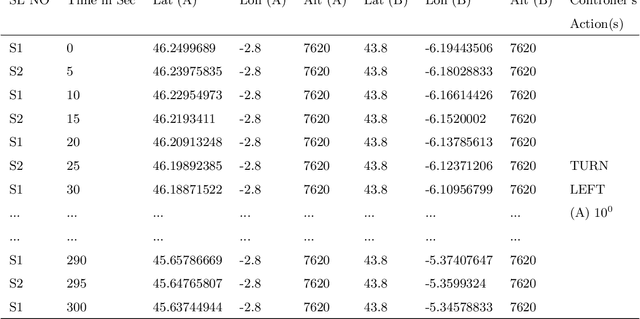
An aircraft conflict occurs when two or more aircraft cross at a certain distance at the same time. Specific air traffic controllers are assigned to solve such conflicts. A controller needs to consider various types of information in order to solve a conflict. The most common and preliminary information is the coordinate position of the involved aircraft. Additionally, a controller has to take into account more information such as flight planning, weather, restricted territory, etc. The most important challenges a controller has to face are: to think about the issues involved and make a decision in a very short time. Due to the increased number of aircraft, it is crucial to reduce the workload of the controllers and help them make quick decisions. A conflict can be solved in many ways, therefore, we consider this problem as a multi-label classification problem. In doing so, we are proposing a multi-label classification model which provides multiple heading advisories for a given conflict. This model we named CRMLnet is based on a novel application of a multi-layer neural network and helps the controllers in their decisions. When compared to other machine learning models, our CRMLnet has achieved the best results with an accuracy of 98.72% and ROC of 0.999. The simulated data set that we have developed and used in our experiments will be delivered to the research community.
Refined Commonsense Knowledge from Large-Scale Web Contents
Nov 30, 2021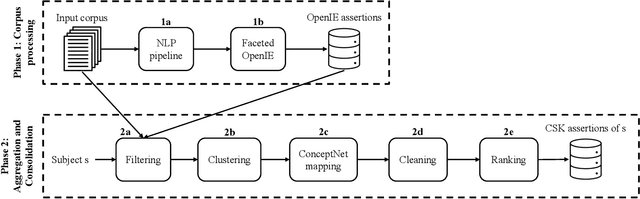
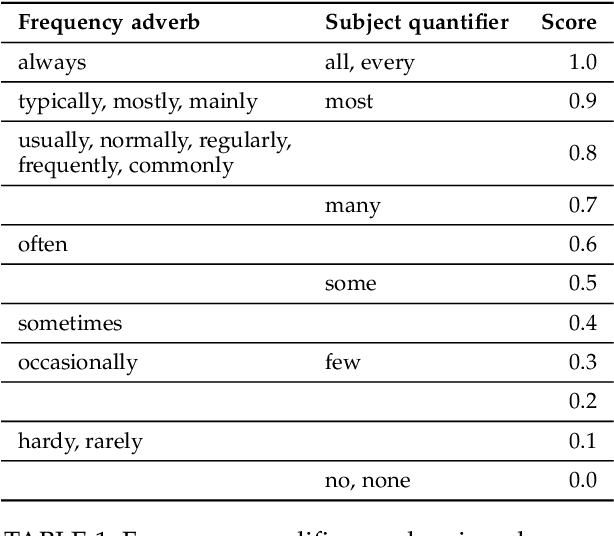
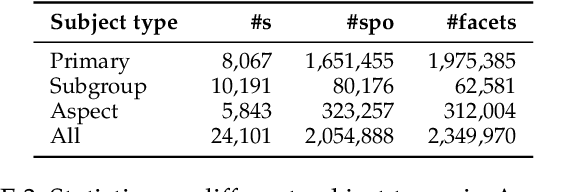
Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications. Prior works like ConceptNet, COMET and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and strings for P and O. This paper presents a method, called ASCENT++, to automatically build a large-scale knowledge base (KB) of CSK assertions, with refined expressiveness and both better precision and recall than prior works. ASCENT++ goes beyond SPO triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter is important to express the temporal and spatial validity of assertions and further qualifiers. ASCENT++ combines open information extraction with judicious cleaning and ranking by typicality and saliency scores. For high coverage, our method taps into the large-scale crawl C4 with broad web contents. The evaluation with human judgements shows the superior quality of the ASCENT++ KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of ASCENT++. A web interface, data and code can be accessed at https://www.mpi-inf.mpg.de/ascentpp.
Varifocal Multiview Images: Capturing and Visual Tasks
Nov 19, 2021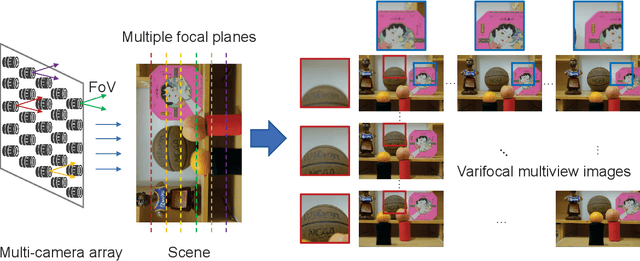
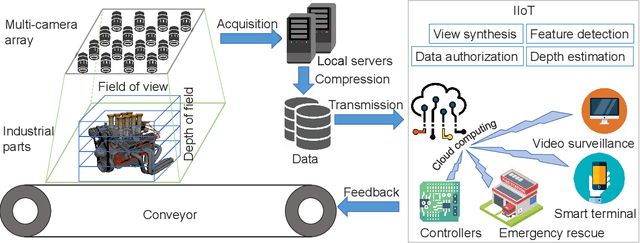


Multiview images have flexible field of view (FoV) but inflexible depth of field (DoF). To overcome the limitation of multiview images on visual tasks, in this paper, we present varifocal multiview (VFMV) images with flexible DoF. VFMV images are captured by focusing a scene on distinct depths by varying focal planes, and each view only focused on one single plane.Therefore, VFMV images contain more information in focal dimension than multiview images, and can provide a rich representation for 3D scene by considering both FoV and DoF. The characteristics of VFMV images are useful for visual tasks to achieve high quality scene representation. Two experiments are conducted to validate the advantages of VFMV images in 4D light field feature detection and 3D reconstruction. Experiment results show that VFMV images can detect more light field features and achieve higher reconstruction quality due to informative focus cues. This work demonstrates that VFMV images have definite advantages over multiview images in visual tasks.