 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HyperInverter: Improving StyleGAN Inversion via Hypernetwork
Dec 01, 2021

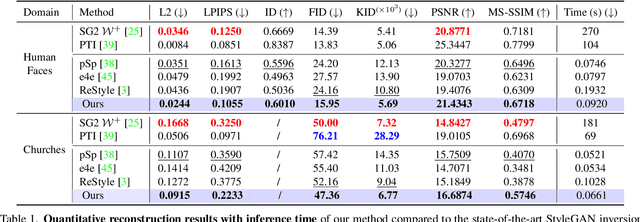
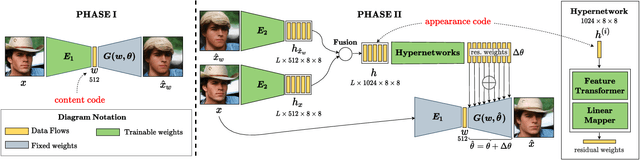
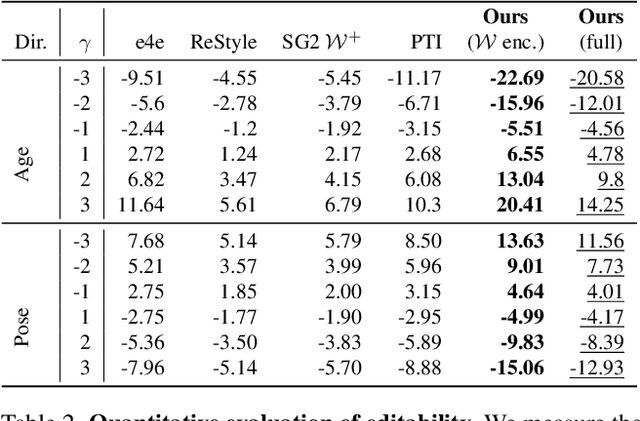
Real-world image manipulation has achieved fantastic progress in recent years as a result of the exploration and utilization of GAN latent spaces. GAN inversion is the first step in this pipeline, which aims to map the real image to the latent code faithfully. Unfortunately, the majority of existing GAN inversion methods fail to meet at least one of the three requirements listed below: high reconstruction quality, editability, and fast inference. We present a novel two-phase strategy in this research that fits all requirements at the same time. In the first phase, we train an encoder to map the input image to StyleGAN2 $\mathcal{W}$-space, which was proven to have excellent editability but lower reconstruction quality. In the second phase, we supplement the reconstruction ability in the initial phase by leveraging a series of hypernetworks to recover the missing information during inversion. These two steps complement each other to yield high reconstruction quality thanks to the hypernetwork branch and excellent editability due to the inversion done in the $\mathcal{W}$-space. Our method is entirely encoder-based, resulting in extremely fast inference. Extensive experiments on two challenging datasets demonstrate the superiority of our method.
Inductive Biased Estimation: Learning Generalizations for Identity Transfer
Oct 04, 2021
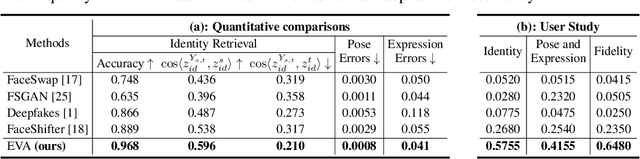
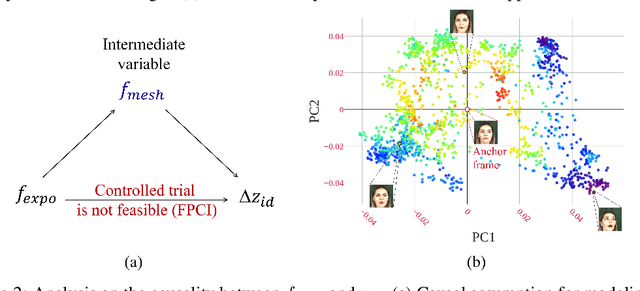
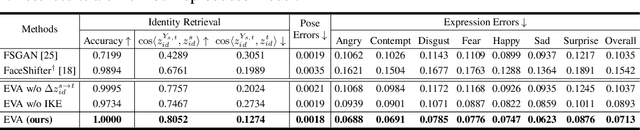
Identity transfer often faces the challenge of generalizing to new situations where large pose and expression or background gaps exist between source and target face images. To improve generalization in such situations, biases take a key role~\cite{mitchell_1980_bias}. This paper proposes an Errors-in-Variables Adapter (EVA) model to induce learning of proper generalizations by explicitly employing biases to identity estimation based on prior knowledge about the target situation. To better match the source face with the target situation in terms of pose, expression, and background factors, we model the bias as a causal effect of the target situation on source identity and estimate this effect through a controlled intervention trial. To achieve smoother transfer for the target face across the identity gap, we eliminate the target face specificity through multiple kernel regressions. The kernels are used to constrain the regressions to operate only on identity information in the internal representations of the target image, while leaving other perceptual information invariant. Combining these post-regression representations with the biased estimation for identity, EVA shows impressive performance even in the presence of large gaps, providing empirical evidence supporting the utility of the inductive biases in identity estimation.
Pretrained Cost Model for Distributed Constraint Optimization Problems
Dec 15, 2021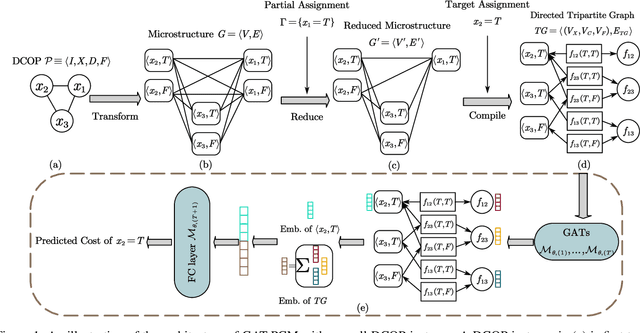
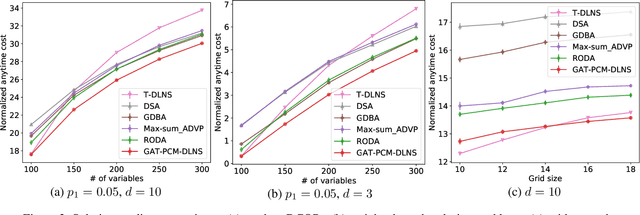
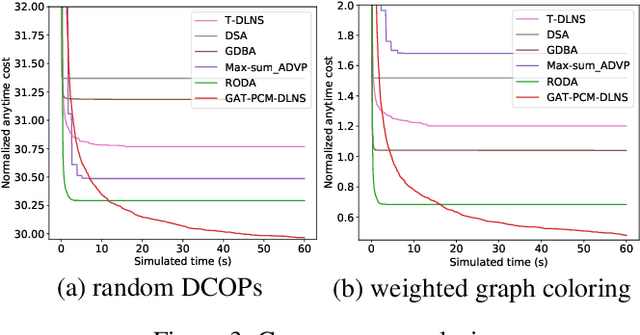
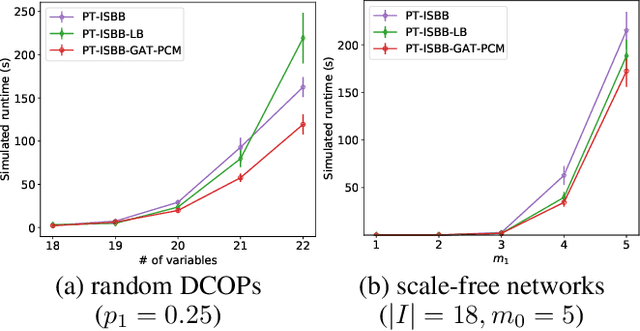
Distributed Constraint Optimization Problems (DCOPs) are an important subclass of combinatorial optimization problems, where information and controls are distributed among multiple autonomous agents. Previously, Machine Learning (ML) has been largely applied to solve combinatorial optimization problems by learning effective heuristics. However, existing ML-based heuristic methods are often not generalizable to different search algorithms. Most importantly, these methods usually require full knowledge about the problems to be solved, which are not suitable for distributed settings where centralization is not realistic due to geographical limitations or privacy concerns. To address the generality issue, we propose a novel directed acyclic graph representation schema for DCOPs and leverage the Graph Attention Networks (GATs) to embed graph representations. Our model, GAT-PCM, is then pretrained with optimally labelled data in an offline manner, so as to construct effective heuristics to boost a broad range of DCOP algorithms where evaluating the quality of a partial assignment is critical, such as local search or backtracking search. Furthermore, to enable decentralized model inference, we propose a distributed embedding schema of GAT-PCM where each agent exchanges only embedded vectors, and show its soundness and complexity. Finally, we demonstrate the effectiveness of our model by combining it with a local search or a backtracking search algorithm. Extensive empirical evaluations indicate that the GAT-PCM-boosted algorithms significantly outperform the state-of-the-art methods in various benchmarks. The pretrained model is available at https://github.com/dyc941126/GAT-PCM.
Task-Oriented Communication for Multi-Device Cooperative Edge Inference
Sep 01, 2021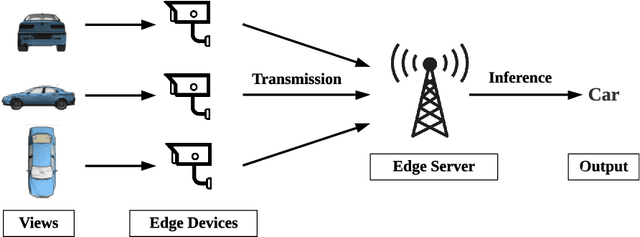
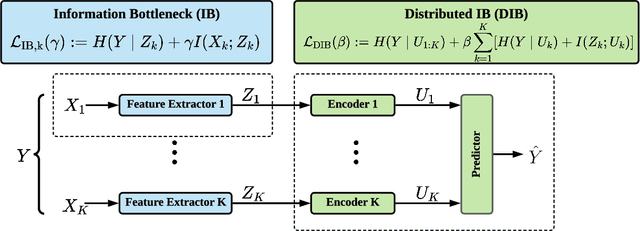
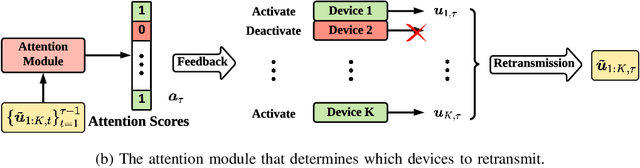
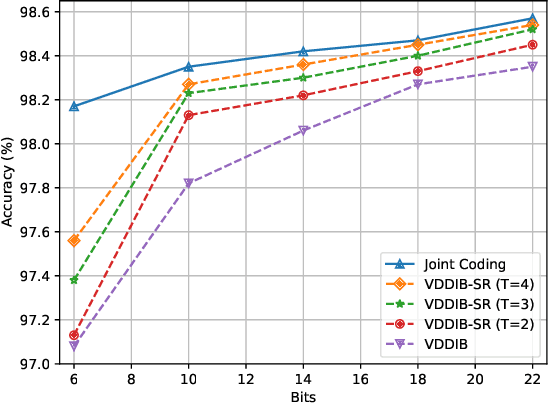
This paper investigates task-oriented communication for multi-device cooperative edge inference, where a group of distributed low-end edge devices transmit the extracted features of local samples to a powerful edge server for inference. While cooperative edge inference can overcome the limited sensing capability of a single device, it substantially increases the communication overhead and may incur excessive latency. To enable low-latency cooperative inference, we propose a learning-based communication scheme that optimizes local feature extraction and distributed feature encoding in a task-oriented manner, i.e., to remove data redundancy and transmit information that is essential for the downstream inference task rather than reconstructing the data samples at the edge server. Specifically, we leverage an information bottleneck (IB) principle to extract the task-relevant feature at each edge device and adopt a distributed information bottleneck (DIB) framework to formalize a single-letter characterization of the optimal rate-relevance tradeoff for distributed feature encoding. To admit flexible control of the communication overhead, we extend the DIB framework to a distributed deterministic information bottleneck (DDIB) objective that explicitly incorporates the representational costs of the encoded features. As the IB-based objectives are computationally prohibitive for high-dimensional data, we adopt variational approximations to make the optimization problems tractable. To compensate the potential performance loss due to the variational approximations, we also develop a selective retransmission (SR) mechanism to identify the redundancy in the encoded features of multiple edge devices to attain additional communication overhead reduction. Extensive experiments evidence that the proposed task-oriented communication scheme achieves a better rate-relevance tradeoff than baseline methods.
A Volumetric Transformer for Accurate 3D Tumor Segmentation
Nov 26, 2021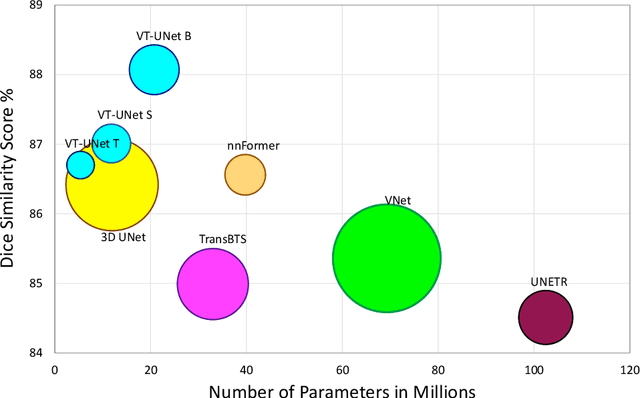
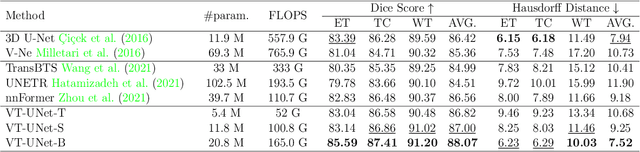
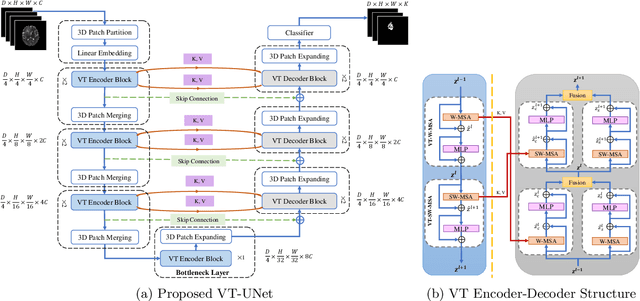
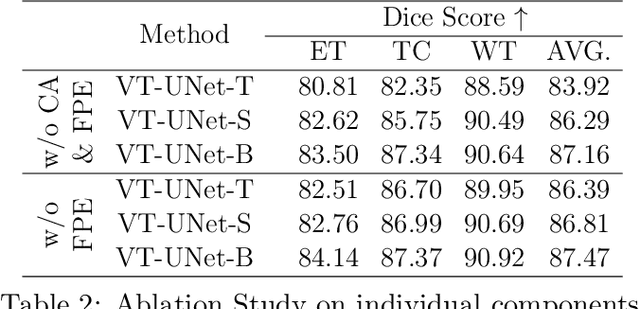
This paper presents a Transformer architecture for volumetric medical image segmentation. Designing a computationally efficient Transformer architecture for volumetric segmentation is a challenging task. It requires keeping a complex balance in encoding local and global spatial cues, and preserving information along all axes of the volumetric data. The proposed volumetric Transformer has a U-shaped encoder-decoder design that processes the input voxels in their entirety. Our encoder has two consecutive self-attention layers to simultaneously encode local and global cues, and our decoder has novel parallel shifted window based self and cross attention blocks to capture fine details for boundary refinement by subsuming Fourier position encoding. Our proposed design choices result in a computationally efficient architecture, which demonstrates promising results on Brain Tumor Segmentation (BraTS) 2021, and Medical Segmentation Decathlon (Pancreas and Liver) datasets for tumor segmentation. We further show that the representations learned by our model transfer better across-datasets and are robust against data corruptions. \href{https://github.com/himashi92/VT-UNet}{Our code implementation is publicly available}.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos
Dec 15, 2021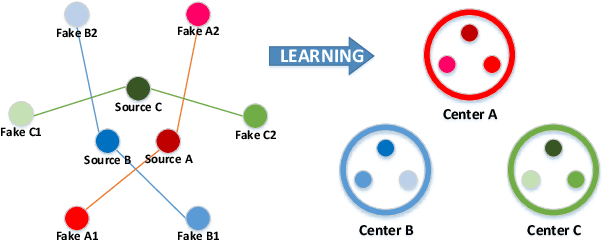
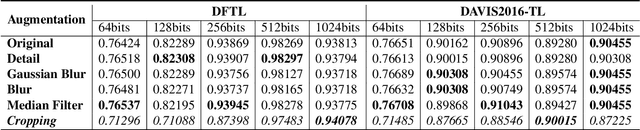
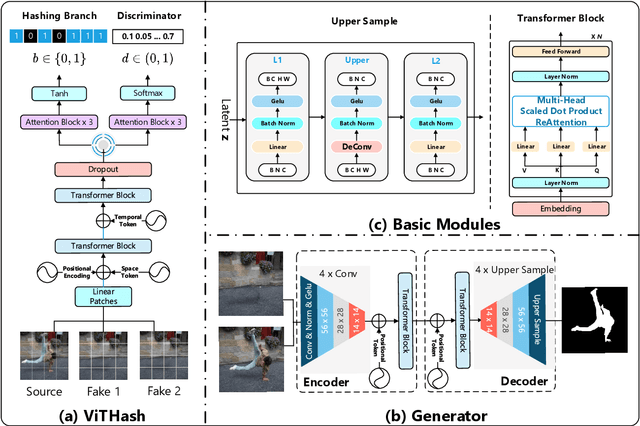

Conventional fake video detection methods outputs a possibility value or a suspected mask of tampering images. However, such unexplainable results cannot be used as convincing evidence. So it is better to trace the sources of fake videos. The traditional hashing methods are used to retrieve semantic-similar images, which can't discriminate the nuances of the image. Specifically, the sources tracing compared with traditional video retrieval. It is a challenge to find the real one from similar source videos. We designed a novel loss Hash Triplet Loss to solve the problem that the videos of people are very similar: the same scene with different angles, similar scenes with the same person. We propose Vision Transformer based models named Video Tracing and Tampering Localization (VTL). In the first stage, we train the hash centers by ViTHash (VTL-T). Then, a fake video is inputted to ViTHash, which outputs a hash code. The hash code is used to retrieve the source video from hash centers. In the second stage, the source video and fake video are inputted to generator (VTL-L). Then, the suspect regions are masked to provide auxiliary information. Moreover, we constructed two datasets: DFTL and DAVIS2016-TL. Experiments on DFTL clearly show the superiority of our framework in sources tracing of similar videos. In particular, the VTL also achieved comparable performance with state-of-the-art methods on DAVIS2016-TL. Our source code and datasets have been released on GitHub: \url{https://github.com/lajlksdf/vtl}.
Shaking Syntactic Trees on the Sesame Street: Multilingual Probing with Controllable Perturbations
Sep 28, 2021
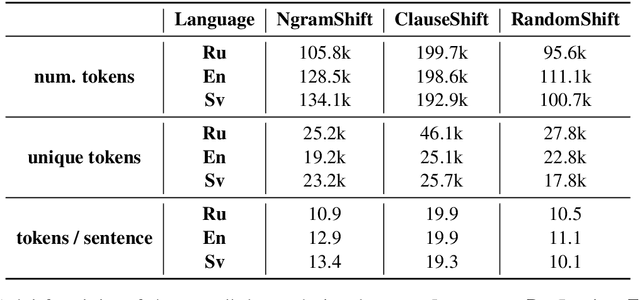
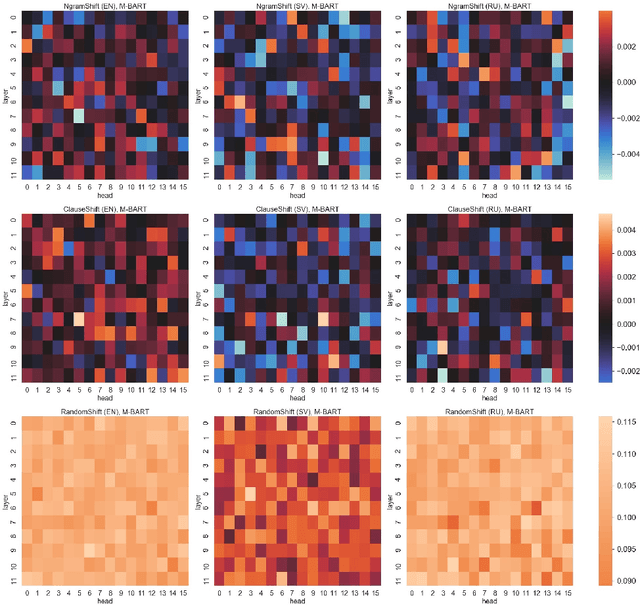

Recent research has adopted a new experimental field centered around the concept of text perturbations which has revealed that shuffled word order has little to no impact on the downstream performance of Transformer-based language models across many NLP tasks. These findings contradict the common understanding of how the models encode hierarchical and structural information and even question if the word order is modeled with position embeddings. To this end, this paper proposes nine probing datasets organized by the type of \emph{controllable} text perturbation for three Indo-European languages with a varying degree of word order flexibility: English, Swedish and Russian. Based on the probing analysis of the M-BERT and M-BART models, we report that the syntactic sensitivity depends on the language and model pre-training objectives. We also find that the sensitivity grows across layers together with the increase of the perturbation granularity. Last but not least, we show that the models barely use the positional information to induce syntactic trees from their intermediate self-attention and contextualized representations.
Improved Knowledge Graph Embedding using Background Taxonomic Information
Dec 07, 2018



Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.
Fusion Detection via Distance-Decay IoU and weighted Dempster-Shafer Evidence Theory
Dec 06, 2021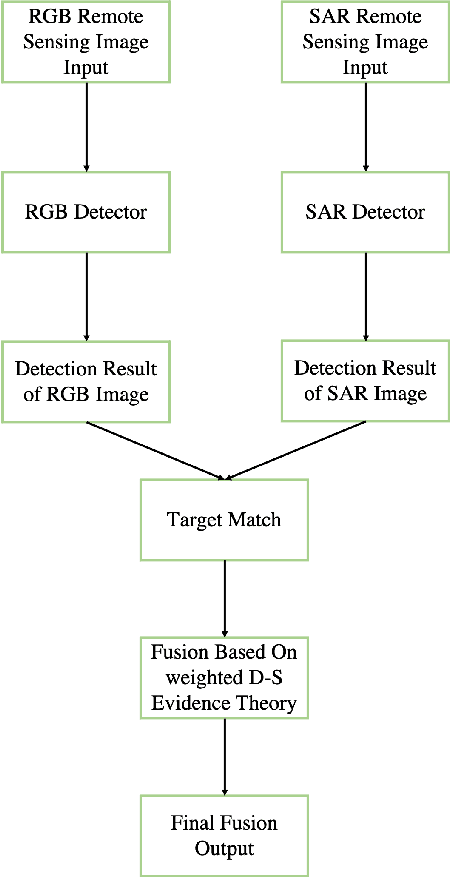

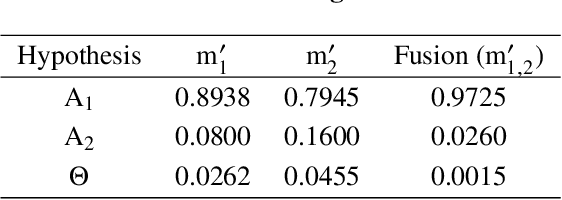
In recent years, increasing attentions are paid on object detection in remote sensing imagery. However, traditional optical detection is highly susceptible to illumination and weather anomaly. It is a challenge to effectively utilize the cross-modality information from multi-source remote sensing images, especially from optical and synthetic aperture radar images, to achieve all-day and all-weather detection with high accuracy and speed. Towards this end, a fast multi-source fusion detection framework is proposed in current paper. A novel distance-decay intersection over union is employed to encode the shape properties of the targets with scale invariance. Therefore, the same target in multi-source images can be paired accurately. Furthermore, the weighted Dempster-Shafer evidence theory is utilized to combine the optical and synthetic aperture radar detection, which overcomes the drawback in feature-level fusion that requires a large amount of paired data. In addition, the paired optical and synthetic aperture radar images for container ship Ever Given which ran aground in the Suez Canal are taken to demonstrate our fusion algorithm. To test the effectiveness of the proposed method, on self-built data set, the average precision of the proposed fusion detection framework outperform the optical detection by 20.13%.
You Only Need End-to-End Training for Long-Tailed Recognition
Dec 15, 2021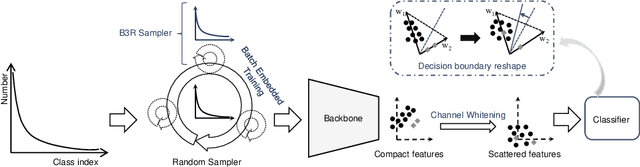
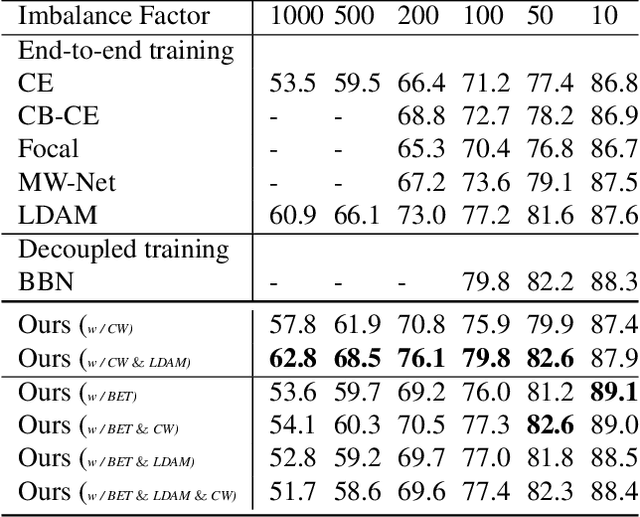
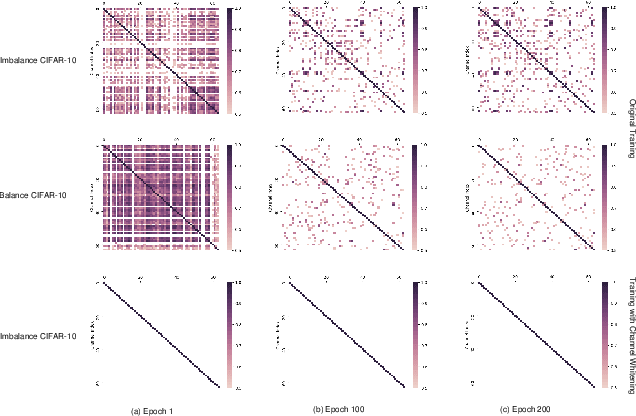
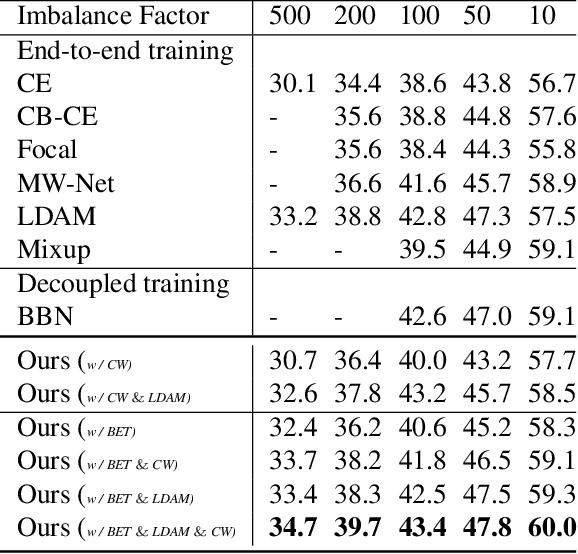
The generalization gap on the long-tailed data sets is largely owing to most categories only occupying a few training samples. Decoupled training achieves better performance by training backbone and classifier separately. What causes the poorer performance of end-to-end model training (e.g., logits margin-based methods)? In this work, we identify a key factor that affects the learning of the classifier: the channel-correlated features with low entropy before inputting into the classifier. From the perspective of information theory, we analyze why cross-entropy loss tends to produce highly correlated features on the imbalanced data. In addition, we theoretically analyze and prove its impacts on the gradients of classifier weights, the condition number of Hessian, and logits margin-based approach. Therefore, we firstly propose to use Channel Whitening to decorrelate ("scatter") the classifier's inputs for decoupling the weight update and reshaping the skewed decision boundary, which achieves satisfactory results combined with logits margin-based method. However, when the number of minor classes are large, batch imbalance and more participation in training cause over-fitting of the major classes. We also propose two novel modules, Block-based Relatively Balanced Batch Sampler (B3RS) and Batch Embedded Training (BET) to solve the above problems, which makes the end-to-end training achieve even better performance than decoupled training. Experimental results on the long-tailed classification benchmarks, CIFAR-LT and ImageNet-LT, demonstrate the effectiveness of our method.