 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Predicting Chemical Hazard across Taxa through Machine Learning
Oct 07, 2021
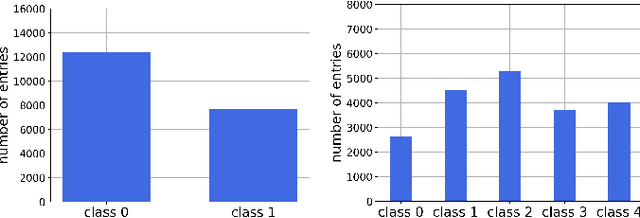
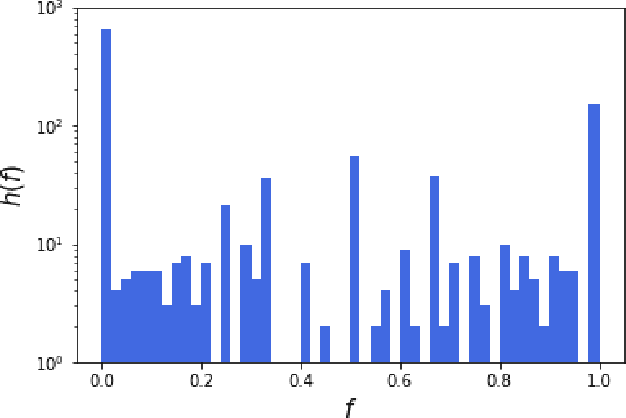
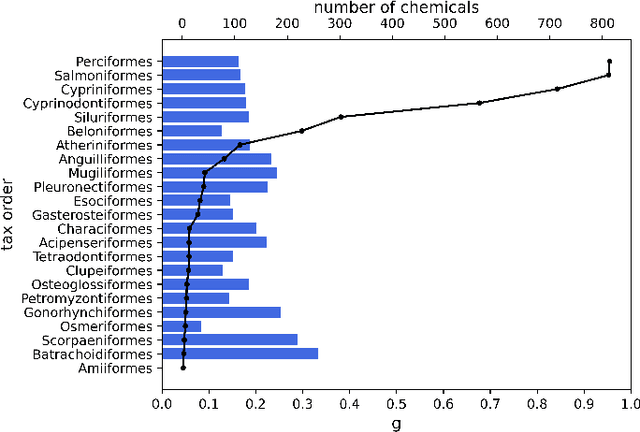
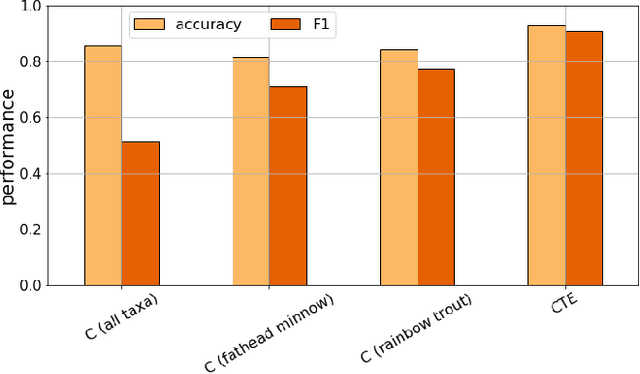
We apply machine learning methods to predict chemical hazards focusing on fish acute toxicity across taxa. We analyze the relevance of taxonomy and experimental setup, and show that taking them into account can lead to considerable improvements in the classification performance. We quantify the gain obtained by introducing the taxonomic and experimental information, compared to classifying based on chemical information alone. We use our approach with standard machine learning models (K-nearest neighbors, random forests and deep neural networks), as well as the recently proposed Read-Across Structure Activity Relationship (RASAR) models, which were very successful in predicting chemical hazards to mammals based on chemical similarity. We are able to obtain accuracies of over 0.93 on datasets where, due to noise in the data, the maximum achievable accuracy is expected to be below 0.95, which results in an effective accuracy of 0.98. The best performances are obtained by random forests and RASAR models. We analyze metrics to compare our results with animal test reproducibility, and despite most of our models 'outperform animal test reproducibility' as measured through recently proposed metrics, we show that the comparison between machine learning performance and animal test reproducibility should be addressed with particular care. While we focus on fish mortality, our approach, provided that the right data is available, is valid for any combination of chemicals, effects and taxa.
GQE-PRF: Generative Query Expansion with Pseudo-Relevance Feedback
Aug 13, 2021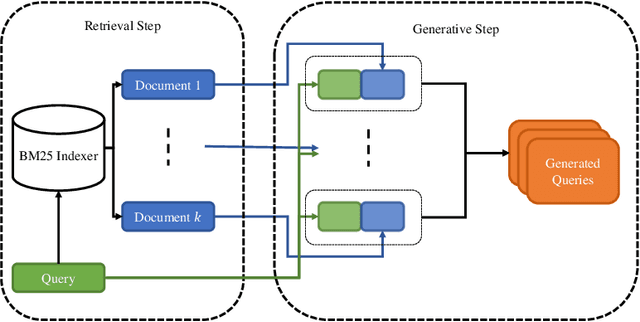

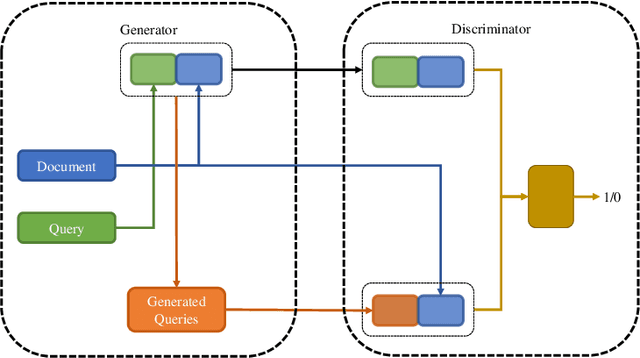
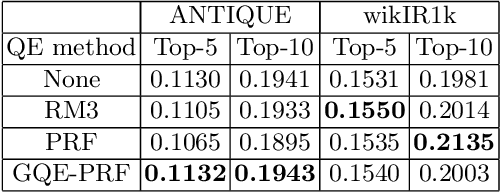
Query expansion with pseudo-relevance feedback (PRF) is a powerful approach to enhance the effectiveness in information retrieval. Recently, with the rapid advance of deep learning techniques, neural text generation has achieved promising success in many natural language tasks. To leverage the strength of text generation for information retrieval, in this article, we propose a novel approach which effectively integrates text generation models into PRF-based query expansion. In particular, our approach generates augmented query terms via neural text generation models conditioned on both the initial query and pseudo-relevance feedback. Moreover, in order to train the generative model, we adopt the conditional generative adversarial nets (CGANs) and propose the PRF-CGAN method in which both the generator and the discriminator are conditioned on the pseudo-relevance feedback. We evaluate the performance of our approach on information retrieval tasks using two benchmark datasets. The experimental results show that our approach achieves comparable performance or outperforms traditional query expansion methods on both the retrieval and reranking tasks.
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Oct 07, 2021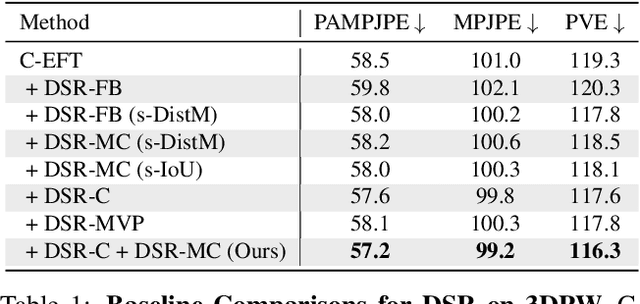
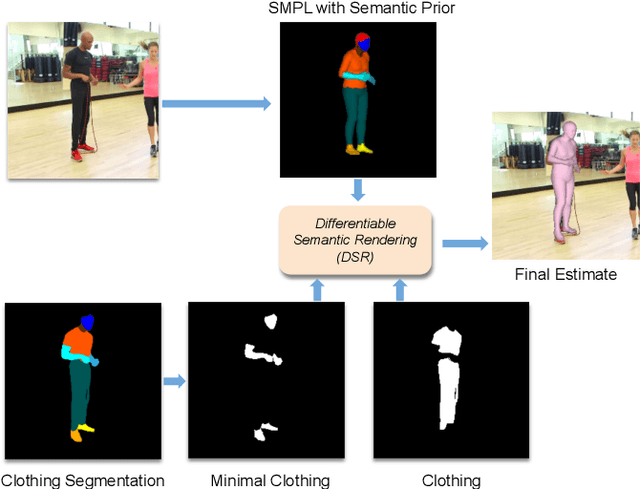
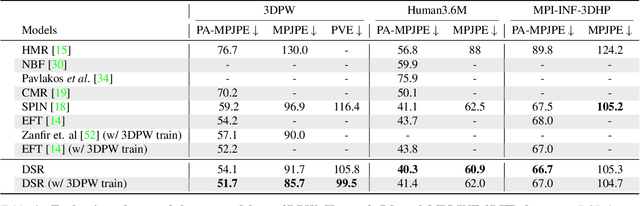
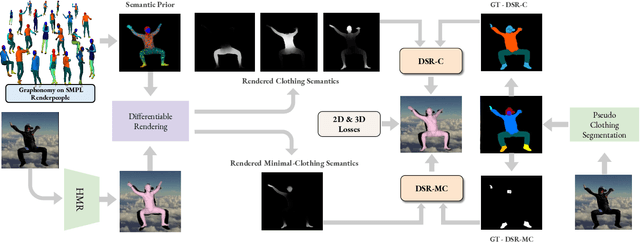
Learning to regress 3D human body shape and pose (e.g.~SMPL parameters) from monocular images typically exploits losses on 2D keypoints, silhouettes, and/or part-segmentation when 3D training data is not available. Such losses, however, are limited because 2D keypoints do not supervise body shape and segmentations of people in clothing do not match projected minimally-clothed SMPL shapes. To exploit richer image information about clothed people, we introduce higher-level semantic information about clothing to penalize clothed and non-clothed regions of the image differently. To do so, we train a body regressor using a novel Differentiable Semantic Rendering - DSR loss. For Minimally-Clothed regions, we define the DSR-MC loss, which encourages a tight match between a rendered SMPL body and the minimally-clothed regions of the image. For clothed regions, we define the DSR-C loss to encourage the rendered SMPL body to be inside the clothing mask. To ensure end-to-end differentiable training, we learn a semantic clothing prior for SMPL vertices from thousands of clothed human scans. We perform extensive qualitative and quantitative experiments to evaluate the role of clothing semantics on the accuracy of 3D human pose and shape estimation. We outperform all previous state-of-the-art methods on 3DPW and Human3.6M and obtain on par results on MPI-INF-3DHP. Code and trained models are available for research at https://dsr.is.tue.mpg.de/.
Self-Conditioned Probabilistic Learning of Video Rescaling
Aug 18, 2021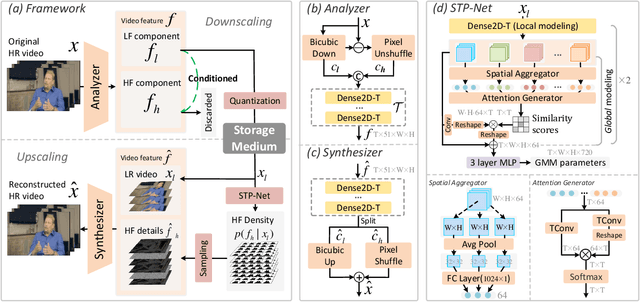
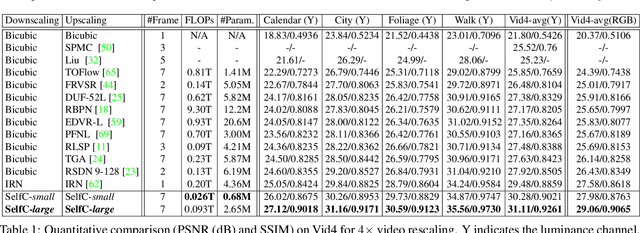
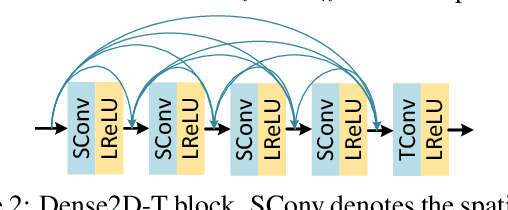

Bicubic downscaling is a prevalent technique used to reduce the video storage burden or to accelerate the downstream processing speed. However, the inverse upscaling step is non-trivial, and the downscaled video may also deteriorate the performance of downstream tasks. In this paper, we propose a self-conditioned probabilistic framework for video rescaling to learn the paired downscaling and upscaling procedures simultaneously. During the training, we decrease the entropy of the information lost in the downscaling by maximizing its probability conditioned on the strong spatial-temporal prior information within the downscaled video. After optimization, the downscaled video by our framework preserves more meaningful information, which is beneficial for both the upscaling step and the downstream tasks, e.g., video action recognition task. We further extend the framework to a lossy video compression system, in which a gradient estimator for non-differential industrial lossy codecs is proposed for the end-to-end training of the whole system. Extensive experimental results demonstrate the superiority of our approach on video rescaling, video compression, and efficient action recognition tasks.
Visualization of Real-time Displacement Time History superimposed with Dynamic Experiments using Wireless Smart Sensors (WSS) and Augmented Reality (AR)
Oct 17, 2021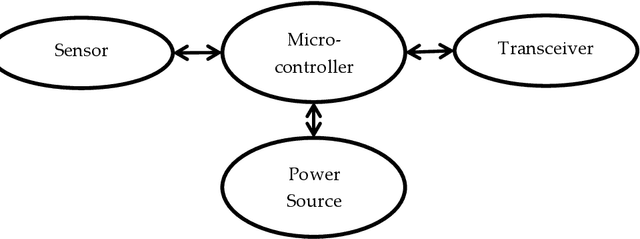
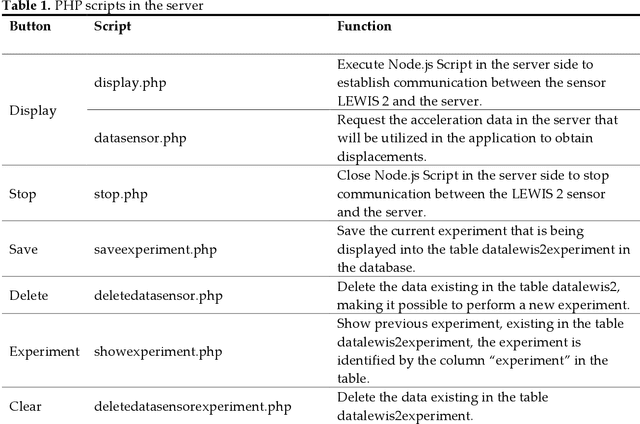

Wireless Smart Sensors (WSS) process field data and inform structural engineers and owners about the infrastructure health and safety. In bridge engineering, inspectors make decisions using objective data from each bridge. They decide about repairs and replacements and prioritize the maintenance of certain structure elements on the basis of changes in displacements under loads. However, access to displacement information in the field and in real-time remains a challenge. Displacement data provided by WSS in the field undergoes additional processing and is seen at a different location by an inspector and a sensor specialist. When the data is shared and streamed to the field inspector, there is a inter-dependence between inspectors, sensor specialists, and infrastructure owners, which limits the actionability of the data related to the bridge condition. If inspectors were able to see structural displacements in real-time at the locations of interest, they could conduct additional observations, which would create a new, information-based, decision-making reality in the field. This paper develops a new, human-centered interface that provides inspectors with real-time access to actionable structural data (real-time displacements under loads) during inspection and monitoring enhanced by Augmented Reality (AR). It summarizes the development and validation of the new human-infrastructure interface and evaluates its efficiency through laboratory experiments. The experiments demonstrate that the interface accurately estimates dynamic displacements in comparison with the laser. Using this new AR interface tool, inspectors can observe and compare displacement data, share it across space and time, and visualize displacements in time history.
Quality and Cost Trade-offs in Passage Re-ranking Task
Nov 18, 2021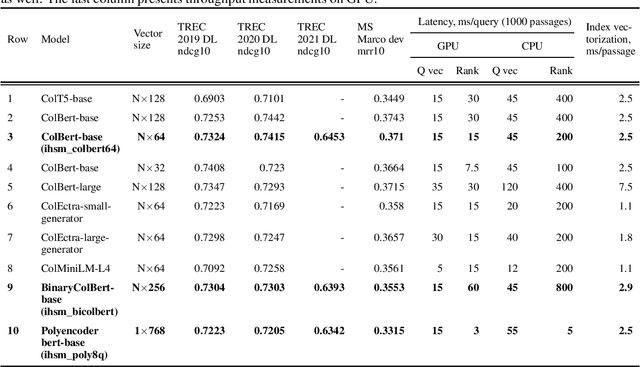
Deep learning models named transformers achieved state-of-the-art results in a vast majority of NLP tasks at the cost of increased computational complexity and high memory consumption. Using the transformer model in real-time inference becomes a major challenge when implemented in production, because it requires expensive computational resources. The more executions of a transformer are needed the lower the overall throughput is, and switching to the smaller encoders leads to the decrease of accuracy. Our paper is devoted to the problem of how to choose the right architecture for the ranking step of the information retrieval pipeline, so that the number of required calls of transformer encoder is minimal with the maximum achievable quality of ranking. We investigated several late-interaction models such as Colbert and Poly-encoder architectures along with their modifications. Also, we took care of the memory footprint of the search index and tried to apply the learning-to-hash method to binarize the output vectors from the transformer encoders. The results of the evaluation are provided using TREC 2019-2021 and MS Marco dev datasets.
Simple stopping criteria for information theoretic feature selection
Nov 29, 2018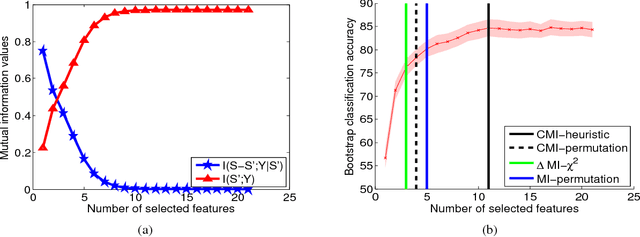
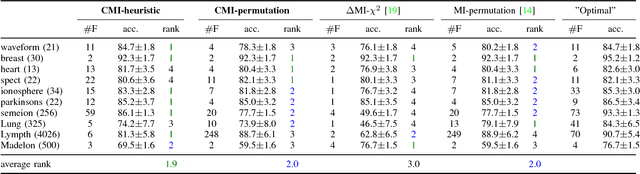
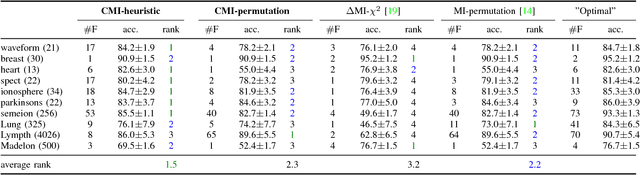
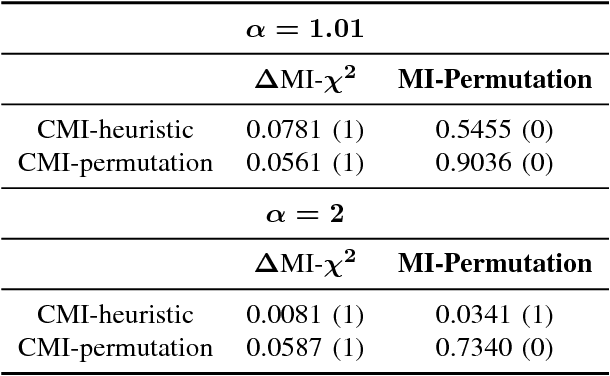
Information theoretic feature selection aims to select a smallest feature subset such that the mutual information between the selected features and the class labels is maximized. Despite the simplicity of this objective, there still remains several open problems to optimize it. These include, for example, the automatic determination of the optimal subset size (i.e., the number of features) or a stopping criterion if the greedy searching strategy is adopted. In this letter, we suggest two stopping criteria by just monitoring the conditional mutual information (CMI) among groups of variables. Using the recently developed multivariate matrix-based Renyi's \alpha-entropy functional, we show that the CMI among groups of variables can be easily estimated without any decomposition or approximation, hence making our criteria easily implemented and seamlessly integrated into any existing information theoretic feature selection methods with greedy search strategy.
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021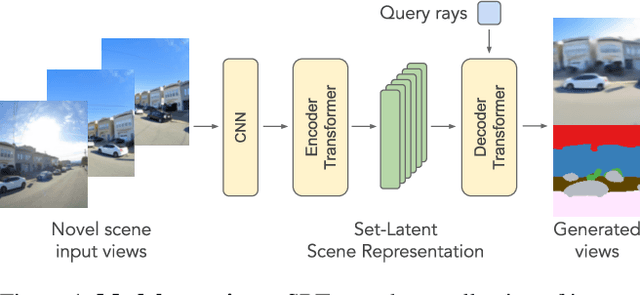

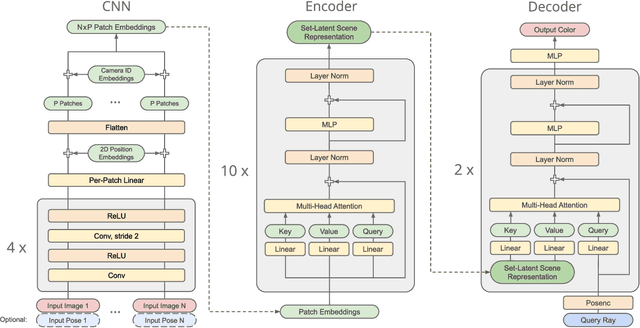
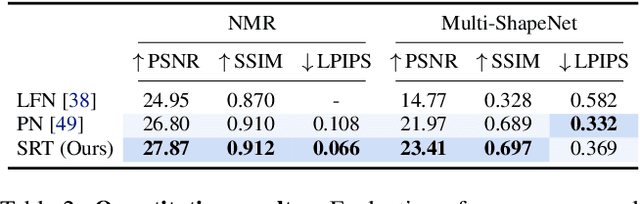
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
The Vision and the Perspective of Digital Tourism
Sep 20, 2021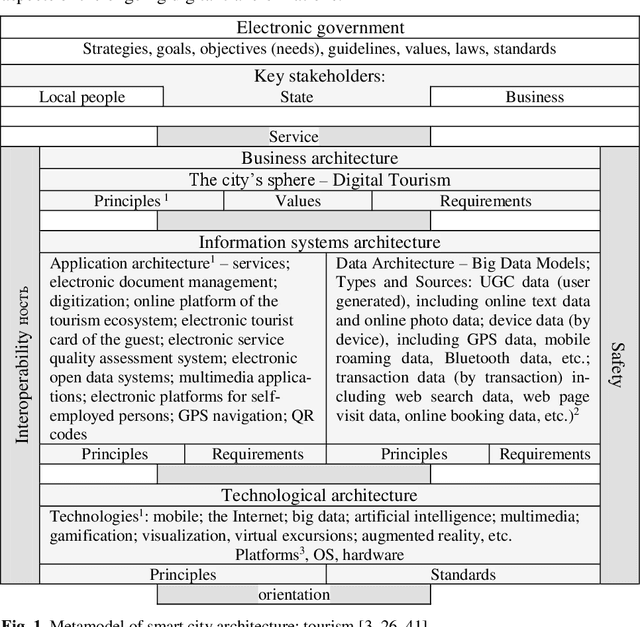
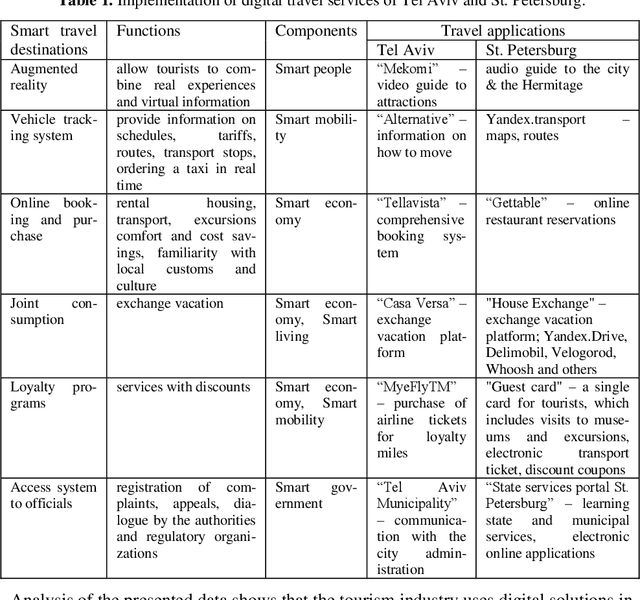
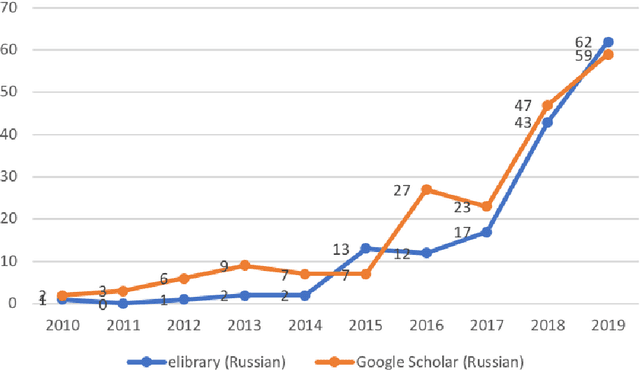
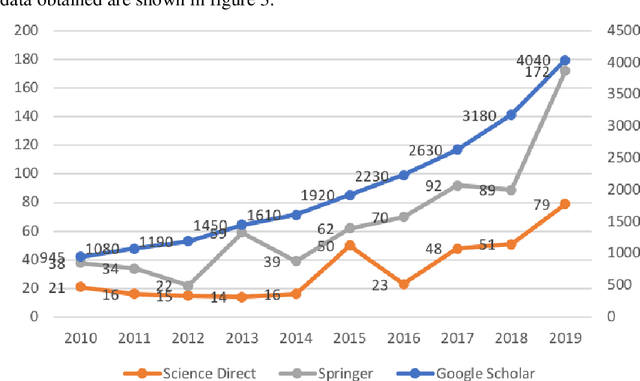
The dynamics of the modern information society changes the usual areas of human activity, generates various innovations based on the widespread use of Information and Communication Technologies (ICTs). Virtually, every activity today is technology related. In these conditions, scientific activity is also changing. Digitalization processes act as integrative to various scientific directions, which form the base for interdisciplinary scientific research. The study of their formation is an important scientific task aimed at predicting the development of both science and society as a whole. In this study, based on the integrated use of ICTs, we consider methods of the terminology base analysis in various interdisciplinary research directions on the instance of tourism in the digital age. The development of scientific interest in the area of digital tourism in Russian and global scientific discourses is also compared. The purpose of this paper is to proof the relevance of scientific study in the field of tourism digitalization, to identify the generic directions and trends of digital tourism, and to specify technologies for the implementation of digital tourism using the case study of St. Petersburg.
* 22nd Conference on Scientific Services & Internet (SSI-2020), Novorossiysk-Abrau (online), Russia, September 21-25, 2020
Dependency Induction Through the Lens of Visual Perception
Sep 20, 2021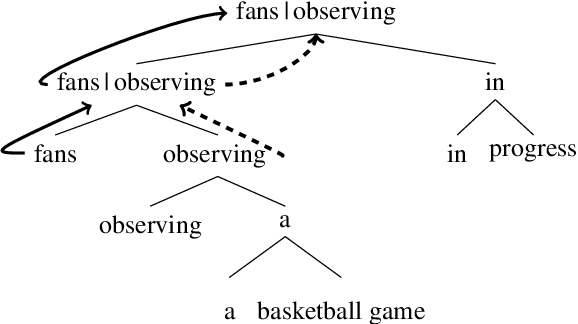
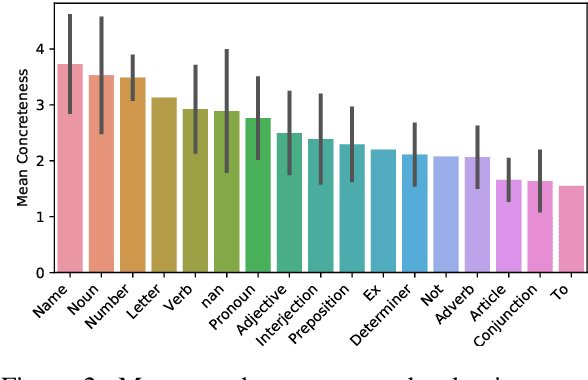
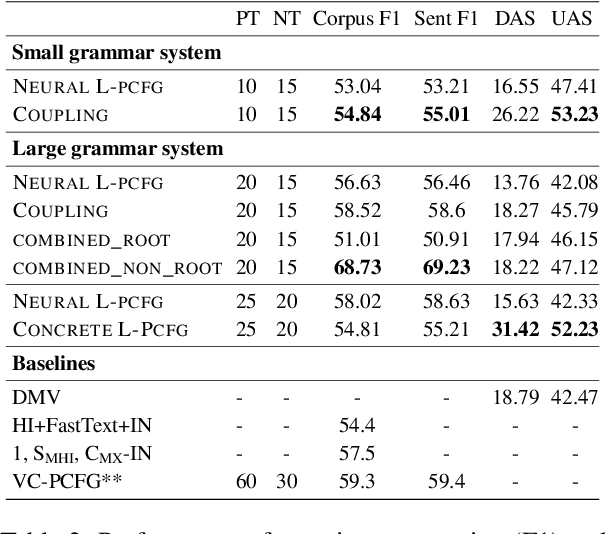
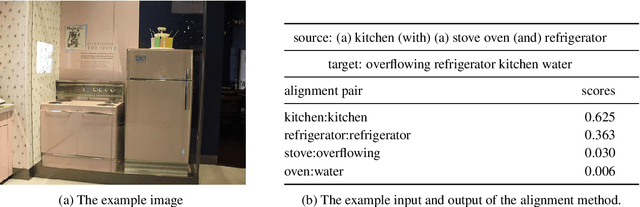
Most previous work on grammar induction focuses on learning phrasal or dependency structure purely from text. However, because the signal provided by text alone is limited, recently introduced visually grounded syntax models make use of multimodal information leading to improved performance in constituency grammar induction. However, as compared to dependency grammars, constituency grammars do not provide a straightforward way to incorporate visual information without enforcing language-specific heuristics. In this paper, we propose an unsupervised grammar induction model that leverages word concreteness and a structural vision-based heuristic to jointly learn constituency-structure and dependency-structure grammars. Our experiments find that concreteness is a strong indicator for learning dependency grammars, improving the direct attachment score (DAS) by over 50\% as compared to state-of-the-art models trained on pure text. Next, we propose an extension of our model that leverages both word concreteness and visual semantic role labels in constituency and dependency parsing. Our experiments show that the proposed extension outperforms the current state-of-the-art visually grounded models in constituency parsing even with a smaller grammar size.