 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Source Inference Attacks in Federated Learning
Sep 13, 2021
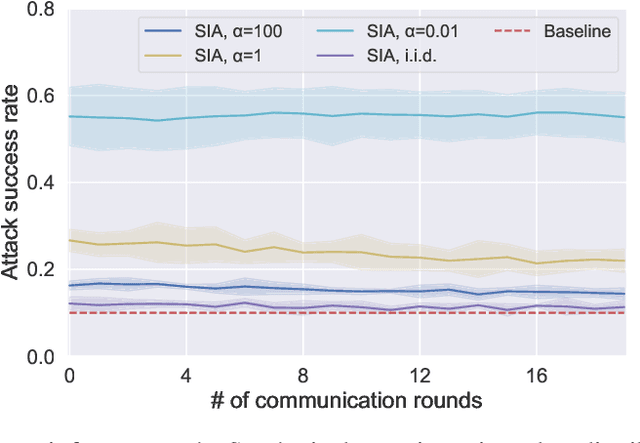

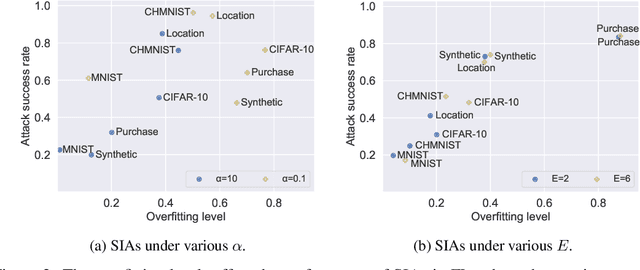
Federated learning (FL) has emerged as a promising privacy-aware paradigm that allows multiple clients to jointly train a model without sharing their private data. Recently, many studies have shown that FL is vulnerable to membership inference attacks (MIAs) that can distinguish the training members of the given model from the non-members. However, existing MIAs ignore the source of a training member, i.e., the information of which client owns the training member, while it is essential to explore source privacy in FL beyond membership privacy of examples from all clients. The leakage of source information can lead to severe privacy issues. For example, identification of the hospital contributing to the training of an FL model for COVID-19 pandemic can render the owner of a data record from this hospital more prone to discrimination if the hospital is in a high risk region. In this paper, we propose a new inference attack called source inference attack (SIA), which can derive an optimal estimation of the source of a training member. Specifically, we innovatively adopt the Bayesian perspective to demonstrate that an honest-but-curious server can launch an SIA to steal non-trivial source information of the training members without violating the FL protocol. The server leverages the prediction loss of local models on the training members to achieve the attack effectively and non-intrusively. We conduct extensive experiments on one synthetic and five real datasets to evaluate the key factors in an SIA, and the results show the efficacy of the proposed source inference attack.
Fusing Visuo-Tactile Perception into Kernelized Synergies for Robust Grasping and Fine Manipulation of Non-rigid Objects
Sep 15, 2021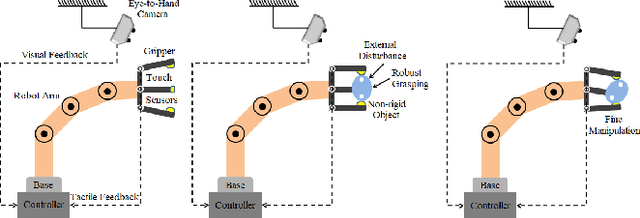
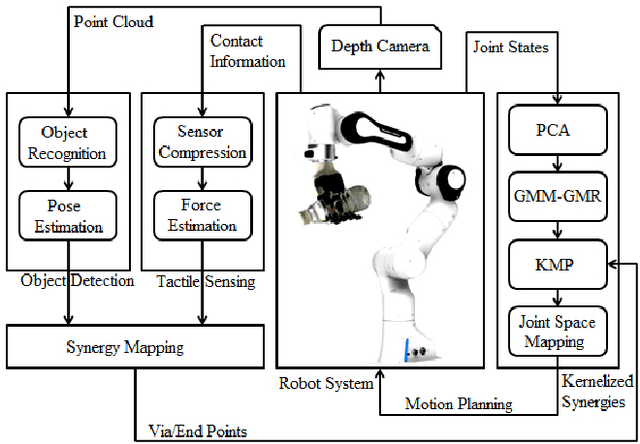
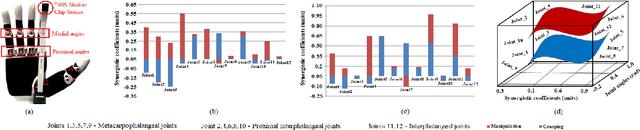
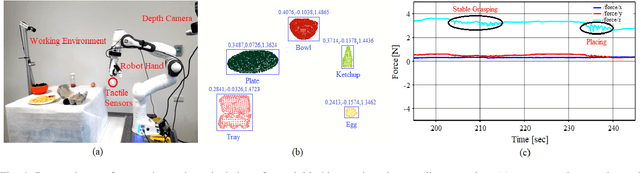
Handling non-rigid objects using robot hands necessities a framework that does not only incorporate human-level dexterity and cognition but also the multi-sensory information and system dynamics for robust and fine interactions. In this research, our previously developed kernelized synergies framework, inspired from human behaviour on reusing same subspace for grasping and manipulation, is augmented with visuo-tactile perception for autonomous and flexible adaptation to unknown objects. To detect objects and estimate their poses, a simplified visual pipeline using RANSAC algorithm with Euclidean clustering and SVM classifier is exploited. To modulate interaction efforts while grasping and manipulating non-rigid objects, the tactile feedback using T40S shokac chip sensor, generating 3D force information, is incorporated. Moreover, different kernel functions are examined in the kernelized synergies framework, to evaluate its performance and potential against task reproducibility, execution, generalization and synergistic re-usability. Experiments performed with robot arm-hand system validates the capability and usability of upgraded framework on stably grasping and dexterously manipulating the non-rigid objects.
$\infty$-former: Infinite Memory Transformer
Sep 15, 2021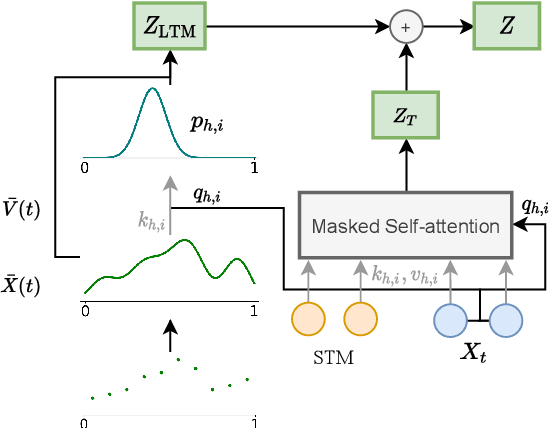

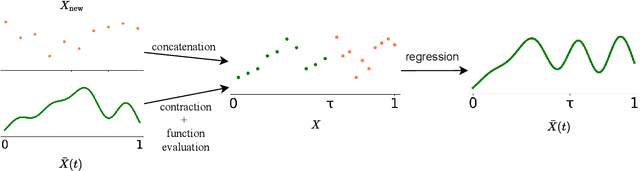

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.
Precise URL Phishing Detection Using Neural Networks
Oct 26, 2021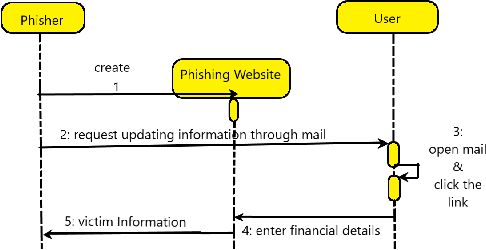
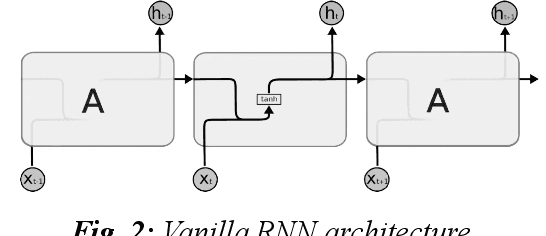
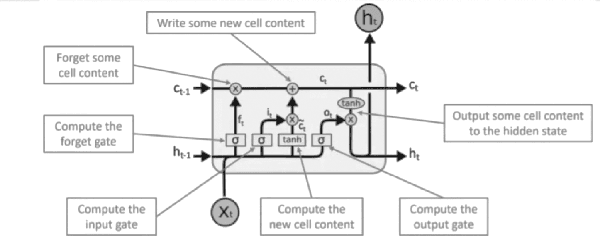
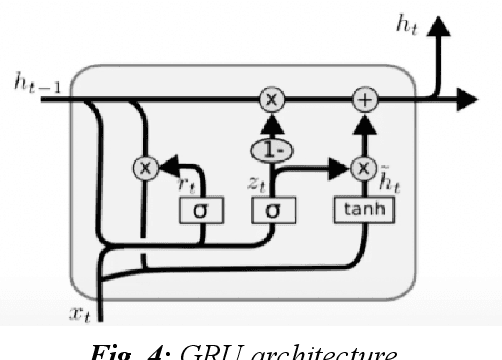
With the development of the Internet, ways of obtaining important data such as passwords and logins or sensitive personal data have increased. One of the ways to extract such information is page impersonation, also called phishing. Such websites do not provide service but collect sensitive details from the user. Here, we present you with ways to detect such malicious URLs with state of art accuracy with neural networks. Different from previous works, where web content, URL or traffic statistics are examined, we analyse only the URL text, making it faster and which detects zero-day attacks. The network is optimised and can be used even on small devices such as Ras-Pi without a change in performance.
Quality and Cost Trade-offs in Passage Re-ranking Task
Nov 18, 2021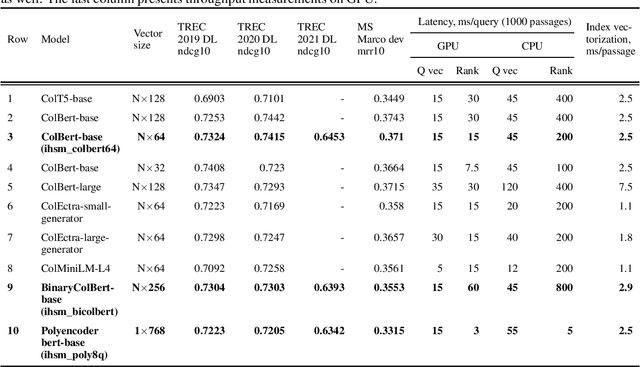
Deep learning models named transformers achieved state-of-the-art results in a vast majority of NLP tasks at the cost of increased computational complexity and high memory consumption. Using the transformer model in real-time inference becomes a major challenge when implemented in production, because it requires expensive computational resources. The more executions of a transformer are needed the lower the overall throughput is, and switching to the smaller encoders leads to the decrease of accuracy. Our paper is devoted to the problem of how to choose the right architecture for the ranking step of the information retrieval pipeline, so that the number of required calls of transformer encoder is minimal with the maximum achievable quality of ranking. We investigated several late-interaction models such as Colbert and Poly-encoder architectures along with their modifications. Also, we took care of the memory footprint of the search index and tried to apply the learning-to-hash method to binarize the output vectors from the transformer encoders. The results of the evaluation are provided using TREC 2019-2021 and MS Marco dev datasets.
HYPERION: Hyperspectral Penetrating-type Ellipsoidal Reconstruction for Terahertz Blind Source Separation
Sep 12, 2021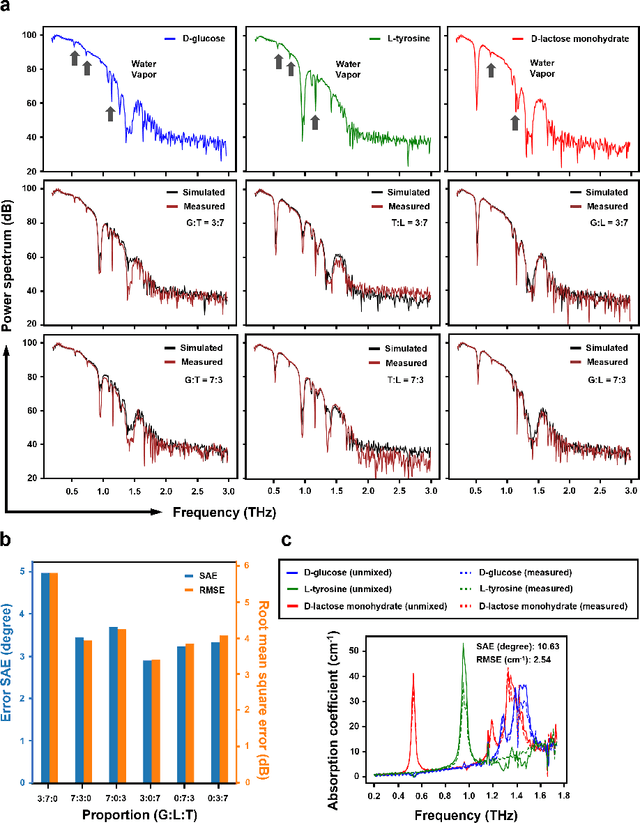
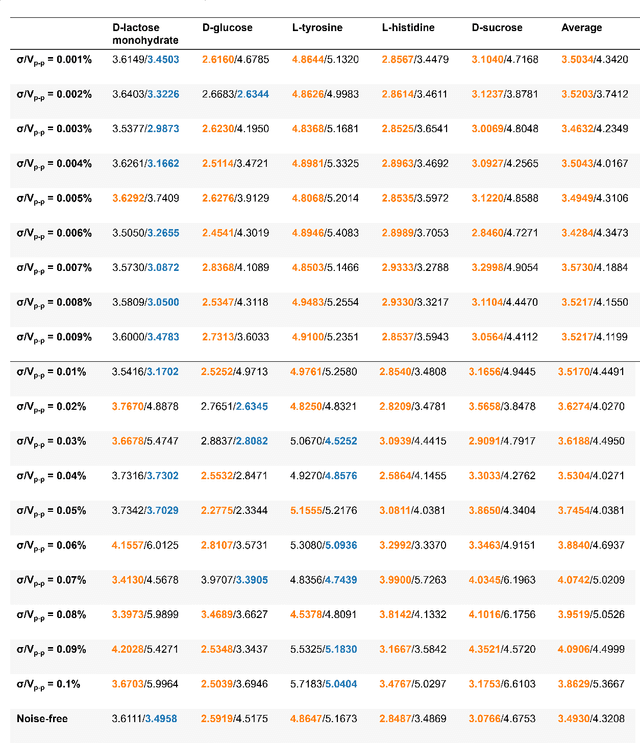
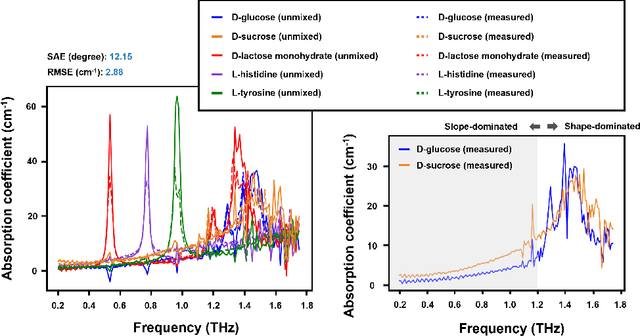

Terahertz (THz) technology has been a great candidate for applications, including pharmaceutic analysis, chemical identification, and remote sensing and imaging due to its non-invasive and non-destructive properties. Among those applications, penetrating-type hyperspectral THz signals, which provide crucial material information, normally involve a noisy, complex mixture system. Additionally, the measured THz signals could be ill-conditioned due to the overlap of the material absorption peak in the measured bands. To address those issues, we consider penetrating-type signal mixtures and aim to develop a \textit{blind} hyperspectral unmixing (HU) method without requiring any information from a prebuilt database. The proposed HYperspectral Penetrating-type Ellipsoidal ReconstructION (HYPERION) algorithm is unsupervised, not relying on collecting extensive data or sophisticated model training. Instead, it is developed based on elegant ellipsoidal geometry under a very mild requirement on data purity, whose excellent efficacy is experimentally demonstrated.
Topic Detection and Tracking with Time-Aware Document Embeddings
Dec 12, 2021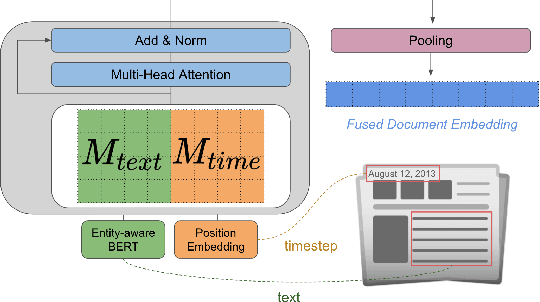

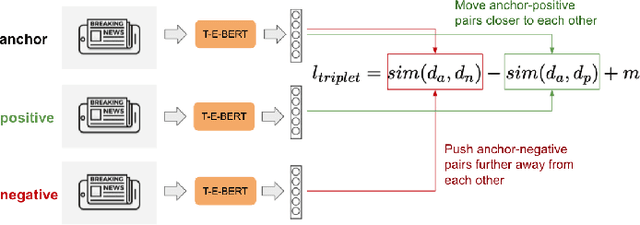
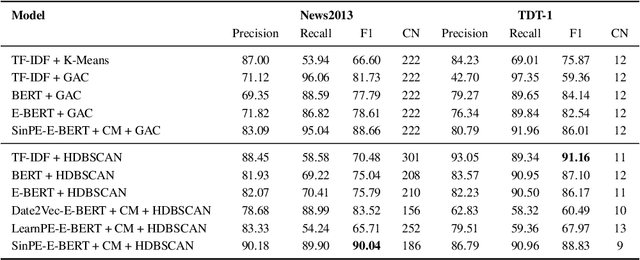
The time at which a message is communicated is a vital piece of metadata in many real-world natural language processing tasks such as Topic Detection and Tracking (TDT). TDT systems aim to cluster a corpus of news articles by event, and in that context, stories that describe the same event are likely to have been written at around the same time. Prior work on time modeling for TDT takes this into account, but does not well capture how time interacts with the semantic nature of the event. For example, stories about a tropical storm are likely to be written within a short time interval, while stories about a movie release may appear over weeks or months. In our work, we design a neural method that fuses temporal and textual information into a single representation of news documents for event detection. We fine-tune these time-aware document embeddings with a triplet loss architecture, integrate the model into downstream TDT systems, and evaluate the systems on two benchmark TDT data sets in English. In the retrospective setting, we apply clustering algorithms to the time-aware embeddings and show substantial improvements over baselines on the News2013 data set. In the online streaming setting, we add our document encoder to an existing state-of-the-art TDT pipeline and demonstrate that it can benefit the overall performance. We conduct ablation studies on the time representation and fusion algorithm strategies, showing that our proposed model outperforms alternative strategies. Finally, we probe the model to examine how it handles recurring events more effectively than previous TDT systems.
Will bots take over the supply chain? Revisiting Agent-based supply chain automation
Sep 03, 2021Agent-based systems have the capability to fuse information from many distributed sources and create better plans faster. This feature makes agent-based systems naturally suitable to address the challenges in Supply Chain Management (SCM). Although agent-based supply chains systems have been proposed since early 2000; industrial uptake of them has been lagging. The reasons quoted include the immaturity of the technology, a lack of interoperability with supply chain information systems, and a lack of trust in Artificial Intelligence (AI). In this paper, we revisit the agent-based supply chain and review the state of the art. We find that agent-based technology has matured, and other supporting technologies that are penetrating supply chains; are filling in gaps, leaving the concept applicable to a wider range of functions. For example, the ubiquity of IoT technology helps agents "sense" the state of affairs in a supply chain and opens up new possibilities for automation. Digital ledgers help securely transfer data between third parties, making agent-based information sharing possible, without the need to integrate Enterprise Resource Planning (ERP) systems. Learning functionality in agents enables agents to move beyond automation and towards autonomy. We note this convergence effect through conceptualising an agent-based supply chain framework, reviewing its components, and highlighting research challenges that need to be addressed in moving forward.
* 38 pages, 5 figures
Predicting Levels of Household Electricity Consumption in Low-Access Settings
Dec 15, 2021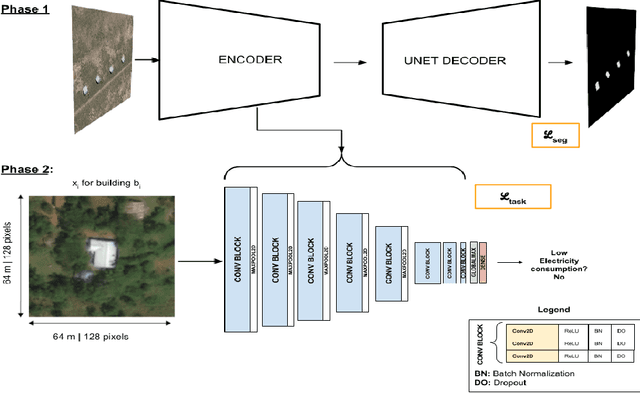

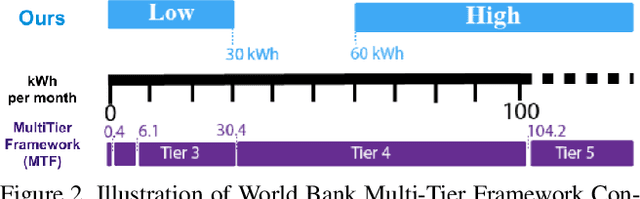
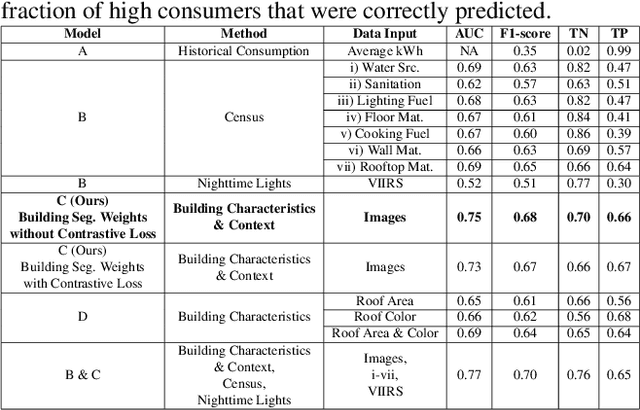
In low-income settings, the most critical piece of information for electric utilities is the anticipated consumption of a customer. Electricity consumption assessment is difficult to do in settings where a significant fraction of households do not yet have an electricity connection. In such settings the absolute levels of anticipated consumption can range from 5-100 kWh/month, leading to high variability amongst these customers. Precious resources are at stake if a significant fraction of low consumers are connected over those with higher consumption. This is the first study of it's kind in low-income settings that attempts to predict a building's consumption and not that of an aggregate administrative area. We train a Convolutional Neural Network (CNN) over pre-electrification daytime satellite imagery with a sample of utility bills from 20,000 geo-referenced electricity customers in Kenya (0.01% of Kenya's residential customers). This is made possible with a two-stage approach that uses a novel building segmentation approach to leverage much larger volumes of no-cost satellite imagery to make the most of scarce and expensive customer data. Our method shows that competitive accuracies can be achieved at the building level, addressing the challenge of consumption variability. This work shows that the building's characteristics and it's surrounding context are both important in predicting consumption levels. We also evaluate the addition of lower resolution geospatial datasets into the training process, including nighttime lights and census-derived data. The results are already helping inform site selection and distribution-level planning, through granular predictions at the level of individual structures in Kenya and there is no reason this cannot be extended to other countries.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021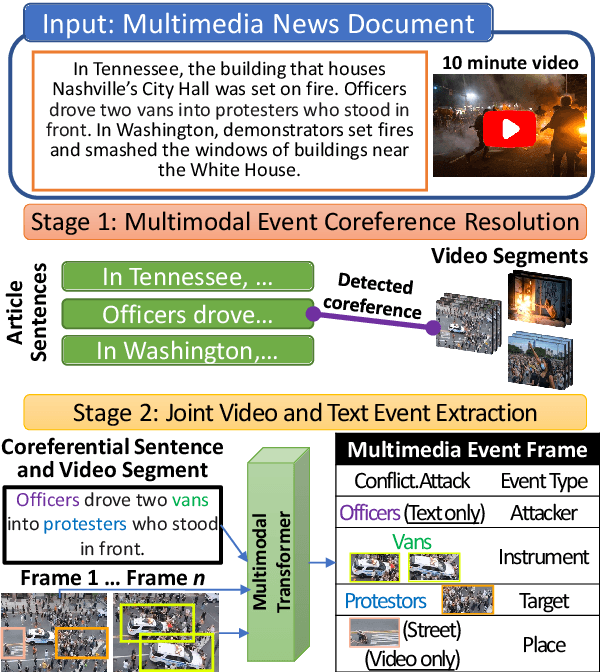
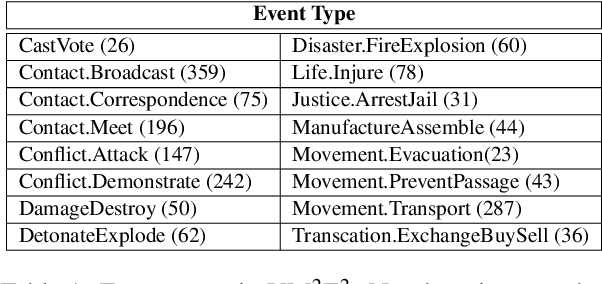


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.