 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Social Recommendation with Self-Supervised Metagraph Informax Network
Oct 08, 2021

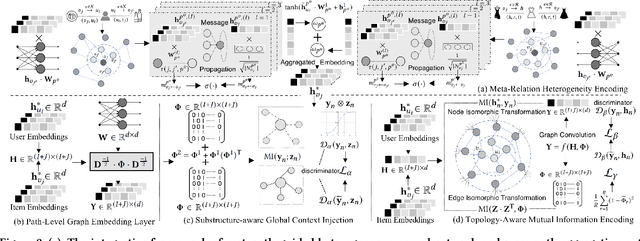

In recent years, researchers attempt to utilize online social information to alleviate data sparsity for collaborative filtering, based on the rationale that social networks offers the insights to understand the behavioral patterns. However, due to the overlook of inter-dependent knowledge across items (e.g., categories of products), existing social recommender systems are insufficient to distill the heterogeneous collaborative signals from both user and item sides. In this work, we propose a Self-Supervised Metagraph Infor-max Network (SMIN) which investigates the potential of jointly incorporating social- and knowledge-aware relational structures into the user preference representation for recommendation. To model relation heterogeneity, we design a metapath-guided heterogeneous graph neural network to aggregate feature embeddings from different types of meta-relations across users and items, em-powering SMIN to maintain dedicated representations for multi-faceted user- and item-wise dependencies. Additionally, to inject high-order collaborative signals, we generalize the mutual information learning paradigm under the self-supervised graph-based collaborative filtering. This endows the expressive modeling of user-item interactive patterns, by exploring global-level collaborative relations and underlying isomorphic transformation property of graph topology. Experimental results on several real-world datasets demonstrate the effectiveness of our SMIN model over various state-of-the-art recommendation methods. We release our source code at https://github.com/SocialRecsys/SMIN.
An Energy Consumption Model for Electrical Vehicle Networks via Extended Federated-learning
Nov 13, 2021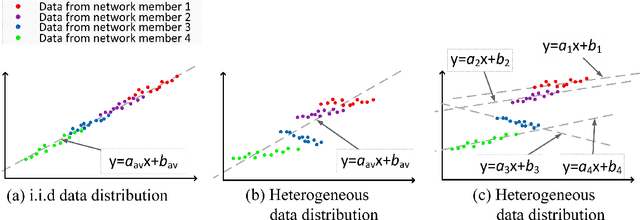

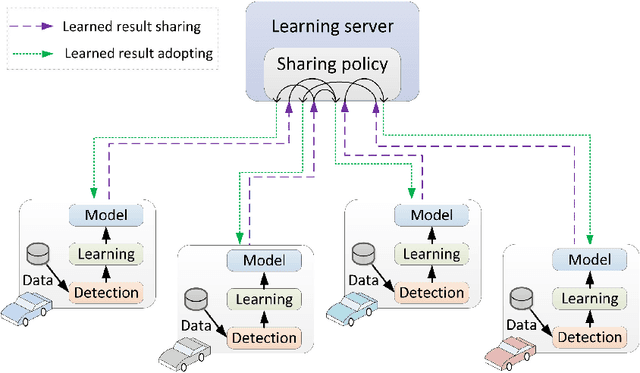
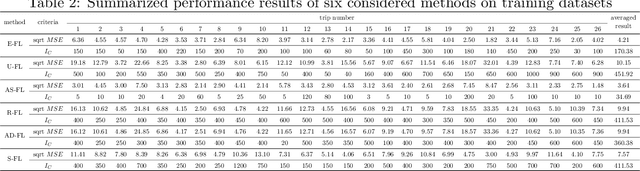
Electrical vehicle (EV) raises to promote an eco-sustainable society. Nevertheless, the ``range anxiety'' of EV hinders its wider acceptance among customers. This paper proposes a novel solution to range anxiety based on a federated-learning model, which is capable of estimating battery consumption and providing energy-efficient route planning for vehicle networks. Specifically, the new approach extends the federated-learning structure with two components: anomaly detection and sharing policy. The first component identifies preventing factors in model learning, while the second component offers guidelines for information sharing amongst vehicle networks when the sharing is necessary to preserve learning efficiency. The two components collaborate to enhance learning robustness against data heterogeneities in networks. Numerical experiments are conducted, and the results show that compared with considered solutions, the proposed approach could provide higher accuracy of battery-consumption estimation for vehicles under heterogeneous data distributions, without increasing the time complexity or transmitting raw data among vehicle networks.
AirObject: A Temporally Evolving Graph Embedding for Object Identification
Nov 30, 2021
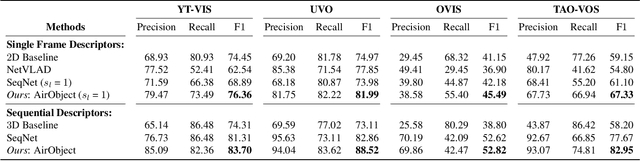
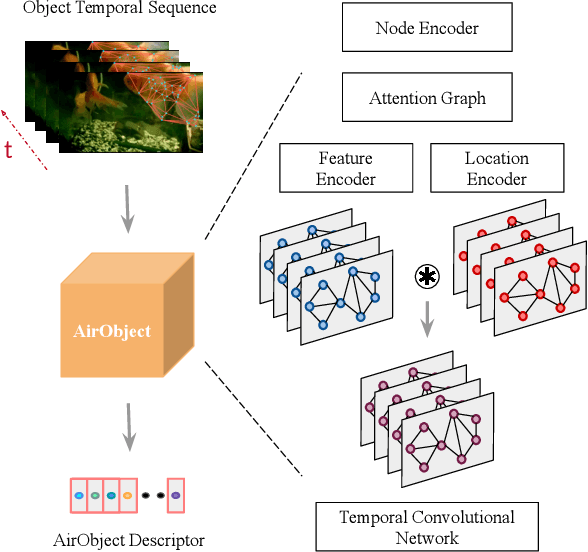
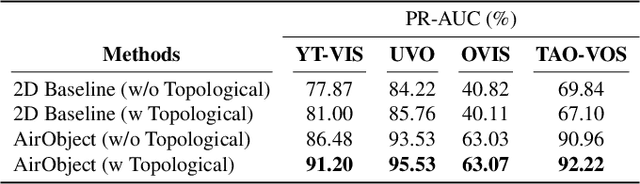
Object encoding and identification are vital for robotic tasks such as autonomous exploration, semantic scene understanding, and re-localization. Previous approaches have attempted to either track objects or generate descriptors for object identification. However, such systems are limited to a "fixed" partial object representation from a single viewpoint. In a robot exploration setup, there is a requirement for a temporally "evolving" global object representation built as the robot observes the object from multiple viewpoints. Furthermore, given the vast distribution of unknown novel objects in the real world, the object identification process must be class-agnostic. In this context, we propose a novel temporal 3D object encoding approach, dubbed AirObject, to obtain global keypoint graph-based embeddings of objects. Specifically, the global 3D object embeddings are generated using a temporal convolutional network across structural information of multiple frames obtained from a graph attention-based encoding method. We demonstrate that AirObject achieves the state-of-the-art performance for video object identification and is robust to severe occlusion, perceptual aliasing, viewpoint shift, deformation, and scale transform, outperforming the state-of-the-art single-frame and sequential descriptors. To the best of our knowledge, AirObject is one of the first temporal object encoding methods.
Direct Noisy Speech Modeling for Noisy-to-Noisy Voice Conversion
Nov 13, 2021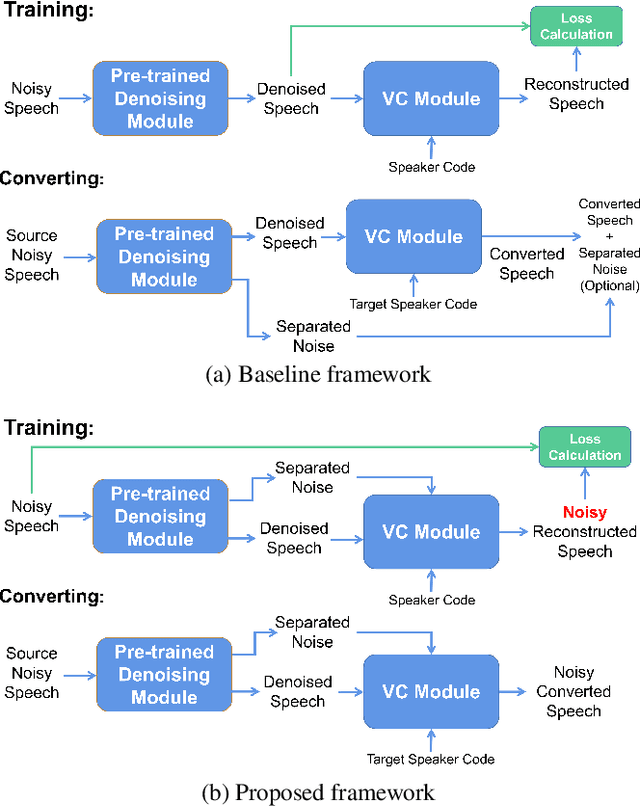
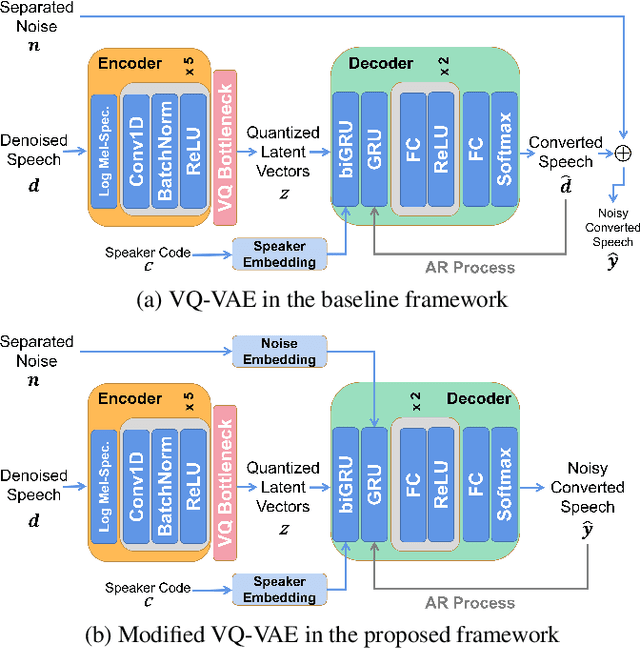
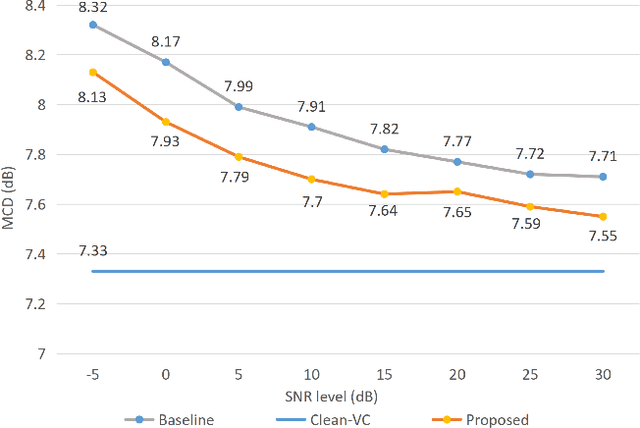
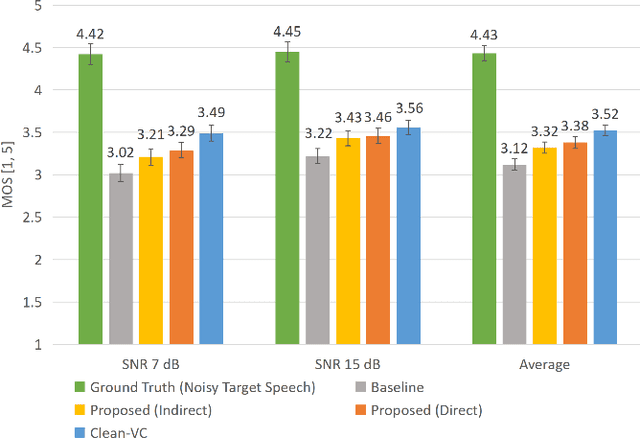
Beyond the conventional voice conversion (VC) where the speaker information is converted without altering the linguistic content, the background sounds are informative and need to be retained in some real-world scenarios, such as VC in movie/video and VC in music where the voice is entangled with background sounds. As a new VC framework, we have developed a noisy-to-noisy (N2N) VC framework to convert the speaker's identity while preserving the background sounds. Although our framework consisting of a denoising module and a VC module well handles the background sounds, the VC module is sensitive to the distortion caused by the denoising module. To address this distortion issue, in this paper we propose the improved VC module to directly model the noisy speech waveform while controlling the background sounds. The experimental results have demonstrated that our improved framework significantly outperforms the previous one and achieves an acceptable score in terms of naturalness, while reaching comparable similarity performance to the upper bound of our framework.
Multiway Non-rigid Point Cloud Registration via Learned Functional Map Synchronization
Nov 25, 2021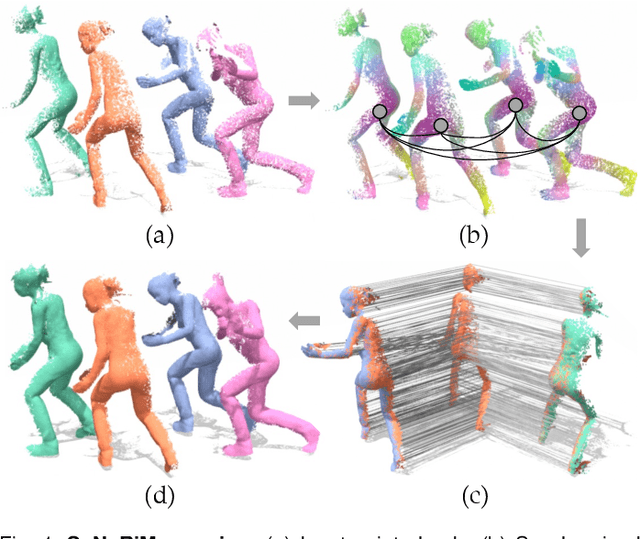
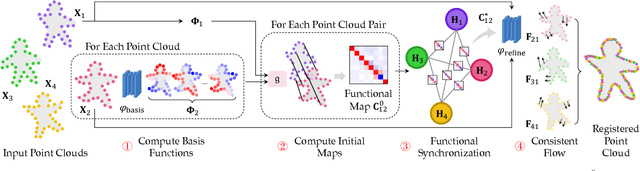
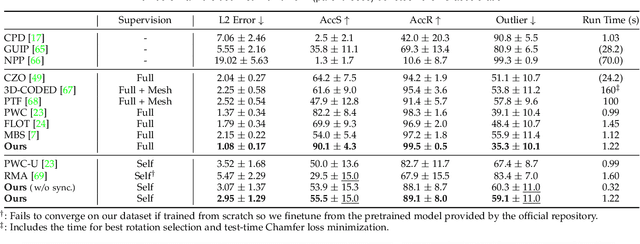
We present SyNoRiM, a novel way to jointly register multiple non-rigid shapes by synchronizing the maps relating learned functions defined on the point clouds. Even though the ability to process non-rigid shapes is critical in various applications ranging from computer animation to 3D digitization, the literature still lacks a robust and flexible framework to match and align a collection of real, noisy scans observed under occlusions. Given a set of such point clouds, our method first computes the pairwise correspondences parameterized via functional maps. We simultaneously learn potentially non-orthogonal basis functions to effectively regularize the deformations, while handling the occlusions in an elegant way. To maximally benefit from the multi-way information provided by the inferred pairwise deformation fields, we synchronize the pairwise functional maps into a cycle-consistent whole thanks to our novel and principled optimization formulation. We demonstrate via extensive experiments that our method achieves a state-of-the-art performance in registration accuracy, while being flexible and efficient as we handle both non-rigid and multi-body cases in a unified framework and avoid the costly optimization over point-wise permutations by the use of basis function maps.
Source Inference Attacks in Federated Learning
Sep 13, 2021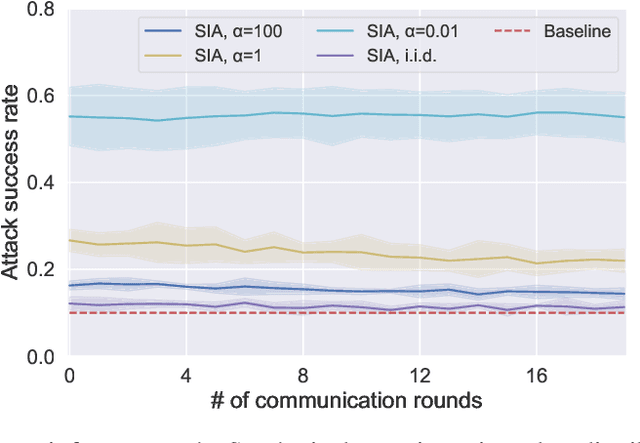

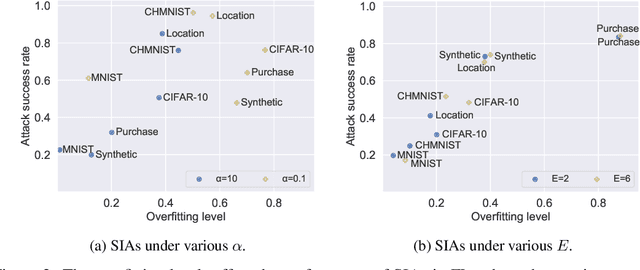
Federated learning (FL) has emerged as a promising privacy-aware paradigm that allows multiple clients to jointly train a model without sharing their private data. Recently, many studies have shown that FL is vulnerable to membership inference attacks (MIAs) that can distinguish the training members of the given model from the non-members. However, existing MIAs ignore the source of a training member, i.e., the information of which client owns the training member, while it is essential to explore source privacy in FL beyond membership privacy of examples from all clients. The leakage of source information can lead to severe privacy issues. For example, identification of the hospital contributing to the training of an FL model for COVID-19 pandemic can render the owner of a data record from this hospital more prone to discrimination if the hospital is in a high risk region. In this paper, we propose a new inference attack called source inference attack (SIA), which can derive an optimal estimation of the source of a training member. Specifically, we innovatively adopt the Bayesian perspective to demonstrate that an honest-but-curious server can launch an SIA to steal non-trivial source information of the training members without violating the FL protocol. The server leverages the prediction loss of local models on the training members to achieve the attack effectively and non-intrusively. We conduct extensive experiments on one synthetic and five real datasets to evaluate the key factors in an SIA, and the results show the efficacy of the proposed source inference attack.
A Deep Learning Approach for Macroscopic Energy Consumption Prediction with Microscopic Quality for Electric Vehicles
Nov 25, 2021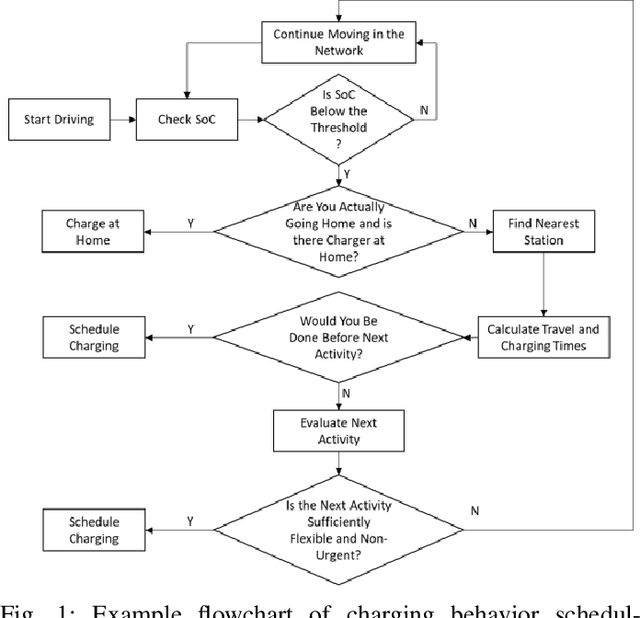
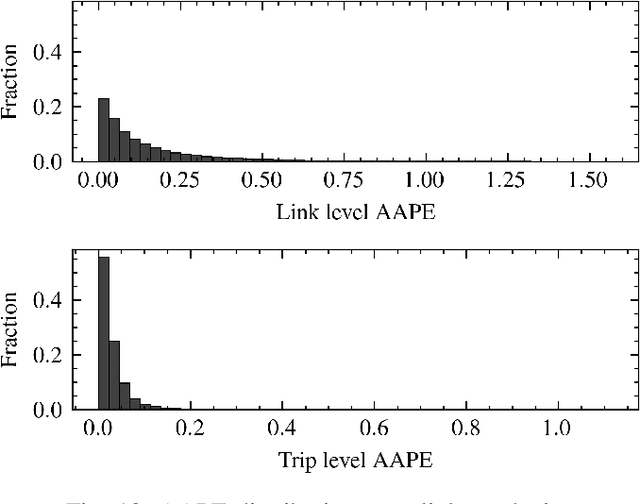
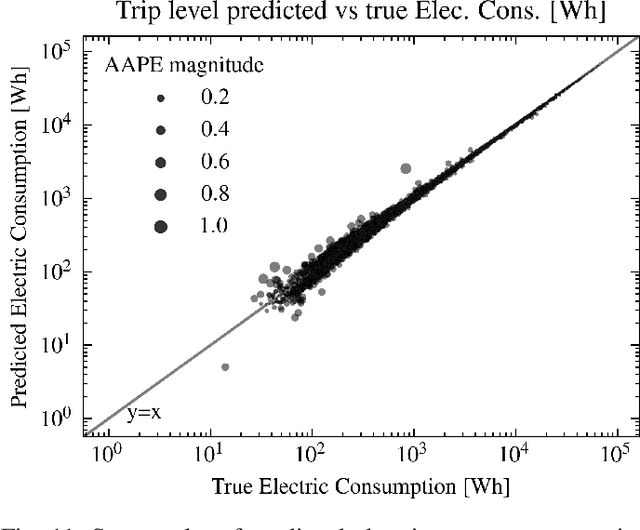
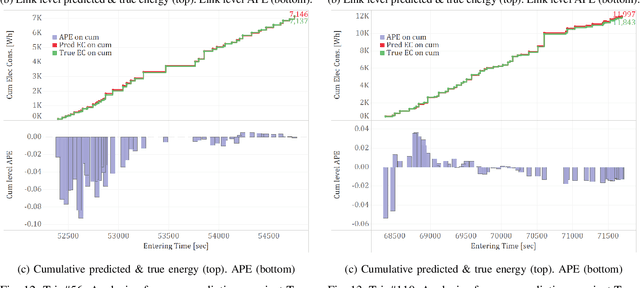
This paper presents a machine learning approach to model the electric consumption of electric vehicles at macroscopic level, i.e., in the absence of a speed profile, while preserving microscopic level accuracy. For this work, we leveraged a high-performance, agent-based transportation tool to model trips that occur in the Greater Chicago region under various scenario changes, along with physics-based modeling and simulation tools to provide high-fidelity energy consumption values. The generated results constitute a very large dataset of vehicle-route energy outcomes that capture variability in vehicle and routing setting, and in which high-fidelity time series of vehicle speed dynamics is masked. We show that although all internal dynamics that affect energy consumption are masked, it is possible to learn aggregate-level energy consumption values quite accurately with a deep learning approach. When large-scale data is available, and with carefully tailored feature engineering, a well-designed model can overcome and retrieve latent information. This model has been deployed and integrated within POLARIS Transportation System Simulation Tool to support real-time behavioral transportation models for individual charging decision-making, and rerouting of electric vehicles.
Fusing Visuo-Tactile Perception into Kernelized Synergies for Robust Grasping and Fine Manipulation of Non-rigid Objects
Sep 15, 2021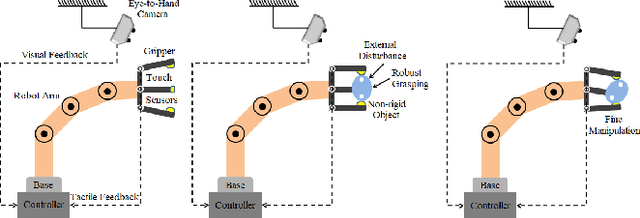
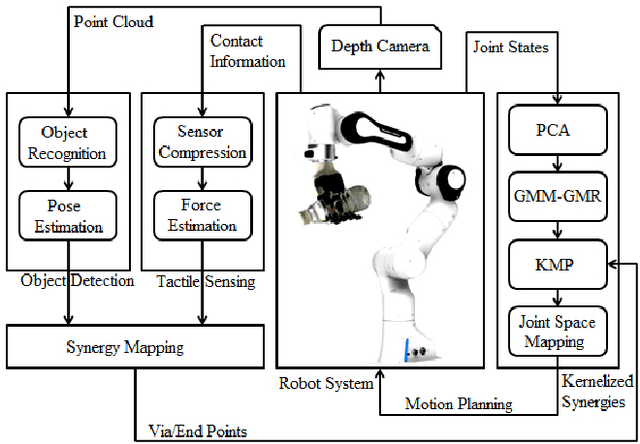
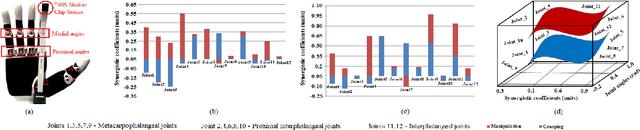
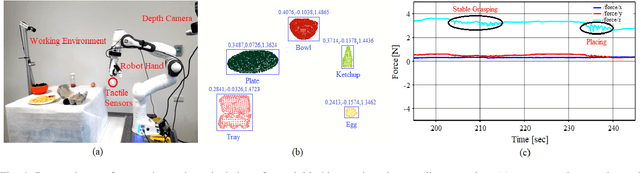
Handling non-rigid objects using robot hands necessities a framework that does not only incorporate human-level dexterity and cognition but also the multi-sensory information and system dynamics for robust and fine interactions. In this research, our previously developed kernelized synergies framework, inspired from human behaviour on reusing same subspace for grasping and manipulation, is augmented with visuo-tactile perception for autonomous and flexible adaptation to unknown objects. To detect objects and estimate their poses, a simplified visual pipeline using RANSAC algorithm with Euclidean clustering and SVM classifier is exploited. To modulate interaction efforts while grasping and manipulating non-rigid objects, the tactile feedback using T40S shokac chip sensor, generating 3D force information, is incorporated. Moreover, different kernel functions are examined in the kernelized synergies framework, to evaluate its performance and potential against task reproducibility, execution, generalization and synergistic re-usability. Experiments performed with robot arm-hand system validates the capability and usability of upgraded framework on stably grasping and dexterously manipulating the non-rigid objects.
HYPERION: Hyperspectral Penetrating-type Ellipsoidal Reconstruction for Terahertz Blind Source Separation
Sep 12, 2021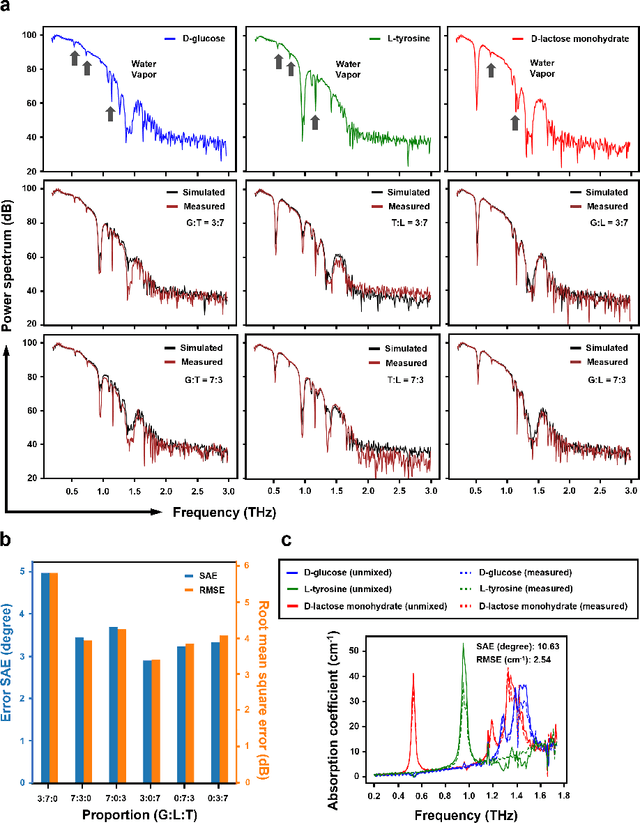
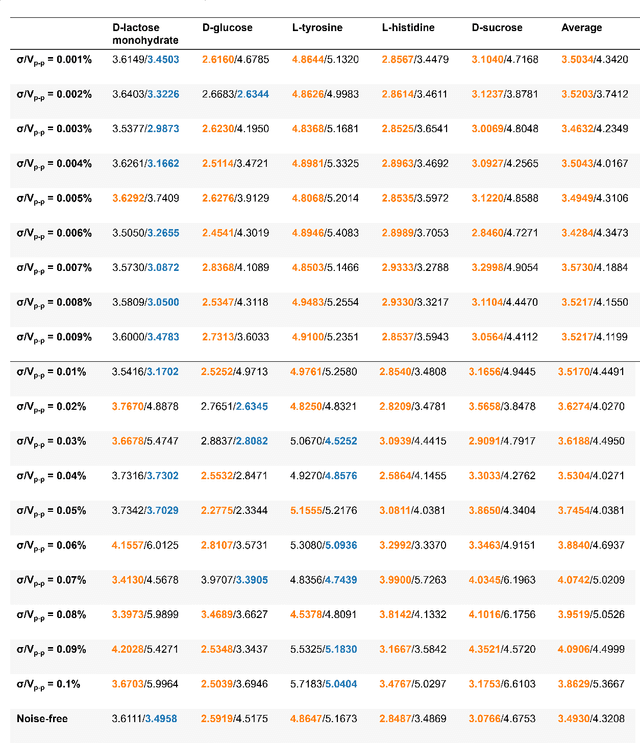
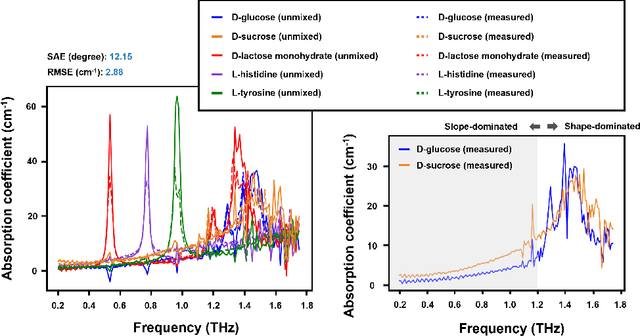

Terahertz (THz) technology has been a great candidate for applications, including pharmaceutic analysis, chemical identification, and remote sensing and imaging due to its non-invasive and non-destructive properties. Among those applications, penetrating-type hyperspectral THz signals, which provide crucial material information, normally involve a noisy, complex mixture system. Additionally, the measured THz signals could be ill-conditioned due to the overlap of the material absorption peak in the measured bands. To address those issues, we consider penetrating-type signal mixtures and aim to develop a \textit{blind} hyperspectral unmixing (HU) method without requiring any information from a prebuilt database. The proposed HYperspectral Penetrating-type Ellipsoidal ReconstructION (HYPERION) algorithm is unsupervised, not relying on collecting extensive data or sophisticated model training. Instead, it is developed based on elegant ellipsoidal geometry under a very mild requirement on data purity, whose excellent efficacy is experimentally demonstrated.
$\infty$-former: Infinite Memory Transformer
Sep 15, 2021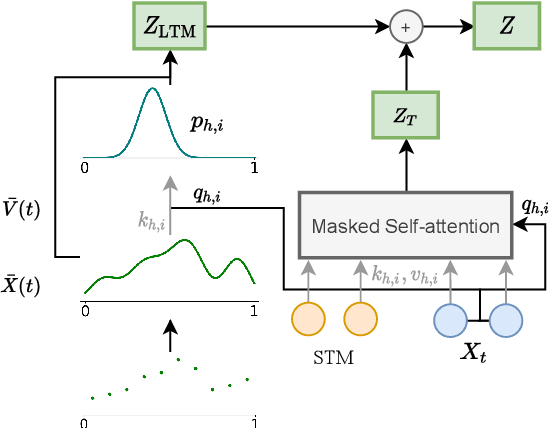

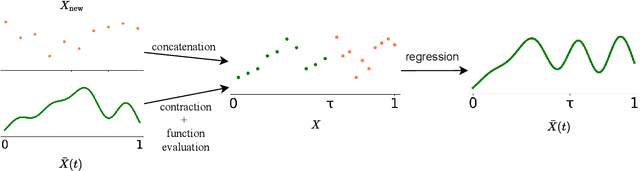

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.